A Proof That P Is Not Equal To NP?
A serious proof that claims to have resolved the P=NP question.

Vinay Deolalikar is a Principal Research Scientist at HP Labs who has done important research in various areas of networks. He also has worked on complexity theory, including previous work on infinite versions of the P=NP question. He has just claimed that he has a proof that P is not equal to NP. That’s right: 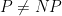
Today I will talk about his paper. So far I have only had a chance to glance at the paper; I will look at it more carefully in the future. I do not know what to think right now, but I am certainly hopeful.
The Paper
Deolalikar’s draft paper is here—he was kind enough to give me the pointer to his paper. For now please understand that this is a “preliminary version.” See the discussion by Greg Baker, who first posted on his paper.
At first glance it is a long, well written paper, by a serious researcher. He clearly knows a great deal of complexity theory and mathematics. His Ph.D. thesis at USC is titled:
On splitting places of degree one in extensions of algebraic function fields, towers of function fields meeting asymptotic bounds, and basis constructions for algebraic-geometric codes.
My first thought is who knows—perhaps this is the solution we have all have been waiting for. If it is correct, the Clay list will drop down to five. I assume he would take the prize.
But first there is the small issue of correctness. Is his paper correct?
I suggest you look at his paper to see his own summary of his approach, and of course the details of his proof. At the highest level he is using the characterization of polynomial time via finite model theory. His proof uses the beautiful result of Moshe Vardi (1982) and Neil Immerman (1986):
Theorem: On ordered structures, a relation is defined by a first order formula plus the Least Fixed Point (LFP) operator if and only if it is computable in polynomial time.
Then, he attacks SAT directly. He creates an ordered structure that encodes SAT. He then argues if P=NP, then by the above theorem it must follow that SAT has certain structural properties. These properties have to do with the structure of random SAT. This connection between finite model theory and random SAT models seems new to me.
The one thing that strikes me immediately is his use of finite model theory. This is one area of logic that has already led to at least one breakthrough before in complexity theory. I believe that Neil used insights from this area to discover his famous proof that 
An obvious worry about his proof, just from a quick look, is the issue of relativization. I believe that the LFP characterization, and similar first order arguments do relativize in general. However, it is possible that his use of concretely encoded structures prevents his entire argument from relativizing. We will need to check carefully that his proof strategy evades this limitation. I am on record as not being a fan of oracle results, so if this is the problem for his proof, I will have to re-think my position. Oh well.
Deolalikar does cite both Baker-Gill-Solovay for relativization and Razborov-Rudich for the “Natural Proofs” obstacle. His proof strategy ostensibly evades the latter because it exploits a uniform characterization of P that may not extend to give lower bounds against circuits. In fact the paper does not state a concrete time lower bound for SAT, as the proof is by contradiction. Since the gap in the contradiction is between “



Open Problems
Is his paper correct? How does he avoid all the “barriers” that have been claimed to surround the P=NP question? Let’s hope it all checks out.
Trackbacks
- P NP ? - The Quantum Pontiff
- Tweets that mention A Proof That P Is Not Equal To NP? « Gödel’s Lost Letter and P=NP -- Topsy.com
- A Random Forest» Blog Archive » P ≠ NP
- Quantized Thoughts » Blog Archive » P vs NP finally resolved?
- Echoes in the blogodome: P!=NP? | Generic Language
- This Week in the Universe: August 3rd – August 9th « The Language of Bad Physics
- A proof that P is not equal to NP? « An Ergodic Walk
- P not equal to NP; proof atlast? « Stranger’s Words
- 惠普研究员Vinay Deolalikar声称证明P!= NP, 102页PDF | 丕子
- Everything Is Vanity » Blog Archive » A Proof That P is Not Equal To Np? GDel’s Lost Letter and P=Np
- P 不等于 NP……么? - Apple4.us
- Wiskundemeisjes » Blog Archive » Bewijs voor P != NP ???
- P!=NP?! « Simple Notions
- A Proof That P Is Not Equal To NP? « Gödel's Lost Letter and P=NP | Blogavert
- This could be a landmark day in computer science « Interesting items
- A relatively serious proof that P ≠ NP? « Antonio E. Porreca
- Proof of P≠NP – iProgrammer | Muratayumi.com
- P Np
- Proof of P≠NP – iProgrammer » Reading, Deolaliker, Proof, That, Liptons, Richard » Auto Move is.com
- A Proof That P Is Not Equal To NP? « Gödel's Lost Letter and P=NP
- Proof of P?NP – iProgrammer
- Proof of P≠NP – iProgrammer » Reading, Deolaliker, Proof, That, Liptons, Richard » Season Style
- How to get everyone talking about your research!
- A Proof That P Is Not Equal To NP | Centralized Breaking News Source
- A Proof That P Is Not Equal To NP? « Gödel's Lost Letter and P=NP « Arie Blog
- P != np
- Vinay Deolalikar 證明了 P 不等於 NP? « Chicken's Finite Playground
- P ≠ NP ? [ Vinay Deolalikar from HP Labs Publishes His Proof to the Web, $1Million Clay Institute Prize May Very Well Await ] | Computational Legal Studies™
- P is not NP: a proof perhaps « Karela Fry
- A Proof That P Is Not Equal To NP? « Gödel's Lost Letter and P=NP | Blog News
- Deolalikar’s manuscript « Constraints
- Wordpress Belarus » Blog Archive » A Proof That P Is Not Equal To NP? « Gödel's Lost Letter and P=NP
- Initial Reaction to New P!=NP Paper | Reflections on Operations Research
- P 不等于 NP……么? « lei
- P or NP, that is the question! « OU Math Club
- A Proof That P Is Not Equal To NP? « Gödel's Lost Letter and P=NP - http
- Computing Community Consortium
- A Proof That P Is Not Equal To NP? | Skoopio.com
- Biweekly Links – 08-09-2010 « God, Your Book Is Great !!
- Top Posts — WordPress.com
- HP Researcher Claims to Crack Compsci Complexity Conundrum | Hot Electronics Trends
- HP Researcher Claims to Crack Compsci Complexity Conundrum | Find Tech News
- P≠NP. at webCONSUL
- Issues In The Proof That P≠NP « Gödel’s Lost Letter and P=NP
- Pembuktian P≠NP? « Proof { }
- a new paper P # NP, it might be an unsurprised huge milestone of the CS « Yet another tech crunch blog
- 代码疯子 » 惠普研究员称已解决计算机科学第一难题
- Posible solución al problema P vs NP « Series Divergentes
- הוכחה ש-P שונה מ-NP? « לא מדויק
- A Proof That P Is Not Equal To NP? « Gödel's Lost Letter and P=NP | Wordpress Headlines
- P≠NP? | Q
- Vinay Deolalikar says P ≠ NP « viXra log
- P ≠ NP? | Elias Diab log
- P ≠ NP? It’s bad news for the power of computing | HiTech Dot Com
- P ≠ NP? « The Math Less Traveled
- dia a dia, bit a bit… por Silvio Meira » será que P~=NP?
- ForexMachineGun Robot uses No Cheesy Indicators! | 4x Income
- Links with little comment (P != NP) « More than a Tweet
- “Million dollar maths puzzle sparks row” – Because it wouldn’t be interesting with a row? « Jack's Personal Blog
- Ya hay una wiki para el análisis de la demostración de P≠NP de Deolalikar « Francis (th)E mule Science's News
- Wine, Physics, and Song » Blog Archive » Claimed proof of P note equal to NP by Vinay Deolalikar is being taken seriously
- Open discussions on an open problem - Jimagine - Information and Society
- P != NP Proof by HP Researcher « Sohan Akolkar : Personal Blog
- Researcher claims solution to P vs NP math problem – Wikinews » August, Lipton, Turing, Richard, Clay, Deolalikar » casestudys.info
- Re: Raz w miesiacu | Nauka i Ochrona Środowiska
- More Short URLs for the Copy Short URL Add-on | fredericiana
- The quest for the lost shtukas » Deolalikar P vs NP paper
- La prueba de Deolalikar P != NP « Computación Cuántica
- P versus NP versus PR « Thore Husfeldt
- P נגד NP ומדליות פילד. שתי הערות לסדר היום | ניימן 3.0
- Summer « A kind of library
- island94.org » P, NP and Panlexicon
- p np | WebBuzz
- Proof that P is not Equal to NP? | Volkan Tunalı
- At last P != NP or not [closed] | Q&A System
- P vs. NP, A Primer (And a Proof Written in Racket) | Math ∩ Programming
- Thanks For Sharing « Gödel’s Lost Letter and P=NP
- será que P~=NP? | dia a dia, bit a bit
- At last P != NP or not [duplicate] | CL-UAT
- Proposed solution for Riemann hypothesis? — Uncage
- Proposed solution for Riemann hypothesis? – Panicking
- Proposed solution for Riemann hypothesis? – Drizzly
- Proposed solution for Riemann hypothesis? – Excitations
- será que P~=NP? | dia a dia, bit a bit | por Silvio Meira
- P ≠ NP? It’s bad news for the power of computing | News In The World


My expectation is that his technique will be found proving that a certain class of polynomial algorithms do not solve SAT. The question is whether this class is somewhat new or not. As someone put it before (I didn’t save the link), how does it prove that answers to SAT are not encoded starting from 10^10^10 digit of ?
?
This proof claim is a very interesting development. I’ve seen many proof claims for P != NP over the years, but none have generated this much excitement on the web.
If the standards for a proof of P != NP being acceptable are such that the proof must directly address why the answers to SAT are not encoded starting from 10^10^10 digit of pi, then I doubt this proof will fulfill these standards.
But are such standards fair? I mean, we all know that the answers to SAT are not encoded starting from 10^10^10 digit of pi, right?
> we all know that the answers to SAT are not encoded starting
> from 10^10^10 digit of pi, right?
Actually we don’t, and of course you can replace with
with  or any other irrational number of your choice :).
or any other irrational number of your choice :).
Seriously, such kind of questions is the way to pinpoint wrong assumptions about a (potentially existing) algorithm. For this particular paper, I already see that the author talks about “start with partial assignments to the set of variables in the formula…” There is no reason to believe that a polynomial algorithm for SAT must do any such thing. Moreover, it is possible that variable assignments are not needed at all and satisfiability can be inferred without constructing a satisfying assignment explicitly. I do not pretend to fully understand the paper but my impression is that the error is about too much assumptions about SAT algorithms again.
@Stas —
“Moreover, it is possible that variable assignments are not needed at all and satisfiability can be inferred without constructing a satisfying assignment explicitly.”
I do not think so. If you can decide SAT in poly time, you can also find a satisfying assignment. Let f(x1,x2,…) be a boolean formula.
Set variable x1=0. Decide whether reduced formula is satisfiable.
Set variable x1=1. Decide whether reduced formula is satisfiable.
If f is satisfiable, this tells you whether x1 needs to be 0 or 1 to satisfy it. Repeat for x2, x3, … until you have located the satisfying assignment.
I am pretty sure these steps are all poly-time.
In other words, if you solve the SAT decision problem, you are also (in effect) finding a satisfying assignment. So assuming that is what you are doing in the first place is not unreasonable.
Nemo,
> If you can decide SAT in poly time,
> you can also find a satisfying assignment.
Yep, that’s right. But it doesn’t imply that satisfiability can’t be decided without finding a satisfying assignment. If SAT answers are starting from digit of
digit of  , you first looks up the answer and then run the procedure you described to get the assignment.
, you first looks up the answer and then run the procedure you described to get the assignment.
First note that by the density of the reals there *certainly* is a real number that encodes the answers to SAT. (In fact for any countably infinite list of things there exists a real number that encodes it). This not a problem for the following reason:
If we have a proof that P≠NP, then we know that the n-th digit of the real number that encodes the answers to SAT cannnot be computed in polynomial time.
Just because the answers are encoded in an real number does not mean that the answers are any easier to retrieve. In other words, calculating the value of given digit of the real number that encodes the answers to SAT is no easier than calculating the answer to the corresponding SAT instance.
I don’t think that this is quite fair, either. We know, for example, that evaluating a position in generalized Go is EXPTIME-complete, so not in P by the time hierarchy theorem. But I don’t think any reasonable person would claim that the proof (of either the hierarchy theorem or the poly-time reductions to Go) really “explains” why the solutions aren’t encoded starting from the 10^10^10 bit of \pi. Certainly that’s a corollary, but it’s not one that has any real bearing on the structure of the proof.
I think Stas’ comment is most insightful, as it gets to the heart of why no one has convinced the CS community that P != NP (even though it is true). I will make a gentleman’s bet that the CS community will reject the Deolalikar paper or any other paper claiming to prove that P != NP for this reason.
How does one prove that the answers to SAT are not encoded starting from the 10^10^10th digit of pi? Common sense says that they are not, but still it could be true just by coincidence (true for no reason). This is a conclusion of Gregory Chaitin’s work on algorithmic information theory, that mathematics is full of facts that are true for no reason.
EXPTIME-complete problems like Go are proven to be in P just by showing that they are equivalent to a problem specially designed so that it runs in EXP-time. But with NP-complete problems, it’s not this simple, which is why I think no one will ever convince the CS community that P != NP unless the CS community lowers the bar and takes a leap of faith that you are not going to find the answers to SAT encoded starting from the 10^10^10th digit of pi.
Note that the n-th digit of Pi can be calculated in C*n^3*log(n)^3 time (http://lacim.uqam.ca/~plouffe/Simon/articlepi.html).
So a proof that P≠NP would directly imply that the solutions to SAT are not encoded in Pi, or any other real number who’s general n-th digit can caluated in polynomial time.
Interestingly, by the density of the Reals, there necessarily exists a real number, w, such that the digits of w encode the answers to SAT. But if we have a proof that P≠P then we know that the general n-th digit of w cannot be computed in polynomial time.
🙂
oops. That last paragraph should have read:
“But if we have a proof that P≠NP then we know that the general n-th digit of w cannot be computed in polynomial time.”
I take back my comment that I made above on August 10, 2010 9:35 am.
Does the paper seem to imply anything stronger – like NP \neq co-NP or P \neq NP \cap co-NP?
Sid,
Great question. It could, but first we need to understand it.
Thanks.
Having seen this only since 5:30 this (Sunday) afternoon, here’s my attempt at a somewhat more fleshed-out description of the proof strategy, still at a very high (and vague) level: Deolalikar has constructed a vocabulary V such that:
1. Satisfiability of a k-CNF formula can be expressed by NP-queries over V—in particular, by an NP-query Q over V that ties in to algorithmic properties.
2. All P-queries over V can be expressed by FO+LFP formulas over V.
3. NP = P implies Q is expressible by an LFP+FO formula over V.
4. If Q is expressible by an LFP formula over V, then by the algorithmic tie-in, we get a certain kind of polynomial-time LFP-based algorithm.
5. Such an algorithm, however, contradicts known statistical properties of randomized k-SAT when k >= 9.
If there is a conceptual weakness, it might be in step 3. This step may seem obvious given step 2., and maybe the paper has been set up so that it does follow immediately. However, it does need comment, because general statements of the P–LFP characterization are careful to say that every polynomial-time decidable query over a vocabulary V can be encoded and represented by an LFP+FO formula over Strings.
Let me give a crude analogy where a statement analogous to 3. fails, trotting out our old friends Alice and Bob.
—–
Suppose Bob doesn’t see Alice’s input x, but is allowed to interact with x only by querying Alice through a limited vocabulary. In particular, Bob’s vocabulary has only a predicate EQ: Bob may write down a string y and ask, is EQ(x,y)? For any resource bounds on Bob that define a complexity class C, write C(EQ) to denote the class of languages Bob can recognize given the resources and this limited mode of interacting with Alice. Note that C(EQ) is always contained in C, since the latter is the case where Alice just reveals x.
1. Then NP(EQ) still equals NP, because a non-deterministic polynomial-time Bob can guess x, and then guess whatever else is needed…
2. But P(EQ) is properly contained in P—in fact, it has only sparse or co-sparse languages in it. (I think I proved it equal to the class of P-printable languages and their complements.)
The punchline is that NP = P does not necessarily imply NP(EQ) = P(EQ) when limited to this vocabulary. Thus the analogous statement 3. fails—consider any language Q in NP that is not P-printable. Mind you, this has two major differences from the logic steup: EQ is not a first-order formula, and the logic setting is closer to “white-box” than my use of Alice and Bob.
——
I don’t know whether this is really relevant to the paper once one gets beyond the first level of detail, but maybe it’s a useful first focal point of the conversation about it.
One other note: if you look up the paper’s frequent term Ansatz on Wikipedia, Wikipedia says “educated guess”, but the paper’s use of the term is better translated as, “heuristic approximation scheme whose statistical properties we can prove”—thus I don’t think this a case of resting on an unproved physics conjecture.
Can you explain the connection between model theory and the structure of random SAT? This to me would be the most surprising thing. It seems to me that there can be polynomial-time algorithms even in the clustered phase of random SAT problems.
Cris, so far I think that details of finite model theory are used only in section 4.3, to refine the hypothetical algorithm adduced from the P = NP assumption into a particular simple LFP form. Otherwise, as Dick wrote, “the final proof does not directly use the machinery of finite model theory”.
Regarding your last sentence, vis-a-vis my comment above, we may be saying the same thing—it’s not (yet) clear to any of us why NP = P implies there is a polynomial-time algorithm of that particular form over those structures.
Back in the quantum post, I put in a followup query on the last exchange between Geordie and John Sidles.
Meant to add, an older example relating finite model to random structures is the topic of zero-one laws. That term is not mentioned in Deolalikar’s paper, but is covered in some of its sources, which are turned up by Google zero-one law finite model theory.
“If it is correct, the Clay list will drop down to five. I assume he would take the prize.”
And will you keep posting to this blog?! 🙂
Anonymous,
Perhaps I will continue. As you know I talk on many other topics too. Factor could still be easy and so on. But have thought about name….hmmmmmmmmm
What do you think?
What adds to my confusion is that the latest ideas from physics suggest that random k-SAT and similar CSPs don’t become hard at the clustering transition, but rather at the condensation transition where a subexponential number of clusters dominate the space of solutions. For instance, calculations by Lenka Zdeborova suggest that the clustering transition takes place at c=4 for random graph 3-coloring (in G(n,p=c/n)), but Achlioptas and I proved that a simple algorithm succeeds up to 4.03. This suggests that the d1RSB phase (to use the terminology in the paper) is not necessarily hard. In general, clustering, condensation, and the appearance of frozen variables all seem to be different phenomena, which take place at different densities.
In addition, random k-XORSAT also has a clustering transition, frozen variables, etc., but is of course in P. Deolalikar has a comment explaining why this isn’t a counterexample, but I don’t understand his comment yet…
Of course, all this is with next to no comprehension of the paper, so I may be totally missing the point. But if the claim is that clustering -> hardness, I disagree. And if the proof works, I will celebrate along with everyone else 🙂
Deolalikar claims the condensation phenomenon hasn’t been rigorously proved to his knowledge, as per this paragraph near the bottom of page 54 in the 12pt version of his proof.
“Using statistical physics methods, [KMRT+07] obtained another phase that
lies between d1RSB and unSAT. In this phase, known as 1RSB (one step replica
symmetry breaking), there is a “condensation” of the solution space into a subexponential
number of clusters, and the sizes of these clusters go to zero as the
transition occurs, after which there are no more solutions. This phase has not
been proven rigorously thus far to our knowledge and we will not revisit it in
this work.”
That is correct. My point is that there is some evidence that the “hard” phase doesn’t start at the clustering transition, but at a higher (yet-to-be-proved) density.
Note, however, that for k-SAT for large k, these transitions asymptotically coincide.
I though the same, but looks like the logical argument he is using is that if k-SAT(x) were in P, where x is a partial assignment to be extended to a total assignment if possible, then random k-sat wouldn’t have a clustering phase.
So, he does not prove that random k-sat is hard at the clustering phase, but that the existence of the clustering phase contradicts the fact that k-SAT(x) is in P.
I am also clueless on how he get it…
I agree to the XOR-SAT objection, but couldn’t the proof be adapted as follows: 1) syntactically restrict from NP to MMSNP, which is equivalent to CSP and argue to proof a separation of P vs. CSP first, 2.) note, that for CSP Schaefer’s Dichotomy theorem applies 3.) deal with Schaefer’s tractable CSPs as special cases that can be recognized in a given instance and decided in P, 4.) cover the remaining NP-hard instances with Deolalikar’s argument (assuming the other objections can be closed), 5.) conclude P \neq CSP \subseteq NP, thus P \neq NP.
I am very happy because the problem is most probably solved.
(I am a bit unhappy because I wanted to do it myself.)
Cheers!! 🙂
From the reactions at both Stack Overflow and Math Overflow it looks like the “establishment” doesn’t quite grok the Internet yet (despite using it themselves) 😀
Judging from the discussions on both sites, they grok the Internet just fine — both the upsides and the downsides. But maybe I’m missing your point here? How would you use the Internet in this case?
He mentions the Razborov-Rudich, but the word “natural proofs” is mentioned only once (in the introduction). I would be really surprised if the proof uses uniformity in an essential way and this in itself would be interesting. It would better if he explained why his proof is not “naturalizable”.
I am reading。
很震惊
Not sure what this has to do with social media…
nice post… ty for info
There is one thing which really surprise me:
Page 44 (so 47 of the pdf
http://www.win.tue.nl/~gwoegi/P-versus-NP/Deolalikar.pdf) he gives a “succ” relations, but he stated before that he does not want any order. And he certainly can obtain an order with the succ relation and the least fixed point.
And it is well known that you can compose LFP to obtain only one LFP, hence if it’s proof works, it should also works over structures with an order !
I do not state that it means that the proof is false, but if this works, it also implyes what look like to be a really strange corollary into finite model theory, because it would use a kind of locality which does not take care about the orders relation.
(At least that is what I understand of it… but it may also be because this small part is really close to what was my current research)
I think you mean Page 44 of an earlier 63-page version of the paper (with more condensed lines), which corresponds to page 67, not 47, of the present 102-page version. This is the first page that mentions “successor”.
Indeed, that is the juncture all of us are fingering—I just now see David Mix Barrington’s below. To expand a little on the angle in my first comment above, clearly Deolalikar is here trying to accomplish the implication in what I called “step 3.” above. On p66, point 2., “We need a relation in order to make FO(LFP) capture polynomial time queries on the class of k-SAT structures. We will not introduce a linear ordering…rather we will include a relation [R_E] such that FO(LFP) can capture all…” The supplied relation R_E, however, merely represents one circular chain on the positive literals, plus another on the negated literals. I don’t see how this can be used to do the requisite encoding of Strings—with the BIT predicate, as Dave MB points out below. Thus I don’t see why the LFP-based algorithm has to come out the way he posits.
This may even be besides the issue of ordering. As noted in this blog’s April 5, 2010 post (search “Grohe” in this blog), if P does not have an unordered characterization, then P != NP, since NP has one. Thus in a P != NP proof it seems cricket to assume that P does have one. However, the unordered characterization may not have the particular form that one desires.
It is possible to check the key reference to the Ebbinghaus-Flum online at Amazon.com and Google Books—the latter gave me the pages of the referenced Chapter 11 that the former skipped, when I searched on “LFP” and “IFP” at both places. I don’t yet see a single clear referenced result in section 11.2. A little nitpick, everything in that section is stated for “IFP” not “LFP” as he says—it’s equivalent in general, but again there’s the issue of what exactly does your for-contradiction-resulting-formula actually say?
Another side note: presumably one can crank out a claimed proof of NP != NL by substituting transitive closure (TC) for LFP, or NP != L by limiting TC to graphs of outdegree <= 1 (DTC), both likewise monumental. Does this weakening of the hypothetical help with any of the queried issues? If not, then the “not‘” aspect is a place to focus on for a possible flaw.
Yeah, Immerman-Vardi is still true if “FO” is redefined to have just successor, and neither order nor BIT, because you can use LFP to build order and BIT from successor. (Your point about simplifying his proof to get NP != NL is a good one. We can get order from successor in TC, but I don’t think we can get BIT from order — there are lower bounds on what you can do with just order and addition even if you have the power of LOGCFL.)
It looks like his Gaifman graph in Chapter 7 has just successor, which would meet my earlier objections a priori, but you may be right that what he uses isn’t enough to get order and BIT on strings…
@Barrington,
In fact you can define BIT using only a deterministic transitive closure.
I do not have exact references for this fact, but when I wrote the article about First Order in complexity in wikipedia I wrote a quick proof with the exact formula.
http://en.wikipedia.org/w/index.php?title=FO_(complexity)#Using_successor_to_define_bit
I presume in the main proof (and elsewhere), Deolalikar means instead of $O(n)$.
instead of $O(n)$.
A quick initial read of the paper leaves me unconvinced. At the bottom of page 70, “we will start with partial assignments to the set of variables in the formula, and ask the question of whether such a partial assignment can be extended to a satisfying assignment. Since the answer to such a question can be verified in polynomial time”. The problem with this is that P=NP doesn’t imply that there is a uniform polynomial bound on the verification, so the LFP formulas do not have a uniform polynomial bound.
k-consistency, which is what this appears to be talking about, is in (the lower bound seems to be widely believed, but is not proved). So this route doesn’t seem to help.
(the lower bound seems to be widely believed, but is not proved). So this route doesn’t seem to help.
The Kleene-Rosser paradox is a counter-example to the Immermann-Vardi theorem. It is in P and not in FOL+LFP.
This is sufficient.
What does that even mean? How do you turn the KRP into a boolean question, let alone show it’s in P but not FOL+IFP? The Immermann-Vardi theorem is well enough established that you can’t falsify it in a comment without sounding like a crank.
Assume a Turing machine that recognizes paradoxes, i.e. accepts input iff the input is a paradox. This turns it to a Boolean question.
Here is a proof that KRP is a ounter-example to Cook’s theorem, i.e. SAT is not NP-complete not just Immermann-Vardi’s theorem.
http://arxiv.org/PS_cache/arxiv/pdf/0806/0806.2947v8.pdf
The same result is establshed by diagonalization in an another paper, if you need it just give me your email.
I don’t see how the Kleene-Rosser Paradox provides a counterexample to the Immerman-Vardi theorem?
András
I am confused too. I am not expert on Immerman-Vardi so I could have stated it incorrectly. But that is another issue.
If you assume a Paradox Recognizer Turing machine, it will easily recognize the paradox in polynomial time. So, KRP in P.
Now, how can you express KRP in FOL+LFP. It’s impossible. KRP is self-referential self-negating sentence inexpressible in FOL.
The same argument works for Fagin’s theorem.
A different argument establishes that KRP is irreducible to SAT, then SAT is not NP-complete. Check the ArXiv paper above.
I wouldn’t take him seriously:
http://www.informatik.uni-trier.de/~ley/db/indices/a-tree/k/Kamouna:Rafee_Ebrahim.html
I believe that “P is not equal to NP”.
Maybe I have proved it in 1993~1995.
This proves:
P=NP iff P!=NP.
Dear Anon,
It is not important to take me seriously or not. What is important is to (sxientifically) falsify my argument.
Prove that a Paradox is reducible to SAT.
It is rude/impolite of Anon to say that Rafee should not be taken seriously. Please keep personal attacks and name-calling out of this blog, thank you.
And yes, I too doubt the correctness of the Immerman-Vardi theorem.
I read Immerman’s proof, and it looks like there is a mistake at the end of his proof. (a) He converts the “first” output of his Turing machine (which is equivalent to an optimal solution as above) to LFP form, and (b) then he converts the TM output to a Boolean-query output using some constant $c_0$, however he fails to convert this last TM step to a logic expression using LFP.
And how to syntactically express a decision query based on optimization problems, those with a bound on the objective function value? Problems such as
(1) Given a (possibly weighted) graph $G$ and a constant $K$, does it have a matching with a value of at least $K$?
(2) Given a minimization instance of a Linear Programming (LP) problem and a constant $K$, does it have a feasible solution whose objective function value is at most $K$?
These are not at all clear from his proof.
Sameer, you might have noticed that many CS bloggers remove each and any comment by Rafee as soon as they see it. Why do you think they do this? Could there be a history here, perhaps?
A potential problem that Lance pointed out to me: In Chapter 3 Deolalikar correctly quotes the Immerman-Vardi theorem as referring to finite ordered structures. But in Chapter 4 he quotes the Hanf and Gaifman theorems, which are true but much less interesting over ordered structures. Has Deolalikar just forgotten that his FO(LFP), because it includes FO, has the order and BIT predicates on elements of the universe? In that case every element is related by a tuple to every other element, and the “local neighborhoods” of those two theorems include every element in the structure.
There have been other purported proofs of P != NP that have made this very mistake…
Disclaimer: I certainly haven’t understood how he uses these locality properties later, so I don’t know that he uses them incorrectly, but the disappearance of the ordered/unordered distinction in Chapter 4 is at least troubling.
For information, and as stated higher in this page by Professor Barrington, in section 7.2.1. he introduce a successor relation, which is enough with LFP to obtains both bits and order. So this remark is not really important.
But at least, chapter 4 would be more clear if he did not wait to speak of this order.
How does one represent strings and BIT, unless there is something that can be absent in the structure to represent a ‘0’, or an extra unary predicate on the thus-ordered elements of the structure? It seems to me his “R_E” relation is not flexible or rich enough, in how it represents the two n-cycles.
In descriptive complexity, you can consider your element to be the n firsts naturals number. Then “bit(x,y)” is true when the yth bit of x is true. You can define bit thanks to LFP and succ. Let me give you the proof. The meaning of “if then else” in the formula is
straightforward.
bit(a,b)=(LFP_{P,x,y,b}\phi)(a,b,0)
\phi=(x=0/\y=0/\b=0)\/
(if P(x-1,0,1) then
((y=0/\b=1) \/
if (\forall y'<y P(x-1,y',0))
then \neg P(x-1,y,0)
else P(x-1,y,0)))
Let me explain this formula, we want to state that the least fixed
point is the bit relation when the third bit is 0. We we inductively
computer what bit y validates bit(x,y), this information will be in
bit(x,y,0), and bit(x,0,1) will state that this was computer. When the
bits of x are known we can computer the bit of x+1.
This is really easy: the yth bit of x+1 is 1 iff the bits of x are
such that either: all bit before y are 1 and the bit y is 0, or there
is a bit before y which is 0 and the bit y was one.
This solve the "bit" problem for the computation, I certainly do not
state that it let us encode strings as input. I do not know how he encodes its inputs or how you would encode a string as an input, but I hope my answer is correct for at least half of your question.
Thanks! I take it we’re agreed, however, that the query about Strings in my original comment up at the top is still unresolved.
David,
Thanks for your comment.
We know that random k-SAT isn’t hard, and hard instances of k-SAT are asymptotically 0% of all k-SAT with increasing problem size.
How then could one resolve NP vs P with an argument involving the statistical properties of random k-SAT, when the hard instances have vanishingly small impact on the statistics.
I’ve only skimmed the paper, but that’s the big stumbling block for me.
The proof assumes that P algorithm for NP can be used to get the set of all solutions. For that, you need to be able to solve instances of k-SAT with partial assignment of variables. So, even if only a small fraction of these cannot be solved, this can obscure the solution set structure for almost all k-SAT entries.
But that already sounds wrong. Being able to get the set of all solutions is #P, not NP. #P is outside the entirety of PH and therefore probably much harder than NP.
Excitemetn excitement .. 🙂
“My expectation is that his technique will be found proving that a certain class of polynomial algorithms do not solve SAT”
I agree, that could be a problem. At a very higher level only a proposition of the kind
“if it exist a polynomial time algorithm (not referring to any particular class of algorithms) for this class of problems then a contradiction will arise”,
that is only an existential modus tollens-like argument which abstracts on the concept of algorithm would convince me for a P-NP separation. That´s the kind of proof i expect.
On the other hand I would rule out them automatically proofs of the kind: “i define a class of algorithms and i prove a lower bound for algorithms in such a class or i derive a contradiction based on such a class of algorithms”.
I´ve read so superficially, and only the introduction, the paper that until now i can not see to which of the two kinds of propositions his proof belongs. By now so many experts must be reading it that i would rather wait their opinions.
In any case congratulations to the author. Right or wrong at least he has got a great achievement: that the community pays attention to an attempt of a P-NP separation.
That´s not usual…
I don’t understand why it’s an achievement to get the community to pay attention to a claim. Lots of folks in the field (such as the proprietor of this blog) could get such attention easily by making a claim, but it would be unwanted attention unless the claim was correct. I think most people in the field if they came up with something like this would be to discuss it very discreetly with some colleagues before making any sort of announcement. Emailing it to a bunch of strangers is a red flag in its own right.
You seem to be missing that Deolalikar didn’t make any sort of announcement (unless you’re implying that he “leaked” the paper himself). Also, how do you know that he mailed it to a “bunch of strangers”.
This is much more than a simple claim. The author spent considerable amount of time and energy into something that is not part of his job. Even if the proof turns to be bad, hopefully it will shed some light into the P =? NP problem. That in itself is an achievement
Deolalikar did make an announcement. It was in a public mail to a bunch of prominent complexity theorists, where he also explained how he worked on it for two years or so. This counts as a public statement.
None, i refer to the well known long list of attemps: http://www.win.tue.nl/~gwoegi/P-versus-NP.htm.
I´m not complaining about this situation, that´s just an objective observation. I just wonder why this time there so much buzz. I perfectly understand people which follows sociological red flags as those you point to, and i eventually follow them myself (time economy i supose), althought i think it would be better that the community rely just in content.
By the way, speaking of sociological green flags, how must we interpret the fact that in this linked list the author deserves an special status ? Is this a signal ? Maybe off-topic question…
Conan, what do you base your “public mail” statement on? Greg Baker’s original post (which did not include the paper) quotes Deolalikar as asking for “comments and suggestions for improvements to the paper”, and his home page states that “[t]he preliminary version made it to the web without my knowledge”. People are already ranting on Twitter about how he’s a jackass who don’t understand the scientific process, and here you are putting fuel on the same fire. Why?
I’m basing it on the fact that I got the mail myself, and the paper is attached. This IS a public announcement.
fwiw, Deolalikar just posted an updated version of the paper:
http://www.hpl.hp.com/personal/Vinay_Deolalikar/Papers/pnp_updated.pdf
Updated version of the draft, that is.
The pagination is identical on page 77. On page 78 top, he has deleted the sentence
“In the ENSP model, the covariates are recovered by restricting to the
first n vertices in the bottom row, but now we have a graphical model that can
represent the underlying computation done in order to get to that final state.”
Then after the main proof, on pp84-85, he had added one paragraph:
“It is also useful to consider how many different parametrizations a block of
size poly(log n) may have. Each variable may choose poly(log n) partners out of
O(n) to form a potential. It may choose O(log n) such potentials. Even coarsely,
this means blocks of variables of size poly(log n) only “see” the rest of the distribution
through equivalence classes that grow as O(npoly(log n))). This quantity
would have to grow exponentially with n in order to display the behavior of
the d1RSB phase. Once again we return to the same point — that the jointness
of the distribution that a purported LFP algorithm would generate would lie
at the poly(log n) levels of conditional independence, whereas the jointness in
the distribution of the d1RSB solution space is truly O(n). Namely, there are
irreducible interactions of size O(n) that cannot be expressed as interactions between
poly(log n) variates at a time, and chained together by conditional independencies
as would be done by a LFP. This is central to the separation of complexity
classes. Hard regimes of NP-complete problems allow O(n) variates to
irreducibly jointly vary, and accounting for such O(n) jointness that cannot be
factored any further is beyond the capability of polynomial time algorithms.”
This seems intended to address the actual deterministic lower bound on SAT that would be obtained. This might be obtainable by generalizing Immerman-Vardi to DTIME[t(n)] for some robust collection of time bounds t(n) > poly(n); in a comment above I meant to speculate that 2^{n^{o(1)}} would do. (I should point out that in the uniform setting unlike with circuits, lower-bounding against that does not imply a lower bound of “2^{n^\epsilon} for some epsilon > 0”, though the proof still could establish this stronger bound.)
I’d be interested to know if there is any other difference between the drafts.
Dang—I forgot to eliminate jaggies from a PDF cut-and-paste.
I made a diff of the two drafts, apart from those changes, and of course it’s new introduction, the only difference is:
“it can only display a limited behavior.”
became “it can only display a limited joint behavior.”
(the diff has other changes in it, but as far as I can tell it is only because some page number changed, and a few pagination changes.
I made a diff of the two drafts, apart from those changes, and of course it’s new introduction, the only difference is:
“it can only display a limited behavior.”
became “it can only display a limited joint behavior.”
(the diff has other changes in it, but as far as I can tell it is only because some page number changed, and a few pagination changes.
Here is my rendering of the paper:
1. First claim, based on statistical physics analogies, is that for SAT_k when there are enough relations compared to number of variables, in almost all cases solutions are represented as exponential number of small clusters, that have Hamming distance (number of flips required to jump from one to another) bounded from below by q*n
This interesting result is quoted, and it seems rather plausible.
2. Secondly, it is claimed that P=NP is impossible, since algorithms in P supposedly give structure of solutions where we can jump between clusters in at most O(poly(log(n))) steps, or a statistical statement in that sense.
This is proved, using well known finite model second order logic characterization of class P, by constructing a certain directed graph model of computation (depending on algorithm in P), and then studying the probability distributions. Certain notions of distribution independence/clustering are used.
Part (2) seems to be the key part of this argument, and I need to study the text more to understand it.
However, certain questions arise.
It is well known that CSP (constraint satisfaction problem) is solvable in P if we restrict our relations to some more restricted set. The famous dichotomy conjecture says that under such restriction, we either have solvability in P, or NP completeness.
Now, it appears that the general structure of the proof would pass even when the CSP problem is P reducible. For the part (1) I am not sure, but since the relations are used independently, we can form similar random ensamble only restricted to this fixed subset of 2^k disjunctions. Then presumably there will also be similar phase transition (this is just what seems plausible to me).
For the part (2) however, clearly P algorithm exists.
So, to understand the proof and check for possible problems, maybe this wider restricted CSP framework is useful.
When CSP has a solution (for the restricted set of relations), then there is an algebra describing the set of solutions (this is known in CSP theory). In some cases, solutions can be generated from small subset of solutions by these algebra operations.
What a fascinating turn of events, and thank you for the analysis. I may have to dust off my complex proof hat and wade in to see it for myself.
His proof is wrong, because P = NP.
The space for comments here is too small for a complete proof of this claim.
Even if the correct answer is P=NP, still you can have a correct proof of P!=NP.
🙁
Oh my god it’s you again.
I agree completely. I know for sure they are equal, and nobody can disprove it!
I don’t like the end of the introduction:
“Our work shows that every polynomial time algorithm must fail to produce solutions to large enough problem instances of k-SAT in the d1RSB phase. This shows that polynomial time algorithms are not capable of solving NP-complete problems in their hard phases, and demonstrates the separation of P from NP”
So if the whole proof was correct (not sure of that), this seems only to prove that no polynomial algorithm exists just before the treshold of the kSAT problem… And so? I really believe that this is not generally enough to prove anything stronger than that.
Not knowing much about the details of the proof but with some knowledge of the clustering phase, condensation phase, etc., in random CSPs, the quotation by Laurent above also worries me a little: “Our work shows that every polynomial time algorithm must fail to produce solutions to large enough problem instances of k-SAT in the d1RSB phase.”
I wonder how this reconciles with Chris Moore’s post above, where he points out that for the analogous problem of graph 3-coloring, the 1RSB clustering phase starts at graph density 4.0 but a simple algorithm by Achlioptas and Moore succeeds almost surely till density 4.03. This suggests to me that even for k-SAT, it is quite likely that there might at least be easier *parts* of the 1RSB phase that can be solved by polytime algorithms (although a catch could be that such polytime algorithms must be randomized in nature?).
It is 6am in an airport on a phone keyboard but I believe I can explain why this is not an issue and merely a poor use of nomenclature. Will do so after landing 🙂
For experts: the emergence of frozen variables is where it’s at and this happens very shortly after d1RSB occurs (and much before condensation occurs).
Indeed, after a more careful look, my observation is the same as what Dimitris noted. What Vinay needs for his proof is not just the existence of exponentially many clusters (which could actually be much more problematic than the 4.0 vs. 4.03 example for 3-coloring mentioned above; more on this later) but the existence of clusters with a constant fraction of frozen variables and \Theta(N) inter-cluster distance. As Lenka notes in a follow up post below, this typically happens much later. E.g., for 3-coloring, the (conjectured?) graph density where “freezing” or “rigidity” occurs in almost all clusters is around 4.66, well beyond the 4.03 density till which the Achlioptas-Moore algorithm works.
This seems to resolve the issue Cris and I raised. In other words, Vinay’s claim is for a clustering regime that starts a bit beyond the true d1RSB transition.
OK, but random XORSAT has frozen variables too; the 2-core acts like a low-density parity check code, and since it is whp an expander there is a Hamming distance Theta(n) between codewords.
So Deolalikar’s argument can’t rely on purely statistical properties like clustering and frozen variables: he has to make rigorous his claim that while XORSAT clusters can be succinctly described, SAT clusters can’t.
what about the recent barrier that Wigderson and Aaronson proved, viz., Algebraization barrier ? – does this proof overcome that one?
There seems to be one crude error. I’ll explain.
But first, let me say that the paper does seem to prove a weaker statement. Chapters 1 and 2 (introduction and probability distributions that are used more as motivation), 3, 5 and 6 I’ve read/understood, and they seem to be fine. They also mostly quote known results, and are hence not much under question.
The key chapters are 4 and of course 7. I did not understand fully how the distribution is calculated, but the idea seems to be that since (by chapter 6) almost always the number of variables that “interact” with given variable are limited (by poly(log(n)) when k and \alpha are fixed but n goes to infinity, then this limited connectivity gives rise to reduction in numbers of parameters needed to specify the distribution. Here, computational model is used, where FO formulas in LFP model are viewed as iterations of the FO, which can give rise only to local “interactions” in a bit wider graph.
However, in FO(LFP) the relation R that is the fixed point is not a unary relation (giving values of the variables of SAT-k), but a relation that essentially encodes the whole computation. I do not see this discussed anywhere. The model that he build is not using full power of FO(LFP), though for it he may have well proved his claim. This is what it seems to me, please correct me if I am wrong.
As I understand FO(LFP), we are allowed to use a defined least order fixed point (given by a first order formula), R=f(R,P,x) where P are input relations, and then use a FO(R,P) as our result. It seems to me that in the paper R is restricted to be unary operation, and first order formula he assumes is just conjuction of R(i)=x_i and our SAT_k formula (this implicit in the paper). However, FO(LFP) is much more powerful.
Also, as I said earlier, there are cases of restricted CSP classes solvable in P, and that seems to be in contradiction to what he proved (his proof would work for these to, proving that clustering phase does not appear there, but it is very plausible that it does, since phase transitions described in chapter 5 are apparently general, though this is just my speculation)
The issue is actually discussed in the paper, page 49, section 4.3. So it is mentioned in the paper, but I am not convinced by the very short argument that supposedly reduces this to the case of “monadic” fixed point relation R.
Point marked by 3. seems suspicious in particular.
He also says there that alternatively, we can extend the universe to be consisting of k-tuples.
Now this is questionable on many levels. On a side note, this is not the same k as the one in SAT_k (one of the few minor errors, there are other inessential sloppy places like in the chapter 5 where he puts the wrong formula sum C_i S_i -k >0 to go to spin glasses – shouldnt it be k-sum C_i S_i>0). But more importantly, this constant (denote it by K(k), typically will be greater that k, but for fixed k still a constant, arity of R, since algorithm depends on k alone if P=NP), when taking tuples of size k as inputs, is going to affect statistics.
In any case, this point needs more clarification. He assumes that R is monadic, and in fact admits this clearly in 4.3, and 7 also works under this assumption. But it seems to me that reduction is not properly explained, if not plain wrong.
Since you said:”Correct me if I am wrong”, I would tell you that the Kleene-Rosser paradox represents an obvious counter-example to the Immermann-Vardi theorem:
P = FOL+LFP
KRP in L.H.S. and can never belong to the R.H.S.
Rafee, you rock!
(P != FOL + LFP) == ROTFL!
— AC
I can’t say I understand sections 2-4. But I am one of the folks that is working on the stuff from section 5, the one on 1RSB ansatz of statistical physics.
My thesis (http://arxiv.org/abs/0806.4112) is a good review for that.
But I must say that the d1RSB (clustered) phase in random K-SAT in statistical physics is something different than what Vinay uses. What he uses – all solutions having a nontrivial core (page 56) – is what I called freezing in my thesis. I was the one who actually conjectured (and supported by quite some numerical and heuristic evidence) that it is this freezing of solutions (rather than the clustering of solutions) that is responsible for the onset of algorithmic hardness
For instance: It is very easy to check numerically if a solution an algorithm found has a non-trivial core. And several heuristic works in physics, including a couple mine, show that solutions that are easy to find with known algorithms never have non-trivial cores. On top of that there is this related 2^k/k versus 2^k ln 2 paradox when k is large that he discussed on page 58.
But what is really puzzling for me when trying to understand the proof is the following: How does the fact that XOR-SAT is linear and hence polynomial come out in the proof? Or in other words, how does the proof exclude that there is no “hidden” unknown symmetry in K-SAT that makes the independent parameter space small. In any case, all the statistical physics and probabilistic results I know of do not see any distinction between random K-SAT and random XOR-SAT that would not be smeared away in some other NP-complete constraint satisfaction problem (in particular the so called “locked” CSP are really similar to XOR-SAT in all the solution space properties). For me understanding this is the key point! Any help?
I agree with Lenka that the possibility exists (and is a germane issue) for there to be a “hidden symmetry” in random CSPs which causes the “complexity of describing” the exponentially many solution clusters to collapse (as linearity does for XOR-SAT).
That said, in my opinion, it’d be fantastic if it turns out that everything else works, modulo establishing this lack of a hidden symmetry.
It would mean that a polynomial-size object, the formula, is describing an exponentially large set (the cores of the different clusters) which is “incompressible”.
Is this discussion the likely future of peer review, a sort of rugby scrum from which the ball of proof/nonproof will emerge rolling toward the goal or foul? There are obvious advantages: near realtime, heterodoxy, Mao’s 1,000 schools contending. What’s missing unless someone takes it upon herself, is a coherent critique. How, if the ball does not carry a fatal flaw, is a poor author to react? Is crowdsourcing the right model?
The crowd’s “coherent critique” can be found in the related wiki.
I repent in dust and ashes for not underestimating the self-organizationing properties of the web. I’ll follow the wiki with interest (if only dim comprehension). Thanks.
There is another issue with locality in Claim 3 of Section 4.3: moving from unary relations to k-ary relations for k>1 has a great impact on locality. This is because the distance of tuples is determined on the basis of their constituting elements. E.g., two tuples that have an element in common have distance one. Their counterparts in a unary relation could be far apart.
I must admit that I could not yet read the rest of the paper, therefore I cannot be sure that this lets the proof fail, but that is at least what I suspect.
I agree with your idea…
I have worked in finite model theory for quite some time, including some recent related work on monadic fixed points. My comments refer to the August 06, 2010 version (98 numbered pages). The paper is very well written and interesting to read, and I have spent many hours poring over it. It is of particular interest to me because it uses techniques from finite model theory that are similar to my unpublished manuscript [Lin05]. According to what I’ve seen, including the local and global types being kept track of in the ENSP model, ‘factoring through’ a monadic fixed-point is being done correctly.
The concern I have is with the author’s claim that this analysis can be extended to k-ary inductions. Specifically, in the introduction at the bottom of page 8 “Finally, we either do the extra bookkeeping to work with relations of higher arity, or work in a larger structure where the relation of higher arity is monadic…” as well as section 4.3 at the top of page 49 “but the argument we provided was for simple fixed points having one free variable…” amplified upon in point 3 on that same page. A key point in the proof is on page 70 remark 7.4: “The relation being constructed is monadic, and so it does not introduce new edges into the Gaifman graph at each stage of the LFP computation.” However, the rest of that paragraph goes on to explain that “…we can encode it into a monadic LFP over a polynomially larger product space…”
This construction appears in a recent paper of mine [“A normal form for first-order logic over doubly-linked data structures” IJFCS Vol. 19 No. 1 (Feb. 2008) pp. 205-217] and I think it is useful to refer to the details there in order to understand my specific objections (available on my website). In particular, Definition 3 there explains how to map any k-ary structure into what I called a singulary structure (never mind the terminology, it is just unary predicates and functions). But clearly, when mapping k-tuples into single points, one must preserve the origin of their components by some means, such as the projection functions delineated there. The next section shows that the translation preserves the degree of each node within a polynomial, a fact which is also stated in the paper under consideration.
Even though the successor relation does not significantly change the degree of each node, incorporating it into an LFP in which “the output will be some section of a relation of higher arity…” (as stated on page 71) does. In Appendix A, transitive and simultaneous fixed points are dealt with in a mostly standard way, where each of the individual fixed points are computed in different columns of an induction of wider width. But here’s the problem. The induction relation itself must be monadically encoded, and it may not have bounded degree. In fact, because of successor, it could define an ordering in two of its columns, which would render the Gaifman graph useless. This can be seen most clearly in the aforementioned paper of mine, Figure 1. That diagram illustrates a subsequent sentence stating “But in general, there will be an unbounded number of elements that reference the ground elements, leading to unbounded-degree.”
In short, even though using successor avoids disturbing the diameter of the original structure, I don’t see how circumventing the ordering avoids the problem that a k-ary fixed point could have a diameter one Gaifman graph.
Nevertheless, there are many clever ideas in this purported proof and I would not yet dismiss all hope that it cannot be repaired by some clever means that exploits the specific nature of LFP(<) on SAT such as "… each stage of the LFP is order-invariant." on page 67 (even though this claim appears to hold only for a monadic fixed-point). However, it is my belief that such an analysis will require a new idea in finite model theory. Note that simultaneous inductions (A.2) are not the real problem since the proof can be adapted to deal with multiple monadic fixed points. It is rather the transitivity theorem (A.1). However, since the standard proof of the transitivity theorem uses simultaneous inductions, one would have to find a route which circumvents this, particularly in the case of order. One way to do this might be to re-compute the order every time it is required (similar to a transitive-closure computation) without storing the results. But since this is parameterized, I don’t see a way that it can be done in a purely unary fashion.
As one of the physicist who has been involved in this “1RSB” picture of random K-SAT I wish to add few words.
As pointed out by Lenka and Dimitris, a first source of confusion here is in the nomenclature of the phase transitions in random SAT: Condensation is not d1RSB, which is not freezing… another source of confusion is about the location of the “conjectured” hard sat phase according to this “physicist” picture. Despite initial conjectures, the d1RSB phase is NO MORE believed to be connected to hardness, nor is condensation. In fact, the rigorous work of Moore and Achlioptas in 3-COL (mentioned by Cris) is ruling out both these possibilities.
The conjecture that is the current “state of the art” was proposed by myself and Zdeborova in http://arxiv.org/abs/0704.1269 : the source of the problem for algorithms is the freezing phenomena, solutions associated with a non-trivial core are empirically impossible to find (from our abstract: “We argue that the onset of computational hardness is not associated with the clustering transition and we suggest instead that the freezing transition might be the relevant phenomenon.”). If all solutions are “frozen”, we thus believed that no algorithm whatsoever will solve K-SAT in polynomial time.
We even know now rigorously from the work of Achlioptas and Ricci-Tersenghi that there is a value alpha for random SAT where all solutions are “frozen”. This is the theorem used by Vinay. I would certainly be really pleased if our conjecture on the connection between frozen clusters and computational hardness turned out to be true, and proven!
Wow, this discussion is already Phase Transitions Central :), so let me give my two cents on this issue.
First, I am really happy that the existence of a connection between finite model theory and phase transitions is finally taken into account so seriously :).
Let me point out that a very weak form of such a connection exists: for a class of CSP the emergence of a large spine (freezing) is correlated with exponential resolution complexity (this is a paper of mine with Allon Percus and Stephan Boettcher). Then two results of Albert Atserias (the first one in JACM, the second one with Victor Dalmau in JCSS) essentially connect resolution complexity of 3-SAT with inexpressibility in a form of existential positive infinitary logic $\exists L_{\infty \omega}^{k}$ (see Albert’s paper for precise statement). This can be extended to other CSP.
All this is above the threshold but Dimitris, Paul Beame and Mike Molloy have shown how to prove resolution bounds below the threshold as well. So some result of the type “freezing is equivalent to inexpressibility in $\exists L_{\infty \omega}^{k}$” should probably be true below the threshold as well.
Now there is a loooong way from $\exists L_{\infty \omega}^{k}$ to FO(LFP) and I am skeptical it can be traveled that easily. You’ve heard the reasons (the reliance on locality properties, etc) from other people (Albert Atserias for instance), so I won’t repeat them.
On the other hand the result about $\exists L_{\infty \omega}^{k}$ can be extended slightly, and it would be natural to try to find a logic as strong as possible for which the connection does work (at least for CSP). Of course this logic won’t probably be able to express XOR-SAT, so no direct relevance to the issue of P vs. NP.
P NP is equivalent to a problem in finite model theory about how to tell apart two non-isomorphic models with an Ehrenfeucht-Fraisse game. If I recall, the solution is very easy in the case of just monadic relations in the models. Then the models are just a collection of ‘bags’ of different cardinalities, and a simple back-and-forth game solves if the models are isomorphic or not. It is the binary relations that introduce all the huge complexity in the finite models and have so far hindered efforts to solve P NP through this route.
I agree with an earlier poster that the use of statistical methods is suspicious. Hard instances of k-SAT are a vanishingly small portion of random k-SAT problems.
The proof of P NP is hard because we must be able to say something about ALL possible algorithms. How does the proof in the paper succeed in saying something important of EVERY algorithm, however complex and convoluted?
P != NP is clearly true except in the trivial case of N = 1 and N = 0.
In all other cases, P != (N) (P)
What are you guys talking about – where is the million dollars !!
Shark,
There are other proofs based on similar ideas.
Prof. Lipton, I really admire you that in the middle of so much you kindly replied to foolish comment of Shark.
I lije your humor. 🙂
This is wonderful. Finally. Wait a second. What?
I am a little worried.
Assume we have experts from N different fields and are trying to understand a proof that includes expertise in ALL the N fields (a story like the six blind (wo)men trying to understand an elephant by touching only one part of it). How would they come to a “sure” conclusion about the proof?
“sure” and positive conclusion (negative needs only one mistake in one area)
Hi kp,
Even though the paper, to be written, required the mastery of more than one area, a well written mathematical proof can be checked out step by step unambiguously. Sometimes, when you read a proof it might look like prose, but on request the author should be able to provide a detailed proof. This is a characteristic feature of mathematical proofs over any other kind of human discourse.
In other words, checking out a proof (convincing oneself of its validity) and understanding how the proof works can happen at different moments. When I was in my first year, I knew by heart few proofs that I truly understood only the following year…
Hello all. Mr Deolalikar’s proof is wrong. I won’t bore you all with the intricate details, but I assure you – it’s wrong. I’m a Goldman veteran of nearly a decade, so I know what I’m talking about. I’ve called it here and now — the proof is wrong.
Mike,
Might wish to post this to latest post so all will see.
Umh, please *do* bore us with all the details. That’s what most of us are here for.
What is a “Goldman veteran of nearly a decade”? You mean you’ve been working for the investment bank for 10 years? Why would you mention that?
The safe money is on the proof being wrong, so I’d tend to agree with Mike’s call.
Some worrying clues are the facts that (a) he does not couch the proof in the language that the proof is usually framed in; (b) he introduces a lot of private notation; (c) his text is littered with semi-philosophical asides. These signes usually do not bode well. Still, it might be capable of being turned into a proper proof, or there might be a nugget of a good idea in there.
I want to voice a couple objections to the proof.
1. My general concern is the use of Markov properties to prove some deterministic properties. It may be possible, but quite hard. In general, independence is a very strong property and it is hard to say anything about the lack of independence. Therefore, the reliance on the large size of connected variables isn’t sufficient.
2. Following (1), the following statement is plain wrong and easy to verify:
Chapter 2, pg 28. “When the size of the smallest irreducible interactions is O(n), then we need O(c^n) parameters where c > 1 .”
Before giving an example, I rephrase it completely:
When the size of the smallest irreducible interactions [in a markov network with N variables], is n, then we need O(c^n) parameters [to specify the distribution] where c > 1.
Here’s a counter example. Consider a markov network, of N binary variables. Each variable can be 0 or 1 with probability 1/2. All variables are independent so far. Now, add a constrain that all variables can not be 1 at the same time.
This simple constrain requires ALL variables to be connected, but the description is compact.
In this simple case, the apparent complexity is high, but the distribution is quite simple.
how is that a counterexample? what is the size of “interactions”? how many parameters you need to specify the distribution?
you say this distribution is simple, so it means it takes few parameters, a counterexample would require many parameters required, while having few interactions.
seems that you are wrong here.
In general, a very complicated markov network does not imply that the distribution is complicated. The correct statement is that if the markov network is simple, then the distribution is simple.
I gave an example of a simple distribution that looks like a very complex markov network and does not allow for any refactoring into a simpler distribution over these variables. However, it allows for extremely compact parametrization if we abandon the language of markov networks.
This distribution is specified in that post for arbitrary number of N variables. The number of parameters is constant (170 characters if you like). To represent this distribution in a form of Markov network, one has to link all the variables and get interaction (or clique) of size N.
This also contradicts statement on page 84 ,
“This explains why polynomial time algorithms fail when interactions between variable are O(n) at a time, without the possibility of factoring into smaller pieces through conditional independencies”
This particular distribution can not be factored, but we can easily work with it.
My point is that irreducible size-n interaction is not necessarily a hard thing to work with.
Unfortunately, the paper uses O(n) notation virtually everywhere, instead of Theta or Omega. This leaves room for interpretation.
It is not clear to me what he means by “parametrization”. A text description? Does he mean something more specific. What is the number of parameters for a given distribution (I assume one needs a family of distributions, but even this point is not clear in his paper)
Without having read the whole article (just his synopsis), I get the same impression about the basis of Vinay Deolalikar’s work. It’s as though he’s looking at a complex and apparently random series of numerical digits, and saying,
“We cannot find any correlation or pattern, so the digits must be random. If they’re random, then guessing the digits will require exhaustive search, which is exponential time.”
Not a very sensible conclusion if you are looking at (say) every 17th decimal digit of pi beyond the first few thousand. It’s the wrong approach to any mathematical problem, if you ask me… But then I wouldn’t call myself a real mathematician; so I’ll have to wait until the final expert opinion is out.
good blog really
Great article!
I just heard a very interesting lecture by Prof. N. S. Chaudhari on his polynomial time algorithm for 3SAT problem with intriguing constructive argument. Very exciting to see an O(N^13) algorithm. You can check out the recent papers and slides at http://dcis.uohyd.ernet.in/~wankarcs//index_files/seminar.htm
Hi,
The P=NP or not question is in binary logic P is not equal to NP
however in quantum logic it is. A quantum computer will give a P=NP
Answer and then we move to the next problem.
Regards Dr. Terence Hale
PLEASE RSVP ASAP!!! DID YOU GET ME LONG COMMENT ON MY P =/= NP GEOMETRY PROOF???
HAVING COMPUTER PROBLEMS, SO GAVE 3 E-MAIL ADDRESSES SEPARATED BY SEMICOLONS: FUZZYICS@COX.NET; FUZZYICS=CATEGORYICS@COX.NET AND FAIL-SAFE CHAVAH36@COX.NET
IF SO, PLEASE POST IT!!!
PLEASE RSVP ASAP!!!
BEST BY PHONE: (702) 722-2199 (EXCEPT TUESDAYS AND THURSDAYS NOR NIGHTS)
Всем Доброе утро! Заходите на Сайт который откороет вам мир ПК новости, обзоры,обзоры железа.
I am smarter than all of you, so your argument is invalid.
������������!
�������� ����� SEO ����� – http://www.seoage.ru/ /url>
�� ����� ������ ���������� �������������� � ����������.
��� �� ���� � ��� ���� ������� �� ������ ����������� �����, �����������.
�� ���� ������ ���! 🙂
A temporary solution to the problem would be to make an algorithm to display and input the possible answers into the computer and have it systematically run through all of them individually until it can find NP that way the computer can verify an answer it might just take a bit longer – Albert einstein’s riddle gave me this idea
kind of a backwards approach a computer can work with
Have you argue with him personally? What are his reaction?
Pls help with if p is a Natural number prove p-
Моршанск моршанск такси morshanskoe-taxi.ru.