Thirteen Sigma
Monitoring fabrication in industry and chess

|
|
“Hall of Fame” source. |
Bill Smith joined Motorola as a quality control engineer in 1986. He coined the term Six Sigma to formulate a goal for vastly reducing the fault rate of manufactured components. This needed improving not only the monitoring of quality but also the resolution of testing devices and statistical tools so they could make reliable projections in units of faults per million rather than per thousand. The resulting empowerment of Motorola’s engineers gave such great and verifiable results that Motorola received the Malcolm Baldridge National Quality Award in 1988.
Today I want to talk about the meaning of high-sigma confidence in areas where the results may not be verifiable.
“Six Sigma” refers to the normal distribution curve, whose major properties were established by Carl Gauss. Gauss and others discovered that deviations in scientific measurements all tended to follow this distribution. His Central Limit Theorem provided an explanation of its universality. Thus magnitudes of deviations of many kinds can be expressed as multiples of the standard deviation 
The goal in manufacturing is to make the process so reliable that its 


Six-Sigma programs spread quickly and evolved a martial-arts mythos. Six-Sigma organizations award officially-certified Green Belts, Yellow Belts, Brown Belts, Black Belts, and Master Black Belts. They also have a “Champion” designation.
I wonder if those belts are conferred according to how many Sigmas one achieves, 8 being greater than 7, which is greater than the basic 6 (or rather, 4.5). If so then I should apply—because last week I achieved 13 Sigmas of confidence from my own software process (or rather, 11.3).
Chess Cheating Developments
Last month I was named to a 10-person joint commission of the World Chess Federation (FIDE) and the Association of Chess Professionals (ACP) to combat cheating with computers in human chess events. Discussions have gone into high swing this month, working toward drafting concrete proposals at the FIDE General Assmebly in Tallinn, Estonia, the first week of October. I am on the committee because my statistical model of human decision-making at chess answers a need voiced by many commentators, including Britain’s venerable Leonard Barden as quoted here.
I have, however, been even busier with a welter of actual cases, reporting on four to the full committee on Thursday. One concerned accusations made in public last week by Uzbek grandmaster Anton Filippov about the second-place finisher in a World Cup regional qualifier he won in Kyrgyzstan last month. My results do not support his allegations. Our committee is equally concerned about due-diligence requirements for complaints and curbing careless allegations, such as two against Austrian players in May’s European Individual Championship. A second connects to our deliberations on the highly sensitive matter of searching players, as was done also to Borislav Ivanov during the Zadar Open tournament last December. A third is a private case where I find similar odds as with Ivanov, but the fourth raises the fixing of an entire tournament, and I report it here.
Add to this a teen caught consulting an Android chess app in a toilet cubicle in April and a 12-year-old caught reading his phone in June, plus some cases I’ve heard only second-hand, and it is all scary and sad. It is also highly stressful having my statistics be the only ‘regular’ evidence in several currently unresolved cases—all in which other players made accusations based on unscientific testing before my work came on the scene. Previously, as with the case of Sébastien Feller (which ended for truth purposes with an accomplice’s confession last year), my results were supporting clear physical or observational evidence. But these new cases have deviations beyond the pale of selection-effect caveats, while the following story is on another plane.
Unquiet Flows the Don
Over all my playing years I’ve heard nonspecific rumors of rigged tournaments. Besides prizes and qualifying spots for championship competitions, a motive can be achieving a so-called title norm. The titles of FIDE Master (FM), International Master (IM), and Grandmaster (GM) are FIDE’s “belts,” and to earn them one must score a designated number of points according to the strength category of the tournament. I scored two IM norms in early 1977, but they covered only 23 of the 24 required total games, and achieving my third norm took until 1980. The higher titles bring financial benefit along with prestige. However, until now my results on the few famous specific rumors had been inconclusive.
The Don Cup 2010 International was held three years ago in Azov, Russia, as a 12-player round-robin. The average Elo rating of 2395 made it a Category 6 event with 7 points from 11 games needed for the IM norm, 8.5 for the GM norm. It was prominent enough to have its 66 games published in the weekly TWIC roundup, and they are also downloadable from FIDE’s own website. Half the field scored 7 or higher, while two tailenders lost all their games except for drawing each other and one other draw, while another beat only them and had another draw, losing eight games.
My informant suspected various kinds of “sandbagging”: throwing games in the current event, or having an artifically-inflated Elo rating from previous fixed events, so as to bring up the category. He noted some of the tailenders now have ratings 300 points below what they were then. Hence I thought to test for deviations down. I first took the 21 games involving the bottom two, with their 19 losses, and ran the procedure to compute their “Intrinsic Performance Rating” (IPR) detailed in a new paper whose final version will be presented at the IEEE CIG 2013 conference next month. I wondered whether getting significantly high error with an IPR under 2000 would really constitute evidence of “unreasonably poor” play, but even the high results of my preliminary test did not prepare me for the enormity of the printout of the full test:
IPR = 2925.
When I included the moves made by their opponents in the 21 games, my program gave 3008. This is well above the ratings of the strongest human players, but in the range typical for computer programs before Rybka 3 (my mainstay) emerged in 2008. Moreover my program gave about 
That was from the losers. I wondered what the winners’ games would look like… So I took the 3 days needed to run all my cores on the other 45 games.
Sigmas Amok
Running all 66 games created a sample of almost 4,000 analyzed moves—after excluding turns 1–8 of any game, so called repetition moves, and positions where one side has a crushing advantage. Most cases with single players have involved 9 games totaling about 250 analyzed moves, barely one-fifth of the sample size recommended for a reliable poll. This was effectively 132 games since it covered both sides of a game.
Hence the baseline 
The IPR does not come with a formal statement of unlikelihood, so I ran my Rybka-agreement test for that purpose. My program last Saturday printed the
z = 13.0011.
The last two digits are not significant—they owe to my global use of a 4-place C++ format specifier—but they show that the “13” is not rounded up. For reasons described earlier on this blog I divide by 1.15 to report an “adjusted z-score,” which allows for lack of full independence between moves and other modeling error. This yields the aforementioned 11.3. But I’ve tested that policy only for 

There it is: 

1-in-163,000,000,000,000,000,000,000,000,000,000,000,000.
I don’t know whether any physics experiment for a yes/no predicate has ever claimed 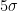
Is it a proof?
And here is the difference from Six-Sigma: an industrial process can be verified by later automated testing of the millions of items, but a one-shot predicate about human events often cannot be.
It Shines Like Truth
The German word for probability, Wahrscheinlichkeit, has the great feature of literally meaning, “the quality of shining like truth.” Whereas the corresponding root for our own word is Latin proba, meaning “test” or “proof.” Truth or proof, can it be either?
In this case I did not have to wait long for more-than-probability. Another member of our committee noticed by searching his million-game database that:
Six of the sixty-six games are move-by-move identical with games played in the 2008 World Computer Chess Championship.
For example, three games given as won by one player are identical with Rybka’s 28-move win over the program Jonny and two losses in 50 and 44 moves by the program Falcon to Sjeng and HIARCS, except one move is missing from the last. One of his victims has three lost games, while another player has two wins and another two losses. Indeed the six games are curiously close to an all-play-all cluster.
I verified this against my own collection of over 11,000 major computer-played games, tolerating 8-move differences, and was surprised to find just the same six identities, no more. So where do the other 60 games come from? My program’s confidence in computer origin is no less, but perhaps someone actually took the trouble to generate them fresh by playing two chess programs against each other?
I am expanding the search to match my database of over 200,000 human games per recent year against the 11,000 computer games, but each year is taking a day. A trial partial search of 2012 turned up a game in a junior tournament identical to the 39-move draw between Garry Kasparov and IBM’s Deep Blue in game 3 of their first match in 1996, but nothing beyond a children’s joke is apparent.
Open Problems
Six identical games may amount to six smoking-gunshots, but why don’t six sigmas, or thirteen?
Note for viewers of this Reddit item: though my 2009–2010 work with Guy Haworth and Giuseppe DiFatta used their Bayesian model, this one is elementary frequentist.
[simplified mention of FIDE’s “belts”; DB-GK draw was 39 not 38 moves; improved overall readability]
Trackbacks
- DynaRack, 13 Sigma, and Legal Information « Pink Iguana
- Bobby Fisher was right | En Passant
- Move the Cheese | Gödel's Lost Letter and P=NP
- D Plus O Equals Do | Gödel's Lost Letter and P=NP
- Littlewood’s Law | Gödel's Lost Letter and P=NP
- The Problem of Catching Chess Cheaters | Gödel's Lost Letter and P=NP
- The Chess Detective | Armchair Warrior
- Playing Chess With the Devil | Gödel's Lost Letter and P=NP
- Depth of Satisficing | Gödel's Lost Letter and P=NP
- Predicating Predictivity | Gödel's Lost Letter and P=NP
- The Doomsday Argument in Chess | Gödel's Lost Letter and P=NP


Really cool stuff. Regarding the last part, where you’re looking at (I assume) all pairs of 200K times 11K games, I wonder if there’s a way to design a reasonable hash function for a chess game. Then, with some appropriate tuning (for false negatives and true positives), you could just hash all the games into buckets and check the collisions, going from O(n^2) to O(n). I admit I haven’t thought about digital representations of chess games at all before so maybe this is more complicated, but could you just represent them as strings and then use an appropriate locality sensitive hash?
Yes—indeed the current expansion of my whole system, in-progress since January, may give me that capability. I’m actually rather surprised at the slow speed of this within ChessBase (v9).
Any possibility of real-time monitoring of games to detect this type of cheating (or whatever you want to call it to avoid being sued)? The hash function idea combined with lots of precomputing might make this feasible.
I greatly enjoyed this post. I suppose an obvious remark to make is that the chances that your statistical model is completely wrong for a reason that nobody has yet spotted are, though low, far higher than 1 in 163,000,000,000,000,000,000,000,000,000,000,000,000. Or is that not the case? An example where I would be happy to agree to a bound like that would be if I heard that somebody had supposedly tossed a coin 1000 times and got 500 heads followed by 500 tails. Then I would have that sort of level of confidence that a trick had been performed. Is your analysis of chess games like that, in the sense that there is an obviously “sufficiently correct” model underlying it.
Thanks. I’ve run almost the entire history of chess in Single-PV “quick mode” and this often gives reassurance of “sufficient correctness”. Here I left out of the post that the 63.3% matching to Rybka for Azov in that test is higher than for any human tournament of more than 4 players in my whole dataset. Only recent computer tournaments have higher, including WCCC 2008 (Beijing) itself at 63.5%. Of the three higher-matching 4-player quads, only Ostrava 2007 had double rounds (816 moves, others under 300 total moves), and it had an average rating of 2631 while the others were higher. I ran my full test on Ostrava, and the IPR came out 2639. The closeness is coincidence—the error bars are +- 140 (or +- 200 with the 1.4 adjustment factor)—but the point is that despite the similar quick-test results with high matching, my model discriminated away from 2900+.
My model also seems to give sensible results on computer matches even when the computers are stronger than my Rybka 3 depth-13 settings. I have Deep Blue at 2910 and 2850 for the two matches against Kasparov, who had only about 2600 both times (Think: Nerves), while its predecessor Deep Thought was 2150 in 1991, and MP successor Hydra hit 3150 in 2005. Deep Fritz 10 running on an ordinary quad-core PC had 2980 while beating Kramnik 4-2 in 2006; Kramnik hit 2730 while British GM Mickey Adams wins “best human” with 2820 even though he got wiped out by Hydra 0-5-1. My model gives just above 3000 to the last WCCC (Tilburg 2011); it was missing the disqualified Rybka and some other top programs.
So I think I’m getting fair “resolution” even without my current upgrade. To answer Martin Cohen above, except for the top games on auto-recording boards it takes time for volunteers to type in gamescores. Running my “quick test”—which needs only Perl scripts not my full C++ analyzer—is even more a motive than suspecting bogus duplicate gamescores for running games while a tournament is in progress, and balancing its “halfway” utility versus the time to type up gamescores now-not-later will be under discussion.
This is an excellent start Professor Regan. We have been discussing anti-cheating on the English Chess Federation Forum for some months now (including contributions from Leonard Barden I might add!). However, there is a body of opinion which seems to believe that its impossible to prove engine-matching moves are as a result of computer cheating. My response is that any anti-cheating allegations should follow a due process and I wondered whether this is the way the FIDE Anti-Cheating Committee are likely to view it?
For engine-matching move cheating allegations my feeling is the process should look something like this:
1. Develop a system to identify when possible cheating may be occurring using matching moves.
2. Using whatever criteria has been decided on one would then proceed to identify players who are falling foul of this criteria.
3. Investigate further using whatever other evidence is available and if the matter can’t be dismissed then a committee should be convened to interview/test player concerned.
4. Player gets interviewed/tested and gets a chance to address concerns before committee. Probably a good idea if these concerns were in writing. Here is the player’s chance to say that he/she is the illegitimate spawn of Data from Star Trek which is why he/she/it can play like a computer or whatever argument they can come up with.
5. Committee comes to a decision.
6. Appeals Committee
Dear Chris,
Thanks for the input! Indeed, this body of opinion is represented on the committee—that’s why I flowed the post from talking about the committee to the box with “is it a proof?” Practically we are starting with due-process, and I have drafted an outline of issues and procedural checkpoints—roughly like yours. As for what to do during a tournament, I am at this very moment (up late) giving the other 9 a hands-on “scholium”, very hands-on… Are you an ECF official? I’d be happy to confer with one…
—Ken R.
Dear Ken
Thanks for getting back to me. I’m not an ECF official, just a chess player who is the Team Manager of the Jutes of Kent in the English 4ncl. We are playing in the European Club Championships in Greece in October and as you know there have been cheating allegations surrounding this tournament in the past. I have asked the ECF if any of their officials are willing to get involved and will of course let you know, Personally, I work in Dubai in the financial services industry and have many years experience of drafting complaints procedures, legal redress and legislation and we seem to be in the early stages of setting up robust procedures with these computer cheating allegations which piqued my interest. Happy to be involved if you think it might be beneficial. Certainly trying to prove cheating using engine-matching moves will be challenging for your committee.
Best Wishes
Chris
With the car recalls, mobile phone recalls with exploding batteries as background examples, do you believe humans can guarantee 6 sigma or whatever 4 in a billion failure? FYI, Motorola will probably exist only in outdated tech forms in police radios and so on.
That’s for reasons other than Motorolla’s quality control… I believe, primarily, their Kodak-esque failure to adapt to a changing industry. (We may be going off topic.)
I am not complaining about M’s market failure. I am whining about human ability to guarantee anything like M’s sigma metric. I was hinting at massive car and phone recalls to illustrate the point that 4 out of billion failure is way out of whack with reality where error seems like 1 out of million and has not got much better with time. It is an irony that M itself has indeed folded pretty much.
An NIH/PUBMED search for the keywords Adademic AND adderall provides substantial grounds to expect that the prevalence of mixed amphetamine use in chess players specifically (and academic researchers generally) is almost certainly substantially higher than the prevalence of computer cheating.
In the absence of strict regulation ccompanied by testing, the prevalence of computer consultation in (intensely competitive) top-level chess, and of steroid use in (intensely competitive) top-level sports, tends toward unity.
What is the prevalence, and what are the trends, regarding the use of Schedule II (USA) and/or Class B/(UK) pharmaceuticals among grad students/postdocs/faculty in mathematics (and other STEM fields)? Soberingly, the medical literature suggests that the prevalence may be of order 10%-20% … and rising.
Is increasing pharmaceutical use in competitive STEM disciplines becoming sufficiently prevalent as to dissuade non-using students from STEM careers? This distressing possibility is becoming more likely year-by-year.
Conclusion Issues that are difficult in the context of computer chess become substantially more difficult when the cognitive augmentation is associated to drugs as contrasted with hardware.
“of mixed amphetamine use in chess players specifically (and academic researchers generally) is almost certainly substantially higher than the prevalence of computer cheating.”
I went to the NIH/PUBMED search you posted and found not one mention of chess in the keywords.
In his defense, no data exists for a reason he already specified: no one’s drug testing at these chess events.
The intended larger point is that Ken Regan’s (terrific!) tools for analyzing computer chess cheating allow us to practice dealing with ethical issues (associated to technological aids to cognition) that are bound to strengthen and deepen in the 21st century. So this particular GLL is (as I read it) is not *solely* about computer chess.
The intended larger point is that Ken Regan’s (terrific!) tools for analyzing computer chess cheating allow us to practice dealing with ethical issues (associated to technological aids to cognition) that are bound to strengthen and deepen in the 21st century. So this particular GLL is (as I read it) is not *solely* about computer chess.
Hi Ken,
Really excellent work. The best part of this is that it can be extended further to uncover the entire cheating ring.
For example, the player “Shojaat Ghane” was one beneficiary of the 2010 Don tournament. Once we know this, his rating progress becomes suspect: http://ratings.fide.com/id.phtml?event=12500313. He briefly reached above 2500 for his GM norm, then dropped to 2300. This calls the tournaments that took him to 2500 into question. Here is one of them:
http://ratings.fide.com/tournament_report.phtml?event16=7906&t=0
“Pavel Zaichenko” and “Roman Borovlev” have only game in online chess databases between them – unusual for a pair of 2400 players, to say the least. Moreover, Pavel “No Games” Zaichenko’s tournament history reveals results from “Cup of Don” events from 2001 and 2002: http://chess-db.com/public/pinfo.jsp?id=4163036.
A very interesting basis for future inquiry. No doubt most of the players in those previous events “forgot” to record their games – but the Tournament Director(s) of these events and beneficiary players may have some explaining to do.
Physicists have routinely observed 13σ events. 5σ has simply become the convention regarding what is announced as a “discovery”, simply because as energy goes up, so too has the complexity of backgrounds. Worse, the particles of interest nowadays are so extremely short-lived, their widths are rather wide, making the particle look closer to noise anyway. In the old days you didn’t bother with “significance”, there was no point because it was obvious a discovery was made.
For example, the J/ψ, PSR B1913+16, and the Oklo nuclear reactor discoveries would all have been off-the-scale if reported in terms of standard deviations.
If you haven’t heard about the Afromeev affair, you may start here: http://en.wikipedia.org/wiki/Vladimir_Afromeev
Notice the spectacular progress of his FIDE rating – http://ratings.fide.com/id.phtml?event=4157770 – and sudden retirement. The allegations in the time were that entire tournaments were staged and computer-generated.
> The German word for probability, Wahrscheinlichkeit, has the great feature of literally meaning, “the quality of shining like truth.”
It can also literally mean “the quality of appearing to be true” because “Schein” means both “shine” and “(false) appearance”, see “Sein und Schein” (“what it really is and what is appears to be”).
“Six of the sixty-six games are move-by-move identical with games played in the 2008 World Computer Chess Championship.”
Is this then proof of cheating in those games, or maybe not, thanks.
The Don Cup 2010 “winner” Iuri Shkuro is currently No 4 in the world blitz rating, he is in the World Top 10 Blitz for a considerable time already. Shkuro made his extraordinary blitz rating in tournaments, organised by himslef in the Kherson, Ukraine area (he also claims that he is the head of the Kherson chess federation), scoring 100% or close in many such tournaments.
In his 2016 article in Russian http://ruchess.ru/blogs/dimakrya/105/ at the Russian chess fed. website, GM Kryakvin states that Shkuro had played 186 games in such tournaments to date, scoring 182 points in these games)) While the line-ups of tournaments was rather conservative: in these 186 games he played against 34 different opponents only.
Mikhail, did you follow the link from my recent comment to the current post, https://rjlipton.wordpress.com/2017/08/17/on-the-edge-of-eclipses-and-pnp/#comment-83664? It mentions what seems to be a reoccurrence…