SAT Solvers: Is SAT Hard or Easy?
Are practical SAT problems easy or hard?

Ed Clarke, a Turing Award winner, was at the recent NSF workshop on design automation and theory. Ed has, for approximately three decades, worked successfully on advancing the state of the art of verification, especially that of hardware.
Today I want to talk about a discussion that came up at the workshop. Ed and others stated that in “practice” all the instances of SAT that arise naturally are easily handled by their SAT solvers. The questions are simple: why is this true? Does P=NP? What is going on here?
I have know Ed since he presented his first paper at the 1977 POPL, a conference that I used to attend regularly. He proved a wonderful theorem about an approach to program correctness that was created by Steve Cook. I worked on extending Steve’s and Ed’s work, my work appeared later that year at the 
Cook had a clever–not surprising it was clever–idea on how to circumvent the inherent undecidability of determining anything interesting about programs. I will try to motivate his idea by the following program:
Search all natural numbers x,y,z ordered by the value of x+y+z, and if f(x,y,z)=0, then print x,y,z and stop.
Here 
Cook’s brilliant idea was to figure out a way to “factor” out the domain complexity. He did this by adding an oracle that would answer any question about the domain. In the above program, this ability means that telling if the program halts is easy: just ask the oracle “is there an 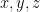

Sounds like a trivial idea. But, wait. If you have access to an oracle for the natural numbers, then anything is easy to determine about any program. This would lead to a trivial theory. Cook had to rule out the possibility that the oracle would be asked “unnatural questions.” By this I mean that you might be able to use the fact the arithmetic is very powerful and encode the analysis of your program into an arithmetic formula. Cook did not want to allow this.
The way he did this is cool: the analysis of the program has access to the domain oracle, but the analysis must be correct for all oracles. Thus, if you try to encode information in some “funny way”, then for some domain(s) your analysis is wrong. This was the clever insight of Cook.
Steve showed that certain kind types of programs could be analyzed with such an oracle and any domain, while Ed proved that certain more powerful type programs could not. I proved a necessary and sufficient condition on the type of programs for which Steve’s method works. My proof is quite complex–I try not to say that about my own work–but it really is tricky. Look at the papers if you are interested, or perhaps I will do a full post on this work in the future.
Thanks Paul
Before we turn to SAT solvers, I want to thank Paul Beame who has helped tremendously with this post. I thank him profusely for his time and effort. Think of this a guest post, but all the errors and mistakes are mine. Anything deep is due to Paul.
SAT is hard, SAT is easy, SAT is hard,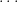
There is something fundamentally strange going on. The theory community is sure that P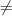
In my post on P=NP is Ill-posed, I raised some of the many ways that the P=NP question could play out. There are plenty of ways that both the theorists and the solvers could be right. As you know I like to question conventional wisdom, and in particular I am not convinced that P=NP is impossible. But, I also question the conventional wisdom of the solvers that practical SAT problems are all easy. So I feel a bit like we are living in Wonderland with Alice: (with apologies to Lutwidge Dodgson aka Lewis Carroll.)
“There is no use trying; one can’t believe impossible things, like P=NP.” Alice says.
“I dare say you haven’t had much practice. When I was your age, I always did it for half an hour a day. Why, sometimes I’ve believed as many as six impossible things before breakfast, like L=P, P=NP, NP=QBP, and
” The Queen replies.
SAT Solvers
In order to start to understand the situation let me first discuss the state of the art in SAT solvers. I have used many comments from Paul, and also have relied on the pretty survey paper of Carla Gomes, Henry Kautz, Ashish Sabharwal, and Bart Selman. This is definitely not my area of expertise, but I hope I can get the main points right. As always all the errors are mine, and all the correct stuff is due to Paul or my ability to transfer the facts correctly from the survey. Please let me know if I made any mistakes.
My understanding is SAT solvers divide roughly into two classes: complete and incomplete. Complete means that the algorithm always finds an assignment if the problem is satisfiable; incomplete means the algorithm may not. The complete ones all use Martin Davis, Hilary Putnam, George Logemann, and Donald Loveland (DPLL) as a basis, but usually add sophisticated methods to make the algorithm go faster. The incomplete methods tend to be different variations on random walk methods. I known the D and second L well in DPLL: I known Davis for a long time and Loveland taught me logic while I was a graduate student at CMU.
The DPLL method is based on a backtracking method. It assigns literal values and makes recursive calls to the simplified set of clauses. If it gets stuck, then it backtracks and continues searching. This method was initially called the DP method, until Logemann and Loveland who added two additional insights: take advantage of unit clauses and “pure” literals. If a literal 

Paul says that there are three keys to fast solvers today.
- Branching heuristics that take into account where the action is based on the learned clauses. One method is called VSADS and uses a weighted majority algorithm.
- Clause learning which is a way of adding new clauses to the formula based on failed branching. This can potentially help avoid large segments of the search.
- Watched literals that allow the modified formula to be kept implicit. This makes the propagation of the updates fast and tends to keep everything in the cache.
Like all backtracking methods, the selection (1) of which literal to set next is extremely important. The same is true, for many other search algorithms. For instance, linear programming with a good pivot rule seems to take polynomial time in practice. Another example, is searching game trees with 
There are many additional ideas that are covered in the survey. One key idea is to make random decisions when to restart the backtracking. The method is restarted even if it is not stuck. The methods usually keeps the clauses already set to guide the next restart (2) of the backtrack algorithm. Finally, note that idea (3) is an implementation one, which is of great importance on modern computers. No doubt similar methods will soon be needed due to the rise of many-core processors.
The second class of SAT solvers is based on random walk technology. These algorithms start at a random assignment and then use various local moves to change the assignment, hopefully toward the correct one. Some algorithms make local improvements, some allow plateau type moves, others use more complex types of random walks. There is evidence that these methods can work well on random SAT problems as well as some of those from real applications.
There also are methods that are random, but are fundamentally different. A relatively new one is called Survey Propagation (SP), which was discovered in 2002 by Marc Mézard, Giorgio Parisi, and Riccardo Zecchina. The solvers based on SP are like belief propagation methods that are used for decoding error-correcting codes. In each iteration about 
Why are Real SAT Problems Easy?
The solvers know well that any DPLL type method cannot be fast on all SAT problems, based on known lower bounds for resolution. However, that still does not explain why these methods seem to work so well in practice. Even the contests–see this site–which are held regularly on solving SAT divide the problems given to the solvers into three classes:
- randomly generated sets of clauses;
- hand crafted sets of clauses;
- examples from “real” applications.
Paul points out that he would take Ed Clarke’s contention that “SAT is easy in practice” with a grain of salt. First, before SAT the verification community was trying to solve PSPACE-hard problems, so SAT is a great advantage since is only NP-complete.
Second, the SAT solvers work except when they fail–reminds me of an Amazing (James) Randi story, for another time. The real difficulty is that no one understands what causes a SAT solver to fail. Tools that have this type of unpredictable behavior tend to create problems for users. Many studies of human behavior show that it’s the variance that makes tools hard to use.
Paul goes on to say that one of the research directions is the discovery of why SAT solvers fail. One problem is symmetry in the problem, since large amounts of symmetry tend to mess up backtracking algorithms. This is why the Pigeon Hole Principle is a “worst case” for many SAT methods.
Even if solvers cannot do as well as Ed claims, I still think that one of the most interesting open questions for a theorist is why do the algorithms do so well on many real problems? There seem to be a number of possible reasons why this behavior is true. I would love to hear about other potential reasons.




Open Problems
I keep quoting Alan Perlis about the power of exponential algorithms. I will soon start to quote Paul Beame who has made some great comments on this issue. Somehow we teach our theory students that exponential algorithms are “bad.” This seems quite narrow and theorists should look at the design and analysis of more clever algorithms that run in exponential time.
I also think another issue raised here is the reliance we place on the worst case model of complexity. As I stated in an earlier post there is something fundamentally too narrow about worst case complexity. The fact that SAT solvers seem to do so well on real problems suggests to me a problem with the worst case model. How can we close this gap between theory and practice?
Perhaps the main open problem is to get theorists and solvers more engaged so that we can begin to build up an understanding of what makes a SAT problem easy, and what makes it hard. And what are the best algorithms for “real” SAT problems.
Trackbacks
- El poder del SAT « Spin Foam
- Adiabaticly Failing for Random Instances - The Quantum Pontiff
- An Amazing Result « Gödel’s Lost Letter and P=NP
- Core Algorithms deployed in Computer Science | bittnt's Research Blog
- 计算机中实际项目程序代码编程常见常用的基本数据结构和算法总结:排序链表红黑树哈希表加密
- 实际项目中的常见算法 | Miao.js
- 常见算法在实际项目中的应用 | zengine
- 实际项目中的常见算法
- [转]实际项目中的常见算法 | 互联世界集团公司首页
- Is computational hardness the rule or the exception? | Windows On Theory


It could also be that the use of SAT solvers is entirely spurious, driven by the availability of technology, rather than by an intrinsic need. Maybe the problems that need to be solved for verification purposes _can_ be reduced to SAT, but it does not mean that they _have to be_ reduced to SAT. The solvers may “work” exactly because they’re asked to solve problems that admit polynomial-time solutions, given a bit more ingenuity and effort. In fact, the claim that “practical instances” are easily solvable can be taken as evidence that the problems to be solved are not really SAT problems after all (ie, they don’t cover the space of SAT problems).
I like this point. What if there was some hidden, as yet, property of a SAT problem that makes it easy. Still fun to try and find it.
A silly example? Suppose that I keep giving you graphs to 4 color. You always can do it. But I know that this is a NP-hard problem. How is this possible? What if each graph I give you was planar, but imagine a world where I did not know the concept of planar graphs. Eventually perhaps I would discover that property and the strange behavior would be revealed.
That is to say:
Sometimes it is better to play the game without knowing the rules!
The real problem may be just the easier subset of all problems. Even before encountering the problem we naturally try to reduce the complexity of the problem in the steps leading to the problem. We recognize the upcoming complex problem and the previous steps have indirect motives to ease the job of the “complex-problem-solver”.
I am not a SAT specialist. But in a similar problem i.e. VLSI routing using rectilinear steiner minimal tree (NP-complete), even during the placement (previous step to routing) we have the RSMT in our hindsight and so we design the placement algorithm with a secondary motive to make RSMT problem easier.
So we might actually be living in the best of all possible worlds, a world which even Russell Impagliazzo could not imagine. A world where P=NP and cryptography is possible…
I think is very interesting to understand why in the specific case practical sat is easy but I think this is a problem of about every “theoretical difficult” problem.
My answer is that the exponential explosion of these problems is simple not practical available.
We can construct problems with incredible combinatorial explosion with complexity 2^2^2^…^N but when we search instances of the problem in the practical domain we can not exceeds the limits of the real .
Probably the SAT is in a border line between exponential and polynomial but for example other problems like images recognition are incredible theoretical difficult problems but human and animals solve the “practical instance” of these problems so well!
Another example is the compression , everyone know that to compress something is so easy and is about always possible to compress data but this is exponential improbable it is about theoretical impossible to compress something.
When we get practical SAT instances where they come from ? The process computing the instances has enough complexity resources to give a difficult instance?
So I think that in the theory we have no bounds but the combinatorial explosions exceeds what is actually available.
Maybe this is rephrasing the points above (modular, or easier subset). But in verification, the SAT instance arises from a program that a programmer wrote. The programmer normally has in mind a simple reason why his program is correct. Given a good interface (say annotations), a programmer can often tell the verifier why the program is supposed to be correct. This proof probably breaks into a very small number of cases since humans aren’t good at simultenously keeping track of hundred different things. Thus it is not so surprising that this proof can be done by a computer. Similarly, when SAT solvers are used to find bugs, the relevant behaviours are small in number and given programmer help (say a few assertions), the problem does become significantly easier. So in both cases, a human has a short proof in mind, which, one may argue, makes the problems much easier: there are a few variables such that if you pivot on them, the resulting subproblems are very easy.
I like this. It’s related to my last point: on the natural selection of the circuits that they use SAT solver on.
The idea that “in ‘practice’ all the instances of SAT that arise naturally are easily handled by their SAT solvers” just sounds bogus. Maybe the solvers easily handle the SAT instances from particular application areas (EDA) that happen to yield instances that are easy to solve. Guess what? Those same circuit design problems were solved by humans more or less by pure head-scratching before SAT solvers came along. That is to say, they are easy problems. SAT solvers don’t appear to be of any use in more traditional search problems like cryptanalysis or theorem proving.
There was a situation in linear programming for a while, where everyone knew that the simplex was very fast in practice, but there were a few known concocted instances where it could be shown to take exponential time. Then Smale/Lemke (?) showed basically that those concocted instances were on a surface of measure 0 in the problem space, and were the ONLY instances where the simplex method took exponential time, i.e. simplex is almost always fast. A while later, Khachian showed that linear programming is in P. The key is that linear programming was easy in practice, including for the “tough” instances, from the very beginning.
It sounds as if the SAT solver guys think they are seeing a similar situation with SAT, but it’s really the other way around. They’ve found the narrow surface where the easy instances live.
The notion that designs that people can think of must be easy to verify is partly borne out in practice: A common experience is that buggy systems are the ones that really cause the difficulty and correct ones are easy to verify. While this is not universal, the very fact that a system seems hard to verify lends credence to there being a bug in it. A designer may have some nice and simple idea about how something should work but after they’ve screwed it up it can be really hard to find any bug!
The problem is that those bugs need to be corrected so it won’t do simply to give up in those cases…
I’m a bit confused. When talking about how ‘most’ SAT problems behave, what is the probability measure over SAT problems being considered? According to my best understanding, the Survey-Propagation algorithm and theory suggest that most SAT problem chosen ‘uniformly randomly’ are easy, and only a very small minority (those ‘near’ the threshold) are hard. Why is it a surprise then that most practical problems are easy? do you need to find a ‘reason’ or ‘structure’ in them, or is the ‘reason’ simply the lack of any reason of them to be hard?
(i guess the cryptography-related problem are even strengthening this point, since they were
‘designed’ or ‘evolved’ to give us these hard instances’). Even if the probability distribution
of problems arising in practice (whatever this distribution means) is vastly different than
uniform, why do we expect many/most of them to intersect the small set of ‘hard’ ones?
Another point, suppose that we believe that SAT is easy, I think an important research direction which i don’t know much about is determining the best ‘SAT reduction’ size for many problems. I once had a practical constraint satisfaction problem with a few hundred variables. I came up with a (what i though is) ‘smart’ encoding of it as a SAT problem, and tried to through it into a SAT solver. The encoding was, however of size O(n^3)
which made the approach in-practical.
Hard! Hard! and once again I say for those of us in the peanut gallery who are just not built that way….Hard!
🙂
I am old enough to have once sat in the peanut gallery.
🙂
hi, I’m from Vietnam. Nice to visit your blog
Dear Prof Richard Lipton,
The property hidden in SAT – though it is well-known to all of us – is that SAT is a logical problem. How did SAT become NP-complete, only for purely logical reasons. Those logical reasons themselves can easily be applied in such a way to deprive SAT from its position as the quintessential language, the most important language in computational complexity theory.
Define the language L={w in Sigma* such that w = NOT w}, you can have L in NP which is a counter-example irreducible to SAT. Hence, SAT is (NOT) NP-complete. There can be many logical languages with the property of L, like the Kleene-Rosser paradox for example.
Not only this, but also SAT became NP-complete due to the properties of the hardware (physical/mechanical) of the Turing machine. So if you derive a satisfiable [SAT] formula from the Voltage-Current characterestics of the emitter-base-collector of the transistors in the CPU, would this imply any specific property of the languages that this CPU is processing?
If you have 3 vehicles A, B and C which none of them can be driven in 3 different directions simultaneously, you get:
[A_x or A_y or A_z] and [B_x or B_y or B_z] and [C_x or C_y or C_z]
Would the satisfiability of this formula imply any property to the symbols/strings/words/language one writes on his vehicle? If you assume this vehicle is Turing-empowered and can process languages.
The language processed by a Turing machine is aceepted/not accepted due to the meaning of its strings and not due to the physical/mechanical properties of the machine which was used to prove SAT is NP-complete.
I’m a bit confused. When talking about how ‘most’ SAT problems behave, what is the probability measure over SAT problems being considered? According to my best understanding, the Survey-Propagation algorithm and theory suggest that most SAT problem chosen ‘uniformly randomly’ are easy, and only a very small minority (those ‘near’ the threshold) are hard.
I’m not sure that’s the case. Instances below the threshold are usually easy, since they usually have a satisfying assignment and the algorithms can find them. Instances above the threshold are usually unsatisfiable but finding proofs of unsatisfiability is difficult. So if the algorithm must be correct whenever it gives an answer, and gives up with a small probability, the algorithm must find a proof of unsatisfiability. The best we know is that one can refute for clause density n^{1/2}. But between constant and n^{1/2} clause density, the problem is harder and at least resolution-based proofs are exponentially long for this range. See e.g. http://theoryofcomputing.org/articles/v003a002/index.html.
Of course this is a bit of a digression: I think what is meant here by most is most of the instances arising in practice. The meaning of that indeed varies from application domain to application domain.
I’d like to raise an intriguing possibility that I think hasn’t been mentioned yet. What if SAT is easy on average? That is, for all poly-time sampleable distributions M, SAT is easy on M-average?
This is similar to, but perhaps more exact than, Michael Mitzenmacher’s idea on entropy mentioned in the post.
If this were the case, then under a reasonable hardness assumption (which I’ll discuss below), the ease of solving all SAT instances arising in practice could be due to the possibility that the instances arising in practice have low computational depth. By computational depth, here, I mean the difference between the poly-time bounded Kolmogorov complexity and the usual Kolmogorov complexity of the string.
Antunes and Fortnow “Worst-Case Running Times for Average-Case Algorithms” show the following result: if EXP is not infinitely-often contained in subexponential space (the reasonable assumption mentioned above), then the following are equivalent for any algorithm A:
1. For any P-sampleable distribution M, A runs in polynomial time on M-average.
2. For all polynomials p, the worst-case running time of A is bounded by 2^{K^p(x) – K(x) + log|x|}, for all inputs x.
(The term K^p(x) – K(x) is exactly the computational depth mentioned above.)
If you are in a job interview for a position in Intel, can you argue with them that SAT is really hard?
I suppose if the interivewing committee ever felt that you consider SAT is hard, so certainly this implies you are not into their business at all.
To supplement the point about entropy and the comment by Josh, instances can be (1) random, (2) non-random but deep, and (3) of low efficient Kolmogorov complexity. The above semi-proved, semi-heuristic thinking says that classes (1) and (3) are easy, so the hard instances are in (2). Which means it’s not easy to construct them quickly—note also the paper Russell Impagliazzo, Leonid A. Levin, “No Better Ways to Generate Hard NP Instances than Picking Uniformly at Random”, FOCS 1990: 812-821.
A particular case of (2) for a given (heuristic) solver A is, for any given length n, the string x_n = “the lex-first string of length n on which A achieves its worst-case running time.” Conditioned on n, that’s a constant-size description of x_n. Hence under Solomonoff-Levin distribution M, time on M-average is Theta-of worst-case running time [Li-Vitanyi], and likewise for other stats such as approximation performance in place of time. I was interested in whether low-KC strings would show such “malign” behavior in practice, but back in the early 1990s I didn’t appreciate the difference between (2) and (3), and the graph instances I and my first PhD student generated weren’t very deep—hence our mixed results.
When talking about how ‘most’ SAT problems behave, what is the probability measure over SAT problems being considered?
Survey propagation uses the following “typical” properties of random 3-CNF formulas below the threshold: The bipartite clause-vertex graph
(1) has large girth and (2) behaves like a constant-degree expander. (Though one could take a large clause and convert it to 3CNF using auxiliary variables, that conversion does not change the behavior of the algorithm.) These properties are not “typical” in any reasonable sense considering the kinds of problems that people actually want to solve. In fact, many of the ways that interesting SAT formulas are generated in practice are via reduction techniques that yield a lot of highly specific gadgets that have variables of large degree and some variables that appear in very large numbers of clauses.
What if SAT is easy on average?
We certainly have that kind of property for some NP-hard problems such as Hamiltonian circuit where we can almost surely find them easily in random graphs at any edge density for which they exist. Until the Survey propagation algorithm came along, most people working on SAT (among them the statistical physicis community from which Survey propagation arose) would surely have reasoned that, together with problems like coloring and clique, the threshold instances under the uniform random distribution will be hard. It still is not out of the question for random k-CNF for sufficiently large k.
Hi,
It sounds like what you are looking for is some kind of measure on the space of SAT problems. Suppose you rank the SAT problems in increasing size/complexity. I am sure these have already been defined in a number of ways. How does the complexity look as a limit as you grow larger? Is the number of hard (by some definition) problems growing or staying the same as a fraction of the total? It seems like there ought to be some experimental evidence that might be useful in this area.
Could one then say that the observation that most realistic problems are easy is a reflection that the percent of hard instances per interval of complexity is slowly decreasing? or that it is flat vs increasing?
Is that kind of reasoning what you are thinking of as a better way to look at complexity? A statistics of toughness of solution over an ordered problem space?
Dick Lipton asks a good question with “The theory community is sure that P{\neq}NP, and so SAT is hard. The solver community is sure that they can solve most, if not all, of the problems that they get from real applications, and so SAT is easy. What is going on here?”
This question becomes better-posed and considerably easier to answer if we transpose it to the quantum domain: “The QIT/QIS theory community is sure that P{\neq}BQP, and so quantum simulation is hard (as Nielsen and Chuang’s textbook asserts, for example). The quantum simulation community is sure that they can solve most, if not all, of the problems that they get from real-world applications, and so simulating quantum systems is easy. What is going on here?”
What is going on in the quantum domain is that most real-world applications concern systems that are (1) measured-and-controlled, and/or (2) in contact with a thermal reservoirs, and/or (3) are near their ground-state of energy.
Now, in the quantum world our analysis is greatly simplified because all three of these conditions are (physically and mathematically) the same condition … because it is well-known that thermal reservoirs are informatically equivalent to (covert) measurement-and-control processes … and as for systems near the ground-state of energy … well heck, they arrive at low temperature by contact with a thermal reservoir. So we can ask Lipton’s question “What is going on” with reasonable hope that a single answer will cover a broad class of physical systems.
For computational purposes, a very convenient way to answer Lipton’s questions is to describe the system dynamics as a symplectic/stochastic process that is determined by equations of Lindblad type. A Choi-type gauge can always be found in which the drift of these equations has the powerful property of concentrating the trajectory flow onto low-dimension manifolds; and these manifolds turn out to have a tensor network structure.
Essentially all large-scale quantum simulation codes exploit this concentration property of the Lindblad-Choi flow … and that’s how they generally solve (very efficiently) quantum simulation problems that formally are in BQP.
Obviously, modern quantum simulation codes can’t simulate quantum computation processes (which are intolerant of measurement and noise), any more than modern SAT solvers can solve hard NP problems.
The advantage of studying quantum simulation as an example of a class of problems that is formally hard, but practically easy, is that the symplectic drift equations have a simple mathematical form that makes it feasible to prove rigorous concentration theorems … theorems that provide solid foundations for Lipton’s ideas in the context of quantum simulation.
I’ll be giving a tutorial on large-scale quantum spin simulations, based on this concentration-theoretic approach to efficient computational simulation, at next month’s Cornell/Kavli Conference: Molecular Imaging 2009: Routes to Three-Dimensional Imaging of Single Molecules.
Obviously we Kavli attendees have a very practical application in mind … atomic-resolution biomicroscopy … but this won’t preclude us from having fun at the Conference, exploring these concentration-theoretic mathematical ideas.
If we were to translate these quantum simulation ideas back into SAT-world, they might be something like the common-sense notion “it is usually true that mistaken inputs and wiring errors do not generate interesting output” … but it is much harder (for me) to see how this might be stated rigorously.
The bottom line is that Dick Lipton’s SAT-related ideas seem to be broadly applicable within the discipline of large-scale quantum simulation, where concentration theory provides a well-posed avenue for turning these ideas into theorems, and the prospect of transformational applications like molecular spin-imaging helps keep everyone excited and focused.
Dick,
Maybe it’s the case that for any particular SAT solver, you can construct a SAT instance that it will choke on…but for any distribution of SAT instances you can construct a particular SAT solver that will, on average, do well on them. Sort of the NP version of the halting problem.
-John
What is the answer to this:
Two cars leave an intersection at the same time. One car is headed North at the rate of 1 Km/min while the other is headed East at the rate of 2.4 Km/ min. What is the direct distance between the two cars, in kilometers, 5 minutes after the cars left the intersection?
They’re thirteen kilometers away from each other since
((1 * 5)^2 + (2.4 * 5)^2)^1/2 = 13,
provided North and East are strictly perpendicular so that Pythagoras applies to this triangle.
“Please feel free to suggest some other ideas.”
Like a keep saying you, Lucy …
☞ Theme One Program • Cactus Language