Deolalikar Responds To Issues About His P≠NP Proof
A principle for checking proofs with an application to the proof

Vinay Deolalikar is standing by his 
I think there are several levels to the basic question “Is the proof correct?”:
- Does Deolalikar’s proof, after only minor changes, give a proof that P
NP?
- Does Deolalikar’s proof, after major changes, give a proof that P
- Does the general proof strategy of Deolalikar (exploiting independence properties in random
-SAT or similar structures) have any hope at all of establishing non-trivial complexity separation results?
After all the collective efforts seen here and elsewhere, it now appears (though it is perhaps still not absolutely definitive) that the answer to #1 is “No” (as seen for instance in the issues documented in the wiki), and the best answer to #2 we currently have is “Probably not, unless substantial new ideas are added.” But I think the question #3 is still not completely resolved, and still worth pursuing (though not at the hectic internet speed of the last few days.)
Today I wish to talk about something other than the P
I would like to share a proof searching trick that I have always used; it must be well known, but I do not know a name for it. The method is quite relevant to the emerging biggest issue in the correctness of Vinay’s proof.
The Principle
Suppose that Alice is trying to prove 
Finally, after months of hard work, Alice has an outline of a proof. She has not checked all the details, but she is quite excited about the potential. She thinks she has her proof. Imagine that she is about to go to explain the proof to Bob.
Just before she does this, Alice notices the following. Let’s call her proof 

where 
Here is the principle: this is bad, very bad, if
I use this principle—unfortunately all too often—to shoot down my own proof attempts. More than I care to admit, I find a clever “proof” of something, but then realize by the principle it will prove too much. It will either prove something dead-wrong or something that is way too hard for my weak method.
Here are two simple examples of this principle: one imaginary and one real.

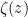
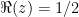

She proves that all the non-trivial zeroes of the zeta function must have a left-to-right symmetry about the line 
The Proof and The Principle
A number of researchers—including Avi Wigderson and Ryan Williams—have pointed out that Vinay’s proof could fall to the above principle. They do not state their concern in this way, but it is essentially a potential violation of the principle.
In particular their concern is how does the proof tell 

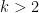
I still do not know for sure what to conclude about this. But this issue is definitely one of the biggest ones that we have seen raised. It is not sufficient to rely on some results having been proved for 

There is a longer discussion of this and related issues with his proof at the wiki page.
Deolalikar’s Answer
Vinay has just responded directly to a number of us in an attempt to explain how his work does use 

Let me try to answer the question, which is “Why does my proof fail for 2-SAT, known to be in P.” The proof requires that the solution space of the CSP be “sufficiently hard to describe.” By that we mean, not possible to describe with fewer than 


Open Problems
Of course the key questions remain: Is the proof correct? Or can it be fixed?
Perhaps the last question is what did we learn from the last few hectic days. I think I learned three things: First, that the community is extremely interested in our basic question, P=NP? I find this very positive. I was shocked at the tremendous interest that was generated.
Second, I like that the community reacted in a mostly positive and supportive manner. I think we owe Vinay a thanks, no matter what the final outcome is. He has raised some interesting connections that, as Tao says, may be useful in the future. He also showed how people can ask hard questions, and how the community can be helpful. Yes, there were some tough comments here and elsewhere, but for the most part I think the experience has been positive.
Finally, I realized that it is not possible to keep up the hectic pace of the last few days for much longer. I hope we helped, I hope we were always positive, and I hope the work here in trying to resolve this exciting event has been a positive contribution. I thank you all for your kind interest.
Trackbacks
- Tweets that mention Deolalikar Responds To Issues About His P≠NP Proof « Gödel’s Lost Letter and P=NP -- Topsy.com
- P != NP for Non-Math Majors | an/archivista
- P != NP proof removed from Vinay’s site (Update: It’s back!) « Interesting items
- World Wide News Flash
- P Vs Np Problem
- Attempt At P ≠ NP Proof Gets Torn Apart Online
- Attempt At P ≠ NP Proof Gets Torn Apart Online » Tech Reviews
- Linkblogging For 12/08/10 « Sci-Ence! Justice Leak!
- Attempt At P ≠ NP Proof Gets Torn Apart Online « Vinoddanims Blog
- Deolalikar’s manuscript « Constraints
- Links with little comment (P != NP) « More than a Tweet
- Attempt At P ≠ NP Proof Gets Torn Apart Online | Techcrumer
- Summer « A kind of library
- J. Caleb Wherry | Blog: Viva la Science
- ¿Qué es eso de que “P ≠ NP”? | El blog de Juan


It’s worth noting that in what I assume was meant to be your “imaginary” example, the lemma (with restriction) actually is true: the non-trivial zeros of the Riemann zeta function _are_ left-right symmetrically distributed about the line with real component 1/2. So Alice perhaps proved her lemma an erroneous way if she didn’t take into account the non-triviality of the zeros in her proof, but nonetheless, that could be patched, the lemma would stand, and the rest of the proof would go through. (Did you do this on purpose?)
I think we all should thank you, Richard, for your enthusiasm in updating this blog, and your providing food for thought (and a space for discussion).
His answer and added chapter confirm that size of parametrization is crucial idea in his approach.
But what does he mean by parametrization of the size X? Clearly, if a question in k-SAT is given by n (size of the problem) parameters then this is O(2^(log(n)), and question parametrizes the answer space (though not in an easy way for hard problems).
Can someone explain what does he mean – how does one determine, given a family of probability distributions, the number of parameters that he speaks of. Presumably, he means some special kind of parametrization, since apparently he does not allow for parametrization with of the solutions with the questions they answer.
sorry this was not supposed to go here, but to be a general comment.
Absolutely agree, thanks for the updates.
Hi Dick and Vinay,
thanks for the response – I’m sure this has been far more hectic and frenzied for you than it has been for any of us watching. I had two questions:
in the absence of properties such as linearity, it is not possible to specify the joint distribution of the covariates in this phase with {O(2^{\mathsf{poly} \log n})} independent parameters.
I assume this is a formal statement (i.e is a lemma of some kind) ? because otherwise it seems to fall prey to Cris Moore’s complaints about what exactly we know about $k$-SAT.
Also, one other source of objection was the model theory aspect, and especially the detailed critique provided by Steven Lindell (see the wiki). I was wondering if there had been any feedback on that front ?
Exactly. Lets hope the proof contains a (precisely stated and proved) lemma that unambiguously establishes the fact that random k-SAT, in general and for large enough k, *simply cannot* be specified in “O(2^poly(log n)) independent parameters”. Only then does the proof take care of the “will the proof hold up in a world without Gaussian elimination?” argument.
It doesn’t need that. As long as the parameterization he uses on the NP / statistical mechanics side is the same as the one he’s using on the P / model theory side, he can derive a contradiction.
Of course, this is also why his comment does not address the objection.
I want to thank you for updating your blog on behalf of thousands (millions) of computer science graduates who can understand the significance of P vs NP
We are hanging by your every word and hoping against hope. To us, this resembles a grand superbowl match, more exciting than any i can recollect.
Every update will be deeply appreciated. We promise to be supportive and positive about the whole thing (we will not cause street riots 🙂 )
–A cs graduate
His answer does not very convincing, it is too hand waving. He should be concrete while telling the differences. Which theorem on 3-SAT formulas he is using to describe this difference in behavior? Between 2 an d9 there is a whole lot of game going on!
Actually, it is known that the non-trivial zeros of the Riemmann zeta function do display symmetry around the line imaginary part = 1/2; any counterexamples would have to appear in pairs. Indeed, one way to verify the conjecture numerically up to a certain point is to calculate contour integrals that count the zeros with sufficient accuracy to detect that the count has gone up by one and not two.
Naturally, the proof of reflection uses in an essetial way the difference between trivial and nontrivial zeros: the trivial ones are related to poles of the gamma function, which is part of the functional equation that establishes the symmetry.
Haha, the non-trivial zeta zeros DO have a left-to-right symmetry about the critical line; the set of nontrivial zeros is invariant under complex conjugation and under the map s–>1-s.
Beautiful posts!
(Oops–naturally I meant the line real part = 1/2.)
I have interacted directly with Deolalikar, so let me instead remark now on a strengthening of your example of how Bob can tell that Alice’s proof of the Riemann Hypothesis is faulty . In fact, this is a real-live example, that happened to an (at the time) young math professor (let’s call him Bernard) at Berkeley. Bernard told me this story when I was a graduate student at Berkeley. Bernard’s former Ph.D. advisor was Serge Lang, a famous number theorist who wrote a well-known textbook on Algebra. Bernard thought he had obtained a proof of the Riemann Hypothesis, and excitedly called Serge Lang in the middle of the night. Lang asked Bernard to tell him exactly which properties of the zeta function he had used in his proof. Bernard told Lang, and Lang’s response was, “Then there must be a bug in your proof. There is another function other than the zeta function that enjoys all of the properties you have given me, and which does not satisfy the conclusions of the Riemann Hypothesis.”.
I realized that it is not possible to keep up the hectic pace of the last few days for much longer.
Commenting from an absolutely non mathematical point of view I understand that it certainly is very stressful for all those doing the real proof checking work on this, but, this is Internet time sorry for you guys you’ve got the good side (so many people joining the fray) you have to bear the hardship. 😉
As Jordan Rastrick put it in another thread:
Even if the proof ends up teaching us nothing about complexity theory, at the very least it should teach us something about how the blogosphere compares to traditional peer review for finding flaws in complicated papers.
You are also at risk of losing the momentum, the interest in the question might vanish as quickly at it built up.
I just did a brief check of the typos collected on the wiki for the second draft, and unfortunately they are mostly still present in the third draft. This seems to indicate that Deolalikar has not yet incorporated the issues raised on the rest of the wiki (but this should be checked at some point). One can imagine that he might already have his hands full, of course…
Incidentally, the list of issues on the wiki has been significantly expanded in the last few hours to incorporate many of the comments in the last day or so; it might be good to have the list looked over by the authors of those comments, and edited or extended as necessary.
I wonder if one of the detriments of the millennium prize is a reluctance to work with collaborators on these problems. I saw that Vinay had collaborated with Joel Hamkins before, who might have helped clarify things. But I imagine that most who think they have found an approach to one of these problems would rather go it alone.
Of course, the desire for unshared glory may occur even without any financial motivation tied to it; indeed, I think for most academic types, the former would be a far stronger motivator than the latter.
No worry, it is hard to find anyone to work on the P vs. NP problem.
It is said to be a carrier-killer!
In the example that Dick gives
P => X
P’ => X’
In reality, P is likely to be an ordered sequence of arguments P = ( P_1->P_2->P_3…………………P_n) not necessarily totally ordered, but at least partially ordered.
It is true that an indirect by-product assertion like P’ implying something implausible is a very good check, and a red flag – but still – shouldn’t the verifer be able to at least pinpoint one P_i that must be broken? Directly. Without any reference to a transformed version of P.
Has there been any such direct refutation to any part of Deolalikar’s claims?
[probably Charanjit Jutla’s comments come closest]
As mentioned in comments by Cris, Terence, and myself near the end of yesterday’s blog page, I don’t think the explanation Vinay gives above or in the latest draft from 8/11 successfully explains why 2-SAT and k-XORSAT do not pose an issue for his proof.
There is a cyclic nature to his argument here — 2-SAT and k-XORSAT are claimed to be ok because we know they have succinct parameterizations to begin with. But what if k-SAT also had such a succinct parameterization (say, because it happened to be in P) but we just didn’t know it yet? Wouldn’t his proof then say that k-SAT is in fact in P, just like it presumably does for 2-SAT and k-XORSAT? If so, he is essentially implicitly using “k-SAT is not in P” to prove “k-SAT is not in P”.
For yesterday’s comments, see:
http://rjlipton.wordpress.com/2010/08/10/update-on-deolalikars-proof-that-p%e2%89%a0np/#comment-4997
http://rjlipton.wordpress.com/2010/08/10/update-on-deolalikars-proof-that-p%e2%89%a0np/#comment-5009
http://rjlipton.wordpress.com/2010/08/10/update-on-deolalikars-proof-that-p%e2%89%a0np/#comment-5026
Thanks – this seems a very useful explanation of the 2-SAT/9-SAT criticism.
He seems to say that a new version (judging from this uptade, not substantially different) will be sent for print.
Because of the imprecision in the text, one can not pinpoint clearly a place where a proof is failing, if it is, though there are many suspicious places.
But perhaps one can give answer to the following question: is the paper going to pass a peer review in a paper?
The answer is most clearly no. Substantial revision is needed just to make clear what he is saying, but judging even from this unclear text, proof seems to fail on many levels. The proof itself is in fact not that complicated (most of the text is overview), and only because of the obsurity of the text it is still receiving benefit of a doubt. But obscurity as way of writing is not a way to pass peer review in any journal that takes peer review seriously.
I agree. But this is the same issue with many of the papers claiming P \neq NP around.
I can think of several papers published in peer reviewed journals of combinatorics which would have implied NP=P had they not contained errors.
Peer reviewers can spot obvious mistakes, but they can’t invest months of their time verifying complicated original research in great detail.
That is why Claymath requires that the result stand for two years before any money is awarded.
Russel Impagliazzo’s comments seem to bear the key here, and supported by everyone too.
that is – Please bring a sequence of extremely precise claims and their respective proofs.
I wonder – if he just reverses the order of the sections- bring up the proof up-front and leave the entire set of expository sections as appendix. Would that have made any difference to the perception (of course that wouldn’t change the correctness – just the perception) ? In theory – No – I guess.
In order to eliminate the k-XORSAT objection, why can’t one assume w.l.o.g. that any PTIME algorithm would of course first apply Schaefer’s dichotomy theorem to single out and solve the trivial cases first, like k-XORSAT (that admit “small parametrization of the solution space”) in order to be left with the “hard” instances, i.e. those which are known (by the dichotomy) not to admit any “small parametrization” and to which the strategy of D’s proof would then apply? This would separate P from CSP and thus from NP, right?
what exactly is “small parametrization”. Can you define it precisely?
OK, I really shouldn’t have used D’s controversial term of “small parameterization” above. The point I want to convey is, doesn’t Schaefer’s Theorem suffice to single out *all* tractable instances, such that “the k-XORSAT objection” can no more be applied to the remaining instances within the hard regime of random k-SAT? I.e. all instances with complex solution space there are then known, by the dichotomy, to be NP-hard and not allow for a PTIME short-cut, unless P=NP?
I think your reasoning is reversed. A proof that some problem is not in P is a partial characterization of what is in P, as is Schaeffer’s Theorem (if P \neq NP). So a proof
that P \neq NP should implicitly yield Schaefer’s characterization as a corollary. In other words, the problems that Schaeffer tells us are easy must not be characterized as `hard”,
and at least some of the problems that he tells us are hard must be characterized as hard.
(The rest will follow.) If the notion of “simple paramterization of search spaces” does not distinguish by itself the two cases, then there cannot be a proof using just that notion. Something additional must be added, i.e., no simple parameterization, measurable non-linearity in some sense, etc.
Russell, thanks for the clarification!
I think the issue is not distinguishing 2-SAT from 3-SAT, but distinguishing XOR-SAT from 3-SAT.
The reason is that it is known that (in the absence of order), 2-SAT *is* definable in LFP and 3-SAT *is not* definable in LFP. If, as I suspect, Deolalikar is not really using the order on the structures, his proof amounts to a re-proof of this known fact, and it will distinguish between 2-SAT and 3-SAT. On the other hand, it is known that XOR-SAT is *not* LFP-definable when an order is not present. Thus, the key test is whether his proof works for XOR-SAT.
Where does Deolalikar prove that the k-SAT solution space can’t be parameterized in O(2^polylog n) parameters, if it’s not a corollary of the statistical results? Is this just a replacement of one hard problem with another?
Also: Above and beyond the question of “can my proof strategy prove something stronger/false,” there’s the heuristic test of “where’s the beef?” If you think you’ve solved a longstanding open problem with very simple methods, that don’t appear to address the basic reasons why the problem is hard, then you’d better double-check your proof. And, honestly, Deolalikar’s proof has a whiff of this about it as well.
(Actually, just last week my advisor and I briefly thought we had a solution to the problem we’d worked on all summer. But we couldn’t figure out where the beef was, so we went over it step-by-step, and indeed found the error in a certain purported averaging argument. I suspect that if Deolalikar wrote his proof out more rigorously, the community would have an easier time doing something similar…)
The initial hype about this proof has all but faded and as an outsider, I can only infer that Deolalikar’s proof is not correct. No expert has so far offered a weak acceptance for the proof and it speaks a lot about their confidence it.
Nevertheless, I was nice to see so many top people actively participating in the discussion!
If VD was with Microsoft instead of HP, the proof updates could be optionally downloaded with Windows update!
I would like to ask the experts: Do you find it worthwile to still search for polinomial time algorithms for NP complete problems? Sometimes my naive intuition is that maybe P = NP, just the ‘right’ algorithm has some very chaotic behaviour. Maybe it will be much easier to find the right algorithm than to prove that it is correct. I’ve described a sample heuristical algororithm for N/2 clique search here. For me it shows that analyzing these algorithms is much harder than actually creating them.
nadamhu, while most experts believe that P does not equal NP, a notable exception is Richard Lipton, director of this blog. If you click the “Conventional Wisdom and P=NP” link at the top of the page, you can read more about this.
Thanks, very interesting. My intuition works the following way: I take it from an information theoretical point of view: I think I’ve created an algorithm which can extract information in polynomial time from a graph whether the vertices are in the N/2 clique or not. (See my previous link.) There is positive correlation between what my algorithm thinks and what is true. This positive correlation holds information.
The challenge is to extract out the following from this information: ‘which vertex is not in the clique for sure?’
So I think the whole issue is something like this:
1. How much information the first half of my algorithm extracts out. (really measure in bits from information theoretical point of view)?
2. Is this information enough? (Is this at least log(n) bits, which is needed to express a vertex which is not in the clique?)
3. Can the log(n) bits of describing the ‘surely not in the clique vertex’ be extracted from the original info? How?
It would be great if some expert can answer the following three questions regarding Vinay’s proof:
1. Is the construction of the ENSP sound (section 8.3/8.4)?
2. Does ENSP lead to the existence of a “simple” distribution in the d1RSB phase of random k-SAT?
3. Is there a known “non-simple” deterministic lower bound on the number of parameters required to characterise the solution distribution in the d1RSB phase of random k-SAT for k > 9.
Vinay’s purported innovation is to create (1) and (2) to contradict 3 (which should be known). So an expert should be able to “easily” answer 3.
What is the definition of these “parameters”?? The solution space can always be characterized by the formula, that is a linear number of parameters.
Dear Professor Lipton,
Not sure, if you are aware, but this story has been covered in one of
India’s leading new paper:
http://hindu.com/2010/08/12/stories/2010081264552200.htm
There are quotes from your posting.
I realised on looking at the wiki that while we have a large number of general “high level” issues with the paper, we do not really highlight more proximate specific issues with particular lines in the proof (except for a listing of trivial errors). To me, the most serious such issue raised so far is the one raised by Lindell on the tupling issue. I have tried to condense Lindell’s critique into a concrete and specific error on the wiki at
http://michaelnielsen.org/polymath1/index.php?title=Deolalikar%27s_P%21%3DNP_paper#Specific_issues
but it should probably be reviewed by someone with more experience with monadic logics.
One should perhaps also start collecting systematically on the wiki the other specific issues, tied to a particular line of the proof, that we have isolated.
BTW, I am not able to understand the relevance of XORSAT and 2-SAT as the ‘sanity checks’ for the proof. AFAIR from Prof. Regan’s description of the proof strategy – isn’t he trying to prove something like IF P=NP, THEN the solution space of randomized k-SAT will have some statistical properties (for k>9…) that we rigorously know not to be true, hence the contradiction…
why are the comments on XORSAT and 2-SAT relevant in this case then?
sorry, i meant the above post to be one-step higher in the hierarchy.
If k-SAT has different statistical properties than the polynomial time computations described (I think) by LFP, and XORSAT also have different properties (similar to k-SAT), then there is a contradiction because XORSAT belongs to P.
This would suggest that these statistical properties are not uniform over polynomial time computations and that some of them exhibit the same behavior as problems in NP or that the description of computations represented in the proof through LFP is not complete for P.
Immediately preceding the wiki’s “Specific issues” section is an “Alternate perspective” section where someone (not me) has posted Leonid Gurvits’ first impressions of Deolalikar’s proof strategy.
The mathematical language of Gurvits’ remarks is very congenial to engineers and physicists, but perhaps less congenial to (say) computer scientists. This reminds us, that as we attempt to “piece together all the pieces and try to create a unified narrative for what is going on with the paper”, it will be a considerable challenge to keep in-mind that not everyone has the same goals or finds the same proof technologies to be mathematically natural.
As a unified narrative begins to emerge from the now-global enterprise that is associated to Deolalikar’s article, it will likely have to tell the same story multiple times, from multiple perspectives, in multiple mathematical languages. We engineers hope so, anyway, because this fosters a rich environment for creative engineering! (and the Japanese filmmaker Akira Kurosawa made a film, Rashomon, that illuminates precisely these multiple-perspective issues).
I think everyone—mathematicians, scientists, and engineers alike—appreciates that only the strongest mathematical narratives can support multiple perspectives, and so it is our good fortune that apparently Vinay Deolalikar—to his very great credit—has gifted us with such a narrative.
Over on Scott Aaronson’s Shtetl Optimized blog, a poster named Beancounter asked a question that I think lots of folks have: How many jobs and opportunities were created due to Vinay Deolalikar’s proof?
Beancounter’s question was at the back of my mind yesterday evening, while I was reading a dusty bound volume of the 1958 Scientific American.
That volume was jam-packed with jobs and opportunities. There were dozens of full-page ads in every issue, literally begging young people to accept good, family-supporting jobs in math, science, and engineering … and offering to pay for their graduate educations at top-rate schools too.
Moreover, the math and science articles of 1958 were super-good and super-fun. Martin Gardner’s column (`nuff said!) … Solid State Masers (pure quantum physics; yet how few physicists foresaw that lasers were just around the corner!) … The Regeneration of Body Parts (this was my proximate research interest, namely, how did Norbert Weiner’s and John von Neumann’s early conceptions of systems biology and regenerative healing initially propagate into the popular culture?).
Many of us older engineers, mathematicians, and scientists were the beneficiaries of that Golden Era. Because at least in North America, per-capita enrollment in STEM degrees (science, technology, engineers, and mathematics) peaked in the 1960s, and has been declining pretty steadily for the subsequent 40 years.
So … uhhh … why aren’t present-day issues of Scientific American similarly packed with family supporting jobs and opportunities?
Now that is a tough question.
Of the hundreds of posts on the topic of Vinay Deolalikar’s proof … many of exceeding merit … among the most relevant (IMHO) was a cryptically short post by Leonid Gurvits—containing several ideas that I wish Leonid would comment upon more fully—because they are immediately relevant to practical present-day challenges in quantum systems engineering and regenerative medicine.
If we want the job-richness of the 1950s to ever come again, those are questions we need to focus upon. So I am grateful to Vinay Deolalikar in particular … and more broadly grateful to tens of bloggers and to many hundreds of posters … for collectively helping to rejuvenate our 21st century hopes, expectations, and enterprise.
This is my attempt to piece together all the pieces and try to create a unified narrative for what is going on with the paper. It is based on trying to integrate several comments by others that I do not fully understand at every level, and so may be somewhat inaccurate; please help in pointing out any deficiencies.
Basically, the strategy of the paper is to assert
1. The solution space to P problems have a simple structure.
2. The solution space to k-SAT does not have a simple structure.
Thus, k-SAT is not in P, and thus P != NP.
Part 1 seems to be relatively uncontroversial (modulo some residual vagueness about what “simple structure” (my wording) means). The main difficulties lie in 2. To establish this claim, Deolalikar employs tools from finite model theory together with some other methods revolving around independence. It seems to be generally believed that these tools are not strong enough to establish a claim such as 2. However, while developing these tools, it appears that Deolalikar has accidentally (and incorrectly) amplified the power of these tools from something that is too weak to establish this claim, to something that is far too strong for establishing this claim. As a consequence, he proves statements about k-SAT (and hence about complexity classes) that are too strong to really be believable (and in particular, appears to establish the incorrect claim that k-XORSAT is not in P).
It is interesting to note that the finite model theory experts are the ones that have been finding quite specific concerns with the paper, and that the random SAT and complexity experts are the ones that are finding the “high-level” objections to the paper. This seems to suggest, as I have done above, that the errors are first originating in the finite model theory sections but are only really manifesting themselves when those sections are applied to random k-SAT and thence to the complexity conclusions.
Is it really true that 1) is relatively uncontroversial ? My (admittedly non-expert) reading of Lindell’s objection is that the claim about FO+LFP only producing simple solution landscapes is itself in question, because the tupling argument used to construct this claim has problems with it.
It seems more like 1) has problems, and even if it were true, it seems to be proving more than 2) (essentially dragging along k-XORSAT for the ride)
I’m not sure this summary is quite right (or at least not quite the way I see it). I agree with your description of the general strategy, but I’m not sure that (1) is uncontroversial. I think that he proves this “simple structure” for only certain forms of LFP formulas (or, if you will, certain classes of polynomial-time algorithms) and then asserts that they apply in general. It is this generalization step that is problematic (as indicated by the issues with tupling/locality and order-invariance).
In fact, I see (2) as less problematic. So, let’s call A the class of problems that can be defined by monadic LFP formulas (where all stages are order-invariant). The solution spaces to these problems have simple structure. It is quite possible (but I don’t have the grasp of statistical mechanics to follow the argument) that he proves that k-SAT is not in A. The problem is that we can then also show that k-XORSAT is also not in A. This shows that A is not all of P, and therefore his generalization step in (1) going from simple structure for A to simple structure for all problems in P fails.
What is true that for every P problem ‘there is’ a simple solution structure– this is trivial as the working of the P algorithm on an instance can taken to be a ‘solution’ for that instance. However, if one fixes a particular notion of ‘solutions’ for a problem, then the ‘structure’ of that particular ‘solution space’ need not necessarily be ‘simple’ just because the problem happens to be in P. Is this what Anuj saying?
1. The solution space to P problems have a simple structure.
2. The solution space to k-SAT does not have a simple structure.
Thus, k-SAT is not in P, and thus P != NP.
Part 1 seems to be relatively uncontroversial (modulo some residual vagueness about what “simple structure” (my wording) means).
My impression has been that Part 1 is the controversial issue, but I suppose that does depend on what is meant by “simple”. For every instance of size n, you can describe its solution space in n bits. The paper under discussion wants to say that every problem in P must have a solution space with “small parameters” and I believe that’s what most people have been worried about, although it’s very possible I missed some key discussion out of all the hundreds of comments.
I have included a specific distribution of 2-SAT formulas where the solution space resembles that of the hard cases of the k-SAT phase transition, here:
http://michaelnielsen.org/polymath1/index.php?title=Deolalikar%27s_P!%3DNP_paper#Issues_with_random_k-SAT
Maybe we should try to understand how many parameters this distribution of 2-CNF formulas is supposed to need for its description.
It may be that a long link with lots of %-signs upsets WordPress—in any event Dick had to manually edit the same Random k-SAT link, which I sent by e-mail directly from the wiki page, when he translated the post from LaTeX last night. The link is just above the section heading “Deolalikar’s Answer”.
Ryan, I don’t quite understand your objection to (1). I have read your comments in the link, and they are very good. But they only explain why NP problems may have a simple solution space (via Valiant-Vazirani), and not why a problem in P may have only complicated solution spaces.
I think the counting problem for 2-SAT is #P-complete. Therefore, the solution space of 2-SAT cannot be “simple” in the sense of “fully characterizable” in polynomial time, because then one could use that to count the solutions.
But I wonder if VD’s idea of defining random distributions over SAT variables could inspire an interesting complexity class, distinct from NP and #P: the class of solution-generating problems associated with NP problems. More precisely, given access to a stream of random bits, the problem is to generate solutions to (say) SAT, such that each solution has a non-zero probability of being generated, and no incorrect solutions are ever generated. It could be called $P, for solution-generation P.
Note that this isn’t stronger than #P – the random generation cannot be used to count solutions efficiently. So it is still conceivable that the solution-generation problem is easy for all P problems, and hard for SAT.
Maybe someone can easily see that this definition makes no sense – let me know.
Ryan, The solution set of 2SAT is closed under median closed; take any three solutions to a 2SAT formula and their component wise median will also be a solution. The converse is also true; any median closed solution set can be represented as a solution of a 2SAT formula. (Thesis of Feder sometime in the early 90’s; but quite easy to prove.)
Something similar is true of HORN-SAT as well; it is downward closed – component wise min of a subset of solutions is also one. Of course, k-XORSAT is a linear subspace.
All of these problems within P have some nice structure in the solution space as well. It is not clear if any of these can “mimic” the k-SAT solution set distribution.
On an unrelated side note, I cannot help but feel that we are watching a cloud and inadvertently imposing our own fantasies in trying to read D’s mind. How else can we explain that nearly a week later we still do not know what “simple structure” or “parameter” is?! And we are all reading a paper without a single original lemma in it? and 120 pages at that!
It is not necessary to prove that a problem in P may have only complicated solution spaces. Again, the specific claim in doubt is: every problem in P must have solution spaces that are “not complicated”, in some sense. To refute this claim, we need only find some problem in P and some infinite sequence of instances (or some infinite sequence of instance distributions) for which the solution space is “complicated”. I could be missing something, but that appears to be the main issue.
In the wiki, I also explain why “complicated solution space” is not necessary to have a hard problem, either. That is a separate objection, more “philosophical”, but it says that the property of k-SAT he wants to use to separate P from NP does not hold for some problems which are NP-hard (and probably NP-complete, under plausible derandomization assumptions), i.e. UniqueSat.
Ryan, I don’t think you are missing anything; agree with you that all we need is some problem in P and i.o. “complicated” cases.
It is also becoming clear that the “parameters are large” cannot be something as simple as “exponential number of them far apart.” But it is unclear what D has in mind when he talks of parametrization.
D says (p36 of 8_11.pdf): Take the case of clustering in XORSAT, for instance. We only need note that the linear nature of XORSAT solution spaces mean there is a poly(log n)-parametrization (the basis provides this for linear spaces).
My intention was to point out that 2SAT also has a similar alibi which may get used . For example: Take the case of clustering in 2SAT, for instance. We only need to note that the median closed nature of 2SAT solution spaces mean there is a poly(log n) parametrizaton ….
V Vinay, you are absolutely right. The 2SAT solution spaces, HornSAT solution spaces, and XOR-SAT solution spaces have tons of structure. (The median property of 2-SAT is quite nice, I think I first saw it in a preliminary version of Knuth vol 4.)
However, I figure that any “barrier” theorem would have to to be about the same kinds of properties apparently used in the paper under discussion: general descriptions of how far apart solutions are, how many solutions are close, things like that. These descriptions do not actually look at logical relations between satisfying assignments such as those you point out, but rather they look at assignments “comparatively”, like points in a metric space. It still looks plausible to me that P-time problems can mimic k-SAT solution spaces at this level of granularity, although I admit I haven’t thought deeply about this (SODA reviewing must go on).
I agree with Ryan’s comment that part 1 is the controversial one from the finite model theory point of view, not part 2. In fact, as I see it, Deolalikar does not even attempt to prove part 2 in his paper and, possibly incorrectly, infers it from known statistical physics results — and this is a big issue with the overall proof “synopsis”.
My current take is that there is a big missing piece: independent of the finite model theory issues, the whole proof strategy relies on part 2 which is neither already known to be true nor attempted to be proven in the paper.
Yes, part 1 is certainly controversial.
This “complex” structure that physicists have observed in K-SAT and Q-COL was first discovered AND rigorously proven in K-XORSAT in the early 2000′. The belief in the statistical physics community is somehow that “Unless a magic symmetry is exploited (as in XORSAT), then the problem is really hard”…
The trouble is, of course, to prove that there is no such Hidden symmetry in SAT and/or COL!
“The trouble is, of course, to prove that there is no such Hidden symmetry in SAT and/or COL!”
Isn’t this exactly the content of dichotomy theorems, like Schaefer’s?
I think this is a summary that everyone was waiting to see – to streamline further reviews.
This one is ‘magisterial’ too 🙂
“Don’t rely on social processes for verification.”
Some people here have uttered the opinion that D. should have waited with the announcement of his proof (attempt) until he had a more rigorous version of his proof.
The most rigorous version of a proof is a proof that can be checked by a machine. There are powerful tools available today that enable to create such proofs, for example Isabelle or HOL-light or Coq. Theorems like the four color theorem, the Jordan Curve theorem or the prime number theorem have been proven in/with them. There is also an ongoing project to formalize the Kepler Conjecture.
You could soften this most rigorous approach by allowing sublemmas to be unproven, so that we have only a proof skeleton. Such a proof skeleton can be used so that concrete questions can be asked, and precise answers to those questions can be given (maybe by providing a machine-checked proof of the lemma, maybe by providing enough informal reasoning).
What is your opinion about this? Why is it, that only so few professional mathematicians, like for example Thomas Hales, try to pursue such a road?
Formalization and mechanization of mathematics is a very interesting projects in my view. However, Vinay’s paper is far away from the rigor expected out of any standard mathematical paper. So it is early to talk about formalizing the proof, because, as I understand, even basic definitions in it are not yet clear.
Can ANYONE here PLEASE give a precise definition of number of parameters that seem central to the proof. He claims that distribution for k-SAT solutions requires exponential number of parameters, and polynomial algorithms can only give O(2^poly(log(n)).
But how does he count these parameters?
Is it something standard in some of the fields (in that case, would someone PLEASE give an explanation) or is he just hand waving. He never gave a precise definition of that, the number of parameters required, which is according to his own words the key idea. But he gives lot of other background. Such shabby imprecise writing is very strange, and one wonders if it is deliberate. Also, since this is central for his paper, it is hardly possible to get into any depth if we do not understand the basic concept – how are these parameters counted. So, is there anyone who has ANY idea what he means?
I don’t think anyone can. Lack of definitions is the biggest problem of the paper.
There is talk that P!=NP says creativity can’t be automated, but it has also been said that the development of AI is independent of, orthogonal to the P<NP question. It seems quite possible, even more likely than not, that AI will be developed. In many labs in industry, academia and military, people are working towards AI. Today is like living in the years before the arrival of nuclear weapons. It was known they were coming. But unlike nukes, AI will proliferate, everyone will have it. It will be used to wage cyberwarfare and physical warfare. AI will magnify conflicts at all levels of society: between nations, paramilitaries, combatants of all stripes, gangs, criminals, companies against rivals, between opponents in lawsuits. AI warfare is the most likely resolution of Fermi's paradox.
I think the premise is misleading. If P=NP via a known, practical algorithm, we can automate much of
what would be considered creative. However, the converse is not necessarily true. I think the difference
is better stated: If P=NP, we can automate creativity right away, without having to understand the domain
or what constitutes creativity. If P \neq NP, then simulating human creativity may require knowledge of human capacities and desires. Even the latter has not been formalized, it is no more than a hunch.
Russell
The more I try to understand this manuscript, the more doubt I have. Here are a few concerns:
1. What does ‘The solution space to P problems have a simple structure’ mean? Does it imply that any decision problem in P has a polynomial delay enumeration algorithm for the number of solutions? We hardly could say more, as there are decision problems in P with corresponding #P-complete counting versions.
2. Did Deolalikar prove that the k-SAT problems have ‘hard’ structured solution space? Even if that was the case, either that kind of ‘hardness’ must be different from the hardness the solution space of XORSAT possess or his prove fails when saying that hardness is an indicator for being out of P.
Indeed for problems in P (such as perfect matching) and even in NL (such as 2-SAT), it is #P-complete to count the solutions exactly. That is, on the level of “counting solutions to an instance”, there is no difference in hardness between k-SAT and 2-SAT, for any k >= 3, they are all #P-complete. This is more evidence that the solution spaces of k-SAT can be “simulated” by those of polytime problems, but it would be nice to make these ideas more concrete.
I have moved the wiki page from its old location to:
http://michaelnielsen.org/polymath1/index.php?title=Deolalikar_P_vs_NP_paper
The advantage of the new URL is that it won’t (I hope) get chewed up on WordPress blogs. Note that the old URL will still work, but will automatically be redirected to the new page.
Please use the new URL whenever possible.
Incidentally, if there’s some unanticipated problem with this, please let me know, and it can be moved back. But at the moment I don’t see a downside to making this move.
Why is it that proofs need to be rigorous and correct but proof critiques need not be?
Isn’t there the potential for libel — especially when the proof critiques are in such a public forum?
Hi Amir, I don’t see leadership like Tao or Gowers (or Lipton or Regan) taking anything other than an optimistic approach to the offered proof and the conversation around it. Even strongly-worded objections (like Russell Impagliazzo’s) have been careful to engage only in mathematical criticism, not personal criticism. The people attacking the author personally are posting anonymously, and some are identifying themselves as graduate students.
As a graduate student myself, I have to wonder how many theorems those commenters have proved on their own. I certainly know, from the struggle of proving my own small-but-new things, that there are (sometimes very long) periods of time where you are sure you have the right idea, but you don’t know how to express it concretely, to anyone, including yourself. Or you start saying things to yourself that make perfect sense, and it requires eyes from outside to point out that your “clear” ideas have no rigorous underpinning.
I think anyone who has dangled their mind off the edge of nowhere like that has to feel for a guy who worked on his own for two years, had the guts to try to connect two research areas that are culturally far apart, and now has a preliminary draft of his work subjected to the most public peer review in the history of the world. Some people want to post snark; that’s on them. I see almost everyone talking about the math — what seems incorrect, and what can be built out of this whole process.
Amir: This is a good question. In a nutshell, a proof critique contrasts a proposed proof with (already known to be true) theorems, and demonstrates how it conflicts with established mathematical intuitions. A correct proof with these properties must be very subtle indeed, so the author of such a proof must be very careful in writing it up. Ultimately, most researchers believe it should be up to the author of that proof to demonstrate why these long-held intuitions must now be false, perhaps by giving alternative intuitions that explain the new proof. Any proof separating or equating P and NP should give us tremendous insight into computation, far more than we ever knew before.
All we are doing is trying to understand how this proof attempt squares with our established intuitions. It doesn’t appear to, so we are trying to figure out why. The default is to believe that the proposed proof must be wrong and the old intuitions/theorems must be correct. The former has not been read, revised, and understood by many people over years of hard thought, while the latter has. But you never know.
Thanks for the quick feedback! It appears that I did not quite assemble the jigsaw pieces in exactly the right order the first time around. Here is the second iteration:
—
The paper introduces a property on solution spaces, which for sake of discussion we will call “property A” (feel free to suggest a better name here). Formally, a solution space obeys property A if it can be efficiently defined by a special family of LFP formulae, the monadic formulae (and there may be additional requirements as well, such as those relating to order). Intuitively, spaces with property A have a very simple structure.
Deolilakar then asserts
Claim 1. The solution space to P problems always obey property A.
Claim 2. The solution space to k-SAT does not obey property A.
Thus, k-SAT is not in P, and thus P != NP.
It appears that Claim 2 is at least intuitively plausible in view of results from statistical physics, though there may still be some lingering issues as to whether the claim is actually proven in the paper. (I assume that this is where the machinery of conditional independence is being deployed?)
But the more serious difficulty is with Claim 1. The starting point here is the Immerman-Vardi theorem, which shows that the solution space to P problems can be described using the first-order logic of LFP. But this is not enough yet to establish Claim 1, because crucial properties such as monadicity are lacking; without such properties imposed, the solution spaces could in fact be quite complicated. Deolalikar somehow manages to obtain this monadicity, upgrading the relatively weak structural control afforded by merely having LFP formulae to the much stronger structural control of property A. However, this seems to have been caused by incorrectly amplifying the power of monadic LFP logic, and ends up proving far more structural control on solution spaces to P problems than one expects.
But now I’m confused as to the status of XORSAT in this narrative. Does the special linear structure of the XORSAT solution space ensure that it has property A? If so, in what way does the argument of Deolalikar seem to conclude that XORSAT does not lie in P?
Relatedly, do we believe Claims 1 and 2 to actually be true (regardless of whether Deolalikar’s proof is valid)? If we believe them both to be true, then this is still a non-trivial and potentially viable strategy towards P != NP. Perhaps the issue is hiding in the precise definition of property A…
But now I’m confused as to the status of XORSAT in this narrative. Does the special linear structure of the XORSAT solution space ensure that it has property A? If so, in what way does the argument of Deolalikar seem to conclude that XORSAT does not lie in P?
I think a middle “trivial” step is needed here.
1.5 (contrapositive) any problem whose solution space does not have property A is not in P
Now the problem is that XOR-SAT contradicts 1.5, because it appears to have property A, and is also in P.
The problem though, as Ryan and others have pointed out, is that lack of property A also appears to consist of two parts:
* “abundance”: many well-separated clusters
* “incompressibility”: Many parameters required to describe the space.
It appears that while k-SAT is know to be abundant, it’s open whether its incompressible, and he doesn’t prove it. XOR-SAT on the other hand appears to be abundant but not incompressible.
On the strength of belief, it appears to be that
* Claim 1 might actually not be true, or at least the proof appears to be flawed
* Claim 2 might very well be true, but there’s no proof of it, and he does not appear to supply one.
Well, logically, the fact that XORSAT obeys both A and P does not seem to contradict 1.5, instead it appears to be consistent with it… hence my confusion.
To rephrase 1 (or 1.5): is the claim then the assertion that a solution space to a P problem cannot be simultaneously abundant and incompressible?
If so, then the job of separating XORSAT from SAT falls to Claim 2… and specifically, to why exactly the argument that shows that SAT is incompressible can’t be carried over verbatim to XORSAT.
I misspoke. my statement should have read “XORSAT is in P and does NOT satisfy property A”.
Suresh,
I am confused by the following statement of yours.
“1.5 (contrapositive) any problem whose solution space does not have property A is not in P”
I agree with the statement above.
“Now the problem is that XOR-SAT contradicts 1.5, because it appears to have property A, and is also in P. ”
However, something is wrong with this statement above. Shouldn’t you be saying
“Now the problem is that XOR-SAT contradicts 1.5, because it appears to have not to have property A, and is also in P.
Anon: yes, sorry. I corrected my statement above, just as you say.
As you say, the issue is in the precise definition of property A. It is not clear (to me) from the manuscript what the exact definition is, but my best guess at the moment is that Claim 1 will turn out to be false, when the definition is made precise. In particular, XORSAT will fail to have property A.
As stated, Claim 1 is very likely false (it is definitely false if the Monadic LFP formula does not have nesting of LFP-operators). But let us not discuss this as it is not that relevant. If I may I would rephrase the thing as follows. Let “polylog-parametrizable” be a property of solution spaces yet to be defined.
Claim 1: The solution spaces of problems in P are polylog-parametrizable.
Claim 2: The solution space of k-SAT is not polylog-parametrizable.
Now, Claim 1 could be split as follows:
Claim 1.1: The solution spaces to problems in Monadic LFP are polylog-parametrizable.
Claim 1.2: Every problem in LFP reduces to a problem Monadic LFP by a reduction
that preserves polylog-parametrizability of the solution spaces.
From these Claim 1 would follow from Immerman-Vardi Theorem (we need successor or linear order of course).
Perhaps Claim 1.1 could be true (we know a low about Monadic LFP, in particular unconditional lower bounds using Hanf-Gaifman locality).
But Claim 1.2 looks very unlikely. The reduction that Deolalikar proposes is standard but definitely does not preserve anything on which we can apply Hanf-Gaifman locality.
Ah, that was a key point I was missing before – the role of reduction, and how one might possibly lose the crucial polylog-parameterizability property (I like this name, instead of the less informative “property A”) through this reduction.
I think this explicates the Claim 1 side of things pretty well. There’s still a separate issue I think on the Claim 2 side, because we still haven’t pinned down how Deolalikar manages to prove non-polylog-parameterizability for SAT in such a way that he doesn’t also prove the (false) statement that XORSAT is also not polylog-parameterizable. Of course, only one of the two issues would be sufficient to stop the argument from being valid as stated, but it would be good to understand things as much as possible here.
I would like to point out a logical fallacy in a lot of arguments of the form “he does not prove non-polylog-parametrizability for SAT without also proving it (falsely) for XORSAT.” I very well understand the general wisdom in putting attempted proofs to such tests (proving “too much” thereby falsifying known theorems) but I think the XORSAT issue is being misunderstood.
Please note that he *only* needs to prove non-polylog-parametrizability for *only* random k-SAT (in general and for large enough k). If we never knew about efficiently exploiting and solving linearity, XORSAT would still have been one of those problems in NP that although not quite NP-complete (in fact almost surely not NP-complete, unless NP \eq co-NP), are not yet known to be in P either (such as factorization and discrete log).
But you say: “But we *know* how linearity enables XORSAT to be in P so there *must* be some way it escapes the fate of SAT!”
This is just the argument, but now all Deolalikar’s proof really needs to establish is a way in which this linearity property of XORSAT enables it have polylog-parametrizability and that’s it. There’s your distinction. No circular arguments.
Of course, this is not to say Deolalikar’s proof is defensible, because:
1. He needs to rigorously prove that “polylog-parametrizability” (itself defined precisely) really has something to do with the separation of P vs NP.
2. He needs to rigorously prove that random k-SAT, in general and for large enough k, simply *cannot* be polylog-parametrizable. (Some kind of lower bound.)
3. He needs to rigorously prove that random k-XORSAT (due to its inherent linearity) *is* polylog-parametrizable.
If 1, 2 and 3 go through, his overall strategy could definitely end up being more than useful.
That is a nice summary.
“But Claim 1.2 looks very unlikely. The reduction that Deolalikar proposes is standard but definitely does not preserve anything on which we can apply Hanf-Gaifman locality.”
-seems like a fundamental bottleneck. Is there a short answer to why Hanf-Gaifman locality does not apply to LFP employing k-ary relational symbols?
This is trying to answer Jutla’s question: “Is there a short answer to why Hanf-Gaifman locality does not apply to LFP employing k-ary relation symbols?”.
The standard reduction from k-ary LFP to Monadic LFP consists in mapping a structure A into it’s power structure A^k, whose universe is the k-th power of the universe of A and whose relations include k projection relations P_i for i = 1,…,k, where P_i relates a tuple (a_1,…,a_k) to its i-th projection a_i (which we can identify with (a_i,…,a_i)). This way we can represent a k-ary relation on A by a unary (i.e. monadic) relation on A^k, and the projection relations serve the purpose of decoding the components of the tuple (which looks like an unavoidable thing to have if we are to simulate a k-ary relation by a monadic relation; but of course this is just the way we know how to do it).
What is the diameter of the Gaifman graph of A^k? It is pretty small: the Gaifman graph of A^k has a path of length 4 between any two tuples (a_1,…,a_k) and (b_1,…,b_k). Here it is: (a_1,…,a_k) -> (via P_1) -> (a_1,…,a_1) -> (via P_1) -> (a_1,b_2,…,b_k) -> (via P_2) -> (b_2,…,b_2) -> (via P_2) -> (b_1,…,b_k). So the diameter is 4, which means that the neighborhoods in the Gaifman graph include everything (provided the radius is at least 2). Bottom line: in A^k we have “local = global” which means that every point in A^k has exponentially-many (in n = |A|) possible neighborhood-types, as opposed to the 2^{polylog(n)}-many that occur in A (assuming A has O(log n) degree as in a random k-CNF formula with a linear number of clauses).
I’m not sure this was the short answer you were expecting. Please ask if something is not clear.
In follow-up to my recent reply to Jutla’s question, perhaps I should also say why Hanf-Gaifman locality does not apply if we work with k-ary LFP directly without the reduction to the monadic case. Here the answer is that if we work with k-ary LFP directly then the Gaifman graph changes after each iteration of the LFP-computation because we need to take care of the new tuples that are added to the k-ary inductively defined relation. And in fact, after O(log n) iterations, the inductively defined relation could very well include the transitive closure of the given successor relation R_E, in which case the Gaifman graph is again fully connected (a clique). Once we have a clique for a Gaifman graph, we have local = global.
Speculating further on this Property A, and along the thread on my previous comment and Ryan’s reply, what if the solution space of P might have complicated structure but always must have an easy ‘entering point’ that an efficient algorithm is able to find.
But this might well be too much of speculation.
To speculate a bit more, the property A could be “polytime samplable solution space”, since this seems to hold for many P problems (2-SAT, XORSAT, linear programming) but most likely does not hold for SAT.
Note, there is a technical problem with asking about the solution spaces of P problems, in that it makes sense only for search problems (but not all P problems are search).
A few times I’ve resisted trying to supply such a property, finding technical flaws beyond my threshold even for a blog comment. But given the interest in building “Property A” even in advance of the author’s expected better treatment, I’ll venture if this is taken as a partial attempt… I’ll phrase it as a property H of arbitrary Boolean functions f: {0,1}^m –> {0,1} rather than solution spaces. The other difference is, this is non-uniform. In general, following your 1.–2. notation in comments above, H(f) is a hardness predicate if:
1. For all sequences of Boolean functions [g_m] in P/poly, for almost all (or variously, inf-many) m, H(g_m) = 0.
2. For functions f = f_m you’re trying to lower-bound, H(f) = 1.
My simplest idea trying to involve Deolalikar’s concepts is to take some distribution(s) D on {0,1}^m, a sufficiently fast-growing function c(n), and define:
H_D(f) == There exists an “easy” predicate R(x,y) where y \in {0,1}^n such that:
(a) f(x) = 1 (\exists y)R(x,y) [R is a witness predicate for f]
(b) The induced distribution E(y) = D({x: R(x,y)}) does not have fewer than c(n) “factors”.
Or use more-particular concepts from Deolalikar’s paper such as “parametrization” to define the predicate in (b)—that’s what would correspond to “property A”. Can something of this general form be made into a would-be hardness predicate? Note that the definer can choose D. The point presumably would be that some D giving a hardness predicate can be supported on the k-CNF subset of the instance space, but not on the 2-CNF or XOR-CNF subsets.
I rejected this because if R is given by poly-size circuits, there are only 2^poly ones to go around, so H(f) holds for at most 2^poly f’s out of 2^{2^m}. This seems too sparse to have real use. The role of “D” has technical problems too—defining it for f = SAT might not work for other f, so maybe it needs to be brought within the quantification. So I’ve left more work to do before this even becomes a concrete “strawman” target for trying out the XORSAT/2SAT objection, but maybe it will help—or better, the author will clarify.
But at least this may helpfully illustrate a couple of Deolalikar’s ideas. For one, note that usually we’d expect a distribution D over Boolean formulas \phi to be symmetric: if you permute the variable labels to get \phi’ you’d expect D(\phi) = D(\phi’), and ditto if some variable x_i and its negation -x_i are interchanged. If so, then E(y) simply becomes the uniform distribution on {0,1}^n, which factors into n fully-independent distributions on {0,1}, corresponding to each variable. But if D is asymmetric, maybe E(y) has nontrivial structure and this has a hope. What’s going on in the paper is more complicated, so really E(y) shouldn’t be this simple. But somehow somewhere, the verb “symmetry-breaking” should correspond to a noun denoting some object that is not symmetric.
May as well finish with a statement of the “Natural Proofs” barrier: Suppose your hardness predicate H(f) is decidable in time 2^poly(m)—note that its argument f can be a truth table of size 2^m. Suppose also that H(f) = 1 for a moderately dense fraction of f’s—say 1/poly(2^m) percent of them. Then your hardness predicate can be incorporated into an algorithm that has a larger probability of breaking any given one-way function or pseudo-random generator than is currently believed possible, relative to the time it expends. Likewise for factoring integers, on which most current such functions and generators are based—thus it would be a “phase shift” in our confidence in Internet security. Since the current belief has stood up for many years, researchers take this as a guide that any successful hardness predicate must either be extremely complex to decide or must be strangely “just-so” sparse—recall above I thought my H_D to be too sparse.
Part (a) of my definition of H_D(f) should read
(a) f(x) = 1 if-and-only-if (\exists y)R(x,y)
—I forgot that the angle brackets in the symbol for this would get blipped as (non-)HTML brackets.
Ah, so “a property A of solution spaces” is just another hardness predicate. Find any A that fails for SAT, and you’ll have a hard time proving that A holds for a given polynomial-computable function f that purports to solve SAT. That is discouraging, but at least I now better understand the vicious natural proof barrier…
Now if only you could convert the function f to a special class C where the property A is easy to check, and that can express any polynomial algorithm! (This seems possible, C could be some formula in FO+LFP.) But, alas, the conversion will not preserve property A…
1. More comments helpful, specially for non experts, about the 2-SAT/k-SAT issue related with this post at comments 1,5,9,13,16,17,21 and 34,35 of today´s post of Scott Aaronson´s blog.
2. By reading the whole discussion, at a very high level, all separation proofs that are based on concrete definitions of algorithms and concrete definitions of properties of problems seems like trying to lift up a heavy body while standing on it.
How can you convince others that your concrete definitions of algorithm and properties acting on any a well defined mathematical object (instance of a computational problem), captures all possible actions (algorithms), and all possible perceptions (properties) relevant for telling easyness appart from hardness, ? It seems that a separation proof for two adyacent complexity classes needs abstraction at least from concrete properties or from concrete algorithms. Computational complexity is about complexity classes and i guess unknown separation or equivalence within classes must be attained by extracting contradictions from already known class separations. Just a guess.
3. As an observer, thanks much to all, Mr. Deolalikar, expert-critics (this combination of mathematicians, TCS generalists and TCS especialized in the tools of the proof, for polymath peer review seems unbeatable) for this 3 days of real scientific action. Congratulations for this (still under construction) collective result !
Niel Immerman has sent an objection to the Vinay. I suggest that someone in the group email him and ask for his remarks and permission to add them to the wiki.
Yes, it will be good to know what Immerman wrote to Vinay Deolalikar.
And it will also be good to know what Immerman has to say on the doubts I raised concerning his 1986 paper. See here: http://rjlipton.wordpress.com/2010/08/08/a-proof-that-p-is-not-equal-to-np/#comment-4818
I hope someone else can also double-check Immerman’s proof and verify its correctness.
Here’s my 2 cents:
I’ve previously worked for HP Bangalore as a software engineer. HP kind of had 3 divisions in Bangalore: Labs, Software and Consulting/ Outsourcing.
The division I worked for, Software had quite an emphasis on innovation. We had the option of research disclosures, or patents. Some of the walls in our building were covered with framed certificates of innovations made by local employees. I found the environment to be tremendously empowering for innovation, especially my boss was really encouraging!
To extend this, I can only imagine what the environment would be like at HP LABS in the US, where Vinay hails from! So it would be for HP Labs Bangalore!
I have graduated with an M.A. in CS at Wayne State before.
But I’ve never felt as empowered to publish anything, even though I think learnt an irreplaceable lot there!
So in fact, I published my first paper, a research disclosure while at HP. And, I was brimming with so much confidence that I published a book AFTER I left HP.
http://amzn.com/1452828687
Even though Vinay’s (and possibly mine) attempts may turn out to be duds, I would encourage you to keep an open mind. Don’t hang us for trying!
The state of affairs is reflected in the fact that, even though there are a ton of brilliant people in US schools, somehow they do not seem to have the confidence or initiative to do great stuff. Maybe its the government funded central research that’s killing innovation. Everything is mired in “String theory” to please the NSF and NIH stuffed suits.
While I was studying in the US, I just thought of my school’s low ranking and that I could possibly never do anything considering my low perch! But I now realize that even people sitting high up in US universities are too strait-jacketed to do anything. No wonder, an outsider, Grigoriy Perelman could develop on Richard Hamilton’s Ricci flow to confidently give his solution. On arXiv.
In the end, I’m a strong believer in the future of corporate innovation.
Go HP!
Milz
Milind – I like your point.
some minor objections
(A) Perelman was no outsider – at least from his biography I never got that kind of an impression
(B) Corporate innovations have happened in the past too – it is not a new thing, some of them are phenomenal by any standard.
(C) Agreed that there’s no reason to believe that – a randomly chosen researcher R_z from a lower rank institute (say, I_z) must end up with lesser contributions than another randomly chosen researcher R_a from a highly ranked institute (say, I_a).
however, if there’s a large gap in the ranking, i.e., a << z – then, the (frequency based) probability of the above statement holding true increases – at least historically. does it not?
just like the hard and easy instances in NP …
As a mathematician, I can confirm that Perelman was no outsider at all. Actually, before the Ricci flow papers he had already lectured extensively in the US, and he had even been offered positions at top universities.
@rjlipton:
I have nothing competent to offer on the subject matter here.
I do want to express my deep admiration and respect for this post and the collegial process that it describes.
As much as everyone wants to know the truth on how P relates to NP, I get a feeling that theoretical computer science, complexity theory in the least, will start to look a bit pale if the question is resolved. At least for some time.
Almost like Jordan retiring from NBA.
The pursuit will continue, but at least for some time, a transient emptiness is bound to be felt.
P \neq NP is really the WARM-UP question for complexity, the easy puff piece to get us going on the
more precise quantitative questions we really want to know. It’s just taken us a while to get going…
We really want to know exactly how hard search problems are, what instances of search problems are
computationally intractable, whether there are average-case hard problems, and whether hard problems
are useful for cryptography. However, the attempt we are talking about here has the potential to skip
right to the punchline we are really after, if correct. It is talking about random instances of SAT, which
would imply one-way functions if proven hard. However, there does seem to be one proviso: it is not
talking about the complexity of the decision problem for these instances (which is really to say “Satisfiable” for the class he is talking about, since they are satisfiable almost certainly), but about
the worst case problem of extending a partial solution to a complete one. Since most partial solutions
cannot be so extended, it might not imply even a hardness on average. (Think of the difference as
winning at chess from starting position, and winning at every winnable position. The second is much more difficult). On the third hand, it might be possible to show from this approach (if correct) that
the problem remains hard on a “planted partial solution”, and hence would give a one-way function.
Deolalikar’s proof IF correct would indeed provide one-way functions. The are ways to plant a solution in such a way that the resulting formula is taken uniformly from the hard region of the random ensemble (this is actually used in some of the proofs by Achlioptas and in physics referred to a “quiet planting”).
@Martin: CSP dichotomies don’t help here, at least not via “slicing off” the easy parts.
There are infinitely many subsets of k-SAT that are in P (for instance, every finite subset is in P) but which are not of the form that the dichotomy theorems apply to. Many of these contribute to the undesirable behaviour of the space of solutions in a probabilistic sense.
András, thanks for answering!
I find Dick’s principle somewhat similar to the principle used in Baker Gill Solovay theorem.
There is an oracle B such that P^B != NP^B. Hmm, wonder if this is true for all oracles.
Not a formal argument, but imagine we “harden” xor-sat by encrypting the solutions somehow.
If we used a key that have <lg n bits, the problem would still be in P.
But alternatively, couldn't we have used some highly complex (but deterministic) algorithm that pre-spreads a key, say, from a seed of lg n bits into a key of n bits.
For most definition of succinctness (or komogrov complexity) the two problems have the same solution space complexity (since they are generated from the same number of bits of information).
But assuming the existence of highly complex key-spreading algorithm, isn't it unlikely for the second case to be in P?
还是期待着更大的证明
It’s possible in principle to have a result like Schaefer’s dichotomy theorem, saying that
“for any random Boolean CSP other than the following finite list (XORSAT, Horn-SAT, etc.),
if random instances have the following properties (clustering, frozen variables, etc.) then the problem is not in P.”
But I see no statement of such a theorem, just the informal phrase “in the absence of a property such as linearity.” The question remains what “such a property” is, and how to prove that SAT doesn’t have one.
VD’s latest comment on his webpage is rather easy-going.
“I have received many suggestions for improvement. A revised version with added material should appear here this weekend.”
He doesn’t seem to be fazed by the dozens of objections (some of them quite serious, apparently) flying around. I wonder how he could consider all these objections as “suggestions for improvement”.
But let’s see which way the crow flies.
It seems that this proof was declared toast several days ago (subject to no new material from the author).
Why is it that it still seems to be keeping people’s interest, and very important people at that. I am not an expert — but is there something in the method/ideas of value beyond this particular attempt at a proof?
Would somebody like to honestly comment—
had this been a proof of P==NP, would Deolalikar still get so much of attention from so many high profile academicians, in such a short time?
Check out
http://www.cs.umd.edu/~gasarch/papers/poll.pdf
2.2 How Will it Be Resolved?
1. 61 thought P6=NP.
2. 9 thought P=NP.
3. 4 thought that it is independent. While no particular axiom system was mentioned, I assume
they think it is independent of ZFC.
4. 3 just stated that it is NOT independent of Primitive Recursive Arithmetic.
5. 1 said it would depend on the model.
6. 22 offered no opinion.
Stephen Cook selected Vinay Deolalkiar’s proof, probably based on his credentials so I think P = NP would have worked?.
http://gowers.wordpress.com/2010/08/14/a-possible-answer-to-my-objection/
In comments TT defines polylog parameterisability.
I really wish I understood it 😉
It has been cool to be a fly in the wall the last few days watching the pros work. Thanks 🙂
Usually I do not post on blogs, but I would like to say that this article really forced me to do so! Thanks, really nice article.
I want to express Vinay my deepest respect for publishing what he was convinced to be a proof for P != NP. It is always easier to be smarter afterwards a la “I always knew that …”, than to have the courage to make a public statement about what one is convinced of.
I myself am convinced that P == NP, but I don’t have anything affirmative to offer,
so I congratulate Vinay for his great article (no sarkasm intended).
Manfred
I was a student under Fred ! I can say because of his teaching i have become a great programmer! Hope he must get a reward from the nation as a best teacher! thanks for sharing! I haven’t read the whole article, as i just saw the name Fred!
Mr Lipton, i would like to comment on the principle of proof you stated above.
In fact i agree with this, although in a slightly different manner.
Although it might sound strange for people abiding by the (neo-)platonic philosophy of mathematics, yet it is quite sound! The principle is that physics CAN limit mathematics in important and meaningful ways.
To make this clear, consider this. We have a (proof of a) theorem that when applied, under the appropriate conditions would imply, for example, that entropy would decrease in a certain system. Then we immediately know this to be false. Thus the theorem and proof is false. Unless one of course would like to keep the theorem and the proof to be useful and applicable in “some other world” and not this very one. One can be quite imaginative here and use various other physical principles (instead of the entropy example above) and check various theorems and proofs under this light. It is infallible and sound!
As a bonus, this can be used the other way around and provide actual (constructive) proofs (instead of just checking). But this is another matter.
Continuing my previous comment, let me cite a story/anecdote.
There were a number of philosophers in the ancient era, from various schools. There were stoic philosophers, eleatic, platonic philosophers and others.
They were arguing about whether there is actual motion in the universe or not. Then suddenly, one cynic philosopher stood up and walked away from the group and the discussion was over.