A Breakthrough Result
A great result on circuit lower bounds

Ryan Williams is one of the top complexity theorists in the world, young or old. He has just released a draft of a result that moves us closer to understanding the mysteries of circuit complexity classes.
Today I want to give a short summary of what he has done, and how he did it. I think it is potentially the biggest, best, most brilliant—okay I really like his result.
The beauty of his result is that while the details are non-trivial it follows a schema that I believe could be used to solve other open problems. I think it could even solve
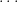
The Result
Ryan proves the following result:
Theorem: The nondeterministic time class
does not have non-uniform
circuits of polynomial size.
Actually he proves several other related theorems.
Note, the theorem shows a non-uniform lower bound. That is a breakthrough. Proving circuit lower bounds that allow non-uniformity is extremely difficult. Somehow the power of allowing the circuit to vary with the input size is very difficult for us to understand. For example, we still do not know if polynomial time is contained in linear size circuits—see my earlier discussion on this.
The Proof Schema
If you want to understand what Ryan has done see his paper. It is well written and explains the details in a clear and careful manner. What I will try to do is give a 50,000 foot view of the proof.

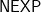

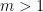

Lemma: The product of an
matrix with an
matrix can be done in
operations over any ring.
See his paper for the details. Wonderful.
Open Problems
Can Ryan’s results be improved? What happens if matrix product can be done faster? The last comment I will leave to Ryan:
“Improved exponential algorithms for satisfiability are the only barrier to further progress on circuit lower bounds for NEXP.”


That’s great!! Congratulations, Ryan (partly for having your name on top of one of this blog’s post)!
Hello,
Could you please link the paper, I can not find it.
Merci!
Over on Scott Aaronson’s Shtetl Optimized weblog, Scott remarks: While Williams’s techniques have nothing to do with Mulmuley’s GCT program, they do fit in well with the Mulmuleyist “flip” philosophy of “proving lower bounds by proving upper bounds.”
Here Scott is expressing a point-of-view that is very congenial to engineers, and which we can further develop by embracing ideas from Ketan Mulmuley’s FOCS 2010 GCT tutorial (to which the Fortnow/GASARCH weblog provides an on-line link).
During the concluding summary of Ketan’s FOCS tutorial he asserts: “The P versus NP conjecture is not saying that the complexity class P is weak; in fact it is saying that the complexity class P is extremely strong … so to prove that P is not equal to NP, you have to actually show that P is big, not small; this is very paradoxical. … The problem is, we don’t know what P is; this is really the main problem in complexity theory at this point. We have no clue. We have a great definition of the complexity class P, but we have no clue what P is. … What GCT theory is saying is “Now begins the real complexity theory of the hard kind.” … We really have to understand what the complexity class P is [and] this problem has turned out to be far grander than we expected.”
Expressed in a mixture of Scott’s and Ketan’s language, what Ryan Williams’ article does (AFAICT) is to expand the domain of classes lower in the complexity hierarchy in order to prove separations among classes higher in that hierarchy.
From an engineering point of view, this paradoxical “flipped” strategy is wonderfully attractive, because for engineers the expansion of lower-level complexity classes (like P) is itself a high-ranking utilitarian good. Indeed, if we are willing to embrace a strictly utilitarian point-of-view, then a pragmatic argument can be made that “the whole point” of studying separation problems is to sustain and accelerate the expansion of P.
Thus, a really beautiful aspect of Ryan Williams’ proof technology (IMHO) is the inspiration and pure enjoyment that its methods are providing across the broad spectrum of STEM researchers, ranging from pragmatic engineers to the purest ivory-tower TCS theorem-provers.
Why are Mod_m gates interesting?
http://cstheory.stackexchange.com/questions/2812/why-are-mod-m-gates-interesting
This brings me back to some thought I’ve had about finding solutions to problems in NP-complete.
If you could show that for some NP problem, every variation with input size N could be solved in P (with a slightly different program), would that give us some insight to P vs NP?
It could be practical, even if P != NP ultimately. Additionally, for each input size N, you could construct a program to solve the problem in sizes up to N by writing a composite program that use the N-input-sized variation and all its N-1, N-2, etc, invoking the right one based on its input size. We could then construct such a program for a big enough N to solve the problems with a known input size.
This would yield Pn = NPn, for all n.
Are there results anywhere that using this, would imply N=NP?
It sounds to me like you are describing the complexity class P/poly (with the clarification that you need to use the same polynomial bound for all sizes, otherwise it’s trivial because each size only has finitely many input possibilities).
Indeed as I google I find such a conditional result, although it doesn’t prove quite as much as P=NP. It’s the Karp-Lipton theorem (by our very same Lipton).
> If you could show that for some NP problem, every variation with input size N could be solved in P (with a slightly different program), would that give us some insight to P vs NP?
That is very easy, by letting the P program simply be the precalculated solution.
That’s not quite so. This is finding a program per size of input, not per input.
What he means is: since for a fixed input size there are only a finite number of inputs, we can store the answer to each input in a table. Our program then simply looks up the right answer from the table. So for any fixed input size we now have a constant time algorithm.
@Bart: Yes, you certainly can do that. You’d need a potentially-huge cache of answers though for this. Additionally, this wouldn’t scale very well, as each new input size addition would need more space every time. What I was referring to, it would be P-time, yet a new program with some alternate configuration that does not grow.
It’s like having 100 X-sized programs, instead of roughly 100*X X-sized constant-time programs.
1. That´s indeed a very nice result. The high level proof strategy is clear. A very simplified version (inspired by this post and the post in “In Theory” blog, i still have to read the two papers…) is:
A = NEXP has polysize ACCO circuits
B = ACCO circuit SAT can be done at least in SUBEXP (that is better than in 2^n time = exhaustive search).
C = NEXP has SUBEXP time algorithms (a fact that would contradict the non-det time hierarchy theorem).
If A and B then C.
B, therefore not A.
2. If this strategy was to be extended for lower classes (i.e. bellow EXPTIME) i wonder where a contradiction could be derived so deep inside the Matryoska complexity doll…
3. Industry seems quite active lately. HP in sumer, IBM in autumn (not that i´m comparing the two results)…aren´t they drinking on sources that Academy ignores ?
proanuiq: I wouldn’t call Ryan “industry”. He is doing a postdoc at IBM research (its true that many postdocs are now sponsored at corporate research labs), but just finished a PhD at CMU, and next year will presumably be a professor at some fancy department.
Hi,
I think that one critical point in Ryan’s beautiful work did not get enough attention: In order to apply Ryan’s technique, you don’t need a (weak) algorithm for deciding circuit satisfiability, but rather a (weak) algorithm for distinguishing an unsatisfiable circuit from a circuit that is satisfied by at least half of its assignments.
The latter distinguishing problem is easily solvable within RP, and the point is that Ryan’s technique requires a weak *deterministic* algorithm.
This fact is important for two reasons:
1. It makes Ryan’s technique much stronger and more applicable, since it is much more plausible to find weak deterministic algorithms for an RP problem than to an NP-complete one (i.e. Circuit-Sat).
2. More conceptually, I think that Ryan’s technique should be viewed as a very powerful instance of the family of “derandomization implies circuit lower bounds” results.
But where is the hard function for ACC circuits?! To call circuit lower bounds obtained by diagonalization and counting a “breakthrough” seems somewhat too generous … I don’t say the result is not interesting: it is! But not in the same level with, say, Razborov’s *explicit* lower bounds. Explicitness is the main adversary of people working in circuit complexity.
The result holds for any NEXP-complete function, such as Succinct 3SAT. Or am I missing your point?
My point is that problems about circuits themselves are not explicit ones. The problem with “succinct versions” of problems is that their inputs are circuits(!). Each circuit C encodes some object, say bipartite nXn graph G_C with n=2^m by: C(u,v)=1 iff u and v are adjacent in G; vertices u are 0-1 strings of length m. Given a circuit C, one asks whether G_C has a particular property. In fact, this is a property of circuits, not of graphs. To have an “explicit” lower bound one should exhibit a graph G such that any circuit encoding G must be large. Such a graph would give a hard to compute boolean function f_G(u,v), the adjacency function of G.
In fact, results of Yao, Beigel and Tarui imply that f_G lies outside ACC if t(G) is larger than n^a where a >> 1/\log\log n. Here t(G) is the smallest number t for which there exists a subset L of {1,…,t} and an assignment of sets A_v to the vertices v such that u and v are adjacent in G iff |A_u\cap A_v| belongs to L. Easy counting(!) shows that t(G) is at least n^{1/2} for almost all graphs. But how to *construct* at least one such graph, at least with the entire power of NEXP?
I actually think Ryan’s result is better than Razborov-Smolensky and the likes (Hastad’s, Furst et al., etc.). Because it does not use combinatorial trickery. It seems that it uses basically only “complexity trickery”. This is a far better framework for complexity theory.
A very interesting interesting point of view: results requiring involved mathematics are worse than those fishing around diagonalization or the like. I think, most students will be with you 🙂
But: is Majority in ACC? I think Ryan hasn’t answered it. That Majority is not in ACC[2] was answered by Razborov using “combinatorial trickery”. Can one re-prove his result using the “complexity trickery”?
Distinguishing between “combinatorial trickery” and “complexity trickery”, pretending that either one is inherently more “involved” than the other, is seriously absurd.
@Stasys,
You are wrong. Combinatorics is not “real mathematics”, certainly not “involved one”: because, it doesn’t regarded as “real mathematics” by a large parts of the mathematical community-so this breaks your sociological argument, and thus you are left only with the formal question: “why is diagonalization less mathematical then counting finite objects (i.e., finite combinatorics)”, and I don’t see how you can answer this formally.
@Anonymous: I agree, this is clear absurd. But I hope you apply this also to what “Friend” said: “I actually think Ryan’s result is better than Razborov-Smolensky and the likes (Hastad’s, Furst et al., etc.)”?
In fact, there even were serious attempts in circuit complexity to do “diagonalization in finite domains”: the fusion method (Razborov), the notion of finite limits (Sipser), etc. Even more, finite limits already *can* give exponential lower bounds for depth-3 circuits. I only don’t think that these “the likes” (as Friend named them) were less serious results.
@Stasys,
there is a difference between my distinction between “better” methods, and yours. I was just claiming that Ryan’s method seems more promising to yield further results in complexity, and gives a framework which is better suited to do so, than the AC^0 probabilistic lower bounds (or the polynomial method), or the monotone circuits lower bounds of Razborov.
On the other hand, you claimed, to my understanding, that regardless of the result itself a method which uses combinatorics is better than a method that uses “diagonalization”. I don’t see how you can defend such an argument.
About the “fusion” and Sipser’s results, I’ve read them once, although I don’t remember them exactly. But I don’t know they can yield Ryan’s result.
@Friend,
You use the term “complexity”, not more granulated terms “structural complexity” and “circuit complexity”. The first is “high level” complexity whereas the second is “low (very low) level” complexity. Hence, the difference in goals and methods. I do not claim that, say, diagonalization is a “poor” argument (sorry, if I could be understood this way): we have a lot of interesting results in structural complexity (and not only there – Cantor) based on it. But I haven’t seen any applications of diagonalization in circuit complexity, in proving lower bounds for specific functions (except for general approaches, and one concrete application of Sipser’s finite limits for depth-3 circuits). On the other hand, “combinatorial trickery” has already produced a whole row of lower bounds.
Shortly: my doubts were NOT about the MERITS of Ryan’s result (they are clear), but rather about its ALLOCATION. If you do not make a difference between structural and circuit complexity, then my doubts were, of course, a nonsense. But I do make.