Functions that use randomness
Shafi Goldwasser is one of the world leaders in cryptography, and is especially brilliant at the creation of new models. This would be true even if she were not one of the creators of IP and ZK; for example, consider her work on fault-tolerant computing. She recently gave one of the best talks at the Princeton Turing Conference, which we just discussed here.
Today I would like to talk about her new model of computation, which was joint work with Eran Gat at the Weizmann Institute.
Well their model is not just off the press, having been posted as an ECCC TR last October, but it is relatively new—and frankly I was not aware of it. So perhaps some of you would like to know about it.
Before I discuss the details of her definition I would like to say: how did we miss it, how could we not have seen it years ago? Or did we—and she is just another example of the principle that we have discussed before—the discoverer of an idea is not the first, nor the second, but the last who makes the discovery. Shafi is the last in this case.
Strange to relate, I (Dick) drafted these words before I knew that one of the previous discoverers was Ken—in an old 1993 draft paper with Mitsunori Ogihara. Ken recalled he had talked with Mitsu about “BPSV” as we finished the previous post, but didn’t discover they had made a paper until late Friday afternoon; it had been an unsuccessful conference submission. Then we discovered that Mitsu and Ken had incorporated the best parts of their draft into a successful conference paper at STACS 1995, of which I had become a co-author. This paper treats puzzles of the kind I thought of during Shafi’s lecture. Déjà vu, but also déjà forgotten.
First A Puzzle
Here is a simple puzzle that is central to Shafi’s work, and I would like to state it first. You can skip this section and return later on, or never. Your choice. But it seems like a cool simple puzzle.
Alice and Bob again have a challenge. An adversary distributes  balls—
balls— red and black—between two urns
red and black—between two urns  and
and  . The division is whatever the adversary wants: each urn could have half black and half red, or one could be all black and the other all red. Alice and Bob have no idea which is the case. Then the adversary gives Alice and , and gives an identical set of urns to Bob.
. The division is whatever the adversary wants: each urn could have half black and half red, or one could be all black and the other all red. Alice and Bob have no idea which is the case. Then the adversary gives Alice and , and gives an identical set of urns to Bob.
Pretty exciting? Well Alice and Bob are allowed to sample  balls with replacement from their respective urns. Their job is to pick an urn: or . They get “paid” the number of black balls in the urns they pick. So far very simple: their best strategy seems clear, sample and select based on the expected number of black balls. This is nothing new.
balls with replacement from their respective urns. Their job is to pick an urn: or . They get “paid” the number of black balls in the urns they pick. So far very simple: their best strategy seems clear, sample and select based on the expected number of black balls. This is nothing new.

The twist is this: Alice and Bob only get paid if they select the same urn. Of course Alice and Bob can agree on a strategy ahead of time, and they also have access to private coins. But they must somehow synchronize their choices. This is what makes the problem a puzzle—at least to me.
A trivial strategy is available to them. Just have each flip a fair coin and take or with equal probability. Note, half the time they will take the same urn and half the time they with get at least half the black balls. Thus their expected payoff in black balls is  . This is a pretty dumb strategy, surely they can use sampling to be more clever and beat
. This is a pretty dumb strategy, surely they can use sampling to be more clever and beat 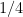 . But I do not see how. Perhaps this is well known, or perhaps you can solve it. Let us know. Actually we knew, but the question is, what did we know, and when did we know it?
. But I do not see how. Perhaps this is well known, or perhaps you can solve it. Let us know. Actually we knew, but the question is, what did we know, and when did we know it?
Now on to Shafi’s model, and then we will connect back to this problem.
The Model
Shafi’s insight is that deterministic algorithms compute functions. That is, given the same input they will always output the same value. This is just the definition of what a function is: each  yields a unique
yields a unique  . Okay, seems pretty simple. She then defines an algorithm that uses randomness to be functional provided it also defines a function. Well not exactly. In the spirit of cryptography she actually only insists that the algorithm have two properties:
. Okay, seems pretty simple. She then defines an algorithm that uses randomness to be functional provided it also defines a function. Well not exactly. In the spirit of cryptography she actually only insists that the algorithm have two properties:
-
The algorithm, over its random choices, has expected polynomial running time.
-
The algorithm for any input gives the same output at least
 of the time.
of the time.
Of course by the usual trick of simply running the algorithm many times and taking the majority output, we can make the output of the algorithm functional with very small probability of error.
The beautiful point here is that algorithms that use randomness but are functional in the above sense have many cool properties. Let’s look next at some of those properties before we get into some of her results.
Applications
Functions are good. And algorithms of the kind Shafi has described are almost as good as functions. Let me just list three properties that they have that are quite useful.
 Functions are great for debugging. The repeatability of an algorithm that always gives the same answer to the same input makes it easier to get it right. One of the great challenges in debugging any algorithm is “nondeterministic” behavior. Errors that are reproducible are much easier to track down and fix, while errors that are not—well good luck.
Functions are great for debugging. The repeatability of an algorithm that always gives the same answer to the same input makes it easier to get it right. One of the great challenges in debugging any algorithm is “nondeterministic” behavior. Errors that are reproducible are much easier to track down and fix, while errors that are not—well good luck.
Functions are great for protocols. Imagine that Alice and Bob wish to use some object  . They can have one create it and send it to the other. But this could be expensive if the object is large. A better idea is for each to create their own copy of the object. But they must get the same one for the protocol to work properly. So they need to create the object using functions. A simple example is when they both need an irreducible polynomial over a finite field. There are lots of fast random algorithms for this, but the standard ones are not functional.
. They can have one create it and send it to the other. But this could be expensive if the object is large. A better idea is for each to create their own copy of the object. But they must get the same one for the protocol to work properly. So they need to create the object using functions. A simple example is when they both need an irreducible polynomial over a finite field. There are lots of fast random algorithms for this, but the standard ones are not functional.
Functions are great for cloud computing. Shafi points out that one way to be sure that a cloud system is computing the correct value is to have it execute functional algorithms. For example, if you wish to have  computed, ask several cloud vendors to compute and take the majority answer. As long as the algorithms they use are functional in her sense, you will get the right value. Pretty neat.
computed, ask several cloud vendors to compute and take the majority answer. As long as the algorithms they use are functional in her sense, you will get the right value. Pretty neat.
Some Cases and Results
Shafi associates to every decision problem a search problem. For example, if the decision problem is whether a polynomial  of degree
of degree  over a finite field
over a finite field  is not identically zero, the search problem is to find
is not identically zero, the search problem is to find  for which
for which  . The famous lemma we covered here says that unless is tiny we can succeed by picking
. The famous lemma we covered here says that unless is tiny we can succeed by picking 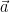 at random—indeed for any
at random—indeed for any  of size
of size  we can get
we can get  . But different random choices may yield different ‘s. Can we, given a circuit for a non-zero
. But different random choices may yield different ‘s. Can we, given a circuit for a non-zero  , always fixate most of the probability on a single ?
, always fixate most of the probability on a single ?
Eran and Shafi’s answer is to use self-reducibility. For each  try
try  as the value for
as the value for  , and test the decision problem to see if the resulting substitution leaves a zero polynomial. For the first (in some ordering of
, and test the decision problem to see if the resulting substitution leaves a zero polynomial. For the first (in some ordering of  ) that says “non-zero,” fix that as the value of , and proceed to
) that says “non-zero,” fix that as the value of , and proceed to 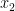 . Since each decision is correct with very high probability, the produced this way is unique. This also exemplifies a main technical theorem of their paper:
. Since each decision is correct with very high probability, the produced this way is unique. This also exemplifies a main technical theorem of their paper:
Theorem 1 A function is feasibly computable in their model if and only if it deterministically reduces in polynomial time to a decision problem in  .
.
Another example takes primes 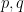 such that
such that  divides
divides 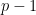 and produces a number ,
and produces a number ,  , such that is not congruent to any -th power modulo . Such an is easy to find by random sampling and then test by verifying that
, such that is not congruent to any -th power modulo . Such an is easy to find by random sampling and then test by verifying that

But again different random choices yield different ‘s. They show how to make unique by using as a subroutine a randomized routine for finding -th roots that itself is made functional.
Both theirs and Mitsu and Ken’s draft paper mention the open problem of finding a generator for a given prime , namely  whose powers span all of
whose powers span all of  . Eran and Shafi show uniqueness is possible with high-probability if one is given also a prime dividing such that
. Eran and Shafi show uniqueness is possible with high-probability if one is given also a prime dividing such that  is small, namely
is small, namely  is bounded by a polynomial in
is bounded by a polynomial in 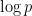 . Of course for many there are no such , but large characterizes strong primes which are useful in cryptography.
. Of course for many there are no such , but large characterizes strong primes which are useful in cryptography.
Shafi’s Main Open Problem
The open problem that she emphasized in her talk is: how to find a prime number in a given interval  ? The obvious method is to pick a random
? The obvious method is to pick a random  in and test to see if is a prime. Actually on can find discussions on this issue in works by Eric Bach—for instance this paper (also nice poster by a co-author)—or see here.
in and test to see if is a prime. Actually on can find discussions on this issue in works by Eric Bach—for instance this paper (also nice poster by a co-author)—or see here.
This procedure uses randomness in an essential manner, even if one uses the deterministic primality test of AKS. She asks: can one find an algorithm that would select the same prime? Note, if one assumes a strong enough assumption about primes—ERH for example—then it is easy, since the gaps between primes are very small. But without such a strong assumption there could be huge gaps.
I have an idea for this problem. It is based on using a random factoring algorithm. The key insight is that factoring is by definition a function. So no matter how you use randomness inside the algorithm you must be functional. Then I suggest that we pick that are not likely to be prime, but are provably going to have few prime factors. But first this takes us back to the Alice-and-Bob puzzle.
Bob & Mitsu & Ken & Alice
Consider the possibilities. For any input , each possible value has a true probability  . If the highest is bounded away from the next—it does not even have to be above 50%—then sufficient sampling will allow both Alice and Bob to observe this fact with high probability, and hence agree on the same .
. If the highest is bounded away from the next—it does not even have to be above 50%—then sufficient sampling will allow both Alice and Bob to observe this fact with high probability, and hence agree on the same .
Actually it suffices for there to be some with bounded away from any other frequency above or below. So long as Alice and Bob know fixed  such that has a gap of
such that has a gap of  , and no higher
, and no higher  has a gap more than
has a gap more than  , they will isolate this same with high probability after a polynomial amount of sampling. In fact all we need is
, they will isolate this same with high probability after a polynomial amount of sampling. In fact all we need is  bounded below by
bounded below by  . This fits in with a general notation for error and amplification in Mitsu and Ken’s draft.
. This fits in with a general notation for error and amplification in Mitsu and Ken’s draft.
One can regard the themselves as the values, and further regard them as outputs of a randomized approximation scheme. This is how Ken and Mitsu conceived the unique-value problem, and Oded Goldreich also saw this in section 3 of his recent paper on 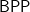 promise problems. Ken and Mitsu proved that it is necessary and sufficient to succeed in the case where there are only two values—that is, given a
promise problems. Ken and Mitsu proved that it is necessary and sufficient to succeed in the case where there are only two values—that is, given a  , compute a function
, compute a function  that always produces one of the two values
that always produces one of the two values  allows. This is the result that went into Section 3 of the published paper.
allows. This is the result that went into Section 3 of the published paper.
This brings everything back to the Alice and Bob urn problem, where urn has a true frequency  of red balls. Can we beat for one play of the game? Can we devise a strategy that could do better in repeated plays while navigating a larger search tree?
of red balls. Can we beat for one play of the game? Can we devise a strategy that could do better in repeated plays while navigating a larger search tree?
Open Problems
Besides the problems above, I personally do not know what she should call this class of algorithms. The class of functions can be called  , but that still does not nicely name the algorithms. Any suggestions?
, but that still does not nicely name the algorithms. Any suggestions?
Like this:
Like Loading...
Related




The ball problem is really elegant! I think I have solved it.
I claim that there is no strategy which beats 1/4, given an adversary who knows the strategy. Just to make explicit some things which I think you intended, there are n balls in each urn, and we are meant to consider the question for s fixed and n tending toward infinity, right?
Fix once and for all Alice and Bob’s strategy. Let a(p) be the probability that Alice will pick urn A, given that urn A has a(p) black balls. Let b(p) be the probability that Bob will pick urn A given that urn A has a(p) black balls. So the expected payoff is
p*a(p)*b(p) + (1-p)*(1-a(p))*(1-b(p))
We would like to make this quantity greater than 1/4 for all p. For a given value of p, imagine (a(p), b(p)) as a point in the unit square. When do we succeed?
For p between 1/4 and 3/4, and not equal to 1/2, the curve
pab+(1-p)(1-a)(1-b)=1/4
is a hyperbola, which cuts the unit square in two arcs. Here is an example for p=0.7:
http://www.wolframalpha.com/input/?i=Plot+0.7+x*y+%2B+0.3+%281-x%29%281-y%29+%3D+0.25%2C+from+x%3D0+to+1%2C+y%3D0+to+1
We win if the point (a,b) is in either the southwest or the northeast corner of the square. When p=1/2, the hyperbola degenerates to two crossing lines, dividing the unit square into 4 small squares, and again we win if we are in the southwest or the northeast quadrant.
When p < 1/4, then the northeast quadrant shrinks down to the origin and disappears. So a strategy which always stays in the northeast will lose for p too small. Similarly, a strategy which always stays in the southwest will lose for p too large.
So the only way to win is to have (a,b) switch from one quadrant to the other as p grows.
But a(p) and b(p) will be continuous functions of p for any possible strategy. So, in order to switch quadrants, they must cross the hyperbola somewhere. At the value of p where they cross the hyperbola, if the adversary chooses that value of p, the payoff will be only 1/4. Moreover, unless they cross at exactly p=1/2, there will be some range of values of p where the adversary could make their profit less than 1/4, as they cross the no man's land of the northwest-southeast diagonal band.
Of course, this is a highly theoretical analysis. If the adversary has limited computational resources, he might not be able to figure out when their strategy would cross the hyperbola.
David, I’m trying to understand your argument, but this sentence has me stumped: “Let a(p) be the probability that Alice will pick urn A, given that urn A has a(p) black balls.” It surely can’t be what you meant to write, but I can’t work out how to correct it because I can’t see what p is.
Sorry, given that p is the proportion of black balls in A.
It seems to me that an even stronger statement might be made, via the Juris Hartmanis-esque principle that “no TM that decidably halts can predict every decision TM that halts, but not decidably.”
Here the point is that the terms of the problem allow Alice and Bob to specify urn-choosing TMs that halt, but not decidably. Against which class of urn-choosing TMs, even an adversary of unbounded computational power cannot provably implement an optimal urn-filling counter-strategy.
In engineering terms, Alice and Bob can defeat their adversary by the “burning arrow” strategy of being fortunate in choosing undecidably-halting algorithms, and then declining to document them … because, how could they? I hope Juris Hartmanis would approve of their method! 🙂
I have formalized the above considerations in a complexity-theoretic question posted to TCS StackExchange: “Does P contain languages recognized solely by ‘incomprehensible’ TMs?”
Anyone who can provide answers and/or references, please post `em! 🙂
The discussion on TCS StackExchange has been edifying with regard to the differing meanings of “undecidable” in proof-theoretic versus computability-theoretic contexts.
One insight (that was useful to me) is that to avoid notational / definitional ambiguity, the above Hartmanis-esque postulate that “No TM that decidably halts can predict every decision TM that halts, but not decidably” might perhaps be more rigorously phrased as “With respect to any system of formal logic, there exist incomprehensible TMs, which are defined as decision TMs that always halt whose language no TM that provably halts can decide.”
Other folks may differ, but for me there is comedic enjoyment in imagining that Alice and Bob are free to specify (perhaps non-deterministically) urn-choosing TMs whose algorithms are incomprehensible to any and all urn-filling adversaries whose algorithms are straitjacketed by a formal proof-of-halting. This might be viewed as a natural proof-theoretic extension of Feynman’s aphorism “A very great deal more truth can become known than can be proven.” 🙂
A similar argument as David Speyer’s: as stated, the payoff of strategies a(p) and b(p) is p * a * b + (1-p)(1-a)(1-b) and is maximized for a=b. However, for continuous a with value at least 1/4, there must be a point x s.t. a(x) = 1-x with payoff (1-x)x^2 + x(1-x)^2 = x(1-x) <= 1/4.
Elaborating.
1. generality and continuity of a(p). As we demanded sampling with replacement, the strategies of players map the number (or sequence) of observed black balls to a probability of choosing urn A. The probability of these outcomes are continuous functions of p and, for every fixed n, the probability of a player to choose urn A is a finite sum of such functions.
2. existence of real x s.t. a(x) = 1 – x. If a(1/2) = 1/2, x=1/2 yields the desired equality. Otherwise, wlog, let a(1/2) 0 or else the payoff for p=1 is 0. Note that the function f(x) = a(x) – (1-x) is continuous, f(1/2) = a(1/2) – 1/2 0. Hence by the intermediate value theorem there exists an 1/2 <= x <= 1 such that f(x) = 0, i.e. a(x) = 1 – x.
3. x as a fraction of n. The fraction of black balls x can be arbitrarily well approximated by choosing n large enough (regardless of x) while holding s fixed; variable s is perhaps possible.
C.lorenz, do you agree that for s>>n Alice and Bob can earn n/2 almost all of the time? If yes, for which s/n do you think they can’t earn anything more than n/4?
Jiav: I did not work out the constants; perhaps it would be feasible to bound the Lipschitz constant of p due to sampling (for p of value at least 1/4+eps), or directly the probability on events of binomial distributions. My guess would be that either of these approaches would yield n increasing polynomially with 1 / eps times a polylogarithm of s. If s and n are polynomially related, I would suppose one can do non-insignificantly better than 1/4. Why? What do you think the relation is?
Sorry, re Lipschitz constants, I meant a(p), not p; and a likely sufficient dependence of s polylogarithmic in n, not the other way around.
> What do you think the relation is?
My guess would be that any fixed s/n will become interesting for some large enough s+n. But that’s equivalent to your last statement right?
Alice, I must say I don’t see the problem. Call p the proportion of black balls in urn B and c some constant we can agree on. Why couldn’t we just have a look and select urn A if pc. The larger s the more confidence we would gain that p is around c, but we would never know if we agree on p slightly below or slightly above c.
Ouch! Touché. Well if the adversary can make us disagreeing on p>c half of the time, I don’t see what we can do.
You don’t listen Bob. I’ve just said we can both gain confidence that p is around c. So please juste sample the urns and see if you can become statistically confident that urn B contains more black balls than A. If yes choose urn B, otherwise choose A. I’ll do the same and we can expect earning around n/2 at least.
… and we can’t expect more as the adversary can simply put n/2 black balls in each urn. Hey Eves can you believe this? Please refine the look of your micro next time, that’s becoming obvious you know.
[sorry text eated in part]
Alice, I must say I don’t see the problem. Call p the proportion of black balls in urn B and c some constant we can agree on. Why couldn’t we just have a look and select urn B if p>c for, say, c=1/2?
No Bob, wrong move. Any such strategy will fail against an adversary setting p=c. The larger s the more confidence we would gain that p is around c, but we would never know if we agree on p slightly below or slightly above c.
Ouch! Touché. Well if the adversary can make us disagreeing on p>c half of the time, I don’t see what we can do.
You don’t listen Bob. I’ve just said we can both gain confidence that p is around c. So please juste sample the urns and see if you can become statistically confident that urn B contains more black balls than A. If yes choose urn B, otherwise choose A. I’ll do the same and we can expect earning around n/2, or more if the adversary is foolish.
… and we can’t expect more as the adversary can simply put n/2 black balls in each urn. Hey Eves can you believe this? Please refine the look of your micro next time, that’s becoming obvious you know.
I’m not sure which side of the dialogue represents your actual views but, if you try specifying a precise sampling algorithm, you’ll see that this doesn’t work. For example, suppose that the algorithm is “draw three balls from A, and choose A unless all three draws are red.” Then the expected payoff is
(1-(1-p)^3)^2 * p + (1-p)^6 * (1-p)
If the adversary chooses p=0.283107, then the expected payoff is 0.21239 < 0.25 . It was after working out a number of examples like this that I became convinced 0.25 is the best possible.
I have a post in moderation arguing that 0.25 is indeed, unbeatable.
David, your point is that any fixed strategy will fail. I don’t argue that.
Actually you assumed s is small (say 3) and n large (notice p=0.283107 implicates n is a multiple of 1000000). In this case I think you’re right Alice and Bob are in trouble.
However if Alice and Bob can get s larger than n, then “sample the urns and see if you can become statistically confident that urn B contains more black balls than A. If yes choose urn B, otherwise choose A.” will lead them to earn n/2. That’s of course not a fixed strategy as s will be increased as long as they are not confident that p is above 1/2.
Regards,
If we are allowed to sample more than $n$ times, and are allowed to sample without replacement, then we can simply dump out the whole urn. So of course we can win in this case.
Also, even sampling with replacement, if we know $n$ in advance, we can choose a strategy so that $a(p)$, $b(p)$ only crosses the no-man’s land at values between $k/n$ and $(k+1)/n$. For example, I suspect the following would work: Say for simplicity $n$ is even. Take $n^4$ samples from $A$. If at least $n^4/2+n^3/2$ are red, take $B$, otherwise take $A$. The point being that, if $A$ has $\leq n/2$ red balls, then we expect the output to be $\leq n^4/2 + O(n^2)$ and, if $A$ has $\geq n/2+1$ red balls, then we expect $\geq n^4/2+n^3+O(n^2)$. So the probability of being at the borderline case is extremely small.
It would be interesting to figure out how small $s$ can be in order to win if we know $n$ in advance and must sample with replacement.
However, I think that, if we must sample with replacement, and if we don’t know $n$, then even strategies which can sample an unbounded number of times won’t help us (as long as they terminate with probability $1$). It feels to me like $a(p)$ will still be continuous for such a strategy.
Of course if s is large enough to know n or if s is small enough (say s=1 and the adversary set p=1/2…) it is trivial to show who will win.
Let me emphasis again the point of the above strategy: Alice and Bob ultimely choose as a function of the observed variance, and this varies as a function of what p the adversary will set.
Put yourself in adversary’s shoes: if you set p=0.5, then for some reasonnable (s and n) chances are A&B will choose A and earn n/2 more than 50% of the trials. So you change p for say p=0.6 to make them disagree more often. But too bad this affect the variance A&B see, thus they still agree more often than 50% of the time. So you try the reverse and set p=0.4. But then again the variance is affected so they will choose urn B more often…. a snake that eat his tail.
Another last way of seing this strategy is that it reverse the informational advantage the adversary have, cause what he’d know is not fixed but conditionnal to his own choice.
Care to propose a specific strategy for Alice and Bob and we can work it out?
I think we can agree that all reasonable strategies are equivalent to a strategy of the form: “Sample balls from urn $A$ until either (1) you have drawn $m$ balls, at least $f(m)$ of which are black or until (2) you have drawn $m$ balls, at least $g(m)$ of which are red. Choose urn $A$ in the former case and urn $B$ in the latter.”
So, what functions $f$ and $g$ do you propose?
>Care to propose a specific strategy for Alice and Bob and we can work it out?
“sample the urns and see if you can become statistically confident that urn B contains more black balls than A. If yes choose urn B, otherwise choose A.”
>I think we can agree that all reasonable strategies are equivalent to (…)
Of course we can’t. Statistical confidence varies as a function of s and p, while the form you suggest is structurally blind to both.
One of us is confused here.
When do you consider yourself to be statistically confident? And, since we want to make sure the algorithm terminates with probability 1, when do we decide that we will never reach certainty and make a choice anyway? Please list some actual cut offs.
I’ll make my best attempt to turn your words “sample the urns and see if you can become statistically confident that urn B contains more black balls than A. If yes choose urn B, otherwise choose A” into an actual strategy. Suppose I define statistically confident as “With confidence level $0.95$, I can reject the hypothesis that $p \leq 0.5$.” I can reject that hypothesis if I make $m$ draws from $A$ and get more then $m/2 + \sqrt{m}$ red balls. So, is my strategy “Draw from $A$ until I have made $m$ draws and get more than $m + \sqrt{m}$ red balls, then choose $B$”? But then we’ll never choose $A$! I need a stopping rule where I stop trying to become confident. Is the rule “Draw from $A$ until I have made $m$ draws, and get either more than $m + \sqrt{m}$ or less than $m-\sqrt{m}$ red balls, then choose $B$ or $A$ accordingly?” But then, if the adversary takes $p=1/2$, the probability that $A$ and $B$ will agree is only $1/2$ and their expected payout is $1/4$.
This sort of thinking is why I think that every strategy can be formulated in terms of two stopping functions $f(m)$ and $g(m)$. I particularly don’t understand why you are objecting that confidence will depend on $p$. Alice and Bob don’t know what $p$ is, so they have to formulate their strategy in a way which is independent of $p$.
>One of us is confused here.
One only? Sounds great!
>When do you consider yourself to be statistically confident?
Any sound test should make, as long as it is not equivalent to the mean being below or above some fixed criterion.
For the sake of clarity here’s one sugestion for s=100,000: count the black balls within the first hundred balls from urn A, the second hundred, the third hundred, etc Then do the same for urn B so that you’ll have two groups of 1000 integers, and finally run a Levin’s test to see if you can get a p-value below 0.05. If yes please consider yourself statistically confident.
>when do we decide that we will never reach certainty and make a choice anyway?
When s is exhausted of course. To me the interesting question is what happens when s and n get larger and larger, and as a function of s/n.
>This sort of thinking is why I think that every strategy can be formulated in terms of two stopping functions
I respectfully disagree with this sort thinking.
> I particularly don’t understand why you are objecting that confidence will depend on $p$
Because the observed variance depends on the actual p chosen by the adversary, thus any strategy based on comparing the variance will also vary as a function of what p the adversary will choose.
One more reply and I’ll turn off for the night. The strategy you propose here only uses 100,000 samples; it doesn’t adaptively choose how long to sample based on results. In that case, $a(p)$ (and $b(p)$, which will be equal to it), is a polynomial in $p$, so definitely continuous, and my argument definitely shows that, for large enough $n$, there is some $p$ which makes this strategy fail.
the Cinderella algorithm. you have a shoe made for her and you try it on as many times you can before 12 P.M. What is the reason you have several variables to consider but the most important in cryptography is the time.think as the genomic interface where every cell has its function, when you as Alice are creating an egg in the ovary you create a sequence of genetic strains every one has an especial function, almost 2 billions of different cells. a polynomial equation would integrate the whole development of the egg when enters in contact wit the male cell it does create an identification and binding operation, but what does it happens when the male cell doesn’t recognize the female cell? there is no binding.because you have a different encoding genome, this can be a crocodile or a mouse , every genome comes attached to a subatomic particle that has a sequence.when you are running a series of exponential numbers you have logarithms and when you are compressing a file on radical numbers you get algorithms, that runs as real numbers, and when you reach radicals on 1 you enter the imaginary numbers.( The bose-Einstein condensate is about compressing nuclear gases). when you add gravity(g) you compress the time and space and if you climb one step at the time in a vertical ladder one time per operation, you can try to fit the bit value into the written algorithm, here you can do this one time a bit, before you can accumulate many attempts the machine locks you out, some times, the same way you throw away the daisies in Vegas o Monte Carlo you can predict the results, have only one try at the time.here in the cryptic value is written in antimatter or -1 just the same way the cell gets his genome Cinderella got her crystal shoe, if you keep compressing the same value in the same space and time you increase the attempts to try the shoe before the time runs out, as long as the value of the empty space remains unoccupied you have a chance to change the surrounding variables values,otherwise the result will be the same. Einstein talks about how to generate this gravity when you travel faster than the speed of light, and when the inertial force starts creating this compression state where the radical becomes -1. this condition of inertial forces joining together in the future before real time happens, is called the analysis of Complex numbers, they are the numbers that you can multiply many times and you get the initial value as 1=C constant of the speed of light. in the diagram of a complex numbers we can see how the statistical samples in the matrix are affected by the gravitational force, here we have to consider the Variance and the standard Deviation of the traced trajectory of time and space.you can divide one byte into many bits but you will have the same value on the wave length unless the bit becomes a quantum bit.
probability and statistics, proof and error in complex numbers.
Niagara Falls algorithm?
Another dumb strategy. Alice and Bob start with random strategy, and use sampling to estimate fraction of black balls in urns A and B, than they bias their choices toward the urn with higher probability of black balls. I guess the odds to select A would be , where
, where 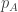 is the estimated fraction of black balls in urn A after last sample. At least this gives extreme values for p_A=1/2, and for p_A=1. Whether this is optimal for all p_A I do not know.
is the estimated fraction of black balls in urn A after last sample. At least this gives extreme values for p_A=1/2, and for p_A=1. Whether this is optimal for all p_A I do not know.
Another primitive strategy would be to peek a ball from the urn you think have more black balls,e.g. count the number of black balls sampled from A, add the number of red balls sampled from urn B and divide by the number of sampled balls, if this number if more than 1/2, sample from A, otherwise from B, if equal sample randomly. As the number of samples goes to infinity, the above calculation gives good estimate of the probability, than in the limit expected payoff is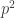 , where p>=1/2 is the fraction of black balls in the urn A or B.
, where p>=1/2 is the fraction of black balls in the urn A or B.
I’m not quite sure how your suggestion for ‘picking an x with large prime factors’ would work? If we take the interval I as (n, 2n) for instance, then any non-prime x in this range will still have its largest prime factor outside of the range, so factoring numbers in the range can’t be of any help and I don’t see how you can deterministically factor numbers outside the range ‘in time’ (not to mention that factoring, unlike primality-checking, isn’t polynomial in the first place!).
I’d be inclined to try and ‘cheat’ the RH by using something pseudorandom like a Halton sequence; since random numbers between (n,2n) are prime with probability 1/log n, then polynomially-many trials should produce a hit. Of course, the trick is finding a Halton-style sequence that’s guaranteed not to ‘cohere’ with the structure of the primes in some sense, but it feels like this might just be accessible with the right version of some regularity principle…
Conisder the case where the adversary has four balls, two red and two black, and you get to sample once from each urn.
The adversary has three strategies: “A-urn all black”, “each urn half-black”, or “B-urn all black”.
You and your partner have many strategies, all of them weakly dominated by (at least) one of the following: “Always choose A”, “Choose A unless you draw reds from each urn”, and “Always choose B”.
This gives a 3×3 payoff matrix with no Nash equilibrium, but a unique mixed strategy equilibrium where the adversary plays probabilities 1/2, 0,1/2 and you play probabilities 1/2,0,1/2. This gives an expected payoff of 1, as conjectured.
I am not sure I am reading between all the lines on this. Since Alice and Bob can coordinate their strategies, if it is true that they have identical copies of the urns A and B, and both urns are labeled consistently (where Alice’s urn A and Bob’s urn A are the same, etc) then the best strategy is to coordinate ahead of time to always pick the same earn and choose by mutually flipping a coin before receiving the urns, or barring a pregame coin flip, just agreeing to always pick A or B before receiving the urns.
This can be decided using a payoff matrix from game theory, since the mutual payoff is always zero in the anti-correlated cases, the best strategy is to ensure they always agree on their choices before the game. Even more basic is that if one assume that the person putting the balls in the urns follows some sort of uniform function then if Alice and Bob agree ahead of time to always choose A, then after repeated trials they should accumulate as many wins as possible. Certainly if we say there is a 50/50 chance of all black balls being in A, then always choosing A will give you a 50% chance of winning all the black balls which is better then 25%.
Just read the previous comments (ex post facto). Looks like this is the right train of thought.
Just a final note, it looks like the best strategy (apologies for repeating things already said/alluded to in other comments) is to agree apriori to always choose A, then sample A with replacement (which follows a simple binomial function) until you reach some agreed upon standard deviation and then switch to B if the mean of the sampling indicates that A has fewer black balls then B.
It would seem that if both Alice and Bob’s urns A are identical then the results of the sampling should converge to the same mean. There will always be some non-zero probability that you can get an anti-correlated switch, but it would be extraordinarily unlikely.
Let us automate the Urn Game by simulating it on three kinds of Turing Machine: two Chooser TMs (provided by Alice and Bob) that choose urns, and a Filler TM that fills Alice’s and Bob’s urns with balls, and a Proctor TM that chooses
balls, and a Proctor TM that chooses  , and moreover certifies (by checking proofs) that everyone’s Chooser and Predictor are functioning in accord with the rules of the game. What rules shall the Proctor TM enforce? A candidate set of rules is: Choosers and Filler must supply an explicit proof of halting to the Proctor TM for checking. Choosers must disclose their TMs to Filler prior to the Filler specifying a TM; this disclosure is called the Filler’s Advantage. The Choosers may specify TMs that are incomprehensible, but the Filler must supply to the Proctor TM a proof that the Filler TM is comprehensible; this restriction is called the Chooser’s Advantage.Here “comprehensible” and “incomprehensible” are defined per the TCS StackExchange question “Does P contain languages decided solely by incomprehensible TMs?”
, and moreover certifies (by checking proofs) that everyone’s Chooser and Predictor are functioning in accord with the rules of the game. What rules shall the Proctor TM enforce? A candidate set of rules is: Choosers and Filler must supply an explicit proof of halting to the Proctor TM for checking. Choosers must disclose their TMs to Filler prior to the Filler specifying a TM; this disclosure is called the Filler’s Advantage. The Choosers may specify TMs that are incomprehensible, but the Filler must supply to the Proctor TM a proof that the Filler TM is comprehensible; this restriction is called the Chooser’s Advantage.Here “comprehensible” and “incomprehensible” are defined per the TCS StackExchange question “Does P contain languages decided solely by incomprehensible TMs?”
Intuition: The Chooser’s Advantage (namely, incomprehensibility) dominates the Filler’s Advantage (namely, total intelligence of the opposing strategy).
This is why the (presently open) question of whether P contains languages that are incomprehensible potentially has practical game-theoretic (and even cryptographic) implications.
Oh heck … HTML list codes are stripped 🙁 … let’s try again.
———-
Let us automate the Urn Game by simulating it on three kinds of Turing Machine:
• two Chooser TMs (provided by Alice and Bob) that choose urns, and
• a Filler TM that fills Alice’s and Bob’s urns with balls, and
balls, and
• a Proctor TM that chooses , and moreover certifies (by checking proofs) that everyone’s Chooser and Predictor are functioning in accord with the rules of the game.
, and moreover certifies (by checking proofs) that everyone’s Chooser and Predictor are functioning in accord with the rules of the game.
What rules shall the Proctor TM enforce? A candidate set of rules is:
• Choosers and Filler must supply an explicit proof of halting to the Proctor TM for checking.
• Choosers must disclose their TMs to Filler prior to the Filler specifying a TM; this disclosure is called the Filler’s Advantage.
• The Choosers may specify TMs that are incomprehensible, but the Filler must supply to the Proctor TM a proof that the Filler TM is comprehensible; this restriction is called the Chooser’s Advantage.
>Here “comprehensible” and “incomprehensible” are defined per the TCS StackExchange question “Does P contain languages decided solely by incomprehensible TMs?”
Intuition: The Chooser’s Advantage (namely, incomprehensibility) dominates the Filler’s Advantage (namely, total intelligence of the opposing strategy).
This is why the (presently open) question of whether P contains languages that are incomprehensible has practical game-theoretic (and even cryptographic) implications.
Oh yes … a key technical point is that the number of urn-balls is finite but unbounded, and both Choosers and Filler must specify their TMs without advance knowledge of
is finite but unbounded, and both Choosers and Filler must specify their TMs without advance knowledge of  .
.
And one more technical clarification (these topics are tricky): the urn-filling is accomplished in the following natural sequence:
• Filler specifies the Filler TM and provides to Proctor a proof (in ZFC) that the Filler TM is comprehensible, following which
• Proctor specifies the number of balls and provides both the Chooser TMs and and
and provides both the Chooser TMs and and  as inputs to the Filler TM, and finally
as inputs to the Filler TM, and finally
• the Filler TM fills the urns with an (adversarial) choice of red and black balls.
AFAICT it is immaterial whether the urns contain an unordered versus ordered set of red-and-black balls … in either case the Chooser’s Advantage (algorithmic incomprehensibility) dominates the Filler’s Advantage (total intelligence of the opposing strategy).
These various definitions and restrictions are tricky and finicky to get right — IMHO this is because the Urn Choice problem is deep.
With the kind assistance of several TCS StackExchange posters, the various complexity-theoretic definitions associated to the question “Does P contain languages decided solely by incomprehensible TMs?” have evolved to be (more-or-less) natural, such that the question itself is now (hopefully) well-posed, and (apparently) this class of question turns out to generically open. Particularly helpful and interesting (for me) are Luca Trevisan’s recent comments on his in theory weblog.
Wrestling with these issues hasgreatly increased my respect for the toughness of finding optimal game-playing strategies and proving lower-bound theorems … even the seemingly simple complexity class P — which is the bread-and-butter complexity class of practical engineering — exhibits many subtleties and deep still-open mysteries.
While thinking on this, it is worth noting that the risk of making an anti-correlated switch is greatest when the real value of P(black) = 1-P(red) approaches 50%.
Since sigma is equal to sqrt[phat(b)phat(r)/x] where x is the number of trials and phat(b) = x(b)/x and phat(r) = x(r)/x such that sigma is sqrt[x(b)x(r)/x^3] = sqrt[(x(b)*(x-x(b)))/x^3)] there is no dependence on actual population size N in determining the standard deviation.
So a priori, without knowledge of N, I don’t know if my standard deviation is small enough to prevent an anti-correlated switch…iow, if Alice’s sampled mean is 50.000000001% with high confidence, and Bob’s sampled mean is 49.999999999% with high confidence, without definite knowledge of N so that Alice and Bob can confidently round to 50%, then an anti-correlated switch could occur.
In any case, a halting condition could be imposed when the amplitude of the statistical fluctuation is much smaller than the apparent space between the finite set of probabilities associated with the population size N (although the specific ratio is still dependent on a decision by the choosers/samplers).
The breakdown would occur in cases where N approaches infinity or is continuous, in which case one would need an infinite number of samples in the cases where the true probability is very close to 50%
Below are a couple of worthwhile refs on picking sample size and stats when sampling with replacement as well as the law of large numbers
http://edis.ifas.ufl.edu/pd006
math.sfsu.edu/schuster/Math124sec5[1].1.doc
http://en.wikipedia.org/wiki/Law_of_large_numbers
Since Alice and Bob are not blindfolded, we could assume they can see the size of the urns and the size of the ball (analogous to knowing the domain and spacing) so one can write:
Vol(urn)/Vol(ball) = N
where the total number of balls in 2 urns is 2N
If sampling from an urn the apparent space between each probability (d) is:
100%/N = d
Where probability is defined where if I where to sample 100 balls and 40 were black, I would say that there is a 40% chance of select a black ball. Which is on observed probability phat(b) which should eventually converge to real probability p(b).
Our standard deviation is expressed as:
sigma = sqrt(phat(b)*phat(r)/x)
where x is the number of samples and phat(r) = 1 – phat(b)
As we sample, the standard deviation (as expressed as a percent) gets smaller. We can compare the spacing between probability to the standard deviation (ratio is defined as z):
d/sigma = z
such that when z = 2 there are at least two standard deviations between a measured probability and its next nearest neighbor.
We also know that N must be an integer, so that:
phat(b) * N = n(b)
and n(b) must approach an integer number.
This also means that z will approach infinity (or 1/z will approach zero) as the sample size x increases.
Following the previous post if:
sigma = sqrt[(x(b)*(x-x(b)))/x^3)] = sqrt[(b*(x-b))/x^3)]
the derivative with respect to x is:
sigma’ = b(3b-2x)/2sqrt(bx^5(x-b))
http://www.wolframalpha.com/input/?i=derivative+y%3Dsqrt%28%28b*%28x-b%29%29%2Fx^3%29
(which has a really neat looking plot)
http://www.wolframalpha.com/input/?i=%28b%283b-2x%29%29%2F%282sqrt%28bx^5%28x-b%29%29%29
In any case, the change in sigma drops off very rapidly,
A plot of sigma’/sigma is interesting
http://www.wolframalpha.com/input/?i=%28%28b%283b-2x%29%29%2F%282sqrt%28bx^5%28x-b%29%29%29%29+%2F+%28sqrt%28%28b%2Fx%29*%28%28x-b%29%2Fx%29*%281%2Fx%29%29%29
which has a simple form
s’/s = (1/2)*(1/(x-b) – 3/x) = (1/2)*(1/r – 3/x)
since r is ultimately determined by some constant true prob p(r)
s’/s = (1/2)*(1/p(r)*x – 3/x) = (1/2)*(1/x)*(1/p(r) – 3)
where (1/p(r) – 3) is a constant k
so s’/s = k/2x
which is an inverse linear function where there is a definite zero when p(r) = 1/3 (which is impossible when dealing with integers)
I’ll leave for now in order to check the math to this point. The idea behind this exercise is to see if there are natural breakpoints where the marginal returns on sampling no longer justify continued sampling. The idea being that there are potential natural halting points based on natural rates. Will have to think about this some more.
“which is impossible when dealing with integers”
not sure why I said that, I think I was thinking about cases where the number N is 10 to some power e.g. 10/3 or 100/3 etc. Obviously 6/3 = 2 = 1/3 * 6
so disregard that comment.
for n=0 , the payoff is trivially ZERO for any strategy.
for n=1 , let both players pick URN ‘A’
The allocations to URNs A and B are:
RB,0
0,RB
R,B
B,R
Assuming these are all equally likely (max entropic distribution) the probability of each of these allocations is 1/4
So the expected payoff to Player1 say is 1/4 ( 1 + 0 + 1 + 0 ) = 2/4=1/2
Now we could get into Knightian uncertainty — but I think that’s getting way too complex too quickly.
Andrew Thompson
ps : I’m obviously getting something horribly wrong here — the obvious candidate being that the players do not actually label the urns consistently between themselves.
But maybe that means we should try a simple labelling problem first, rather than coming up with something totally OTT in the first place ?
PPS : If it were me, I would go back to Probability 101 and think about what probability really means. Some simple coin-tossing exercises might be good for a warm up — preferably in a good bar serving warm beer and peanuts ?