Deolalikar’s Claim: One Year Later
Still no final chapter, lessons learned

Vinay Deolalikar just over a year ago claimed that he had a proof that 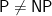
Today I want to make a short comment on the status of his claim.
I recently received an email asking: Has the anniversary slipped your notice?
No. But there is not a lot to say about the situation—for better or for worse. Here is all that we know publicly:

Lessons
Ken and I learned several lessons from last year’s event.

A Worry
My biggest worry about all this is that claims of a major result should be resolved in a timely fashion, since otherwise unpleasant claims of credit and priority may arise.
I worked years ago on an open problem in the area of decision procedures. I proved an 
Here is what I said happened: (The proofs are of the decidability of the problem.)
In act II, two proofs were found: the first by Ernst Mayr and shortly thereafter a proof by Rao Kosaraju. Many did not believe Mayr’s proof, since it was unclear in many places. Understanding these long complex arguments, with many interlocking definitions and lemmas, is difficult. Kosaraju created his proof because he felt Mayr’s proof was wrong. You can imagine there was an immediate controversy. Which proof was right? Both? Neither? There were claims that Kosaraju’s proof was essentially Mayr’s proof, but written in a clear way. The controversy got messy very quickly.
Finally, in act III there is now a new proof by Jérôme Leroux that seems much cleaner. and more likely to be correct. More on this in the future.
I would hate to see this happen with the much more important problem of 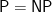
Of course, unlike the vector-addition case, there is no compelling sign of a proof here. However, there may be substantial contributions, perhaps new conditional results, that can possibly come from the work. This may be where the worry most applies. If there is something in Vinay Deolalikar’s long paper, then this is worth attending to, and the first onus is on the author.
Open Problems
How should we remember the event last year? Are there other lessons to be taken away?
Trackbacks
- “I’ll see your 10,000 and raise you…. « WWC
- Weekly Picks « Mathblogging.org — the Blog
- "I’ll see your 10,000 and raise you…. « Innovate.EDU
- Gödel’s Lost Letter and P=NP - erichansander.com
- outline for a NP vs P/poly proof based on monotone circuits, hypergraphs, factoring, and slice functions | Turing Machine
- Graphs and Bananas | QED and NOM
- the NIPS peer review experiment and more cyber zeitgeist | Turing Machine


To me, the lesson of it all is the following:
There are two components to a mathematical proof.
1) Whether the proof is valid or not.
2) Whether the proof is accepted as valid or not.
The overwhelming majority of people only care about 2).
I fully agree.
Can you give an example of a proof where (1) holds but (2) does not? Or where (2) holds but (1) does not?
Please stop saying “OR NOT” after saying “Whether”. You come across as ignorant when you say that.
“1) Whether the proof is valid.
2) Whether the proof is accepted as valid.”
is sufficient.
Don’t be a jerk, Chris. We’re here for hard corps computational complexity, not grammar. Substance before style, always.
In Russian we have exactly the same situation.
«Do you know WHETHER the proof is valid?» = «Знаешь ли ты, верно ЛИ доказательство?»
«How to tell if the proof is valid OR NOT?» = «Как понять, доказательство верное ИЛИ НЕТ?»
But ignorant russians say:
«I do not know WHETHER the proof is valid OR NOT» = «Я не знаю, верно ЛИ доказательство, ИЛИ НЕТ»
Do you know which journal this paper was submitted to and how long the refereeing process takes?
Do we even know whether it is currently under submission anywhere? Frankly, I suspect Deolalikar is never going to officially withdraw this claim of a proof. After all, nobody but him believes he has one, so the claim isn’t causing any serious problems, but withdrawing it would lead to a lot of renewed publicity he might not like. My guess is that the revised paper will be rejected, and indeed has probably already been rejected, and that he won’t bother to resubmit it anywhere else after rejection, but he won’t publicly announce that he has decided not to submit it again.
In the meantime, I think we should consider his refusal to circulate the supposedly fixed manuscript as a de facto withdrawal of his claim.
Dear Prof Dick Lipton,
Wonder if you can relax your reservations to comment on:
Had this been a proof of NP==P, would his paper had gotten as much of publicity? (Deolalikar ‘s paper)
As you mentioned, some very high profile researchers have read his paper. Why? Has there not been any comparable attempt in the other direction, i.e, NP == P proof?
Allow me to say– the TOC community is full of arrogant researchers. They are looking for an evidence of their beliefs! And this is called Science!!
Regards,
Yes, the CS community is full of arrogant researchers because they don’t buy Javaid Aslam’s “proof”.
and also the “NP=P proof” by anybody else 🙂
I’m intrigued as to why you think this episode displays arrogance – the TOC community may (or may not) be full of arrogant researchers, but not being one of them, I don’t know.
But with an outsider’s interest in whether P=NP, I suspect that any serious proof attempt in either direction would generate a similar flurry of activity. A similar thing happened a couple of years ago when someone had a serious go at finding a polynomial time algorithm for graph isomorphism.
Recent polls on “what do you guess the answer is” certainly do not reveal an overwhelming tendency to either view.
In case you aren’t aware of the backstory, Javaid Aslam has spent the last few years circulating a supposed proof of P=NP. It’s actually gotten far more attention than it deserves (for example, a real write-up explaining why it is wrong, at http://arxiv.org/abs/0904.3912). He should be happy that someone read his paper, rather than just dismissing it as crackpot work, but instead he seems to feel bitter, and he imagines unflattering reasons why TOC researchers are neglecting his work.
Turing, Anonymous & Gordon,
No, I am not bitter at all about whether my proof is/was read or not. That is an isolated event.
The frustration is about the TOC/TCS community’s belief that
NP=P ==> Pigs can Fly.
Is there an example of any proof on NP=P that got as much publicity as Devlalikar’s proof?
Yes, of course, I am indeed very grateful to the authors who provided a written feedback, and I did acknowledge that in my followup explanation on arxiv.org: http://arxiv.org/abs/0906.5112v1
PS1: I am too insignificant a researcher to have an ego constituting any bitterness about my work– not my day-job!
PS2: My revised proof is still far from complete, and a lot more corrections are in progress– . So I have nothing to formally claim as of now.
When all the excitement was raging on this site about the “proof”, I offered some comments about a tangential issue. What can be done on the educational side in order to raise the standards of rigor for presentation of mathematical proofs in order to minimize occurrences where authors are slow to realize the flaws?
A routine set of formal requirements is (at least at present) far too draconian for state of the art mathematical arguments.
But I offered the opinion – and still do – that there are sufficiently gentle requirements in this direction that would make a substantial difference and which could be integrated into the Ph.D. math programs.
I believe that there is a workable practical notion of “fully presented semiformal proof”, with theoretical underpinnings, which, if adhered to, would make it relatively easy to settle such controversies by properly placing the burden on the author at particular places in the presentations, in a way that authors would generally accept – greatly facilitating resolutions of such controversies.
Harvey,
I agree. What I think is that it is the duty of the author to make it clear what the new idea(s) are. This should be done up front, and as quickly as possible.
I would personally like to see the creation of a high-level computer “language” that mathematicians can use to write up their proofs so that they can be formally verified. Then, all the problems concerning “Is this proof correct?” would no longer be an issue. Ideally, this language should look like an abbreviated form of English that can handle phrases like “For every”, “there exists”, “Let us suppose that”, “Thereby contradicting the claim”, etc., to make the proofs easy for humans to read and to understand if they were so inclined; and it should NOT resemble symbolic logic or the regular computer programming languages, which are often time-consuming (to non-programmers) to read through to get the ideas of how they work.
(Incidentally, writing code in Object-Oriented languages like C++ already seems to me to be sort of like proving theorems, particularly in Category Theory; and conversely, proving theorems in Category Theory reminds me a LOT of writing code in C++.)
There actually are such languages. But these languages don’t answer the question, “Is this proof correct?” They answer the question, “Does the computer say this proof is correct?”
In an ideal world, these are the same thing, but in the real world, there is a huge difference.
There is a major difficulty with what Craig is suggesting – the so called proof assistants – but not the difficulty Craig mentions. Most of the proof assistants (Coq, Isabelle, HOL, etcetera) produce “proof objects” which are certificates that can be – and are – independently verified. In fact, they could be independently verified even by low level special purpose hardware devices. This seems to lead to some interesting research projects regarding “how certain is certain, practically speaking?”. This contradicts the last sentence of Craig’s post.
The major difficulty is that, at present, we are nowhere near having proof assistants for which it is practical to input serious state of the art proofs. There has been considerable progress along these lines, but more at the level of serious classical theorems that are extremely well understood. This is difficult enough. But something state of the art, barely understood – as all serious new things are – is presently hopeless to deal with on a practical level. There are some very special purpose huge projects associated with certain particular situations – e.g., Hale’s Flyspeck – http://www.flyspeck-blog.blogspot.com/
Harvey,
I meant that in the real world, mathematics is done by human beings. Because of this, you can have lots of knowledgeable professionals like Javaid Aslam (who posted earlier) claiming to have proven that P=NP and lots of knowledgeable professionals like Vinay Deolalikar claiming to have proven the opposite.
Suppose that Aslam or Deolalikar is able to code his proof on a well-known proof-checker like Coq, Isabelle, or HOL. Would the computer science community then suddenly accept that he’s proven that P=NP or P!=NP?
I doubt it. At best, what would most likely happen is that experts would get into deep discussions about how to interpret the results of the proof-checker, much like the deep discussions on this blog a year ago about Deolalikar’s claimed proof. Or at worst, the experts might decide to ignore the results of the proof-checker.
The moral: A proof-checker can assist, but cannot convince.
Craig,
“Suppose that Aslam or Deolalikar is able to code his proof on a well-known proof-checker like Coq, Isabelle, or HOL. Would the computer science community then suddenly accept that he’s proven that P=NP or P!=NP?”
The answer is YES, PERIOD!!!
The real problem is that formalising such a proof is nowhere near practical, even it’s correct, recently someone spent FIVE YEARS formalising the proof of the Four Colour Theorem, the whole thing looks like a huge package of source code of a computer operating system.
I’d have to take the opposite stance of Craig and say I think a lot of people would believe such a proof. The whole idea of the proof assistants is that they produce a certificate that can be _easily_ and _independently_ checked. By “easily”, I mean with a program at most a few hundred lines. (And IIRC there are even proofs that the checkers are correct.)
Now, such a proof is likely not didactic, so there would still be demand for a human-consumable proof. But even without, I think people would generally accept the correctness.
I don’t know of any profession where people would blindly believe something so important to their profession just because a computer says it’s true. I can’t see how Theoretical Computer Science would be any different.
@Craig: I don’t know of any profession where people would blindly believe something so important to their profession just because a computer says it’s true.
Radiologists interpreting CAT scans? Airline pilots flying by wire? Structural engineers using Finite Element Analysis? Physicists designing nuclear weapons? 🙂
Craig,
I met a handful of people who seriously doubt the correctness of computer checkable proofs, they fall into two categories:
a) mathematicians who simply do not like the idea of using a computer whatsoever
b) complete cranks
Tony,
If the CAT scan of a human being’s heart showed a rabbit’s heart, would the doctor believe it just because the CAT scan said so? Most likely he would attribute it to a computer glitch…unless the human got a heart transplant from a rabbit.
And who’s supposed to verify that the outcome of such program is correct? I don’t think I would trust any such program more than myself.
I conceived this as a response to Craig’s first point while in SFO airport, but now in ORD on my way home to BUF it’s relevant to the others as well. By current state-of-the-art, Craig’s 2) is all there is. IMHO, one cannot (yet) claim a human-for-human-written proof is verifiable as a Platonic ideal.
At the 1994 IFIP conference I asked Robin Milner how long it would be before we had systems capable of writing and verifying the kind of proofs we have students do in an undergraduate theory of computation course. I specifically mentioned proofs that certain context-free grammars recognize certain languages—of course the general problem is undecidable, so I meant some fairly simple examples. His reply took me aback: “Fifty years.” Is he still right?
At AAAI 2011 I got similar estimates on the time for a truly effective Turing Test the way Turing conceived it (though one respondent said it’s not robustly defined in his paper). The community is not so interested in this foundational problem full-bore because a lot of other great applications are getting done, and maybe they need to get done before we go full-bore.
A simple google search for “formalization of context-free grammars” or “verified context-free grammars” gives lot of interesting results, maybe not the ones you’re looking for specifically, but apparently in the same ballpark. See here for example a Coq formalization that all context-free grammars can be expressed by pushdown automatas :
http://coq.inria.fr/V8.2pl1/contribs/Automata.html
Now what exactly do you mean: that an expert in proof assistants can formalize the proof the student do, that a student in proof assistants technique car write those proofs, or that a theory of computation student can use computer assistants to write his proofs? I think the answer to the first question is a clear yes, the answer to the second is “it’s not trivial, but yes”, and the answer to the third is probably “no, unless he is really interested in proof assistants”.
I know of only one example where a teacher found practical to ask its student to learn the field material and its proof assistant formalization at the same time, it’s Pierce et al. remarkable “Software Foundations” course ( http://www.cis.upenn.edu/~bcpierce/sf/ ), which is about programming language theory, a field that is quite closely related to proof assistants. I know of other fields where domain-specific tools that students can use can help verify claims (eg. the ProfVerif and Cryptoverif tools in the cryptographic protocol community, or termination checkers for rewrite systems), but to my knowledge they’re not yet part of a all-encompassing mechanical verification from first principles, and more like software implementations of paper-proved proof techniques, like was the software that originally made the proof of the four-colours theorem, before it was fully formalized in Coq. But those communities are working on getting those tools “fully formalized”, and some of them may already have achieved that.
Thanks for detailed reply. A typical example is, prove that the grammar G =
S –> AB | BA
A –> a | AaA | AaB | BaA | BaB
B –> b | AbA | AbB | BbA | BbB
generates the language L of even-length words y \in {a,b}* that are not of the form y = xx.
Robin Milner may have thought I was asking for a computer system that, given a formal specification of L (and G), can generate the proof by itself. I first commented this story in the Fortnow-Gasarch blog here. But I’m happy to pose my query as what you call the “first question” above.
My personal lessons of last year’s “commotion”:
1) The research in TOC is much more rich and much more active than I (as well as many other people from other CS areas) thought.
2) There are even great blogs about the subject, but this is certainly the best.
I started following GLL exactly one year ago when news about Deolalikar’s proof had just swept the world and I was looking for more information.
Please, keep up the great work in this blog and thank you for it.
This looks like the dilemma on human checkable proof of the Four Color Theorem? I think my position is much stronger than Deolalikar’s Claim.
Please see:
http://math.stackexchange.com/questions/8752/human-checkable-proof-of-the-four-color-theorem
or see
http://mathoverflow.net/questions/44673/human-checkable-proof-of-the-four-color-theorem
The best service you can do to Deolalikar is to let this shameful episode pass into oblivion. There are “claims” of proofs of P=NP or P!=NP every month or so, many of them are much better presented (some even published in peer review journals), than the one by this “researcher”. Thanks mostly to this blog unprecedented attention was given only to Deolalikar, and his amateurish attempt at “proof” was consequently debunked in few short days. Bad light was shed not only on his ways, but on this blog too (apparently, bad light is preferred to darkness).
Several lessons could be learned:
*That authority can be easily abused to irresponsibly draw attention to a poorly written, amateurish attempt of solving famous problem if those who are in position unwisely choose to do so, just like it can be abused to marginalize work at its choice – the two sides of the same coin
*That level of research in industry, when disconnected from academia, can be quite abysmal – yet that people assume that just because it is something like HP it has some weight – which proved to be a myth, and default reputation of such auxiliary groups has been reset to zero
*Worst of all, that Deolalikar, who apparently to this day is in denial about failure of his “proof”, has, to put it mildly, serious credibility issues. Any serious researcher would withdraw his paper after so many loopholes have been explicitly pinpointed to him by professional researchers.
*That this blog, which for a while reaped increased popularity from the big media frenzy that it helped sow, is again giving undeserved publicity to Deolalikar, who should be just left alone to rest in shame.
Very well put Serialmoth.
Let me add (repeat)– if Deolalikar’s proof was about NP==P, then my prediction is that he would have not got even half the publicity under the same circumstances.
I hope serialMoth and Javaid won’t mind, if I humbly proffer a contrary opinion, that an increasingly likely (and hoped-for) outcome of this still-evolving process will be: (1) publication of an article by Deolalikar, (2) that has been substantially improved by peer review, (3) whose conclusions are accepted by the broader academic community, and that (4) provides solid foundations for further research, teaching and practical applications.
No doubt the MathSciNet review of Deolalikar’s article will (hopefully) be comparably enjoyable to read as the article itself. Misguided and/or inappropriately snarky reviews of celebrated STEM articles are particularly instructive … if anyone knows of good examples from complexity and information theory (comparable to Joseph Doob’s review MR0026286 (10,133e) for example), please post them, as a cautionary lesson for all. 🙂
Very humbly, indeed. Your posts take half of this blog and some other blogs too.
Cranks abound, but not all cranks are created equal.
However,
(1) There is in reality no article result to be published, certainly not about P/NP
(2) Proper peer review (that is rarely as in depth as it happened on this blog when the paper was shred into pieces) would certainly reject his “paper”
(3) Any conclusions would have little to do with the original claim
(4) It could only provide solid foundation for vacuous remarks by scribomanic usurpers of other people blogs
The name “serialmoth” apparently has never appeared in the blogosphere before—so that conceiving this unique name is itself a considerable achievement—and yet your two posts substantially exceed in the scope and vigor of their criticism any MathSciNet review (known to me). Given that there are presently two million reviews extant, your posts have exceeded the mean critical level by ~4.89 standard deviations … thus the level of talent you have shown us, sir or madam serialmoth, is seemingly among the most rarefied ever displayed on any mathematical forum.
During the affair itself, Dick and I discussed and agreed a policy of modding-thru every attack and strictly not replying to any of them. My reason was not to detract one jot from the intellectual conversation that was going on. Even if our saying some things in defense would have caused ten others to jump in on our side, that was something we did not want. Thanks to those who did anyway, including John then and now.
This past week we also discussed whether to have a separate entry like this one, or work in a reference to Dr. Deolalikar and the anniversary as part of another post. For instance, we’re doing a post on aspects of David Ferrucci’s plenary talk on IBM’s “Watson” at AAAI 2011 that struck me as having general problem-solving import for theory researchers, and could have related that to conceptual flaws in the paper. Or a post on “post-normal science” whereby those with pressing social needs for answers try to guess them before all the results are in—the fact that even in pure math “good” guesses turn out wrong, and long proofs ditto, tell you where our words of caution will come from. However, one reason we chose a separate entry was to allow serialmoth’s kind of conversation to happen now. (Another was not having time to finish either of the above in time.:-)
Regarding his/her particular comments here, I believe we’ve attended to them already in this post, except for the “quite abysmal” crack on industry which (answering “Curious” below) we certainly don’t endorse—instead see the opinion I gave to Lee Gomes of Forbes in the “UPDATE” here. We did independently do John Sidles’ check on “serialmoth” being a unique moniker.
I can defend John in ironic fashion: Dick and I are both quantum-computing skeptics. One thing we’re experiencing, however, is that it’s difficult to do creative work out of a skeptical position—I think this point was made on Scott Aaronson’s blog or some physics blog but cannot find it. On the other hand, John’s QSE and STEM group does a lot of creative work, and it’s always interesting to see the positions that go with it. Meanwhile we do believe that some creative publishable work can come out of Deolalikar’s draft, specifically (by me) a paper on low-level descriptive complexity of his conditional probability and projection notions (but giving classes lower than P), and a “half paper” or laundry-list on attempts to create new hardness predicates from the phase-transition notions. So Dr. Moth, can you tell us the creative work or constructive intent that goes with what you are saying?
The Lipton-Regan practice of non-counterattack seems (to me) wholly admirable; without doubt this practice contributes largely to the genuinely scholarly warmth of Gödel’s Lost Letter and P=NP. My own snarky post (immediately above) departed from this practice; in the words of Lord Voldemart “I do regret it,”and I hereby apologize for that post to serialMoth, and to Ken and Dick, and to everyone.
Ken makes a good point too that “it’s difficult to do creative work out of a skeptical position,” … and this is the case, whether the topic is quantum computing, P vs NP decidability, or (if you think about it) any other scholarly topic.
In practice, however, folks who might be called quantum progressives substantially outnumber quantum skeptics. Quantum progressivism recognizes that the decades since the 1940s have witnessed exponential improvements occurring simultaneously in computational hardware, computational algorithms, and sensing technologies. By rough-but-reasonable metrics, computing capability has a 24-month doubling cadence, algorithm efficiency an 18-month cadence, and sensor channel capacities a 12-month cadence.
Quantum progressivism amounts to the expectation that this triple cadence can be sustained during many coming decades, coupled with an appreciation that each individual cadence substantially augments the value of the other two. This progressive point-of-view is best viewed not as a skeptical subset of the 20th century’s now-traditional LANL/QIST roadmap, but rather is an embracing superset. Although we don’t presently have quantum computers (and perhaps it is unclear whether we will ever have them) no-one is skeptical regarding the evident fact that key ideas from quantum computing research are already playing vital roles in sustaining the 21st century’s triple cadence.
Once you have a claim to a solution to an important problem like this, isn’t the best action to post it on the arxiv until submitting it to a journal?
Would anyone be interested in a solution to the Hamiltonian Problem that only requires a polynomial number of steps but requires multiplication of exponentially large numbers and requires an exponential amount of precision.
I believe it’s well-known that P=NP if you assume you can use exponential precision (and using exponential precision is a quite common error in purported proofs of a problem being in P)
Hasn’t Deolalikar already proved that P=NP? His “proof” required no more resources than its verification. But more seriously: Dick wrote “he will not let the public see his proof, nor will he post it”. Has such a behavior anything to do with the scientific ethic at all?! No withdraw, no publicity.
I agree with Anonymous (August 12, 2011 8:42 am): “we should consider his refusal to circulate the supposedly fixed manuscript as a de facto withdrawal of his claim”. I am not sure if such “anniversaries of unethical scientific behavior” are worth to be celebrated, as now happened …
Less seriously again, perhaps Deolalikar has given us a zero-knowledge proof that P!=NP.
Please let me expression my appreciation of this Gödel’s Lost Letter column as the single most sensible essay (that I have read) on the Deolalikar episode. Perhaps when the dust settles, the column might be expanded into an academic article, to join two much-cited articles that (IMHO) have provided a similarly sensible perspective upon similar mathematical themes: De Milo, Lipton, and Perlis’ Social processes and proofs of theorems and programs (1979) and Thurston’s On proof and progress in mathematics (1994).
Folks, we know the proof is junk–Scott Aaronson says so. Let’s not waste anymore time on trash, okay?
“That level of research in industry, when disconnected from academia, can be quite abysmal “. I hope Dick and Ken don’t endorse this claim.
Such a topic cannot be passed by by a crackpot trisector
In psychology there is a term of Learned helplessness http://en.wikipedia.org/wiki/Learned_helplessness, where if initially there is no way to escape, say, pain animals learn it, and then later, even if there good chances to escape pain, animals do not attempt to find a way to escape pain. I think the proofs of P=NP in the field have such symptoms. I also have such symptoms, and therefore will not attempt to publish anything, and provide arguments here. I neither can make arguments more elementary nor write them in a technically correct form.
Claim 1. Givens rotation:





Claim 2. Repeating claim 1 one can show that . From which if
. From which if  , where
, where  is global minimum of polynomial
is global minimum of polynomial  , i.e. if polynomial can be written on the first form than all non-negative polynomials (in terms of changing constant) have representation as a sum of squares.
, i.e. if polynomial can be written on the first form than all non-negative polynomials (in terms of changing constant) have representation as a sum of squares.
Claim 3. .
.
Proof is in http://mkatkov.wordpress.com/2011/05/14/max-cut-and-sum-of-squares/. Moreover, span the full vector space, i.e. any quadratic matrix can be represented as a linear combination of
span the full vector space, i.e. any quadratic matrix can be represented as a linear combination of 
Claim 4. by claims 2 and 3, and therefore the global minimum of p can be found by semi-definite program by Parillo thesis (2000) and NZ Shor (1987).
by claims 2 and 3, and therefore the global minimum of p can be found by semi-definite program by Parillo thesis (2000) and NZ Shor (1987).
Claim 5. Partition problem (divide sequence of integers into 2 parts that sum of parts are equal) can be encoded as whether the minimum of
into 2 parts that sum of parts are equal) can be encoded as whether the minimum of  is zero or not (see Monique Laurent http://homepages.cwi.nl/~monique/files/moment-ima-update-new.pdf, and Wiki for details).
is zero or not (see Monique Laurent http://homepages.cwi.nl/~monique/files/moment-ima-update-new.pdf, and Wiki for details).
Claim 6. The minimum is polynomial in
is polynomial in  , and therefore semi-definite program distinguish zero from non zero in polynomial time.
, and therefore semi-definite program distinguish zero from non zero in polynomial time.
Notes. everything is over real numbers, all vectors are column vectors, is ordinary vector transpose, all matrices are real symmetric matrices. If you can write it technically correct, I have no claims of priority.
is ordinary vector transpose, all matrices are real symmetric matrices. If you can write it technically correct, I have no claims of priority.
Sincerely yours,
Crackpot trisector.
Notation: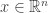 – column vector,
– column vector, 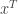 – its transpose, and
– its transpose, and 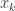 – its component,
– its component,  – gradient of
– gradient of  .
.
Proposition 1. For all square symmetric matrices , and
, and  when non-negative.
when non-negative.
Proof.
For small matrix in the expression above is positive definite by diagonal domination. Cholesky decomposition lead to the following expression
matrix in the expression above is positive definite by diagonal domination. Cholesky decomposition lead to the following expression  . Matrices
. Matrices 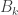 span the full space of symmetric matrices in
span the full space of symmetric matrices in  .
.
Suppose are the projections of
are the projections of  onto
onto 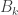 , then for
, then for  ,
, 
We define Givens rotation as




 . Note, Givens rotation preserve polynomial.
. Note, Givens rotation preserve polynomial.
Suppose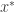 is the global minimum of
is the global minimum of  , then
, then  , from which
, from which  is the smallest value where
is the smallest value where 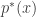 is non-negative. Note,
is non-negative. Note,  is trivial and excluded here, for
is trivial and excluded here, for  the
the  is already a sum of squares.
is already a sum of squares.
Repeating Givens rotations , since polynomial is preserved, we obtain that all non-negative
, since polynomial is preserved, we obtain that all non-negative  are represented as a sums of squares.
are represented as a sums of squares. 
This is sufficient for semi-definite program to find the global minimum up to additive precision in time
in time 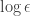 by Parillo thesis (2000) and NZ Shor (1987). Nevertheless, there is simpler argument, that may lead to efficient practical algorithm for large dimensions, but that is for tomorrow, if Dick will not stop me here. In short, the semi-definite program appears to be in single variable, and one can perform line search, in particular, by bisection. Then one need only to check matrix non-negativity, i.e. that the minimal eigenvalue >0. I have stupid way to do that, if someone has a good algorithm for large-scale matrices, I would appreciate it.
by Parillo thesis (2000) and NZ Shor (1987). Nevertheless, there is simpler argument, that may lead to efficient practical algorithm for large dimensions, but that is for tomorrow, if Dick will not stop me here. In short, the semi-definite program appears to be in single variable, and one can perform line search, in particular, by bisection. Then one need only to check matrix non-negativity, i.e. that the minimal eigenvalue >0. I have stupid way to do that, if someone has a good algorithm for large-scale matrices, I would appreciate it.
A quote from Wiki: “In computer science, the partition problem is an NP-complete problem. The problem is to decide whether a given multiset of integers can be partitioned into two “halves” that have the same sum”. In other words, the question is, given a sequence (column vector) of integer values , whether there exist another vector
, whether there exist another vector  , labeling sets, e.g. one set is labeled by +1, and another by -1, that
, labeling sets, e.g. one set is labeled by +1, and another by -1, that  , where
, where  is transpose operation. That is equivalent to asking whether the global minimum of quartic non-negative polynomial
is transpose operation. That is equivalent to asking whether the global minimum of quartic non-negative polynomial  is zero or not. The first term enforces zeros if exists at
is zero or not. The first term enforces zeros if exists at  . To give you geometrical intuition the first term penalizes for going away from labeling set, and it is quadratic nearby labeling set (
. To give you geometrical intuition the first term penalizes for going away from labeling set, and it is quadratic nearby labeling set ( ), the second term is the distance of point prom hyperplane orthogonal to
), the second term is the distance of point prom hyperplane orthogonal to  . Distinguishing between zeros and non-zeros is hard for small values of the minimum, that can only happen nearby labeling set
. Distinguishing between zeros and non-zeros is hard for small values of the minimum, that can only happen nearby labeling set  , moreover the minimum will be approximately along
, moreover the minimum will be approximately along  from the nearby labeling set, e.g. we can estimate the minimum looking at
from the nearby labeling set, e.g. we can estimate the minimum looking at ![y= \alpha a: 4 a^T a \alpha^2 + (a^T ([\pm 1]^n+ a \alpha) )^2=](https://s0.wp.com/latex.php?latex=y%3D+%5Calpha+a%3A+4+a%5ET+a+%5Calpha%5E2+%2B+%28a%5ET+%28%5B%5Cpm+1%5D%5En%2B+a+%5Calpha%29+%29%5E2%3D&bg=ffffff&fg=333333&s=0&c=20201002) (assuming worst case scenario that the best
(assuming worst case scenario that the best  )
) 

 , from which minimum is approximately
, from which minimum is approximately  , which for large
, which for large 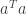 behaves as
behaves as  plus higher order corrections.
plus higher order corrections.
Algorithm.
Input: column vector
Output: TRUE/FALSE (whether there exists perfect partition)
Remark. All operations are assumed in place
1. Remove $a_i=0$, they can be later added to any set, adjust n.
2. Chose small , for example
, for example  . Perform Cholesky decomposition for
. Perform Cholesky decomposition for
Note its block diagonal form, the decomposition is really need only for part.
part.
3. Prepare , where
, where  identity matrix. Write it in vectorized form
identity matrix. Write it in vectorized form
4. Find projections .
.
5. Perform Givens rotations (see above) on , until all, except 1,
, until all, except 1,  .
.
6. Prepare semi-definite program. In order to account for quadratic form, and constant we need extra dimension.
Let![\vec {xx}= \left[ \begin{array}{c} x_1 x_1 \\ x_2 x_2 \\ ... \\ x_n x_n \\ x_1 x_2\\ x_1 x_3 \\ ... \\ x_{n-1} x_n \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cvec+%7Bxx%7D%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x_1+x_1+%5C%5C+x_2+x_2+%5C%5C+...+%5C%5C+x_n+x_n+%5C%5C+x_1+x_2%5C%5C+x_1+x_3+%5C%5C+...+%5C%5C+x_%7Bn-1%7D+x_n+%5Cend%7Barray%7D%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002) and
and ![\vec {xx_1}= \left[ \begin{array}{c} 1\\ x_1 x_1 \\ x_2 x_2 \\ ... \\ x_n x_n \\ x_1 x_2\\ x_1 x_3 \\ ... \\ x_{n-1} x_n \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cvec+%7Bxx_1%7D%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+1%5C%5C+x_1+x_1+%5C%5C+x_2+x_2+%5C%5C+...+%5C%5C+x_n+x_n+%5C%5C+x_1+x_2%5C%5C+x_1+x_3+%5C%5C+...+%5C%5C+x_%7Bn-1%7D+x_n+%5Cend%7Barray%7D%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002) ,
, ![\vec {Q_t}= \left[ \begin{array}{c} -t \\ \vec Q \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cvec+%7BQ_t%7D%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+-t+%5C%5C+%5Cvec+Q+%5Cend%7Barray%7D%5Cright%5D+&bg=ffffff&fg=333333&s=0&c=20201002) ,
, ![L_1= \left[ \begin{array}{c} 0 ... 0 \\ L \end{array}\right]](https://s0.wp.com/latex.php?latex=L_1%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+...+0+%5C%5C+L+%5Cend%7Barray%7D%5Cright%5D&bg=ffffff&fg=333333&s=0&c=20201002)
Then quartic polynomial of interest =
=
7. Fix , define
, define  .
.
8. Initial test. If is non-negative, return FALSE.
is non-negative, return FALSE.
9. Bisection. Set .
. is non-negative then if_2
is non-negative then if_2  return FALSE, else_2 set
return FALSE, else_2 set  endif_2.
endif_2.
If_1
Else_1 if_3 return TRUE else_3 set
return TRUE else_3 set  endif_1.
endif_1.
END
simple test for nonegativity: perform eigenvalue decomposition, test if minimal eigenvalue greater than 0. That require a lot of memory.
Complicated test: use power iterations to find largest eigenvalue . If
. If  is positive, compute largest eigenvalue for (M(t)- \lambda I), also by power iterations, possibly followed by Rayleigh quotient iterations with CG solver. That need only what is already stored in memory + two vectors, that, although slow can handle
is positive, compute largest eigenvalue for (M(t)- \lambda I), also by power iterations, possibly followed by Rayleigh quotient iterations with CG solver. That need only what is already stored in memory + two vectors, that, although slow can handle  on desktop computer.
on desktop computer.
You almost convinced me that collaborative mathematics is not possible, at least in tough problems with prejudice. Assume my posts as a weird way to run polymath project. I’m trying to make it as technical as possible, that people with different expertise can confirm part of the statements, and to point out what need more work, if no one wants to help. (I see it as “1. correct/wrong/why”). Also, If Dick really believe that P=NP, and see a grain of rationality in the arguments below, you can run real polymath project (at least all problems were run by well known mathematicians, I fear Terry Tao, to do that, and write a lot of stupid stuff, as the algorithm above, where M(t) is always positive definite).
Summary: .
.
1. The NP-complete partition problem can be reduced to asking question about global minimum of polynomial
2. Given all sets of inputs , there is a polynomial gap in the global minima of
, there is a polynomial gap in the global minima of  between partitioning subset with perfect partition (
between partitioning subset with perfect partition ( ), and non-partitioning subset (
), and non-partitioning subset ( , where
, where  is polynomial. see arguments above.
is polynomial. see arguments above.
3. Semi-definite program, behind sum-of-squares program find lower bound of non-negative polynomials with additive precision in time
in time  .
.
4. The lower bound is tight, e.g. semi-definite program converges to the global minimum, when , where
, where 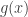 are some polynomials, e.g.
are some polynomials, e.g.  is sum of squares.
is sum of squares.
5. For the global minimum at position , from which
, from which 
6.
For small matrix
matrix  in the expression above is positive definite by diagonal domination. Cholesky decomposition lead to the following expression
in the expression above is positive definite by diagonal domination. Cholesky decomposition lead to the following expression  . Matrices
. Matrices 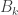 span the full space of symmetric matrices in
span the full space of symmetric matrices in  .
.
7. , by construction, and is zero at
, by construction, and is zero at 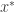 .
.
8.
 (see vector notation above), from which it follows that
(see vector notation above), from which it follows that  is a matrix with singular vector
is a matrix with singular vector 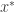 .
.
9. Givens rotation preserve polynomial.
preserve polynomial.
11. Eigenvalue decomposition of real symmetric positive definite matrix , where
, where  is orthonormal,
is orthonormal,  is diagonal with real positive entries
is diagonal with real positive entries  .
.
12. (
( are column vectors of
are column vectors of  ), by Givens rotations one of the axis can be can aligned with
), by Givens rotations one of the axis can be can aligned with  , and others being orthogonal to it. Then
, and others being orthogonal to it. Then  with
with  , and
, and 
13. Substituting 12 into 8 show that , from which
, from which  and
and  are collinear.
are collinear.
14.



15. by 4 semi-definite program approaches global minimum of exponentially fast, and
exponentially fast, and
16. by 3 in time distinguish between partitioning sets and non-partitioning.
distinguish between partitioning sets and non-partitioning.
sorry, in 14 in 3rd expression there is no sum, and should read
should read 
There is no sum in 14 4th expression either
Is it conceptual not to spend half of hour on linear algebra? Give it a chance.
To ensure collinearity of and
and  one need to look at the Hessian of
one need to look at the Hessian of  . By the givens rotations,
. By the givens rotations,  , Hessian of which is
, Hessian of which is  . Comparing two Hessians it is necessarily that
. Comparing two Hessians it is necessarily that  .
.
To ensure one need to look at Hessians, and compare the term without x
one need to look at Hessians, and compare the term without x
I suspect that Deolalikar’s argument (and any other argument along similar lines) may be unable to establish it’s thesis for terminological, rather than logical, reasons.
My reasoning:
It follows from Theorem VII of Goedel’s 1931 paper that any recursive relation of the form f(x)=y constructively defines an arithmetical relation [F(x, y)] such that:
(i) f(m)=n if, and only if, [F(m, n)] is true under the standard interpretation S of the first-order arithmetic PA.
Since f(x)=y is recursive, there is a deterministic Turing machine TMf such that, for any given natural numbers m and n as input, TMf will halt and return the value 0 if f(m)=n, and 1 if f(m) =/=n.
From (i), we may also conclude that there is a non-deterministic Turing machine UTMF such that, for any given natural numbers m and n as input, UTMF will halt and return the value 0 if F(m, n) interprets as true under S, and 1 if F(m, n) interprets as false under S.
Now it immediately follows from the peculiar nature of the definition of [F(x, y)]—in terms of Goedel’s Beta-function—that there is no deterministic Turing machine TMF such that, for any given natural numbers m and n as input, TMF will halt and return the value 0 if F(m, n) interprets as true under S, and 1 if F(m, n) interprets as false under S.
However, we cannot conclude from this that P=/=NP since, if Lf is the language accepted by TMf and LF that accepted by UTMF, it follows from (i) that x is in Lf if, and only if, x is in LF.
In other words, the terminology of set theory (which is used to define the classes P and NP in Cook’s definitions) does not reflect the differences in computational properties between the number-theoretic relations f(x)=y and F(x, y) that is highlighted by Goedel’s Theorem VII.
There’s something about this post I don’t quite like. I think it is that this post doesn’t seem to be showing much respect for the review process (i.e. the request that the paper be made public, and implied annoyance that the authors don’t have a copy too look at). Also the implication that Deolalikar may not understand the critiscims seems particularly out of line (at least, unncessary).
I feel it would be better to say nothing at all, and not “gossip” about something that is ultimately factual. Either it is, or it isn’t, and until it’s shown other way, why talk? Why try and derive some point? For blogging fodder? Seems useless.
As an aside, I also don’t think too much concern should be given to priority of solving. We’re all a scientific community there; let’s be happy that “we” solve it, not that “you” do. How much more progress could be made if we changed to that?
Nice points. Ideally we agree with your last one, but life is not ideal. On your middle point, our post’s intro and my comments above say we “dragged our heels” on posting about it, while some others felt we should. On your first point, no annoyance and “no comment”, while on the “implication”, we were concerned at the time that the community was talking past Dr. Deolalikar—and put much effort into bridging the concepts in our summaries, one of which was expressly adressed to him.
“Respect for the review process”? I’m not even sure what that means. We don’t owe the review process respect: peer review is a handy tool for catching mistakes, evaluating novelty, and filtering by quality, but ultimately it’s just a practical tool, not a sacred ritual worthy of great reverence. And it’s certainly not an excuse not to circulate a manuscript.
In fact, as far as respect goes, the situation here is exactly the opposite. Deolalikar is not showing any respect for the research community. The general principle is that you can’t claim credit for proving a theorem if you’re not willing to explain the proof, and it’s obvious that the community needs principles like this. By publicly announcing announcing that he has fixed his proof but won’t show it to anyone except a (possibly imaginary) journal editor and referee, Deolalikar is violating this principle and asking for credit he doesn’t deserve.
As for whether it would be better to say nothing at all, if Deolalikar would do the same I’m sure everyone would join him. But as long as he persists in publicly claiming a proof, it’s reasonable for the community to publicly discuss and evaluate his claim.
The culture of scientific publication has changed a lot, and imho for the better. At this point, I would argue that authors who don’t post their work on a publicly available archive (like arxiv.org) are failing to respect the review process.
Anonymous, your various posts on this topic raise centuries-old questions relating to trust: How much should scholars trust their colleagues? Trust peer review? Trust editors who administer peer review? Trust the STEM bloggers who (nowadays) increasingly channel scholarly discourse?
These issues arise in other disciplines too, and there is a celebrated legal maxim that is à propos to the Deolalikar episode:
The substitution “justice”→“peer review” is natural, as is the (far stronger) substitution “justice”→“mutual scholarly respect and trust.”
If there has been any net diminution of mutual scholarly respect and trust associated to the Deolalikar episode, it seems (to me) that Deolalikar himself is wholly blameless, as are the journal editors, and as are the various STEM weblog hosts. Because this respect and trust are held wholly by ourselves. And with regard to the mutual web formed of this respect and trust — the web upon which the integrity and viability of the STEM enterprise has always wholly depended — this web quivers unceasingly, yet it remains intact and strong. Good! 🙂
I am aware of this. However, do you know of any solutions to the Hamiltonian Problem of this type.
Javaid,
Proofs were never meant to convince people of the truth of a proposition. They were meant to confirm propositions that people already believe to be true. They were also meant to be used as ammunition in arguments with people who believe propositions to be false.
As an experiment, announce that you have found a counterexample to Golbach’s conjecture by presenting a large number 2n. Claim that there are no two primes that add up to 2n. (This experiment is unethical if your claim is false, so I wouldn’t recommend it in real life. Just think of it as a thought experiment.) See how long it takes for someone to prove you wrong by finding two primes that add up to 2n or if your claim is correct verify your claim. I bet it will take a long time either way, because most people believe Goldbach’s conjecture is true and won’t even bother to check out your claim.
Why are there people who have proofs that God exists and other people who have proofs that God doesn’t exist? Why do different religions with contradictory claims exist in which each of the followers believe they have proof that their religion is the truth? Why do different schools of economics exist (Keynesian, Monetarist, Austrian) in which each side believes the other is completely wrong?
And why should mathematics or computer science be any different?
I came to this conclusion after finishing my paper proving that P != NP here: http://arxiv.org/abs/cs.CC/0607093
To me, my proof is correct, but not everyone agrees and most people don’t give a darn either way. I don’t think it’s because of arrogance. It’s just the way the world works. People think in different ways. And most people don’t really care one way or another and will go with whatever everyone else says.
My above comment was a response to a comment made by Javaid Aslam, but his comment has dissapeared.
I also would like to know what really happened.
I had used the html generated by MSW, with the hope to give better format but it showed some auto-generated code by MSW.
html is also supposed to be acceptable in these “text” boxes.
I could post it again (in plain text) if approved by Dick/Ken.
A small remark about your Goldbach suggestion: I could claim that there were no two primes that added up to and be confident that nobody would refute the claim, simply because we don’t know any primes with
and be confident that nobody would refute the claim, simply because we don’t know any primes with 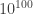 digits. (Obviously we couldn’t write such a prime out in decimal notation but it’s conceivable — though incredibly unlikely — that someone might be able to describe a prime of that magnitude in some other way.) But if I made such a claim, then the onus would surely be on me to back it up. It’s clear that if the claim was correct I’d have to have a theoretical reason for it, since checking all cases is out of the question. So in the end there wouldn’t be much difference between this and saying, “I’ve solved such and such a conjecture and am not going to show you the proof.”
digits. (Obviously we couldn’t write such a prime out in decimal notation but it’s conceivable — though incredibly unlikely — that someone might be able to describe a prime of that magnitude in some other way.) But if I made such a claim, then the onus would surely be on me to back it up. It’s clear that if the claim was correct I’d have to have a theoretical reason for it, since checking all cases is out of the question. So in the end there wouldn’t be much difference between this and saying, “I’ve solved such and such a conjecture and am not going to show you the proof.”
I completely disagree with your claim that mathematical proofs are on a par with proofs of the existence or non-existence of God. That is because correctly written mathematical proofs have the quality of “expandability”. If I don’t understand the proof of Lemma 2.3, I can get the author to give more details. If I still don’t understand, we can find the step that I don’t follow and expand that, and so on. Eventually we will reach axioms. (Note that I am not claiming that it is practical to write out entire proofs in terms of set theory. All that is necessary is that I should be able to zero in on bits that bother me.) Proofs of the existence of God do not have this quality.
gowers,
As for Goldbach’s conjecture, you are of course right, but I was only thinking about numbers that could be written down in decimal form in real time.
And didn’t Godel claim that he could prove that God exists? http://en.wikipedia.org/wiki/G%C3%B6del's_ontological_proof
Another example I forgot to mention of experts that believe they have irrefutable arguments on both sides of the debate is the Intelligent Design/Macro-Evolutionist debate. (There are biologists and theologians on both sides of the debate.)
As for the quality of expandability that you claim mathematics has which makes it different than proofs of God, this might be true in theory but is it true in practice? When a paper goes to a referee at a math or CS journal and the referee doesn’t understand the central proof of the paper, will he contact the author for more details about the proof or will he reject the paper? I think it is probable that if the referee doesn’t believe the theorem or doesn’t believe the author has a correct proof, he won’t waste his time and will reject the paper.
One of the differences I noticed as a student between proofs in theology/ethics and proofs in mathematics is disagreement about the axioms. Usually the logic is fine, it’s the axioms that are up for debate. Whereas in mathematics, with a few exceptions, we pretty much all agree ZF(C) is a good system for doing math (even though people with foundational concerns like to move proofs to PA, I think there is tacit agreement that ZF(C) is fine for doing real math).
Another difference is just how deep the theorem-proving goes with the axioms. From Peano Arithmetic, we get the Prime Number Theorem, requiring thousands of intermediate results. Whereas if you read a theological or ethics proof, it’s usually a small number of logical steps–say, a dozen or two. And often you get absurd results if you take the axioms to their logical conclusion–a common technique in criticisms of an argument.
Even in the Godel proof that you cite, if you really investigate the consequences/models of those axioms, you can see how the argument unravels (in particular what possible positive properties are admissible).
I have a hard time understanding the statement “Proofs were never meant to convince people of the truth of a proposition. They were meant to confirm propositions that people already believe to be true.” An awful lot of math–really, a lot–is quite stunning, and it’s only through proofs that we convince ourselves that these stunning facts are, in fact, facts.
Who would have guessed there are infinitely many prime numbers?
Who would have guessed that the angle bisectors of a triangle all meet at a single point?
Who would have guessed Cauchy’s integral theorem?
Who would have guessed Godel’s incompleteness theorem?
…
I would even go so far as to say the distinguishing feature of mathematics (in which I include some of the mathematical subfields of philosophy) is that it deals in *proofs*, not merely arguments or observations.
Luke G
If the comment by Javaid wouldn’t have been mysteriously erased, what I said would have made more sense in the context of his comment.
Think of it this way: Suppose that some mathematician, Stubbornecles, claimed to have a deductive proof that there are only finitely many primes – and Stubbornecles were living back before Euclid’s proof was known.
Then Euclid comes along with his proof that there are infinitely many primes. The odds are that Stubbornecles would go to his grave not accepting Euclid’s proof as valid. That’s what I meant when I said, “Proofs were never meant to convince people of the truth of a proposition. They were meant to confirm propositions that people already believe to be true.”
Craig, a visit to Freek Wiedijk’s web page “Formalizing 100 Theorems” might strengthen your confidence in the reliability of peer review. Of Wiedijk’s starting list of top-100 mathematical theorems, 86 have been formalized to date, and (so far) none have been found to be false. Various flaws and imprecisions are found, to be sure, but in every case the flaws have been readily fixed. This is evidence that (in the long run) the assessments of mathematical peer review are reasonably accurate.
This doesn’t mean it’s easy to find errors in one’s own work (or in other folks’ work either). In practice, peer review occurs near the end of the error-finding process; earlier stages include working with co-authors (which is by far the single best check-and-balance), talking with colleagues, giving lectures, explaining ideas to students, carrying through numerical and even physical experiments, etc. Moreover, journal editors possess a pretty accurate sense of whether a manuscript has been been through this improving process.
For outsiders it can happen that none of these early-stage error-checking mechanisms are accessible, in which case it is perfectly acceptable — and even a very good idea — to straightforwardly hire a reviewer.
My experience has been that practicing mathematicians, scientists, engineers, and physicians change their minds readily in the face of factual evidence … and all of these professions embrace computer analysis to help them improve their judgement.
It is far less common for eminent politicians, theologians, and philosophers to change their minds (although Wittgenstein famously was one philosopher who did) … and none of these professions embrace computer analysis. One wonders why that is? IMHO this question has simple answers and good answers, but no simple good answers.
Dear Craig,
Your supposed proof that P!=NP exhibits several of Scott Aaronson’s ten signs that a proof that P!=NP is wrong. It is therefore a bit foolish of me to engage with it, but since it was better written than many such attempts, let me do so — I feel that there’s a tiny chance that you might actually accept that it is wrong, though your sentence beginning, “To me, my proof is correct, but not everyone agrees …” is not promising.
I admit to not understanding the early lemmas. You appear to define a gamma-comparison between two numbers to be an algorithm that decides whether or not they are equal. And then you appear to say that any algorithm that decides whether or not two numbers are equal must be a gamma-comparison. I don’t see why that lemma isn’t just true by definition. But at least if it is true by definition it is true.
The real problem comes with Lemma 4. There you assert that any algorithm that fails to use sorted lists to solve Subset Sum must take time proportional to 2^n. Let me criticize that in two different ways.
First way: the theory of NP-completeness tells us that we can transform the problem into any other NP-complete problem with at worst a polynomial change in the running time. Suppose, then, that we transform the problem into the problem of finding a clique of size m in a graph with n vertices. Then we have left the original problem behind to the point where we cannot be said to be “using ordered lists”. Where is your proof that this approach via finding cliques must take time 2^n? (To prove that, you need a lower bound for the clique problem, which you do not provide, not surprisingly because it is a formidably difficult open problem.)
Second way: you appear to be under the impression that to prove that two numbers are not equal it is necessary to prove that one is larger than the other (perhaps after some kind of transformation). But that is not true. Another way of doing it is to show that one is even and one is odd. Of course, that doesn’t always work, but it works a lot of the time, and could in principle be used to reduce hugely the number of pairs one has to check. Indeed, given a bunch of numbers and a target, I can easily rule out at least half the subsets on parity grounds. (If all numbers are even then divide them all by 2.) Might it be possible to continue with this line of thinking and obtain a solution to subset sum that works faster than 2^n and makes no use of sorted lists? I don’t know, but what I do know is that your argument doesn’t even address the possibility.
The rejection of, or lack of interest in, your argument by the mathematical community is thus not some interesting phenomenon in the sociology of mathematics. It’s simpler than that: the argument is wrong. (And I haven’t even started on the fact that we now know that any proof that P does not equal NP must get past certain “barriers” and that any serious attempt at a proof must explain how it manages to do so.)
Dear gowers,
I really didn’t want to get into an argument over whether my proof that P!=NP is valid on this blog. But you started the argument, so I’m going to finish it.
First of all, your mentioning of Scott Aaronson’s “ten signs that a proof that P!=NP is wrong” and “It is therefore a bit foolish of me to engage with it” indicates to me that you were prejudiced before even reading my paper that my proof is wrong. So it is not surprising to me that you found what you perceive to be mistakes.
As far as your critique of my paper goes, you ask, “Where is your proof that this approach via finding cliques must take time 2^n?” That’s called “moving the goalposts”. I gave a proof of Lemma 4 that under certain conditions, any algorithm solving subset-sum must take 2^n time. Then instead of finding a flaw in the proof, you moved the goalposts demanding that my proof of Lemma 4 directly address your question about cliques.
You also suggested that maybe it is possible to make use of the parity of the subset-sums to eliminate possible matches with the target integer and criticized my proof for not addressing this possibility directly. Again, this is a moving the goalposts fallacy. I gave a proof of Lemma 4 that under certain conditions, any algorithm solving subset-sum must take 2^n time. Then instead of finding a flaw in the proof, you moved the goalposts demanding that my proof of Lemma 4 directly address your question about parity.
OK here goes. First, I certainly expected your proof to be wrong. That is prejudice of a sort, but not blind prejudice, since I still recognised the need to understand WHY it was wrong.
Secondly, I didn’t move the goalposts: I kicked the ball right between them. You claimed that every proof that doesn’t use sorted lists must take a certain length of time. But your “proof” of that claim makes a number of unsupported assertions. My arguments above are designed to demonstrate that support is needed. Instead of repeating them in a louder voice (so to speak) let me try to give a further argument.
Take the following sentence: “And since Q does not make use of sorted lists of subset-sums, like the Meet-in-the-Middle algorithm does, its gamma-comparisons between these subset sums and the target integer will not rule out possible matches between any other subset-sums and the target integer.”
The point of my parity observation is that that sentence is missing something important. Suppose I look at a particular subset sum and calculate that it is not equal to the target integer. That piece of information alone doesn’t help with any other subset sums. But I do not have to restrict myself to that piece of information alone. Suppose, for example, that as well as observing that my particular subset sum doesn’t equal the target integer, I also look at whether its parity is the same as that of the target integer or different from it. Then with the help of that extra information I can rule out a number of subset sums without working out what they are. For instance, if a certain subset sum is even and so is the target integer, then I do not need to look at any subsets that differ from the subset I’ve just looked at by one single odd number.
But maybe you’ll be more convinced if I just demonstrate that your Lemma 4 is plain false. Here’s an algorithm that makes no use of sorted lists and takes time 2^{n-1}.
First preliminary step: if all numbers are even then divide them all by 2. Continue until there is at least one odd number involved in the problem.
Second preliminary step: split the numbers (apart from the target integer) into odd and even ones.
Main algorithm: if the target integer is even, then compare it with all subset sums that use an even number of odd numbers. (There will be 2^{n-1} of these.) If the target integer is odd, then compare it with all subset sums that use an odd number of odd numbers. (Again, there will be 2^{n-1} of these.)
This algorithm takes time 2^{n-1} (plus a little bit for the preliminary steps).
Let me illustrate it with an example. Suppose my target integer is 100 and my numbers are 16, 18, 20, 30, 44. I begin by dividing everything by 2 (for convenience — it leads to an equivalent problem of course.) So my new target integer is 50 and my numbers are 8, 9, 10, 15, 22.
Now I split these into the odd ones, 9 and 15, and the even ones, 8, 10 and 22. Because my target integer is even, I know that I must either use both 9 and 15 or neither. So I don’t have to check the subsets that involve exactly one of 9 and 15. This results in my having to check only 16 subsets rather than 32.
That’s already enough to show that your lemma is false. Of course, the saving if you use the little trick above is small, so let me emphasize that I have just used one rather simple-minded idea to achieve it. With more effort, one can almost certainly do a lot more.
I hope you’ll drop this suggestion of yours that my criticisms are based on prejudice. Finding a counterexample to your main lemma may have been motivated by a kind of prejudice (I would prefer to call it very strong and well-founded prior expectation), but the counterexample itself is an objective mathematical fact.
Dear Thimoty,
Would it by possible for you to spend a short moment, and peak obvious contradictions, in my post from August 17, 2011 5:46 am.
It is not fair, when there is a contradiction, people point it out, if there is no, they are just quiet.
There is missing step 10. which should read

 . Comparing the condition for global minimum
. Comparing the condition for global minimum  with 5. the only possible value for
with 5. the only possible value for  , which bring us to sums of squares representation for
, which bring us to sums of squares representation for  .
.
Using Givens rotations bring
Dear gowers,
I’ll admit, that is very clever, much more clever than other objections that have been raised toward my proof. But no matter how clever a person is, if he is prejudiced to a certain viewpoint, he’ll find ways to justify his viewpoint, right or wrong.
The algorithm that you presented doesn’t contradict Lemma 4, because Lemma 4 doesn’t even pertain to this algorithm. Why? Because it makes use of sorted lists of subset-sums and Lemma 4 doesn’t pertain to algorithms which make use of sorted lists of subset-sums.
How does your algorithm make use of sorted lists of subset-sums? Suppose x_1 x_2…x_m and y_1 y_2…y_m are binary representations of integers x and y, where x_m and y_m are the last bits that tell whether an integer is odd or even. Now consider any ordering relation, <, such that x < y if x_m=0 and y_m=1. Then for your example of a set, {8, 9, 10, 15, 22}, we have 8<9, 8<15, 10<9, 10<15, 22<9, 22<15, which are sorted lists of subset-sums with respect to this new ordering relation that we have defined. And your algorithm makes use of these sorted lists of subset-sums by separating the evens from the odds. So Lemma 4 doesn’t pertain to your algorithm, which is why your algorithm doesn’t disprove Lemma 4.
Even though gowers’ critique is much more clever than other critiques, it is pretty much along the same lines of all of the critiques that I have gotten for my paper, including referee reports to journals I’ve sent this paper to – the reader decides that the proof is wrong a priori; then he finds reasons to justify his viewpoint. It’s never the other way around.
Nevertheless, I’m completely open-minded to the possibility that my paper is wrong. And I don’t say this without evidence to back me up. I withdrew the first paper that I wrote on arxiv.org titled P!=NP precisely because someone on usenet comp.theory found a counterexample, just as gowers claimed he had found. It was quite humbling. Anyone can check this out.
Also, when I said gowers was prejudiced, that was not intended as an insult. If I were in gowers position, I would have most likely done the same thing, except I don’t think I would have come up with as clever an argument as gowers.
May I make a request to gowers or anyone who is interested in my paper? I would rather talk about it through email, not on this blog. You can email me at the email address on my paper if you’d like to talk.
In my algorithm I made absolutely no mention of the sorted list you subsequently defined, so I don’t see any sense in which my algorithm “made use” of that list. Indeed, with such a generous definition of “made use of” pretty well anything could be said to be making use of a sorted list.
To see why this is a problem, consider the following statement that forms part of your Lemma 5: creating a sorted list of size M must take at least M units of time. Early on in the lemma you talk about “making use of” sorted lists, but by this stage you are talking about “creating” sorted lists. In my algorithm above, I did not have to create a sorted list, even if you consider me to have made use of it. (If you don’t believe me, I’ll outline how I might actually program a computer to perform my algorithm: it doesn’t put the subset sums into any kind of list even if you could if you like regard it as “making use of a list”.) So there’s a missing step: if you make use of a sorted list (by your definition) then why do you have to create that list?
Just to repeat, in my algorithm I don’t have to create the list. Since you consider me to have made use of the list, you are FORCED to regard making use of a list and creating a list as different concepts. Hence the need to fill in the missing step in Lemma 5.
gowers,
Can we please continue this conversation via email? I’d like to answer you, but the blog host, Richard Lipton, emailed me, “Good idea to talk one on one”.
I am trying to re-post my previous comment that had disappeared perhpas because of some garbage characters generated by the MSW html generator.
———————————>> ———————- >> ——————————————————-
On Science, Religion and Arrogance
—————————————————–
I would like to clarify the [misunderstood] basis of my claim of the arrogance in the TCS community. Sometimes I see a pattern of arrogance which makes a researcher’s belief more a religion than Science.
Let me begin with my conjecture:
Those who believe that NP!=P indirectly claim that they have a “complete” knowledge of the behavior of combinatorics, or at least adequate enough knowledge of the combinatorics involved in any NP-Complete/Hard problems to the extent that they cannot accept the possibility of a polynomial time algorithm.
Some evidence supporting this conjecture is:
Most of the structures in combinatorics, such as Permutation Group and Graph Theoretical structures that are well studied, are highly restricted in their behavior by the axioms that define them. Once we start relaxing those restrictions, we could be entering into a very different universe.
Let me pose some example questions from perfect matching and permutation group enumeration problems.
• How much do we know of graph theoretic generators of perfect matchings similar to the permutation group generators? (leaving aside the time complexity of generation/enumeration )
• Are there such graph theoretic generators even for the perfect matchings in complete bipartite graphs or for those in graphs containing only polynomially many perfect matchings, enumerating all the perfect matchings in polynomial time? Would researchers even care to know the generators for perfect matchings in a complete bipartite graph?
• Can we represent any arbitrary subgroup of a symmetric group by a bipartite graph containing precisely those perfect matchings?
Somewhere Scott Aaronson once mentioned that even some Nobel laureates in Physics view the research on quantum computing very similar to that on Perpetual Machines. Yet he views NP=P result being as senseless as imagining pigs to fly, while comfortably embracing quantum computing.
Once an anonymous researcher on GLL had responded to my blog comments saying that he/she was willing to read my paper (on #P=FP) [only] IF I could produce RSA challenge results (integer factorization) using my claimed algorithm. Leaving aside the fact that any algorithm with a time complexity of O(n^18) would need trillions of years on any classical sequential computer, was there any such standard or condition set for Deolalikar’s claimed proof of NP !=P?
Thus my frustration (or the “bitterness”) was due to the resistance of the researchers against the willingness even to read my paper rather than with “buying” the proof. What was the basis for this resistance?
The lead-off post in this week’s newly resurrected (hurrah!) Quantum Pontiff is a link to economist Phillip Maymin’s provocative (and enjoyable) preprint Markets are efficient if and only if P = NP. Maymin’s preprint is interesting on many levels, one of which is that the preprint might have been subtitled “How to flaut Scott Aaronson’s list ‘Ten signs a claimed mathematical breakthrough is wrong’ and still reasonably expect that your proof will be accepted by the mathematical community.”
A key point is that Maymin’s preprint is mathematically orthodox: it embraces conventional nomenclature, asserts well-posed definitions, employs viable proof strategies, and claims theorems that do not contradict known results. As Tim Gowers’ patient explanations on this topic have made clear, every accepted mathematical proof abides by these principles.
Yet Maymin’s preprint does (very enjoyably) flaut at least the following five of Scott’s ten rules: Rule 1: the manuscript isn’t TeX’d, Rule 3: the approach seems to yield something much stronger and maybe even false (namely, that implication the postulates of free-market economics are wrong), Rule 5: the approach conflicts with a known result (namely, the empirical evidence that markets often are efficient), Rule 8: the manuscript wastes lots of space on standard material (the reductions are trivial, the exposition belabored), Rule 10: the techniques just seem too wimpy for the problem at hand (undergraduate-level complexity theory suffices).
It’s not easy to write a short essay about why Maymin’s preprint is receiving attention despite transgressing these rules. The answer presumably has to do (in part) with economist Reinhard Selten’s deliberately provocative maxim:
An expanded version of Selten’s point was made by Scott Aaronson in one of the answers to his (highly recommended) 2011 “Ask me anything” post on Shtetl Optimized. Scott asserts:
These reflections help us appreciate that Maymin’s preprint is transgressive not by virtue of its mathematical conclusions (which are orthodox, natural, and even obvious), but rather because Maymin’s reasoning transgressively illuminates that economics calls itself one discipline, yet functions as two disciplines (or more).
We are led to appreciate as natural questions like, is complexity theory one discipline, or two (or more)? Is quantum information theory one discipline, or two (or more)? What are the boundaries between these disciplinary schisms? How should we allocate resources to them? How can mutual respect be productively sustained? Provocative articles like Maymin’s, and good web-logs like Gödel’s Lost Letter and Shtetl Optimized, challenge us by posing these tough questions.
John Sidles appears to think Maymin’s paper is un-interesting from the perspective of computational complexity and I think it’s un-interesting from a finance perspective, since he appears to claim only that markets are not strongly efficient iff P!=NP and the belief that markets are weakly efficient at best is, I think, widely held. I noted from his website that the paper is to be published in Algorithmic Finance, of which he is the managing editor. The advisory and editorial boards are a stellar list of names from computational complexity (eg David S. Johnson, Dick Lipton) and finance (eg Myron Scholes, Richard Thaler). Could Dick and/or one of the finance people comment on what is interesting about this paper ? From a finance perspective, one of its references (Computational Complexity and Information Asymmetry in Financial Products by Arora, Barak et al) is much more interesting (to me, at least).
I’d like to thank John Sidles for being the medium to bring Arora, Barak et al to my attention and to Dick and Ken for keeping this blog. I never fail to read it and it’s brought me some useful (to me) knowledge that was new to me.
Ha ha ha ..reading this post a bit late .. but almost getting a cruel fun thinking that this dude Craig probably has no idea who this ‘other person’ called gowers is.
and such folks continue to generate answers to P/NP question.
Scott Aaronson definitely deserves a theorem in his name for so accurately describing crackpots. Almost like a primality-testing algorithm or something like that 🙂
I think it’s more likely that gowers doesn’t know who this dude Craig is, or else he wouldn’t be wasting his time. It’s like Jack Nicholson trying to reason with his pals in One Flew Over the Cuckoo’s Nest. And of course, Lipton is the guy who keeps this place sane.
It is possible also for folks to respect Craig’s passion for mathematics, and to admire and appreciate Tim Gowers’ thoughtful and painstaking comments upon Craig’s work, and to be glad that environments like GLL&P=NP exist where these good things happen. As William Thurston has written:
By Thurston’s criteria, pretty much every GLL&P=NP post contributes materially to progress in mathematics … and we can be grateful to GLL for this. This includes thought-provoking exchanges like the one between Craig and Gowers, in which all parties acquitted themselves with grace (IMHO), by showing us (in Thurston’s words) “how compelling and interesting the journey of mathematics can be, at all its stages.”
Thank you John. I am glad that this blog exists too.
As for the anonymous comment, “this dude Craig probably has no idea who this ‘other person’ called gowers is”, as far as I’m concerned, it doesn’t matter whether gowers is a guy who cleans toilets for a living or the mathematician, Tim Gowers, who probably knows 1,000x more math than I know.
I’ll to treat them both the same way here, because the content of an argument is much more important than who is arguing.
For what it is worth: I think that the odds and evens algorithm for subset sum outlined above by Gowers indeed generalize to an algorithm running just as fast as the more famous meet-in-the-middle 2^{n/2}poly(n) time algorithm.
Input: Positive integers a_1,a_2,…,a_n and a target positive integer t.
Question: Is there a subset of the a_i’s that sum to t?
Algorithm sketch: Pick a random prime p of magnitude ~2^{n/2}. Build a table T:[0..n]x[0..p-1].> Z such that T(j,s) is equal to the number of ways to build the sum s modulo p using a subset of the j first a_i’s. Note that we can build the whole table T(0,0)->T(n,p-1) in time 2^{n/2}poly(n).
The idea now is that in T(n,t mod p) not only the correct solutions to the instance are counted, but also an expected fraction of 1/p of the other subset sums. So with a bit of luck with our choice of p, we only need to list the first ~2^{n/2} solutions to the modular subset sum = t mod p counted in T(n,t mod p), and explicitly evaluate them to see if they sum to t over the integers to find a solution to the original problem, or with large probability conclude that there are none.
Listing these modular subset sums counted in T(n,t mod p) can be done efficiently by just following the table backwards.
“Maymin’s preprint is interesting on many levels…”
Indeed! Amongst which is that of laymen like me for, if I am reading between the lines of Maymin’s paper correctly, it seems to be based (albeit implicitly) upon a number-theoretic (rather than set-theoretic) definition of the PvNP problem in terms of functions (rather than ‘languages’) as below (a definition which, again if I am reading it right, appears acceptable to the cognoscenti since one of them must have refereed the paper):
Definition 1: A number-theoretic function F(x1, x2, …, xk) is algorithmically verifiable if, and only if, for any given set of natural numbers (a1, a2, .., ak), there is a Turing machine that computes F(a1, a2, …, ak) and halts on null input.
Definition 2: A number-theoretic function F(x1, x2, …, xk) is algorithmically computable if, and only if, there is a Turing machine that computes F(x1, x2, …, xk) and halts when input any given set of natural numbers (a1, a2, .., ak).
Definition 3: A number-theoretic function is computable if, and only if, it is algorithmically verifiable.
Weak CT: A number-theoretic function is computable if, and only if, it is instantiationally equivalent to an algorithmically computable function.
Definition 4: P=NP if, and only if, weak CT holds.
If the above analysis is correct, then it would explain why some arguments to prove that P=/=NP—such as the one that I have offered earlier—are misdirected.
I reasoned that P=/=NP by constructively defining a function that is computable but not algorithmically computable in the above sense. This, however, serves only to introduce a terminology that ‘falsifies’ classic CT by shifting the goalpost.
Classic CT: A number-theoretic function is computable if, and only if, it is algorithmically computable.
Apropos the wider intent of Maymin’s paper, he seems to make the interesting point that if weak CT holds, then the market is efficient and there is some way to execute any number of separate OCO orders “… in such a way that an overall profit is guaranteed, including taking into account the larger commissions from executing more orders …”, since “… the market allows us to compute in polynomial time the solution to an arbitrary 3-SAT problem”.
In other words, the market is both determinate and predictable (at the very least to Laplace’s deity).
Whilst if weak CT does not hold (i.e. P=/=NP) then the market is not efficient.
In other words, the market may be determinate in some weak sense (of being subject to probabilistic laws), but it is unpredictable (even to Laplace’s deity, who too must open the box to discover whether Schroedinger’s cat is dead).
Since, unlike CT, it is not immediately obvious how a weak CT can either be verified or negated even in principle, the resolution of the PvNP problem may, eventually, turn out to require a theological commitment; perhaps on a par with the belief that the axiom of infinity of set theory cannot introduce an inconsistency.
The YouTube video Phil Maymin at TEDxNSIT, titled “On the Nature of Genius, Trading and Hindsight”, is very lively and fun to watch.
The way I parse Maymin’s lecture (which is probably not the way he conceived it), it might alternatively have been titled “We think we’re Ents working with Gandalf in service of the Enlightenment, but maybe we’re Orcs laboring for Saruman in Orthanc.”
More seriously, Maymin invites us to think seriously about non-technical (and even moral) uses of the word “efficient”, as contrasted with the strictly technical economic meaning that Maymin’s lecture imputes to it. And of course, the same temptations occurs in complexity theory with regard to words like “computation”, “simulation”, and “verification”.
Especially when we explain our mathematics to our colleagues in other disciplines, or to the broader public, or political leaders, we need to mindful of the ever-present temptation to simplistically conflate the moral, practical, and mathematical meanings of technical terms … like Maymin’s most-used technical term “making money.”
If all that humanity seeks to achieve in the 21st century is to make money, with little regard for the vitality and viability of the underlying structures that give human value to money, then by the end of the 21st century (IMHO) we are all too likely to be sharing a planet that is an overheated resource-poor wasteland, inhabited by 10^10 desperate and despairing people, each clutching a certificate that shows they have plenty of money.
I’m confident we can do better than that. 🙂
Reading the comments on this posts makes me sad. All this discussion about the import of prejudice on reading proofs and proofs in general is void, in my opinion.
A proof is a series of logical “arguments” that derives some proposition from a certain set of assumptions. If these stepts are unclear enough for someone to doubt them, they have to be made clearer. A “clearly” correct proof, on the other hand, has to be accepted even by a person who did a priori assume the claim to be false, simply because (s)he can check the individual steps for correctness.
I am aware that this is an idealistic viewpoint as many “proofs” nowadays are not definite but make heavy use of “as we see”, “obviously” and the like. These are phrases that introduce ambiguity and thus room for prejudice to attack.
This is where proof assisstants may come in handy. A proof expressed in a way that such a system verifies (not finds!) the proof _has_ to be correct (assuming the used calculus is consistent). The individual steps, as many as they might be, can be checked by humans if they so desire. The difference to a “human digestible” proof is that it has to be brutally formal in a way most mathematicians never write proofs.
Maybe we do not have to got that far. Writing proofs more formally might save the day. Such proofs are not meant to inspire understanding, but to be easily checked. In order to have some result accepted, we clearly need both: one version to convince, and another that can be easily checked.
Nothing to be sad about. The world is not in black and white but in color. Why should mathematics be any different?
“Reading the comments on this posts makes me sad.”
It should actually be encouraging, for that is the way things are; which—if you reflect upon it—possibly provides the necessary incentive for striving to make them as we think—no matter how wrongly at times—that they should be.
See Nathanson’s plaintive article “Desperately Seeking Mathematical Truth” in the Opinion’s section of the August 2008 Notices of the American Mathematical Society, Vol. 55, Issue 7.
Thank you for this pointer. I do not know how to respond non-fatalistically, though. Of course we can take perceived ills as incentive to do better, but if you believe more experienced researchers you won’t get anywhere by adhering only to “clearly” proven things. And the more we build upon those shaky fundaments, the deeper we fall if some genius finally finds out that “obviously true” conjecture X does not hold at all. (In the case of P/NP we don’t even have informed conjectures, apparently, so there are even shakier branches of theory.)
“Of course we can take perceived ills as incentive to do better, but if you believe more experienced researchers you won’t get anywhere by adhering only to “clearly” proven things. And the more we build upon those shaky fundaments, the deeper we fall if some genius finally finds out that “obviously true” conjecture X does not hold at all.”
Understandable; but I think it was Newton who made the point that it doesn’t necessarily take a genius to see farther. Only someone willing to, first, stand on the shoulders of a giant and have the self-belief to see things as they appear from a higher perspective (achieved more by the nature of height than the nature of genius); and, second, avoid seeing them through the eyes of the giant upon whose shoulders one stands.
It was a lesson I learnt—for better or worse—from my ‘giant’, the late Professor M. S. Huzurbazaar, in my final year of graduation in 1964 when I protested that the axiom of infinity (in the set theory course that he taught) was not self-evident to me, as (he had explained in his introductory lecture) an axiom should seem if set theory were to make any kind of coherent sense.
He agreed that it was not really as self-evident as an axiom ideally ought to be. My natural response was to ask him if it was self-evident to him, to which he replied that he believed it to be ‘true’, despite its lack of an unarguable ‘self-evidence’.
It was his remarkably candid response to my incredulous—and youthfully indiscreet—query as to how an unimpeachably objective person such as he (which was his defining characteristic) could hold such a subjective belief that has shaped my thinking ever since.
He said that he ‘had’ to believe the axiom to be ‘true’, since he could not teach us what he did with ‘conviction’ if he did not (he was one of the most respected and revered teachers of Modern Algebra—now Category Theory—Set Theory and Analysis of his times in India at both the graduate and post-graduate levels).
However, he continued, that should not influence me in believing the axiom to be true, and holding it as self-evident.
His words—spoken softly as was his wont—were: “Challenge it”.
Although I chose not to follow an academic career, he never faltered in encouraging me to question the accepted paradigms of the day when I shared the direction of my reading and thinking (particularly on Logic and the Founadations of Mathematics) with him on the few occasions that I met him over the next twenty years.
However, if the self-evident nature of the most fundamental axioms of mathematics (those of first-order Peano Arithmetic and Computability Theory) were to be shown as inconsistent with a belief in the ‘truth’ of the axiom of infinity (a goal that continues to motivate me), I believe that the shades of Professor Huzurbazaar would feel more liberated than bruised by the ‘fall’.
Some very sharp comments were made on the blog about Deolalikar and his work. So also, after he prepared the first updated draft of the work. Consider that he had not even made his proof public but only sent it to a few individuals and asked them not to share it.
Any reasonable, sensitive individual will not give his work for such a public review again and rather wait through a journal review, after reading such comments; Thus, all you can do is wait. You can wish that if Deolalikar discovers a bug in proof (that he finds cannot be fixed), then he will let someone here know. So, the chapter can be gracefully closed.
If he does that we should laud him for being courageous to do that – as there will be many people here that will mock him again for it.
I checked Deolalikar’s page at http://www.hpl.hp.com/personal/Vinay_Deolalikar today.
The paragraph about his paper is still intact, but is now displayed in teeny-teeny-tiny type.
Does this must presage something?
Interesting justification. I prefer to read it Marcy Lu