Bait and Switch: Why Are Lower Bounds so Hard?
A potential obstacle to lower bounds

Steven Rudich is the 2007 recipient of the famous Gödel Prize for his work on ”natural proofs”. I will cover that work in another post. In addition, Steven has done some beautiful work in the foundations of computational complexity. Lately, he has turned his considerable talents to education of students. He is a wonderful explainer of ideas and I wish I could be half as good a lecturer as he is.
Steven once explained to me why he thought that lower bounds are so hard to prove. His idea is really quite simple. Imagine that you have a friend who is interested in computing some boolean function 

Here is a more precise way to state this method. Let us define some measure on how close a boolean function 
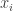


This method makes a lot of sense to me. Any computation starts with the the lowly variables that must be far away from the goal of
Bait and Switch
Steven’s brilliant insight is what I call a ”bait and switch” trick. Bait and switch is my term–do not blame Steven. The trick is only a heuristic at this time. However, it wipes out most attempts that researchers have tried to use to prove lower bounds. I think that it is a very powerful tool for seeing that an approach to proving lower bounds is doomed to fail.
Recall that a bait and switch is a form of fraud. The idea is to lure customers into a store by advertising a product at a ridiculously low price, and then attempt to get them to buy a different product. The original product may not have even existed.
We can use the same method of fraud to ”shoot down” lower bound attempts. Imagine again that we want to show that 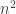

First we compute 
Then, we compute 
Finally, we compute 
Clearly, the final answer is 
I think of this as a bait and switch trick: you first compute 


The reason this destroys lower bound methods is that computing
I find Steven’s idea very compelling. I think that he has hit on the core of why lower bounds are so elusive. About two years ago I was on a program committee that received a paper claiming a major lower bound result. The paper was hard to read, and while we doubted the result we could not find any flaw. Outside experts who had been working on the paper for a while, such as Steve Cook, had no idea if the paper was correct or not. The committee was in a bind: we could reject a potentially famous paper or we could accept an incorrect paper. I applied the ”bait and switch” rule to the paper. The author had used a type of progress measure. He argued that as the computation proceed at time 

Open Problems
The obvious open problem is to try to build Steven’s insight into a theorem. Can we prove that there is no measure approach to showing lower bounds? This seems possible to me. I cannot yet see how to make this into a formal theorem, however. Note, also these comments about bait and switch work for arithmetic computations too. We just replace 


Trackbacks