The Meaning of Omega
And the meaning of the recently-broken metric TSP approximation ratio

Andrew Stothers wrote in 2007 a first-year qualifying report for the University of Edinburgh PhD programme. In only eleven pages he presented the parts of the famous paper by Don Coppersmith and Shmuel Winograd (CW) that do enough to obtain 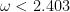

Finally, it will also be possible to investigate bilinear algorithms further and use more complex means to determine whether or not “better” algorithms exist for matrix multiplication.
Today we wish to explain what 
I (Ken) wrote a similar first-year qualifier in summer 1982 after my first year at Oxford—they are a staple of leading British universities. Like Andrew’s it was not obligated to have original research, just to demonstrate understanding and capability. One item found its way into a conference paper, but my 1986 dissertation ranged into various other topics.
What distinguishes Andrew’s Nov. 2010 dissertation is its singular focus on accomplishing the objective of his proposal. And doing it. The resulting paper with his advisor Sandy Davie has recently been submitted. Meanwhile in North America, Virginia had been thinking about the same problem since 2005. It may not be true as asserted here that “hundreds of people tried to improve” it after 1987, but we’ll guess about as many people thought about it. It’s enough to note that many researchers felt it worthy of pursuit, including Andrew’s advisor, and that progress took large concerted effort. The nature of this effort—including the use of computers—may be an important harbinger for science by itself.
What Does ω Mean?
The definition of 

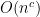

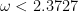
As many have noted, 
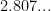
One of the central questions in physics is, why do the fundamental constants of nature have the values they do? The desire for why, in the face of evidence that the values could be arbitrary, has aroused such passion that string theorist David Gross channeled Winston Churchill in exhorting young physicists to “never, never, never give up.”
Now in mathematics it may seem nonsensical to ask, why do numbers like 

Barriers and Breakthroughs
Hence also the interest in whether 


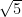
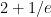
The value 
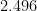
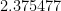
The Salesman Always Rings 1.5
The Traveling Salesman Problem (TSP) seeks the shortest route to visit each of a given set of sites, coming back in a ring to the starting site. When the sites are in real space and “shortest” refers to Euclidean distance, finding the length 


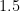
This

Actually their original paper did not give a value—it merely proved the existence of an 


Improvements and Predictions
It must be said that the OSS paper and its predecessor introduced techniques that were more novel to the problem than is evident for the new matrix-multiplication papers, and the predecessor won the SODA 2010 “Best Paper” award. However, a referee could have wondered, why bother moving heaven and earth in a restricted case to demonstrate an increment a thousand times smaller than “nano”? Indeed the version of OSS linked above still ends with “
What happened is that the change attracted interest on several continents, and the people in Europe who made a bankable improvement are not even in the euro zone. First Tobias Mömke and Ola Svensson of KTH in Stockholm obtained 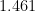
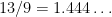
It is noted by all that an even older paper by Michael Held and Richard Karp from 1970 had set a believable target for provable improvements of Christofides’ bound, namely a conjectured ratio of 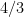
We note that Markus Bläser has contended in a comment that the extension of CW used by both new papers has limitations, and we infer that some other experts concur. However, the paper by Vassilevska Williams in particular has two new ingredients: a framework for managing any tensor power as a base algorithm, and a computer implementation of the framework. She also employed an insight of Stothers to simplify the analysis. Though we can imagine a geometrical insight that higher powers bring returns that “shrink geometrically,” can we really constrain the likelihood that pursuing them might dislodge a different insight that changes the whole game? Is there a limitation theorem here? All we know is that the game has changed, and perhaps the game is afoot.
Worth and Values
The last issue we wish to raise is the reliability of judging the worth of past achievement by present assessment of what it may or may not lead to in the future. We have posted several times on surprises and the difficulty of predicting or guessing how things will go. Of course impetus into the future is necessarily part of claiming something now a “breakthrough.”
However, if we seek a reliable and consistent standard of judging worth, we should use a value that the community has understood for many years: intellectual substance and effort. This value, plus the simple salience of the goal, led our principals to invest the years of work in the first place. Depth of thinking is our gold standard, while applicability is our paper currency. The improvements of 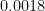

Dick and I hope this explains why fundamental effort and easily-stated achievement, on a fundamental problem after nearly a quarter-century of stasis, elicited the reaction it has. We agree with, and have tried to extend, Timothy Gowers’ comments here. As for how these values can be invested, only time will be the teller.
Open Problems
Can we be more open about the value of pursuing problems?
What is
Suppose we know something special about two 

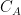

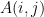

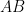
[corrected Ola Svensson’s name]
Trackbacks
- Weekly Picks « Mathblogging.org — the Blog
- Cup Sets, Sunflowers, and Matrix Multiplication | Combinatorics and more
- Leprechauns Are Tricky « Gödel’s Lost Letter and P=NP
- Leprechauns Are Tricky « Gödel’s Lost Letter and P=NP
- No-Go Theorems | Gödel's Lost Letter and P=NP
- Genius at Play: The Curious Mind of John Horton Conway | Short, Fat Matrices
- Limits On Matrix Multiplication | Gödel's Lost Letter and P=NP
- Baby Steps | Gödel's Lost Letter and P=NP


Quantum mechanics is how nature multiplies matrices. Feynman path integrals (which are fundamental to non relativistic quantum mechanics and relativistic quantum field theory and string theory) are essentially a way of multiplying matrices. And the world is not classical dammit, it’s quantum mechanically, as Feynman reminded us. So if you want a truly fundamental limit, shouldn’t you be including quantum mechanics?
I did insert the word “classical” before “model of computation” when defining omega to anticipate (but not say) this kind of comment :-).
How do you multiply non-unitary matrices in QM? 😉
Just curious on this important work. So is the basic idea to use Strassen’s 7 multiply algorithm for 2×2 matrices and generalize that to 2^kx2^k matrices using tensor powers and in this case k = 8?
Interesting work,
No it is more complex than that. Another object is raised to a high power—a tensor power. Then that object is used to find a matrix product algorithm.
Is there a place I can read the synopsis of what the general idea (including some nice see through details and big picture)? Her paper looks well written but still looks beastly for someone new to the field. Thankyou for the help.
Also say if someone finds 3×3 times 3×3 can be done in 21 steps, would it improve present exponent? If so, by how much?
I guess by your ref to “her paper” you’ve already read our description in the previous post, and of course there’s Stothers’ survey linked in the intro but it gets to brass tacks of the CW method real fast. For brass tacks of other methods, there is this 2008 survey by J.M. Landsberg, which actually has the stuff most of interest to me in all this (polynomial ideals/varieties, quantum, phylogenetics/DNA). Unfortunately Joachim von zur Gathen’s 1988 survey and Strassen’s 1991 survey seem to be behind e-walls; I could dig for others but my kids need this machine. The popular text by Cormen-Leiserson-Rivest(-Stein) has a chapter-or-section(s) devoted mostly to Strassen’s algorithm.
The answer to your second question that simply follows Strassen would be the log-base-3 of 21, which Google tells me is 2.77… Just a little better than 2.807… I don’t know how much more could be based on that—enhancing the basis is the main strategy of the two present papers.
@Interesting work
It turns out that multiplying two 3-by-3 matrices provably takes more than 21 scalar multiplications. However, two 48-by-48 matrices can be multiplied with only 47,217 scalar multiplications, yielding an exponent of 2.7801…
@Kenneth W. Regan Thankyou a lot. The Geometric introduction to MM is very interesting. I am going to look at it.
@anon: I do not think 21 lower bound is proved. The best lower bound is 19. I just looked at page 18 of Stothers Thesis.
@Kenneth W. Regan: Your phrase “enhancing the basis” – what does it precisely mean?
It is confusing because basically any combination Ola, Olaf, Olav, Olle, Ole, Olof, Olov, Ulla (female) results in a scandinavian name but my name is Ola 🙂
Thank you and sorry—updated. Dave AGP raises a good question about my inference below.
I am too curious not to ask, is it verifiable that Svensson and Mömke were attracted by the OSS result as you suggest? I couldn’t tell from their arXiv version (no mention of “inspired by,” but not “independently” either).
To be clear, in either case both of their results are quite beautiful! And I like hearing more about history and motivation (if accurate)!
We were working on the problem and had some results such as the subcubic case before the announcement of the OSS result.
That said, the OSS result improved the performance guarantee for general graphs and made us more determined to also do that with our approach. So from my perspective, this motivated us to work and think harder.
In short, the techniques are different and independent but the OSS result inspired us to work harder.
Thanks!
Another recent breakthrough of this kind is http://arxiv.org/abs/1103.6161
“The Grothendieck constant is strictly smaller than Krivine’s bound” by Mark Braverman, Konstantin Makarychev, Yury Makarychev, Assaf Naor, also to appear in FOCS 2011
Colin McQuilian,
I was on that committee and agree that the improvement to the Grothendieck constant was a quite neat paper.
Please let me say that for eminently practical reasons this general topic (the computational complexity of linear algebraic systems) is immensely interesting to us simulationists.
It is notable in particular that the Braverman-Makarychev-Makarychev-Naor article expresses a Great Truth: “We chose not to state an explicit new upper bound on the Grothendieck constant since we know that our estimate is suboptimal” which nicely complements the Great Truth that Andrew Stothers and Virginia Vassilevska-Williams both wonderfully contributed to mathematics in providing such upper bounds.
That these opposing great truths can creatively and amicably coexist is (to me) the sign of a healthy culture of mathematics — long may this peaceful coexistence continue!
As a non-specialist, a continuing source of puzzlement (to me anyway) is that steady improvements in upper bounds for algorithms that multiply general matrices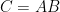 are not accompanied by better bounds for solving general linear equations
are not accompanied by better bounds for solving general linear equations 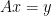 ; the former having complexity
; the former having complexity  for
for 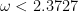 (and decreasing) while the latter has complexity
(and decreasing) while the latter has complexity  (and seeming stuck at this value (?) ).
(and seeming stuck at this value (?) ).
Is there some obvious-to-experts reason why the problem of general matrix multiplication is yielding progressive improvements in computational efficiency, while the complexity of solving general linear equations remains fixed at ? If so, what might be that reason? And is the problem of solving general linear equations “pleasantly parallelizable” in a way that helps us understand this discrepancy?
? If so, what might be that reason? And is the problem of solving general linear equations “pleasantly parallelizable” in a way that helps us understand this discrepancy?
As a followup, the Russian mathematician V. I. Solodovnikov wrote two articles in the late 1970s and early 1980s, titled “The extension of the Strassen estimate to the solution of arbitrary systems of linear equations” (MR538927) and “Upper bounds of complexity of the solution of systems of linear equations” (MR659085) that in essence establish that the direct solution of general systems of linear equations (1) has the same computational complexity as matrix-matrix multiplication and (2) is pleasantly parallelizable. For those of use who burn exaflops of computing power in “sharping” dynamical one-forms to trajectory tangent vectors on large-dimension state-spaces, this doubly favorable scaling is thought-provoking — mathematics and nature conspire to make large-dimension simulation far easier than naively seems possible.
If a fft like algorithm like $O((nlogn)^2)$ was found, it would imply $\omega=2$, right?
So even if $\omega=2$ was proved, the hunt for fast matrix multiplication still wouldn’t have ended.
What exactly is the matrix multiplication problem? As defined, it uses symbolic multiplication and treats each entry as a variable, not as a number.
A completely different problem is if we consider matrix multiplication with numbers. Namely, let us suppose that we have to multiply two nxn matrices with integer entries, such that entries are integer numbers taking m bits. Then look at the algorithms for this that take time O(n^c m^d). Then clearly infimum, call it e, over all such c is no greater than your \omega, but the converse is not necessarily true.
In fact, it might be that e=2 is mych easier to obtain – would such restricted matrix multiplication algorithm be of any value (theoretical/practical – would you call it breakthrough)? Are there any inequalities for e (the restricted number matrix complexity exponent) that are better than the general purpose inequalities for your \omega?
Some conspiracy theory:
“Meanwhile in North America, Virginia had been thinking about the same problem since 2005.”
“Acknowledgments. The author is grateful to Satish Rao for encouraging her to explore the matrix multiplication problem more thoroughly”
“Postdoctoral Scholar at UC Berkeley, Sept. 2009–Sept. 2011”
The article is correct as written. To compare, I’ve been thinking about what should be the “correct” measure of N-partite quantum entanglement since 2002, decided in late 2007 that polynomial-ideal invariants might furnish such a measure, worked on it while on sabbatical in 2009, but the 2008 survey by J.M. Landsberg (which I found to answer a comment above) gives me a fresh pointer on it—see page 13. What was your point and purpose, anyway?
I was astounded how people take Gowers’ comment literally…
Hint: try to read it as a recommendation letter then it’s obvious how much enthusiasm there is when he say:
“That last reason is a perfectly legitimate reason to get excited, but the first two reasons are legitimate reasons not to overdo the excitement (which I don’t think you did, by the way).”
Anonymous, the relevant parts of this post were written in British. Do you understand them?
—Dr. K. (Orde) Wingate Regan, M.Sc. Oxon. 1982, D.Phil. Oxon. 1986, Junior Fellow of Merton College 1984-1986 and 1988.
Omega is a good example of an uncomputable number: for us to know its value, it would imply we can travel to the future and see what new algorithms have been invented. I agree that it’s elegant to define it as the infimum of all c such that nXn matrix multiplication has an O(n^c) algorithm, but once you’ve said this you can’t prove anything about it. You know that a lower bound exists, period. The only way of getting closer to it is coming up with a better algorithm for the same problem. IMHO, the time it takes scientists to get closer and closer to Omega is a much more accurate indicator of the hardness of matrix multiplication, than the value of Omega itself.
On a related, albeit possibly obvious, note, with O(n^3) classical processing hardware, one can multiply two n x n matrices in O(log n) time. Despite being fairly obvious, it seems to get overlooked in some papers talking about using a polynomial amount of quantum processing hardware to perform matrix operations in polylogarithmic time, which is made decidedly less notable by the classical result.
W=What I think.
However good you are at solving a problem, the way you solve it isn’t a measure of its complexity. At most, it’s only a measure of your own abilities.
More precisely: an upper bound for the complexity and a lower bound for the abilities. I like the symmetry of it. 🙂