A problem about this forgotten complexity measure

Erik Winfree is one of the leaders in DNA computation, especially the theory of self-assembly using DNA. He won a MacArthur Fellowship in 2000, among many other awards for his terrific work. With Paul Rothemund he wrote a STOC 2000 paper titled “The Program-Size Complexity of Self-Assembled Squares,” work that contributed to their sharing the 2006 Richard Feynman Prize in Nanotechnology.
Today Ken and I want to talk about program size: about how many instructions are needed to compute something.
A DNA self-assembly system consists of a set of tile types, rules of assembly, and theorems of the form:
The number of tile types to create  is at most …
is at most …
The rationale to reduce tile types is simple: making duplicates of tiles is like printing, its cheap; but making many types of tiles is expensive. Each tile type requires a separate printing. So there is a natural imperative to reduce the number of tile types.
Hence a major goal of their research, using their terminology, is to reduce the “program complexity.” Thus there are parts of computer science theory where program size is important, but this area uses a non-standard notion that may say nothing about programs for conventional computers, which are the kind we want to study.
If you are interested, consider going to the next DNA Conference which was started by one of us, Dick, years ago. They are now on the twenty-first edition.
Let’s look at program size of machines not tile systems, since it came up recently in some thoughts Ken and I had on  . We do think about that question sometimes…
. We do think about that question sometimes…
Size of Code, Old and New
In the real world the size of a program is probably much more important than the time it takes or the amount of memory it requires. The size of code directly correlates with the cost of writing the program and maintaining it, with its number of bugs, and with its security issues. Big program are usually expensive in all ways. If we are creating the next great app that will make us all a fortune, we want the program to be a manageable size.
Yet complexity theory—for the most part—is focused almost entirely on the time a program takes or the space it uses. Not on its size. Hence we study time classes like  and space classes like
and space classes like  , logspace. And we prove theorems like hierarchy theorems. But not many theorems say anything about the size of a program. In one of the first posts on this blog, I posed this challenge:
, logspace. And we prove theorems like hierarchy theorems. But not many theorems say anything about the size of a program. In one of the first posts on this blog, I posed this challenge:
Prove there is no algorithm for  that runs in polynomial-time and can be written down on a single piece of paper. You can make the paper 8.5 by 11, if you wish. The writing has to be normal size. No tricks.
that runs in polynomial-time and can be written down on a single piece of paper. You can make the paper 8.5 by 11, if you wish. The writing has to be normal size. No tricks.
I went on to say that while “conventional wisdom” is confident in 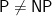 , so that no such program exists, yet I find it shocking that even this one-page challenge appears to be hopeless.
, so that no such program exists, yet I find it shocking that even this one-page challenge appears to be hopeless.
Well perhaps we can prove it equivalent after all, in the course of raising two questions. The first is about program size overall, and the second about the size of “new code” that needs to be written to solve a new problem, versus using already-written routines. To further our-real-world analogy, the latter have presumably already been debugged, and no one has to pay for writing them again.
Let’s look at the main obstacle and then the two questions.
An Obstacle?
Here is the source of our questions that we have recently thought about. Imagine, try to imagine if you can, that . This implies that every nondeterministic Turing Machine (NTM) that runs in linear time can be simulated by a deterministic TM (DTM) that runs in time  for some constant
for some constant  . The constant is absolute, but it can be small or large or astronomical. Thus one reason that could still imply nothing about practical computing is that could be the obstacle. Even a modest size
. The constant is absolute, but it can be small or large or astronomical. Thus one reason that could still imply nothing about practical computing is that could be the obstacle. Even a modest size  would render many applications useless.
would render many applications useless.
This is nothing new—we have pondered before that could be huge. And have postulated that one reason that none have found such a deterministic algorithm is that most tools in algorithm design are not set up to create algorithms that have running times of the form

Dynamic programming, divide-and-conquer, clever data structures, random sampling, linear programming, semi-definite programming, and others do not yield such galactic running times.
Ken and I wonder if the obstacle could be not that is large, but that the program size hidden away in the statement

has a blowup. Suppose that  . That would sound great—too good to be true. But it could still be useless. What if given an NTM program
. That would sound great—too good to be true. But it could still be useless. What if given an NTM program  that runs in linear time, the corresponding DTM program
that runs in linear time, the corresponding DTM program  that runs in time is itself huge? The fact that the program is deterministic and runs fast is really of no value if the program is exponentially larger than . If this is the case, then even though the running time is small, the program is of no value.
that runs in time is itself huge? The fact that the program is deterministic and runs fast is really of no value if the program is exponentially larger than . If this is the case, then even though the running time is small, the program is of no value.
This is the obstacle that we are interested in. Our response will involve universal simulators, which can be small, even tiny. We will first wrap one inside a famous old construction by Leonid Levin, and then write a little more “new code.” But first, what questions might a complexity theorist ask about program size?
Two Simple Questions
For both questions, our general task will be taking a nondeterministic program of size  that runs in some nondeterministic time
that runs in some nondeterministic time 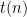 , and simulating it by a deterministic program of size
, and simulating it by a deterministic program of size 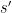 in time
in time  that is at most polynomially slower:
that is at most polynomially slower:  . It’s enough to suppose is linear, so the goal is
. It’s enough to suppose is linear, so the goal is  . We won’t care if is huge, so long as it is fixed and avoids being huge. Our questions are:
. We won’t care if is huge, so long as it is fixed and avoids being huge. Our questions are:
-
Could it be that any polynomial-time deterministic program must be exponentially bigger, that is
 ?
?
-
Can we arrange that
 , or even
, or even  , where the constant in the
, where the constant in the  is not only independent of (of course), but also small in an absolute sense?
is not only independent of (of course), but also small in an absolute sense?
Of course if these questions are generally moot. But if , could the reason for the equality not being practical be that the program blows up in size, not that the running time blows up? Put another way, could we have but 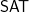 requires a program so large that it cannot ever be used? Note, this says nothing about the running time of the algorithm.
requires a program so large that it cannot ever be used? Note, this says nothing about the running time of the algorithm.
The short answer to the first question is no. This is because of reducibility and completeness for  . The code for the reduction from the language of to is linear in the size of . Call this code
. The code for the reduction from the language of to is linear in the size of . Call this code  . By there is a fixed deterministic polynomial-time program
. By there is a fixed deterministic polynomial-time program  for . The program that takes an input
for . The program that takes an input  and outputs
and outputs  runs in poly-time and has size . Moreover itself can be viewed as a fixed piece of code that takes the code of as a parameter, so the size can be regarded as
runs in poly-time and has size . Moreover itself can be viewed as a fixed piece of code that takes the code of as a parameter, so the size can be regarded as  or even just
or even just  in terms of “new code.”
in terms of “new code.”
However, the ‘O’ here includes the unknown size of the possibly-huge program . Hence this doesn’t fully answer the second question. That’s our point: can we do better?
The Idea
The basic idea, Levin’s “universal search,” is well known, and we covered one aspect of it here. We have not seen it addressed regarding program size, however.
Levin’s universal machine  accepts a Boolean formula
accepts a Boolean formula  only when it has found a satisfying assignment. Call this “verified acceptance.” It means that can possibly err only by rejecting a that is satisfiable after all. If
only when it has found a satisfying assignment. Call this “verified acceptance.” It means that can possibly err only by rejecting a that is satisfiable after all. If 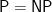 is true, then Levin’s code—which is known and small—will run in polynomial time, and accept except for finitely many errors.
is true, then Levin’s code—which is known and small—will run in polynomial time, and accept except for finitely many errors.
What does on a formula of size  is first spend steps trying to prove that the first yea-many small polynomial-time programs don’t recognize with verified acceptance. Let
is first spend steps trying to prove that the first yea-many small polynomial-time programs don’t recognize with verified acceptance. Let 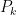 be the least program that does not fail this test. then runs
be the least program that does not fail this test. then runs  . If it gives a satisfying assignment, accepts ; else rejects. Then the code
. If it gives a satisfying assignment, accepts ; else rejects. Then the code  has size with “new code” where the constant in the is small and known, not huge.
has size with “new code” where the constant in the is small and known, not huge.
If , then some runs in polynomial time  , and (by the self-reducibility of ) recognizes with verified acceptance. Let
, and (by the self-reducibility of ) recognizes with verified acceptance. Let  be least for this. Then each of the machines
be least for this. Then each of the machines  makes some mistake, and some finite time
makes some mistake, and some finite time 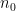 suffices for to cross off each one. Hence whenever
suffices for to cross off each one. Hence whenever  ,
,  simulates and gives the same answer in basically the same time, which becomes the overall polynomial runtime of . This carries over to runtime
simulates and gives the same answer in basically the same time, which becomes the overall polynomial runtime of . This carries over to runtime  for our code on of length
for our code on of length  .
.
The issue is, what happens when  ? Our code may err. We could “patch” it by adjoining a lookup table for the finitely many errors. But this table becomes part of the program size and might be huge. Moreover a given table could be buggy—remember that the famous Pentium bug of 20 years ago came from a few bad lookup-table entries.
? Our code may err. We could “patch” it by adjoining a lookup table for the finitely many errors. But this table becomes part of the program size and might be huge. Moreover a given table could be buggy—remember that the famous Pentium bug of 20 years ago came from a few bad lookup-table entries.
Patchless Assembly?
Levin originally stated his for factoring rather than . The point is that the language

belongs to  , and so can be recognized with verified rejection as well as verified acceptance. Then with reference to the above description of in general, rejects only if outputs a verified rejection. If gives no verified answer, then takes as much time as it needs to get the correct answer. This still settles down to polynomial time for .
, and so can be recognized with verified rejection as well as verified acceptance. Then with reference to the above description of in general, rejects only if outputs a verified rejection. If gives no verified answer, then takes as much time as it needs to get the correct answer. This still settles down to polynomial time for .
Thus it is not possible to have factoring in  but all polynomial-time programs for it are huge. To be sure, the running time can be huge—indeed itself may be huge and its size gets reflected in concrete running times—but the code for itself is small. And it is all known code which can be already debugged.
but all polynomial-time programs for it are huge. To be sure, the running time can be huge—indeed itself may be huge and its size gets reflected in concrete running times—but the code for itself is small. And it is all known code which can be already debugged.
We could try to do the same for by having solve exhaustively if fails to find a satisfying assignment. The problem then becomes not knowing when to stop and “trust” when in fact the first good one is found. The nub is whether we can use the assumption of to “bootstrap” the verification of succinct proofs of unsatisfiability. The mere existence of succinct proofs, however, that are verifiable without the assumption implies  .
.
Can we make the short code simulating perfect, without patches? We like the metaphor of as interacting and adapting in an environment of short programs, which it “assembles” into its own code before finding the one that works best.
We are not bothered about the conversion time being exponential in the size of the that is ultimately selected. After all, compared to the short timespan of recorded human history, the time it has taken us to evolve feels “exponential.”
Open Problems
Can we write code today, on one sheet of paper, that accepts exactly and runs in deterministic polynomial time if ?
Incidentally Ken fit much of a 3-tape Turing machine that does universal simulation of assembly programs onto one sheet for Buffalo’s theory courses.

Like this:
Like Loading...
Related




I would guess that one page is vastly larger than the provable Kolmogorov complexity limit for ZFC. That is, it is probably impossible to prove that *anything* requires more than a page (maybe even more than a couple hundred bytes?) to represent.
This reminds me of one of my favorite algorithms, Hutter’s algorithm (http://www.hutter1.net/ai/pfastprg.htm), which at first glance appears to answer your one-page SAT challenge in the negative. (Actually, it doesn’t.) Hutter’s idea was to extend Levin’s universal search so that rather than blindly running an exponential (in program size) number of programs until one is verified to work, instead the algorithm blindly tests an exponential (in proof size) number of proofs to find a fast algorithm that must work, and spends most of its time running that algorithm. It’s a bit more subtle than that, but the bottom line is that if there is a *provably* polynomial time algorithm for SAT, Hutter’s short and simple algorithm is also polynomial time for SAT — and its asymptotic slowdown is less than a factor of 5. Contrast that to Levin’s universal search, for which the multiplicative slowdown factor is exponential in the program size. Gargantuan slowdown is not to be avoided though: Hutter’s algorithm just moves it to the additive constant in the upper bound.
The trouble is that you can’t prove that Hutter’s algorithm is correct, because whatever sufficiently powerful formal system you choose for your proofs, you can’t prove that to be correct.
Nonetheless, it’s one of my favorite algorithms.
Why do you think that the explicit reference to a formal system is a drawback? For the purpose of such an algorithm, one would probably use a formal system equi-consistent to PA or some type theory. PA and most practically useful type theories are weaker than ZFC, so proving the correctness of the corresponding instantiation of Hutter’s algorithm in ZFC should be no problem. Proving an independent runtime bound for Hutter’s algorithm on the other hand…
If you had a fast SAT solver, you could use it to improve the efficiency of “Algorithm A” in Hutter’s algorithm, which uses an appropriately scheduled exponential search for the SAT instead. This could reduce the constant offset in the runtime up to a factor exponential in the length of the shortest proof.
Maybe I’m misunderstanding, but couldn’t you just tell the universal search routine to spend “constant” time (say) 10^(10^10) verifying each program and using the first one which passes? (Then I think the only issue for code size would be if the constant required is so large that it cannot be described succinctly, e.g., far beyond recursive Ackermann and into “busy beaver”-type constants.)
We expect our programs to have reasonable probability of being at the same time manageable, fast and easy to find. When we can’t find them, we then look for a proof of non-existence… which must also have reasonable probability of being of manageable size, understandable and not too hard to find.
And the story doesn’t stop there, because in case of failure we may also look for a proof that none of the above is possible… which proof will in turn be subject to the same feasibility requirements – and so on, ad infinitum…
In my opinion, P=?NP is best treated by philosophy. Of two things: either NP-complete problems are unfeasible and a reasonably simple proof of this will be found someday – I call it the Hilbert viewpoint – or NP-complete problems are easy but it’s their proof which is unfeasible – I call it the Gödel perspective.
The disturbing novelty in complexity theory is that none of both viewpoints is more likely to be true the other one.
Let’s formalize the idea that proving P≠NP is as hard as solving an NP-complete problem in polynomial time. Given a problem P, is there a Curry-Howard isomorphism Ψ that transforms every proof that P has no algorithm of time-complexity C, into an algorithm of time-complexity C for some polynomial reduction of the problem P? If so, then Ψ would transform every proof of P≠P into an algorithm that proves P=NP – and P≠NP would thus be proved undecidable.
I vaguely remember that there was a reason why Levin’s “universal search” can’t be patched up today, i.e. without knowing n0. Or perhaps it was just a reason why this would be non-trivial, not why it would imply knowledge of n0. Of course, we can guess at the correct program, but encoding some arbitrarily huge n0 in terms of the Ackerman function, but that’s not how the open question is meant.
This has been in the wikipedia for a long time:
http://en.wikipedia.org/wiki/P_vs_NP#Polynomial-time_algorithms
It’s one-sided only, similar issue to our post.
Not sure if it applies directly, but if you place a bound on the number of variables n, for SAT, you could build a program that is just one giant lookup for all the precomputed answers. You could find a way to insert those answers into the code. There are an infinite number of input strings for any number of variables but those map to a finite number of solutions, most likely in P (indexes and hashing would help). In that way, you could create a machine that would run in P, with exp code size, but only for a fixed n or less. From this perspective, it is easy to see that n would be dependant on our underlying technical progress (memory and disk) and that no general solution of this nature could ever work, neither would compression since the usage is infinite if n is infinite.
Paul.
Transport theory broadly conceived — to include momentum as a conserved/transported quantity, such that transport theory encompasses (e.g.) Navier-Stokes dynamics — is particularly well-suited to the discovery of small-size/complex output simulation algorithms, as evidenced by the burgeoning creativity of the computational discipline of discrete simulation of fluid dynamics (DSFD).
A newbie question. If instead we pose the problem as follows:
Is there an algorithm for {\mathsf{X}} (assuming {\mathsf{X}} is in NP) that runs in polynomial-time and can be written down on K pieces of paper.
Is this problem in NP?