On The Intersection of Finite Automata
Can we beat the classic emptiness test for the intersection of finite automata?

George Karakostas and Anastasios Viglas are two excellent theorists, who both have their PhD’s from the Princeton computer science department. I was the PhD advisor of Viglas, and later had the pleasure of working with both of them on several projects.
Today I want to talk about finite state automata, and an open question concerning them. The question is very annoying, since we have no idea how to improve a classic algorithm. This algorithm is decades old, but it is still the best known. There seems to be no hope to show that algorithm result is optimal, yet there also seems to be no idea how to beat it. Oh well, we have seen this before.
It was a great pleasure to work with George and Anastasios. I enjoyed our work together very much, and they have continued working together over the years—on a wide variety of topics.
I really do not have any really great stories about them, or even one of them. One story that does comes to mind is about steaks. George likes his steak cooked well done, as I do too. I know that is probably not the proper way to order a steak, but that is the way I like them. But, when George says “well-done” he means “well-done.” I always loved the way George would explain this to our server: They would ask George, “how would you like your steak cooked?” And George would say, “well done—actually burn it.” This usually caused some discussion with the server, and George had to be insistent that he really wanted it “burnt.” I like someone who is definite.
Let’s turn from steaks to finite automata, and to a question about them that is wide open.
Intersection of Finite State Automata
The power of deterministic finite state automata (FSA) is one of the great paradoxes, in my opinion, of computer science. FSA are just about the simplest possible computational device that you can imagine. They have finite storage, they read their input once, and they are deterministic—what could be simpler? FSA are closed under just about any operation; almost any questions concerning their behavior is easy to decide. They seem “trivial.”
On the other hand, FSA are more powerful than you might guess—this is the paradox. While FSA cannot even count, they can do magic. I have already pointed out that FSA play a major role in the modern analysis of hardware—BDD’s, they can be used to prove the decidability of complex logical theories—Presburger’s Arithmetic, and they are used everyday by millions to do searches. Every time you search for a pattern in a text string, especially when you use “don’t cares”, the search is done via FSA technology. Simple, yet powerful.
I want to raise a question about FSA that seems to be interesting, yet is unyielding to our attempts to understand it. In order to understand the question we first need some simple definitions. If 

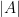
One of the classic results in the theory of FSA is this:
Theorem: If
and
are FSA’s, then there is an FSA with at most
states that accepts
.
The proof of this uses the classic cartesian product method: one creates a machine that has pairs of states, and simulates both 

Corollary: If
and decides whether or not
George, Anastasios, and I noticed that there is no reason to believe that this cannot be improved. I guess that is a double negative, what I mean is: let’s find an algorithm that solves the emptiness problem for 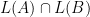

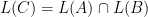
is approximately the product of the number of states of
Our Results
We worked hard on trying to beat the standard approach and could not improve on it. So eventually we wrote a paper that in the true spirit of theory, assumed that there was a faster than product algorithm for the intersection of FSA. Then, we looked at what the consequences would be of such an algorithm. Our main discovery was that if there existed faster methods for the intersection of automata, then cool things would happen to many long standing open problems.
You could of course take this two ways: you could use these results to say it is unlikely that any algorithm can beat the product algorithm, or you could use these results to say how wonderful a better algorithm would be. It’s your choice. I like to be positive, so I tend to hope that there is a faster algorithm.
Suppose that 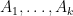


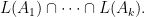
Call this the product emptiness problem (PEP). Note, if 
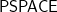
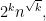
for example.
Here are a couple of results from our paper that should help give you a flavor of the power of assuming that PEP could be solved more efficiently, than the product algorithm. As usual please check out the paper for the details. All the results assume 
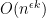

Theorem: If
, then there is an algorithm for the knapsack problem that runs in time
, for any
.
Theorem: If
, for any
I have discussed the following earlier.
Theorem: If
for any

A Sample Proof
None of the proofs of these theorems are too difficult, but the most complex is the last result. This result uses the block respecting method. Here is a sample proof that should demonstrate how 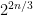
Let 
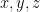

and neither 




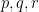
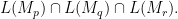
There are two cases. If there are no solutions, then

But, 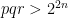

The above is a primality test. We make it into a factoring algorithm by adding a simple test: we insist that the first automata also test that
Open Problems
Can one solve the PEP in time faster than the product algorithm? Even for two automata this seems like a neat problem. I find it hard to believe that the best one can do is to build the product machine, and then solve the emptiness problem.
I do have one idea on a possible method to improve the PEP in the case of two automata. Suppose that 
This can be done by a non-deterministic pushdown automata that uses at most 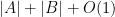


Isn’t the problem of non emptiness for the intersection of a fixed number of automata in NLOGSPACE? One guesses a word in the intersection and checks on the fly that it is accepted by all the automata, which only requires to remember one state for each automaton at any point?
On the emptiness of a pushdown automaton, the algorithm that comes to my mind is to construct an equivalent grammar of at worst cubic size and test it for emptiness in linear time.
An equivalent construction for the emptiness of $L(A)\cap L(B)$ would be to intersect $L(A)\cdot L(B)^R$ with the set of even palindromes on the same alphabet $\Sigma$, which can be described by a context-free grammar of size linear with $|\Sigma|$. But again the usual algorithm for the emptiness of the intersection of the language of a context-free grammar and a regular language is at worst cubic in the size of the automaton for the regular language.
Some more insights might be found in the inter-reductions between context-free parsing and boolean matrix multiplication (Valiant, JCSS 10, 1975, and Lee, JACM 49(1), 2002).
Another point could be that the pda is very special. It does only one turn. Perhaps that can help?
The point is to do it faster than n^k. You are right that is easy. But how easy?
I liked this post! I had no idea that people still did work with FSA’s anymore!
A question on the primality test. Is there a reason you chose three primes of length 2n/3, as opposed to other numbers of primes that multiply large enough?
Sure. Great point. Just wanted to make the point. By selecting more and smaller primes you would get even faster time bounds.
It’s nice to see people revisiting questions in automata theory. Automata theory used to be one of the core areas of theoretical computer science. In fact, the “A” in “SIGACT” used to abbreviate “Automata”. Over the last 15 years, however, the STOC/FOCS community lost interest in automata, and now the “A” in “SIGACT” abbreviates “Algorithms”. During this period, however, automata theory has become highly relevant to the theory and practice of computer-aided verification, as well as database theory. Some questions in automata theory, open since 1960, have been settled only this year!
A possible way to reach the expected solution is to let these two languages be mirrored languages, that is, L(A) = L(B), and LEARN the relations between them as memberships, such as, LITERAL(b) is the member of WORD(a), WORD(b) is the member of CLAUSE(a), and so on. Then it permits checking relations in kn time. The concept was introduced by Wang, Boolos, Parsons and others as iterative set theory.
This problem can be very nicely treated in the framework of parameterized complexity. First, it is not very difficult to give a parameterized reduction from k-Clique to k-PEP: one way to do this is to let the alphabet be the set of vertices, each FSA accepts words of length 2 times (k choose 2) describing the endpoints of the (k choose 2) edges, every FSA checks if the endpoints of each edge are really adjacent, and the i-th FSA checks if the k-1 edges incident to the i-th vertex of the clique all use the same vertex for the i-th vertex. This reduction shows that k-PEP is W[1]-hard and hence not fixed-parameter tractable (that is, no f(k)n^O(1) algorithm) unless FPT=W[1].
Second, we observe that this reduction transforms the parameter linearly (or more precisely, does not change it at all, since the number of FSA’s is exactly the size of the clique we are looking for). Thus a f(k)n^o(k) algorithm for k-PEP implies that there exists a f(k)n^o(k) algorithm for k-Clique. Now we can use the results of Chen et al. “Linear FPT reductions and computational lower bounds” (STOC 2004) saying that if there is a f(k)n^o(k) algorithm for k-Clique, then the Exponential Time Hypothesis fails: n-variable 3SAT can be solved in time 2^o(n).
Note that this is actually a stronger statement than what appears in your paper: not only ruling out the possibility of algorithms with running time n^o(k), but also algorithms with running time, say, 2^2^2^2^k n^o(k).
I find it quite interesting that your paper essentially invented the same line of reasoning as the Chen et al. paper to obtain tight lower bounds in the exponent.
Thanks. Two issues first the algorithms can be random, how does that work with the fixed viewpoint? Second, it still is possible that such algorithms exists…no?
Sorry, I was sloppy: by “ruling out the possibility” I meant “does not exist unless something unlikely happens”. So if algorithms with the given running time exist, then the Exponential Time Hypothesis fails. The same argument shows also that if there is a randomized algorithm with the given running time, then the randomized version of ETH fails: there is a randomized 2^{o(n)} time algorithm for n-variable 3SAT.
This is a really awesome comment! I guess that I somehow missed it back eight years ago. 🙂
Where can I find Dexter Kozen’s proof of PEP \in PSPACE-complete?
Got it. D. Kozen. Lower bounds for natural proof systems. In Proc. 18th Symp. on the Foundations of Computer Science, pages 254–266, 1977.
What is known about how the product construction compares to the complement of the union of complements construction?