Old Ideas And Lower Bounds On SAT
Known lower bound methods for SAT

Fred Hennie was a professor of Electrical Engineering at MIT for many years, who did seminal work in the theory of computation. He is famous for a number of beautiful results on lower bounds, as well as work on algorithms and even discrete mathematics.
Today I want to talk about attempts over the years to get lower bounds on SAT. Of course if P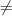
The lower bounds on SAT use connections between old ideas and new ideas—between problems once studied for their own sake and problems that now are considered central.
The Models
The models we are interested in are all single-worktape Turing Machines (TM’s). Well, that is a lie: the models we are really interested in are multiple-tape Turing Machines, but no one seems to have a clue on how to get even an 
Here are the three models of Turing Machines that we will discuss:
Sometimes the basic model was called “off-line,” and other times the last model was called this too. This has confused me—so be careful when reading any papers in this area. For some reason the names shifted years ago, and this shift can cause lots of confusion. I wonder if the confusion might have been driven by the interest years ago in real-time computations.
A computation that computes a function in real-time must output a bit every step of the computation. This type of computation was interesting because it is possible to actually prove lower bounds on them. For example, it is still impossible to prove non-linear lower bounds for multi-tape TM’s for natural problems that are in polynomial time. Fifty years. No progress. None. However, Mike Paterson, Michael Fischer, Albert Meyer were able in 1974 to prove strong lower bounds on an even more inclusive model of computations for integer multiplication. Their proof used a method called the overlap method created by Steve Cook and Stål Aanderaa in 1968. I think that this concept and their work is one of great results in complexity theory—I will have to discuss it in detail in the future.
Hennie’s Result
I believe that Hennie proved the first quadratic lower bounds on the basic model. Note, his result shows that the bound is also tight.
Theorem:
recognition requires
time in the basic model.
Recall a string 
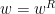
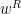
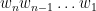
“No, it never propagates if I set a gap or prevention.”
More than the result what was interesting was the proof method. Hennie used what is called a crossing sequence argument. Roughly, he showed that in testing if a string is a palindrome the tape head would have to move across the middle part of the tape order-
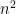
Since Hennie
There have been many results since Hennie’s pioneering paper. Many of these papers use crossing sequence arguments, sometimes variations of the original method. I will just summarize some of the main results—I apologize if I have left out your favorite results.
- Wolfgang Maass proved a similar lower bound on the basic model with a one-way input tape.
- Dieter van Melkebeek and Ran Raz proved a pretty result on a model that is even stronger than the basic model plus two-way input. They allowed random access to the input and still proved a lower bound of order
where
.
- Ryan Williams in this paper has recently proved related and even stronger results.
The results by van Melkebeek and Raz extend to Turing machines with one 
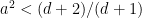

Toward Even Stronger Bounds
The stronger results by Ryan Williams are based on the fact that SAT is complete, which is something that Hennie did not have available to him back in the 1960’s. Also at the time it was interesting that relatively simple languages could be used to get lower bounds. Today we are more interested in SAT than any artificial problem.
Ryan in his paper also gives evidence that getting much stronger lower bounds on SAT via these methods will require new ideas. Perhaps they are already out there, perhaps not.
One question I believe is open is: what happens here for probabilistic one-tape machines? I am especially interested in these since they are related to getting lower bounds on practical SAT algorithms such as GSAT. Recall that algorithms like GSAT operate as follows: They select a random assignment for the variables, and then look for an unsatisfied clause. If there are none, then they have found a satisfying assignment. If there is an unsatisfied clause, then they randomly pick such a clause and flip a variable.
The key point is this: any algorithm of this type can be implemented efficiently on the basic model plus a random access input. Thus, suppose van Melkebeek and Raz’s theorem could be improved to work for probabilistic TM’s. Then it would follow that any algorithm like GSAT would take at least 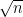
Open Problems
One problem is to check the details that GSAT style algorithms can be implemented as claimed. The much harder problem is to show that the lower bounds can extend to randomized TM’s.


> One question I believe is open is: what happens here for probabilistic one-tape machines?
I also think that is open.
However, you can prove a lower bound for QSAT_3 on a weaker model where the (unbounded sequential-access) work tape is initialized with random bits
http://www.ccs.neu.edu/home/viola/papers/BPvsE.pdf
This uses the INW generator to reduce the number of bits to sublinear, and then uses standard tricks. The use of generators is inspired by the previous work by Diehl and van Melkebeek.
To extend the lower bound to the more natural model in which you can toss coins at any point, you would need a stronger type of generator for that type of machines. I once looked into this and I remembered that the necessary worst-case lower bounds are known, but a psedorandom generator is not, which seemed a nice problem in pseudorandomness.
The same work http://www.ccs.neu.edu/home/viola/papers/BPvsE.pdf also discusses what is an obstacle in proving a lower bound for SAT. That’s because the Sipser-Gacs-Lautemann simulation of BPP in Sigma 2 incurs a quadratic blow-up, which is too loose for the trading-quantifiers techniques. The simulation can however be made quasilinear in the 3rd level, which is what the proofs use.
Emanuele
Emanuele,
I will have to apologize for not referencing your paper. I will look at it and plan to discuss it soon. It seems very nice.
Thanks
Don’t we know that GSAT or Walk-SAT requires sqrt(n) flips from arguments similar to the number of steps local search on the hypercube needs to find a local minimum of a function? (Aldous, Aaronson)?
I know that you don’t want to distinguish the two but GSAT has an extra minimization step over all variables which clearly can’t be implemented efficiently on a 1-tape TM. The correct versions to use are WalkSAT which works more like the version you say. (What you describe seems more like the pure random walk version that Papadimitriou showed was O(n^2) for 2-SAT and Schoening analyzed at (4/3)^n for random 3-SAT.) (A simple version of Walksat picks a random unsatisfied clause, will look for a free flip (one that won’t make any other clauses unsat) first (not in the original form but a big win in practice), if none is found it will flip a random variable with probability p and with probability 1-p will pick the “best” flip in the clause – one that leaves the fewest other clauses unsat.
It is not even clear that EACH assignment flip that the WALKSAT algorithm makes can be implemented in linear time in the input size on a 1-tape TM with random-access input. There are two pieces of information – the current assignment and the set of unsatisfied clauses that must be maintained. Given only the assignment it would be more than linear time to calculate the UNSAT clause list from scratch so one needs to maintain the current list of unsat clauses on tape. (I will assume 3-CNF so one would maintain the bit vector of which literals in each clause are currently true.) One can clearly scan this to randomly choose such a clause. One can then scan the clauses to see which ones have changed Moreover, once one flips a bit one needs to update the current status of the clauses (which is order of the input size – a log n factor bigger than the # of literals though still linear in the input size.) The additional cost of doing WalkSAT stuff would still be linear for 3-SAT since one could “try out” each flip in turn.
However, I do not see how to do each step in time proportional to the number of literal occurrences of the literals in the chosen clause (which is the amortized time that WalkSAT REALLY runs in per bit flip and is often constant per step). One can even assume to make things easier that in the randomly accessible input presentation you also have the inverted table that in augments the list of clauses by lists of which clauses each literal appears in. (This doesn’t seem like cheating since it is fixed once and for all but maybe it breaks the lower bounds.) It seems clear that with this additional information one can access the clauses that need to be changed but one still can’t get to the record of which clauses/literal occurrences are satisfied without scanning the whole formula which is linear. Also the assignment and the record of satisfied clauses would need to be in different parts of the tape so even sharing information between them would be hard.
Is linear time on a 1-tape per bit flip an OK simulation?
Sorry about the typos. Bottom line: linear time per bit flip seems OK but doing better doesn’t.
Paul: Yes, I believe this is what Dick has in mind. If each bit flip can be done in linear time, then (intuitively) a n^{1.5} time lower bound implies that at least n^{.5} bit-flips are needed, infinitely often (for one-tape machines that get to spend n^{1.5} time picking their initial assignment).
Knowledge Recognition Algorithm (KRA) as a new idea with possible low bound on 3SAT
From KRA aspect, all languages are organized in the form of member-class iterative-set relations as knowledge between two mirrored languages. An instance of 3SAT is a set of specific knowledge. That is, each 3SAT problem contains m disjunctive clauses, and each disjunctive clause can be represented by a set of eight conjunctive clauses including one complement. For example, disjunctive clause (x1 ∨ x2 ∨ ~x3) can be presented by a set of eight conjunctive clauses {(x1 ∧ x2 ∧ x3), (x1 ∧ x2 ∧ ~x3), (x1 ∧ ~x2 ∧ x3), (x1 ∧ ~x2 ∧ ~x3), (~x1 ∧ x2 ∧ x3), (~x1 ∧ x2 ∧ ~x3), (~x1 ∧ ~x2 ∧ x3), (~x1 ∧ ~x2 ∧ ~x3)} in which a 3-variable-clause (~x1 ∧ ~x2 ∧ x3) is a complement of (x1 ∨ x2 ∨ ~x3).
In the knowledge (iterative set) structure, each 3-variable-clause C3 contains three 2-variable-clause C2 as its members. For example clause (x1 ∧ x2 ∧ x3) contains three 2-variable-clauses {(x1 ∧ x2), (x1 ∧ x3), (x2 ∧ x3} as its members. Each 2-variable-clause C2 may belong to multiple 3-variable-clauses C3.
Each 2-variable-clause C2 contains two variables as its members. Each 4-variable-clause C4 contains four 3-variable-clause C3 as its members. Each 3-variable-clause C3 may belong to multiple 4-variable-clauses C4.
Different from conventional 3SAT algorithms, KRA does not search assignment directly. It recognizes the complements as rejections at each level of the set through iterative relation recognition. That is, KRA recognizes which conjunctive clause is not satisfiable. If all the eight clauses of any set are rejected, then there is not assignment for the formula. If there is at least one clause in each set that remains, then there is at least one assignment that is the union of clauses of each set. If there are more than one clause in each set that remain, then there are multiple assignments that are the unions of the clauses of each set respectively.
Dick,
How about using a virtual “Oracle” tape on the basic “one-tape”, read from and write to both the tapes, especially write set relations “belongs to” and “contains of” between the two types? That is, let the string of the basic tape as the member of the string of the Oracle tape iteratively.
Prof. Lipton,
Amazon sent me an email saying your book shipped yesterday, so it’ll be in the hands of the unwashed masses on Tuesday. =)
Has anyone heard of the supposed proof that P=NP, published in a peer reviewed journal – Journal of Indian Academy of Mathematics, Vol 31, No 2 (2009), pp 407-444, by a professor Narendra Chaudhari, professor at IIT. He has a respectable list of mainstream publications (genetic algorithms and similar stuff). Is this proof wrong? Why is noone paying attention? His article is written in a standard form, with explicit explanation of the algorithm. Given that this blog is taking a somewhat unortodox view (that in fact P might be equal to NP), and that Journal of Indian Academy of Mathematics seems to be mainstream, and that professor Narendra Chaudhari seems to be mainstream, and that IIT has already given us some surprises (PRIMES in P), it makes sense to ask – has anyone heard of this? The paper is published almost a year ago (in November 2009.) and journal has reasonable mathematical reputation, so either article was found to be wrong, or this journal is completely ignored. If that is so, then why? Clay Mathematics prize for a good reason gives 2 years for community to digest such proofs, but noone seems to be aware of this, even though it is published in a peer reviewed journal apparently published by Academy of Sciences of the India, which supposedly counts as mainstream.
Here is list of some of the mainstream publications of this guy:
http://www.informatik.uni-trier.de/~ley/db/indices/a-tree/c/Chaudhari:Narendra_S=.html
Here is scanned copy of his paper.
http://dcis.uohyd.ernet.in/~wankarcs/index_files/pdf/Vol-31-No-2-2009-pp407-444-scanned-copy.pdf
Here is link of some seminar talk from which I got this info (from this link, I searched for Deolalikar and hence found this by accident).
http://dcis.uohyd.ernet.in/~wankarcs//index_files/seminar.htm
Can someone please answer the following questions:
1. Is this publication known to people in TCS? If so, is it wrong?
2. If it is not known, why is noone taking this publication seriously? Is reputation of the journal bad, or are people just isolated from what goes in India?
3. Given that PRIMES in P was quickly checked and confirmed, why it didn’t happen with this paper? Are people so saturated with cranks who “prove” P vs NP that a mainstream publication from India is ignored?
4. If this proof is wrong, how did it pass peer review in this Journal? If this happened to some western Journal it would be a well known incident, a serious dent to its reputation (though wrong results do occasionally pass peer review, and even get to Science or Nature). Does no-one care?
It appears that this proof is wrong. He essentially uses the clause method, but then claims that it is polynomial, since his list of clauses can only grow to be O(n). But there can be exponentially many clauses?! Each clause can grow to the size of O(n), but the number of such clauses is exponential. Unless they do not contain negations, but he allows that, this is like Horn-SAT, only it isn’t. Somebody should check this, it is really strange that review is so sloppy in such a reputed Journal/or if it is not that this journal is ignored.
It looks like some people are at least aware of the paper, as it’s #57 on this list:
http://www.win.tue.nl/~gwoegi/P-versus-NP.htm
Interesting, from now on any post about new P vs NP claims are censored from this blog, even when they are published in a peer reviewed journal of the Indian Academy of Sciences by a professor of Indian Institute of Technology. Is censorship really what you want?
I am skeptical as to how well “peer reviewed” the journal in question is. It is not of the better known “Indian Academy of Science” (www.ias.ac.in)(which if I recall correctly was founded by CV Raman, and has had some distinguished fellows in its more than 75 years of existence) but of the so called Indian Academy of Mathematics, which I never heard of even when I was a student in India((at IIT Kanpur, on of the older IITs).