The P≠NP “Proof” Is One Week Old
Another update on progress understanding the proof of Deolalikar

Terence Tao is leading, as often is the case, with some very insightful comments on the status of Vinay Deolalikar’s proof.
Today Ken Regan and I want to try to summarize the main issues with Deolalikar’s proof of P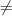
We intend to give a short summary of where the proof stands and outline what will happen next. A side-effect is this will help “refresh” a comment thread growing past 250 entries on our last post. We hope that a constructive discussion can continue here and on other blogs, as the proof strategy is finally understood by the community. We do believe that beyond the claimed proof there has been much interesting discussion on a host of topics, and we think this discussion has been informative.
We are still hopeful that the promised final release of the “journal paper” by Deolalikar for peer review will be able to answer all the questions raised here and elsewhere. We wish Deolalikar good luck—we hope in a small way we have been able to help him, if indeed he is successful in either releasing a correct proof or deriving some rigorous lesser results from it.
The Two Main Issues
In our opinion there are two parts of the proof, each of which contains difficult issues. Perhaps these issues can be resolved, but the consensus right now seems to be these issues will be hard to avoid.



The First Order Issue
This issue seems to us to be potentially fatal. Recall Neil Immerman pointed out that the proof mis-uses FO(LFP)—and the consequence of this mis-use is that the complexity class studied is not
To our knowledge no one has disputed Neil’s claim. It is unfair to argue from authority, but Neil is one of the best in the world in this area of logic. The proof is using Neil’s theorem—who better to point out a flaw in this part of the proof. Since this was communicated Thursday evening there has been ample time for, or someone else, to respond. An answer to this needs to affirm that the class being captured by the first-order part of the paper really equals
Perhaps the pith of the issue is that FO(LFP) is a somewhat exotic way to define
The Solution Space Structure Issue
Here on Saturday Tao posted evidence to have “isolated the fundamental problem with Deolalikar’s argument” on the
The particular problem found by Tao is that Deolalikar’s concept of “polylog parameterizability” of a distribution on a solution space may not carry over to the induced distributions when certain variables are projected out. This is not merely analogous to how 
Tao has also created a separate wiki page on polylog parametrizability, as beginning the rigorous delineation and evaluation of the physics-derived tools in Deolalikar’s paper. The master wiki page continues to be updated.
Some Technical Details on The Solution Space Issue
Here is a more detailed version of this last issue. For 


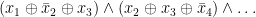
These formulas are equivalent to systems of linear equations over the finite field 

Ryan Williams has also demonstrated such a correspondence within the 
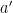


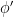
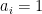
Then 
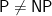
It needs to be noted that Deolalikar’s argument takes solution spaces not just as point-sets but as supports of distributions 
Deolalikar’s Response
Meanwhile, Deolalikar has responded to the previously raised issues with a three-page synopsis and the following statement on his personal web page:
“The 3 issues that were raised were (a) the use of locality and the techniques used to deal with complex fixed points (b) the difference between 9-SAT and XORSAT/2-SAT and (c) clarification on the method of parametrization. I will address all these in the version being prepared, which will be sent for peer and journal review.”
The “version being prepared” evidently refers to an earlier promise of a fully technical paper, which many evaluating his work have found wanting. The original paper’s latest version is dated 11 August, while his papers web folder includes all previous versions.
The synposis contains a key footnote:
“In earlier versions of the paper we used locality. We later realized that locality is not the fundamental property of first order logic that we require. What we require is that the first order formula based its decision at each stage only on the presence of fixed formulae in a fixed number of element types, as described by the Gaifman and Schwentick-Barthelmann Normal Forms. Both monadic and complex LFP have this property at each stage, since it characterizes all first-order formulae. It simplifies our proof and resolves the issues raised about the finite model theory portion of the proof.”
The last sentence aims to answer Neil’s objection, but does it? Recall Neil’s contention is that the class 
Is It Over?
Yogi Berra said, “It ain’t over til it’s over.” To judge from the discussions reported above, it ain’t over. This is so even with the passing of some days since the community has determined that the answers to the first two of Tao’s three questions which we headlined on Wednesday is “No”, and most probably likewise the third. It is hard to believe that this all started just one week ago this Sunday. It seems longer than that.
There has been lively give and take with numerous researchers, and several distinguished academics including Harvey Friedman, Robert Solovay, and Barkley Rosser Jr. have contributed numerous observations. Take away all of these, and there are still math+CS background comments, even ranging to ones by Tao on the Borel-Cantelli Lemma, that are recommended reading. It is not possible to acknowledge everyone’s contributions in this short space, but we are grateful for all.
Open Problems
What solid research can emerge from the discussion? New barriers? More tools for working with distributions? How is this affecting the perception of theoretical computer science as a profession, and the dynamics of the community?
Trackbacks
- Update on SVPD project: Draft interface and listing of feature ideas « Interesting items
- Tweets that mention The P≠NP “Proof” Is One Week Old « Gödel’s Lost Letter and P=NP -- Topsy.com
- Top Posts — WordPress.com
- Proofs, Proofs, Who Needs Proofs? « Gödel’s Lost Letter and P=NP
- Projections Can Be Tricky « Gödel’s Lost Letter and P=NP
- links for 2010-08-23 « Dan Creswell’s Linkblog
- Summer « A kind of library
- Forty Five Minutes To Where? « Philly Bluejay
- 聊聊P/NP问题 « 人云亦云
- 聊聊P/NP问题 : 弯曲评论
- Wine, Physics, and Song » Blog Archive » Consensus on Deolalikar’s P vs. NP proof-attempt (via Scott Aaronson)
- Deolalikar’s P vs NP paper » Interesting Things
- Is Deolalikar's 2010 proof that $P ne NP$ correct? | CL-UAT


I have to disagree with the assessment given in the post. I think that Terrence Tao got to the core of the issues, and believe his understanding of what D. has done is most accurate. However, I also think that what were identified as “fatal flaws” by Neil (with the exception of XORSAT issue) are not fatal at all.
Let me explain.
D. has promised to answer three issues (a), (b) and (c), and I believe he will be able to do so, with the exception of (c) where he will have to clarify what his parameters mean, and there the Tao’s point about projection/non projection problem will be clearly shown to be the only real flaw.
That is not to say that Neil and others on this blog did not point out the real error, but this is a fixable flaw. Also, I believe that D. will be able to answer (b). It all becomes clear when one has Terry’s interpretation of polylog parametrizibility in mind.
There are two interpretations of polylog parametrizibility – with projections (call it ppp) and without projections (call it pp). Explicit examples have been found that show ppp is not the same as pp (c.f. polymath wiki page about polylog parametrizibility).
If we use ppp, then there is an alternative proof that any probability distribution on {0,1}^n that can be obtained by polynomial probabilistic algorithm is ppp (see http://rjlipton.wordpress.com/2010/08/12/fatal-flaws-in-deolalikars-proof/#comment-5566 for a simple proof, not involving finite model theory). So this means that D. can fix the “fatal flaw” and answer (a), since what he is saying is correct, with respect to ppp.
There is also a direct proof that k-XORSAT has ppp. However, for k-SAT we cannot do this if P!=NP. This is how I believe he will answer (b).
However, although explanation from statistical physics results why there are exponential number of parameters needed for k-SAT is missing in the paper, it is entirely possible that this argument will be given by D. but showing only exponential number of parameters WITHOUT PROJECTIONS, in the sense of pp rather than ppp, as Terry also hinted this to be a possible outcome.
Thus, the real trouble seems to be confusion of pp with ppp, as Terry has pointed out. This seems to be the only unfixable flaw.
To show that k-SAT does not have ppp (as oposed to not having pp, which might be a lot easier, and possibly D. has done that) is to show that k-SAT cannot be sampled with polynomial size circuits. This however probably has the familiar natural proof barrier problems, and it is very unlikely that this approach brings us any closer to P!=NP then we have been before.
Yes, I’m inclined to agree; the FO(LFP) issues are ultimately something of a sideshow (except to the extent that it is always suspicious when what is initially billed as an important component to an argument can be conveniently discarded when serious errors are found in that component).
One thing this illustrates is the importance of setting out precise definitions. I feel that if Deolalikar had written down a precise definition of what it meant for a solution space to be polylog parameterisable, the difficulties would have been found a lot sooner, and in particular probably by Deolalikar himself, well before he finished the preprint to share with others. As it stands, there is a disturbing lack of awareness of this projection issue in the paper; it is not just that the issue is not dealt with correctly, it is that no mention of it is made at all. In particular, the crucial (and, in retrospect, far too hand-wavy) proof of P != NP on page 99-100 talks very loosely about “the variables” without specifying whether these are the original n variables of k-SAT, or of some polynomially larger problem, without any sign of awareness that this is a crucial distinction.
Ultimately, it seems that what Deolalikar has really proven is not that P != NP, but rather that pp != ppp (for which we have a simple half-page proof)…
I realised after posting that my initial remarks about the FO(LFP) issue being a “sideshow” may be misconstrued. This statement was made with the benefit of hindsight, now that we know about the pp/ppp issue. Until then, it did seem indeed that the FO(LFP) errors were the most serious problem with the paper. It was only after the discovery of these errors caused the author to promise to remove a portion of the FO(LFP) machinery from the paper that attention began to refocus on other aspects of the argument, and in particular on the very topmost level of the argument concerning the mysterious “property A” which we now understand somewhat better (it appears that “property A” was trying to simultaneously be both pp and ppp).
So I think we can see here some benefit from the open collaborative approach; the different strands of inquiry on the paper were not pursued completely independently of each other, but instead reinforced each other indirectly.
To give a (somewhat artificial) analogy: as I see it now, the paper is like a lengthy blueprint for a revolutionary new car, that somehow combines a high-tech engine with an advanced fuel injection system to get 200 miles to the gallon.
The FO(LFP) objections are like a discovery of serious wiring faults in the engine, but the inventor then claims that one can easily fix this by replacing the engine with another, slightly less sophisticated engine.
The XORSAT and solution space objections are like a discovery that, according to the blueprints, the car would run just as well if the gasoline fuel was replaced with ordinary tap water. As far as I can tell, the response to this seems to be equivalent to “That objection is invalid – everyone knows that cars can’t run on water.”
The pp/ppp objection is like a discovery that the fuel is in fact being sent to a completely different component of the car than the engine.
I am also not getting how impossibility of sampling a distribution by a resource bouded TM implies impossibility of finding a point in the support of the distribution by the same class of TMs.
If you can prove that ppp=pp impies NP !=P, that would be an astounding achivement in itself. So, I think there is still something missing.
We have examples showing p is not equal to ppp.
I mean pp is not equal to ppp, so we cannot prove pp=ppp since that is not true.
ah ok. But, lets say for the sake of the argument, you reached a point where you have two types of distribution classes, and it is not obvious that one is not the same as other…Further, one captures SAT instance solutions, and the other samplable by PPTM. I would think it still doesnt prove NP !=P.
To make it simpler. Suppose D or someone is able to prove that SAT instance solutions are not ppp. Then does it prove NP!=P? I think not. so the former is possibly not equivalent (or even hard) to proving NP !=P.
If someone proved for any particular family of k-SAT formula, that distribution on the space of solutions that is quasi uniform (it is not exactly uniform, but is well defined, depending just on the order of variables and solution space of a formula) is not ppp, then this would indeed prove that P!=NP.
Note that we have to have a family of formulas, since ppp is asymptotic statement – ppp means that number of parameters is O(c^polylog), and this makes sense only if you have infinitely many formulas, and n tends to infinity.
so the idea is that since PPTms can only sample ppp, and hence can’t sample this quasi uniform distribution on solution space, then somehow PTIME machines can’t find a point in the support of the quasi uniform distribution?
Sorry for being pesky, but I do not get it. Even if you substitute probabilistic PTIME machines in my last sentence in the para above, just because a randomized algorithm can find a point in a uniform distribution (quasi or otherwise) over solution space, from that it –does not– follow that another PPTM can sample the quai-uniform distribution over the solutions.
Yes. If PTIME machines were able to find a point in a support, i.e. if P=NP, then that would mean that they could sample this quasi-uniform distribution too.
By contrapositive, if we know they cant sample it, then it follows P!=NP.
Scott Aaronson has a new tech report out on the equivalence of sampling and searching: http://www.eccc.uni-trier.de/report/2010/128/
in other words, classical computers can efficiently sample the output distribution of every quantum circuit, if and only if they can efficiently solve every search problem that quantum computers can solve
I wonder if the techniques therein have any value in this discussion of sampling vs searching.
A quick search through the complexity zoo has shown that Bellare Goldreich and Petrank (2000) showed how to do sampling of witnesses in BPP with NP oracles. So, if NP=P then sampling would go to BPP. The result by Sahltiel and Umans (05) which derandomizes this requires a hardness assumption, so that can’t be used.
I presume you are using these results.
Anyway, that is interesting, but as someone else is pointing out ppp is not very useful to characterize PTIME exactly. Its just that PTIME \subseteq ppp.
Getting back to it, now that NP maynot be so easily in ppp, all I can see so far is that if one can find a solution to SAT instance, then sampling its witnesses is in BPP. Whereas what has been shown is that PPTMs can sample only ppp. One still needs something like BPP can only sample distributions which are close to ppp.
But, I think this makes things epsilon better than nothing.
Vloodin, for the record we have followed your comments carefully, including your comment this morning on how projection of polylog parameterizability can follow from the basic characterization of P, which was added to by Janos Simon. Your comment played into our writing, “In a classic machine model it seems to us that the claims might be transparently false when reflected in the other issue.” We don’t know who you are by name, which inhibits us somewhat from mentioning you as such—but perhaps it played into why Dick went with a photo of a crowd when the post’s format by the standard style on this blog was to headline Tao alongside his projection objection.
One thing about the FO(LFP) issue: it is evident from the cited footnote that this has caused Vinay Deolalikar to revise his original argument. That’s a journalistic fact that the other objections have not yet attained. We cut some sentences drawing more attention to this fact. It also was the first to be fully concrete in terms of the paper, and could have been engaged by the author with a direct response. We’ve been aware that the movement has been from the FO/uniform side to the solution-space and distribution side (without uniformity), and I think our writing has reflected this.
Ultimately it may be “choose your poison”—either the proof only works on a class X that’s a proper subclass of P, or when you word it for the “Real P”, then you find the gap in the “pp” versus “ppp” issue, as you nicely say it. As long as we don’t know definitively, we keep the balance.
Paul Beame, indeed agreed. The words “proof strategy” and “claimed proof” in the main paragraph of the lead section were there from the beginning. In other places, like my sentence with “Ultimately” above, just saying “proof” to denote a generic object seems simplest.
Meant to write “Paul (Beame)…” since of course we know Paul. Also meant to write that if we’re off-base in the mathematics itself, besides interpretation of what’s important, by all means correct us. For instance I deviated from the wiki page in making the “EXT” form of Ryan’s argument the primary one, aware that this involves other issues and hoping I’ve cast them correctly.
What do you mean “As long as we don’t know definitively, we keep the balance”? What do you need to know? The way you put it is nice enough: either “simple” means pp and then the proof fails because the polynomial-time part is flawed, or “simple” means ppp and then the proof fails because NP-complete part is not known.
Thanks. It has certainly been fun to follow and participate in this blog, which like so many other people from the math/physics/cs crowd I found only thanks to the D.’s paper. I think it is great that you made this possible, and even though P vs NP seems to remain open, this hasn’t been a wasted time.
I do think that Niels objections can be answered, and also do not quite understand Ryan’s argument (it seems to me that SAT0 is quite different, for instance it seems that it can only detect partial solutions with tail-zero extensions if we use it in a way D. used k-SAT), but I guess the main point is to move the discussions forward and you people have done this nicely during this past week.
As for D.’s paper, Tao’s insight really helped me in understanding it. I was very frustrated by the lack of proper definitions in the draft – particularly annoying was the lack of clarity regarding the parameter issue – leading to a couple of sarcastic remarks about D. and his style of writing. In retrospect, that was not fair to D. who due to his different background probably is not used to rigor that some of us expect. But now it is increasingly clear that D. had an idea that, even if not completely worked out (I have still to see his linking of phases to number of parameters, even in the pp sense), made sense and was plausible enough. Unfortunately, it contained an error, as is often the case in such situations. Maybe he could have talked directly to someone in the area (given that he is from Paolo Alto), and was a bit rushed, but then things would not have been so exciting. We can only thank D. since a lot of people learned many things due to this whole affair. And certainly, it showed us that one does not have to be in Paolo Alto to exchange mathematical thoughts with leading people.
vloodin=DL 🙂
Although I have not read the paper, except for the FO(LFP) sections, I may not be up to the mark here. But, I feel that maybe he could have worked with pp instead of ppp if he used just FO with monadic least fixpoints. It will be interesting to prove, as you have done for PPTM sampling only ppp, that FO(monadic-LFP) characterizes pp. Some small techincal difficulties like logics define only predicates and not functions (and supplying uniform distrubution as part of the input tape etc) can eaily be handled.
What I am getting at is, you can shift back and forth between the problem betwenn FO(monadic LFP) vs FO(k-ary LFP), and pp vs ppp. It maybe the same problem.
vloodin: I think it would be extremely useful to make the “Polylog parameterizability” wiki clearer. In particular 1) define pp, 2) define ppp, 3) give the proof that random K-SAT is pp (is it true?), 4) Separate the example showing that pp!=ppp. 5) State as a theorem with a proof (or at least a sketch): If k-SAT is ppp then P!=NP.
Related question: If I assume that there is no algorithm that would count solutions in random k-SAT in polynomial time. What more do I have to prove to show that P!=NP?
Lenka, pp and ppp are “simplicity” properties, so when you say “if k-SAT is ppp” you mean “if k-SAT is not ppp”. But it turns out that ppp is too liberal and that k-SAT *is* ppp, so the whole approach is bogus: pp is too weak to capture P and ppp is too strong to leave k-SAT out. See the thread started by Anuj Dawar a bit below.
So even I am confused :). My point was that it would be simpler to summarize these definitions and statements in some condensed way such that one does not have to go trough the dozens of comments here.
Lenka:
(1) and (2)
A probability distribution on {1,o}^n is pp (polylog parametrizable), if there is a directed acyclic graph G on n vertices (each vertex corresponds to a variable from the set {x1..x_n}), so that distribution can be written in the form
p(x_1,x_2…x_n)=\prod_{i=1}^n p_i(x_i;ps(x_i))
where ps(x_i) set of parent nodes of x_i and size of ps(x_i) is O(polylog(n)).
Here p_i(x_i;ps(x_i)) satisfies p_i(0;A)+p_i(1;A)=1, for every fixed assignment A of the variables from ps(x_i) (for instance, if ps(x_1)={x_2, x_3,x_5} then one assignment A could be for instance x_2=0, x_3=1, x_5=1)
ppp is the property polylog parametizibility with projections, meaning you can express your distribution as a projection on the first n variables of a polylog parametrizable distribution on {0,1}^(n+m) (but polylog in n rather than in m+n, this point is unimportant when m=poly(n)).
Note that polylog is an asymptotic statement, you are dealing with families of distributions and letting n go to infinity (say, corresponding to instances k-SAT problems where you let n go to infinity) – this is only to make sense of the asymptotic statement.
(3) Random k-SAT (i.e. quasiuniform distribution on the solution space of a k-SAT) is quite possibly not pp, but I do not know the proof of either that or the opposite (possibly, D. knows how to prove k-SAT is not pp, since that is easier than proving that it is not ppp)
(5) If k-SAT is NOT ppp, then P!=NP.
Sketch: If P=NP, then we can sample quasi-uniform distribution (with a distribution that is not quite uniform, but is described in the following way – if for a partial assignment x_1…x_n-1 there is extension to a full solution with both x_n=1 and x_n=0, set p(x_n;x_1…x_n-1)=1/2, otherwise it is 1 (i.e. (1/2,1/2) and (1,0) distributions respectively, cf. Tao) in an obvious way with algorithm in P – just start partial assignment and extend it based on weather there is a full solution or not.
Then, we use the following Lemma: if we can sample a distribution with a polynomial algorithm, then it is ppp. Proof is here
http://rjlipton.wordpress.com/2010/08/12/fatal-flaws-in-deolalikars-proof/#comment-5566
Finally, if we know that k-SAT is not ppp, then P!=NP
(4) Example separating ppp from pp is EVEN: uniform distribution on solutions of equation x1+x2+…+xn=0 in {0,1}^n (+ is here XOR, if you like). Proof is in wiki
Thank you!!!! I start getting it :). I would have to think this trough properly, but it seems to me that the clustering of solutions may imply that k-SAT is not in pp. But I agree with you that k-SAT is not ppp is whole another story, one would have to show that there is no “hidden symmetry” that does not allow any projection to reduce the number of parameters. But still, being very optimistic maybe D has some idea how to do that.
Just to retract my claim that k-SAT is ppp. I think I got the definition now. We don’t know if k-SAT is ppp.
The title of this post seems dangerously misleading especially given what has transpired since. A proof is something that is logically sound. It would be much better to write “proof claim” or “claimed proof” instead of “proof” in each instance. We have already seen how things have been distorted by the media and this title only seems to inflame that distortion. Indeed it remains to be seen how long that claim of a proof will survive.
Paul,
Did not mean to mislead…I may change title.
Putting “proof” in quotes (as I just did) could be perceived as you mocking Mr. Deolalikar’s attempt, which you clearly haven’t been doing. I would suggest changing it to “proof claim” (without the quotes).
So maybe it should be rectified by writing: “(“proof”)”.
I think it’s fine to just say proof. Quoting it or qualifying it looks like a dig at the proof author. I should point out that the P vs NP page calls all its entries proofs, and repeats verbatim the claims made in the authors’ abstracts without further comment.
When the proof is 100% dead, we can then refer to it as an attempted proof.
Perhaps “solution” can be used to mean verified proof.
The quotations around the word in the title are an improvement. In a way we should not blame the press for their reactions. Recent claims and intimations of the proofs of Fermat’s Last Theorem and the Poincare conjecture have eventually been borne out. They would have a hard time distinguishing reactions this time from those reactions even though within a matter of hours I believe that there was a strong consensus among researchers in the field who had looked at the paper that the attempted proof would not stand (though a quick direct refutation of the approach was not possible because of the lack of details and formal statements).
The speed of dissemination is not unusual for the field but it is for a claim in this form. Consider all the splashy results of our field that have been promulgated quickly via e-mail and blogs. They started with the self-reducibility and interactive proofs for the permanent twenty years ago and more recent notable ones include AKS’s PRIMES in P paper, Dinur’s substantially simplified PCP proof, and Reingold’s Undirected Connectivity in logspace. In all of these the main results and approaches have been verified within hours by many researchers independently.
Though this episode has given our big questions some media attention and clearly attracted outsiders to the field, I don’t see that we can keep repeating this approach with future unverified claims and retain media respect.
We do have experience with complex proofs of claims being sent around. We regularly see long and somewhat involved but ultimately fatally flawed attempts at proving some complexity results but usually these are of technical claims that would not draw the general public’s attention and are quietly dealt with over a longer period of time. (Indeed sometimes the authors only claim a minor result that is “under the radar” and don’t realize that their arguments if true would imply much greater consequences.) Usually these do not go shooting across e-mail and the blogs because people are naturally suspicious of the claims and so don’t tend to pass them on. (It is natural to try to mine these attempts for useful intuitions but my experience in digging into them was that there weren’t any so I am now much less inclined to attempt any such mining. ) Maybe this approach is too cautious for the big claims made here but I think we need some sort of happy medium.
I think this discussion has reflected very well on the TCS community and the role played by Lipton and Regan has been particularly commendable.
I have no idea what this means for the future, but clearly the nature of peer review is very different from what it was in the pre-blog era.
Absolutely!
It is elementary to note that FO(LFP) does not express all P, in the study of Finite Model Theory. Still, it is possible to separate NP from P. That’s when attention is confined only to ordered structures. Thus, if proper distinction between ordered and unordered structures is observed, separation is possible even when FO(LFP) is properly contained in P.
To express NP under ordered structures one can use Fagin’s theorem to express it as second order logic (existential) with the presence of order. But, surely, this route to P vs. NP has been explored before.
Agreed with Craig. Considering this web blog is closely following by experts and laymen around the world, a better title should be “The Claimed Proof For P≠NP Is One Week Old”.
As to the last part of the question, for me the perception I have of the community is good. I’m happy to observe that there is generally agreement between what needs to be done, there is not a split between people who think the proof is true and those who don’t. The analysis is beautiful to watch and in general I think friendly (with the odd exception).
I think it’s obvious that some sort of structured community-based proof-analysis process would be beneficial (though I’m biased in this view as I’ve come up it such a scheme, and am working on it) but not perfectly neccessary. The Polymath project seems close enough for now. As an outsider, at the moment, it’s nice to see that even the experts want the proof in a more understandable and easily-accessible format.
Certainly the discussion has made me very interested in complexity theory (so much so that I’m introducing everyone I know to it).
Prof Lipton,
It would be nice to “preserve” or archive (time capsule) this entire blog for historical reference lest it may become the lost blog of the lost Godel letter. For someone in the bleachers of this effort, it is fascinating to see an entirely new phenomenon of online public peer review.
badri,
What a cool idea. I think I will try to do that.
Great idea.
You should write a paper on the whole episode.
Would you like to see a web service designed specifically to support the kind of peer review that we have seen for this proof?
If so, what sorts of features would you like to see in such a service?
For example, one might have peer review of peer review, PageRank-like measures for authors, credit assignment in the case of a successful proof, etc.
Moreover, you could really turn this into a spectator sport to generate interest in the field, give accurate information to the media, etc.
That would be awesome. Especially for someone new to an area, having an open review process like this readily available along with a paper can be invaluable for both judging as well as understanding a given piece of work.
And its not just for the sake of non-experts… even the accomplished researchers might find it a useful tool to quickly broaden their scope to other topics for which such crowd sourced reviews are readily available.
I think this might also directly incentivize performing genuinely meaningful work, since the game would no longer be that of publishing a paper in some journal or top conference anymore…
Another advantage: it incentivizes the process of reviewing itself… at least compared to the status quo, where reviewers do the job in complete darkness
In fact, I wonder if there is anyone who thinks open crowd sourced reviewing as a rule is a bad thing. And if so, can you say why?
The clear disadvantage is that attention of people who have deep expertise is a scarce resource. The amount of effort this proof attempt has attracted is not scalable, as Harvey Friedman pointed out a few days ago. How will this process prevent burn-out?
Precisely since their attention is a scarce resource, it is better to give these people with deep expertise complete flexibility to review whatever they want, instead of a program chair assigning papers to review at their own discretion.
It’s an interesting idea, but one would have to be careful to pull over best practices where appropriate. For instance, double blind reviewing has the advantage of lessening the likelihood that the reviewer will be distracted by irrelevant facts about the author (nationality, ethnicity and gender cues from the name, etc.) and allowing the reviewer to be frank in her analysis. Making double-blindness work while also ensuring that the reviewers are qualified requires someone to vet the reviewers. The social scheme necessary may be complex, but I’m sure is still manageable.
And thanks to everyone involved here; I’m a CS prof who isn’t a complexity person, and it’s been very enlightening to be able to follow the ongoing discussion.
It seems to me that blindness may not be as necessary (or relevant) for a public review because the review itself will be available for others to evaluate…. Even if this evaluation may be difficult to make immediately, at least the possibility that things might eventually become transparent at some point should be enough to make the reviews as accurate as they could be.
If saying negative things is not easy anymore openly, then thats not too bad either. People could speak up just when they have something nice to say. When aggregated over a large group, this has the implicit effect that when nobody says anything, then thats effectively a vote down…
Yes, this would be wonderful Amir.
Wonder if it could be integrated into or built on top of arxiv.org or ssrn.com or similar… perhaps that would be ideal (version tracking, etc.).
Are there good candidates for this sort of thing right now?
In reply to your final question: I have no background in computer science (I do have a pretty good background in math, though mostly through self-study), and I have found this discussion to be fascinating. I’ve especially appreciated the attempts (of Terence Tao, in particular) at trying to summarize Deolalikar’s proof strategy, and the problems it faces, on a more abstract level. Overall, the quality of the discussion has been incredible, and I’m now significantly more curious about complexity theory than I was before.
It would be nice to capitalize as much as possible on this entire experience – which probably is not yet over. I’m thinking of two arenas.
1. Can we use this experience to generate ideas for modifying or upgrading the educational process?
2. Can we use this experience to generate ideas for modifying or upgrading the refereeing/publication process?
I already discussed arena 1 twice before. Basically, my idea was to add a necessary component to the Ph.D. process (geniuses excepted) that some limited portion of their thesis be “fully detailed” in a precise, but reasonable, manageable, sense short of being machine checkable (i.e., short of being created in, say, Mizar, Isabelle, Coq, etc). This idea would really have to be fleshed out carefully, theoretically and practically, to be fully workable. But this can be done. It would also serve to introduce scholars to at least some important general features of formal verification – a field in its infancy that is destined to become of great importance in the future – at least in industry.
The further discussion here reminds us of the obvious requirement that “all terms must be defined totally unambiguously” is of central importance in any “fully detailed” proof.
Of course, I do realize that this is obviously not going to “prevent” all flawed “proofs” of spectacular claims (and other claims) from being “released”. In fact, it has been suggested that this is so much fun and so valuable a way for people to meet, that we shouldn’t try to “prevent” it even if we could.
But I claim that reforms in category 1, surrounding proof writing, if implemented with the proper finesse, will undoubtedly do a lot of people at various levels of abilities, in various intensely mathematical fields, a great deal of good.
There are other aspects of proof writing that one can also think about regimenting in some way. I’m thinking of high level design. But here, we don’t have a good way to systematize the requirements – like we do in the low level of the “fully detailed”. Also I get the feeling that the present educational process is better, or much better, at requiring clear and sound statements of overall proof structure – correct me if I am wrong.
In arena 2, the following idea occurred to me, and surely others. YOU submit a paper to Journal J. J asks if YOU if YOU want private or public refereeing. For private refereeing, business as usual, anonymous and all that. For public refereeing, J puts up a website for your paper, which is seen by the entire world. People all around the world are invited to NONANONYMOUSLY comment on the paper, at any level of detail that they choose. [Inevitably, there needs to be a moderator for this, to sieve nonsense]. YOU get to comment on their comments, at any time. YOU may of course put up all kinds of corrected versions in the process. This goes on until YOU decide that there is enough there that the paper is ready to be accepted – in YOUR opinion. THEN the Editorial Board decides whether the paper should be published, or whether it should just hang there on the website, or suggest that YOU revise according to comments on the website, etcetera. YOU are allowed to even complain about the Editorial Board. As long as this remains civil, this continues. NOTE: Details to be worked out.
In regards to writing machine checkable proof, in fact, if you find someone with ex-Soviet background, kids were taught to write exactly the sort of proof you described, in basic Euclidean geometry, around the age of 14 or so.
There have been times and locations in the US where this has been done as well.
Dear Professor Friedman,
I have the greatest respect for you. However, I do take issue with some of the points you raise:
1) You believe that formal verification is somehow going to revolutionize the industry. I think this is a sad mistake. I know this because I have a PhD in formal verification, and I know how flawed this dream is. I have become much more realistic. Given that formal verification cannot be used for even small real-world systems, there is no chance for formal verification to be applied to current or future real-world systems.
2) I agree with your public refreeing process. I think it is a good idea
3) The value of teaching proofs through using proof verification software is also a good idea. CS PhD students should have some idea of how proofs work.
V:
a) Formal verification has loads of industrial applications, see John Harrison at Intel, for example.
b) He was NOT talking about formal verification of software, but machine checkable proofs (the candidate proof is already there) and even mathematical constructivism!
Thanks, V, for the kind words – perhaps you have too much respect!
To be exact, I wrote
“[formal verification] is a field in its infancy that is destined to become of great importance in the future – at least in industry.”
which is not quite the same as what you said I said. In a few of the major computer companies, a serious amount of resources is now devoted to formal verification. See, e.g., http://asimod.in.tum.de/2010/Harrison_Abs_10.pdf http://www.cl.cam.ac.uk/~jrh13/slides/nijmegen-21jun02/slides.pdf http://www.computer.org/portal/web/csdl/doi/10.1109/ICVD.1997.568077 http://reports-archive.adm.cs.cmu.edu/anon/2009/CMU-CS-09-147.pdf
It is true that the most success thus far, by far, is in formal verification of hardware. There, the investment by industry apparently has a good looking bottom line. For software, the situation is of course trickier, for many reasons – including that it is generally much more difficult to verify software than hardware. But I am convinced that there will be major changes in the future in how software is produced and formally verified in industry. Perhaps not in 2010. But, I conjecture, before P != NP is proved.
Dear Professor Friedman,
You might want to look at Leslie Lamport’s short paper, “How to Write a Proof,” which limns a scheme for humans in the hope that they will far less likely to prove something that isn’t true. It’s here:
http://research.microsoft.com/en-us/um/people/lamport/pubs/lamport-how-to-write.pdf
I think this also fulfills your wish that it could give someone practice in the thinking required to write machine checkable proofs. I found this about two years ago, and it improved my own proof eyes and proof writing ability greatly. I hope this is relevant to your question.
Thanks for that link. D’s proof attempt, even if incorrect, has led me to discover this and other blogs and a veritable gold mine of interesting references, links, and an entire larder for thought.
Lamport’s paper has been discussed at Math Overflow, as well as related work by professor Friedman and others. The discussion is still short, and mostly contains links to various resources that I have yet to digest.
If you have any good ideas, please contribute! The link is:
http://mathoverflow.net/questions/16386/proof-formalization
As someone working on formal verification, I am not excited about full-fledged computer-checkable proofs. It’s so tedious and boring. Clearly the ‘refereeing’ process that D.’s paper is undergoing is the best one can expect, but I am afraid it will not become the standard, because most papers are not like that and there is a first-time affect. By the way, STOC/FOCS are notorious for the laconic yes/no answer they provide to authors, compared to a much more verbose tradition of referee report in other branches of CS, when there is even a rebuttal phase where the author ansewrs the anonymous referees.
Harvey, As a journal editor I find your last suggestion of allowing the possibility of public refereeing to be extremely interesting.
I’m less than sanguine about the idea of public refereeing. Not because I think it shouldn’t be public, but because I’m skeptical that most papers will get the degree of attention needed. P vs NP is sui generis in my mind, and the average paper is unlikely to get a thorough review by relying on public refereeing rather than mandating a set of reviewers.
Maybe a hybrid model, where all discussions are public, but there are still a mandated set of reviewers, might be useful.
Please note that I suggested that the author have the right to ask for a normal private review, or a public one with no anonymous reviewers.
There are a lot of details to be worked out and issues to be resolved, and what I suggested above on August 15, 2010 7:32 pm were my first thoughts.
There are some interesting possible side effects of this approach. It may highlight many big developments rather early on, to a wide community, and also fast track particularly important papers. Also, it may create an invaluable open forum for potentially paradigm shifting controversial innovations, as the disagreeing reviewers have it out on crucial issues, comfortably below the flame level.
Prof. Freidman,
Your second idea in particular is an excellent one. Regardless of whether a particular paper gets published or not it promotes distribution of ideas and methods. I don’t know how many journals would be willing to go along with this, though.
We are still hopeful that the promised final release of the “journal paper” by Deolalikar for peer review will be able to answer all the questions raised here and elsewhere.
I really don’t think you should be as encouraging about the “journal paper”, for two reasons. One is that non-expert onlookers will interpret it as a vote of confidence. Do you seriously think the chances are anything but negligible that Deolalikar will successfully patch up this proof, say by the end of 2010? If so, you seem to be the only one.
The other reason is that I strongly believe Deolalikar should publicly withdraw his claim of a proof. There’s no reason he can’t work on fixing it, and perhaps he someday will fix it. (I very much doubt this approach can ever work, but who knows how he will modify it in the years to come.) But the story would then be “he had an idea, he gave an incorrect proof based on that idea, and later he came up with a new, correct proof based on it”, not “his original proof was right all along”. Until he produces that new proof, he should withdraw his claim.
This is what upsets me the most about the whole story so far. Anyone can make a mistake, and people who choose to work on the most difficult problems deserve some respect (as well as sympathy when their efforts sadly fall short). However, it’s unprofessional to respond to criticism by more or less saying “Hey, that proof a lot of experts just spent a week examining – the one that’s 102 pages in 12pt font. Did I tell you it was just a warm-up proof? When you see my real proof, which explains what I really meant when I said all that incorrect stuff, you’ll see that all your objections are answered.”
Your points were embodied in sentences that were considered for this post but cut. For the moment please respect that our editorial (and less-editorializing) policy reflects a wide range of perspectives. One guide here is to keep it concrete—we reproduced Deolalikar’s footnote which is a primary source, and which opens the door for people to say what they conclude. We’re just amazed at the immediate technical discussion; the meta-discussion will need greater distance of time anyway.
I do not think VD should be bullied into withdrawing his proof. The burden can be placed on the reviewers to withdraw their support as well!
To be civil, I believe that it should be left as work in progress or whatever.
Has there been any news about D.’s promised draft? Or any news how D. reacts to the Tao’s projection objection (pp vs. ppp?)
I agree. The amount of collective effort here in is an unprecedented help to D for understanding and patching up his proof. If in fact the proof ultimately worked then we would have a new debate to whom this proof should be credited to. Our ultimate objective is to understand but credit seems to be important to some.
You’ve actually touched the first of several examples of large concerns Dick and I have had that are not in the space of comments we’ve seen so far. I mean, I think I’ve scanned over a thousand comments, and yours is the first to strike me as articulating the issue of “credit” along lines we’ve cared about. What happens when imprecisely specified ideas are rendered concrete by others? What should happen? I don’t want to guess here—it’s too early—but just know that this has been in our mind as we write, even if we don’t use those words.
Yes, the issue of ‘credit’ is bound to cross one’s mind. But
1. The current status is far from where such a consideration becomes relevant.
2. If at all it all VD comes up with a final correct proof – the majority credit will still be his. Many objections raised are being termed as ‘unfixable’. Most likely they indeed are. But if VD shows otherwise to all of that – it goes to his credit only.
3. Certain kind of suggestions, such as – bring more formal sturcture, or show that it is failing for 2-SAT, establish why all barriers are being circumvented clearly – albeit they are valuable, but are too generic.
But there are other discussions, that added so much value here as well. Immerman’s own letter (one example, but probably not the only one) is an excellent example.
In the end, looks like Scott Aaronson’s money is safe 🙂
I don’t agree. Terence Tao has already came up with the defintion of poly parameterizable. The credit is only Tao’s although inspired by the proof. So if vd uses this definition he should give proper credit.
Oh! don’t get me wrong.
If this proof carries through, Terence Tao’s name should be undeniably associated in the credits. As will be a few other names.
That’s probably an easier part to fix here 🙂
In my view the reason many people were prepared to put a bit of effort into publicly clarifying some of the ideas in Deolalikar’s paper is that they were fairly confident that this would not ultimately result in a correct argument, so thorny questions of credit would not arise. Contrast it with the treatment of Perelman’s papers. They had flaws (as I understand it), but the general feeling was that the approach was a serious one with a good chance of being basically correct. In that situation people were prepared to make efforts to clarify the proof, and the credit they got was gratitude for the heroic task they undertook rather than a share of the mathematics, so to speak.
Speaking of credit, is Richard Lipton already planning to write a book about this whole episode?
http://www.amazon.co.uk/Question-Godels-Lost-Letter/dp/1441971548
This book is a collection of blog posts from last year – it’s unrelated to this proof.
To add something to Gowers’s comments about Perelman’s proof – when Perelman’s first preprint appeared it was immediately clear (that is, after a superficial reading) to experts in differential geometry familiar with Hamilton’s already elaborated program to prove geometrization via the Ricci flow that Perelman was offering serious, deep ideas to resolve the already known serious obstructions to Hamilton’s approach. The exposition was such that the ideas were quite clear, if not all the details of how they were implemented, but Perelman was already known for his proof of the soul theorem, some work on generalized curvature bounds with Burago and Gromov, etc. – so one’s initial reaction was to take the preprint seriously.
Here the situation seems (sociologically) rather different.
the idea of presenting (parts of) proofs in a machine checkeable format is absurd. it creates an unnecessary overhead (people need to learn the programming language a la mode) and impedes the creative process (people will gravitate to “easier” in the sense of programming proofs). I do not object to machine checking if the effort is done on the machine side (perhaps using AI) but at the moment it sounds an exaggeration.
Spending our efforts checking “narratives” instead of rigorous proofs in the usual mathematical tradition (lemma, theorem etc) will make mechanized proofs more valuable and life harder for the rest of us.
anonymous –
I have the feeling that you think you are responding to me. Is that correct?
Assuming this is correct, I did not suggest that (parts of) proofs be presented in machine checkable format in my earlier postings here. Only, for part of a Ph.D., some limited proof be given in “full detail”. The theoretical work I suggested that needs to be done must explicate “full detail” so that this becomes something user friendly of the kind that many professionals who are particularly concerned about errors creeping in in critical parts of their proofs will do on their own.
It is, however, a research ambition to actually also make this not only very friendly and easy to read, but also machine checkable. However, that goal is secondary to what I am suggesting, which is educational.
prof friedman ok I understand this is a noble objective. I am just afraid that the sketchier publishable proofs become the more imperative mechanized proofs will be.
Also consider that the actual checking of the “proof” was done by a handful of people. It could not be otherwise as they are the real experts. Blogosphere or not, these same people would “peer review” the paper and ultimately decide acceptance in the mathematical community. So not really much of a difference in that respect. In another respect it is didactic to students and fun for the voyeurs non experts as the private became public.
in a more typical crowd sourced review situation, the number of reviews that a piece of work gets would be variable…. unlike the current one where reviewers are fixed beforehand. So the valuable finite expert attention will have a lot more flexibility in terms of where it chooses to give its attention… making the whole process presumably a lot more efficient
Anonymous, you may have underestimated the possibility of the medium. The open process attracted more experts, and not necessarily the same ones that would have been involved in anonymous peer review. This was one of the complaints of other anonymous commenters: that great mathematicians convened here to understand an ill-formed proof instead of doing whatever the commenter believed would be a more productive use of their time.
They came here not only to understand the proof, but for reasons that transcend the peer review process as this is usually understood. Unless your experience with peer review is different from mine, I have not been online discussing papers for review with my colleagues–I’ve been doing this in private, generally without the benefit of discussion with other reviewers. One-way communication from the editor about my overdue review is hardly a substitute. The process here isn’t invariant under “blogosphere of not.” It would not work at all without the blogosphere.
The technology is at the point where the need for more specialized systems to conduct this kind of review is apparent. We don’t have (or seem to have) LaTeX in comments on this blog. We cannot reorganize the comments by time stamp, assign roles, weight comments or ratings by a user’s standing in the community, and so on. As for automated theorem proving, we don’t even have an online library of definitions and statements of mathematical theorems. An online system for peer review might facilitate the creation of such a library. But in any case, the effort here suggests that work on systems for doing and reviewing online mathematics needs to be supported more than it has been.
There is a need to generate greater public awareness of the work that mathematicians and computer scientists do, and to ensure adequate funding for research. That is, unless you believe that mathematicians and computer scientists already have been doing a stellar job promoting their work and are rolling in dough.
@ math grad student:
I have to respectfully disagree with your assessment that formal verification has *loads* of industrial application. (and by the way, Professor Friedman did state clearly that formal verification is going to revolutionize industry. Please read his first post carefully).
Yes, formal methods have had some impact on hardware verification. I know most of the people in formal methods (including the Intel folks you are referring to). These guys understand the limitations. The only people who are most enthusiastic about formal verification are either
1) Have already heavily invested their careers in formal methods
2) Have never written significant software
3) Outsiders who don’t understand the difficulty of using formal tools, and don’t understand the cost/benefit of using formal tools (For certain hardware applications these tools makes sense. Not otherwise)
Formal verification can be a great crucible for new ideas, but not an effective end in itself.
@V:
> These guys understand the limitations.
Could you explain these limitations?
Formal methods have the following serious issues:
1) Usability: Formal tools are exceedingly difficult to use, and despite decades of research (nearly 50 years) not much progress has been made in making them useable by the ordinary programmer
2) Incorporating change: You have to constantly maintain correspondence between your code and your formal spec. Otherwise, they may go completely out of whack, and the formal spec becomes useless
3) Automation: Most of these tools are not as automatic as one would want them to be
4) Complexity: Most problems in formal arena are PSPACE-hard or harder. Model-checking is PSPACE-complete.
There are whole host of other issues with formal verification. However, the current orthodoxy in computer science is wedded to the idea.
Contrast software systems with biological systems. Bio systems are far more complex than software systems. There are no theorems we can prove about bio systems. Yet they work, most of the time.
The key point is that as complexity of systems increase, proving stuff about them is just too hard. We need a different paradigm for software assurance.
I don’t know where WordPress will put this comment, but it’s a followup to the concerns raised by V about formal verification. (Apologies to Messrs. Lipton and Regan for being off-topic, but things seem to be winding down, so I figured it was ok.)
It’s not quite correct to say that model-checking is PSPACE-complete. V knows this, I’m sure, and was being brief, but the reader interested in further information might want to check out The Complexity of Temporal Logic Model Checking by Schnoeblen for a fuller picture. Some logics are more tractable than others, in both theory and practice.
Also, model checking is now being applied to biological systems. One survey is Quantitative Verification Techniques for Biological Processes by Kwiatoska et al.
Besides complexity, your argument is merely a problem of engineering practice, in particular if you are so concerned with “ordinary programmers”, then it is indeed never going to be possible to make formal methods accessible, since as far as I am aware, most of them do not even bother to work out how to multiply two matrices!
First of all: thank you all for the insight in the claimed proof during the last week! I, as a young scientist, really appreciate this – without those wonderful blogs and explanations I would certainly have not been able to capture the idea of the “proof”. Maybe someone is interested in some trivia: I added some statistics about the interest on P_NP and Deolalikar on my recently started blog – got inspired ^^. http://youngscientistseeksguidance.wordpress.com/
“Tao has also created a separate wiki page on polylog parametrizability, as beginning the rigorous delineation and evaluation of the physics-derived tools in Deolalikar’s paper. ”
Humpf, I do no like the use of “physics-derived tools” here. Statistical physics works on random k-SAT describe the set of solutions, nobody in physics derived any tools for “polylog parametrizability”. “Physics-derived” should not be used as a synonymum for “unclear”, or “we-think-ill-defined”. Physics is an exact science, the sometimes necessary lack of mathematical rigor is always (that is in the high quality works) backed up by experiments, simulation, self-consistency, and agreement with observations.
I agree. The lack of rigor in D.’s paper was due to somewhat sloppy writing and lack of attention to detail. In physics, as in all exact sciences, one strives for clarity, and although there is plenty of intuitive reasoning the formulations are given in a precise mathematical language to great extent. Vagueness might appear, but the ideas are expressed as clearly as possible, supported often by examples that illustrate main points without any fault. There is perhaps a bit of a more relaxed attitude with respect to proofs, but one always knows what one is talking about. The rich input form String theory, for instance, has given mathematics a lot of deep insights, deep theorems have been formulated based on physics intuition. Witten is also one of the greatest mathematicians though he originally comes from Physics.
Concerning the solution space issue, I think it is important to distinguish “search space” and “solution space”. Search space belongs to an algorithm, so a complicated search space could only explain why an algorithm does not work, but in any sense, it cannot prove that the problem itself is hard.
We can define the solution space as the acceptance paths of a NDTM. However, there are unlimited number of NDTMs solving the same decision problem, and for any problem in P one can construct a NDTM with a “complicated” solution space, see my previous comment here: http://rjlipton.wordpress.com/2010/08/12/fatal-flaws-in-deolalikars-proof/#comment-5466
If one could turn this hand-waving into a strict theorem, then it might be a new barrier saying that no proof looking at the solution space can prove that P != NP.
Above this barrier the best what could come out from Deolalikar’s approach is that #P-complete problems cannot be solved in polynomial time. Indeed, #P is defined directly via the acceptance paths of a NDTM for an NP problem, which precisely defines which solution space we have to consider. But we are light years from any rigorous proof, first the parametrization issue should be fixed, then somehow it should be proven that fast counting is impossible if the number of parameters is high.
Istvan:
“#P-complete problems cannot be solved in polynomial time… But we are light years from any rigorous proof …”
Somebody might be just around the corner to solve a #P-complete problem in polynomial time.
That would be quite surprising… Then it immediately would follow that P=NP…
As far as I can tell the converse of your argument also holds; one can turn any problem in NP into one with a “simple” solution space NDTM. The devil seems to be in the details as usual… Do you have a proposed definition of simple solution space?
No specific definition, just some vague idea that all paths of a NDTM can be described with a tree, and a solutions space is simple if the acceptance paths are ‘aggregated’ on the tree.
But you are perfectly right, why it wouldn’t be the case that an alternative NDTM exists with a simpler solution space. Then it is also hopeless to prove P != #P in this way…
You ask whether he has answered Neil’s objection. Of course, we won’t know until we see a new version of his paper and we get a precise account of what he means by “the first order formula based its decision at each stage only on the presence of fixed formulae in a fixed number of element types”. But, in any case, this is only aimed at answering one of the two objections that Neil raised.
Neil’s objection was that the reduction of higher-arity fixed points to monadic fixed-points produces a structure of low-diameter and therefore destroys locality. Deolalikar suggests he can get around this by working directly with higher-arity inductions, not using locality, but some yet to be defined property of first-order formulae.
Even if he were able to flesh this out, it does not address the second of Neil’s objections and that is Deolalikar’s claim that he can assume that every stage of the induction is order-invariant. Let P’ denote the class of problems definable by an LFP induction, every stage of which is order-invariant, even allowing for higher-arity fixed-points. Then, one can (relatively easily) prove that P’ does not contain parity, or XOR-SAT. In other words, P’ is strictly weaker than P (though it does containe P-complete problems).
This issue has not been addressed in the synopsis at all. My conclusion is that, even if he is able to flesh out his synopsis, Deolalikar has still not answered the main thrust of Neil’s objections.
Of course, we don’t know how D. is going to answer Neil’s objections. But the point is that the thing which he is trying to prove using finite model framework is true.
Namely, each distribution that can be sampled with a polynomial algorithm satisfies ppp, i.e. has polylog number of parameters if one allows projections. That this statement is true can be checked with alternative simple proof based on probabilistic TM. Weather he can formulate a proof of this with his approach (using FO(LFP)) or not, the statement which he is proving stands on its own, so it is just a matter of skill to get it using finite model theory framework – he would have to change his present proof, which he announced, but since he is proving a true statement there is no doubt that it is possible to fix his argument – or he can just replace it with alternative proof based on TM.
To analyze his proof, we can break proof of his main theorem to a sequence of lemmas that he essentially uses. If a lemma is true on its own, then that place is not a fundamental flaw even if his proof of a lemma is incorrect; rather, an incorrect proof of a true lemma, which can be easily proved otherwise, is a fixable flaw. Using such an analysis, we can conclude that the fundamental problem in the paper is located elsewhere – in the part which claims that k-SAT has no ppp. It appears that he might have proved k-SAT has no pp, but it is at least as hard to prove k-SAT has no ppp as it is to prove P!=NP. So, ultimately, the ppp vs pp distinction kills both his proof and his approach.
Right. I see what you’re saying, though I think you’re being generous in describing it as what D. is trying to prove. As I understood it, he was trying to prove that every problem in P has the property pp (not just ppp), and this claim is demonstrably false. My point is that it might be true for the class P’ that is defined by LFP formulas whose stages are order-invariant.
But, does your argument that all distributions samplable in P have the property ppp not, in fact, apply to all of NP, using the fact that these are just projections of P sets? Or, in other words, start your argument from a nondeterministic rather than a deterministic Turing machine?
He never stated what he was trying to prove, but since he used projections in his proof the most he can hope to prove is variant with ppp. Even in his monadic version he uses projection in the second part of the proof (last chapter).
The argument does not apply to NP. ppp corresponds to polynomially samplable by distributions (on a circuit level), projections are used to get probability distributions and cannot be used for NP, since otherwise we would get polynomial algorithms for NP.
Isn’t the uniform distribution on the satisfying assignments of a k-CNF formula ppp? Proof:
Let F(x_1,…,x_n) be the k-CNF formula, with Boolean variables x_1,…,x_n and clauses C_1,…,C_m, where C_i depends on the variables x_{i_1},…,x_{i_k}. Let S be the set of satisfying assignments of F, a subset of {0,1}^n, and let \nu be the uniform distribution on S. Now consider the straight-line program that computes m+1 new variables z_0,…,z_m as follows:
z_0 = 1,
z_{i+1} = z_i AND C_i(x_{i_1},…,x_{i_k}).
Each depends on k+1 variables (a constant).
Let S’ be the set of all strings (x_1,…,x_n,z_0,…,z_m) in {0,1}^{n+m+1} that satisfy these equations and also the condition that z_m = 1. The map (x_1,…,x_n,z_0,…,z_m) -> (x_1,…,x_n) maps S’ bijectively into S. Thus, the uniform distribution \nu’ on S’ projects to the uniform distribution \nu on S.
On the other hand \nu’ is polylog-parameterizable through the explicit factorization given by the straight-line program, if I understood the definition from the wiki.
vloodin: Maybe I’m misunderstanding your definition of ppp, but from what’s on the wiki, and your argument showing that all problems in P have this property, I don’t see why we can’t extend it to all of NP. Take the polynomial-size circuits that verify witnesses for your set, and project out the intermediate results, and this should give you the uniform distribution over the solution space. So why is the distribution pp before the projection – well, by exactly the argument you give, namely we are now talking about poly-size deterministic computation.
I think the comment from Anon. above is exactly right. And it’s not only for k-SAT, but can be made to work for any problem in NP.
For a Boolean function f taking {0,1}^n to {0,1}, let g be a function computed by a n^c size circuit that takes {0,1}^n+m to {0,1} such that f is the projection of g.
The polynomial-size circuit can be assumed to be of bounded fan-in and can be turned into a straight-line program with a new Boolean variable for every gate of the circuit, and each variable depends on only two previous ones. Let’s say this involves N new variables.
Then for each particular instance, i.e. a string in {0,1}^n, you get a program that gives a pp distribution on the space spanned by m+N bits which is pp. Projecting out the last N gives you the uniform distribution on the solution space you’re looking for.
To return to the main point, as we summarized it a couple of days ago, the strategy in D’s paper consists of two claims:
1. every problem in P has property A
2. k-SAT does not have property A
We still don’t know exactly what property D has in mind, but we have explored two plausible alternatives. If “property A” is pp, then claim 1 is false (with parity and XOR-SAT being counterexamples). If “property A” is ppp, then claim 2 is false (not just unproven) because every problem in NP has this property.
I do not think that the above proof that k-SAT is ppp is valid because the aforementioned distribution with the n+m+1 variables does not sample the solution space of k-SAT (ie, there is no guarantee that it holds z_m=1) .
Anon:
The problem in your proof is the last step, checking if z_m=1.
you should be able to write your distribution as product
\prod p(x_i; ps(x_i)) \prod p(z_i;ps(z_i))
where ps is a parent set in your directed graph.
Since you are describing z_i as a deterministic function of ps(z_i),
p(z_i;ps(z_i)) is going to be 0 or 1 depending of ps(z_i) that you described
and weather you have right or wrong assignment for z_i. That part is OK. But how do you discard the part where z_m=0? z_m is result of your computation, and there is no way to take just the part with z_m=1.
Also, partial ordering with respect to directed graph means that ps(x_i) is restricted. It is not clear from your proof what is ps(x_i) – if it were just a subset of {x_1…x_n} than you gain nothing from projection, your parametrization is pp. You don’t say what ps(x_i) is, but it can have at most a couple of z_j – when all x_i appear in clauses C_j for j<j0, then you can use just z_j with j<j0 for ps(x_i), since graph is acyclic. The trick is to get x_i to depend on auxiliary variables, not other way around (in proof that PTM are ppp x_i appear in the LAST step of computation, as entries in the tape at the last moment T).
Anuj:
To prove that NP sampling is not ppp is to prove P!=NP, since if P=NP then NP sampling is ppp. Of course it is possible that NP sampling has ppp, which would invalidate D's approach even further. But I do not see how you can get that NP sampling is ppp. As you can see from problems in Anon's proof, you have to be careful about projections. If you had an easy NP sampling on a circuit level (which is what ppp gives you), and the circuit could be obtained in some systematic way, then you could likely be able also to obtain answer to NP questions – for instance, to each k-SAT formula f you can get a (k+1)-SAT formula equivalent to f_1 f OR (x1 AND x2 AND … xn) with mn clauses, which has at least one solution (1,1,…1), so, if you can sample this in a quasi-uniform way, then you can check if there are other solutions too. Thus, NP sampling seems as hard as k-SAT, if not harder.
Can you please remind why XOR-SAT is not pp?
Lenka: Because EVEN is in XOR-SAT; solution space of x_1+…+x_n=0 (+ is xor) is such that whichever n-1 variables you choose, the last one is sum of all the others (on solution space). Hence, if you can express uniform probability distribution in the form that pp requires, than that variable has to depend on all the others, which is not O(polylog) – also see wiki for this.
Thanks. I think I got the definition now. The answer to my question is: we don’t know.
I see. I had another look at the definition on the wiki. Indeed, my argument does not show that the solution space of k-SAT is ppp. Rather, if I understood it right, it shows the following.
Choose some way of encoding k-CNF formulas as binary strings, and let f be the function that maps an n-bit sequence to 0 if it represents an unsatisfiable formula and to 1 if it is satisfiable.
Then, the uniform distribution on the set of n+1-bit sequences (x,f(x)) is ppp.
This is, of course, not at all the same thing as saying the uniform distribution on the solution space is ppp.
But, isn’t the argument that problems in P give rise to ppp distributions also referring to the distribution on (x,f(x))?
No, the proof is constructing distribution on solutions as the end result, x_1…x_n are computed as function of some random parameters – they are end results/outputs of computation, rather than being arguments/inputs in computation, as in your case.
Question about how efficient sampling is affected by the number of parents with these recursively factorized distributions.
I only see this affecting the space complexity of the sampling.
For instance, for the pp distribution of EVEN over n variables, the first n-1 variables are independent. So we can flip n-1 coins. So now for the nth flip we have to look up from the conditional distribution p(x_n;x_1…x_n-1) the parameters to sample the last value.
Now if this was stored in some table form there are an exponential number of parameters needed to describe the distribution. But the lookup from such a table could be done quickly using some kind of indexing strategy.
Therefore I don’t quite see the direct connection between the size of the conditional distributions and the complexity of sampling.
I suggest to start a polymath project on P vs NP. It seems to me that it would be a
good idea. First, experts from different countries could discuss on the subject and
exchange easily ideas with each others. Second, a programme could be written in
order to select a few possible strategies that could work and to determine which
unresolved problems should be attacked to understand better the P vs NP problem. In
that context, sub-polymath projects could be launched to try to prove unresolved
problems of a certain difficulty.
If one see this as a long-term project it make sense 😉
Sure, Luca (Trevisan, I presume?). A particular part of it is, I’d suggest a wiki on Candidate Hardness Predicates and their status (counterexample, naturalize, algebrize, impact other unknown/unlikey things, wide open…).
I could contribute a few, e.g. on the arithmetic side, Definition: H(f) = the polynomial ideal formed by the first partial derivatives of f has exp(exp(n))-many minimal monomials m in it, where “minimal” means that no proper divisor of m is in the ideal. Motivation: for DET this count is 0, for PERM it’s apparently astronomical, so there’s a notable structural difference. Status: This has a counterexample: f_n can have linear-size arithmetical circuits of total degree 6 and yet give 2^{2^n} minimal monomials. Then related ones involving Hilbert functions, Castelnuovo-Mumford regularity, “etc.”—all with forms of the same basic counterexample. I think eventually Deolalikar’s work will furnish some hardness predicates.
Quite properly, most of the discussion on this particular topic has centered upon solidly traditional mathematical objectives: (1) Establish whether the high-strategy proof strategy is correct, or conversely, how it fails. (2) Clearly express that strategy as a correct proof, that is peer-reviewed and published in what the Clay Institute delicately calls “a refereed mathematics publication of worldwide repute”, and (3) Apportion credit for this enterprise justly and reasonably, in accord with the traditional norms of academia.
Respect for these traditional objectives is of course crucial to associating enduring value not only to Vinay Deolalikar’s proof, but to any mathematical proof … and this is why there is universal insistence that they be respected.
A tougher question is, are these traditional objectives sufficient to the occasion?
In the back of many folks’ minds (especially young folks) are some soberingly tough challenges: an overheating resource-pour planet; a planetary population of order 10^10 souls who require family-supporting jobs; a mathematical profession that will approach 10^7 practitioners in all but the most dystopian of near-term futures.
To meet these challenges, our planet’s single greatest resource is the creativity of its inhabitants. To focus this creativity, perhaps our greatest resource is aspirational challenges. And of the aspirational challenges that reside in the domain of mathematics, the P≠NP challenge is, by consensus, among the dozen-or-so greatest.
Thus there is a sense, that if the minimal acceptable result of this episode—namely, a correct peer-reviewed article with credit justly apportioned—is also the sole result, then we will have collectively missed … perhaps irretrievably … a crucial opportunity to learn how to rise to the challenges of the 21st century.
It is not so easy to say what novel resources might arise from this episode. Novel aspirational narratives, perhaps? Certainly these narratives have an honorable tradition in the mathematical literature.
Not everyone need embrace the same aspirational narratives … a too-rigid uniformity would not even be a desirable goal. But if people’s personal mathematical narratives are evolving as a result of this episode, then I hope that they will post about it.
All of this is really SMASHING for raising the awareness of leading-edge mathematics. Only problem for me (and I’m by no means mathematically illiterate) is that the leading edge is sooooooo far over me head! Maybe the SECOND or third-smartest mathematicians herein could break down the key elements into lay-speak, and allow me to understand a bit more of what the excitement is all about.
Newton was able to simplify his findings in terms of an apple and his head.
Einstein, with a 3-element equation was able to show a HUGE amount to most of the World.
PLEASE! Allow all these experts to chew the mathematical fat and confirm or deny a breakthrough, and remember that we’re mostly going to have to believe you anyway…. it helps if you can make us as comfortable as possible in placing that much trust and belief into your assurances.
I can try one thing—if we’d had more time Saturday-into-Sunday maybe we could have added something like this about Terence Tao’s observation to the main article:
——————————————————————————
Look at your silhouette from a light in a dark room. It is the result of a mathematical projection, here from a 3D image into the 2D wallspace. This is a completely natural physical operation—indeed, it’s the guts of quantum measurement. What may be surprising is that it’s bound up with the notion of “nondeterminism” that defines NP. To wit:
a point p in the 2D space is part of the projection if-and-only-if there EXISTS a point p’ in the 3D image that gets projected onto it.
Now the point p’ might be unique—it might be the tip of your nose. Or there might be many points, as with light (not) going through your skull. Either way, the “exists” makes it an NP matter. Indeed it is a completely typical one: let the “image” be the set of points (F,a) where F is a Boolean formula and a is a 0-1 assignment to its n variables, such that F(a) = true. The “image” is a language in P, since “F(a) = true” is easy to verify. But when you project out the “a” co-ordinate, what you get is the language SAT of Boolean formulas F for which there EXISTS an “a” making F(a) = true, which is the canonical NP-complete language.
This seems surprising because with silhouettes you think of the projection as being simpler than the 3D image. In particular you’d realize some features of your head might get washed out in the projection (e.g. double-chin gone), but you wouldn’t expect anything to get more complicated. When you’re talking about statistical features, however, perhaps that can happen. The above about SAT shows a belief that with computational features it does happen. When you’re dealing with concepts that draw from distributional statistics and from computation, where is the boundary?
What Tao has found and directly stated is that the paper as written pays insufficient attention to the issue of features being preserved under projections, specifically the concept of “polylog-parameterizability”. And because of the above point about SAT, this seems to be making a “vicious cycle” back to the P vs. NP question itself. The “3D image” is the solution space of Boolean formulas, but after tupling and handling many more coordinates than I’ve mentioned, then taking slices. Exactly how this issue applies to the paper apparently still has to be hashed out in full, but it’s a recognized gap in things as they stand.
—————————————————————
I could even say more, like how the “Valiant-Vazirani Theorem” essentially says that in the case of SAT and other NP predicates, the whole 3D image can be successively “hashed” so that questions about the membership of any projected point p get determined entirely by tests for tips-of-noses. But I gotta get back to “real work” :-).
Perhaps I should say projection is a natural concept rather than operation—whether Nature actually “does” projections seems bound up with the Copenhagen versus Many-Worlds debate. I thought I’d come up with a nice quip, “Projections are only in the eye of the beholder”, but a quick Google of that (without quotes) +quantum tells me that its wordspace is well populated…
Ken, your post raised my hopes of an (eventual) Gödel’s Lost Letter essay upon the topic “Why quantum separability is NP-hard”. Such an essay surely would find an eager readership … your short remark was plenty illuminating in itself. Thanks!
My thanks for the time you’ve spent on your illumination Mr Regan.
It helps.
I’m beginning to wonder if just maybe there is a duality involved? Sometimes P will = NP and sometimes it won’t – and determining >>when<< it is and when it isn't is another "Uncertainty Principle", spoiling the Order we'd perhaps prefer!
I will follow this discussion with added interest (and a little more enlightened).
Dear All and Dick,
I believe Sameer is raising 2 important issues here:
http://rjlipton.wordpress.com/2010/08/08/a-proof-that-p-is-not-equal-to-np/#comment-4818
a) Sameer and Rafee *seem* to doubt the standing validity of the Immerman-Verdi theorem.
b) Rafee may need help with his proofs.
I have almost always felt sorry for Rafee since I learnt about him on the internet. As he is trying to do science in his own way from a remote country. This happened weeks before Vinay came into the picture!
So I do not believe that defending Vinay was completely a nationalistic or such issue for me as some responders rushed to point out. I like to think of it as an interesting cultural coincidence.
I do agree that I opportunistically advertised in this FIFA World Cup of the nerds 2010, and I see absolutely nothing wrong with that! I have seen a Georgia Tech Google Adwords ad for its 7th ranking in US News theoretical Computer Science. Here are the rankings, I cannot locate the ephemeral Google ad though 😀
http://grad-schools.usnews.rankingsandreviews.com/best-graduate-schools/top-computer-science-schools/computer-theory
By the more or less objective and deductive nature of a theorem or proof, advertising or betting about a proof should not change the inherent validity or invalidity of the theorem or proof.
So considering the above 2 main issues, with a view towards the future, I think automated theorem verifiability is the way to go. It may take a few decades. Any computing device in any corner of the universe should be able to download a digital theorem or proof or conjecture file and run a verification on its own. Something like when your anti-virus software downloads an update, its smart enough to run a checksum verification!
This would mean that somebody’s creative output – whether coming from Immerman-Verdi, Sameer, Rafee, me or a spaced out alien cockroach; can always be tested beyond reasonable doubt by anybody who has a computing device. Otherwise knowledge and its understanding and agreement would be with an elite few, potentially doubted by the others.
Dick, I thank you very much for hosting this whole event, and being one of the most “open minded” and game-changing academics I know, and not deleting my opportunistic advertisements 😀
I have started to already think of Georgia Tech as “Seabiscuit”, a tenacious favorite underdog contender in the theoretical Computer Science race now!
Sorry for the rant 😀
Cheers – Milz
http://amzn.com/1452828687 (!)
Could you please stop linking to your Amazon book? This is a blog for serious discussion. Notice that no one else has plugged a book here. Could the moderators remove posts with amazon links?
I don’t need help to prove that SAT is not NP-complete. The Kleene-Rosser paradox is in NP and irreducible to SAT.
You need to reduce KRP to SAT which is impossible. My proofs are now with one of the top journals for 7 months and am waiting for their reports.
Milind Band(ek)ar:
How would you feel if players participating in the “FIFA World Cup of the nerds 2010” leave a negative review for your book on Amazon, citing your amateurish behavior and shameless plugging? I see absolutely nothing wrong with that (like you see nothing wrong with ruining a very interesting discussion with your arbitrary and totally irrelevant rants). Trust me, your posts were absolute travesty considering the quality and level of discussion that is going on on this blog. Please refrain, watch from the sidelines and try to learn something.!
I agree with anon here, moderators please remove the posts by “milz” blatantly plugging his stupid book – they are quite annoying, nauseating and totally irrelevant.
Dear All,
I believe Sameer is raising 2 important issues here:
http://rjlipton.wordpress.com/2010/08/08/a-proof-that-p-is-not-equal-to-np/#comment-4818
a) Sameer and Rafee *seem* to doubt the standing validity of the Immerman-Verdi theorem.
b) Rafee may need help with his proofs.
Considering the above 2 main issues, with a view towards the future, I think automated theorem encoding and verifiability is the way to go. It may take a decade or two.
Any computing device in any corner of the universe should be able to download a digital theorem or proof or conjecture file and run a verification on its own. Something like when your anti-virus software downloads an update, its smart enough to run a checksum verification!
This would mean that somebody’s creative output – whether coming from Immerman-Verdi, Sameer, Rafee, me or a spaced out alien cockroach; can always be tested beyond reasonable doubt by anybody with a computing device. Otherwise knowledge and its understanding and agreement would be with an elite few, potentially doubtable by the others.
Dick, I thank you for hosting the impromptu FIFA World Cup of the Nerds 2010 😀
And of course, the Clay Mathematics Institute and Grigoriy Perelman for being the inspiration in the first place!
Sorry for the rant 😀
Cheers – Milz
@math grad student:
You said “Besides complexity, your argument is merely a problem of engineering practice”.
Engineering practice is far harder than you think. Automating formal techniques is extremely hard, for example. If it were easy, it would have been done already.
We need to start thinking about self-evolving, self-correcting, self-programming software. A formal approach is not going to take you far.
Oops, I totally forgot that V and others has been talking about automated theorem proving in their own little corners for the past few days.
http://rjlipton.wordpress.com/2010/08/15/the-p%e2%89%a0np-proof-is-one-week-old/#comment-5646
Dick, could you please delete one of my duplicate rants mentioning aliens above.
I have been known to go to great lengths in making a fool of myself, but I absolutely draw the line at these offending closely spaced duplicate posts 😀
Anon above, others are not plugging their book directly here, but their reputation as researchers, which will bring in the dough for them later and also the “remote possibility” of somebody buying their books on amazon?! Take this you … http://amzn.com/1452828687 http://amzn.com/1452828687 http://amzn.com/1452828687 Doh!
Cheers – Milz
V (and others talking about automated theorem stuff),
Here is a link “Formalizing 100 theorems” you may be aware of
http://www.cs.ru.nl/~freek/100/index.html
Another popular link from the Netherlands:
http://www.win.tue.nl/~gwoegi/P-versus-NP.htm
One of the professors who taught me CS studied there:
http://www.cs.wayne.edu/~fstomp/
My book (http://amzn.com/1452828687) was inspired by an “open problem” posed in this book co-authored by the creator of CVS:
http://www.cs.vu.nl/~dick/PTAPG.html
So I believe Netherlands is a fountainhead of sorts for theoretical CS. Maybe its the space cookies 😀
Cheers – Milz
ahmm, nobody seems to have any problem with the counter argument in the post (about mapping (\phi,a’) to (\phi’,a’) with a trivial solution), so it’s probably just my poor understanding.
Perhaps someone can explain what I’m missing here:
why is this mapping have anything to do with complexity?
this argument only shows that for any (\phi,a’) with solution a there is a mapping f = f_{\phi,a} such that all-0 is a trivial solution of \phi’ = f(\phi). How does it make the problem “easy”?
1. if the “check the all-0 assignment” is considered an “algorithm in P”, then so is the algorithm “check the assignment a “.
2. more generally, how can we even claim that an *instance* of the completion problem (i.e. of (\phi,a’)) is even “easy” or “hard”? the general completion problem certainly cannot become “easy” using the mapping f, as f is instance-specific.
do you mean something like applying the relevant f for each instance separately, and then look on the structure of the entire solution space? would that still be considered “the same structure” to the solution space of the original problem?
1. if the “check the all-0 assignment” is considered an “algorithm in P”, then so is the algorithm “check the assignment a “.
Not true, “check the all-0 assignment” refers to infinitely many assignments (one for each number of variables, n), each of which are all-zero. When formula on n variables is received, algorithm checks all-zero on n variables. All-zero assignment has advantage that it is maximally compressible. When assignments a on n bits have high Kolmogorov complexity (cannot be encoded in less than n/2 bits) then the algorithm “check the assignment a” for infinitely many assignments a cannot be implemented on Turing machines. Most assignments a have this property.
For a single instance – there is no difference between the two, since an instance (\phi,a’) [with solution a] already includes the number of variables to complete m=|a|. There’s no notion of Kolmogorov complexity here, since we only discuss a single string.
I understand that for a *set* of instances (i.e. \phi with different assignments a_1,a_2,… ; or different formulas \phi with increasing size) there is a difference.
However (that’s point 2.), different instances (even of the same formula) require different mapping functions f. So now you have a polynomial algorithm, but I’m not sure it solves a similar problem.
It is not the same to claim that f_{\phi,a} preserves the structure of solution space of \phi (which is obviously true), and that separately mapping each instance of a certain set (or a probability distribution over such set) , preserves the structure of the entire space of solutions to all instances. The latter seems like a much stronger claim, and not necessarily true.
As a metaphor, consider a linear transformation carried on, say, a tree in R^2. Clearly all properties of the tree remain. Now suppose you perform a (different) linear transformation on each of a large set of distinct trees, so that all their root now coincide. This is far from being the same – (non)connectivity for example is not kept.
do you mean something like applying the relevant f for each instance separately, and then look on the structure of the entire solution space? would that still be considered “the same structure” to the solution space of the original problem?
yes…. the map is not supposed to be uniform… i think the point was that the structure of the solution space has nothing to do with the complexity of the problem…
Well, in that case (i.e. non-uniform mapping), this is a very weak argument against the use of the structure of solution space, and it’s certainly not a *proof* that using the structure cannot work.
I admit I do not fully understand Tao’s counter argument, but it does seem that it relies on this mapping example in any way.
what i don’t understand about this proof is simply this:
if we are relying on sampling or clustering to solve randomized k-SAT at the point when the sample/cluster size becomes exponential, then wouldn’t we require an algorithm with exponential space complexity? as P is contained in PSPACE, that should be enough to prove NP != P.
no need, for statistics, physics, metaphysics, etc.
my understanding was that either we are not restricted to that type of solution or the reducibility of randomized k-SAT within NP does not provably extend to that point.
if that’s incorrect, and i’ve stumbled upon a simple proof that NP != P, I’ll be happy to provide a billing address to the Clay Foundation.
I’m not sure if I’m answering the question you are actually asking, but as far as I can see, you only would need exponential space if you have to store all the samples simultaneously. If you just iterate through them, you need only to store something like the current one, which takes linear space. This is one way of showing the already known result that NP is in PSPACE.
Also as far as I understand, half the point of the P vs. NP question is that we don’t know whether we have to use the exponentially expensive solution methods we already know about.
a) if you’re only storing the current one(s), that would be constant space not linear
b) the assumption we’re starting with is that NP could equal P. if you have to iterate through an exponential number of things to solve an NP-complete problem, then it obviously isn’t.
in terms of a, i misread what you wrote. sorry.
you are correct that it wouldn’t be constant, but if the cluster itself is exponential in size, how could that only require linear space?
ah. i see. the cluster size is not exponential.
there are exponentially many clusters.
makes much more sense.
Question from complete stranger: what happens if we turn definition of Turing machine around and express state at moment t-1 via state[t] (as “OR” of states leading to state[t]).
Then we get logically equivalent definition. So, if time is running backwards starting from final state, we arrive to initial conditions within polynomial number of “steps” (so to speak)
Which is another way of saying that with time running backwards, P=NP.
Based on this observation, any formal proof of P!=NP in “real world” should use the condition that time is running only forward. But time is not a logical notion (logical predicates describing Turing machine are static), and in general it would be quite difficult to provide formal non-circular definition of statement “time is running forward”. Just a wild idea, not sure it makes any sense.
I Hope that Vinay.D will improve his paper according to this long discussion.But today I think that there is some more fundamental question in computation then if PNP. “Is there a new model of computing other then the Turing machine?”.
( p.s : I sent a blessing to ICM2010 in two days)
Vloodin says “explanation from statistical physics results why there are exponential number of parameters needed for k-SAT is missing in the paper, it is entirely possible that this argument will be given by D.” But D. has quoted this result even if he hasn’t
repeated the argument, hasn’t he? Does he need to give the argument if it’s already in
print in STOC’06 ?
On page 56 he says “Later, [ART06] rigorously proved that there exist exponentially many
clusters in the d1RSB phase and showed that within any cluster, the fraction of
variables that take the same value in the entire cluster (the so-called frozen variables)
goes to one as the SAT-unSAT threshold is approached”. Doesn’t each frozen variable
give rise to a parameter? At least that was my impression. Or is that what is in question?
Not that I’ve read any statistical physics papers in my life, although I think D. is making
a good case for this being a worthwhile endeavor. I see the quoted paper at
http://arxiv.org/PS_cache/cs/pdf/0611/0611052v2.pdf but I can’t find the word “parameter” in it.
I meant to say, what is missing is the part starting from the physics results, that are quoted, to get the claim that k-SAT needs exponential number of parameters. Exponential number of clusters is not the same thing as exponential number of parameters, even in the sense without projections. Argument is needed to link the two. Although this might not be too hard, he has not provided this argument, which is something NOT present in the papers he is quoting, that do not mention parameters in his sense at all (as far as we know, I haven’t checked the papers but the people who did this work and from this area, like Lenka, had as much trouble deciphering what he means by “parameters” as anyone else). But as I said, there might be a link from number of clusters/frozen variables to number of parameters without projections, and it might not be too hard to prove, though it is not trivial/obvious and a proof is missing linking the two in his draft.
What is entirely unlikely is that he will be able to get exponential number of parameters WITH projections. That question on its own is not easier than P!=NP question, so it appears that he did not come any closer to solving P!=NP riddle.
This is answer to post by Micki St James above.
I agree with vloodin and could not answer better to Micki. The [ART06] do not show anything about number of parameters needed. This is a concept developed in D’s paper and even if maybe he has some connection in mind, the proofs/precise statements/definitions are missing in his paper.
It’s a amazing discussion !
That’s a new path to make research in 21st century .
Thank you 与非 !
I’m just making a random comment on a social issue, but would it be fair to say that Deolalikar was clever enough to fool himself? That is, the ppp vs pp problem now being isolated, much of everything else is all “just” fancy language to some extent (though perhaps interesting in its own right, but not for P vs NP), and if he hadn’t the brights to know, research, and write all that, then the core underlying fallacy would more easily be seen? If you look at other attempts of P vs NP, the flaws are usually more direct in nature.
For the other issue, while it is cute to see boffins exploring all these ideas, maths and science is always about whether the proof or idea works, not whether it is aesthetic. From other areas, having widespread group blogs like these can easily lead to groupthink (usually slowing drifting to it over a period of time, as naysayers are invisibly and unknownly marginalised) if there is not care to avoid it.
Vloodin: Your explanation of the pp vs ppp issues is very convincing, though I do not share your pessimism about the amount of progress this makes.
Essentially you’re saying that the theorem “P != NP iff the solution space of k-SAT is not ppp” is too easy to prove, and therefore no “real work” has been done, right?
However, a few days ago many have doubted that studying solution spaces has any chance of separating complexity classes. Now it’s becoming clear that “ppp” is a valid hardness predicate on the solution space of SAT.
This suggests the existence of other such predicates that might be easier to apply, but still powerful enough to separate some classes (not necessarily just P and NP). This approach seems to be almost unexplored, and not obviously subject to relativization or natural proof barriers, so it might be fruitful.
The real problem was that until Terrence Tao made sense of the parameters noone understood what D was talking about. Tao got to the bottom of the issues with noticing projection problem.
With this definition in mind, it turned out that essentially ppp is nothing other than random sampling, which is of course not new. D. claims that from physics results follows that k-SAT is not ppp, but he probably proved just pp, if he had proved anything from physics results (he just quotes them at this point). And to prove that k-SAT is not ppp is to prove that k-SAT solution space has no easy quasiuniform sampling, which means that k-SAT cannot be solved easily (there is a way to see this). Which means we did not move a bit from proving P!=NP – proof of P!=NP along D.’s lines involves a Lemma (k-SAT is not ppp, not proved in D.’s paper, but wrongly assumed to follow from physics results), which is as hard (if not harder) than P!=NP, since content of the lemma says essentially the same thing as P!=NP.
I meant study of random sampling is nothing new.
Regarding the sampling as hard a searching issue:
See my answer to Anuj:
http://rjlipton.wordpress.com/2010/08/15/the-p%E2%89%A0np-proof-is-one-week-old/#comment-5755
Also see comment of Sauresh and Aaronson’s paper it links to:
http://rjlipton.wordpress.com/2010/08/15/the-p%E2%89%A0np-proof-is-one-week-old/#comment-5734
Ah, OK. What I meant is that there could be some property other than ppp (and possibly unrelated to random sampling) that might work.
I see. Yes, that is possible.
Solution spaces of restricted CSP that can be solved in P satisfy some algebraic properties (in the sense of universal algebra). Also, statistical physics results do suggest link of hardness to properties of solution spaces. I guess that was D.’s initial idea. So even though his proof seems to be dead now, the general approach might as well make sense.
I don’t think that we have fully captured all, Vinay’s conception of independent parameters. In his intro, he mentions two cases as having compact descriptions.
One distribution over two variables where each variable is independent, each outcome with equal probability.
{(0,0),(1,0),(0,1),(1,1)}
This needs only two parameters P(x_1) and P(x_2) to specify. He describes this as a limited range interaction.
Then he mentions another over five variables but only two of the outcomes have non-zero probability.
{(0,0,0,0,0),(1,1,1,1,1)} every other one has a 0 probability.
And he describes this as a limited value distribution in this case you still need only two numbers to specify the joint distribution, if you just work in a subspace that can generate only two outputs.
This makes me thing we need a more powerful way to characterize a distributions described by Jun Tarui here, http://rjlipton.wordpress.com/2010/08/12/fatal-flaws-in-deolalikars-proof/#comment-5557.
For instance, for the following distribution
uniform (or any positive) measure on the n-cube – {(0,0,…,0)}
Jun argues that the last cluster is exponential because it depends all the previous values.
But actually, we can still have a compact representation if we allow simple functions when making the table of values. We only need one parameter and a simple function for the last conditional distribution p(x_n;x_1…x_n-1) .
This function would test if any of the previous variables were non-zero. If so it would return p(x_n=1) = some value.
Otherwise, it would just return p(x_n=1) if all previous variables are 0.
Clearly, there is still an efficient parametrization of this conditional distribution if we allow simple (linear) functions.
“This suggests the existence of other such predicates that might be easier to apply, but still powerful enough to separate some classes (not necessarily just P and NP). This approach seems to be almost unexplored, and not obviously subject to relativization or natural proof barriers, so it might be fruitful.”
I tend to agree. However, as was said earlier on this blog, and as far as I know, all predicates that were suggested so far (mainly in statistical physics) do not distinguish between k-SAT and k-XOR-SAT. But even a result X!=NP where X is some class that does not even contain computation of a determinant might be interesting, isn’t it? Also of course complexity people will probably have much better ideas than physicists of what such predicates might be for different classes X.
Well if somebody wants to discuss this more in detail, and if the statistical physics insight may be of any use. I am available :)!
My comment below (posted earlier) might have some relevance to this discussion, although it merely represents the intuitive understanding of a C.S. graduate. I think statistical metrics are generally unsuited to the separation of complexity classes (unless of course, your statistical metrics are strong enough to represent entire classes of problems solvable by entire classes of machines – in which case I think you are going beyond the realm of mere statistics.) At risk of repeating myself, this is the core of what makes me intuitively uncomfortable about V.D.’s claimed proof. In my view, it’s as though he’s looking at a complex and apparently random series of numerical digits, and saying,
“We cannot find any correlation or pattern, and our best existing algorithms fail to find any useful correlation; so the digits must be random. If they’re random and/or not interrelated in any discernibly useful way, then guessing the digits will require exhaustive search, which costs exponential-time.” – Not a very sensible conclusion if you are looking at (say) every 57th digit of pi beyond the first few thousand (which will look fairly random, unless you know what you’re looking for.)
Is my intuition wrong? If so, can you help me to understand how? This would be much appreciated.
I’m pretty sure this is not Luca Trevisan.
That was meant to be a response to Ken Regan’s response to “Luca”.
I wanted to add one small observation about ppp, which is that it is actually quite a wide class of distributions and supports, including some “hard” ones. For instance, consider the space of collections k-clauses on n-variables for which the corresponding SAT problem is solvable. (This is a subset of {0,1}^C, where C is the space of k-clauses on n variables.) [Note that this space is NOT the same as the solution space of a single SAT instance; this is the base/fibre distinction talked about earlier.]
On the one hand, if P!=NP, we know that this space is not in P. On the other hand, it supports a ppp distribution, because one can randomly select a solution (x_1,…,x_n) first, and then select a random family of the clauses that are obeyed by this solution.
What this suggests to me is that ppp is actually quite a weak property. While it is still possible (and perhaps even likely) that a random SAT solution space does not support a ppp distribution, actually separating the SAT solution space from ppp may well be a much harder problem than the original problem P != NP.
Another example of a set supporting a ppp distribution would be the image of a one-way function, such as a hash function. Such sets are interesting for the purposes of theoretical cryptography, but they may actually be somewhat unrelated to the P!=NP problem (they seem to be focused on separating a different set of Impagliazzo’s “Five Worlds” than the P!=NP problem is).
I think there is a difference between properties “there is a distribution supported on a set that is ppp” and “there is a quasi-uniform distribution supported on a set that is ppp” (quasiuniform in the sense that D. gets in his last chapter).
For instance, it seems that while solution space of a k-SAT0 formula has a ppp distribution supported on it, to get a ppp quasi-uniform distribution on it in a systematic way (so that graph can be defined/computed efficiently) would mean NP can be solved in probabilistic quasipolynomial time.
On an unrelated note, is there some easy way to see that k-SAT solution space is not pp (say to get this from Physics results, as D. apparently wanted to do)?
I need to explain: k-SAT0 formula has a ppp distribution whose support is solution space since we can check every assignment and then if it fails, we just turn all variables to 0 (this is computation on probabilistic TM).
On the other side, if we can compute a quasiuniform distribution on a probabilistic TM, then we can check weather there are other solutions, which is as hard as k-SAT.
Some comments on polylog parameterisation without projections (= pp): I think we can consider an alternative definition, the one that is more general than Terry Tao’s definition.
Consider a factorization formula of a probability measure mu on the n-cube:
mu(x1,…,xn) = Product_{j=1,…,n} p_j(xj; x_pa(j)).
In Tao’s definition, each factor pj is the conditional probability.
A more general setting: Allow each pj to be an arbitrary nonnegative-real-valued function. Since mu is a probability measure, its probability weights must sum up to 1, but this constraint can be easily incorporated by normalization, i.e. dividing the whole thing by the positive real M = Sum over the ncube of the Product above. Let me call a new version “polylog parameterisation by functions”, ppf.
1. Some probability distributions studied in statistical physics seem to admit ppf. In particular, Ising models. (For example, for 2-dim Ising model, we can give an underlying square-grid an acylic direction (say, from the origin towards (n,n)) and write down a factorization formula.)
2. Earlier (cf wiki), I gave two examples that do not admit pp. These two examples do not admit ppf either. The same zero vs nonzero argument applies.
3. Consider the solution space S of random k-SAT with constant density. The uniform measure on S does admit ppf with high probability (with probability 1-1/quasipoly). The reason is as follows. Consider a SAT instance consisting of m clauses. Say that literal xj or negation(xj) is the *last* literal in clause Ck if for every literal xi appearing in Ck, i <= j. For example, x4 is the last literal in (x1 OR x2 OR x4). The uniform measure on S can be expressed as a ppf-factorized form by defining p(xj; xi's) to be 1 if all clauses Ck in which xj or neg(xj) is the last literal are satisfied; and 0 otherwise. For a random k-SAT F with constant density, the probability that, for some j, literals xj or neg(xj) appear more than polylog times in F is at most 1/quasipoly; so with high probability we have a ppf factorization.
4. So in terms of D's paper, the notion of ppf does not help (because the solution space of random k-SAT admits ppf). I believe that the solution space of random k-SAT does not admit pp (original Tao's version); but my arguments for two couterexamples cannot show this because they don't distinguish pp vs ppf .
As a computer science graduate with a little mathematical intuition, Deolalikar’s apparent proof strategy seems unreasonable to me, even without reading more than his synopsis. The suggestion that a well-defined Statistical Property X (a randomness-metric or information-complexity-metric or graph-complexity-metric or something of the sort) can be used to determine the general tractability of a mathematical problem; goes against reason.
Consider a theoretical system of encryption that uses techniques that are too complicated for Property X to sniff out [according to Gödel, such a system must exist.] In my theoretical encryption system, all messages are fully compressed down to their minimum possible length, prior to encryption; using a compression method that is more complex than Property X can handle. So the input-space and the solution-space, and every other problem-space expressible in terms your Property X can understand, must all look completely random and intractable to Property X…
But this does NOT mean to say that the problem itself is intractable. Just that using any particular Property X (even a theoretical one) short of a generalised polynomial-time computation machine cannot come close to proving that the problem in question cannot be solved in polynomial time. (Credit T.Tao with the basis for this part of my argument.) The fact that V.D. is bringing statistical properties into his “proof” at all seems to undermine the whole thing for me, whether those theoretical statistical properties are well-defined or purely theoretical. Notwithstanding the inadequacy of your Property X for un-encrypting my encrypted messages, or even for finding out whether I encrypted a real message or just random noise; this will never take away from the fact that there might exist a Property Y that will provide a polynomial-time mechanism for unencrypting my messages.
So intuitively, it seems to me that the proof-strategy itself is fundamentally flawed and unfixable. It’s a beautiful idea though, and I think Deolalikar should go to work on some information-theory and get the credit that he deserves in that field first instead of going straight in for the big kill. He probably has the skill and relevant specialist expertise to develop useful new methods of data compression for specialist purposes.
I have just realized that, thanks to Ryan Williams’ insight (I still do not understand what he meant though, rather disagree with what I think he was saying), and another comment due to Anuj Dawar and Anon, and point made by Tao, we have that the solution space of every k-SAT formula is a support of some ppp distribution. See my comment above for why k-SAT0 formulas have a ppp distribution supported on its solution space. But then, via Ryan Williams, so do any k-SAT formulas.
Thus, any solution space of a k-SAT formula has a ppp distribution supported on it.
Of course, for quasi-uniform distributions situation seems to be a bit different – getting them on k-SAT formulas seems to be as hard as solving k-SAT.
It seems to me that the solution space of k-SAT0 is trivial. A solution space only makes sense for a decision problem of the form L = {x | exists y such that R(x,y)}, where R is a poly-time predicate – the solution space for a given x is then the set of y that satisfy R.
Can we write k-SAT0 in this form? Yes, by making the predicate R do all the work of checking if x allows an all-zero assignment, while ignoring its y-argument. Defined this way, the solution space of k-SAT0 contains every y, not just the y’s that define satisfying assignments. Am I right?
Here I meant solution space of a k-SAT formula that is satisfied by assignment (0,0…0). So, a k-SAT0 formula is just a k-SAT formula satisfied with this assignment.
Actually, I don’t see why the SAT0 solution space (which is basically just a translate of the SAT solution space) necessarily has a ppp distribution. It is true that one can easily decide (by testing at 0) whether this space is non-empty or not, but the extension problem, i.e. seeing if a partial assignment of literals can be extended to a full solution to SAT0, seems to be as difficult as the original SAT problem to solve (unless the partial assignment consisted entirely of zeroes, but this is a very special case).
I suppose one positive achievement from Deolalikar’s paper is that he has essentially established the following fact, which in retrospect is actually fairly easy to prove, but which I for one had not seen before:
Proposition. If P=NP, then the solution space to any NP problem, if it is non-empty, can be expressed as the image of a function f: \{0,1\}^n \to \{0,1\}^n of polynomial complexity (thus f can be expressed as a circuit of size poly(n)). In fact one can even make f uniform in n (so the conclusion here is actually a little bit stronger than just being in ppp).
The proof is easy; one simply generates a random solution to the NP problem one literal at a time, using the polynomial time solvability of the extension problem to always ensure that one is guaranteed to find a solution in the end. There are precisely n random bits needed here, one for each literal.
As I said before, it may well be that the solution space of a random k-SAT problem cannot actually be represented as the image of a polynomial complexity function, which in principle gives a way to prove P!=NP. But proving this looks strictly harder than proving that P!=NP, and so does not appear to be a viable approach to me.
p.s. It is true that the distribution I gave on solvable SAT problems need not be quasi-uniform (in the sense of a uniform exponential lower bound on the probability of a given problem being selected), but it does not seem to me that such a property is ever used in the Deolalikar argument, which is focused instead on the support of the distribution, rather than on the distribution itself. (In particular, he relies on the “ampleness” property (Definition 2.1) rather than on quasiuniformity.)
Ok, let me give my argument in more detail.
Let f be a k-SAT formula in n variables satisfied by (0,0…0) assignment. Let X be its solution space, and let |X|=A be number of solutions. Then define the following distribution p on {0,1}^n.
p(0,0…0)= (2^n-N+1)/2^n
for any other solution (x1…xn)
p(x1…xn)=1/2^n.
Then this distribution is ppp. The reason is simple: this distribution can be computed on a probabilistic Turing machine. Simply generate (x1…xn) with n coin tosses, so you get a uniform distribution. Then check this assignment. If it is not a solution, then set all variables to zero. This generates the required distribution, and hence this distribution is ppp.
Should be p(0,0…0)=(2^n-A+1)/2^n above, A-size of solution space.
Of course you might as well drop the shifting trick by fixing some satisfying assignment. Your sampler is very non-uniform anyway as you need to know the size of the solution space.
Yes, it is non uniform, that is my point. I do not need to know the size of the solution space (though that would not matter since we are on a circuit level).
The quasi-uniform definition is way too weak, and hence you get this trivial claim. Showing *uniform* distribution on solutions is not ppp,
will still prove you something by Bellare Goldreich and Petrank (2000).
You will need to show that BPP can only sample distributions close to ppp.
Then, if uniform distribution on solution space is not in ppp, you end up proving NP \not subseteq BPP.
Ah, I see. So ppp is an even wider class than I thought, it that it contains distributions supported on SAT0 solution spaces. The same argument also gives a (non-uniform) way to create ppp distributions on any non-empty SAT solution space (or indeed, any non-empty solution space of a function in P), by using some (non-uniformly selected) specific solution (a_1,…,a_n) to the SAT problem as the “default”.
If so, then it appears that there is in fact no separation of P and NP going on here, even at the conjectural level; regardless of whether P equals NP or not, the k-SAT solution space supports a ppp distribution. So the ppp concept is of no actual use for this problem.
Thanks vloodin! It looks like you have given a more direct argument than my half-baked intuitions about SAT vs SAT0. I am not sure you disagree with me as much as you think you do!
Sorry if my comments were sometimes cryptic, but the last few days have been extremely busy for me, and I could only comment sporadically. But I have enjoyed catching up on the discussion over the last hour, especially the “true” meaning of parameters.
here is a more precise statement if one uses uniform distribution on solution space instead of quasi-uniform.
1. Thm: PPTMs can only generate outputs with distributions in ppp.
2. Suppose BPP=NP; and since BPP^{NP} can sample uniform distributions over NP witnesses (Bellare et al), PPTM^{NP} can sample distributions statistically close to uniform distribution on NP witnesses. Since NP=BPP, by Zuckerman amplification, PPTMs can sample distributions stat close to U on NP witnesses.
3. Claim: There are families of SAT formuale, one for each n, such that
uniform distribution over their solutions is NOT stat close to any ppp distribution, asymptotically.
4. 1, 2, and 3 lead to contradiction.
BTW, It is known htat BP \subseteq PH. But I am not sure if that means PPTMs can sample uniform distributions over NP witnesses.
Sorry, point (2) should have started by “Suppose NP \subseteq BPP”.
I think vloodin is right, and in fact the following holds.
Prop. f:{0,1}^n –> {0,1} admits a ppp whose support equals f^{-1}(1) iff f in NP/poly, i.e., nonuniform-NP.
Proof Sketch: : Assume that f^{-1}(1) admits a ppp distribution D(y1,…,ym,x1,…,xn) with n main variables x1,…, xn and m auxiliary variables y1,…,ym. Then, for x in {0,1}^n, f(x) = 1 iff there is some y in {0,1}^m such that D(y1,..,ym,x1,…,xn) > 0. So f is in NP/poly. (We are assuming that determining D( ) > 0 can be computed in time poly in the number of variables in ppp representation of D.)
The discussion has been noted by the NYT:
http://www.nytimes.com/2010/08/17/science/17proof.html?hpw
…nstructing this proof was uncovering a chain of conceptual links between various fields and viewing them through a common lens.”
An outsider to the insular field, Dr. Deolalikar set off shock waves because his work appeared to be a concerted and substantial challenge…
Dear Prof. Friedman,
This is a very speculative question, but I am wondering whether you think that it
may be possible that there are natural questions directly related to computational
complexity (say involving the world inside EXPTIME) that are independent of ZFC.
Actually it would be interesting enough if some strong assumption (say about large
cardinals) could be used to get some results about complexity.
Sorry if this is a hopelessly naive question!
It is of course *possible* that logical issues are what is holding up progress on the massive number of critical lower bound issues throughout theoretical computer science. E.g, that one has to use more than ZFC in order to make progress on these problems.
Unfortunately, I cannot say that I have any kind of viable research program for showing that ZFC is inadequate for these crucial problems.
Let me also add that if I did have such a viable research program for showing this, I would probably write this posting.
I’m assuming that you are being coy here, especially given your assertion from the preface of your BRT book: “In fact, it still seems rather likely that all concrete problems that have arisen from the natural course of mathematics can be proved or refuted within ZFC.”
But it looks like you will keep us guessing!
Vinay D. has updated his web page as follows:
“The preliminary version was meant to solicit feedback from a few researchers as is customarily done. I have fixed all the issues that were raised about the preliminary version in a revised manuscript; clarified some concepts; and obtained simpler proofs of several claims. This revised manuscript has been sent to a small number of researchers. I will send the manuscript to journal review this week. Once I hear back from the journal, I will put up the final version on this website.”
Also, only the synopsis of the proof is now available both from his web page as well as from his paper web folder.
He should get a quick review. Things are pretty clear by now.
I cannot check now his “ampleness” assumption (I did not save his draft 3), but if Tao is right, and he relied on supports of ppp distributions, than there is no chance he has proved anything. He might have fixed (a) ,(b) and (c), but his proof is dead due to pp vs ppp issue. I guess he is just trying to save face, it doesn’t seem to be easy for him to admit defeat.
A retraction would have been a much wiser move.
Can one of the elite group of people who received a copy of the latest version of D’s paper, post it on the web for public consumption?
There you go again imputing motives to the man and judging “him” without knowing zilch about him (albeit, kudos to you that you restrained yourself for hundreds of postings by just sticking to the math).
His decision to retract all previous drafts and not post his promised proof for public scrutiny, in the wake of all the analysis and online attention that he was getting, speaks volumes. Unfortunately, not volumes in mathematics. His math may not separate P from NP, but his acts better separate him from a quack.
I think that normally Tao should definitely be one of the people to get a copy of the latest draft.
He has said:
“The preliminary version was meant to solicit feedback from a few researchers as is customarily done. I have fixed all the issues that were raised about the preliminary version in a revised manuscript; clarified some concepts; and obtained simpler proofs of several claims. This revised manuscript has been sent to a small number of researchers. I will send the manuscript to journal review this week. Once I hear back from the journal, I will put up the final version on this website.”
Responding to Dick Lipton.
I have been following this with indirect interest. Logical aspects of P != NP (intuitionism, bounds, provability in ZFC), online interactive refereeing, and educational reform (experience with small fully detailed proofs, formal verification).
From what I see, the consensus now is that the serious work needed to prove P != NP has not really begun in the manuscript. If this is the case, as it appears to be, there is not going to be anything close to a proof of P != NP in the revised manuscript either, whether or not it is sent in for journal review.
So my interest is particularly focused on the thought process behind not retracting the “proof” at this point. Not so much for the social aspect (though I am curious about that too), but for the logical aspect. I.e.,
#) what role, if any, does lack of experience or familiarity with “fully detailed proofs” have in the release of the original manuscript, the release of the revised manuscript, and the absence of retraction of the claim?
60 manuscripts are listed at http://www.win.tue.nl/~gwoegi/P-versus-NP.htm Most of them are available there.
Does anybody know anything about how many of these claims of P = NP or P != NP have been retracted? Or have none of these claims been retracted?
Of the ones not retracted, does anybody know anything about other research activities of these claimants? Or how my question #) above might relate to these claimants?
I, like probably most people here, would never even conceive of releasing a claim to having proved P != NP (or P = NP) without being accompanied by a complete fully detailed proof. Absent that, I would at most put a very hedged statement like “we believe this approach has a reasonable chance of leading to a proof of …”, and probably weaker.
Obviously, the first priority here is to get to the bottom of the manuscript, any revised manuscripts, and the approach. But as things wind down, perhaps people will get interested in the questions I just raised.
How long for the “journal” to get back.
Personally, I opine that it doesn’t matter which statistical “distributions” he uses or doesn’t use. The use of statistical distributions or properties on problem-space or solution-space or intermediate-step-space simply isn’t strong enough to prove that a constructive solution is impossible. So it doesn’t really matter what Deolalikar means by “ampleness”, spatial-completeness, randomness, or anything else. If statistical distributions of any kind are the foundation of his “proof”, then his proof cannot possibly be complete (which means it would be a non-proof – just a set of interesting ideas.) My opinion.
Anonymous wrote: “Can one of the elite group of people who received a copy of the latest version of D’s paper, post it on the web for public consumption?”
– It appears from the paucity of public copies that Deolalikar has sent his latest manuscript exclusively to those scholars he considers to be his friends and supporters, and with a non-disclosure agreement to ensure his publishers get all the preeminence they deserve. I’m interested to scan through it and see if there are any fundamental differences – but I’m not biting my nails waiting for publication, to be perfectly frank.
journal will take how much time to answer.
Vinay sent the manuscript of the proof to a select group of researchers for review, which obviously included a few top-researchers in the field. I seriously doubt, if that group only included ‘his friends and supporters.’ In any case, he expected a review and feedback in a rather congenial manner. Instead for whatever reason, someone in the group (or in the resulting forward chain) decided to post the proof online – I seriously doubt if Vinay wanted this – or he would’ve posted it online himself. However, this forced him to (prematurely?) release it himself.
What followed was frenzied and very public ripping apart of the proof, by the likes of Tao, Gowers, Lipton, KWRegan, Immerman, for which I am sure even Vinay was not prepared for. Call it unprecedented collaboration of top notch mathematicians or whatever, certainly, the result is quite embarrassing for a career researcher like Vinay. I am sure he appreciates that Tao and others spent time on studying his proof, but the extremely public scrutiny was probably unwarranted, which I think was further exacerbated by the all the media attention the ‘news’ got. In a way, I feel sorry for Vinay. I am sure he didn’t bargain for this. The multitude of heavy weights were all looking for just flaws, while he has to look for explanations/workarounds/fixes for those flaws (projections? ;-). That too at a near impossible pace and not in a relatively relaxed manner that probably was his intent.
I’d say give Vinay a break. Let him recuperate a bit and gather his wits. He is not an unreasonable guy and neither a total amateur (after all he’s mathematician and a researcher). I’m sure he wouldn’t try to push a paper/proof that’s half-baked, more so, after his current ordeal. While it was okay to analyze his proof, I don’t think analyzing his motives or character is justified (argh! isn’t this post attempting the same ;-).
But I am sure it’d really help if the people here (at least identifiable ones) who identified the flaws in the original proof can at least confirm or deny if they received a copy of the updated manuscript. Tao, Lipton, KWRegan, anyone? They should have!
Roger,
No manuscript here
dick
Nor here. One point to note, Deolalikar’s communication speaks separately of sending the MS to a few researchers privately and then sending out for journal review. The latter is completely private—an automatic “NDA”, you’re not supposed to tell anyone you were even chosen. Here we are speaking about the former, on which giving an answer (which can still be “no comment”) falls under reasonable journalistic expectation.
It is good you (Roger Waters) reminded people that Vinay Deolalikar was “outed”. The NY Times article misses the actual sequence in saying he “posted … and [then] quietly notified”. I called attention to the actual sequence as documented on the original Greg Baker source to a contact I know there. But since the story’s essence that Deolalikar went ahead in public is still valid, I decided not to ask for a correction.
bay. Page 116 is very interesting.
Roger W – a clarification.
The “heavyweights” in this discussion (and I am NOT one of them, so needless to say I don’t have the said manuscript) have been justifiably constructive toward Vinay Deolalikar, in responding to V.Deolalikar’s paper with suggestions about how to convert his outline work into a complete and rigorous proof. I think most of them (T.Tao etc.) could be counted as V.Deolalikar’s “friends and supporters”.
We are all looking to get as much good as possible out of V.Deolalikar’s hard work on this very hard and interesting problem. No scientific paper should be accepted as a basis for future work unless it is first proven [as far as possible] that there are no potential flaws in it, or else, until its possible flaws are well known. This process of understanding, accepting and improving upon previous work involves constructive criticism, and also necessarily involves the “rejection” of any flawed components in the work presented. It’s in the nature of mathematics, and the subject’s “heavyweights” would be unprofessional to avoid applying real scrutiny to the basis of such an important work.
It’s a compliment to V.Deolalikar that even at this stage, we appear only to have outline counter-proofs to his work. Granted, some of the vagueness in the counter-proofs/ constructive criticisms offered might have been elicited by vagueness in V.Deolalikar’s own published work, and this vagueness/ elusiveness might in turn have been elicited by V.Deolalikar’s work being “outed” prematurely as you suggest; but whether V.Deolalikar’s work is ultimately right or wrong, this discussion is another milestone in our general understanding of this subject. Imagine if V.Deolalikar’s hard work only eliminates one possible proof-strategy from future consideration – this step might prove invaluable to the eventual resolution of the P/NP problem. Even in the worst-case scenario, his paper might save other professionals from wasting time on a dead-end method. His effort is to be praised, whether or not this work is correct.
It is time for friends who know VD well to talk to him. Given the unexpected public scrutiny, one never knows the kind of pressure he is under. For his own good and well-being, a conversation with his friends and colleagues @HP may enable him take a set of actions that will be appreciated by the community he is trying to impress. This may help avoid any damage, however unfair, to his reputation.
IN RESPONSE TO:
“However, this forced him to (prematurely?) release it himself.”
Nothing forced him to post his proof online! In fact, if he had refrained from posting it (along with updates, dedications, summaries, etc no less) even if someone else against his preference had posted it, there would be no criticism against him. Why? Because then it would not constitute a claim to the world that he had proved it. But in fact this is what his claim was and apparently still is.
I also did not receive a manuscript.
I think that the public scrutiny phase of this ms has basically been concluded. In fact, I can confidently predict that within the next 24 hours, the attention of the mathematical community will be redirected somewhere else entirely…
You spoke my mind. I sincerely hope that D’s paper withstands this onslaught.
As the self proclaimed top-notch researchers shamelessly tried to rip the integrity of this smart researcher, I have no shame in questioning the motive behind making this public without thinking of the consequences.
Did vloodin get a copy of the latest (revised) version?
Matthew:
I never said that “heavyweights” shouldn’t have done real scrutiny. In fact, such careful analysis is the intent of peer-review process, isn’t it.
However, I am not sure if the manner in which it happened was entirely justified. Media unjustly made him a hero (without any understanding of the review process), and then, equally unjustly, portrayed him as a quack. The real reviewers here on Lipton’s blog had been careful and very professional in their comments. However, some of the non-contributing-compulsive-blog-commentators, who weren’t content with watching from sidelines (and searching, reading and trying to assimilate stuff being discussed), started personally targeting D. and his motives, which, to be honest, I find appalling . All I’d say is put yourself in his shoes and try to fathom what happened in the last week or two.
I agree with you that correct or not Vinay’s work was useful. I must say, I benefited – I read about quite a few topics and go to know of the existence of quite a few new areas! It also lead to the sad-realization, how little I know.
Badri:
I just hope Vinay keeps his head high and is able to get back to normal life.
I also hope that at least something meaningful should come out of his work, so that at least it is not a total wasted effort (for Vinay and many other more accomplished people here who spent time analyzing the proof). This, I think, will also dictate how open the top-researchers will be, in future, to spend their precious time on analyzing such claims (instead of turning into more Scott Aaronsons).
Anon:
I don’t think the chain of events is entirely in agreement with your assessment.
Anonymous:
vloodin cannot get a copy because I don’t know if anyone here know who he is. The vicious side of my mind is trying to calculate the probability that he is a colleague of D.! 😉
Terence:
Certainly, the attention of mathematical community, media and the masses has already moved on to other things.
I don’t know where else to say this, but during the last few weeks, it was exhilarating to read your analysis and comments, and, I look forward to reading more of your work.
And most importantly, Vinay D., if you happen to read this:
It is only imperative that you provide the copies of your latest proof to the people on this blog who provided some constructive criticism to your earlier version. I think it is the respectful and honest thing to do.
You may request them to not discuss it in detail in public, or, maybe a section of the wiki can be made private for analysis.
But at least we all (the masses) will know that the right people are evaluating it. Otherwise, I feel, you risk denting your reputation as a sincere, serious and professional researcher.
Waters: I do not know who you are much more than you can guess identity of any of the people here who decided to post anonymously (though there are indications that you might be a fan of rock star Roger Waters and an entry level CS graduate student). Your comments however reveal a pretty nasty level of hypocrisy. The main point of the discussion here was to get to the bottom of D.’s paper, and understand what he was trying to do and weather there is any merit in it – this was perhaps the very first public review of a very public paper. Yet there was no “Roger Waters” here to help scrutinize and understand the paper. There is no evidence of your efforts to read D.’s draft, no questions that you posed about it. You experienced no frustration in dealing with D.’s constant hand-waving and lack of proper definitions for basic notions that he used. You provided no explanations, no arguments and ideas, offered no examples, counterexamples or shortcuts, and one can make a pretty good guess that you did not contribute to the wiki on dedicated polymath pages. It is not clear how much of the arguments even here you followed and appreciated, quite possibly an appeal to authority was enough (which is of course not unreasonable for some people). Yet somehow you find your call to judge, insinuate, advise and speculate about both D. and other people, whilst lecturing how one shouldn’t do what you are doing in all your posts.
To answer your insinuations, I am certainly not a colleague of D. who I have never met and do not even really care who he is. This whole episode reflects badly on HP researchers, I doubt that any of them are used to much mathematical rigor (which I am sure they do not need extremely in their daily work, though I wonder if it would help save HP some bugs in their products), which of course means that it is understandable that D.’s paper ended as it did, it is not something unheard of even for the much more rigor inclined researchers. I also do not belong to TCS people (my field is completely unrelated, of course P vs NP is a matter of general mathematical culture) and hence there is no reason why I would receive D.’s draft.
Had Waters ever cracked a longstanding question, he’d know about the passion, pain, fears and agonies associated with checking and rechecking crucial arguments and would understand the need to see if the proof finally goes through. Wanting to check a proof in discussion with someone is normal, and so are mistakes. So the unusual thing about D. is that he worked in complete isolation, and that he apparently did not confide in someone before e-mailing it to a relatively wide audience, that got the proof leaked. He cannot be blamed for the leak, but he did post the paper to his page afterward, all with public announcements that did not suggest a too great desire for privacy, riding on the media hype that raised him to stars. That eventually backfired, but the embarrassment is not so huge as some seem to think – this is after all one of the hardest problems known to math/cs. He is not going to be a new Jan Schoen. What he does next is matter of his integrity, but certainly he deserves some time to think things through, and realize that his paper is beyond repair, as it seems to be beyond reasonable doubt at this point.
Whoa! Whoa! Whoa! Take it easy, Vloodin, will ya?
I don’t understand, what was the intent of your detailed analysis of my lack of contribution to the analysis of proof. Perhaps you missed it, but I already stated in my earlier post, in response to Matthew, “I benefited – I read about quite a few topics and go to know of the existence of quite a few new areas! It also lead to the sad realization, how little I know.” In case it wasn’t clear to you, well, I watched the entire episode from sidelines, read and tried to comprehend the posts. I chose to keep quiet because I had nothing meaningful to add.
Why did I make the last few posts, now? Over the course of the week, I realized, as Vinay’s proof was ripped apart and more flaws emerged, the tone of the posts became nastier, including the tone of many of your posts towards the end. It was obvious that most of the top researchers who had identified themselves by name refrained from making any such comments. The anon posters didn’t. So I decided to chime-in and give my perspective, which was – while it’s alright to be ruthless when analyzing D.’s proof, categorizing him as a quack perhaps isn’t. For the concerns regarding apparent lack of transparency and hand-waving from D., my point was that these blog posts and comments and the wiki weren’t the review mechanisms that perhaps D. wanted or opted-for. Lipton and KWRegan both acknowledged this view.
I decided to post anonymously because I haven’t added any meat to the real discussion. At the same time, I wanted my posts to have some identity. Reason for posting as Roger Waters – after lot of struggle, I had scored Row 3 tix for the 09/28 The Wall show at Quicken Arena here in Cleveland the day I first posted, and I was ecstatic. Art and music are my present fields – and I am not a entry-level CS grad student, though I know a few very closely.
You seem to have been particularly offended by my speculation that you might be a colleague of D’s. It was a facetious remark, which you completely missed. After Terence Tao, perhaps you came up with most number of interesting points and displayed a remarkable command of the diverse topics used in proof – which practically rules out that you are an amateur. Yet, in a world hungry for credit, you decided to stay anonymous, which is little hard to digest. Conspiracy theorists would argue that – you are a colleague of D’s or still better, D. himself.
Next time no premature release of paper. Wait for satisfaction of reviewers then release! Otherwise problem.
@Roger Waters
“Conspiracy theorists would argue that – you are a colleague of D’s or still better, D. himself.”
Hello, I am a Professional Conspiracy Theorist and can confirm this.
Prof. Lipton asked in one of his earlier blogs
“is it possible for an amateur to solve the P/NP problem?”.
On a second thought – the question is almost equivalent to P/NP problem itself –
i.e.,
1. you consider an amateur to be a machine with smaller resources
2. the question at hand sounds analogus to a NP problem in the sense that – given a proof, one (or the community) can verify it in polynomial time ( 1 week in this case)
🙂
Anonymous remarks: Prof. Lipton asked in one of his earlier blogs: “Is it possible for an amateur to solve the P/NP problem?”
Terry Tao’s essay on the Clay Institute web site asserts: “I don’t believe that any field of mathematics should ever get so technical and complicated that it could not (at least in principle) be accessible to a general mathematician after some patient work … counterbalancing the trend toward increasing complexity and specialization at the cutting edge of mathematics is the deepening insight and simplification of mathematics at its common core … the accumulated rules of thumb, folklore, and even just some very well chosen choices of notation can make it easier to get into a field nowadays.”
Needless to say, the entirely of Tao’s essay is well-worth reading.
Moreover, from a historical point-of-view, amateurs (and students) have *really* shone at repurposing classical problems into new even better problems.
In CS and QIT, four works-by-students-and-amateurs that come to mind are Ralph Merkle’s early work on public key cryptography, Hugh Everett’s early work on many-worlds quantum mechanics, Stephen Wiesner’s early work on quantum money, and Raymond Damadian’s early work on magnetic resonance imaging, (and I would put Troy Schilling’s thesis under Abhay Ashtekar, Geometry of quantum mechanics, in this class too). These cases remind us that it does happen that students and/or outsiders do have very good ideas … even transformational ideas … that even the very greatest experts and specialists collectively have overlooked for decades.
But these cases also illustrate the worth of academic traditions and norms. Authors have an absolute obligation to help readers by respecting norms of behavior and presentation, by writing clearly, and by responding constructively to criticism.
In particular, it’s tremendously helpful—for students and amateurs especially—to work with coauthors; their criticisms and questions are invaluable. Also, never turn down an opportunity to present your work … pretty much everyone appreciates that speakers have learned more from preparing their lectures, than audiences ever have learned from listening to them.
None of the above are my own ideas; these opinions are so widely held in academia as to be nearly universal, and they are well-illustrated in this (still unfinished) Deolalikar episode.
I have absolutely nothing to disagree.
just wanted to bring out the artifically-perceived (for the lack of a better word) self-referential nature of the question – just for fun.
The self-referential nature of P vs. NP proves: “P=NP iff P!=NP”. This happens when you give a Turing machine a self-reference as an input. Try the Kleene-Rosser paradox.
Proof of: “P=NP iff P!=NP” – Syntactic.
The proof is by diagonalization as follows: We shall encode the Kleene-Rosser paradox as both the diagonal and its complement of a tabular representation of the class NP.
NP={L_1,L_2,L_3,…}
L_1={w_11,w_12,w_13,…}
L_2={w_21,w_22,w_23,…}
L_3={w_31,w_32,w_33,…}
Each string w_ij can be written as the Turing machine describing it which can be written as two substrings, the first its input and the second is the computation configurations:
= w_iw_j
Hence we have,
L_1={w_1w_1,w_1w_2,w_1w_3,…}
L_2={w_2w_1,w_2w_2,w_2w_3,…}
L_3={w_3w_1,w_3w_2,w_3w_3,…}
Note that both the diagonal and its complement can easily encode the Kleene-Rosser paradox as:
KR={kk_1,kk_2,kk_3,…}={Not kk_1, Not kk_2, Not kk_3…}
Use the encoding e(kk_i)=w_iw_i and e(Not kk_i) = \bar w_i\bar w_i
You obtain: e(KR) in NP iff e(KR) NOT in NP, then of course e(KR) irreducible to SAT iff it is reducible to SAT.
Hence, P=NP iff P!=NP.
This should not be surprising as the lambda calculus is equivalent to Turing machines. By direct encoding of the lambda calculus paradox, you obtain it on Turing machines.
This proof was syntactic, the same result can be reached via independently via semantics.
P.S. submitted to the Theory of Computing Journal 6.5 months ago.
P=NP iff !=NP proof – Semantics
The line of argumentation of Cook’s proof of CNF SAT being NP-complete is as follows (quoted from Lance’s blog equivalent to Cook’s paper you can check here in Prof Lipton’s blog – just A(w) instead of \phi(w)):
“Let A be a language in NP accepted by a non-deterministic Turing machine M. Fix an input x, we will create a 3CNF formula \phi that will be satisfiable if and only if there is a proper tableau for M and x”
1. Let w be the encoding of the Kleene-Rosser paradox, thus e^-1(w)=Not e^-1(w), where e is an encoding function.
2. M accepts w.
3. SAT is NP-complete, Cook’s theorem.
4. There must exists \phi(w):\phi(w) is satisfiable.
5. Then \phi(w) is satisfiable iff M accepts w iff e^-1(w)=Not e^-1(w)
6. M accepts w is “True”.
7. Then: \phi(w) is satisfiable iff e^-1(w)=Not e^-1(w) – Logical Contradiction.
8. Then There must be no \phi(w) which is satisfiable.
9. Then SAT is (NOT) NP-complete.
journal will take how much time to answer
I’m really not sure, it varies and depends on the paper, topic, editors, etc.
Wow! No wonder Vinay D. did not submit to a slowpoke boring journal.
http://people.cs.uchicago.edu/~fortnow/papers/growup.pdf
You’re waiting for 6.5 months now for a response from the journal?
Review the Clay website, it mentions “journal review may take years”
Hmm…
Is that why Grisha Perelman did not submit to a boring old journal for review … He submitted to the arXiv and alerted the experts – the media wrote a story and the experts worked on verifying it! On both accounts he won!
http://www.newyorker.com/archive/2006/08/28/060828fa_fact2?currentPage=all
http://en.wikipedia.org/wiki/Grigori_Perelman#Verification
http://www.doctoryau.com/hamiltonletter.pdf
Terry Tao posts (August 18, 2010 10:04 am): “I can confidently predict that within the next 24 hours, the attention of the mathematical community will be redirected somewhere else entirely …
Gosh … is this a hint that the curtain is soon to rise on a surprise TCS Act II?
If so, hurrah! … and in any event, TCS Act I has been truly wonderful … for which, this note is an appreciation and thanks.
He meant Field’s Medal announcement tonight.
Doh! … uhhh … wait a sec … nowadays it’s mighty hard to name a branch of mathematics that’s *not* of broad interest to engineers … so thank you sincerely, anonymous, for the explanatory heads-up.
http://en.wikipedia.org/wiki/Grigori_Perelman#The_Fields_Medal_and_Millennium_Prize
Well, discussion of the the “proof” has dwindled into some kind of embarrassed silence. But, hey, at least we were all a part of something really new, right? The first time that a purported solution to the P vs NP problem was widely and immediately discussed, all thanks to the wonder of on-line forums. Not quite, as a search through Google groups for “swart” and “np” reveals. If I recall correctly, the Usenet buzz at the time was much more widespread than revealed by this search.
The silence is a respectful one (respectful to both Deolalikar and Tao), since the leading researcher in this discussion (Tao) has adjourned the debate. We are following his recognised leadership. There appear to be no dissenters among the heavyweight researchers, on this point. If any new information becomes available, I expect that Professor Lipton will write a new page about it on his blog.
Has Vinay Deolalikar benefitted career-wise from his 15 minutes of fame?
There’s no such thing as bad publicity:-)
Thanks, that gives me hope 😉
Well 15 minutes of fame and months and possibly years of infamy (being the oft-cited precedent).
Not only was his proof minutely analyzed (which was excellent), but he is already being excused of ‘quackery’, deliberately not providing clarity, intentionally obscuring things in order to pass-off incorrect results as proof.
Vinay’s original email mentioned that he worked in isolation on this and not even his co-workers knew about it. In the cut-throat world of an industrial research lab, there would be colleagues who are quite happy to see Vinay’s debacle. There will be smirks and hushed conversations on why he did it and how’s he coping with it. His competency would be doubted on perhaps unrelated areas too.
(OK perhaps I painted too morbid a picture, but you get the drift…)
And, you both are not researchers, are you?
Read “accused” instead of “excused” – changes the meaning completely.
Such an error in a ‘proof’ would prove P=NP instead of P!=NP
“Has Vinay Deolalikar benefitted career-wise from his 15 minutes of fame?”
This question is irrelevant to most of us, although we do wish him well, and wish well to all who may attempt such works. Roger Waters states:
“The real reviewers here on Lipton’s blog had been careful and very professional in their comments.” Indeed. If I were in Vinay Deolalikar’s shoes, I would ignore everyone apart from the recognised heavyweights, who have done enough hard work to know what it must feel like in Deolalikar’s shoes, having had their own experiences of failure in ambitious projects.
News journalism rarely presents an accurate and complete version of reality, even in non-technical fields. Anyone who has had any news published about them, or something they were involved in, should know this. I doubt V. Deolalikar’s HP research colleagues will be taking the news media seriously, as I’m sure they must be serious people. V. Deolalikar still appears to have access privileges to his personal space on HP’s web servers, so we might see more from him in the future. We should not be surprised, and neither should his HP colleagues; if this experience stimulates him for more conscientious future works.
It is also doubtful that any real research heavyweights will be put off from investigating future claims – the mind of a true researcher is too inquisitive for that. Terence Tao has been wise to adjourn this discussion for now – let’s follow his example and wait until new information is made available for comment.
Industrial Research is cut-throat? I thought university research was cut-throat back-stabbing! An industrial researcher can move to one of several companies and work at any level. Can also start a business.
A career academic cannot move and act freely because his or her reputation moves with them wherever they go in academia. Also they are running like a hamster on a wheel to get tenure.
http://en.wikipedia.org/wiki/2010_University_of_Alabama_in_Huntsville_shooting
If industrial research was cut-throat, Vinay D. would not have been motivated enough to have spent 2 years of his personal time working on the problem.
We don’t see many academics/ university researchers motivated enough to have done that except Andrew Wiles in the UK. University researchers must be suffering through their lives, and Vinay D. must have a higher salary too?
http://people.cs.uchicago.edu/~fortnow/papers/growup.pdf
And an American one (Kepler Conjecture, computer aided proof, considered 99% solved):
http://en.wikipedia.org/wiki/Thomas_Callister_Hales
http://en.wikipedia.org/wiki/Kepler_conjecture
It surprises me how much background is required even to comprehend the Synopsis.
If this proof were being standardized under ANSI guidelines I would expect a lot
of technical terms would need to be defined in the glossary. Most of them may be familiar to researchers in the field but maybe not to new grad students. Here’s the list I came up with, leaving out words arguably used in their ordinary English sense like “interacting”,
“partial assignment” , “iterated”, and “patch”.
1. system of random variables
2. graphical model
3. directed graphical model
4. distribution of system of random variables
5. parametrization of distribution of system of random variables
6. Gibbs potentials
7. recursive factorization of a directed graphical model
8. LFP operator
9. FO(LFP)
10. polynomial time
11. successor structure
12. flow of information in FO(LFP)
13. directed flow of information
14. embedding of flow of information
15. larger graphical model
16. FO(LFP) query
17. run of a query
18. final assignment of a run of a query
19. LFP (of some fixed arity)
20. solutions of a query
21. distribution of solutions of a query
22. representation of LFP computation by directed graphical model
23. monotonicity of an operator
24. parameterization of a directed model
25. paramaterization with Gibbs potentials
26. mixtures of models
27. sheaf-like property
28. positive first order formula
29. operator which comes from a positive first order formula
30. independent parameters
31. joint distribution over a mixture
32. joint distribution over all mixtures
33. random k-SAT
34. hard phase of random k-SAT
35. the core
36. clusters
37. P (see also 10.)
38. NP
If providing these definitions is pop quiz 1 in the complexity class may I suggest
that the quiz be given open book?
Micki
Even with a full draft of the paper in front of you (an “open book”), you cannot make out what these terms are. For example, there is/was no formal definition of “independent parameters” in the paper… the commenters here (led by Tao) had to construct a best guess of what was meant. Same goes for many of the other phrases.
This has been an EXCELLENT example of how coordinated debate and discussion via simple web-based communication can further Mankind’s progress.
Mr Deolalikar’s belief that he had proven P!=NP has (by now generally accepted) been disproven should be recorded as an Historic Milestone; not in terms of the outcome, but more in terms of its method and speed.
Gratitude should be accorded to Mr Deolalikar – who quite possibly may have forseen that eventuality? (It would be fitting indeed if some person of unquestionable integrity were to now publish a prior disclosure from Mr Deolalikar stating that the disclosures he made just a week ago were intended to excercise the VEHICLE, not its “load”?)
I encourage all to take a step away from the current excitement of the hunt, and to examine the territory and “hue and cry” employed in discovering that the fox was, in fact, a false trail.
No-one died.
Everyone gained!
Three cheers for Mr Deolalikar – an unveiler if not a Prize winner.
PS: I have virtually NO conenctions with the sharp end of mathematics research, nor have I any connection, friendship (or hatred) of Mr Deolalikar.
As considering the above comments,and give the below two points:
1.If P=NP, then the solution space of any k-SAT problem with at least one solution, supports a ppp distribution.
2.The hard phase of k-SAT does not support any pp distribution.
we may simply got the prove that np(or hard) questions were all below the solution space with singularities that can (or can not) be wiped out with topological surgery.
Because P questions have a solution space without singularites, so If we can prove that NP questions have a solution space with singularites, we may simply got the prove that P!=NP.
above two opinion seems confusing,but in fact they are physically different!
the first opinion measured by the method of pp or ppp was not by the meaning of a Turing machine while the second opinion was.
By the help of Tao’s counter example, we can prove that a Turing machine can’t find any singularities of P or NP problems and on the contrary a Poly machine will do.
Assume that the parameterizability of a PP machine is the ability to classify the complexity of various solution space, which may classified according to the invariant of Topological space, and the diagram of complexity-classify may similar to Neil Immerman’s “world of computability and complexity”,then we can found algorithm on pp machine new,that is wholly differet to Turing machine,after this process,we can combined the pp machine with Turing machine through a mirror-bridge,and in the process of combining some details may not lost and finally we can get a poly machine logically very like our brain.
Maybe an interesting question about the above 5 statements are how the singularities to be find and how the complexity to be classified,to answer such a question,we may review two articles of rjlipton:one is “Projections Can Be Tricky,August 19, 2010″and another is “Computing Very Large Sums,June 9, 2009”.in short,these two articles give out two insights as:”Projections can be tricky “and”Computing exponential size sums are sometimes easy and sometimes hard”.thees insights are really important for us to find the entrance of NP problems.
now we look into the tracendental number, we can hold the idea that the pp property or parameterizability realized by a poly machine are always have trancendental number as parameters in the polynomial algorithm.
Hello I am just wondering if anybody still has a copy of D.’s proof. The link is broken on the HP website?
To see an early version of the paper you could Google
scribd pnp12
Also, sometimes searching for
cache:
succeeds.
A trancendental number means what?
If your mathmaticians don’t mind, I’d like cite the Shark’s post under the topic of “A Proof That P Is Not Equal To NP?”, which can be found at here (http://rjlipton.wordpress.com/2010/08/08/a-proof-that-p-is-not-equal-to-np/#comment-4768)
\\\\\\\\\\\\\\\\\\\\\\\\\\\\
“Shark permalink
August 10, 2010 5:49 pm
P != NP is clearly true except in the trivial case of N = 1 and N = 0.
In all other cases, P != (N) (P)
What are you guys talking about – where is the million dollars !!
Reply rjlipton permalink*
August 10, 2010 5:54 pm
Shark,
There are other proofs based on similar ideas.
Reply Anon permalink
August 11, 2010 8:42 am
Prof. Lipton, I really admire you that in the middle of so much you kindly replied to foolish comment of Shark.
Sherman permalink
August 14, 2010 5:46 pm
I lije your humor. ”
\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\
Maybe, we’d better know that Shark’s “trivial” proof not only untrivial but also is a definitely genious insight,for a reason that we do agree “1” and “0” are two foundmental models of logic both in our brain and the computer, as I’ve mentioned above,they’re obviously different when we consider the meanings under the model.
We all know that on the aspects of physics,there’re two differen’t models too.one is the “Classical Physics” and the other is “Quantum Physics”.we also knew the latter is “upward compatible”. namely under “Quantum Physics”, we can only denote the meaning of our problem by wave functions.
Whether it could be taken to compare with the difference between a Turing machine and a Poly machine?Surely,we can!Because the logic of proof also is based upon these two models which we called “Law of contradiction” and “Law of identity”.A Polynomial or Non-Polynomial problem do have a solution space which is according to the Laws of logic, and just in the solution space, the question and the answer are identified with “1” and “0”.
so the P vs NP question now is transformed to: the wave functions how to be projected to the classical functions,and the answer we expect must depends not only on describing it superfacially but also how to ask the Non-Polynomial question with wave functions.
We knew that “Mahler classified the complex numbers into four classes, but he did so considering the values of polynomial expressions close to zero.”
the four classes “A\S\T\U” are differenciated by boundaries throughout approximate which were all hold in a generalised continued fraction form.e.g,pi and e are not Liouville numbers.
hence, “Mahler’s classiffication as a ‘measure theory’ way of seperating the transcendental numbers out.”
Considering the definition “A transcendental number is defined as a complex number that is not the root of a non-zero polynomial equation with algebraic coefficients.”
and prof.John Sidles have made this statements “Now, whenever it happens (as in Hilbert space), that any one of the metric, symplectic, and complex structures can be computed from the other two, the resulting state-space is said to be Kählerian. ”
maybe we can made a final arguement about the NP problems like this :some of them can be descibed by wave functions with corresponding patterns and others we can’t!
and thats the answer to the two questions already been asked above reply.
IS THE LAST THEOREM OF FERMAT AN EXAMPLE OF NP PROBLEM… BECAUSE IT IS SO HARD TO PROVE BY COMPUTERS… …
and in the same way any solution of that theorem is easily verified in a computer too… but its prove is so hard so it necesarily requieres a mathematical prove…
A couple of people wanted to aid me, but no one tended to make me understand this problem more clearly than you. I am waiting for you to publish more.