A Negative Impossibility Theorem
A positive result on clustering

Ravi Kannan is a long-time friend, a brilliant theorist, and a wonderful speaker. He has won numerous awards, including the Fulkerson Prize and the Knuth Prize, for his ground-breaking research.
Today I wish to talk about a recent presentation that Ravi gave at Tech on clustering, which contained a negative impossibility theorem.
The theorem is from his book with John Hopcroft on algorithms for this century. This is a novel work that focuses on data not algorithms, is a labor of over five years, and may become the algorithm book. I have only had a short chance to look at the book, which is available on-line, but it looks exciting. Here is a quote from their own introduction that may help explain their unique view:
[W]e have written this book to cover the theory likely to be useful in the next 40 years, just as automata theory and related topics gave students an advantage in the last 40 years. One of the major changes is the switch from discrete mathematics to more of an emphasis on probability and statistics. Some topics that have become important are high-dimensional data, large random graphs, singular-value decomposition along with other topics covered in this book.
See their actual book for details.
Not Not
I cannot resist using a double negative in the title of this discussion. I should avoid that, but oh well. Of course a double negative is when we use two negations within the same sentence. In English they cancel out, but such sentences are considered poor style. Our friends at Wikipedia name Persian, Portuguese, Russian, Spanish, and Ukrainian as languages in which the double negative amplifies the negative content.
French is an intermediate case, and English has flipped from negation being additive to multiplicative. Wikipedia gives these examples from Geoffrey Chaucer’s Canterbury Tales:
About the Friar, he writes “Ther nas no man no wher so vertuous” (“There never was no man nowhere so virtuous”).
About the Knight, “He nevere yet no vileynye ne sayde / In all his lyf unto no maner wight” (“He never yet no vileness didn’t say / In all his life to no manner of man”).
Since we are having some fun let me quote an old joke:
A linguistics professor was lecturing to his class one day. In English, he said, a double negative forms a positive. In some languages though, such as Russian, a double negative is still a negative.
However, he pointed out, there is no language wherein a double positive can form a negative.
A voice from the back of the room piped up, “Yeah, right.”
Languages are complex. So let’s move back to clustering and the safety of more precise mathematical issues.
Clustering
Just to be clear, leaving our jokes behind, I would like to define what we mean by clustering. Given a set of objects, clustering divides them into a set of disjoint groups so that elements in each group, called a cluster, are more similar to each other than to those in other clusters. Here is a simple example:

Clustering is used wherever there is data: we find clusters used in areas from science and engineering to policy making and politics. Unfortunately clustering itself is a hard area, because there does not seem to be one precise general definition of what a good clustering is. A consequence of this is there are many algorithms for clustering. Many. Wikipedia points out that there are over 100 clustering algorithms that have been published. This could be a low estimate.
An interesting idea might be to try and cluster the clustering algorithms to see
Clustering Is Impossible
Jon Kleinberg is famous for many things, but one is his pretty result on clustering. In the spirit of Kenneth Arrow’s impossibility theorem on good voting systems, Jon has proved that a reasonable clustering system is impossible.
Following Arrow, Jon states three simple axioms, and then shows that there is no clustering method that satisfies the axioms. Of course people run clustering algorithms every day, just as people make decisions via voting all the time, so one must take such negative results with some care. Indeed one of my recurrent points is that we must be very careful how we interpret negative results. See these discussions for some further thoughts.
Let’s turn to look at Jon’s theorem. He assumes that there are a set of 

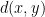




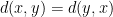

Nothing surprising, nothing dangerous, nothing up his sleeve.
Then a clustering method is a function that assigns to any such set with its distance function a partition into clusters. Of course so far this is all easy: just assign everything to the same cluster. That works. But we must have some properties that we insist that the clustering method satisfy. The hope is that the properties, we will call axioms, restrict the method to be “reasonable.”
Scale Invariance: This says that replacing the distance 

This seems very reasonable: put another way, you can measure distance in feet or in meters—the resulting clustering will not change. Who can argue with this?
Richness: This says that any partition of
Again this seems reasonable. Given the points and a partition, since there is no structure on the points, there should be a metric that yields any partition we like. No? Seems safe, and again who can argue with this?
The final axiom is:
Monotonicity: This says when we shrink distances between points inside a cluster and expand distances between points in different clusters, we get the same result.
See Jon’s paper for a formal definition, and do note that he calls it “consistency.” I think it is more a monotone type property. Again it seems unassailable. Yet.
Theorem:
There is no clustering method that satisfies scale invariance, richness, and monotonicity.
Clustering Is Possible
Enter John and Ravi. They show that Kleinberg’s pretty negative theorem on clustering can be dodged, provided one is willing to change things a bit.
Let’s look at their theorem. For starters they assume that the points
They use the same two axioms that were used before: scale invariance and monotonicity. They replace Jon’s axiom of richness by the following:
Richness II: For any set 


I by the way do not like using
With this modest alteration, they can now prove:
Theorem:
There is a clustering method that satisfies scale invariance, richness II, and monotonicity.
Thus after a change of no little reasonableness, good clustering is no longer impossible. In particular, this constitutes a proof that it is not possible to prove an impossibility result for clustering under this definition. Well to put it more positively, their proof is an algorithm. I will let the details serve as an advertisement for their book.
Open Problems
I hope you did not dislike this discussion too much. What other algorithms satisfy Richness II?


Run-on italics and end of post. (No need to include this comment.)
According to various sources – one here http://opinionator.blogs.nytimes.com/2010/02/14/the-enemy-of-my-enemy/?_r=0 – the “yeah, right” joke is due to Columbia philosopher Sidney Morgenbesser.
But does the “monotonicity” axiom make sense? Explaining myself would be easy if I could draw a diagram. Let me try anyway:
Let’s say your clustering algorithm gives a partition of the points into two discs. Then shrink and move of the discs away, while diving the points in one disc into two much smaller discs within the original one, clearly separated.
By monotonicity we should still get the same result, but three clusters is arguably better in this case.
That seems like a good point. (And here I thought the “richness” axiom was obviously the weak link.) Somehow this feels like the issue that a connected projection may not imply connected original image sets.
This is discussed in Kleinberg’s paper. If you give up this strong monotonicity for something one-sided (i.e., shrink-and-spread gives a refinement of the partition, instead of the same partition) then it is not hard to come up with clustering algorithms satisfying all three.
Here’s a trivial way of proving Kleinberg’s theorem:
Start with a configuration which clusters all points individually (which exists by the range condition). Now, up to scaling, you can create any point configuration you like, by spreading points apart by different amounts. By monotonicity you always get the same partition. Thus if your clustering function is monotone and scale-invariant, and if the range includes the complete partitition, then the range only includes the complete partition.
Neither monotonicity nor scale invariance are natural properties. For monotonicity Petter gives an example where two clusters become under any natural definition of clustering three. It is also possible to create two clusters where upon shrinking a point in one cluster moves to the other under any intuitive definition of clustering.
As for scale invariance, consider a cloud of dots with average distance a million miles away. Do they form a cluster? If they are stars they most definitely do, if they are atoms they most definitely don’t. To have a meaningful definition of cluster one needs to have a scale of the general magnitude of the interaction forces.
What Petter wrote, my thoughts exactly. Monotonicity needs to say something like that a point that is clustered does not exchange clusters, if point x was in cluster K, monotonicity says either point x remains in cluster K, or moves to a new cluster M, where M is a proper subset of K.
Another version is:
Note: the above “yeah++”-negation story is commonly attributed to the philosopher Sidney Morgenbesser, who was famous for many sayings, including Morgenbesser’s (new to me) lament when dying of Lou Geherig’s disease:
Um.
Hierarchical (versus “ordinary”) clustering can be done functorially/naturally, as shown by Carlsson and Mémoli. This sidesteps the Kleinberg theorem, and it can be (i.e., I have written notes in which it is) shown how to obtain a “functorial cluster embedding” nonlinear dimensionality reduction scheme as a result.
Regarding the number of published clustering algorithms, I estimate that in bio-informatics alone the number ranks in the hundreds. Similarly in the field of ‘social networks’. The total number must rank well into the thousands. 10,000 is a nice number and apparently a Chinese way of indicating a very large undefined number. Some maxim should be coined such as ‘if you don’t know what to do invent another clustering algorithm’, or ‘there’s lies, damned lies, statistics, and then there is cluster analysis’. It is a woefully underspecified problem, and hence it is always possible to demonstrate that one algorithm is better than another.
Yeah, the “genius undergraduates” are all going to figure out n-dimensional geometry, probability and statistics without having learnt any discrete (or continuous) mathematics.
What are these people smoking?