Benford’s Law and Baseball
What distributions follow the knock of opportunity?

Ted Hill is a Professor Emeritus in the Mathematics Department at Georgia Tech, and has two other affiliations. He graduated from West Point in 1966 where he roomed with General Wesley Clark, then served in Vietnam, and now maintains a website on his academy class. His other Georgia Tech site has interesting and vigorous personal material, and some fascinating mathematics projects with applications. He is arguably the world’s expert on Benford’s Law, along with Arno Berger of Alberta. The “law”—or phenomenon—is that many tables of numbers drawn from real-life data are skewed to favor 
Today I wish to probe the boundaries of this law, and argue for a new case of the law whose explanation seems particularly simple.
Simon Newcomb first noticed in books of logarithms that the pages with those beginning
In his 1881 two-page paper, Newcomb computed the frequencies of first digit in base 10, and also the second (which can be zero):

Frank Benford, however, was the first to observe the phenomenon in large-scale data—his 23-page paper published in 1938 observed 20,229 data points. Curiously they did not include the famous example of the first digits of heights of hills and mountains. The surprise is that regardless of the units of measurement (such as feet or meters) or the numerical base—provided the base is substantially less than the ratio of the largest value to the smallest—
Our questions are when do distributions follow this law, and (for a later post) what does it mean when data doesn’t?
Derivations and Explanations
The shared insight between Newcomb and Benford is that many data sets are really ratios of two uniformly distributed quantities. The unseen denominator is the choice of units. Represent the ratio in base 

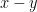


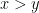
![\displaystyle B: [0,1) \rightarrow [1,b):\quad B(z) = b^z;\quad\text{so~} \Pr_B([c,d]) = \log_b(\frac{d}{c}).](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++B%3A+%5B0%2C1%29+%5Crightarrow+%5B1%2Cb%29%3A%5Cquad+B%28z%29+%3D+b%5Ez%3B%5Cquad%5Ctext%7Bso%7E%7D+%5CPr_B%28%5Bc%2Cd%5D%29+%3D+%5Clog_b%28%5Cfrac%7Bd%7D%7Bc%7D%29.+&bg=ffffff&fg=000000&s=0&c=20201002)
We can identify intervals 



A data set follows Benford’s Law if in any sufficiently small base
, about half of the data points have leading digit between
and
.
[Update 4/1/2013: I am not sure about this, and have been unable to trace the source I used at the time.]
For base 10, with 


It follows that Benford’s Law is scale-invariant in the sense of units not mattering—the only requirement is values being spread over a couple of powers of the base. This should not be confused with the idea of focusing on subsets of the range, such as 100 to 999 versus 1,000 to 9,999, or of identifying the numerical base with the unit of measurement, as either case can violate the requirement. Scale invariance can be axiomatized so that the above continuous version 
Hill’s two 1995 papers rigorously proving the base and scale invariance, and deriving Benford’s Law for certain processes of selecting a distribution and then choosing from it, have been credited as “explaining” the law. This goes also for an extension to certain mixtures of uniform distributions by Élise Janvresse and Thierry de la Rue, and a post three years ago by Terry Tao. The upshot is that data resulting from a complex mix of factors will tend to hit one that obeys Benford’s Law, and any such factor is “absorbing” in the sense that it causes products and certain other kinds of distributions that incorporate it to obey the law as well.
However, Hill and Berger warned last year that there is
No Simple Explanation In Sight For [the] Mathematical Gem.
To underscore this, their paper on the “basic theory” spans 126 journal pages.
The kind of explanation I seek would help in cases where the law applies-but-not-quite, to recognize where and why it is not holding. We start with a crude idea that gets the skew right, but not necessarily the distribution.
An Opportunistic Explanation
The explanation that I first heard, which is also listed first by Wikipedia here, is that Benford’s Law results from exponential growth processes. Picture mountains growing as land is pushed up until the process stops. Then we could say the skew aspect of Benford’s Law holds “because”
the opportunity to stop growing at 1,xxx feet always comes before
the opportunity to stop growing at 2,xxx feet, which comes before
the opportunity to stop growing at 3,xxx feet, and so on.
Whether the numbers conform depends on how the “stopping probability” 
Take Me Out Of The Ballgame
One of the categories in Benford’s original table of statistics is labeled “Am. League,” but this is not elaborated in his 1938 paper and I do not know what it refers to. I do know, however, that it cannot mean the statistic that first caught my eye when I suspected a data bug in an online fantasy baseball league I was playing in eight years ago. It concerns whether a baseball pitcher logs 


In the great majority of cases, a starting pitcher pitches a whole number
After not finding a convenient way to gather the data for these cases online, I went “low-tech” myself and humanly scanned the boxscores printed by the local Buffalo newspaper from last Monday through today (Sunday). This missed some late West Coast games but gave an unbiased seelction of about 100 games. I found these values:
- Starters,
- Starters,
- Relievers,
- Relievers,
.



In games there is a strong correlation of 


The opportunity for the manager to take a pitcher out of the game after
innings always comes before the opportunity to do so after
innings, for all whole-number values of
.
A countervailing factor is that
A Different Test, and a Bug
In a different test, on Thursday July 19 I looked up total stats for all pitchers using the “7 days” option in my Yahoo! fantasy league. This summed multiple games for some starters and many relievers, but the phenomenon still held: 25-20 for starters, 56-45 for relievers.
Over a full season I would expect the effect in cumulative stats to weaken, much as with Benford’s Law for digits after the leading one. The effect I saw in August 2004, however, definitely concerned one-day stats.
In a fantasy league run for MLB.com by SportingNews.com, I noticed one morning that the reported change in the total of innings pitched by my players was 1/3 of an inning less than the total shown on my team page for the previous day. Curious, I summed my team’s total for every day of the season and found a bigger discrepancy. I found similar effects for two other teams in my twelve-team league. Here is my belief of the explanation.
The interface displayed one-third of an inning as .3 and two-thirds as .7. Clearly the programming had a routine to display values that way, and perhaps it was even applied to round the daily totals. What I believe is that the daily team totals were being summed as numbers of the form X.3 and X.7 (besides X.0 in whole-number instances) to make the season team total, and that this sum was then rounded to display as Y.3 or Y.7 or Y.0. Of course this is silly, but it explains what I saw: The Benford-esque plurality R of X.3 day-totals over X.7 data points would accumulate an error of -0.033R in the grand total, and over a matter of weeks R would be large enough to cause rounding or truncation to compute a smaller value.
I brought this to the attention of the game’s tech-support, and received a reply that acknowledged it as a bug, but said it was limited to the display—that actual team totals used to enforce season-long innings-pitched quotas and compute other stats were not affected. I was not convinced, and thought to check it by the more-arduous task of computing my team’s ERA (earned run average) and WHIP (walks plus hits per inning pitched) statistics manually, but I realized the two-place precision by which they were displayed would probably not be enough to identify the discrepancy.
I considered pressing this further, with dreams of getting a minute on NPR’s “Science Friday” or somesuch, but I was trying to finish various things before the start of term. I did not find mention of this on an independent forum, nor anything like this 2006 post. Upon realizing that even if I was right, the reality behind the glittering “MLB.com” label would probably be no more than some young programmer taking a bad shortcut, I let it drop.
Open Problems
Is this a valid instance of Benford’s Law, or of a cruder principle that aligns with it? How far does opportunity-for-stopping go as an explanation?
Was I right about the fantasy-baseball bug?
Does the distribution of evaluations of chess positions given by chess programs, standardly in units of hundredths of a pawn, follow Benford’s Law? I’ve logged millions of such evaluations, and they seem to follow a distribution flatter than Benford but more skewed than half of a bell curve. This may be thrown off by the fact that 0.00 (meaning dead equality or game immediately drawn) has over ten times as many data points than any other value for the Rybka program, and apparently over twenty times for another program called Stockfish. A future post may elaborate this.
[Update 4/1/13—not sure about one statement above, as noted]
Trackbacks
- Saul Bass 1969 Bell Logo Movie and Benford’s Law applied to Yahoo Fantasy Stats « Pink Iguana
- Saul Bass 1969 Bell Logo Movie and Benford’s Law applied to Yahoo Fantasy Stats « Pink Iguana
- Interstellar Quantum Computation | Gödel's Lost Letter and P=NP
- A Computer Chess Analysis Interchange Format | Gödel's Lost Letter and P=NP
- Bias In The Primes | Gödel's Lost Letter and P=NP
- The Entropy of Baseball | Gödel's Lost Letter and P=NP
- The Breakthrough Result Of 2019 | Gödel's Lost Letter and P=NP


Boxscores in today’s paper (from yesterday’s games, completing a baseball week): Starters 4-7, Relievers 24-15. Includes a case of three relievers pitching 2/3 of an inning each, by Houston against Pittsburgh. I would love to have an easy way to compile the stats for a whole season.
Not related to Baseball, but related to Benford, these two posts:
– Benford’s Law and email subjects and
– Benford’s Law and email sizes
> Dick loves the “low-tech” detection method: look for pages that are worn—we would do that very differently today.
I guess the first three keys on an old numeric pad should be more worn out than the others… 🙂
This might be a silly question, but if a set of numbers obeys Benford’s Law, would you expect the second digit to have the same behavior? If not, what’s so special about the first non-zero digit?
The second digit has the less-skewed behavior shown in the second column of Newcomb’s table (which was fair-use screen-captured from the JSTOR link given just above it). One can derive that a little painstakingly by using the given formula Pr_B([c,d]) = log_b(d/c) for values of c,d that span ranges with that particular second digit. The reason why things focus on the leading non-zero digit, rather than (say) on leading decimal places that have a significant 0, is the invariance under multiplying by b which shifts the decimal point. Once you have a leading digit, however, 0 comes into play as a second digit.
My chess data, incidentally, shows patterns like this:
…
-0.02 — -0.02: 575.67 / 8507 = 0.0677
-0.01 — -0.01: 613.55 / 8951 = 0.0685
0.00 — 0.00: 6908.52 / 77228 = 0.0895
0.01 — 0.01: 479.93 / 8551 = 0.0561
0.02 — 0.02: 489.15 / 8472 = 0.0577
0.03 — 0.03: 499.19 / 8580 = 0.0582
0.04 — 0.04: 512.76 / 8782 = 0.0584
0.05 — 0.05: 592.40 / 9522 = 0.0622
0.06 — 0.06: 564.14 / 9293 = 0.0607
0.07 — 0.07: 660.14 / 10190 = 0.0648
0.08 — 0.08: 674.90 / 11070 = 0.0610
0.09 — 0.09: 680.59 / 11283 = 0.0603
0.10 — 0.10: 660.58 / 10219 = 0.0646
0.11 — 0.11: 714.04 / 10946 = 0.0652
0.12 — 0.12: 640.53 / 9869 = 0.0649
0.13 — 0.13: 634.55 / 9602 = 0.0661
0.14 — 0.14: 633.64 / 9866 = 0.0642
0.15 — 0.15: 612.34 / 9616 = 0.0637
0.16 — 0.16: 642.43 / 9626 = 0.0667
0.17 — 0.17: 624.56 / 9132 = 0.0684
0.18 — 0.18: 621.26 / 9263 = 0.0671
0.19 — 0.19: 627.72 / 9190 = 0.0683
0.20 — 0.20: 632.52 / 9099 = 0.0695
0.21 — 0.21: 631.88 / 8977 = 0.0704
0.22 — 0.22: 570.49 / 8564 = 0.0666
0.23 — 0.23: 639.92 / 8712 = 0.0735
0.24 — 0.24: 596.15 / 8436 = 0.0707
0.25 — 0.25: 598.39 / 8261 = 0.0724
0.26 — 0.26: 624.81 / 8431 = 0.0741
0.27 — 0.27: 604.25 / 8138 = 0.0743
0.28 — 0.28: 598.76 / 7875 = 0.0760
0.29 — 0.29: 598.60 / 7844 = 0.0763
0.30 — 0.30: 566.77 / 7408 = 0.0765
0.31 — 0.31: 586.55 / 7318 = 0.0802
0.32 — 0.32: 553.00 / 6957 = 0.0795
…
Left-hand is the advantage in hundredths of a pawn for the side to move, while the column before the = sign (which I’m focusing on) is the # of positions with that advantage. Note that a 0.00 value has way more data points than any other, and I surmise that it “attracts” nearby values causing the 0.01..0.09 range to skew “up” rather than “down”. Even if I redistribute it, however, the resulting distribution is still flatter than Benford both in the leading and the second digits. This is mystifying me, and distracted me for two days while writing the post.
I stumbled across Benford’s law in Hamming’s Numerical Methods book. He provides a derivation of the law for multiplicative processes in his paper from 1970, http://www.alcatel-lucent.com/bstj/vol49-1970/articles/bstj49-8-1609.pdf
This is harder to get from the newspaper, but it would also be useful to have this additional information …
There are two ways for the starting pitcher to be taken out after X innings. He could be removed before taking the field in inning X+1 (e.g. for a pinch hitter in the NL), or he could throw at least one pitch in inning X+1 but be removed before getting anybody out.
So we should compare X, X +1/3, and X + 2/3 for starting pitchers who threw a pitch in inning X + 1.
I would expect that X is pretty common, because of the tactical thinking of managers. When the game gets into the late innings, especially if the pitch count is high, the manager is watching closely for signs that the starting pitcher is tired. The pitcher walks the first batter and out he goes …
It would also be interesting to see if the distributions are different between AL and NL, to assess the impact of the designated hitter rule.
Thanks—that’s an interesting idea. It might require a Web-crawler script to go thru game pitch-by-pitch logs—I had a different reason for wanting to write one some years ago for a possible advanced programming project. Beefed-up boxscores do say “N.N pitched to 2 batters in the 9th” etc., but my local paper does not have them.
To really do a fair comparison with your suggestion for “X”, one might need to distinguish also cases of X+1/3 and X+2/3 where the pitcher did not retire the last batter he faced. In any event, X+1/3 and X+2/3 are on fairly equal game footing as I stated them.
Earlier this year I published a book on Benford’s Law (“Benford’ Law: Applications for forensic accounting, auditing, and fraud detection, Wiley, 2012). The book reviews many applications of Benford’s Law including fraud detection, income tax evasion, and the evaluation of the integrity of scientific data. The book also shows how to run the Benford’s Law tests in Excel and Access. The companion site http://www.nigrini.com/benfordslaw.htm includes data sets, Excel templates, photos, and other items of interest, including my first 1993 Benford’s Law article.
Hi Mark! A very happy owner of the first edition of your book here. I’ve made an online Benford test for anyone to check their numbers at: http://first-digit.appspot.com
why is it that I find this relevant for the discussion?
http://imgs.xkcd.com/comics/nine.png