Cook’s Class Contains Pi
Cook’s class and the BBP algorithm for Pi

Steve Cook won the Turing Award for his famous paper on SAT that started the P=NP problem. He has done many other wonderful things in many areas of computational complexity, I especially love his work on proof systms. I am proud that my Cook number is 
Cook is also famous for having a complexity class named after him: 
When I was an assistant professor at Yale University, David Dobkin and I would often argue about what is better having 

Computing 
Computing

These and other remarkable formulas are the basis of modern computations of
The problem with these fast algorithms is not speed, they run in almost linear in the number of bits that you want of
In 1995, David Bailey, Peter Borwein, Simon Plouffe discovered a beautiful algorithm that changed all this. Their algorithm–called BBP–computes the 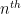

From the viewpoint of complexity theory they showed that the problem of computing the 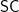
The BBP Algorithm
There are two things about the BBP algorithm that I find intriguing and want to share with you:
- The algorithm uses the exponential trick that we sometimes take for granted as computer scientists;
- The algorithm has a bug. It is not really an algorithm. Well it is almost an algorithm.
The first point is that the algorithm uses the following:
Lemma 1 The value of
modulo
can be computed in time polynomial in the number of bits in
.
This well known fact–to computer scientists–is of central importance to many areas. It is used in cryptography, in number theory, and elsewhere. It is interesting that they felt the need to explain the
exponential trick in some detail . For example, they not only give the detailed code of this trick, they give the following example:

“thus producing the result in only 5 multiplications, instead of the usual 16”. I would like to talk more about this important idea in a later post.
Let’s now turn to finally explaining how their algorithm works. Rather than compute the bits of 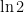

is a well known summation–to those who know such sums. Their idea is this: to compute the 





where 



since all the other terms are integers: we use that 





Thus, to find the 

Call the first sum 

The sum

for 

Clearly, this can be computed in polynomial time to 

They then have the factional part of 



A “small detail” what is the value of 



What About
The BBP method is the same for

Part of the exciting story of their algorithm is how they found this summation. It was not known to anyone, they had to go out and discover the summation. How they did this is a long story that I will talk about another day. They used guessing and a clever search method based on lattice algorithms.
Note, the structure of their summation is of the same type as that for

where 
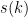
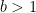

A Bug?
The beautiful algorithm of BBP does not actually work. The problem is simple. In a nutshell: what if the fractional part they get lies between 




The problem has to do with long runs of 

vs

how do you tell them apart if the run of
”There is a vanishingly small possibility that a particular computation targets a section that is subject to small round-off errors being carried for many digits (e.g. in base 10, a long string of zeros or string of 9’s within the constant) and that the error will propagate to the most significant digit, but being near this situation is obvious in the final value produced.”
Excuse me, this is nonsense. The statement “vanishingly small possibility” is a statement of probability theory. There is nothing random here at all. I agree that it seems that the problem may never arise in practice, but that is different. The last point of the quote is correct. If the value of the fractional part is very close to
Open Problems
The obvious open problem is fix BBP and make it a real algorithm. I have a strong belief that the following should hold:
“Theorem” 2 Computing the
The plan of a proof is to use their basic BBP method. However, when one detects a long run of

for integers 


I may write a post working out the details of this argument, or you can take a try and work it out.
Trackbacks
- Cantor’s Non-Diagonal Proof « Gödel’s Lost Letter and P=NP
- Making An Algorithm An Algorithm—BBP « Gödel’s Lost Letter and P=NP
- How Deep is Your Coloring? « Gödel’s Lost Letter and P=NP
- Transcendental Aspects of Turing Machines « Gödel’s Lost Letter and P=NP
- One Man’s Floor Is Another Man’s Ceiling « Gödel’s Lost Letter and P=NP
- An Old Galactic Result | Gödel's Lost Letter and P=NP
- The Other Pi Day | Gödel's Lost Letter and P=NP
- The Value of Pi | Gödel's Lost Letter and P=NP


There’s a typo in the Ramanujan series for 1/π : the numerator in the sum should be (4k)!(1103 + 26390k) , not (4k!)(1103 + 26390k) .
Thanks, will fix as soon as can…rjlipton (dick)
You should definitely take out your frustrations on the offending page by editing it!
From reading up about Irrationality Measure and from assuming that the authors of the paper knew about it, it seems you would need another ‘trick’ to prove theorem 2 in addition to any details, do you have one in mind?
Happy pi-boxing day!
It seems that bounding the length of the runs by a transcendence measure is not sufficient (at least not in the straightforward way).
Suppose that we want to find bit $n$, and the run of 1s goes from $n$ to $j$. Then the error is roughly $2^{-j}$, but $s$ has size roughly $2^n$. We therefore get that $cn > j$, which gives us linear space instead of the desired poly-logarithmic space.
I left out the details. What I think may be true is this:
Try the BBP on bit thru
bit thru 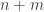 for large
for large  . Then, if all near
. Then, if all near  I think will get a contradiction with the measure. The point is that you do poly calls to their small space algorithm. Does that make sense?
I think will get a contradiction with the measure. The point is that you do poly calls to their small space algorithm. Does that make sense?
That makes a lot of sense. Suppose that the first bit we can definitively decide is bit k. The algorithm can only “fail” if we get 011111…110… or 100000…001…, so either way, x must occur before the end of the run. But once we know the value of a bit within the run, we know which type of run it was. So b_n=1-b_x. And by the above calculations, the run is at most linear in length.
I suppose I should be a bit more formal about x being in the run, but it just gets ugly to type. 🙂
Good post, your post could really help me in my work. Hopefully this will help increase my traffic more. Thanks for sharing.
I read your approach by checking m different bits. The problem that I originally saw is that you need m to be on the order of n, so you have to check pseudopolynomially many values, not polynomially many.
How do you get the nifty math mode in your comments?
BTW: It looks “Simonn” is comment spam
To get math mode in comments you must use latex. The “trick” is that you must type
BUT leave no space between the first $ and the latex phrase.
daveagp: How does this result in pseudopolynomially many calls?
jeremy: the “polynomial” in poly-time algorithm refers to polynomial in the size of the input, measured in bits. so an algorithm that takes only one integer, , as input, actually has input size
, as input, actually has input size  .
.
(e.g. you can add numbers two -bit numbers using
-bit numbers using  operations. the value of the numbers is around
operations. the value of the numbers is around  … what I mean by this example is that poly-time in the input size is the same as polylog-time in the input value, at least if the input to the algorithm is one integer)
… what I mean by this example is that poly-time in the input size is the same as polylog-time in the input value, at least if the input to the algorithm is one integer)
the proposed algorithm takes time proportional to the input value, which is not polynomial in the input size – this is typically called a pseudopolynomial time algorithm. (another example: factoring a number into primes can be done in pseudopolynomial time using the naive approach of trying all factors one at a time. more info lives at http://en.wikipedia.org/wiki/Pseudo-polynomial_time) it would not be practical to use it to find, say, the th bit of
th bit of  .
.
sorry, I should clarify the last sentence: the transcendence measure bound does not guarantee that, a priori, when you run the algorithm to compute the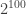 th bit of
th bit of  , you will get definitive bits in any reasonable amount of time.
, you will get definitive bits in any reasonable amount of time.
that having been said, in actually running the algorithm, the definitive bits may usually come up pretty early – transcendence measure only provides an upper bound, not a lower bound. if we were to assume somehow that pi’s bits were “random,” then it is “likely” that for all inputs up to , you do not need to check more than $O(X)$ bits. this might be what the sketchy wikipedia article was trying to say informally.
, you do not need to check more than $O(X)$ bits. this might be what the sketchy wikipedia article was trying to say informally.
I had assumed we were encoding in unary to begin with, since the BBP algorithm was already using O(n) time.
Aha – yup, you’re right, I was mistaken on that point. Also, I found in my reading of a certain wiki-like encyclopedia that there is a factor missing from the formula, which should be
factor missing from the formula, which should be

and found that
Herbrand isn’t the only person to have a universe named after him, as Alexander Grothendieck also does.
Cool. Did not know—what a great thing.
> Roughly, a long run of 1’s would violate the above inequality for pi.
Then you have solved a problem that was open for a long time and thought to be exceptionally hard, normality of pi base 2 (negatively). I really doubt it is that simple.
Hello.
What if, in a general theory of everything kind of way, some singular human conscious had used simple Yes(I should feel guilty) or No(I do not feel guilty) answers to answer every moral question that he could remember that had ever occurred in his life. In this way he could have become completely pure. He would have truly asked himself all the questions that could be asked of him. He would have emotionally evolved back to when he was a child.
What if he then assigned an ‘It doesn’t matter as life is only made to make mistakes’ label on every decision that he had analysed.
This would not make him God or the devil, but just very still and very exhausted. Anybody can do this but just for the purpose of this experiment lets say I have done this. Which I have.
There are no fears in me and if I died today I could deal with that because who can know me better than myself? Neither God or the Devil. I am consciously judging myself on ‘their’ level.
To make this work, despite my many faults, take ME as the ONLY universal constant. In this sense I have killed God and the Devil external to myself.The only place that they could exist is if I chose to believe they are internal.
This is obviously more a matter for a shrink more than a mathematician, but that would only be the case depending on what you believed the base operating system of the universe to be. Math / Physics / morals or some other concept.
As long I agreed to do NOTHING, to never move or think a thought, humanity would have something to peg all understanding on. Each person could send a moral choice and I would simply send back only one philosophy. ‘ LIFE IS ONLY FOR MAKING MISTAKES’.
People, for the purpose of this experiment could disbelief their belief system knowing they could go back to it at any time. It would give them an opportunity to unburden themselves to someone pure. A new Pandora’s box. Once everyone had finished I would simply format my drive and always leave adequate space for each individual to send any more thoughts that they thought were impure. People would then eventually end up with clear minds and have to be judged only on their physical efforts. Either good or bad. It would get rid of a lot of maybes which would speed lives along..
If we then assume that there are a finite(or at some point in the future, given a lot of hard work, there will be a finite amount) amount of topics that can be conceived of then we can realise that there will come to a time when we, as a people, will NOT have to work again.
Once we reach that point we will only have the option of doing the things we love or doing the things we hate as society will be completely catered for in every possible scenario. People will find their true path in life which will make them infinitely more happy, forever.
In this system there is no point in accounting for time in any context.
If we consider this to be The Grand Unified Theory then we can set the parameters as we please.
This will be our common goals for humanity. As before everyone would have their say. This could be a computer database that was completely updated in any given moment when a unique individual thought of a new idea / direction that may or may not have been thought before.
All that would be required is that every person on the planet have a mobile phone or access to the web and a self organising weighting algorithm biased on an initial set of parameters that someone has set to push the operation in a random direction.
As I’m speaking first I say we concentrate on GRAINE.
Genetics – Robotics – Artificial Intelligence – Nanotechnology and Zero Point Energy.
I have chosen these as I think the subjects will cross breed information(word of mouth first) at the present day optimum rate to get us to our finishing point, complete and finished mastery of all possible information.
Surely mastery of information in this way will lead us to the bottom of a fractal??? What if one end of the universes fractal was me??? What could we start to build with that concept???
As parameters, we can assume that we live only in 3 dimensions. We can place this box around The Milky Way galaxy as this gives us plenty of scope for all kinds of discoveries.
In this new system we can make time obsolete as it only making us contemplate our things that cannot be solved because up to now, no one has been willing to stand around for long enough. It has been holding us back.
All watches should be banned so that we find a natural rhythm with each other, those in our immediate area and then further afield.
An old clock watch in this system is should only be used when you think of an event that you need to go to. It is a compass, a modern day direction of thought.
A digital clock can be adapted to let you know where you are in relation to this new milky way boxed system.(x,y,z).
With these two types of clocks used in combination we can safely start taking small steps around the box by using the digital to see exactly where you are and then using the old watch to direct you as your thoughts come to you.
We can even build as many assign atomic clocks as are needed to individually track stars. Each and every star in the Milky Way galaxy.
I supposed a good idea would be to assume that I was inside the centre of the super-massive black hole at the centre of the galaxy. That would stop us from being so Earth centric.
We could even go as far as to say that we are each an individual star and that we project all our energies onto the super-massive black hole at the centre of the galaxy.
You can assume that I have stabilized the black hole into a non rotating perfect cube. 6 outputs /f aces in which we all see ‘the universe and earth, friends’ etc. This acts like a block hole mirror finish. Once you look it is very hard to look away from.
The 6 face cube should make the maths easier to run as you could construct the inner of the black hole with solid beams of condensed light(1 unit long) arranged into right angled triangles with set squares in for strength.
Some people would naturally say that if the universe is essentially unknowable as the more things we ‘discover’ the more things there are to combine with and therefore talk about. This is extremely fractal in both directions. There can be no true answers because there is no grounding point. Nothing for the people who are interested, to start building there own personal concepts, theories and designs on.
Is it possible that with just one man becoming conscious of a highly improbable possibility that all of universes fractals might collapse into one wave function that would answer all of humanities questions in a day? Could this be possible?
Answers to why we are here? What the point of life really is et al?
Is it possible that the insignificant possibility could become an escalating one that would at some point reach 100%???
Could it be at that point that the math would figure itself out so naturally that we would barely need to think about it. We would instantly understand Quantum theory and all.
Can anybody run the numbers on that probability?
50/50
Isoperimetric inequality & RE Turing Degree/ pi transcendence measure
Isoperimetric extremum : equilateral triangle and circle
Isoperimétric unit = sqare “like” a triangle / circle
“Vitruvian Man” 8/5 : (3,4,5) (4,1, sqr 17) 1!+…+5! = 1+…+17 = 153 R/ 0! = 1
(3,4,5) (5,4, sqr 41) 1+2+3+4 = 10
(17+5)/2 = 11
99*99 = 9801
33*33 = 1089
1089 + (3+4) * 2 = 1103 cunningham chaine 2n+1 1103 2207 (real gnomon)
1+ 153 * 2 * 5 = 1531 smalest cunningham chain 2n-1 (i gnomon)
1531 3061 6121 12241 24 481
1089 + (41 * 2 * 2 * 5) + 24 481 = 26 390
No symetry : smalest cunnigham chain 2n-1 4 iteration 1531
2n+1 2
RE Turing Degree
“long square” (3,4,5) 12 / (14/4) ^ 2 = 0,97959183… 2,05 % incompletness
RE Turing degree (E. Post)
pi transcendence measure ?
sqr p 2
e 2
pi 2 * 1,0204… smallest transcendant BBP like ?
\Displaystyle 1+\frac{1}{1\cdot 3} + \frac{1}{1\cdot 3\cdot 5} + \frac{1}{1\cdot 3\cdot 5\cdot 7} + \frac{1}{1\cdot 3\cdot 5\cdot 7\cdot 9} + \cdots + {{1\over 1 + {1\over 1 + {2\over 1 + {3\over 1 + {4\over 1 + {5\over 1 + \cdots }}}}}}} = \sqrt{\frac{e\cdot\pi}{2}}
If one non-trivial zero of zeta isn’t on the 1/2 real then one is false :
– pi is BBP like and satisfies a transcendence measure
– e isn’t BBP like but satisfies a transcendence measure
– 1531 is the smallest Cunningham chain 2nd kind (2x-1) and length 5 (4 iterations) and 2 is the smallest one fot ehe 1st kind (2x+1)
Quod Erat Demonstrandum
Max arithmetical reduction of the Lipton problem :
1+2+3+4 = 10 = 2 X 5 1!+2!+3!+4! = 33 = 16 + 17 (transcendence measure)
1+……+17 = 153 = 1!+…+5! = 12 * 10 + 33 (BBP like)
Then 1/2 zeta : (Separable extension = Galois cohomology)
Vitruve : (4,3,5) (16,1,17) (16,25,41)
5+17/2 = 11
1531 3061 6121 12241 24 481 Cunningham 2n-1
2 5 11 23 47 – 2n+1
99*99 = 9801 33*33 = 1089 4*99 = 396
1089 + 2*(3+4) = 1103
1089 + 2*41 *10 + 24 481 = 26390
Zéta archimedian spiral pi
Gamma log spiral e
Separable extension = Fermat’s spiral (Cubical parabola epsilon = +1 -1) :
2/3 4/5 16/17
(cf Sieve of Matiiassevitch)
– irrationality measure e = 2 (Borwein)
– Pi is BBP like and irrationality measure = or > 2 then pi is O(Log(|x|)) (Chee Yap)
– e¨i.pi = -1 (Euler)
– Fermat is true (Willes)
– 4/(3+5) = 1/2 (“Vitruvian man”)
Hypothesis :
1. Lamda Oracle = Arithmetic mean (3,4) / Quadratic Mean (3,4) = 0,9899494… ?
2. Incompletness (recursion) = 1 – Lambda = 1,00506… % ?
3. Irrationality measure Pi = 2 / Lambda = 2,020305… ?