Update on Deolalikar’s Proof that P≠NP
An update on the P not equal to NP proof

Timothy Gowers, Gil Kalai, Ken Regan, Terence Tao, and Suresh Venkatasubramanian are some of the top people who are trying to unravel what is up with the claimed proof that P 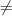
Today I will talk about the Group’s effort to help all of us understand the claimed proof of Vinay Deolalikar. Of course many others are working towards the same goal, but the Group is one that I have been interacting with the most.
This came about when some of the Group suggested that we start to be more organized and use wiki technology to handle the serious public discussion needed to understand the proof. I completely agree. One hold-up is we are currently unsure what Vinay wishes to happen. We are in direct communication with him, but he has not yet made it clear what he wishes.
The Group has decided for now to let things go along in the current ad hoc fashion. If and when Vinay wants help, we are prepared to help in any way that we can. For now we will follow Clint Eastwood who once said:
“Don’t just do something, stand there.”
Well it is hard to just stand there, since I cannot resist from making some suggestions that may help frame the discussion, and hopefully help us help Deolalikar. We must keep the tone constructive and supportive—the Group all agrees with this. I think that we need more people working on hard problems, and we should be as constructive as possible.
As I said, we have been communicating with Vinay, who is occupied with revisions to answer queries that have been made—and nothing should be inferred from periodic changes in links and drafts and wording on his HP sites.
Whatever happens I believe that the community should be excited and pleased that a serious effort has been made. I hesitate to make parallels, but recall that Andrew Wiles’ first proof fell apart. He needed the help of Richard Taylor and another year to get his final wonderful proof of Fermat’s Theorem.
Suggestion One
I have been trying to figure out what Vinay’s paper is doing. I wonder if the following analogy is helpful. Consider a much weaker notion of computation we’ll call uniform tree computations (UTC)–those familiar with complexity will recognize this as 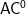
For those who are not complexity experts this is just the class of computations that can be computed by a special class of boolean formulas. A formula is easily represented as a tree. For example, the arithmetic formula 

The same happens with boolean formulas. Suppose the input to the formula is

where each 

Further, the tree is restricted in two ways. First, the size of the tree is a fixed polynomial in the number of input variables, 

The power of this class of computation comes from the ability of the operations to have many inputs from other nodes of the tree. The weakness of this class is due to the polynomial size restriction and the constant depth.
I claim that SAT cannot be computed by a UTC. This follows from known hardness theorems. What I am interested in is can Vinay use his technology to give a new proof of this theorem. If I am following his current write-up such a proof would have to go something like this. Suppose that a UTC could compute SAT. Pick two distributions 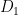
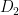
Then, Vinay’s technology should be able to show that UTC is too weak to tell these two distributions apart. If he could do that, then he would have a new proof that shows that SAT cannot be computed by this weak model of computation. This would give us some hope that he could solve the more complex problem he needs to prove his main theorem.
Suggestion Two
The next two suggestions are due to Ken Regan. Vinay can perhaps use his technology to prove a much weaker separation result, but one that is wide open. He could try to separate nondeterministic logspace (NL) from NP. The point is NL is defined by first order formulas and transitive closure. This is a much simpler notion than fixed points. Yet a proof that

would be a major breakthrough.
I suggest this to Vinay as a possible way to give us some insight into his ideas, and perhaps allow him to simplify some technical issues. If this is too much of a detour, I understand. But it could be a useful “warm-up” exercise. We see this type of idea all the time in new proofs. If you can show that a new proof can solve weaker questions, even questions that are known, that can be very confidence building.
Suggestion Three
This is to clarify how essential is the use of uniformity. This is used in the FO(LFP) characterization of P, but on current appearances, not as strongly as in proofs by diagonalization where one has a recursive-enumeration of polynomial-time machines. Various kinds of induction are involved, but maybe not an induction over (first-order “bodies” of) FO(LFP) formulas that would be tantamount to such an enumeration. The FO(LFP)formula seems to be treated as a single object, which opens a door for asking, what about it cannot be extended to talk about a nonuniform sequence of objects each with the same limitations on size and locality?
Several commenters have voiced expectation that non-uniform lower bounds should come out of the proof’s basic strategy. If so, then Vinay could try to state and prove a concrete circuit size lower bound. Here it takes even less than NL or L to be earth-shaking: a bound above 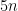
Let’s come at this point in a different way. Vinay’s use of conditional independence seems strikingly new. One of Ken’s colleagues even remarked in department email that you’d expect to see that in a statistical computer vision course, not in complexity proof. However, it seems to fit in well with concepts and results involving distributions that underly hardness-versus-randomness and other pivotal developments in complexity, including said barrier.
In particular, it seems that Deolalikar’s development can be used to create a new family of potential hardness predicates 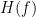
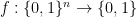
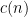
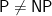
This may be getting ahead of the current discussion, so let’s come back to suggesting that the use of uniformity should be scrutinized and clarified. If it is not needed, then the issues about FO(LFP) could be dispensed with. Another win is this could help Vinay further develop the new ideas that come out right away in his chapters 1–2.
Open Problems
Do these ideas help Vinay? Do they help us understand him? I hope so.
P.S. I hope these discussions are helpful to the community at large.
[5.5n –> 5n for AND-OR(-NOT) circuit lower bound; the “5.5n” source was including the input gates]
Trackbacks
- Tweets that mention Update on Deolalikar’s Proof that P≠NP « Gödel’s Lost Letter and P=NP -- Topsy.com
- World Wide News Flash
- P != NP proof removed from Vinay’s site « Interesting items
- P = Non P o non più? » Ocasapiens - Blog - Repubblica.it
- daily snapshot | 11 August 2010 « randomwalks: stage #3
- 或许,P!=NP证明并未完成 | 丕子
- === popurls.com === popular today
- Echoes in the blogodome: P!=NP? | Generic Language
- La prova del sì e no « Oggi Scienza
- The $1,000,000 Question (of the week) « faunæ or automat?
- A Beautiful Sausage - Lee Gomes - Digital Tools - Forbes
- Tweets that mention Update on Deolalikar’s Proof that P≠NP « Gödel’s Lost Letter and P=NP -- Topsy.com
- P Vs Np Problem
- A Beautiful Sausage » Deolalikar, P=NP, This, Deolalikars, Richard, Wiles » casestudys.info
- A Beautiful Sausage | Muratayumi.com
- La opinión de Terence Tao sobre la demostración de P≠NP de Deolalikar « Francis (th)E mule Science's News
- The ethics of scientific betting – MIT Technology Review | Muratayumi.com
- Twilightish: 'Diaries' stars 'thankful for Twilight' | New Twilight
- Deolalikar’s manuscript « Constraints
- P=NP Update « OU Math Club
- P≠NP vrai ou faux? | Ze Rhubarbe Blog
- Sciencia-Geek » La opinión de Terence Tao sobre la demostración de P≠NP de Deolalikar
- Projections Can Be Tricky « Gödel’s Lost Letter and P=NP
- Summer « A kind of library
- P is not NP: a proof perhaps « Karela Fry
- tongue but no door (dot) net » Blog Archive » Deolalikar Slides
- P vs. NP,我们从过去的一周中学到了什么? « Tony's Blog
- P vs. NP,我们从过去的一周中学到了什么? 转自木遥 | 窦赞
- Culture ‘Travelling Salesman’ movie considers the repercussions if P equals NP | Azg Theory | Azg Theory


One clarification I’d like to see: As you say, Deolalikar claims to construct a “hardness predicate” which intuitively is a measure of the “complexity” of the solution space — it’s something to do with a factorization of a distribution into conditionally independent parts. Unfortunately I can’t figure out where in the paper he explicitly defines this parameter, so I’m not sure exactly what it is. Can anyone clear this up?
FWIW, my gut feeling about what this measure should do to prove P != NP (which aren’t backed up by the years of experience of many other commenters, of course, but still might be worth putting out there) is that it should act like a second cousin of Kolmogorov complexity. For instance, an efficiently decodable linear code of length n might have similar statistical properties to random k-SAT, but in a certain sense the uniform distribution on it is an “efficient transformation” of the uniform distribution on {0, 1}^m for some m < n. Since {0,1}^m is easy to describe, the linear code should have fairly low "hardness."
Forgive me if the above doesn't make sense. Thinking about this paper may have slightly melted my brain.
Actually no—Deolalikar doesn’t claim that; I was suggesting it might be inferred from his work. You’re basically right to query about explicitness—it comes down in Section 7 to a comparison of Theta(n) with O(polylog n). We cut out a suggestion that he make the lower bound more explicit about time.
We wrote suggestions (1) and (3) independently, but you can marry them to say: (1) First try AC^0, where we already know one can get the answer even without caring about uniformity. If your proof mechanism is fine there without it, then try (3). If uniformity is needed, then try (2).
I like the idea of testing this out on “simpler” cases to build confidence. I also think that after the euphoria of the last few days passes, maybe the serious slog to understand this can continue without the heightened nervousness and excitement that causes people to overreact to silences or changes of drafts on a page.
These posts are proving to be immensely useful to structure the various threads. Inspecting the wiki and the comments on the previous post though, I’m not getting a sense that either the LFP ordering objections, the LFP bounded vs unbounded universe issue, or even the random k-SAT phase transition issue is moving in any particular direction. Maybe the relevant participants are waiting for feedback from Vinay ?
I agree with the spirit of this posting. I am not an expert in complexity theory so I am unable to provide any feedback (not even elementary). However, I like it that there are researchers like Vinay who are not afraid of tackling the hardest problems. I am anxious to know what are the consequences of Vinay’s work.
I was wondering if anyone can suggest some introductory references on finite model theory and the concepts discussed in section 3 of the paper.
Jeff
I am not an expert but Immerman’s book is one. Also a search will yield several surveys on-line.
I found out this thorough introduction by Gradel (it’s from a book dedicated to finite model theory):
http://www.logic.rwth-aachen.de/pub/graedel/FMTbook-Chapter3.pdf
(The address is correct, but the link doesn’t work; maybe this would do it):
here
Elements of Finite Model Theory by Leonid Libkin
Yes, these these discussions are very helpful! Thank you for updating us on the process.
I am somewhat distressed to see so many people spending a lot of time on this.
It does not actually look like a serious attempt at P vs. NP to me. It does not seem
to have any original ideas, just an intuition that has been often expressed that
search spaces broken up into many clusters far apart are hard for standard search
algorithms (but as has been pointed out, can also be exhibited by problems in P,
such as solving linear equations.) I don’t see any real statement of a series of lemmas
that imply the main theorem, and the conclusions reached do not seem to be
supported by any claims made earlier.
I’d like to see a clearly articulated lemma that states the properties used that imply a
problem is not solvable in P. In particular, it should be possible to see that the properties
fail for random linear equations, or other easy instances of search problems.
I agree with Russel’s comment. I also do not think that the paper is a serious attempt. The statements made in the paper are not accurate enough, and it seems that there is no real specific arguments supporting each part.
On the other hand, the fact that many serious people invest time on thinking about the ideas illustrated in the paper (although these are not new ideas), might be a good thing overall.
Russell, if all D were using here is separation of clusters his proof would be a lot shorter. Where are the exponentially many conditionally independent jumps between clusters (p.88) in solving linear equations? If they exist then your objection might be sustainable, but if they don’t then D’s approach potentially could also show that k-SAT is not in BQP.
I also agree with Russell that the absence of a sequence of mathematical lemmas leading to the result is problematic. And I do not see a good reason for it.
On the other hand, regarding k-XOR: as we all know, the cluster-centers in k-XOR form a linear subspace. Whereas in random k-SAT there is no reason to believe that that’s the case. It’s worth noting that, as far as I know, nobody has proved anything regarding the placement of the k-SAT cluster-centers.
Indeed, consider the following model (which I proposed as a toy model a few years back):
Repeat exponentially many times:
– Form a random string in {0,1,*}^n by letting each bit be 0/1/* independently (with some probability for each letter).
– Interpret each resulting string as a cluster, i.e., the 0/1 variables are “frozen”, whereas the * variables are not.
As it turns out, heuristic (but mathematically sophisticated) computations by Lenka Zdeborova suggest that the above “model” agrees with all the statistical physics predictions regarding random k-SAT.
So, if this turns out to be true, one can interpret the random CSPs as “lifting” the randomness used to define the (expander defining the) instance, to the space of solutions.
If it turns out not to be true, this means that there must be some “hidden symmetry” that causes the “complexity” of describing the cluster centers to collapse (as linearity does for XOR). That, in itself, seems to me like an amazing thing to happen.
So, this sounds like a win-win to me.
Russel, I disagree. Irrespective of the correctness of the proof, checking it leads to smart people working together, exploring and checking existing and new ideas, which is a net win for everybody, including themselves. In other words, even if the proof fails, it was a good excuse for these experts to come together, discuss ideas and to learn from each other.
which is a net win for everybody, including themselves
You are counting the benefits but not the cost. The question isn’t whether this discussion has been a good thing in absolute terms, but rather whether it was a better use of the participants’ time than whatever they would have been doing otherwise. From that perspective, I consider it clearly a net loss.
I find it difficult to believe that a few experts spending a few days (it has only been two days) is a net loss for everyone. If anything, this actually shows the great camaraderie in the complexity theory (and in CS) community, that everyone can come together to work on and discuss something interesting . Prof. Lipton has done an amazing job in getting everyone together, and making the discussion 100% constructive. I am more than happy to point this to researchers in other fields (e.g. medicine and pure sciences), where ideas are closely guarded and cut-throat competition exists to win the rat-race.
I totally agree with Martin and Pradeep. In some ways, this is the best kind of peer review you can hope for (esp. on such a difficult problem), and there is very constructive work by the community. In itself, this process is a victory for the blogosphere. There is genuine excitement (as warranted by a serious attempt) and either way (proof correct or not), there have been many positives, not the least of which is rekindling the interest of many in the mathematics touched upon.
Professor Lipton,
Your accessible and well-written writings motivate me to continue studying mathematics. I develop software for a living; to stay sharp, I try to study ‘real’ proofs in my spare time. Complexity is an amazing field… I cannot wait to see what we’ll learn about computation (and its relation to physics, and to everything else).
Thanks for the inspiration!
“P.S. I hope these discussions are helpful to the community at large.”
This member of the community at large can’t understand a word you say, but is nevertheless fascinated by every new post and comment. Seeing the review process unfold in public has rekindled my long-dormant interest in mathematics. I intend to register for a class this fall and (who knows?) perhaps pursue that Ph.D. after all these years.
Don’t infer from the paucity of experts who can contribute to the public conversation that you might as well confer entirely in private; on the contrary, public discussion is an immense service to the community. Thank you.
A side note. Dick mentions an email that the use of conditional independence is surprisingly new. There’s one place where conditional independence (and relatedly, conditional mutual information) has been used successfully, which is in proving lower bounds for problems in communication complexity as well as streaming. There’s a long list of papers on this topic, but a key piece of work is the information statistics approach by Bar-Youseff, Jayram, Kumar and Sivakumar: http://portal.acm.org/citation.cfm?id=1016208
Actually, “conditional independence”, is used almost everywhere where randomness is involved in complexity theory: in proofs of correctness of various pseudorandom generators, extractors, the parallel repetition theorem, the communication complexity lowerbound for disjointness etc etc.
Dear Russel,
What is distressing about a few experts on the subject spending a couple of weeks (unlikely; but, let us stretch it to that) on figuring out what is wrong with the proof? And seeing if there are any aspects of his approach that may be useful and so on. It is not as if such claims are surfacing every other day. It seems snobbish to say that people should not spend time on an effort like this….especially, when there have not been many explicit announcements by complexity theorists that they working on this important problem…and some of the “leading beacons” of the theory community made comments in poor taste about some ongoing efforts. ofcourse, the community seems to be slowly acknowledging the value of the approach.
Thanks
Actually, there are many “proofs” of P vs. NP all the time. There were two or three posted on math archives this month. The primary distinction between this one and the others seems to be social,
rather than technical. Namely, this one seems to have gotten the label of a “serious” effort,
without much technical distinguishability from many of the other similar claims.
My problem with this attempt is that
it is not clearly written. There should be an outline with a list of lemmas that together imply the
main result. Then we can try to verify or disprove the lemmas. Instead, we are spending time discussing what certain passages in the paper might mean, and only considering it invalid if there is no possible valid interpretation. The more ambiguous the text is, the more difficult this is. That’s
why it is usually incumbent on a mathematician to be as unambiguous as humanly possible.
People like Tao and Gowers can accomplish a lot in a few days, so I think if there’s no
meat here, it is a shame to waste those days. Especially since I don’t think either of their backgrounds matches this paper particularly well, and they don’t spend a lot of time on
computational complexity per se, so I’d like “our” share of their time to be very productive.
I’d be happy to be shown wrong, and
will be going through my copy of the paper just like everyone else, but I’m getting frustrated.
Dear Russel,
I am sorry to be pedantic about it. But, are you suggesting that we stand to lose a “lot” {whatever it means} if the likes of Tao and Gowers spend a couple of weeks on this? For instance, do you think they could come up with a proof for a weaker lower bound result in complexity theory? Moreover, Vinay has not forced anyone to spend their time. Perhaps this curiosity to check things for themselves that has made the likes of Tao and Gowers what they are {great mathematicians}. I would not be distressed as long as they are doing it happily and willingly!! Time is anyway an amorphous quantity to those who realize it 🙂
More importantly, thank you very much for clarifying your source of botheration. I do agree that Vinay could have helped his cause with an outline of ideas and succession of claims that helps him arrive at his claimed proof.
As frustrating as the process is, we can hardly blame Deolalikar for that. I’m pretty sure he never intended for things to unfold in such a public fashion. If people had refrained from making public what had been communicated to them privately, and given him a chance to digest the feedback, maybe we would be looking at a more polished paper (regardless of correctness).
To me, Deolalikar soliciting feedback before going public shows seriousness of intent at least (if not seriousness of the paper itself), and this alone sets him apart from the countless arxiv drivel.
Couldn’t agree more, Russell.
Good comment Russell, finally someone had the balls to say it. Come on, this proof is a joke and everyone competent knows it. The paper is 80 pages of citing/surveying crap and 20 pages of nonsense. It’s a shame so much good brainpower is being wasted on attempting to salvage something from this trash.
Well, good to hear you’re such an expert on this and on surveying what “everyone competent” thinks about this attempt. Why are you wasting your own brainpower on trashing “this trash” then?
People like you should not be in grad school, as you claim, or even in CS.
Dear grad student,
Being skeptical and pessimistic about this work is OK, attacking the author or others spending *their* time is not. If you don’t like what is going on here why are following it? Go do whatever you like, others can decide for themselves if it worths their time.
I’m just a programmer with some math/CS background.
The paper did seem really “thin” to me, just stringing together existing results rather than the hard constructions I’d imagine would be required for P!=NP (not that I even knew the terminology past a couple of pages).
It’s still fine the people here are being really nice about the situation. “Perhaps some of claims can be used for something… ” “you might have opened up new vistas”
As folks well know, there’s certain psychology that impels some random group of population to throw-out almost-always misguided efforts to solve the great problems of mathematics. The folks who do with little math background get labeled “cranks”.
In the case of P!=NP, it seems like even a serious, trained mathematician could fall into the same trap just because the result is so far beyond what one can expect from the existing machinery of Theory of Computation.
I suppose all I’m saying really is that folks who being so nice here should also show some mercy to the ordinary “cranks”. Yes, the chances are nearly certain that your average “crank” is ignoring the obvious holes in their logic out of a neurotic hope they can finally get attention for their “discovery” that they perhaps didn’t get from their family/teachers/friends/etc. But keep in mind, this neurotic trap is lurking for at least many people.
But that’s just my thinking…
cs grad student:
Is it really necessary to be an asshole and use words like “joke”, “crap” and “trash” to describe Deolalikar’s work?
I truly despise elitists like you who need to put down other people in order to make yourself feel better.
I’m sorry, nobody, but yes, it is really necessary.
i’m sorry dear Hugo, this seems necessary only for those “control-freak experts” whose “monopolising expertise” is based on, and derived from that!
They understand they cannot control and monopolise actual knowledge so they instead try to monopolise (by various means, including the ones you describe) “certificates and cliques” so as to appear as (the infallible) experts.
Prof. Lipton, at least a weaker version of one of your open problems ( can amateurs solve P/NP) is proven now.
A relatively unknown figure can at least create a serious churn across the community w.r.to P/NP.
Deolalikar isn’t an amateur by any means, but he wasn’t a Razbarov or Wigderson either (until now).
I wish one of the experts would create a tutorial article (with links to wiki entries, papers, books) geared at non-expert CS/Math grads about the recent developments in complexity theory, esp. concentrating on the stat.phys. connection, that enable this maybe-proof.
http://www.ugcs.caltech.edu/~stansife/pnp.html
Check that out, might help.
“I am somewhat distressed to see so many people spending a lot of time on this.
It does not actually look like a serious attempt at P vs. NP to me.”
Thank you Russell for saying something non-anonymously that the rest of us are thinking. Look at the paper. It is not a serious attempt. It is not a rigorously written mathematical argument. If any serious mathematician really believed they had an approach to P vs. NP, they would definitely seek to write it in a straightforward, easily verifiable way. And Deolalikar has a Ph.D. in mathematics; he should know the standards of mathematical writing.
Read the paper. He is more interested in buzzwords than clarity. It is quite clear that there is something very wrong in the model theory part of the paper, which is where all the interesting action has to be happening. After having a very weak (and incorrect) characterization of P, the proof could end in a variety of ways. The author has chosen to reach a contradiction using random k-SAT. And this, apparently, is leaving some people (who are unfamiliar with the work on random CSPs) hailing it as a “new approach.”
I think that many bloggers have become quite enamoured with being part of the publicity storm, and are thus complicit in its continuation. The situation is very simple: If he believes he has a proof, then he should write a 10-page version without all the unnecessary background material, stream of consciousness rambling, and overly verbose ruminations. Just the math, please.
What you will find is not that he has discovered a shocking new technique. This is not very good work that happens to have a subtle flaw. This will not solve some special case like NL vs. NP. Instead, it is simply a misunderstanding caused by a lack of rigor and a lack of professional mathematical colleagues against whom he can check his ideas.
Let’s try to be responsible here, as a community. Let’s not say things like “Vinay’s use of conditional independence seems strikingly new.” How can you say this without understanding the proof, even at a very basic level? This reeks of bombastic pseudoscience.
If there was a clear statement of Deolalikar’s claim, we would see, immediately, that it is false. Please, someone tell me: If a distribution over assignments to a random k-SAT formula is generated by a polynomial time algorithm (by checking all the partial assignments, as he does), what structural property does it have that distinguishes it from the actual set of solutions?
The biggest mistake here is the response of the community. We should definitely NOT be supportive of such efforts. Think about it: Do you want to have such a reaction every week, to every new “proof” claiming to resolve a famous open question? We should reinforce the responsible action: To produce a clear, concise, carefully written proof and send it quietly to a few experts who can give it a first reading. After it has been revised and rewritten to their standards, humbly circulate it more widely; say that you are hopeful that your proof is correct, and you would be exceedingly grateful to address the comments of interested readers.
As currently written and announced, Deolalikar’s manuscript is disrespectful to the community. We are given a bad name so he can have 15 minutes of fame. Please stop propagating this madness. It’s irresponsible.
Amen.
If you are familiar with random k-SAT literature, you should have noticed some experts on the topic who have commented here and in the previous posts, and you would have read their comments to see if they think there is anything interesting in it.
FYI, he didn’t publish his paper publicly, he sent it privately to some expert for comments, it got forwarded several times and at the end someone copied it to some public site. (but anyway, he should have spent more time on polishing the paper.)
I agree we should not encourage cranks, but we *should* encourage serious mathematicians and computer scientists to work on open problems like this.
A similar argument could be made (and was, I guess) about the contributions of Augustine Galois to mathematics – he couldn’t manage to do the work of communicating his ideas, on paper, in a nice clear fashion that’s instantly accessible to other mathematicians – so he was a crank and Group Theory was a giant waste of everyone’s time, right? Or something.
This man is not a crank. Nor is he an expert in complexity (although he has published in the field), and this is the computer science problem to end all computer science problems, so his proof is almost certainly flawed, like the rest.
But if its “getting too much attention” its because at least some smart people in a position to evaluate the work don’t think its a complete waste of time.
The beautiful thing about science and mathematics is that ultimately it doesn’t matter if you’re an expert or an amatuer, if your exposition is long or short, rigorous or hand-wavy, etc; what matters is if you are right or wrong. The cranks who argue that “insiders” must be wrong because of the occasional scientific “outsider” who was right miss the point that insiders are just people with a track record of being right, and the fact that the occasional outsider who becomes famous for being right doesn’t change the fact that the vast majority are invisible, and wrong.
This cuts both ways. “Insiders” arguing that outsiders should be dismissed out of hand – “only a PhD and an industrial researcher, not a professional academic, not exposed to genuine peer feedback, hasn’t communicated the ideas clearly enough, therefore this is obviously garbage” are missing the fact that if its garbage, that will become readily apparent in due time. If its already apparent to you, then decide whether demonstrating clearly why its garbage to save other people from the effort is a better way to spend your time than whatever else you could be doing, and act accordingly.
“The community” of researchers, like every other, consists of individuals, and they are all free to spend or not spend their time on approaches they think do or don’t show promise, as they see fit. This has proved to be a pretty workable system so far.
If any of you think the likes of Professors Tao and Lipton would be spending their time better – presumably, on your own pet research projects – then convince them of it. If you think its all just media hype inefficiently allocating people’s attention, well sure, it probably is. Once you’ve figured out a better way to do things, please feel free to share them as I’m sure civilisation will benefit a lot.
Even if the proof ends up teaching us nothing about complexity theory, at the very least it should teach us something about how the blogosphere compares to traditional peer review for finding flaws in complicated papers.
Hi Jordan
Hi believe that you may have wanted to refer to “Evariste Galois” 🙂 (I am French too…)
For some reason I can only reply to my own comment, not to Pascal reply’s to it.
Suffice to say thank you Pascal, of course you are right and I stand corrected.
Perhaps I was getting Galois mixed up with Cauchy? I think in future I will just stick to the surnames of famous mathematicians to avoid this kind of a mix up 🙂
Thank you Russell for saying something non-anonymously that the rest of us are thinking.
There is a certain irony in this sentence being signed ‘Concerned Citizen’.
And, yes, I know, I’m not signing my own name either, but then again I’m not thrashing Deolalikar. If I had any comments to make about the scientific contents of the paper, I would use my own name, and you would be able to decide how much credibility you would want to assign to my statements.
Hear hear.
I am very curious to understand this comment by Harrison.
“Another issue: If I understand his argument correctly, Deolalikar claims that the polylog-conditional independence means that the solution space of a poly-time computation can’t have Hamming distance O(n) [presumably he means \theta(n)], as long as there are “sufficiently many solution clusters.” This would preclude the existence of efficiently decodable codes at anything near the Gilbert-Varshamov bound when the minimum Hamming distance is large enough. ”
There are linear-time decodable codes (Spielman) with high rate, but I do not know if they are “near” the Gilbert-Varshamov bound. In any case, I do not understand this comment and it looks interesting.
As I understand it, the statistical part of the argument centers on the following:
(i) FO(LFP) computations are incapable of “constructing,” in a certain sense*, solution spaces with the property that there are exponentially many solutions and the least (average?) Hamming distance is O(n).
(ii) Random k-SAT, for k large and the clause density in certain regimes, has the property that there are exponentially many solutions but the least (average?) Hamming distance is O(n).
(* More precisely, they can’t extend a partial solution to a full solution.)
My comment simply points out that greedy constructions give us lots of subspaces of {0,1}^n with the properties stated in (i). (Actually, so does a random linear code…) So if there’s a code such that one can extend a partial codeword to a full codeword in polynomial time — as long as there is an extension — then either the proof strategy breaks, or I’m reading the proof incorrectly.
I could not follow most of the discussions because of my lack of knowledge in the subjects. However, Gil’s comment made me curious. I can say that: random ensemble of codes on hyper-graphs (even bipartite graphs) with local Hamming code meets the GV bound up to a high rate (covers the high distance case easily) and they are linear time decodable to correct a small but constant proportion (O(n)) of errors. Although I am not aware of any algorithm that corrects up to half the GV distance (even close to it).
I cannot agree more with what Russell said.
Besides, for someone knowing the finite model theory used in the paper, there is a
jump in the reasoning that lacks justification. This is the jump from Monadic LFP to
full LFP. The only justification for this crucial step seems to be Remark 7.4 in page 70
of the original manuscript (and the vague statement in point 3 of page 49), but this is
far from satisfactory. The standard constructions of the so-called canonical structures
that Vinay refers to (see Ebbinghaus and Flum book in page 54) have a Gaifman graph
of constant diameter, even without the linear order, due to the generalized equalities
that allow the decoding of tuples into its components.
Issues along these lines were raised before here http://rjlipton.wordpress.com/2010/08/09/issues-in-the-proof-that-p%e2%89%a0np/#comment-4677
and in comment 54 here http://scottaaronson.com/blog/?p=456#comments
among others.
I like the suggestions in this post. They can convince skeptical people like me to see that there is at least some real meat in this paper. The question about how essential is uniformity is specially interesting. I personally would like to know what Eric Allender thinks about this, even more after reading harrison’s comment above.
Although there is a serious problem regarding what is being used about k-SAT that does not hold for k-XOR-SAT (http://michaelnielsen.org/polymath1/index.php?title=Random_k-SAT), it seems that some experts are not completely pessimistic that it can not be fixed or at least bring up interesting questions into attention, i.e. even if (which I think will) does not stand.
Regarding Russell’s concerns, I guess Gowers, Tao and others are not spending any more time on checking this right now (unless they have found something in it which is of independent interest) and probably are waiting to see Deolalikar’s response to what have been said so far. He should be given some peace and more time to think about them, and I like Dick’s positive attitude toward this. But I also agree with Russell that the paper could and should have been written in a better way before being sent to anyone (being a first draft does not change anything here and he should have expected what would happen if his claim was taken seriously. If he did not think that it would be, he shouldn’t have sent it to them). He could have waited a few more weeks, polishing the structure of his paper, spelling out what are the key lemmas, being more rigorous, …; which would make it easier for others to see what is going on in it.
typo in my previous comment:
“even if (which I think will) does not stand.”
should be
“even if it does not stand (which I think won’t).”
A potential bug in Deolalikar’s proof
=========================
I believe Vinay’s proof has at least one potential bug. I believe he is considering only those algorithms that determine satisfiability by constructing assignments to the variables in the input k-SAT formula. He then purportedly shows that if these algorithms run in polynomial time we have a contradiction.
THE BUG IS THE FOLLOWING:
It is not necessary for an algorithm to assign variables in order to determine satisfiability. It is entirely possible that there is some as-yet-undiscovered algorithm that determines k-SAT satisfiability simply by syntactic manipulation of the input k-SAT formulas.
Any proof of P!=NP (that is based on k-SAT), must show that there is no polynomial time algorithm for k-SAT. It shouldn’t matter how satisfiability is determined.
Following is an example of an algorithm for determining satisfiability of simpler kinds of SAT formulas without the need for generating a partial assignment, and does so by pure syntactic manipulations. I call these formulas ‘implication clauses’ with only 2 variables (implication clauses with two variables are essentially formulas of the form x1 => x2, x3 => negation(x4), …)
1) Chain the implications in the input appropriately (i.e., if the input contains x1 => x2 and x2 => x3, then conclude x1 => x3), derived all possible such formulas (by transitive closure)
2) If we have at least one formula of the form x1 => negation(x1), then return UNSAT
3) Else, return SAT
Vijay: If there is no polynomial algorithm of the form he assumes (i.e. one that finds the satisfying assignment itself), then P != NP. For if P = NP, then SAT is in P, and you can easily find the satisfying assignment (by iterating SAT queries).
Concerning Suggestion One, UTC understood as FO+BIT will be able to tell the two distributions appart simply by approximately counting the number of clauses: that uniform AC^0 (= FO+BIT) can approximately count up to a factor of 1+1/polylog(n) is a celebrated result of Ajtai.
On the other hand, Deolalikar’s technique could perhaps apply to UTC understood as FO+Successor where Hanf’s locality still makes sense and neighborhoods in the Gaifman graph are still polylog-sized; for contrast, in FO+BIT, Gaifman graphs have neighborhoods of linear size.
(Background: FO+BIT = first-order logic assuming a predicate over the universe 1,…,n that holds at BIT(i,j) if the i-th bit in the binary expansion of j is 1; FO+Successor = first-order logic assuming a predicate over the universe 1,…,n that holds at Successor(i,j) if j = i+1).
D’s proof splits at the root into two main pieces: a characterization of the infeasibility of k-SAT, and a characterization of the inability of P to cope with that infeasibility. Warming up with UTC or NL would only simplify the latter piece. And you’d be foolish to start out with a paper limited to just those without doing P as well, since otherwise the descriptive complexity crowd will step in and grab the brass ring without you. Your best bet would be to treat P up front and leave the pedagogy to others in the interest of brevity (such as it is), as D has done.
However unclear you might think D’s paper, it is a model of clarity compared to Peter Weiner’s SWAT(FOCS)’73 exposition of his linear-time suffix-tree algorithm, and that turned out in the end to be correct, though it took a month of refereeing to untangle it.
I’d like to respond to the tone of a couple anonymous comments.
It is almost irrelevant to me whether the proof, as currently written, is correct. (I expect there to be flaws, perhaps unfixable ones.) What excites me — and, I think, a lot of other people — is the attempt to join together descriptive complexity with statistical physics. The bridge between finite, discrete complexity, and hardness in the continuous world “has to exist,” and the “evidence” for this can be found in everything from the distribution of the primes to the computer simulation of chemical reactions. Despite this, over the last few years, I’ve gotten the impression that researchers in logic and physics tend to be put off by — even scared by — the notations and dialogues of each other. So when someone from “outside” says he’s found a way to connect the two areas, it’s intriguing.
I’ve certainly gained insight into areas I had no clue about whatsoever, until just a couple days ago. It seems to me this whole situation is only partly about trying to understand a proof. Perhaps the more important part is us trying to understand one another.
Aaron says: “It seems to me this whole situation is only partly about trying to understand a proof. Perhaps the more important part is us trying to understand one another.”
Terrific! In the memorable words of Star Wars’ Han Solo: “Well that’s the real trick, isn’t it?”
If only Dick’s blog supported applause icons … 🙂
I have not attempted to deconstruct the proof myself, nor would I be able to, but I am taken aback by the complete lack of respect such as exhibited by Russel. Calling this proof “trash” without even stating specific reasons why it does not work and other such nonsense.
There have been no concrete evidence regarding the proof either way but if even the top minds in the field of Complexity Theory (including professors from my alma mater – although Neil Immerman has not mentioned anything yet) agree that this is a “serious proof by a legitimate researcher”, there must be something to it. The involvement of numerous fields is also an “eye-opener”. I am eagerly awaiting the outcome of this, but to jump to conclusions and call this proof trash is completely disrespectful and immature.
How can you say that the “top minds” in Complexity Theory agree that it is a serious proof when Russell Impagliazzo, who is probably the “top mind” in the field, and Scott Aaronson, who isn’t far behind (I’ll let them battle it out) both say exactly the opposite? Even Prof. Cook’s original e-mail that may have set off the storm of interest only said that it “appears to be a relatively serious claim”. I think that is a fairly weak statement of support.
Amen, but I don’t think Russel was the one who called it trash.
I did not call the proof “trash” or any other demeaning name, and I have no disrespect for the author, although I am frustrated with his writing style. I am also
not telling anyone what they should or should not work on.
What I am most concerned with is how we distinguish between “serious” and “non-serious” attempts at famous theorems. The use of the criterion: “famous researchers are spending time on it” or some such leads to a snowball effect. As a researcher in complexity, I should be dropping everything in my life to consider a serious proof that P \neq NP. Is this such a proof? Because others are spending time on it, maybe it is. At least it would be better to waste my time on it than for them to waste theirs…But then we’re all wasting all of our time on (what seems likely to be) a dead end.
Here’s why I think this paper is a dead-end, not an interesting attempt that will reveal new insights. As Terry says in his post, the general approach is to try
to characterize hard instances of search problems by the structure of their solution
spaces. This general issue has been given as an intuition many times, most notably
and precisely by Aclioptas in a series of lectures I’ve heard over the past few years.
(Probably co-authors of his should also be cited, but I’ve Aclioptas give the talks.)
The problem is that this intuition is far too ambitious. It is talking about what makes INSTANCES hard, not about what makes PROBLEMS hard. Since in say,
non-uniform models, individual instances or small sets of instances are not hard,
this seems to be a dead-end. There is a loophole in this paper, in that he’s talking
about the problem of extending a given partial assignment. But still, you can construct artificial easy instances so that the solution space has any particular structure. That solutions fall in well-separated clusters cannot really imply that the search problem is hard. Take any instance with exponentially many solutions and
perform a random linear transformation on the solution space, so that solution
y is “coded” by Ay. Then the complexity of search hasn’t really changed,
but the solution space is well-separated. So the characterization this paper is attempting does not seem to me to be about the right category of object.
The paper combines two approaches that I have heard many times as intuitions,
and did not seem to add any real substance to either. He talks about “factoring”
the computation into steps that are individually “local”. There are many ways
to formalize that steps of computation are indeed local, with FO logic one of them.
However, that does not mean that polynomial-time computation is local, because
the composition of local operations is not local.
I’ve been scanning the paper for any lemma that relates the locality or other weakness of a composition to the locality of the individual steps. I haven’t seen
it yet. Can anyone point me to where this is done?
The other part is the structure of solution spaces. As has been pointed out, while
the structure of solution spaces can make a problem hard for specific algorithmic
approaches, single instances of problems are not hard. (Although there may be a
loophole in asking for extensions of given solutions…) Here, I would like a statement of exactly what structural properties are required, and why random
linear codes (with sparse parity check matrices) do not have these properties (since extending a partial solution
to a full solution for such a code can be done in polynomial time, and the logical
structure of such a problem is similar to k-SAT.)
whiskers:
Do you know ANYTHING about complexity theory?
The fact that Steve Cook said it looks serious does not mean it is anywhere near the standard of a bloody mathematical proof.
Besides, Cook is indeed the person who formulated the problem but if you ever care to know more about him, apart from winning the Turing award, he also works in proof complexity and bounded arithmetic, while this dudes used finite model theory and some bizarre statistical physics.
Thanks, Russell, for explaining further your reservations, which go a long way towards answering my own question #3 – in particular I now see more clearly how the method “proves too much” by also separating some non-uniform complexity models, which among other things brings one dangerously close to triggering the natural proofs barrier. The locality issue has been brought up elsewhere too, and looks to be quite an important point.
I understand your concern about the snowball effect, but actually I think this time around, the fact that we concentrated all the discussion into a single location made it more efficient than if everybody just heard rumours that everybody else was looking at it, and dozens of experts each independently and privately wasted hours of time doing the same basic groundwork of reading the entire paper before reaching their conclusions. I think the net time cost has actually been reduced by this method, though of course the cost is far more visible as a consequence.
I think there are a number of useful secondary benefits too. For instance, I think this experience has greatly improved our “P!=NP Bayesian spam filter” that is already quite good (but not perfect) at filtering out most attempts at this problem; and I think we are better prepared to handle the next proposed solution to a major problem that makes it past our existing spam filters. Also, I think the authors of such proposed solutions may perhaps also have a better idea of what to expect, and how to avoid unnecessary trouble (well, the best advice here is not even to try solving such problems directly, but somehow I think this advice will not be heeded 🙂 ). Such authors often complain that their work gets ignored, but actually they may be lucky in some ways, when compared against those authors whose work gets noticed…
Indeed, there is quite a few works trying to characterize hard instances of search problems by the structure of their solution
spaces. Computations and numerical experiments in statistical physics provide many nice heuristic arguments why some local algorithms (local search, simulated annealing …) should have trouble on certain random instances (the question is related to why glasses relax so slowly to the equilibrium, that is where the connection with real physics comes from). In particular, the daring but still standing physics conjecture is that instances in the frozen phase on random K-SAT (used by Deolalikar) are among the hardest NP problems.
Statistical physics methods, that are widely believed exact in physics, but so far are not fully rigorous, predict many properties of the solution space. Some of these properties are proven rigorously, a number of these proofs are indeed due to Achlioptas and his collaborators.
But none of these results has the ambition to say anything about the P!=NP question. If this is what Deolalikar managed to do, then I am truly impressed and happy. But even if he did not, I would love to understand if the math in his work can be used to formalize the class of algorithms that cannot work in polynomial time if the structure of solutions on a random NP-complete problem has certain (to be specified) properties. This class of algorithms should probably not include Gaussian elimination.
Given so many great mathematicians discuss here, anybody intrigued by this question?
Hello, I think you confused the authorship of Russell Impagliazzo’s comment with the rude reply that came after it (the one that did have words such as ‘trash’).
“Despite this, over the last few years, I’ve gotten the impression that researchers in logic and physics tend to be put off by — even scared by — the notations and dialogues of each other. So when someone from “outside” says he’s found a way to connect the two areas, it’s intriguing.”
I don’t get that impression in the slightest. I’m no expert but I like reading Scott Aaronson’s blog about quantum computing and it seems to me that at least in that field, there is plenty of willingness to bring physics knowledge to bear on complexity problems.
Of course you’re right about that, none. I was talking more about the communication barrier between people who do model theory, as opposed to people who do a lot of PDE’s — or even finite dimensional Hilbert space people (quantum computing) vs. infinite dimensional (e.g. quantum control). This is of course based on my limited perception. More important is increased communication we can build, going forward, whether my perception is right or wrong.
To agree with Vaughn above there are many proofs which were initially considered unclear but which were later found to be correct.
(1) Kurt Heegner was an amateur mathematician who solved the famous “Class Number One” problem but his proof was only accepted after his death due to some minor mistakes.
(2) Louis de Branges proved the Bieberbach conjecture but his initial paper also had some small mistakes which led to widespread disbelief.
(3) Roger Apéry proved the irrationality of Zeta(3). But his proof was very sketchy and most of the math community didn’t believe him. But 3 guys (Cohen, Lenstra and van der Poorten) set out to check his work and found that it was essentially correct.
So lack of clarity in the initial draft is not a reliable indicator of whether a paper makes important developments.
So lack of clarity in the initial draft is not a reliable indicator of whether a paper makes important developments.
It’s a pretty reliable indicator – you are taking some of the most famous examples where the indicator failed.
The Heegner case is the saddest, since he died before vindication, but there were indeed gaps in his proof. In hindsight Stark discovered they were fixable, but this certainly wasn’t obvious in the 50’s.
The Apery and de Branges cases have major social factors at work. Apery gave an exceptionally eccentric account of his argument (leaving out proofs of the main assertions, answering questions about where his identities came from by replying “they grow in my garden”), but as soon as people checked some of his identities with a calculator (which I understand happened immediately after his talk), they recognized that he was on to something.
In the de Branges case, he had previously claimed to have solved major problems (for example, the invariant subspace conjecture), with no success, so there was an attitude of “oh no, not de Branges again”. Plus he was using this as an opportunity to push his elaborate theory of Hilbert spaces of entire functions, and he became angry when people successfully simplified the proof by removing hundreds of pages of this material. So basically de Branges was inadvertently doing everything he could to alienate people.
Of course you’re right that an unclear proof may turn out to be right in the end, but your examples are very far from typical.
Anon: There were no gaps in Heegner’s work. See Birch’s article in the MSRI “Heegner points and Rankin L-series” volume.
Another example is Mihailescu with Catalan (not yet with Leopoldt). One sage of note was annoyed that his techniques worked “just when I stopped reading them” [his continual rewrites]. In fact, in one version, he had an infinite sum of algebraic numbers that converged to an algebraic number, and applied a Galois action to each side… and in worked in this particular case!
A common thread for most of these cases is eccentricity, like Heegner calling Pythagorean triangles by the phrase “Harpedonapten.” Birch’s article calls his paper “amateurish” [maybe more from the root “amato” (lover) than the more sciolistic meaning] and “mystical” in style, so again the weight lies on the author for some of the confusion.
Birch also says nothing more than that it relies on Weber — pace Stark, who points out that closely related parts of Weber are incorrect (and which led to suspicion with Heegner) but the exact ones he uses are in fact valid. A better paper to quote is Stark’s “On the ‘Gap’…” paper http://dx.doi.org/10.1016/0022-314X%2869%2990023-7 where he deals with an irreducibility question that Heegner elided.
Apery has many tangential factors, and he personally never in fact published a proof. The question of whether he actually did prove some of the identities of concern has never really been addressed, as the successors (hypergeometric Gosper, then A=B) have made this almost automatic. His insight was to follow this trail in the first place. One transcendence theorist said his opening statement of the talk was something like (to his non-French ear): “I am going to prove the irrationality of a certain real number – but my idea of the real numbers might differ from yours,” probably an ill-considered oblique reference to his then-recent battles over French maths curricula. I think he is the only person to beat Serre in both chess and table tennis, but that is a mere story.
Contrary to this, Miyaoka’s FLT proof (for large p) in 1988 was quickly cleaned up because it was clear what he was doing. Prior to this, I think that incidence was maybe the highest powered joint quasi-public peer-review. Not that it influenced Wiles any….
Robert says: There are many proofs which were initially considered unclear but which were later found to be correct.
Robert’s examples were all proofs by mathematicians, but it is common also for proofs conceived by engineers to be criticized by professional mathematicians. Over on Scott Aaronson’s blog I cited some examples by Poincaré (who worked as a mining engineer).
There is also J. L. Doob’s 1948 review (MR0026286 (10,133e) 60.0X) of Claude Shannon’s seminal “Mathematical theory of communication” that concluded “The discussion is suggestive throughout, rather than mathematical, and it is not always clear that the author’s mathematical intentions are honorable.”
That is why Deolalikar’s proof technology (and its various transforms, per Leonid Gurvits’ posts on Shtetl Optimized) with its blend of physical and mathematical elements, seems very interesting independent of whether his proof is formally correct.
I’m willing to help with the proof, but there needs to be some way of figuring out how to divide up the prize money if and when a proof is finally accepted. Vinay will of course get most of the prize money, but surely those who help contribute to it are justified in claiming some of that money too? Perhaps a legal structure should be put in place before a formal wiki is created? That was the level of contribution can be tracked and monetized.
So you’re in it for the money, eh? Not saying Delalikar isn’t, but this is about so much more than just money. Shame.
I assume this is a joke, but it’s worth noting that (in the unlikely event that this leads anywhere) the Clay prize committee is in charge of deciding how to divide the prize among several people. They are unlikely to recognize anyone but truly major contributors – for example, there’s the precedent that the people who verified Perelman’s proof were offered nothing, despite putting in enormous amounts of work. So don’t count on a “every blog comment is worth $1” policy. 🙂
I think I ought perhaps to comment that I’m not myself devoting every waking hour to trying to understand what Deolalikar has done. It involves a lot of stuff that I don’t know about, and a preliminary glance at the paper makes me thing that it has an oddly expository flavour — I can’t see where the work is being done. (That doesn’t in itself rule out correctness, but it makes me anxious.) Basically, it’s obvious to me that whether or not the proof is correct is something that others will find much easier to determine than I will. The reason Dick mentions my name is that I was on an email list for a particular correspondence about the paper.
My interest would increase dramatically if somebody could give a proper synopsis of the proof. Deolalikar gives a synopsis, but it isn’t of a kind that one can understand. To illustrate what I mean by a “proper synopsis”, here is one for the Green-Tao theorem. Green and Tao deduce their theorem from Szemeredi’s theorem. On the face of it, that seems impossible, since the density of the primes is smaller than the best known bound for Szemeredi’s theorem. They accomplish the deduction by showing that the primes are relatively dense inside a “pseudorandom” set. This allows them to “lift” the primes to a dense subset of {1,2,…,n}, apply Szemeredi’s theorem (in a form that gives not just one but many arithmetic progressions) and then pass back to the primes again. Even this appears to be impossible, since the primes have some important non-randomness properties such as not containing any even numbers greater than 2. However, there is a standard trick in number theory, known as the W-trick, where you pass to an arithmetic progression that contains no multiples of the first k primes for a suitably chosen k. The primes in such an arithmetic progression turn out to sit densely inside a pseudorandom set.
With a synopsis like that, people who know the right kind of mathematics can set about working out the proof for themselves, turning to the Green-Tao paper for clues when they get stuck. That’s what I’d like to see more clearly from Deolalikar: a reduction of the problem to a sequence of simpler problems.
Timothy,
Thanks for great comment.
Yes I agree. We all would like to see some summary like this.
One of my first posts ever is relevant—see this on elevator rides and proofs.
Yes, that post of yours expresses very well how I feel. Since I’m replying, let me make the additional point (to my previous comment) that everything I said in the Green-Tao summary can itself be broken down. For example, if somebody says, “That sounds a bit pie-in-the-sky. What do you mean by ‘pseudorandom’?” it is perfectly possible to give an answer, to explain how it relates to existing notions of pseudorandomness, etc. And if you want to know more about the lifting process, that’s possible too, without any need to go into details.
A general remark (nothing to do with the paper under discussion).
An overly expository tone is rather typical when you’re stretching yourself and writing in a field that you’re not 100% familiar with. It’s a red flag, it makes for a somewhat irritating read, but I would hate to let this influence my opinion of the contents of a paper. Outsiders, unencumbered by baggage, sometimes come through with good ideas.
I think we all thank Mr Deolalikar, first for having expent his time in working in such a hard problem and second to share his ideas about it in public. It is truth that a most succint and clear comunication would have been welcomed (and still is) as some have pointed. IMO this more than 100 pages paper can be summarized in 10 pages with a list of the key already known lemas/theorems from the different fields he uses (FMT, Rk-S etc…) and the new propositions.
Now, both prestigious mathematicians and what is more important IMO, great specialists in the tools he uses for the purported proof (by the names i´m seeing first spades in their fields) are paying attention to this attempt. This is unusual.
I´m of those who thinks that it is good that people work in these problems (even if their attempt result turns out to be wrong), it is good that they communicate it, and it is good that the community reacts. But i´m missing something: Mr. Deolalikar´s feedback.
Maybe he was not asking for this reaction from the community, but it has happened. I think the community expects a public answer from him: does he still claim he has a proof ? will he give answer to the possible bugs pointed by experts ? is he working fixing it ? is he simplifying it ?
IMO just a short comment in this blog which has centralized all the discussion will suffice.
For me, the concerns about SAT vs. XORSAT can be boiled down to a very concrete question:
Is the logic that Deolalikar uses powerful enough to express Gaussian elimination?
If so, he must be relying on a statistical property that k-XORSAT doesn’t have, but k-SAT does. Since both problems provably have a phase with an exponential number of clusters, O(n) frozen variables, and O(n) Hamming distance between clusters, what property is this?
Of course XORSAT is linear and we all believe SAT is irredeemably “nonlinear”, with no succinct description of its clusters; but the similarity between SAT and XORSAT seems to show that purely statistical ideas aren’t sufficient to prove this.
If not, then as suggested above he may be separating NP from some lower-level complexity class where Gaussian elimination is impossible (somewhere below DET?)
As a separate point, note that if his proof, if correct, shows that there is a poly-time samplable distribution on which k-SAT is hard on average — that hard instances are easy to generate. In Impagliazzo’s “five possible worlds” of average-case complexity, this puts us at least in Pessiland. If hard _solved_ instances are easy to generate, say through the “quiet planting” models that have been proposed, then we are in Minicrypt or Cryptomania.
Cristopher Moore: “If so, he must be relying on a statistical property that k-XORSAT doesn’t have, but k-SAT does. Since both problems provably have a phase with an exponential number of clusters, O(n) frozen variables, and O(n) Hamming distance between clusters, what property is this?”
Exponentially many conditionally independent jumps between the clusters. (Remark 8.12 on p.102 (pdf p.107) of the Wednesday edition, Remark 7.11 in earlier editions.)
How would you show their conditional independence for XORSAT?
Despite the fact that conditional independence is the first concept of the paper, about the only comments people are making about it is the fact that it’s been used in other problems before. Surely the latter fact makes CI more relevant to this proof rather than less.
As I wrote earlier, the proof divides into two parts, thankfully as stated right up front in the first paragraph of the abstract of Wednesday’s edition (earlier editions left this division to readers with sufficiently vivid imaginations).
This means that to refute the argument it now suffices to refute one of these two parts: either show that PTIME-solvable spaces are not always parametrizable with c^(poly(log n)) parameters for some c > 1, or show that k-SAT has no phase where c^n parameters are required for some c > 1.
As Dimitris wrote earlier in response to my response to Russell, the latter would be remarkable, so this is an unpromising refutation approach; you will almost surely need to refute D’s argument here at some finer granularity.
To me the more dramatic part of D’s proof is his claim that problems in P necessarily factor as above.
My feeling (and I may be completely off base here) is that we understand NP better than P. The obstacle to deciding P=NP is not whether NP contains hard problems, which we’ve known for several decades to be the case, but whether P is up to those hard problems.
This suggests the following division of labour in analysing D’s proof.
1. Verify that his reasoning about k-SAT is fundamentally sound, fixing bugs as needed.
2. Find the fatal flaw in his argument about PTIME and FO(LFP).
If either 1 fails or 2 succeeds, D’s proof fails.
The only remaining possibility then is that 1 succeeds and 2 fails. But in this case obviously all the attention is now focused on 2, which is to say on PTIME. This is where I believe the effort should have been concentrated from the outset. Any real insight into P=NP must come primarily from insight into P.
2. Find the fatal flaw in his argument about PTIME and FO(LFP).
Does this not qualify?
http://michaelnielsen.org/polymath1/index.php?title=Lindell%27s_Critique
Or does the latest draft patch it? Looks like more than a band-aid will be needed.
About Russell’s Impagliazzo comment on well spent time: unlike computers, human beings use critical sense before deciding whether to spent time on ‘important matters’ or not. I believe we can trust top mathematicians and scientists to know how to spent their time in a pretty productive manner. They don’t need ‘external’ management and direction on this matter.
Fact is, many people are intrigued by the P=NP issue and the amount of reaction on the web proves there are many people reading about it, and even working on it, if not in their spare time.
Fact is, there are multiple papers claiming to have solved this issue. Many do fail for reasons which have been stated again and again. Many do fail because they take shortcuts or do not address well-know concerns about proof methods. It is obvious that using valuable resources to check those papers and communicate about the same issues again and again is not optimal.
30 years ago, we did not have the Internet. The latest research papers and information was available only in specialized publications. Today, we have the possibility to make this information that available to a wide audience at extremely low cost. This could be organized by savvy people in the field.
I love rjlipton’s intention in his introduction. Vinay Deolalikar may have been careless in stating that P=PN is solved, but there is no reason to stigmatize him. As of today, we don’t know for sure whether his paper may or may not be fixable, or whether it only requires clarifications.
Globally speaking, we should not ignore the power of big numbers. If people want to work on P=NP, we should only welcome this. We don’t know whether this question will be solved by a mainstream mathematician or a maverick amateur. We just don’t and we can’t predict what will happen.
If centralized information about failed attempts was made available on the Internet, we can reasonably trust that all candidates will read it, rather than taking the risk of being proved wrong publicly. It will only help them improve the quality of their contribution, which is what we are all interest in.
“30 years ago, we did not have the Internet. The latest research papers and information was available only in specialized publications. Today, we have the possibility to make this information that available to a wide audience at extremely low cost. This could be organized by savvy people in the field.”
The process of how this proof has been put into the public view is fascinating on its own. It’s a social science experiment on its own!
P.S. The problem with the availability of this information is that every news blog & outlet has blindly picked up the “P=NP may be finally solved! Researcher will get $1M!” sensational headline before the paper has even been read by others.
My comments:
1. Vinay’s paper is not a serious attempt at a solution of P vs NP. The reason is that it is not written in a clear mathematical or rigorous format. Therefore, it has no specific, or at least (approximate) specific meaning. For instance, if I state a lemma, and it’s proof is written in plain English, with most of the sentences ambiguous, and hence undefined, then what I wrote is not a proof. The measure of ambiguity is of course relevant here, and it is a fuzzy measure. But Vinay’s paper seems below the accepted threshold (as evident by lengthy discussions containing questions like “what does he precisely mean in this or that paragraph” and so forth). In this view, the paper does not even contain a proof.
2. That said, it is not unavoidable that some ideas related to Vinay’s paper will be found successful in resolving some problems. But this has not a lot to do with the content of Vinay’s paper in itself, rather with the efforts of many others trying to think about this ideas. In other words, this would be true if we substitute Vinay’s paper by any other paper out there claiming to have proved P vs NP.
To sum it up, I would say that Vinay’s paper is not a serious attempt, but the interest and happening surrounding it are not necessarily bad things for several reasons, both scientific and meta-scientific.
Deolalikar’s is a fascinating paper illuminating a lot of interesting areas of complexity, physics, and statistics. I hope it’s proven right.
Can anyone shed some light on the use of the Gaifman Locality Theorem (GLT)?
Martin Grohe and Stefan Wohrle sum it up as: “Gaifman’s locality theorem [12] states that every first-order sentence is equivalent to a Boolean combination of sentences saying: There exist elements a_1, …, a_k that are far apart from one another, and each a_i satisfies some local condition described by a first-order formula whose quantifiers only range over a fixed-size neighborhood of an element of a structure.” [An existential locality theorem, 2004]
It seems that if every element in the successor graph is a boolean variable of the k-SAT instance, then surely the value of that variable cannot solely be dependent on just a small neighborhood of that element, since one could presumably find examples where flipping a far-away bit could in some cases require another solution that is indistinguishable by such a small neighborhood.
If >8-SAT features such long-range dependency, assuming the ordering is proper and k-XORSAT can be differentiated…
Could one even amend the problem so that the elements are pre-ordered in the most devious way possible, ensuring long-range effects? I’m sure I’ve misunderstood how the paper constructs its structure, but it seems intuitively GLT is a very good attack…
I think his use of GLT is indeed problematic. The author at some point
changes the context from FO+LFP where the relation P in the LFP can be of arbitrary arity to FO+LFP where the relation P is monadic. Indeed, you cannot apply Gaifman locality with FO+LFP, but the problem is no more if the LFP is monadic. However to have a monadic LFP, he has to change his structure from singletons to k-tuples, BUT this changes the Gaifman graph a lot (it becomes of diameter at most 2) so that you cannot apply Gaifman locality usefully anymore.
Said otherwise, I would not be surprised if the entire argumentation of this paper could be conducted from ESO rather than FO+LFP (which quickly become EMSO once we handle the k-tuples, and thus you can somehow use Gaifman locality) and thus prove that SAT is not in NP…
After reading your instructive reply and the comments of Terence Tao, Albert Atserias, Steven Lindell, and many others including the wiki, it seems applying GLT is indeed a complex issue.
Being as I’m clueless, I of course wouldn’t know if GLT is a good attack or not in this particular application, but it certainly is an interesting approach.
I don’t know if it helps to avoid the potential opaqueness of LFP by considering only iterated quantifier blocks in addition to the logics you listed:
“P is also equal to the set of boolean queries expressible by a quantifier block iterated polynomially many times. … P = FO(LFP) = FO[n^{O(1)}] = SO-Horn.”
[http://www.cs.umass.edu/~immerman/descriptive_complexity.html]
But I assume that is kind of implicit…?
Thank you for the pointers to ESO and MSO. I need to understand those better.
I think there are several levels to the basic question “Is the proof correct?”:
1. Does Deolalikar’s proof, after only minor changes, give a proof that P != NP?
2. Does Deolalikar’s proof, after major changes, give a proof that P != NP?
3. Does the general proof strategy of Deolalikar (exploiting independence properties in random k-SAT or similar structures) have any hope at all of establishing non-trivial complexity separation results?
After all the collective efforts seen here and elsewhere, it now appears (though it is perhaps still not absolutely definitive) that the answer to #1 is “No” (as seen for instance in the issues documented in the wiki), and the best answer to #2 we currently have is “Probably not, unless substantial new ideas are added”. But I think the question #3 is still not completely resolved, and still worth pursuing (though not at the hectic internet speed of the last few days). It seems clear that one has to maneuvre extremely carefully to pursue this approach without triggering (in spirit, at least) the natural proofs obstruction, and one has to do something clever, non-trivial, and essential to separate k-SAT from things like k-XORSAT. So it is now clear that one should be quite skeptical of this approach a priori. But it would still be good to have an explicit explanation of this skepticism, and in particular why there could not conceivably be some independence-like property of random k-SAT that distinguishes it from simpler random structures, and which could be incompatible with P. I think we are getting close to such an explanation but it is not quite there yet.
If nothing else, this whole experience has highlighted a “philosophical” barrier to P != NP which is distinct from the three “hard” barriers of relativisation, natural proofs, and algebraisation, namely the difficulty in using average-case (or “global”) behaviour to separate worst-case complexity, due to the existence of basic problems (e.g. k-SAT and k-XORSAT) which are expected to have similar average case behaviour in many ways, but completely different worst case behaviour. (I guess this difficulty was well known to the experts, but it is probably good to make it more explicit.)
p.s. Regardless of how significant or useful Deolalikar’s proof is (and how much of a “waste of time” it would be for so many people to be looking at it), it has provided a rare opportunity to gather a surprisingly large number of experts to have an extremely high quality conversation around P != NP. One may have strong feelings about the specific circumstances that created this opportunity, but I do not think that that should be cause to squander the opportunity altogether.
Good comment, I agree.
Completely agree.
And I should add, in reference to Russell’s comment that we are all adults here and we all make our own decisions about where we want to spend our time.
People like you Terry or Timothy Gowers, whose respective great achievements and distinguished records are there for all to see, should not be lectured by anybody, certainly not by Russell, about what you guys decide to get interested in.
Actually, I respect Russell’s own substantial achievements greatly, and do not think that there has been much lecturing going on at all around here. If the sole purpose of this exercise was to verify the manuscript, I would in fact completely agree with Russell’s opinion (and the opinion of many other complexity theorists that I trust) at this point. My point though is that now that we are all here, there are opportunities to do other things beyond mere verification.
Concerning question 3, my feeling is that the general proof strategy will
not work as it relies on locality properties of a fragment of LFP (Monadic LFP)
that is not shared by all of LFP. For analogy, it’s as if he wanted to prove
P != NP by first showing DTIME(n) != NP by getting structural results on
linear-time algorithms, and then trying to reduce all of P to DTIME(n) while
preserving the same properties. The point is that the standard reduction to the
fragment in question (the “tupling” issue, as it’s been called) is known to not
preserve the locality properties he needs and the write-up does not provide any
alternative way of making the reduction in such a way that locality is preserved.
But again, all this is from the feeling one can get from reading an imprecise
statement of the strategy as it is presented in the paper, so I could be shown
wrong.
“…due to the existence of basic problems (e.g. k-SAT and k-XORSAT) which are expected to have similar average case behaviour in many ways, but completely different worst case behaviour.”
I am not sure what this means. A) There are questions regarding the probability of a random formula to be satisfied; B) there are questions about the expected behavior or worse case behavior of certain specific algorithms, and C) there is the issue of expected behavior or worst case behavior of the best possible algorithm.
I dont think k-SAT and k-XORSAT behave similarly wrt average case behavior of best possible algorithm, are they?
I always thought that statistical questions that we can study about k-SAT and related problems, while very exciting, only refer to specific algorithms; somehow we need an additional ingredients to be able to discuss arbitrary algorithms and in this additional ingredients we better separate k-SAT from easy problems.
The plan for showing that no algorithm will behave well is not clear to me, even on a very vague level. But maybe this was already explained in the discussion and I missed it.
Sorry, “average case” was perhaps a poor choice of words. I meant to refer to the global structure of the solution space (e.g. the size, shape, and separation of clusters, etc.)
If nothing else, this whole experience has highlighted a “philosophical” barrier to P != NP which is distinct from the three “hard” barriers of relativisation, natural proofs, and algebraisation, namely the difficulty in using average-case (or “global”) behaviour to separate worst-case complexity, due to the existence of basic problems (e.g. k-SAT and k-XORSAT) which are expected to have similar average case behaviour in many ways, but completely different worst case behaviour. (I guess this difficulty was well known to the experts, but it is probably good to make it more explicit.)
This is basically my objection in the wiki: http://bit.ly/aXPMWl
Admittedly, what I wrote there is merely “philosophical”, but again the point is that a strange solution space is neither necessary nor sufficient for NP-hardness.
It is a great idea to try to formally define this barrier and develop its properties. I think the “not necessary” part is pretty well-understood, thanks to Valiant-Vazirani. But the “not sufficient” part, the part relevant to the current paper under discussion, still needs some more rigor behind it. As I related to Lenka Zdeborova, it is easy to construct, for every n, a 2-CNF formula on n variables which has many “clusters” of solutions, where each cluster has large hamming distance from each other, and within the cluster there are a lot of satisfying assignments. But one would like to say something stronger, e.g. “for any 3-CNF formula with solution space S, that space S can be very closely simulated by the solution space S’ for some CSP instance variables that is polytime solvable”.
P.S. I have no idea why the word “variables” appears in the last sentence
I too am in favor of a more rigorous proof using a sequence of mathematical lemmas leading to the result. This would allow us to prove or disprove each lemma. Even if the end result falls short by a few lemmas, we will still have gained those lemmas which we have proved.
Related to the comments by Gil Kalai and Cristopher Moore above, consider the following “problem”: Given n/2 mod-2 linear homogeneous equations for n binary variables, decide if a nontrivial solution exists.
Of course, a nontrivial solution always exists (the null space has dimension at least n/2); so for this problem the trivial algorithm that just always returns “yes” works. Yet, when these equations are random, solutions have the minimum distance at least 1/10n with high probability (this being just a random linear binary code), ie, the solution space splits up into 2^Omega(n) clusters, each with n frozen variables, and with Omega(n) distance with high probability.
What’s the difference between this vs random k-SAT that the proof is exploiting? The trivial algorithm above has the simplest possible complexity.
One issue in your objection that I can see is that to get a random linear binary code with clustering and frozen variable properties that you suggest, I believe the random mod-2 linear equations needs to chosen uniformly from all possible such equations, meaning that they will have roughly n/2 variables per equation or “constraint” on average.
Deolalikar, I believe, represents each constraint — a clause since he is working with k-SAT — by encoding the one truth assignment that the constraint violates. To represent k-XORSAT constraints like so, you would need to represent the 2^{k-1} violated truth assignments. Now, this should not be a problem when k is a fixed constant. But in your case, if each XOR constraint (i.e., a mod-2 linear equation) has roughly n/2 variables, this basic representation itself becomes exponential. In other words, something in the proof would need to change in order to apply it to your setting.
Even random 3-XORSAT formulas have whp O(n) Hamming distances between their codewords if you condition on every variable appearing in at least two clauses — and the 2-core of a random formula has this kind of randomness. So k-XORSAT for constant k >= 3 already has the properties we’ve been referring to.
Also, a micropoint to a previous comment: XORSAT allows variables to be negated, so just saying “yes, set all variables to zero” is not generally correct.
Even someone like me who thinks it is a historical accident that this particular mathematical question became synonymous with ‘theory’ in CS (every tribe needs a flag/religion), cannot but observe with delight the scholarly discussion triggered by the paper, showing that the medium can be used not only for twitting/distracting/selling. Romanticismn is back!
At the meta-level it will be particularly frustrating/amusing if it turns out that a major problem in CS is solved using physicists ideas – the revenge of the dead 😉
Let me chime in about watching this experience, speaking from the point of view of the guy who was the NSF program director for Theoretical Computer Science back 8-9 years ago. Let’s say, strictly for the sake of argument, that the answer to Terence’s Question 3 is yes, and that a year from today some result smaller than a Clay Prize result but still meaningful has come out of this work.
What a great story for the program director for this area to give to the new AD of NSF, and for him or her in turn to feed to Congressional staffers and to the news media–from the very start, this community could pull in a bunch of its best people to work collaboratively, in the dog days of summer vacation time, and they wound up Pushing Science Forward (Pooh Caps Intended), and, oh yes, they also on the side drew in at least two world-class superstar mathematicians not directly part of the smaller TCS community who also volunteered take part in the work.
If it comes out that way, then TCS will have a great “good news” story about how research can be done in the 2010s.
I see less cause for optimism. The author worked for several years in stealth mode because he felt it was too dangerous to publish what he was doing until he had something sufficiently close to a complete proof, which likely resulted in substantial wasted effort. The community, meanwhile, seems to have been pulled together more to make sure that the proof is wrong that to check that it is right; if a weaker result is salvaged, we got lucky. This is hardly a model of what we want collaborative research to be. The existing academic incentive structure is just a huge barrier to truly collaborative community work.
The good news is that there is substantial potential synergy primed for exploitation, if the right incentives can be found. (Unfortunately, the prizes, both monetary and non, that accompany a big problem like P=NP probably do more harm than good.) This is perhaps where we need new ideas. For example, what if the NSF promised a big pot of funding for TCS if the community can solve P=NP (or some other big problem) by some date, and there was some post-facto community process (not publication) used to apportion credit to individuals?
Regarding Suggestion Two (i.e., using ideas proposed by Deolalilkar to prove a weaker result, NL != NP), it seems to me that this “simpler” result is entangled with the unresolved k-SAT vs. k-XORSAT issue in a way that makes it even more implausible, in the following sense:
If the fragment of FO(LFP) logic used in the proposed proof is “fixed” to capture NL (rather than P) and the proposed logic construction goes through for k-XORSAT as it seems it might, then we would be proving that no algorithm in NL can solve k-XORSAT in the hard region, i.e., NL != P. This certainly seems quite unlikely to me at this point.
If this is correct, on a meta-level, it suggests that Suggestion Two can only help simplify matters if we first resolve the XORSAT issue satisfactorily.
Yes of course, that’s an excellent point about how the issues can interact.
I do believe the author has thought things through enough to have a good answer on the XOR-SAT issue. We lack, however, a clear combinatorial statement of structures that result from Deolalikar’s formulations. One general point is that the paper uses verbs and the language of processes (symmetry-breaking, phase transitions…) where we’d rather see nouns.
My own expectation is that what the author provides will naturally yield a non-uniform would-be hardness predicate, which however will either fail to head off the objections, or will run into “Natural Proofs” trouble—perhaps from closeness to notions of distributional hardness that have already been found wanting. Yesterday I tried to supply a simple one based on his ideas as a strawman to focus the objections on some concrete target, but it looked like failing for reasons other than the ones intended.
On that note, here’s a question I was holding for the TCS Q&A site, but, since that site still hasn’t gotten to Beta, and since my question was inspired by the discussion around the Dealolikar paper, maybe I should ask it here.
Could someone please provide a Physics-of-SAT for Dummies explanation of (1) clustering, (2) condensation, (3) freezing?
I’d be happy to post this question elsewhere, if it’s not appropriate here.
To clarify, I posted because of: “My point though is that now that we are all here, there are opportunities to do other things beyond mere verification.”
Dimitri Achlioptas provided a nice summary on the wiki – look at the subpage on random k-SAT.
I’m just catching up with this discussion, having had a chance to look at the paper yesterday and today. I see that others have seen some of the flaws that I can see in the argument. I think the argument going from an LFP formula to graphical models with conditional independence is highly dubious. It is hard to say it’s wrong, because it is not clearly enough formulated to point to a specific error.
Albert above has already pointed out the problem that coding a high-arity fixed point as a monadic by considering the tuple-structure leads to a trivial Gaifman graph.
Another problem I see is the order-invariance. Deolalikar (after justifying the inclusion of the successor relation R_E) that *each stage* of any LFP formula defining k-SAT would be order-invariant. While it is clearly true that the LFP formula itself would be order-invariant, this does not mean that each stage would.
So, it seems to me that this proof shows (at best) that k-SAT is not definable by an LFP each stage of which is order-invariant. This has an easy direct proof. Moreover, it is also provable that XOR-SAT (or indeed parity) is not LFP-definable in this sense.
There is a nice and lengthy post by Steven Lindell on the “A proof that P is not equal to NP?” page here regarding the k-ary vs Gaifman that confirms these doubts.
http://rjlipton.wordpress.com/2010/08/08/a-proof-that-p-is-not-equal-to-np/#comment-4898
So, Tao’s remarks may mark the definitive judgment here on the proof: not easily fixable and probably not fixable with great effort, but maybe he made a breaktrhough in his innovative combination of tools and approaches that drew the attention of so many people. I am not able to judge myself if the proof is correct or not, but it certainly does seem that a lot of serious doubts have been raised about whether he really characterized P sufficiently fully before proceeding to the main argument, and, although Chris Moore shifted in this thread to the Gaussian elimination argument, his pointing out of the apparent confusion over clustering versus freezing at the ultimate stage struck me as pretty serious, although perhaps that is fixable.
In any case, I would like to applaud Deolalikar for his particular combining of approaches. Maybe this will not lead to substantial theorems as Tao suggests might be the case, but I think it will stimulate new research in a variety of related areas that use complexity theory, model theory, as well as statisical physics, including such areas as econophysics and in other fields.
I want to take the opportunity to congratulate the CS and math community for showing on this blog that it is able to conduct an overall intelligent and polite public discussion about the P vs NP problem.
In the past, I’ve seen such conversations on the web quickly turn into insults and flame wars, but not here on this blog. I hope that this will be the future of scientific discussions on the web.
This blog is truly outstanding for the service it renders to the community. I think while we are at it waiting to see whether we may have significant learning from Deolalikar’s approach, we should also set these basic questions (for sanity) that must be answered precisely (that should pass the elevator pitch test) before we pay so much attention to any such future proof. Of course, I would surely like to add the structure that Impagliazzo prefers, though I agree that may not be necessary.
Could anybody tell me if these phase transitions (d1RSB, etc.) proved to happen or just measured by theoretical physicists?
in XORSAT, everything is rigorous, and clustering/freezing threshold is known exactly. See Monasson, and Dubois & Mandler.
In k-SAT there are rigorous results for k >= 8, and the asymptotic scaling of the clustering and freezing transitions with k is roughly the same. There are results for k-coloring as well. See Achlioptas for SAT.
Note that there is another strand of the literature involving the “tree reconstruction problem” which places lower bounds on the clustering transition: see Montanari, Sly, Vigoda, Bhatanagar etc.
“Measured” isn’t the right term for the physics work: it’s not just numerical experiments, but a detailed analytic approach which is backed up by experiments. For good explanations of the various transitions from the physics point of view see Zdeborova, Krzakala, Montanary, Mezard.
Many thanks for these references!
sorry, I mean Achlioptas and {Ricci-Tersenghi, Coja-Oghlan}.
Thanks for this ref defining differences between recursiveness and measurements of physics which show how things actually work
in practice I may be coming round to a different perspective;time and analysis is a priori for all involved thats clear.
Sorry for the stupid question, where can I find the wiki mentioned in Suresh’s and Terence’s posts?
http://michaelnielsen.org/polymath1/index.php?title=Deolalikar_P_vs_NP_paper
Shukran! (I think you understand ;))
Vinay has posted a new version on HPL website.
I say, we must appreciate Clint Eastwood’s contribution on the matter “Don’t just do something, stand there” – where’s the wiki? that should be a good place to ‘stand there’ 🙂
Dick, kudos for the good humor, you should publish a CS book with some of the humor alive.
Cris Moore’s upcoming book is a fine example: http://www.nature-of-computation.org/
Answer to my own question: the wiki is here: http://michaelnielsen.org/polymath1/index.php?title=Deolalikar%27s_P!%3DNP_paper
Or was it perhaps someone else’s contribution:
“Online I find references to Jesus, God, Buddha, Peter Ustinov, Tom Servo/ Mystery Science Theater 3000, the White Rabbit, Forest Whitaker, and Ronald Reagan. It’s hard to know who was first but I’m inclined to give special mentions to the ‘Alice in Wonderland’ movie references.”
http://answers.google.com/answers/threadview/id/186295.html
Humour is a good thing thanks for it always on this site. The idea of personifying wisdom like an express train heading for us (polylog fasterthan solutionspace)is rather amusing I suggest. V DEOL.the train driver?? Animists in the film world report immediately…..
PS I mean animation-experts.
Deolalikar has a new version of his paper up which includes a new 3. chapter,
“Distributions with poly(log n)-Parametrization”
There is an updated version of the alleged proof, dated 2010-11-08: http://www.hpl.hp.com/personal/Vinay_Deolalikar/Papers/pnp_8_11.pdf
PS: thanks for this blog and all those who are commentating – it is extremely interesting for outsiders to follow the discussion!
Page 38 of that draft relates communication (directly?) with Leonid Levin and Avi Wigderson, and refers to a manuscript “[Deo10]” under preparation.
This new draft seems to be improved, and it appears that a clear statement (possibly falsifiable) can be figured out from it. Also, note that what was section 4.3 (much criticized for apparent flaws) is now removed.
In the added section, there is crucial point which explains his main strategy:
“[ample] distributions take the typical number of joint values.
Definition 3.2. A distribution on n variates will be said to have irreducible O(n)
correlations if there exist correlations between O(n) variates that do not permit
factorization into smaller scopes through conditional independencies.
It is distributions that possess both these properties that are problematic for
polynomial time algorithms. We will see that distributions constructed by polynomial
time algorithms can have one or the other property, but not both.”
In section 8 there is explanation how distributions are generated:
“Now we “initialize” our structure with different partial assignments and
ask the LFP to compute complete assignments when they exist. If the partial
assignment cannot be extended, we simply abort that particular attempt and
carry on with other partial assignments until we generate enough solutions. By
“enough” we mean rising exponentially with the underlying problem size. In
this way we get a distribution of solutions that is exponentially numerous, and
we now analyze it and compare it to the one that arises in the d1RSB phase of
random k-SAT.”
So, as far as I understand, he defines two properties:
(1) A set of probability distributions is ample, if it requires exponential number of parameters to define.
(2) A probability distribution is irreducible if “there exist correlations between O(n) variates that do not permit factorization into smaller scopes through conditional independencies.”
Then he generates distribution of solutions for each instance of k-SAT problem by (uniform?) partial assignment which he extends by (if P=NP) polynomial algorithm.
This is a bit confusing. I am not sure if my reading is correct. The property 2 is a property of a single distribution of solutions (corresponding to a single instance of a k-SAT). The property 1 appears to be a property of a family of distributions.
Yet obviously if each distribution corresponds to a k-SAT problem, so presumably there are n parameters that specify the distribution. If anyone understands what he means by (1), please explain.
Sorry, I missed, section 4.3 is still present (as section that is still there).
It would be very helpful if the statement can be extracted to the following extent: Polynomial algorithms cannot generate such and such family of distributions (and make this statement precise). Then we can understand the k-XORSAT (and other restricted CSP) objection and figure out what he means and weather we have a counterexample.
But the precision level of the manuscript is far from satisfying. There is a lot of handwaving, which makes it difficult to understand paper and formulate objections/analyze possible flaws in the argument.
“the precision level of the manuscript”
Just thinking out loud here, but the original mail said “In the presentation of this paper, it was my intention to provide the reader with an understanding of the global framework for this proof. Technical and computational details within chapters were minimized as much as possible.” and a quick look at his arXiv papers seem to indicate that he can be very precise if he wants to, so apparently this paper is written this way for a reason…
“so apparently this paper is written this way for a reason…”
Good point
Here we go…
http://www.jmilne.org/math/tips.html
“Here we go…”
Can you think of a reason that doesn’t assume bad faith?
I tried to write in the wiki what are the diff between the version 2+epsilon and 3
http://michaelnielsen.org/polymath1/index.php?title=Update#Change_betwen_2.2B.26epsilon_and_draft_3
He added and changed big paragraph (and also a new section), but what I think may be more interesting (and harder to find if one don’t take time to use “diff” to check exactly) is the few word that changed. Like some “monadic” who appeared in the text.
I hope this may be usefull for some people. And once again I do not promise that I did not miss anything.
Breathtaking! I hope Vinay has addressed some of the concerns…
This blog is becoming once of the most entertaining and exciting reading I remember in recent past 🙂
Vinay Deolalikar, in his last update to his home page, writes: “Please note that the final version of the paper is under preparation and will be submitted to journal review”.
In your opinion, can a paper like this really be subject to a standard refereeing process, especially considering the ongoing online discussion? How did the refereeing process go on for other high-profile results in the past?
The exact paragraph:
“This short section owes its existence to Leonid Levin and Avi Wigderson,
both of whom asked us whether our methods could be used to make statements
about average case complexity. We will return to this issue in future versions of
this paper or in the manuscript [Deo10] which is under preparation”.
Average-case entry in scene. These are big names and this confirms that Mr Deolalikar is still claiming the proof and working on it. We all hope that the new manuscript is the simplified one.
Where Deo10 has the working title “A distribution centric approach to constraint satisfaction problems.” Also note that the HP home page has been updated, and now explicitly states that the final version of the P≠NP paper will be submitted to journal review.
Eh, meant to write *his* HP homepage.
Question about parametrization:
He speaks about parametrizations of distributions that require some number of parameters. But what does he mean?
Apparently, number of parameters is function of a single distribution (not family of distributions?) since he says that there is high probability that number of required parameters will be exponential (beginning of new section 3).
So, what is this number of parameters? Given a distribution on a probability space of size 2^n (consisting of all 1-0 vectors (x_1,… x_n), how do I compute number of parameters that he talks about.
It makes more sense if there is family of distribution involved, but then he possibly means that parametrization is of some special form.
If anyone can help with this, please explain, since this seems to be crucial point in his argument, and also a way to analyze his paper/search for clear(=falsifiable) statements.
On the k-XORSAT issue, I’m pondering about the following: why can’t k-XORSAT as well as the other tractable special cases identified in Schaefer’s Dichotomy Theorem just be “identified and special-cased”? The machinery of D’s proof could then be applied to the remaining instances that are known to be NP-hard by the same theorem. Wouldn’t this lead to a separation of P != CSP \subseteq NP? (assuming the other raised objections against D’s proof can be settled)
Unique k-sat is also NP-Complete for n>=3. However, a solution space consisting of only one solution is easily parametrized with a small number of parameters, and the Hamming distance between solutions disappears.
It strikes me that if one re-reads the paper, mentally applying the arguments to random unique k-sat, instead of random k-sat, the things lacking in the approach become glaringly apparent.
The set of tools employed is not of sufficient expressive power to resolve the question being asked.
Note that this is under *randomized* polynomial-time reductions. Nevertheless, assuming P=BPP, what you’re saying is true. That is, all NP problems are polynomial time equivalent to a problem with “simple” solution space. This suggests that his “complexity measure” cannot distinguish between P and NP.
This is I think one of the big red flags about the given approach.
Btw, this was first pointed out by Ryan Williams, I believe.
It almost seems to me like this already invalidates the proof. From a high-level point of view, his proof constructs a property T such that any language in P has property T. To separate P from NP he therefore needs that *no* NP-complete problem has property T. But assuming P=BPP, there is an NP-complete problem that does not satisfy property T.
Of course, you can try to show P\ne NP by arguing P\ne BPP, but it seems very unlikely that this is what is happening in his paper. Probably, you can find a heuristic argument why the proof strategy fails without assuming P=BPP. Any thoughts, anyone?
Mike, regarding your statement “It almost seems to me like this already invalidates the proof”:
As has been pointed out earlier in this blog (yesterday I believe) that there is no direct contradiction because of UniqueSat, even if we ignore the randomized reduction issue. The proposed proof argues that any problem captured by FO(LFP) must have a “simple” solution space structure. This (whether correct or not) does not imply that every problem with a “simple” solution space structure can be captured by FO(LFP). In other words, simplicity of the solution space is argued to be a necessary condition to be in FO(LFP), not a sufficient condition. So UniqueSat doesn’t directly invalidate the proof.
The issue, if any, is more philosophical and at a meta-level — that the proposed technique relies on a property of solution spaces that seems neither necessary nor sufficient to make a problem NP-complete. Can that ever work? In principle, yes; but perhaps not so likely.
UniqueSat is not just some arbitrary solution space that fails to be captured by FO(LFP), it is a proper subset of Sat, into which Sat has a polynomial reduction.
So we have an argument about Sat which it is claimed separates P and NP, but we can inject Sat into a proper subset of itself to which that argument fails to apply.
This is at the very least worrisome.
Deolalikar’s attempt to address the XORSAT issue in his latest update puzzles me. He states in section 3.1.2, Value Limited Interactions, “Take the case of clustering in XORSAT, for instance. We only need note that the linear nature of XORSAT solution spaces mean there is a poly(log n)-parametrization (the basis provides this for linear spaces). The core issue is that of the number of independent parameters it takes to specify the distribution of the entire space of solutions.”
This argument, presumably “taking care of” XORSAT, relies on our knowledge that XORSAT captures a linear space which can be succinctly represented by, for example, a basis for that space. But what if we lived in a pre-linear-algebra and pre-Gaussian-elimination world? He should still be able to argue, in that low-knowledge-level world, that XORSAT solution spaces admit a poly(log n)-parameterization — otherwise he would have incorrectly proven, in that world, that XORSAT is not in P.
Put another way, if SAT was in fact in P and we knew of a succinct structure for SAT akin to linear spaces for XORSAT, wouldn’t his new argument make his proof not apply to SAT either? (That’s, of course, not good, as what a mathematical proof shows should not depend on our knowledge or lack of knowledge of some aspect of the truth.)
I agree, that’s the key question. For XORSAT, there is a polynomial-time algorithm which takes an XORSAT formula and a string of O(n) random bits, and generates a random satisfying assignment. This works even in the clustered phase, where we can start by choosing a random cluster.
We all believe that there is no such polynomial-time sampling algorithm for k-SAT. But this is what we are trying to prove…
Yes, I agree that this is not directly addressing the XORSAT issue. Basically, what we have here is the following two assertions:
1. The lengthy argument in Deolalikar’s paper shows that k-SAT does not have a short parameterisation.
2. An easy argument shows that k-XORSAT has a short parameterisation.
But what we do not yet have is the proximate cause as to why the claim 1 cannot be perturbed to
1′. The lengthy argument in Deolalikar’s paper shows that k-XORSAT does not have a short parameterisation
which of course would contradict 2. In short: what is the first specific step in this part of the paper which works for k-SAT but not for k-XORSAT?
This is super defining probs.Like cold calculating sniper org at main issues in the battle area.Thanks
“The core issue is that of the number of independent parameters it takes to specify the distribution of the entire space of solutions.”
What exactly does he mean by number of parameters/parametrization?
The number of parameters needed to specify instance of k-SAT is the same as number of parameters needed to specify k-XORSAT and it is size of a problem, n. This then determines the solution space (though not necessarily in an easy way). So the answer is parametrized by a question.
This is unless he considers parametrizations of some special form. How can one, given a family of distributions determine number of parameters that he speaks of?
vloodin is dead-on. Unless we can get a clear definition of what a phrase like “2^{poly(log n)} parameters” is supposed to mean, we are only going in circles. I fail to understand how the solution space to a problem instance described in n bits could require “2^{poly(log n)} parameters” to describe, for any reasonable definition of “parameter”. (This is what is claimed now for k-SAT, when k is large enough.)
“how the solution space to a problem instance described in n bits could require “2^{poly(log n)} parameters”
you probably meant 2^n.
Yes, exactly – why is k-SAT needing 2^n parameters. Every instance of k-SAT is specified by size of the problem parameters, which is n (or, if n is number of variables, when his alpha is fixed, of that order, certainly O(2^poly(log(n))).
For k-XORSAT he says that solutions allow easy parametrization – by basis of space of solutions. All is well, this parametrization is easy, but nontrivial. How is that so different from parametrizing k-SAT with the question. Note that basis parametrization of k-XORSAT is not very different (in information content), from parametrizing with the question – solutions to a linear system (over Z/2Z) Ax=b is parametrized with (A,b) no worse than with a basis of solutions.
Perhaps the number of parameters is not a function of family of distributions, but of a single distribution (some places in the paper suggest this interpretation). But the question remains: how is that number determined, given a single distribution (over a probability space of size 2^n of all n-bit words of lenght n, (x_1…x_n))
Re. Immerman’s 1986 proof that FO(LFP) captures P:
Can someone please check again whether his proof is correct? I think his proof is incorrect, incomplete.
There is an error at the end of Immerman’s proof, as I have explained here:
http://rjlipton.wordpress.com/2010/08/08/a-proof-that-p-is-not-equal-to-np/#comment-4818
If there is a bug in Immerman’s proof, then Vinay’s proof will not stand either.
I seriously suggest getting rid of the P~NP problem from the million-prize mathematical problem list.
First of all, it is not even a mathematical problem, it is a computer science problem.
Secondly, this problem is very dry.
It is time the blogs take a break and give time to Mr Deolalikar to construct and provide a response to the suggestions, bugs, objections, etc. As I understand, he is still working full time for HP, and needs all the time to work on the proof. Blogs have brought together TCS community and crafted a coherent response to the proof and done the job. The bet, and additional discussion will be a lot pf pressure on him to respond quickly. The blogs need to set an expectation of the time line of his response and take a break to re-convene later.
HALLELULA working brother
Such proof would have to cover all classes of approaches … like continuous global optimization.
For example in 3SAT problem we have to valuate variables to fulfill all alternatives of triples of these variables or their negations – look that
(x OR y) can be changed into optimizing
((x-1)^2+y^2)((x-1)^2+(y-1)^2)(x^2+(y-1)^2)
and analogously seven terms for alternative of three variables. Finding global minimum of sum of such polynomials for all terms, would solve our problem. (from www .scienceforums.net/topic/49246-four-dimensional-understanding-of-quantum-computers/ )
It’s going out of standard combinatorial techniques to continuous world using gradient methods, local minims removing methods, evolutionary algorithms … it’s completely different realm: numerical analysis.
Such proof could work on concrete valuations, but here we work between them.
Does/can it cover also continuous approaches?
About the suggestion to “use wiki technology to handle the serious public discussion needed to understand the proof”:
It could have been nice to see Wave used for such a discussion just a few week before it is shut down by Google. I know no other technology that can so smoothly accommodate the whole variety of communication modes from wiki to asynchronous discussions (forum or talkback-like) to synchronous discussion (chat-like, though tree structured instead of linear, so chat can easily transform into wiki when it’s ready. Just counting the number of copy-pasted parts of posts here shows the advantage of being able to reply inline). And of course there’s plenty of math support there through gadgets (it’s a sad fact that math is not recognized as a language that must be supported as part of “internationalization”). Though I doubt if Google’s current implementation (that they ar planning to close in the near future) could handle the load.
Remove spyware detection software works by the computer for infection by malicious software. The software looks for malware that are already installed on your computer. After scanning is complete, and detection, the software displays a report found the number of malicious software and was removed from the system.
There are a number of mining software available. Before choosing a program, it is important to read the comments on the first application. Do not read the comments from unknown Web sites, since the main objective of these reviews is to mislead the consumer to purchase non-compliant. Instead of knowing what the renowned experts in the market, as they tell the PC magazines.
I really, really, REALLY want Deolalikar’s proof to be wrong, because I badly want P=NP,
as much as I would feel bad for Deolalkar. Think of all the practical scientific problems we could tackle if P=NP. I couldn’t care less about those cryptographists who want P!=NP. We need P=NP to help do things that actually HELP people and non-humans, not just make life a greater police state with all this cryptography crap.
I am not a specialist in complexity theory. I have and never had an interest in proving P!=NP or P=NP, although I DO desperately need the money! I found a happy tiny niche in the sub-sub-subfield of differential algebra known as differential resolvents in which to write my PhD dissertation and subsequently publish in peer-reviewed journals.
There is stillsomething to be said for attacking specific Hardness probs. the case recalled here is the famous Heesh Number Query. All you have got to do is decide on the Algor
for a tile-shape which explains the maximum bounds ie envelope repeats possible of a geometric arrangement The known limit plus 1 to ident a new corona level is also capable of addressing Dimensional problems as well apparently. Tough enough to wonder about.