Proving Cook’s Theorem
Another proof idea using finite automata

Steve Cook proved three landmark theorems with 1971 dates. The first has been called a “surprising theorem”: that any deterministic pushdown automaton with two-way input tape can be simulated in linear time by a random-access machine. This implies that string matching can be done in linear time, which inspired Donald Knuth and Vaughan Pratt to find a direct algorithm that removes a dependence on the input alphabet size. This was before they learned that James Morris had found it independently, later than but without knowledge of Cook, and their algorithm is now called KMP. Fast string matching has thousands of applications. Second was his characterization of polynomial time by log-space machines with auxiliary pushdowns, a fact which may yet help for proving lower bounds. Then there was his third result, which appeared at STOC 1971, and was given a “slif” (stronger, later, independent form) by Leonid Levin.
Today I want to present a proof of the famous Cook-Levin Theorem that 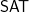

I am currently giving a class on complexity theory, and thought this proof might have some advantage over the usual proofs. There are the original tableau-based proofs, the later circuit-based proofs, and variations of them.
The proof here is based on my favorite kind of objects—well one of them—finite automata. They are remarkably powerful and can be used to give a relatively clean proof. At least I believe the proof is clean for students—I would like to hear any thoughts that you all may have about it. It needs no assumption about oblivious tape access patterns, and does not use lots of complex indexing.
So let’s take a look at the proof. Here is a Wordle from STOC 1971:

Introduction
My goal is to try and give a proof of Cook’s famous theorem that is easy to follow. There are many proofs already, but I thought I would try and see if I could give a slightly different one, and hope that it is clear. My thought is that sometimes the measure of clarity of a proof is the same as “ownership”: if you wrote it—own it—then it is clear. But here goes a proof that is a bit different.
The overarching idea is to do two things: (i) avoid as much detailed encoding as possible, and (ii) leverage existing concepts that you probably already know.
Machines
Let 





- the start ID
, which depends on the input, and
- the accepting ID
, which can be made unique and independent of the input.
For ID’s,

means that 
Saying that 





If one string is longer, we suppose the other is padded with a special null character to have equal length, and then we shuffle.
You might ask why introduce FSA when our goal is to encode NTM’s? It turns out that our proof will take the following steps:
-
Show that the behavior of an FSA can be encoded by
–
-
Show that the behavior of a NTM can be reduced to the behavior of FSA’s, and so to
-
Finally, replace
A Slight Generalization of
A 

Here each 
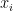

Note that

and 

Then

is the conjunction. This is satisfiable if and only if there are variables
There is nothing mysterious or strange about
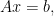
where 

to make it look like the 
The difference between
Cook’s Theorem
Our plan is to show that we can encode 

Theorem 1 The problem
–
–
is
-complete.
Proof: Let 


of length 
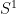



Let 
Claim: We have 



Then we claim that the conjunction of the clauses of all the

are satisfiable if and only if

Thus to complete the proof of the theorem we must show that claim about the existence of
Encoding With FSA
Theorem 2 Let
be a one-tape NTM. Then there is an FSA
that depends only on
and
,

Proof: The FSA
Encoding With ––
Theorem 3 Let
there are a set of general-clauses
over
variables so that

Proof: The idea is to look at the sequence

where 
- One clause that checks that
is the start state of
- One clause that checks that
is a possible state that
.
- One clause that checks that
is an accept state of
Clearly all of these can be done by general-clauses: they are just Boolean tests.
Final Reduction to
A 

for example.
The final step is to note:
Theorem 4 The problem
This proves Cook’s Theorem.
Nand Now For a Shortcut
Ken tells me that especially in Buffalo’s undergraduate theory course, he uses—and gets away with—a big handwave. He states the principle
“Software Can Be Efficiently Burned Into Hardware.”
He uses this to assert that the witness predicate 

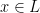

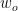

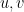


Together with the singleton clause 

This proof has some nice features. It shows the completeness of several restricted forms of
Open Problems
What do you think of the proof via finite automata?


Synchronicity Rules❢
I just started reworking an old exposition of mine on Cook’s Theorem, where I borrowed the Parity Function example from Wilf (1986), Algorithms and Complexity, and translated it into the cactus graph syntax for propositional calculus that I developed as an extension of Peirce’s logical graphs.
☞ Parity Machine Example
I guess I’m a little confused why you are so attached to the Turing machine as a model of computation. If you start with with the fact that Boolean circuits can do polynomial time computation with polynomial-size circuits — something that every CS major understands, since programs can be “compiled” down to machine language and thence to hardware — then we can take Circuit SAT as our root problem. The reduction from Circuit SAT to 3-SAT is extremely simple: just invent additional variables for the internal truth values of the circuit’s wires, and express in CNF form the assertions that each gate in the circuit functions properly, and that the output is true.
Isn’t this 1) a lot simpler, 2) just as rigorous, and 3) a lot easier for modern CS students to understand?
Chris, That sort of method leads to less clarity on the distinction between P and P/poly.
I know that’s the usual argument, but I don’t agree. One can always address uniformity in circuit classes after presenting this proof. What a student needs to understand is that for any fixed instance of an NP problem (Hamiltonian Path, Graph Coloring, etc.) it is easy to produce a circuit that checks solutions, and thus reduce the problem to an instance of Circuit SAT.
I agree that you need a uniform program to do this reduction: on the other hand, this reduction is extremely simple in most cases that we discuss. For local problems like Graph Coloring, it’s in DLOGTIME, i.e. local gadget replacement.
Do you really think that starting with single-tape Turing machines is better pedagogically? Doesn’t it just create more formal overhead for the student to wade through, before they get a chance to appreciate what NP-completeness is all about?
“… why you are so attached to the Turing machine as a model of computation.”
Good question, since theoretically any deterministic algorithm would seem to be equally logical for distinguishing between NP and P from a foundational perspective.
Roughly speaking, the importance of the Turing machine model is that we are factoring an infinite machination into an infinite component times a finite component, where it’s the same finite component each time. That amounts to a significant reduction in conceptual complexity.
Cris, exactly what you say is in the last section of the post. When I lecture, I do indeed use the words “…check that every NAND gate works correctly…” and present it as a basic instance of hardware verification. But for lower bound purposes, maybe there is interest in exactly how low one goes for the verification to remain NP-complete.
Hi Ken,
I know, and I like your “software can be burned into hardware” line. I guess my claim is that it’s not that much of a handwave! Yes, we need to teach the idea of uniformity, and at some point we need a uniform model. But we should feel free to use whichever model makes it easier for us to get NP-completeness up and running.
For teaching, my favorite uniform model is the program, written in the student’s favorite programming language. The fact that it doesn’t matter whether we use Java or Lisp for this is a wonderful fact, and the students need to appreciate it (and the hard work that went into proving it in the 1930s, i.e. the equivalence of partial recursive functions, lambda expressions, and Turing machines). But I prefer to start with the “software” proof of NP-completeness, and then to circle back and say “why can we get away with this?” At that point we can talk the equivalence (up to polynomial time) of different models of computation.
hi CM/all john savages book “models of computation” [free online! very nicely typeset] is partly a massive research project to reformulate/”reframe” most computational/complexity theory in terms of circuits, one that I generally agree with, but which few other researchers seem to have consciously acknowledged although there is much pursuit [allender comes to mind as another authority/expert who has advocated a circuit-centric view over many yrs]. also stasys jukna has contributed strongly to this agenda with his book “boolean function complexity, advances and frontiers”.
the TM model seems to predate circuits, but circuits are arguably a more fundamental or natural way to understand computation in many ways.
its a real ongoing paradigm shift [worthy of a blog somewhere at least?] that is somewhat unrecognized/unremarked on so far. it somewhat reminds me of the major theoretical “teams” in physics eg standard model vs strings etc.
also note that for circuits the P vs NP problem is P/poly vs NP, a stronger assertion, and the concept/distinction of uniform vs nonuniform comes into play.
surely [even after decades of research] one is not really provably superior to the other (circuits/TMs) in all cases, each has its own context, but they exist in a close theoretical coupling/synergy/symbiosis. two sides of the same coin. the yin & yang of complexity theory. and cooks proof is a nice example of this deep interconnection (which is more obvious four decades in retrospect thx in part to massive research in circuit-related complexity classes).
personally I have gone in the direction of circuits esp for complexity class separations & believe the view may eventually/ultimately lead to a P/poly != NP proof. this is because of the deep ties between monotone circuits and extremal set theory….
[CM ps enjoyed reading about your exploits in “complexification” by waldrop yrs ago.]
oops sorry got that link wrong! here is a NP vs P/poly proof sketch/outline using circuits/hypergraphs etc
vznvzn you are coming out as a crank. If Ken or Lipton, thought your ideas were worthwhile, they would have written about them.
sincere congratulations J on the feat of combine the converse of argumentum ad populum, genetic fallacy, and argumentum ad hominem all in only two sentences! do they teach this stuff in school any more? but, dont feel too bad, because even elite theorists are known to fall in the same basic traps of reasoning. =)
No, it’s not a more fundamental or natural way.
Indeed, the very thing that makes computation a natural and interesting notion is exactly that it is independent of the particular choice of implementation. Choose any reasonable implementation, make sure it doesn’t suffer from obvious limitations in power (only finitely many machine states, inability to make an unbounded number of intermediate computations) and you end up with the same notion. So there can’t be a more natural or fundamental way to approach computation since such a way would undermine the very naturalness and interestingness of the notion of computation itself.
I mean it’s like saying that counting pebbles is the fundamental/natural way to understand the natural numbers. It may be true that evolutionarily/historically counting fingers is neurologically easier and occurred first but what makes the numbers the numbers is that they behave the same regardless of what you describing. The best way to understand the numbers is by understanding the numbers!
—
Indeed, I think all this focus on circuits is holding back the computational complexity theory from looking at more powerful results from number theory and distracts from looking more closely at what makes the difference between the relativizeable complexity results and the non-relativizeable ones.
ok, will bite, just have to ask
what results are you referring to, did you have something specific in mind?
ps re J, feel is also guilty of argument from ignorance
Dear Pip,
Since you are proposing a new proof for the CLT, would you be slightly starting to believe that paper http://www.andrebarbosa.eti.br/The_Cook-Levin_Theorem_is_False.pdf?
It’s interesting you mention NAND gates and 3SAT.
Recently I tried to come up with a method to encode logic gates (OR and NOT) on Flow Networks with costs, and tried to show how this could maybe be applied to solve 3SAT in poly-time using minimum cost flow algorithm.
Obviously there’s probably some flaw that I don’t see (yet). I will have to implement this and test my theory.
http://polyfree.wordpress.com/2013/10/07/logic-gates-on-flow-networks/
I have often heard the sentiment that it should be easy to see, especially for CS students, that programs are equivalent to circuits and hence it suffices to prove Cook’s theorem by proving that Circuit-SAT is reducible to SAT. I don’t think it is any where as simple as that. Typical programs are complicated and have non-local references because of the RAM model and it is easy to get confused by the size of integers, pointer addressing etc etc. The idea of non-determinism, checking solutions vs coming up with them, and a proper understanding of when a language is in NP are, in my experience, not easy to teach.
If that’s so, then it gives you a good opportunity to teach a little about hardware. Can the students design a circuit that takes an n-bit input x and a log_2 n-bit input i, and returns x with the i’th bit flipped?
If not, then I think we have a larger pedagogical problem 😉
Yes, they can design such a circuit but this is precisely where the uniformity issues comes up. They can also write code on a regular computer for the same problem with x and the index i given. However the code runs on a fixed size hardware (their laptop) while the circuit designed for the problem depends on n, the size of x. Of course one can say that circuit itself can be generated by a uniform program but then one is really getting back to a uniform model of computation at some level.
Nice share sir, but i still doubt with this theory
Almost surely I missed something in this proof, but since it does not require a lower bound on k, the number of boolean variables in each SAT clause, I think you can just substitute “3-SAT” by “2-SAT” and the theorem would read “2-SAT is NP-Complete”, which is of course not true. Am I missing something here? Maybe the point is that the encoding of the clauses hinted by Theorem 3 requires some clause to have exactly 3 boolean variables?
A gate with k inputs and one output requires k+1 variables to describe; thus the CNF clauses need size k+1 (in general). Since one-input gates don’t suffice, we get k+1=3 as the smallest possible clause size in the proof.
I was teaching the last spring my first ever undergraduate course, happened to be “the introduction to TCS”.
Usually in this class the complexity, i.e P vs NP, is barely touched. Most of the time is spent
on regular and context free languages and Turing machines. Anyway, I gave “informal” treatment of Cook-Levin very similar to yours. BTW, in the simple Theorem 3 you need to mention locality in order to get back to Cook-Levin. Actually, the proof from Wikipedia is quite similar. I tried to be very concrete and put the main focus on colorability and maximum clique(because of the connection, Motzkin-Straus, proved in the class, to the continuous world). Colorability is a great motivation for complexity: it is easy to convert an algorithm
for k-colorability to the algorithm for m-colorability, m 2. The students really liked and understood this motivation.
And it can be done without Cook-Levin as for the colorability it is very easy to write down the boolean formula. But, say for maximum clique what is needed is a “short” boolean formula describing all boolean strings with exactly k ones. The case k= 1 is simple and actually is used in Wikipedia proof.
And I gave this formula for “large” k using FSA. Also, similarly to your examples, I talked a lot about linear
equations: gave the algorithm for 2-colorability based on the gauss elimination.
The cool thing about this algorithm: it counts the number of colorings as well; and some of the students were learning
the gauss elimination at the same time in linear algebra class. The connection was a shock!
Thanks a lot for this blog and best regards, Leonid.
Suppose to be “Colorability is a great motivation for complexity: it is easy to convert an algorithm
for k-colorability to the algorithm for m-colorability, m 2.
The students really liked and understood this motivation.”
Somehow some of my sentences in the posts above got lost, with completely kosher words, strange.
How do you encode an instance of SORTING into an instance of 3-SAT? And how do you encode an instance of FACTORING into an instance of 3-SAT? I’d bet the former encoding yields much bigger instances than the latter.
My other guess: this size difference is an explanation of why SORTING is easier than FACTORING. The intuition comes from quantum mechanics. Small objects have unpredictable behavior, but large groups of small objects are deterministic.
Is it possible to infer, from the mere probabilistic nature of observing a quantum particle, that a sequence of bits can only be found on a probabilistic basis? If quantum mechanics is the ultimate machine language, then that’s a likely hypothesis.
Thus, whenever a digital data – algorithm or data structure – is observed, this is due to its low-enough Kolmogorov complexity – i.e. the length of the shortest program which outputs this data. Although uncomputable, K-complexity is a function defined on all bit sequences and it plays the role of a probability distribution – just like probability waves in quantum mechanics.
Being undecidable, K-complexity would have been different in another Universe generated by another Big-Bang. In one of those, the Riemann Hypothesis is perhaps an easy lemma for undergraduate students – along with P!=NP – but the fundamental theorem of algebra is undecidable.
Well, perhaps not exactly undecidable but a hard conjecture anyway. What is provably true, provably false or provably undecidable in another Universe is the same as in ours, but the hardness of the proofs might be different.
So, whenever you come across a very hard conjecture, it may just be “true for no reason” in the words of Gregory Chaitin. My opinion is that the distribution of easiness and hardness is completely casual, depending on the quantum structure of our Universe. In another one, the same fact might have been true for some reason.
“P is true for no reason” means “all proofs of P have zero probability of being found”.
I wouldn’t use the automata proof. It is technically nice but it hides the intuition why the theorem is correc, and students intuitively understanding the reason why a statement is correct is very important for me.
I prefer using students programming skills and experience rather than their knowledge about automata theory.
Dear Dick/Ken,
Scott Aaronson’s recent blog post and preprint on Busy Beavers prompted me to go back and look at some of the work I did in the late 1980s when I was trying to understand Cook’s Theorem. I had posted a link to that work above but the site where it was has fallen off the live web so here’s the new improved edition —
🙞 Differential Analytic Turing Automata
Most folks here may find it quicker to skip to Part 2 and refer to Part 1 only as needed.
Regards,
Jon