The Isolation Lemma and Beyond
The isolation lemma and recent applications

Ketan Mulmuley, Umesh Vazirani, and Vijay Vazirani are three great theorists: Ketan is most famous these days for his attempts to use algebraic geometry to prove lower bounds, Umesh for his seminal work on quantum computing, and Vijay for his many contributions to the theory of approximation algorithms–his book on this is already a classic.
Today I would like to talk about an old result of theirs: the famous Isolation Lemma. This beautiful result has had a huge impact on many parts of complexity theory. The reason for this post is that there have been recent results either using the lemma or using related lemmas. Also their famous result is just another example of great results that have not been awarded the accolades they deserve. Oh well.
Umesh and Vijay were one of the early pairs of brothers in the theory of computing. I think the first pair was probably the Fischer brothers, Michael Fischer and Patrick Fischer. Now we have many more pairs of siblings, who both work in the theory of computing. I am currently working with one half of a pair of identical twins. Is that right?
The Isolation Lemma
The Isolation Lemma (IL) is, in my opinion, one of those results that seems magical. There are countless examples of the power of randomization, but there is something very surprising about this result.
Let 


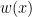


If the set with the minimum weight is unique, then call the weight function 
Lemma: Let
be a family of
element subsets of the set
. Then,
Here
the random function from
.
![\displaystyle \text{Prob}_{w}[ w \text{ is isolating for } {\cal F}] \ge 1-\frac{n}{N}.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Ctext%7BProb%7D_%7Bw%7D%5B+w+%5Ctext%7B+is+isolating+for+%7D+%7B%5Ccal+F%7D%5D+%5Cge+1-%5Cfrac%7Bn%7D%7BN%7D.&bg=e8e8e8&fg=000000&s=0&c=20201002)
That there is no dependence on the structure or lack of structure of the family
Applications
There are many classic applications of the IL. Of course before the IL there was the beautiful paper of Leslie Valiant and Vijay on unique SAT, which was used in Seinosuke Toda’s famous theorem reducing the polynomial hierarchy to 
In the last few years there have been a number of quite different applications. I would like to highlight a few of these.

Theorem: Let
be a polynomial over
. Let
be the upper bound on the degree of
and can test whether
.
Theorem: There is a randomized algorithm that determines if a given graph has a simple path of length at least
in
time.

See his pretty paper for the details. The main lemma–actually in the paper it’s Theorem 3.1–is an kind of isolation result. He encodes the graph problem as the problem of determining whether or not a polynomial 


What Ryan shows is this: evaluate the polynomial at a random element from a certain group algebra. Then, all non-multilinear terms evaluate to zero, and some multilinear terms survive. Finally, he makes use of randomness again to detect this. I think that this is in the spirit of the IL, randomness is used to isolate the multilinear terms from the non-multilinear terms. Take a look at the paper and see if you agree.
Open Problems
One of the on-going questions is de-randomizing the Isolation Lemma in specific cases. Since there are 
Another obvious related question is: what structure on the family


A small typo in the lemma: the sets in F need not be n-element sets, they can have arbitrary size. (n denotes the size of the ground set X.)
Hi Dick,
We have a paper (STOC ’93, SICOMP ’95) which shows that one gets a better randomness complexity if an upper-bound Z on the size of the family F is known: we need O(log n + log Z) random bits. (In the context of general set-systems, we also show this bound to be tight for the IL.) We spent much time to improve this for the specific context of matching, to no avail.
Wonderful. I am sorry I missed referencing this.
Hi
A caveat about the result of Arvind, Mukhopadhyay, and Srinivasan that you mention: their algorithm runs in time polynomial in n,m,d AND the number of monomials appearing in the polynomial. In other words, the algorithm is polynomial time only when the non-commutative polynomial computed by the input circuit is sparse. The existence of deterministic identity testing algorithms for the general case remains open, as far as I know.
Yes, I should have stated the theorem more clearly. Still a very cool result. Does the general case imply anything that you know about?
Yes that is right.
And I guess the recent famous twins in TCS are the Makarychevs (Charikar’s students)? Are there more?
A deterministic algorithm for the general case would imply some sort of circuit lower bounds in the Kabanets-Impagliazzo sense. Pretty much the same proof (as that of Kabanets-Impagliazzo) shows that if there is an efficient deterministic identity testing algorithm for the Polynomial Identity testing problem for non-commutative circuits, then either or the non-commutative Permanent does not have polynomial sized arithmetic circuits. Since we don’t yet have explicit lower bounds for general non-commutative circuits, that is something.
or the non-commutative Permanent does not have polynomial sized arithmetic circuits. Since we don’t yet have explicit lower bounds for general non-commutative circuits, that is something.
Hi,
A deterministic polynomial-time algorithm for identity testing of non-commutative circuits will imply strong lower bound result for non-commutative circuits (analogous to Impagliazzo-Kabanets result appeared in STOC 2001 and originally stated for commutative circuits).
In the non-commutative model, the strong lower bound is only known for non-commutative formulas (Nisan 91). AMS’08 paper gives a deterministic polynomial-time algorithm for non-commutative sparse polynomials only, as Srikanth mentioned. In another paper with Arvind (in RANDOM 2008), we show a new randomized polynomial-time identity testing algorithm for non-commutative circuits using isolation lemma.
Thanks,
Partha
I have an old, many author, paper that shows that the random self-reduction ideas also apply to non-commutative polynomials. I wonder if there are any connections. I have not thought about this for a long time.
Anyway thanks for your comment. Very pretty work.
No. There are more. My half is Atish Das Sarma, his other is at Stanford.
http://blog.computationalcomplexity.org/2009/02/baseball-families-and-math-families.html mentions some other pairs of brothers in CS theory.
Umesh and Vijay each visited me in Oxford on their way to/from India when we were all students, Vijay twice.