How Not To Prove Integer Factoring Is In P
A possible barrier to proofs that factoring is in polynomial time

Mihalis Yannakakis is a Knuth Prize-winning complexity theorist and database expert. With Christos Papadimitriou in 1988, he framed the systematic study of approximation algorithms for 


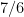
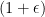

Today I want to talk about a “barrier” to many attempts to prove that integer factoring is in polynomial time, including a recent one that drew on ideas that were first applied to Traveling Salesman and related problems.
The very first of 94 current entries on Gerhard Woeginger’s indispensable page of claims to have resolved 
In 1988, Mihalis Yannakakis closed the discussion with his paper “Expressing combinatorial optimization problems by linear programs” (Proceedings of STOC 1988, pp. 223-228). Yannakakis proved that expressing the traveling salesman problem by a symmetric linear program (as in Swart’s approach) requires exponential size. The journal version of this paper has been published in Journal of Computer and System Sciences 43, 1991, pp. 441-466.
This is what we call an unconditional barrier. There are also conditional barriers, which are demonstrations that particular ways of solving one problem (such as proving a lower bound) entail solving an ostensibly harder problem (such as getting an unexpected upper bound or achieving a stronger-seeming lower bound).
Barriers Have Domains
The Maginot Line was a barrier, but it covered only one part of the border. Yannakakis’ barrier has two qualifiers: “symmetric” and “linear” before programs. By the former, it left open the chance of advances that evaded the symmetry condition, which is basically that the effect of the constraints is invariant under permutations of the variables. Such was the feeling that a recent announcement, of the extension of the barrier by Samuel Fiorini, Serge Massar, Sebastian Pokutta, Hans Raj Tiwary, and Ronald de Wolf, was titled:
Decades-old P=NP ‘proof’ finally refuted.
This work shared the Best Paper prize at STOC 2012, and the abstract explains the content simply:
We solve a 20-year old problem posed by Yannakakis and prove that there exists no polynomial-size linear program (LP) whose associated polytope projects to the traveling salesman polytope, even if the LP is not required to be symmetric. Moreover, we prove that this holds also for the cut polytope and the stable set polytope. These results were discovered through a new connection that we make between one-way quantum communication protocols and semidefinite programming reformulations of LPs.
However, the abstract also emphasizes another qualifier: “the LP’s polytope projects to the traveling salesman polytope.” This allows a possible loophole via different formulations for which projection to the standard TSP polytope used by Swart is not an issue. Then we need to see how far the logic of this paper (and a FOCS 2012 followup noted on the blog of my Tech colleague Pokutta) extends to alternative formulations. But first we also need to note that other kinds of constraint-management “programs” besides LP’s have powerful polynomial-time algorithms.
Programming
For those of us in computer science the term “programming” means something special: it covers the act of writing software for any computer of any type. The term is used in many other ways; one that was new to me is how architects use it. Programming is the term they use when collecting information for the design of a new building. See here for a description.

Programming also is a term used to talk about various types of problems. “Linear Programming” refers, of course, to the problem of solving a system of linear inequalities over the reals. This is a terrifically powerful problem, with an almost countless number of practical problems that can be reduced to it. Thanks to the brilliant work of George Dantzig, the powerful simplex method was created to solve them. Only later with the likewise great work of Leonid Khachiyan was it proved to be in
There are many other types of programming in this sense. Here is a partial list of types that are known to be in polynomial time:
- Convex Programming over
variables.
- Integer Programming over a fixed number of variables, i.e
.
- Quasi-convex Programming over
All of these are in polynomial time in the size of the inputs, although the second requires the number of variables to be fixed, and on the third we are a bit unsure between the 2001 source cited by this Wikipedia page and this 2006 survey. The best algorithms often use some variation of the ellipsoid method of Khachiyan.
Convex programming means that the objective function 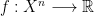
![{a \in [0,1]}](https://s0.wp.com/latex.php?latex=%7Ba+%5Cin+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
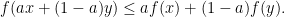
Quasi-convex means that for all values 
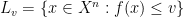
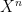
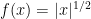
We need to note that all the above problems are closed in the sense that if 
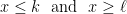
for any constants 

The Barrier
Okay you are planning to show that factoring is in polynomial time. One obvious idea is to use powerful previous work—a good problem solving rule is to be “lazy” and use other powerful methods. That is do not attempt to solve factoring, or any problem, from first principles. Use powerful tools.
The way this could be done is to try to reduce the search for the factors of a given 
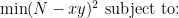

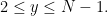
Note that if 
But suppose that you found a much more clever encoding into one of the programming types and the proof was correct. Here is the barrier: add the constraint 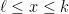
Barrier: If there is a program whose minima are integer factorings, belonging to one of the polynomial-time genres that are closed under adding constraints of the form
, then
is in randomized polynomial time.
…And a Loophole?
As observed on the thread, the
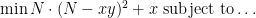
Presupposing other parts still work to make extrema occur at integers, a min less than
However, this kind of change may disturb quasi-convexity or other properties the objective function needs for the program to belong to the chosen class. And even so, if the formulation you are attempting to use would extend to cases where any factoring serves as a minimum, then the above conditional barrier comes back into play.
In summary, if you can reduce factoring to solving a programming problem for
Open Problems
Can we make the above barrier into a more formal one? I believe that this would be helpful. Perhaps there is a more general barrier result similar to the ones for Traveling Salesman problem that can be proved.
[added to paragraph after bulleted mention of quasi-convex programming, in response to query in comments]
Trackbacks
- » Factoring remains hard. Interesting proof angle: “a new connection that we make between one-way quantum communication protocols and semidefinite programming …” Gordon's shares
- Shor’s algorithm and period finding | Crackpot Trisector Notes
- Mathematical Mischief Night « Gödel’s Lost Letter and P=NP
- Thanks For Sharing « Gödel’s Lost Letter and P=NP
- Primality and Factoring in Number Fields | Combinatorics and more
- Complexity of factoring in number fields - FAQs System


I don’t know whether factoring is in P but my guess is that it’s not. My feeling is we’ll never know the exact answer. I have a theory about this: we can only estimate the probability that such problems are in P – and it seems very low for factoring. The closer you are to NP-completeness, the more you must content yourself with probabilities.
While results that show that NP-complete problems cannot be solved by certain linear programs are very interesting, there is a meta-barrier to this approach for proving barriers: as linear programming is P-complete, proving in full generality that such a problem cannot be solved by linear programming is equivalent to proving P != NP…
Yup—indeed that’s a(nother) (meta-)example of the distinction made in the post between a conditional and unconditional barrier.
I have my doubts about this paper. It seems the authors have nothing to say about the complexity of Semi Definite Programming. Do they assume/imply that SDP is polynomially solvable? It’s not known. Then how can they use the SDP reformulation of LP? The decision version of SDP is not NP-complete unless NP=CoNP. See the paper by Ramana, Math Programming (1997), Vol 77, p. 129-162.
No, for the TSP result they do not use SDPs at all. In fact what they show is that any polyhedron which can be linearly projected onto the TSP polytope (i.e. any extended formulation) must have a superpolynomial number of facets.
The set of positive polynomials is convex as the set of positive definite matrices, but in contrast to semi-definite programming, there is no polynomial complexity “polynomials” programs. and the difficulty is not in the convexity, but in deciding whether the object is belong to the convex set.
I am confused by your statement that quasiconvex programming _in a fixed number of variables_ is polytime solvable, and I would appreciate it a lot if you could give me a reference or elaboration on that.
My confusion is because I always thought that quasiconvex programming can be solved in polynomial time even when one drops the fixed-number-of-variables constraint. Right now, I cannot back this up with any nice references to papers, but at least the Wikipedia-entry on quasiconvexity (http://en.wikipedia.org/wiki/Quasiconvex_function) seems to agree with me, as it says that “In theory, quasiconvex programming and convex programming problems can be solved in reasonable amount of time, where the number of iterations grows like a polynomial in the dimension of the problem (and in the reciprocal of the approximation error tolerated);” The article refers to a paper by Kiwiel that I am planning to read, but did not yet read.
Thanks in advance!
I was unsure about that—after consulting with Dick, I’ve revised the mention and following paragraph to reflect what you say, linking also David Eppstein’s 2006 survey which is what I had found to check the original post draft. The survey says mainly that QC is a subclass of GLP, and on Wikipedia’s GLP page the opening paragraph says “subexponential in the dimension”.
Alright, thank you very much for clearing that up. It is a coincidence that just now when you post this article on your blog, I happen to encounter a quasiconvex programming problem in my research. I am about to delve into the quasiconvex optimization literature in order to figure out the details of these claims (I recall vaguely that e.g. it is often assumed in this type of paper that a real arithmetic operation requires only 1 time unit, and things like that. In this case polynomial time solvability does not immediately hold). This might take a while since everything seems very technical, but I will post something here once I figured this out.
What is known about the complexity for factoring in other rings of algebraic integers? In cases where factoring is not unique can certain optimization or decisions problems regarding prime factors be NP-hard?
I posted a question about it it the TCS stackexchange. http://cstheory.stackexchange.com/questions/16214/complexity-of-factoring-in-number-fields I am curious what can be said.
It’s impossible to make any distinction between:
1) polynomial algorithms exist but are prohibitively hard to find
2) there’s no polynomial algorithm
One of the challenges of complexity theory is to develop an appropriate framework for this situation. In fact, complexity classes behave just like fuzzy subsets.
I’m trying to make sense of your question, and find myself asking a whole lot of other more basic questions. For instance, what does it mean to “find” an algorithm? Does it mean (something equivalent to) writing a program that calculates a given function? Or does it mean coming up with a program and proving that it really does do the job? To illustrate the distinction, “If is even and
is even and  then print YES, else print NO” is almost certainly an algorithm that tells you whether or not a positive integer is a sum of two odd primes, but I have no idea how to prove it.
then print YES, else print NO” is almost certainly an algorithm that tells you whether or not a positive integer is a sum of two odd primes, but I have no idea how to prove it.
Also, from the standpoint of conventional complexity theory, if an algorithm exists then it is a finite object and so can be found in finite time by brute force. (The same goes for a proof that the algorithm works if that exists.) So the appropriate framework would have to look at just one instance of a problem and give a big lower bound for the finite time that is needed, which is not easy to do. For example, if you are given just one instance of 3-SAT, chosen in such a way that you would expect it to be one of the very hardest instances, there is a constant-time algorithm for solving it, which is simply to print out the correct answer out of YES and NO. So how do we make sense of the statement, “This is a hard instance of 3-SAT”? One obvious idea is that we insist on a proof that the answer is correct. Maybe if the formula is unsatisfiable there is no short proof, but if it is satisfiable, the satisfying instance will be a short proof, so what we are trying to say formally is that that satisfying instance can’t be found in a short time. But it can — if you are incredibly lucky. So we want to say something more like that it can’t be found in a short time in a systematic way that is in some sense independent of the particular problem instance. But that independence requirement is pushing us back towards considering a class of problems rather than one single problem.
Is this the kind of thing you mean when you talk about “one of the challenges of complexity theory”?
It took me a long to appreciate that in conventional complexity theory, the second statement is true, but deciding the truth (or otherwise) of the first statement is an open (and seemingly difficult) problem that belongs to a large class of open (and seemingly difficult) problems in complexity theory.
Here the intuition is that an finite algorithm may exist, and moreover be enumerated on a finite list of algorithms … and yet deciding which member of that list is the desired finite algorithm may be undecidable.
Perhaps this is one of those classes of problems, that in engineering practice are very difficult, for the complexity-theoretic reason that fundamentally these questions are undecidable?
1 is a short finite object. sin(x), cos(x) and x^2 can be computed to any precision in a finite time. But there is a difference in time and resources it take to compute f(x)=1 and f(x)= sin^2(x)+cos^2(x), or even f(x)= 1/2+1/4+…1/2^n … (which is not computable, unless you know convergence properties) unless you know how to manipulate the objects without actually computing them, and that is the main problem in the computation. The theorem can be seen as the statement in prolog, where the proof is a side program, attached to the statement. Once the proof is evaluated to true, the statement of the theorem can be used without the proof, providing shortcut for computation. And in a practical sense, I’m missing the consistent programming language with such a property. People use test suites to mimic the proof.
So Tim, I do not see how you can find a finite program by brute force to compute the third version of f(x).
Mkatkov, your intuitions are well-matched to issues that Juris Hatmanis discusses at-length in his 1978 monograph Feasible computations and provable complexity properties.
Considerations arising from Hartmanis’ work are illuminating in regard to the decidability of the
sevensix Clay Institute Millennium Prize problems. For all we know, any or all of the six remaining problems could be undecidable.But if we ask the nuanced question: “Which of the remaining Millennium Prize problems are most amenable to a proof of undecidability?”, then we appreciate that Hartmanis’ work provides at least a starting point in regard to proving PvsNP’s undecidability.
However interesting, any such proof would likely result merely in adjustments to the statement of the PvsNP problem. Yet on the other hand, if adjustments are indicated, then they are better made sooner than later.
Inspired by Gowers’, mkatkov, and Serge’s various questions and comments — and motivated too by Scott Aaronson’s sage advice “post well-posed questions to the various StackExchanges — I have posted to MathOverflow the question “For which Millennium Problems does undecidable -> true?.”
We discussed some aspects of Serge’s assertion in various earlier discussions including this one http://rjlipton.wordpress.com/2011/06/24/polls-and-predictions-and-pnp/ .
There are actually various frameworks that computational complexity (and also computability theory) can already apply to study distinctions of the kind Serge is postulating being impossible.
In Cryptography it is common that a task can be easy if you know a certain secret and computationally hard if you don’t. And it is even possible that a task in a family of tasks seems hard unless you know a certain secret related to the specific task but some tasks in the family are already easy if you know a certain secret associated to the whole family.
In learnability theory we know that to learn an easy computer program can be a difficult task. Proof complexity can be regarded as a program for showing the P not equal NP cannot be proved in certain proof systems.
All in all, Serge’s claim that his distinction is impossible to make is close in spirit to assertions that are studied formally in computation complexity and related areas of TCS.
There’s an argument for P=NP: the algorithm’s already too difficult computationally to be ever found by anybody. So there no reason why, moreover, it shouldn’t exist at all: one reason’s more than enough! 🙂
Most CS statements which tend to endow us with more powers are unprovable. This includes the feasibility of quantum computing, the negation of Church’s thesis and the separation of some complexity classes.
In linguistics, the secrets you mention are the natural languages. Knowing one of them allows you to understand most of the texts written in it but some other texts require some specific knowledge to understand what they’re about.
Thank you Tim for your answer.
By “find”, I mean with a proof. I’m sorry for having said above that my guess for factoring wasn’t in P: in fact there could well be a polynomial algorithm with nobody ever making use of it. When people wonder what the world would be like if P=NP, they actually mean: if it was proved correct, then implemented on a computer, and the polynomial was of low degree, etc… However if an algorithm for 3-SAT was proved correct if and only if Goldbach’s conjecture is valid, this would already be considered a real breakthrough… 🙂
The problem with brute force is that it takes too much time. It goes into what I call “prohibitively hard”. In the other branches of mathematics you never have to consider an infinite number of methods and then take the lower bound of their efficiencies. If we already knew all existing methods we wouldn’t be doing mathematics… 🙂 On the other hand, to consider an infinite number of instances is always necessary. That’s called generalization and I like your justification of it.
I wonder if it’s possible to do away with this intractable notion of lower bounds… but what to replace them with? In my opinion, complexity involves time deeply. Before the AKS primality test was found, prime testing was hard. Now it’s not any more. Thus, the degree of membership of NP problems in P can increase over time: complexity depends as much on the problem as on the algorithm. They say beauty’s in the eye of the beholder. I say complexity’s in the mind of the solver.
Serge, this is an interesting comment about the history of algorithms. Personally, I dont think our insights about complexity when it comes to the rough scale of polynomial/exonential and to the major algorithmic tasks have changed deeply over time. (In particular, prime testing was easy before AKS.)
Thanks Gil.
I agree with you: our insights about complexity don’t change that much over time. This is probably because the difficulty of trying to find an efficient algorithm more or less reflects the complexity of the algorithms you’re most likely to come up with.
Thanks Tim and Gil for your explanations. I now understand that complexity is attached to the problems and not to whatever means are used to tackle them.
But let’s go one step further: is complexity just an algorithmic notion or – as the story of quantum computers suggests – also a concept of physics? If the hardness of building the machine was taken into account, we’d have a new notion of complexity – both mathematical and physical – which would be more helpful to compare quantum complexity classes with classical ones. For example, the hardness of integer factoring is, IMHO, independent of the couple “build a classical computer” + “write a classical algorithm” or “build a quantum computer” + “write a quantum algorithm”.
This suggestion might also represent the “new framework” I was looking for. 🙂
Erratum: more helpful *for comparing* the classes. 🙂
In other terms, it’s difficult to build a quantum computer *because* factoring is hard. It won’t be solved more easily by transferring its complexity from the program to the machine.
And who said that Convex Programming is in P? It depends on your constraints and the objective function, whether they are linear or non-linear. In its most general sense, Convex Prog is NP-hard. See the papers by Immanuel Bomze, E. De Klerk, or Miriam Dur (all in the Netherlands).
You are right about that in some sense, but I think what is meant is that convex programming is in P subject to some basic technical conditions, e.g., that your goal is only to approximate the optimum to some epsilon-precision; that you have a polytime first-order oracle for the objective function; a polytime separation oracle for your convex body, and some balls contained in and containing the convex body that are of reasonable size, and maybe something more. I think there is a theorem precisely stated somewhere in the Convex Optimization book of Boyd and Vanderberghe.
Just found out that that was a wrong reference. The theorem that I am talking about is not in the book “Convex Optimization”, but in “Lectures on Modern Convex Optimization”, by Ben-Tal and Nemirovski. Chapter 5.
I’m starting to suspect conspirology here. In every explanation of Shor’s algorithm it is written that period finding is hard, and no references, no ideas why it’s hard, what approaches have been used. No real information. Does anyone have references on the classical approaches to period finding?
i used 1st grade arithmetic to calculate gazillion digit prime numbers and factor gazillion digit
numbers practically instantly. i used 2 1st principles. this method makes the prime number theorem, riemann conjecture and birch swinnerton dyer conjectures superfluous. unfortunately since i did not solve rc nor bsd i cannot get the million dollars. but you said that adding the constraint l <=x<=k turns it into np complete. if so then p=np
Did anyone read this manuscript ? http://vixra.org/abs/1505.0169
Where is the mistake ?
So this paper would put NP into randomized polynomial time?
http://arxiv.org/abs/1602.06910
I have a concern about this result. Why wouldn’t a convex optimization method (like interior point) work on this problem, if the problem definition allows convexity? Is it because we only deal with two variables and also therefore data sparsity or just because we require very high precision on those variables? I mean if a convex program is guaranteed to be solved with already known methods it should be valid for this problem too. Otherwise the same barrier should apply to all other optimization problems.