Quantum Algorithms A Different View—Again
A view of quantum algorithms via linear algebra

David Hilbert is famous, beyond famous. He is one of the greatest mathematicians of all time. I wish to quote him on theories:
A mathematical theory is not to be considered complete until you have made it so clear that you can explain it to the first man whom you meet on the street.
Today I want to expand on a previous discussion on quantum algorithms (QA). I had several ideas that I tried to convey in that discussion. Perhaps it was a mistake to try and do more than one. Oh well.
Let me try, again.
Algorithms Not Physics
My goal was to remove QA’s from any physical considerations. If this offends the quantum experts, then I am sorry. No I am not sorry. I think we need to do this to make progress.
We have done this decoupling almost completely with classical algorithms. When we explain a new classical algorithm we talk about high level operations—we do not talk about transistors and wires. Nor gates and memory cells. I would venture that few theorists could explain the details of how an L2 cache works, or how a modern arithmetic unit does pipelining, or in general how processors really work. The beautiful point is, it just does not matter for most of theory.
It is this ability to think at a high level for the creation and analysis of classical algorithms that, I believe, is the reason theory has been able to create such powerful algorithms. These algorithms are often described at a level way above any implementation details. I believe this is fundamental, and one of the cornerstones of why theory works.
Here are two classical algorithms: RSA Encryption and the Number Field Sieve (NFS). Both have changed the world, and were on Dick Karp’s list at the last Theory Day at Tech as great algorithms. Neither is described at a low level. For example, RSA is usually described in terms of operations on large integers—each of these operations requires millions of binary operations to perform. NFS is described also at a very high level. Without this ability I doubt that either algorithm would have been discovered.
I think that to make radical progress on QA’s we need to move away from a bit-level understanding and analysis and move to a high-level understanding. This is what I tried to supply in the previous post on quantum algorithms. If I failed in that goal, I apologize to you, but I believe that this goal is the right one. Perhaps someone else will be able to succeed in raising the level of detail—I hope so.
Geometry Not Quantum Mechanics
In that previous discussion I tried to make the assumptions needed to understand the Deutsch algorithm as simple as possible. This was to help a non-expert to “see” what was happening without any quantum mechanics details. I also believe that by stripping away tensor products, qubits, Hadamard Transforms, and all the rest we could lay bare what is really happening. I agree that none of these concepts are too difficult, but are they essential to make a person have a “feel” for what is happening with QA’s? I do not believe that they are.
I also hope that this view can be used by theory experts to make further progress on QA’s. If the details are pushed aside and all that is left is a simple question about unit vectors on the sphere, then I hope that we might be able to find new insights. I am working right now on doing this, and I believe that I may succeed. If QA are “just” questions about geometry, then I assert that we may be able to find new QA’s or prove new lower bounds. I still believe that is true.
Grover’s Algorithm
Lov Grover discovered one of the most important QA known in 1996. Or is that “invented?” The algorithm named after him is able to search a space of size 

Grover’s beautiful result has many applications. You can think of his algorithm as allowing the computation of an
It should be noted in this and many other applications there are nice interactions between Grover and standard methods. That is, the optimal results often follow from a “clever” use of Grover’s algorithm.
The Linear Algebra View
Let me explain Grover’s algorithm using just linear algebra. We begin in a state 

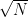





![{R \subseteq [N]}](https://s0.wp.com/latex.php?latex=%7BR+%5Csubseteq+%5BN%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
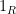


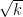

All states 


where 






The first operation is an 




where 




All pairs of different rows have dot product 




The algorithm then simply computes

where 


Grover Analysis
The key here is to prove that the algorithm works: that is after applying the matrix 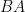



We can see intuitively from the above action of 




Finally, as we noted above, if we do not know
Open Problems
The goal here was not to supplant the current view of QA’s. Nor was it to not teach all the details to our students. The goal was both less and more important. It was to start to try to create a way to look at QA’s that was simpler, more accessible to many. And at the same time could lead us to discover new insights into QA’s. I believe that the more ways we can define and view a mathematical topic, the better is our understanding.
I hope that I helped in this regard. In any event thanks to all who read that discussion and this one. Thanks for being supportive—even those who disagree with this approach.
Trackbacks
- Interesting question posed; How to formulate an entirely new thought process for inventing Quantum Algorithms? « Interesting items
- Linkblogging For 02/09/10 « Sci-Ence! Justice Leak!
- Quantum Algorithms Via Linear Algebra | Gödel's Lost Letter and P=NP
- A Quantum Connection For Matrix Rank | Gödel's Lost Letter and P=NP


I agree that this picture of reflection operators is the best way to see Grover’s algorithm, and it’s how I teach it. (Grover’s original paper talks about a “flip around the average”, but rotation is clearer.) Indeed, a student can understand this without even knowing about complex numbers. It’s also true that there’s no need to delve into the “hardware” of qubits and gates for Grover’s algorithm.
For Shor’s algorithm, on the other hand, I think it’s difficult to understand why we can carry out something isomorphic to the FFT on Z_N in O(log^2 N) time without some sense of the circuit model and tensor products. We can talk about “quantum parallelism”, but if you take that idea too liberally, then quantum computers seem more powerful than they really are — e.g. you can get the (probably false) impression that we can solve NP-complete problems with quantum computers.
So at some point it gets confusing unless you actually embrace the mathematical structure of these operators. Moreover, the isomorphism between Coppersmith’s circuit for the QFT on Z_{2^n} and the butterfly circuit for the FFT is both beautiful and instructive.
When I was first learning about quantum computing, the challenge was understanding that n qubits live in a 2^n-dimensional space, giving unitary operators that are exponentially large—but that some of these unitary operators can be described, and carried out, efficiently. As you said in your previous post, we actually have the same thing in randomized algorithms, where these matrices are stochastic rather than unitary—we just usually don’t put it that way. Once we do, then tensor products really are just product distributions (sorry to repeat myself).
So while I agree with you that we want to work at a “software level,” and get away from individual bits and gates, I think that tensor products are essential to understanding what space we’re swimming in, and what operations we have a hope of carrying out efficiently.
Anyway, tensor products are part of linear algebra, not physics 🙂
Cris—we actually agree about tensor products, if viewed as linear algebra or “Nature’s way of Tupling” ;-).
One question I’d like to pose here: Discussions of Grover’s algorithm strike me as having in mind either of two basic settings:
(1) “SAT setting”: We model assignments in {0,1}^n by basis states of n qubits. Grover searches for a satisfying assignment in O(sqrt{2^n}) time.
(2) “Site setting”: We have N physical sites, some of which have gold coins. Grover finds a gold coin in O(sqrt{N}) time. (?)
This post suggests the former, with N = 2^n. My question is about the latter: is it regarded as true? There’s a paper by Aaronson and Ambainis that asserts yes by solving the problem of signaling time between regions.
However, that isn’t the full issue for me—maintaining coherence and the “scaling-up” problem in general strike me as involved. With Luddite obtuseness, I simply think searching N physical sites (as opposed to 2^n assignments implicitly held by n sites) requires N units of “effort”—in some sense of “effort” I’ve been unable to formalize (yet). Do you know of published arguments about this, or is it a non-issue?
If (2) were true, wouldn’t it be possible to take advantage of Grover’s algorithm to combine them with certain Parallel Computing algorithms.
Sorry, if I am misunderstanding you here. I am pretty new to this area.
I will try to identify a middle ground between Cris’ and Ken’s comments as follows. If we look for a geometric feature of Grover’s algorithm, and unravel that algorithm as a (random) quantum trajectory from an initial state to a final state, then AFAICT the most natural geometric property of that quantum trajectory is its mean length.
Without actually *doing* the calculation, we can hope that this mean length might plausibly (in some sense) be provably shorter-than-classical.
Now, if that is as far as we allow our calculations to take us, then perhaps we are wasting a geometric opportunity. We reflect that sailors way back in 1802 possessed a sophisticated understanding of Riemannian geometry as a local version of Euclidian geometry (due to Bowditch) … the sailors just didn’t *call* it Riemannian geometry (until 1854 or so).
Similarly, without our (presently) having a sophisticated understanding of non-Hilbert quantum dynamics, it is none-the-less feasible to convert the discrete projections of the Grover algorithm into continuous Lindblad processes, and pullback those Lindblad processes (by standard methods) onto the tensor network manifolds that Cris describes.
Then we can ask (mathematically well-posed) questions like: What state-space rank is required for quantum dynamics on tensor network state-spaces to achieve a computational speed-up in the same class as Hilbert state-spaces?
We can imagine this line of research as leading to as a cool proof that *only* linear Hilbert spaces support short computational paths … that tensor network state-spaces do not support efficient quantum computation for the geometric reason that their shape is too “foam-like.”
A nice aspect of this line of research is that it encourages us to read classic articles like Charles van Loan’s review article The ubiquitous Kronecker product (2000), which develops many of the themes that Cristopher Moore’s post mentions.
The general theme of van Loan’s review is that a considerable portion of vector-space projective “magic” generalizes naturally to Kronecker-space pullback “magic” … thus his article is particularly well-matched to Dick’s and Ken’s recent post “Projections Can Be Tricky.”
As van Loan says, “By and large, a Kronecker product inherits structure from its factors”, and it often happens—in quantum dynamical systems in particular—that the structure of the factors is precisely what are interested to preserve, for various informatic, dynamical, or computational reasons.
I have to agree with Cris here. Thinking about quantum computation only in terms of linear algebra where all transformations and measurements are on equal footing becomes thinking about quantum information theory. Not that there is anything wrong with that. Query complexity results like Grover’s and the related square-root(N) lower bound on searching are really about information theory and should not be considered algorithmic results. When a quantum question can be rephrased as a linear algebra question in one, big space (without those tensor products) we are indeed often able to answer it (e.g. the many tight upper and lower bounds in query complexity and the even more precise bounds in quantum information theory). Of course the same thing happens in the theory of classical computation with combinatorics playing the role of linear algebra.
ah,how surprisingly it is.seems we’ve got the same idea, here is my comments(http://rjlipton.wordpress.com/2010/08/15/the-p%e2%89%a0np-proof-is-one-week-old/#comment-6266)
Prof. Lipton says: This matrix is given as a “black box”—we are not allowed to inspect it. It really represents the verification predicate that an element is a solution.
Is it not the case that we’re actually talking physics right there – but just hiding it in language.
I’m not sure how much “real” physics is in the mathematical formation of quantum computation (or quantum mechanics). Perhaps the question raised is to find more useful of quantum “procedures” that can be referred to in high level. Kitaev’s phase estimation is such an building block (that can be used to do factoring and other things); that is, if a quantum operation Q satisfies some property then given an eigen vector of Q the corresponding eigenvalue can be computed.
More precisely speaking, there’s doesn’t seem to be a way to state in plain and elementary linear algebra on how one can implement this specific Oracle linear transformation ( A).
Definitely not with the knowledge of classical algorithms and its notions.
Comes physics, and one can bring in quantum zeno effect; to say even the fact that such a transformation is “probably” possible.
In earlier algorithms of Deutsch, Simmon, or even the most famous one due to Shor – this wasn’t needed. But not for Grover’s case.
I do understand that your point wasn’t to supplant the current view of a QA.
And I do agree that progress does happen when one raises the view level. The identification of wave mechanics and matrix mechanics into the Hilbert Space view was one example.
But at the same time, the sheer idea of quantum computing came from a thought that occured a very low {in the sense of being close the implementation} level.
I think both are important.
As a follow-up to the discussion of Charles van Loan’s The ubiquitous Kronecker product, and in particular the principle “a Kronecker product inherits structure from its factors”, let’s consider how van Loan’s ideas can extend our notion of a qubit. Our text will be another classic article, Richard Thompson’s Is quantum mechanics linear? (Nature, 1989).
In essence, Thompson’s article reminds us that resonance is an everyday phenomena; our eyes experience resonances as color, and our ears experience them as tones. Throughout the 19th and 20th centuries, experimental physicists studied resonant dynamics in smaller-and-smaller physical systems that were more-and-more carefully isolated, culminating in the near-perfect isolation achieved in today’s single-atom traps … which of course can be viewed as dynamical qubits and their d-dimensional generalization “qudits.”
Thompson’s article discusses the implications of a striking phenomenon: as we isolate qudits more carefully, their resonant lines become narrower, and their resonant frequency becomes more nearly amplitude-independent. Astonishingly, no experimental limit has ever been observed to either the line-width narrowness or the amplitude-independence; both have been verified to a relative precision of (very roughly) 10^(-22).
As Thompson’s article describes, physicists like Steven Weinberg have argued forcefully that these data require that the state-space of quantum mechanics be a Hilbert space, and that the dynamical evolution on that state-space be a linear unitary transformation. During the latter half of the 20th century, these arguments became so widely accepted, that nowadays most textbooks repeat them uncritically, or even state them axioms.
What articles like van Loan’s teach us is that Weinberg-type arguments have physical plausibility similar to Deolalikar’s claimed P≠NP proof … and similar mathematical rigor too! Which is to say, Weinberg-type arguments have plenty of physical plausibility, but (as we now appreciate) a notable lack of rigor.
The point is that the Bloch equations on a two-state qubit exhibit the same line-narrowing and amplitude-independence as larger Hilbert spaces. When we combine these states as low-rank Kronecker products, then van Loan’s principle “a Kronecker product inherits structure from its factors” ensures that line-narrowing and amplitude-independence can still be dynamically present, even on non-Hilbert Kronecker-product state-spaces (aka, tensor network manifolds).
These mathematical insights amount to the idea that unitary evolution on linear Hilbert spaces generalizes naturally to symplectic flow on Kähler manifolds, and (this is van Loan’s insight) there is no obvious conflict with experiment in doing so.
These ideas have been rattling around ever since Dirac, and have been stated plainly by authors such as Ashtekar and Schilling. What’s new is the dawning recognition by mathematicians that these ideas are natural and beautiful … and the dawning recognition by systems engineers that these ideas are immensely useful in practical simulations … and the dawning recognition by physicists that these ideas might even be true.
What this means, in practice, is that some barriers in computational complexity are going to fall, and others are going to be evaded … and in consequence, new opportunities are opening for everyone.
The theme of this Lipton/Regan post being “Quantum Algorithms: A Different View”, the lesson here is that one undoubted service that we can do for our students, is to help equip them with a broad mathematical toolset, in preparation for a 21st century in which—for sure—everyone will be evolving new views of quantum algorithms (and classical ones too) … which is fun!
PS: The above post was written largely in homage to the themes of tomorrow’s workshop “Barriers in Computational Complexity,” which is sponsored by Princeton’s Center for Computational Intractability.
Speaking as someone who is neither presenting nor attending, but nonetheless has a keen practical interest in computational complexity (both classical and quantum) … this is going to be a terrific workshop.
As with any complexity-related workshop—and what workshop isn’t complexity-related?—the broader the mathematical toolset the participants bring to bear, the better (and more fun) the workshop.
That is how, by gently cultivating a broader base of mathematical understanding, weblogs like Dick’s are accomplishing (IMHO) a great deal to make every conference better.
Prof. Sidles,I really benifited a lot from your brief comments on quantum mechanics,thank you very much!
as considering:
==================
What this means, in practice, is that some barriers in computational complexity are going to fall, and others are going to be evaded … and in consequence, new opportunities are opening for everyone.
==================
I’m not sure I can hold the direct meanings of your words as like on proofing P!=NP problem.
Thanks, 住持! There are many good articles relating to geometric-versus-algebraic descriptions of quantum dynamics … see the reply to “anonymous” below.
One specific Barriers II talk that I had in mind was Scott Aaronson’s (Saturday) lecture “The Computational Complexity of Linear Optics”, on research that done with Alex Arkhipov. We quantum systems engineers admire this Aaronson/Arkhipov line of research very much (without necessarily appreciating all its ramifications); it’s exemplary of complexity-theoretic research that that “defines new opportunities for everyone.”
For sure, there will be *many* other excellent talks at Barriers II … it is very good news that Bill GASARCH is attending (since Bill habitually capitalizes his surname, I will too) and has promised to webblog about it.
I like this observation from Lance (Fortnow). If you have n’t seen it, then I encourage you take a look here:
http://people.cs.uchicago.edu/~fortnow/papers/quantview.pdf
Lance’s paper (titled One Complexity Theorist’s View of Quantum Computing) does a terrific job of explaining quantum mechanics from an algebraic and informatic point of view … and so it is highly regrettable that there is no similarly short and clear article (that I know) which explains quantum mechanics from a geometric point of view.
Here is the shortest self-study path that I know — it has the advantage of encouraging you to read two outstanding textbooks. Start by reading carefully Lance’s Section 3.2: Where’s the ‘bra’ and ‘ket’ notation?. Then open Dirac’s classic textbook The Principles of Quantum Mechanics and read Chapter 1, Section 6 Bra and Ket Vectors.
There Dirac states plainly what Lance’s article (for reasons of space) glosses-over: “The bra vectors, as they have here been introduced, are quite a different kind of vector from the kets, and so far there is no connection between them.”
At this point you are advised to (temporarily) *stop* reading Dirac, and turn instead to John Lee’s Introduction to Smooth Manifolds, specifically Chapters 5-6, titled Vector Bundles and The Covector Bundle.
Now you are in a position to say (to yourself) “Aha! Dirac’s ‘bras’ are Lee’s covectors, and Dirac’s ‘kets’ are Lee’s vectors. But what does Dirac mean, when he says ‘there is no connection between them'”
What Dirac means (expressed in the geometric language of Lee’s text) is that there is no connection between bras and kets that is natural (that is, independent of coordinate system). As Lee’s book explains, to establish a geometrically natural connection we require either (or both) of two kinds of structure: a symmetric geometric structure that is called a metric, and/or an antisymmetric geometric structure that is called a symplectic structure.
In particular, Hilbert space is endowed with both metric and symplectic structure; the metric structure allows us to compute probabilities (by associating length to trajectories), and the symplectic structure defines a geometrically natural dynamical flow (via the usual Hamiltonian potentials).
Now let’s do the following geometric trick: we’ll convert a tangent vector to a covector via the metric structure, then convert the covector back to a tangent vector via the symplectic structure. The resulting vector-to-vector linear map defines a third structure, which is called a complex structure … and you guessed it … Hilbert space is equipped with a canonical set of basis vectors in which the complex structure is our old algebraic friend: simple multiplication by “i”
Thus we appreciate the complex numbers that are (mysteriously) ubiquitous in Lance’s and Dirac’s text have a straightforward significance from a geometric point-of-view.
Now, whenever it happens (as in Hilbert space), that any one of the metric, symplectic, and complex structures can be computed from the other two, the resulting state-space is said to be Kählerian. As we might expect, comparably many mathematical articles have been written on Kählerian geometry as on quantum dynamics, for the natural reason that they are (in essence) the same wonderfully rich subject.
The upshot of this is that we recommend that quantum systems engineering students learn to appreciate quantum dynamics both backwards and forwards; both algebra-first and geometry-first. This approach to quantum dynamics undoubtedly is more work in the short run … but (we think) it is more fun in the long run.
Please excuse the self-promotion, but my paper (with Avinatan Hassidim and Seth Lloyd), A Quantum Algorithm for solving linear systems of equations shows that the problem of solving Ax=b and sampling from a distribution with Prob[i] proportional to |x_i|^2 is BQP-complete, and therefore a possible alternate model of quantum computation. If the size of A is NxN, then this corresponds to a quantum computation on ~log N qubits, and if A has condition number kappa, then it corresponds to a quantum circuit with ~kappa gates. This gives an alternate way to think about quantum computing in terms of linear algebra.
aram,
I know this paper. It is in my opinion an important paper, and I plan on discussing it in the future. So no excuse needed.
Hi,aram, the matrix inverse method, I think it’s very important and will be useful on changing our understanding of quantum mechanics.could you please give a more detailed explanation here?
Please let me join my colleague 住持 (above) in saying that a post on linear solvers would be very welcome … for at least seven (or more!) reasons as follows.
First, our whole UW QSE Group has heard Aram lecture, and we think this work is terrific! So hopefully, Aram (and Avinatan and Seth) would weigh-in on the weblog discussion.
Second, the problem Ax=b obviously is algebraic (duh!).
Third, the problem Ax=b obviously is geometric … because heck … if A is symmetric, and b is a gradient of some figure-of-merit (like energy), then what we are calculating is the flow toward an optimal state (like a ground-state).
Fourth, the problem Ax=b obviously is dynamic … because heck … if A is antisymmetric, and b is a gradient of some Hamiltonian function, then what we are calculating obviously a dynamical flow (like modes of an extended structure).
Fifth, the key to the problem Ax=b obviously relates to verification and validation … because how can we check whether a claimed solution is tight (particularly if a quantum oracle delivers it)?
Sixth, the problem Ax=b obviously relates to our understanding of God’s Algorithm … because without knowing (or guessing) God’s algorithm in a given case, how can we precondition the problem optimally … either classically or quantum mechanically?
Seventh, solving the problem Ax=b obviously (?) burns more computer cycles than any other (if we take into account this problem’s many guises and approximations) … and so perhaps anything we can learn to solve it better will help to create new jobs … and to enable new enterprises … both of which the world stands in urgent need of!
For these seven reasons—and no doubt more—a post on the topic Ax=b surely would be among the most challenging ever tackled by Gödel’s Lost Letter and P=NP … and would interest an exceptionally broad community … and would be among the most fun too.
Prof.Sidle,
It’s really my pleasure learning from you and other kind person here.
To be honest, I’m not very well aware of the great significance of the equition Ax=b as you have mentioned above, maybe my view is similar to the point in Prof.Lipton’s recent post “Lower Bounds and Progressive Algorithms”, the importance of aram’s paper can be verified by the matrix inverse method because his “progressive” algorithm(or proof) is natural and make sense to our intuition, an optimal balance between efficiency and error rate.
So I guess aram’s proof is somewhat isomorphic to the Heyting algebra, and I myself encouraged adding the intuitive eighth reason to your seven reasons, am I right?
住持, I am sorry not to get back to you sooner.
I really am a nuts-and-bolts engineer—meaning, we really design and build hardware based on our calculations. That is why my seven linear solver examples are very applied … and perhaps that is also why I have no idea at all, of what a Heyting algebra is!
The Wikipedia page on Heyting algebras was not very informative …perhaps it will be a long time before our QSE Group draws up blueprints for the machine shop to fabricate a Heyting manifold.
For an explanation of Grover’s algorithm from a more practical point of view, see
http://qbnets.wordpress.com/2010/01/06/grovers-algorithm-for-dummies/
For a fixed point version of Grover’s algorithm that works even if the product of states s and t is not small, see
http://qbnets.wordpress.com/2010/01/28/my-secret-life-as-a-captain-of-the-grovers-algorithm/
Not exactly related to this post; I had a question. I have just started learning about quantum computation in general from Nielsen-Chuang book.
I wanted to ask if anyone could try finding time to help me with whats going on with the measurement postulate of quantum mechanics. I mean, I am not trying to question the postulate; its just that I do not get how the value of the state of the system after measurement comes out to $M_m/\sqrt{}$.
Even though its just what the postulate seems to say, I find it really awkward that why is it this expression. I do not know if what I ask here makes sense, but this is proving to be something which for some reason seems to block me from reading any further,