Can we expand the base of their use?

|
| Technion commemoration src |
Bella Subbotovskaya was doing Boolean complexity lower bounds in 1961. She originated the method of restrictions of Boolean functions and proved that the formula size of the parity function of  variables is at least
variables is at least  . The parity bound was improved to quadratic in 1971 by Valeriy Khrapchenko, who passed away only last year and was the only child of the Soviet literature and arts leader Mikhail Khrapchenko. Then Johan Håstad strengthened the whole method to quadratic.
. The parity bound was improved to quadratic in 1971 by Valeriy Khrapchenko, who passed away only last year and was the only child of the Soviet literature and arts leader Mikhail Khrapchenko. Then Johan Håstad strengthened the whole method to quadratic.
Today we discuss not possible further sharpenings but rather how to extend the ways of applying it.
Subbotovskaya was most unfortunately killed in a mysterious manner in 1982. George Szpiro in 2007 wrote an article reviewing the circumstances amid her questioning by the KGB for co-founding and hosting the “Jewish People’s University” amid rampant anti-Semitism in Soviet academies. She was also a talented violist and vocalist and investigated computer-assisted musical composition and analysis. See also her MacTutor biography.
As presented by Stasys Jukna in his 2012 book Boolean Function Complexity, Subbotovskaya gave an algorithm for optimizing the trimming of a formula over the 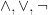 basis at its leaves by substituting for
basis at its leaves by substituting for  of the variables, one at a time. She used an averaging argument that readily extends to give the same-order bounds on random restrictions. Random restrictions have other advantages that have led to wonderful work besides those above, including the recent oracle separation of
of the variables, one at a time. She used an averaging argument that readily extends to give the same-order bounds on random restrictions. Random restrictions have other advantages that have led to wonderful work besides those above, including the recent oracle separation of 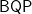 from the polynomial hierarchy. We want to discuss targeting the restrictions toward possible particular sensitivities of the Boolean functions computed by the formulas.
from the polynomial hierarchy. We want to discuss targeting the restrictions toward possible particular sensitivities of the Boolean functions computed by the formulas.
The Method
Subbotovskaya’s argument considers every  or
or 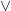 gate
gate  , in a minimal formula
, in a minimal formula  computing the function
computing the function 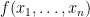 , that has
, that has  or
or  as an input, for some
as an input, for some  to . Note that because is a formula, one of the two possible assignments
to . Note that because is a formula, one of the two possible assignments  to renders the other input
to renders the other input 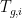 to immaterial. If has
to immaterial. If has 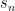 leaves, then we can not only choose
leaves, then we can not only choose  so that or occurs at least
so that or occurs at least  times, we can set it to wipe out at least half of the subtrees .
times, we can set it to wipe out at least half of the subtrees .
The final note is that doing so does not double-cancel any variable: if  contains or , then assigning
contains or , then assigning 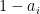 to that occurrence leaves the function computed by unchanged—but that contradicts the minimality of . Hence no subformula contains or . The upshot is that we can set so that the resulting formula
to that occurrence leaves the function computed by unchanged—but that contradicts the minimality of . Hence no subformula contains or . The upshot is that we can set so that the resulting formula 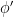 in
in  variables has
variables has  leaves. It is convenient to weaken this inequality by
leaves. It is convenient to weaken this inequality by

so that by iterating we can exploit the identity that for any  ,
,
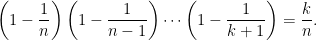
The upshot is that for any , we can set  variables so that the size
variables so that the size  of the resulting formula in variables obeys the bound
of the resulting formula in variables obeys the bound
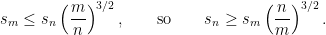
Because the parity function is such that any way of setting variables leaves the formula needing (at least) one read of the remaining variable, we can carry this all the way down to 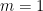 to deduce
to deduce 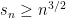 . Note: this is concrete, not asymptotic.
. Note: this is concrete, not asymptotic.
Via induction on gates deeper than those at the leaves, and techniques that adapt to how closely the two subtrees of are balanced, Håstad increased the exponent from 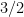 to
to  in all cases, on pain of carrying some lower-order terms that make the bounds asymptotic. His lemmas rely more on the restrictions being random, including one that estimates the probability that the restriction already leaves a formula dependent on only one variable.
in all cases, on pain of carrying some lower-order terms that make the bounds asymptotic. His lemmas rely more on the restrictions being random, including one that estimates the probability that the restriction already leaves a formula dependent on only one variable.
An Intuitive Framing
For sake of exposition we wave away the lower-order terms and write  for the numerical inequalities. We frame the restrictions with notation that can help us target subsets
for the numerical inequalities. We frame the restrictions with notation that can help us target subsets  of variables to restrict, outside of which
of variables to restrict, outside of which  remains sensitive.
remains sensitive.
Definition 1 Let  be a Boolean function. We say that
be a Boolean function. We say that
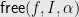
holds provided ![{I \subset [n]}](https://s0.wp.com/latex.php?latex=%7BI+%5Csubset+%5Bn%5D%7D&bg=e8e8e8&fg=000000&s=0&c=20201002) and
and 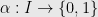 and for some
and for some 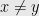 in
in 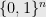 the following hold:
the following hold:
-
The inequality
 holds.
holds.
-
For all
 ,
,

Thus 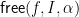 holds provided the value
holds provided the value  is not determined by just knowing
is not determined by just knowing  on the set of positions in . The remaining positions are needed.
on the set of positions in . The remaining positions are needed.
Theorem 2 (Main Theorem of Random Restriction Theory) Let be a Boolean function. Suppose that for a constant positive fraction of  with
with 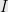 of size
of size  ,
,
holds. Then

An Example and Nonexample
To see how this scheme applies in the case of the parity function, we can set . No matter which inputs are selected, the value of the function stays undetermined after inputs are set. That is, the following is always true:

for all of size at most and all  . Thus the main theorem says that the formula lower bound for the parity function is order
. Thus the main theorem says that the formula lower bound for the parity function is order 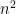 .
.
Note that the only property of the parity function being used is the global way it satisfies . We want to look for other patterns that can yield good bounds. Of course, patterns of sensitivity of Boolean functions have been looked at in many ways. We want to try to build a bridge from them to number theory.
For a non-example, consider the set  of even numbers. Let us number the variables so that
of even numbers. Let us number the variables so that  stands for the ones place in binary notation,
stands for the ones place in binary notation, 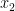 for the twos place, and so on. Then depends only on . Whether holds depends entirely on
for the twos place, and so on. Then depends only on . Whether holds depends entirely on  not belonging to . If
not belonging to . If 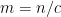 for some
for some 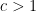 then it holds with constant probability, and the framework gives
then it holds with constant probability, and the framework gives
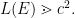
Well, OK, we really know  so this is where the overhead hidden by can’t be ignored. But at least this illustrates how the framework doesn’t get too excited about a frequently alternating numerical function. Similar remarks apply when the function is multiples of
so this is where the overhead hidden by can’t be ignored. But at least this illustrates how the framework doesn’t get too excited about a frequently alternating numerical function. Similar remarks apply when the function is multiples of  where
where  is small.
is small.
A Prime Objective
We would like to apply the random restrictions method to the Boolean function 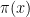 that identifies whether the -bit binary string denotes a prime number. It has been known for decades that the Boolean circuit complexity of
that identifies whether the -bit binary string denotes a prime number. It has been known for decades that the Boolean circuit complexity of  is polynomial. This follows from the existence of a polynomial random algorithm for due to Solvay-Strassen or the later Miller-Rabin algorithm and Adleman’s connection between such algorithms and Boolean circuit complexity.
is polynomial. This follows from the existence of a polynomial random algorithm for due to Solvay-Strassen or the later Miller-Rabin algorithm and Adleman’s connection between such algorithms and Boolean circuit complexity.
There are strong lower bounds on special circuit models, but nothing so general as formulas, let alone unrestricted circuits. Certainly is a harder function that parity, but we don’t know of a quadratic formula lower bound for it. Can we prove one in the framework?
Our intuition comes from considering various ways in which the primes are dense and uniformly—but not too regularly—distributed. Two simple ways are:
-
The average size gap between prime numbers is
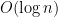 .
.
-
The maximum size gap between prime numbers is
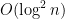 .
.
The first is of course a consequence of the prime number theorem. The second follows from the widely believed Cramér conjecture.
We will not really need this conjecture—we will not need it to hold everywhere. Our basic framework will only need it to hold for a positive fraction of small intervals of numbers that we sample. What we need instead is for a positive-fraction version to hold under a more liberal notion of “gap.”
Here is an outline to try to prove a formula size lower bound of 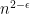 on , for some
on , for some  . Let
. Let

We will use the random restriction method for 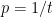 . Apply the method. The issue is now if we leave only input bits unset, then what is the probability that
. Apply the method. The issue is now if we leave only input bits unset, then what is the probability that

Certainly we cannot always leave bit unset like with the XOR function. Look at this:

The input is either

And both are not a prime. In general, our finger has come to rest on the question of what is known or can be shown about the behavior of the set of primes on “hypercubic” sets—that is, sets that add or subtract all sums from a selected subset of the powers of .
Open Problems
There must be other lower bounds on the primes. We cannot seem to find them. Any help?
Like this:
Like Loading...
Related



Hi Dick,
This is an idea: maybe could be helpful or maybe not.
Can be calculated parity in n^(2-\epsilon) when you can calculate the exact number of primes between two powers of 2?
It’s just an intuition….Certainly, if we obtain that \pi(x) in O(n^(2-\epsilon)), then the exact number of primes between the two powers of 2 can be calculated in O(n^(2-\epsilon))) as well. However, could be that an evidence for the existence of exactly two bits (two different powers of two) inside the binary string we are working on. I think this can be extended in smarter way for several bits.
This might not actually work, but certainly using that idea (of using previous knowledge to show new things by reduction ad absurdum) is not new and might be useful and be an easier way of trying to solve the problem.
I hope my comments could be useful in the same way your blog and comments have helped me.
Best,
Frank
:'( remarkable story; died under mysterious circumstances? complexity theory meets conspiracy theory.
jukna’s book on boolean circuit complexity is a world treasure, it seems nothing like it has been written before or since.
esp like some of the reformulations of P vs NP into graph theory, itd be cool if you cover them someday, they are somewhat obscure.
speaking of P vs NP, every year you say we’re no closer; itd be neat if you cover approaches/ directions/ areas of the field that “seemingly” or “conceivably” advance the area and could one day lead to resolution.
ok, yes ofc you do this to some degree already, but maybe theres something overlooked/ missed? 😀 😎
for example there is a lot of work on VP ?= VNP have you guys written on that at all?
https://cstheory.stackexchange.com/questions/529/does-vp-neq-vnp-imply-p-neq-np