A New Provable Factoring Algorithm
Factoring, factoring, the whole day through, keeps on my mind—apologies to Hoagy Carmichael and Stuart Gorrell

|
|
Waterloo Mathematics source |
Michael Rubinstein is an expert on number theory, who is on the faculty of the University of Waterloo. He is one of the organizers of a 61
Today Ken and I wish to discuss a paper of his on one of my favorite problems: integer factoring.
The paper appears in the 2013 volume of the electronic journal INTEGERS, one of whose sponsors is the University of West Georgia. It is titled, “The distribution of solutions to 

Theorem 1 For any
, there is a deterministic factoring algorithm that runs in
time.
The “

The Factoring Divide
Factoring algorithms partition into two types: unprovable and provable. The unprovable algorithm usually use randomness and/or rely for their correctness on unproved hypotheses, yet are observed to be the fastest in practice for numbers of substantial size. The provable algorithms are usually deterministic, but their key feature is that their correctness is unconditional.
For those trying to factor numbers, to break codes for example, they use the fastest unprovable algorithms such as the general number field sieve (GNFS). The cool part of factoring is that one can always check the result of any algorithm quickly, so anytime an unprovable algorithm fails, it fails in a visible manner.
Why care then about slower algorithms that are provable? Indeed. The answer is that we would like to know the best provable algorithm for every problem, and that includes factoring. We are also interested in these algorithms because they often use clever tricks that might be useable elsewhere in computational number theory. But for factoring there is a special reason that is sometimes hidden by the notation. The GNFS has postulated runtime
![\displaystyle L_N[1/3,c] = \exp((c + o(1))(\ln N)^{1/3}(\ln\ln N)^{2/3})](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++L_N%5B1%2F3%2Cc%5D+%3D+%5Cexp%28%28c+%2B+o%281%29%29%28%5Cln+N%29%5E%7B1%2F3%7D%28%5Cln%5Cln+N%29%5E%7B2%2F3%7D%29+&bg=ffffff&fg=000000&s=0&c=20201002)
where 






Nobody knows a deterministic factoring algorithm that beats properly exponential time.
The unprovable algorithms taunt and tease us, because they hold out the promise of being able to beat exponential time, but nobody knows how to prove it. Indeed, as Rubinstein remarks in his intro, each “teaser” is a conceptual child of one of the exponential algorithms. A reason to care about his new algorithm is its potential to be a new way to attack factoring, even though it currently loses to the best known provable methods. These are all slight variations of the Pollard-Strassen method, all running in 

The New Factoring Algorithm
Most factoring algorithms—even Peter Shor’s quantum algorithm—use the idea of choosing a number 



In its outermost structure, it uses this fact: Suppose 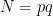





with 
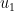
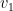






so

Now an issue is that the values 



The increments 


Using 



![{[a] \times [a]}](https://s0.wp.com/latex.php?latex=%7B%5Ba%5D+%5Ctimes+%5Ba%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
A Related Question
I found this work interesting not just because it is a new approach to factoring. I have tried in the past to prove the following type of result: Is there an asymmetric cryptosystem that is breakable if and only if factoring can be done in polynomial time?
I want to replace systems like AES with ones that uses the hardness of factoring for their security. Systems like AES rely on intuition and experimental testing for their security—there is not even a conditional proof that they are secure.
My goal is really trivial. Any public-key system can be viewed as an asymmetric system. But what I want is that the encryption and decryption should be very fast. This is one of the reasons that modern systems use private-key systems to create symmetric keys: performance. Using public-key systems for all messages is too slow.
My idea is not far in spirit from what Rubinstein does in his factoring algorithm. This is what struck me when I first read his paper. His algorithm is slow because it has no idea which “box” to look at. Can we share some secret that would allow
Open Problems
Can we extend Rubinstein’s algorithm to break the 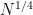
[fixed sentence about private-key/symmetric]


Sharing a secret that would allow {N} to be factored faster seems pretty close to the problem of creating a backdoor in an asymmetric encryption system. It isn’t quite the same problem because a backdoor can be very specialized (only one instance is needed), while you want an efficient backdoor with very many instances that can be created relatively quickly. I don’t know if such an animal exists, but it might be a productive direction to look for ideas.
In the third paragraph from the end you wrote asymmetric, but it seems you mean symmetric (I.e. private-key)
He also shows a subexponential result in his paper?
If you want efficient for symmetric-key yet provable, maybe lattices are the way to go?
Unrelated to factoring, but this may be of interest: “The mate-in-n problem of infinite chess is decidable” http://arxiv.org/abs/1201.5597
Indeed, thanks!
I think it’s a bit expansive to suggest block ciphers don’t have any hardness assumptions. Their difficulty relates to assumed difficulty of inverting finite group and field operations, and replacing a block cipher such as AES with a cipher that depends on the implicit hardness of factoring strikes me as counterproductive, especially since we don’t even know if factoring is hard. My intuition places more confidence in the difficulty of breaking established block ciphers than the hardness of factoring.
It may be appropriate for a protocol that uses a public key infrastructure that utilizes factoring as the hardness assumption for key exchange, where if factoring is broken the key is in the clear anyways, but for systems security we should have multiple independent hardness assumptions, so that if one falls (like factoring, or discrete log) the house wont fall down; unless some day we manage to make a provably secure public key infrastructure to replace them all.
I don’t think any cryptosystem has been proven to be as hard as factoring, but I understand that when working with elliptic curves, breaking ECDH encryption has been proven to be equivalent to solving ECDLP.
Obviously solving DLP would make factoring easy, so any cryptosystem which is provably as hard as DLP is provably at least as hard as factoring.
@m50d, wouldn’t the Rabin cryptosystem (https://en.wikipedia.org/wiki/Rabin_cryptosystem) satisfy the requirement?
“[T]he Rabin cryptosystem has the advantage that the problem on which it relies has been proved to be as hard as integer factorization […]”
I think that the Rabin cryptosystem was based on factoring but not still proven ‘semantically secure’ as done later in the Goldwasser and Micali’s seminal paper.
Am I right?
There is also a provable CCA-secure public-key encryption system from factoring of Dennis Hofheinz, Eike Kiltz, Victor Shoup, published at Eurocrypt 2009.
I do not want to be optimistic, and of cause I made some mistakes 🙂 Just seems that p-adic numbers emerging in the problem. https://mkatkov.wordpress.com/2016/06/01/semiprime-factorization-and-modular-arithmetics/
I think we can make a stronger statement with fewer words for free: there is a deterministic algorithm for factoring that runs in time N^(1/3 + o(1)). Levin’s universal search can simulate all the O(N^(1/3 + eps)) algorithms since factoring is in NP and co-NP.