Digital Butterflies and PRGs
Do some digital lepidopterology on your own PC

George Marsaglia was one of the world’s foremost experts on pseudo-random number generators (PRGs). He passed away last year after a long and fruitful career, which included a Fulbright scholarship in 1949–50 to Manchester where he was co-advised by Alan Turing. He famously discovered systematic deficiencies in early pseudo-random generators, and designed tests for the faithful generation of various important densities. He devised the Diehard Battery of statistical tests for the quality of pseudo-random outputs, which includes tests that simulate the dice game called craps.
Today we propose a new test based on playing chess rather than playing dice. The test employs exponential-time primitives, so it is much stricter—with common asymptotic complexity beliefs—than the usual tests, but it may be feasible for useful data sizes.
The new test draws on a strange but reproducible anomaly that I (Ken) have discovered in the behavior of several major chess programs. In one famous case it caused a program to shockingly lose a high-level game that it was favored to win. The anomaly can be isolated to the programs’ use of tabulation hashing, in the form called Zobrist hashing, as we recently described here.
This post comes with complete directions for you, the reader, to observe it, and also see what is apparently a digital Butterfly Effect. Then we outline how this effect might be expanded into a feasible, general, and powerful test, and explain why we feel this has a chance of working. The potential payoff is to leverage the power of a generically 
Viewing Non-Randomness
Uses of randomness have been vital almost from the beginning of computers. In the early days PRGs were ad-hoc methods that tried to generate streams of bits that worked in a practical sense. The idea came much later that it might be possible to prove that a PRG actually worked. Marsaglia work concerned these early methods, which are still in use today—even as parts of generators that “provably” pass certain kinds of tests.
Marsaglia invented ways to “disprove” many early generators, by exhibiting regular patterns in their output. Significantly he developed a geometric theory based on discrete lattices for these outputs, which gave immediate visual impact to these flaws. Here is a diagram, synthesized from pages 37–38 of this book by Alex Bielajew of Michigan, showing how Marsaglia planes can emerge from output that looked random before a 10-degree rotation:

Marsaglia’s other Manchester co-advisor Maurice Bartlett was known for statistical analysis of data with spatial and temporal patterns, and we speculate that this spurred Marsaglia’s insights. Yet the above is not just a visual trick—it means that any application that requires randomness but is sensitive to these patterns is unsafe. This was demonstrated even for relatively simple applications. Our question now is:
What kinds of tests do we need to assure that today’s more complex applications of PRGs are safe from “perilous dynamics“?
Toward this purpose we would like to suggest a different visualization tool:

For reasons evinced below, this chess position is pregnant for observing hash collisions that cause huge differences in values given by chess programs. There are others like it, and they point toward a general testing strategy.
If you wish to observe the hash collisions and butterfly effect stemming from this position straightaway, feel welcome to jump to the directions for carrying out the experiment below. You need not know much about chess to do this, though for chess fans I’ve added links to game analysis and computer-chess background. For our fellow complexity theorists, however, Dick and I wish first to say more about the rationale for the kind of test we are proposing here.
High-Level Rationale
In brief, our proposal is to take any of several open-source chess programs 
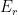
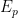
Does
have behavior that is feasibly distinguishable from
?
The question governing the ability to distinguish is: In an application where truly-random is good, to what extent is non-random bad? Let us suppose we have a performance metric 


First, of course this kind of badness is what we fear in general—this is why we desire statistical tests of PRGs in the first place. Second, a non-negligible frequency of “bad” ones among low-complexity strings is enough to make a general statistical test, even if we are given a particular 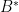
To test a given long string
for randomness,
- Randomly choose a short seed
that expands to a pseudo-random
.
- Run the actual test on
.
If 


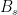





Chess as Canary for Malignness?
Of course it is commonly believed that some particular PRGs 
- A large alternating graph whose nodes have raw real-number values.
- A tabulation-hashing scheme from those nodes to an array holding their values.
- A minimax algorithm that updates node values, followed by selecting a node to be the root of the next search (which need not be an out-neighbor of the current node).
Another application domain could be model-checkers such as SPIN that employ hash tables to cut down huge state spaces. We mean the kind of application we covered here, not modeling the game of checkers—though come to think of it, the fact that checkers has been (at least weakly) solved might make it handy.
The fact of being both simple and complete for a hard class such as 

Theorem 1
For any non-negative real-valued performance metricof algorithms
running on inputs
, and any fixed
is proportional to the worst-case performance.
The simple nub of the proof is that “the first 


This lends credence to low-complexity strings
The bottom line is that murky, complex, unwanted patterns may be throwing off important PRG applications, and it will take murky, complex methods to root them out. The experiment we describe next is only a beginning, but it already exhibits chaotic properties of “digital dynamics” that will need to be accounted for.
Preparing the Experiment
The two main tools are freely downloadable and run under any reasonable version of Windows, including emulators on Mac or Linux. They are standalone applications—they do not require installation or modify the Windows Registry. For those who wish to know what led me to discover this position and why it is tricky, here is a game file reaching it in my analysis of the second match game at the heart of the 2006 “Toiletgate” cheating scandal, and here is further chess analysis and explanation.
★ 1. Download the free Arena chess GUI, which comes as a Zip archive.
★ 2. Download the Toga II 1.4 Beta 5c chess program (.exe) (.zip) chess program, extracting the folder or files anywhere you please.
★ 3. Download from my website the chess position file TKg2m74.pgn, which comes in the standard Portable Game Notation (PGN) format. Locate it anywhere convenient, say inside the Toga II folder.
★ 4. Run Arena, click the “Engines” menu, and select “Install New Engine.” Navigate to the Toga II executable—if you extracted the folder with four executables, for 1, 2, 4, or 8 cores, select the 1-core version. Click OK to the UCI option and say yes to starting the engine “right now.” (UCI stands for “Universal Chess Interface.”)
★ 5. Click the “PGN” menu, select Open, and open the TKg2m74.pgn file. A list of 16 entries will pop up. Double-click the first one to select it—the other 15 permutations are equivalent in chess terms but use different hash keys, and exploring them is up to you.
★ 6. Click on Black’s move 74…Rb7+ in the game-notation pane at right, so that you see the position with White’s King in check to make move 75. You need not attempt to move pieces on the board itself.
You are now ready to run the experiment proper. For practice, exit Arena (click “no” to saving the game) and re-launch it. Notice that it comes back to show Toga II loaded and opens the same PGN file—select game 1 and click on 74…Rb7+ as before.
Running the Experiment
★ 7. From the “Engines” menu again, select Manage, and click the “UCI” tab. Set the “Common hashtable size” to 64 MB as shown here:

★ 8. Click “OK” to go back to the game window, and finally hit the “Analyze” button. After roughly a minute you should see this:

★ 9. After noting the anomalous value at depth 14, and waiting for the depth 15 result to establish that the “White wins” verdict was a temporary blip, just click the red X at upper right to exit the program (or cleaner, first toggle the “Analyze” button to halt the search). Re-start the program, select the same game 1, and re-do step 7 but with only 32MB hash instead:

★ 10. Hit OK, click “Analyze,” and see the different results:

The depth-14 anomaly does not show. Hence we have isolated it to the size of the allocated hash table. You can repeat the above several times to be sure. Each time we are cleanly exiting and re-starting the entire GUI program and chess engine, so we can be sure there is nothing left over in memory from earlier use. But now comes the real fun, on which I am indebted to Toga II’s programmer Thomas Gaksch for the explanation that follows.
Digital Butterfly Effect
★ 11. Exit and re-start, remember to first click 74…Rb7+ after selecting the first game as before, but this time click the “Position” menu and select “Set up a Position…” to reach the following window:

★ 12. Change just the “74” as shown to “75” and hit OK. Then if you wish go and verify that 32MB is still the given hash size (you may ignore Arena displaying “34 MB” above the pane where the analysis appears as this is partly a k/K-byte difference), and click “Analyze” as before. Now the anomaly re-appears, though at depth 13:

★ 13. Finally complete the circle by exiting, re-starting, using the same position setup giving the game start as move 75, and setting the hash size back to 64MB. Depress “Analyze,” and you should see no anomaly.

Thus merely changing the starting move number reverses the phenomenon. Why? Aren’t the board positions always the same?
Here is the explanation given to me by Thomas Gaksch, who created the Toga family based on the chess program Fruit 2.1 by Fabien Letouzey. The positions are not the same to Toga II because of its implementation in regard to the so-called Fifty-Move Rule. This allows either side to claim a draw if fifty moves have passed without a capture or pawn moves. Toga II monitors the count of such moves and has a term in its evaluation fucntion that causes it to play more aggressively as the count (actually a countdown from 100 half-moves called “plies”) approaches the limit.
Now the difference between having 49 moves left and the full 50, the latter being what changing the start point to move 75 confers, is barely more than a tiny flap of the wings in the evaluation. Yet this is enough to change both the search pattern and the hash-table usage, leading to the huge +6.90 hurricane later on.
Other Settings, Other Programs
One can freely play around with other hash sizes, with the other 15 permutations of the position (which bring different hash keys into play), and with other chess programs. Here is a table I did with Fruit 2.1 itself. Like Toga II and Rybka, Fruit gives reproducible runs in the single-thread versions, while recognizing only power-of-2 hash sizes, but not all programs are this way.
Some programs get over-excited about White’s chances without this being a function of hash table size, including the non-UCI commercial Fritz series. The free-source high-grade Stockfish program (current version 2.2.2) does so in shocking fashion, often giving a value over +50.00 to 75. Kd6 before it sees that 75…Rb1 is a viable defense. With another commercial program, its author credited this position with helping him realize he had “over-aggressive search-pruning,” something he termed a “bug” and fixed.
Another open-source strong program is Critter (older open version in Pascal). With Critter one can see effects of varying the hash size, but they are more fleeting—often the value jumps from +0.90-or-so to +1.50 or +1.70-or-so in the middle of the depth 14 round of search, but returns to normal before depth 14 completes.
Extending the Experiment
All this only demonstrates the possibility of reproducible hash collisions that propagate to the root of the search. We have not yet involved a PRG. I do not in fact know how the 781 64-bit keys written literally into the code file random.cpp used by Fruit and Toga II were obtained—Gaksch didn’t know and further queries were unavailing. The Pascal version of Critter bootstraps up from an array of fifty-five 32-bit integers in similar manner to GnuChess 5.0 here, and I know at least one commercial engine does so as well. Stockfish changed at version 2.0.1 from using the Mersenne Twister to using a version of the KISS generator designed by Marsaglia himself, as credited in the browsable Stockfish source code here.
Using PRGs here is unnecessary for playing chess. Since the hashing scheme is fixed once-and-for-all, and there is no need for random numbers on-the-fly, the 50,000 bits should just be obtained from a truly-random source. But the fact that PRGs can be used, let alone that they are being used, is what furnishes the opportunity for discovery. To extend the experiment, take any one of these open-source chess engines, call it
-
Add code to
-
Re-compile
-
Write code that fills the tables with
for randomly-chosen small seed(s)
-
Run
The running step may require large amounts of computer time. Note that our behavior metric is not simply counting collisions—which is intuitively a linear test over 

The essence is that tabulation hashing provides general in-situ tests of PRGs. We note one Google Code project using Zobrist hashing this way, as opposed to building PRGs as described in the paper we covered recently, but mostly this idea seems unexplored.
Open Problems
Will the experiment be fruitful? Does it also shed light on the use of programs such as chess engines that are asymptotically exponential, but feasible in concrete cases? Can it perhaps unite the several senses of complexity that we discussed here, centering on chaotic effects in “digital dynamics”?
[some word changes in the intro]
Trackbacks
- The Higgs Confidence Game « Gödel’s Lost Letter and P=NP
- Branch And Bound—Why Does It Work? « Gödel’s Lost Letter and P=NP
- Graduate Student Traps | Gödel's Lost Letter and P=NP
- Why Is There Something? | Gödel's Lost Letter and P=NP
- The Evil Genius | Gödel's Lost Letter and P=NP
- Some Strange Math Facts | Gödel's Lost Letter and P=NP
- A Quantum Two-Finger Exercise | Gödel's Lost Letter and P=NP
- The Shapes of Computations | Gödel's Lost Letter and P=NP
- A Coup(e) of Duchamp | Gödel's Lost Letter and P=NP


I defeated this chess program once with out even realizing how it happened. The computer was all over my side of the board, winning materials here and there. There was nothing to do to prevent it, so I just pushed a pawn. The computer won more material, and I pushed the pawn again. This happened a bit more. Then what the computer and I realized at the same time was that the advanced pawn was worth more than all the extra material. The computer evaluation just flipped and it got beat like the cheap piece of silicon it was.
Just to note: my morph of the first figure has Alex Bielajew’s permission. The photo of Marsaglia comes from this article. Here is another nice source on “Random Numbers” that mentions his work. Marsaglia himself was incredibly active in online forums this past decade-plus: Usenet search list, two posts noted by Wikipedia here and here.
I’m not sure this is the cause, but a thing I’ve noticed is that since the Mersenne Twister has gotten so much press (very fast and very long period), a lot of people use it without knowing its downside. (For example, since it was published, I’ve seen a lot of libraries starting to use it.) The Mersenne Twister, by nature of its algorithm, produces bit patterns that fail tests of linear independence, and this could be really important for things like hashing.
Many simpler RNGs, like multiplicative lagged Fibonacci, pass all tests of randomness (e.g. TestU01, see http://www.iro.umontreal.ca/~simardr/testu01/tu01.html). I would usually recommend using these, rather than (or XORed with) Mersenne twister, in situations where you may be sensitive to linear independence of bits.
Honestly, 50k bits is not very many by today’s standards, and I would’ve taken for granted that a typical RNG would produce “random enough” bits for such a small size. This is a great example of why choosing a good RNG is important even if you don’t need a lot of bits.
Thanks. Indeed, I was aware from the start that the Mersenne Twister was used by Glaurung, the ancestor of Stockfish and another engine showing the reproducible anomaly, and that MT is slow to “mix”. Am I right to recall reading advice to use only every 100th (or 101st) evaluation, throwing the rest away?
To be sure, this is an example where IMHO one shouldn’t use RNGs at all, but rather get the 50,000 bits from CERN or “true noise”. But I think 50,000 bits is a nice “Goldilocks” size to test for compressibility, though.
Ken, I’m wondering if the goal directed movements are implemented in chess programs? I mean that in solving etudes it seems that humans do not even consider the movements that are not directly leading to the goal, and concentrate on the moves that lead to the substantial improvement in the position (whatever it means), designing the moves to remove obstructing pieces. From the different point of view, when kids are taught chess they sometimes are shown the plan, when opposite moves are not considered at all, and than they are taught how to counteract the opponent moves.
There are some famous “studies that computers can’t solve” where the solution involves giving up a Queen right away for a payoff that doesn’t come until fifteen moves (thirty ply) later. This one is my favorite—note the fix at the bottom of that page. The non-goal move often gets prematurely pruned away and not investigated deeply.
I wonder if similar tests could be done with Go. There’s been a lot of work in the last few years on Go programs which use Monte Carlo evaluations and some I think use similar hashing procedures.