Why Believe That P=NP Is Impossible?
A list of reasons for believing that P=NP is impossible

David Letterman is not a theorist, but is a famous entertainer. I do not watch his show—on too late, but I love to read his jokes in the Sunday New York Times. He is of course famous for his “lists” of the top ten reasons for
Today I plan to follow David and try to list the top reasons why people believe that P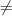
The list I have put together has many reasons: they range from solid theorems, to social, to analogies to other mathematical areas, to intuition. I have tried to be inclusive—if you have additional reasons please let me know.
One thing that is missing from my list is experimental evidence. A list for the Riemann Hypothesis might include the vast amount of numeric computation that has been done. Andrew Odlyzko has done extensive computation on checking that the zeroes of the zeta function lie on the half-line—no surprise yet. Unfortunately, we do not seem to have any computational evidence that we can collect for the P=NP question. It would be cool if that were possible.
It may be interesting to note, that numerical evidence in number theory, while often very useful, has on occasion been wrong. One famous example, concerns the sign of the error term in the Prime Number Theorem: It was noticed that 


is impossible. Here 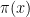


This would have been an interesting fact, but John Littlewood proved a wonderful theorem that showed that not only was 

Belief vs Proof
As scientists, especially theorists and mathematicians, what does it mean to believe X when there is no proof that X is true? I think that there are plausible reasons that you may or may not believe something like P
However, I think that listing potential reasons for believing an unproved statement X can help guide a field. As I posted earlier, if the theory field is really convinced that P=NP is impossible, then this conviction will be manifest itself in many ways: what is funded, what is published, and what is thought about.
While this is a reasonable use of a belief, there are some dangers. The main danger is that if the belief is wrong, then there can be negative consequences. If most believe that some unproved X is true, then:
- Few may work on disproving X, which could potentially delay the final resolution of the problem.
- The field may build an edifice that is deep and rich based on X, but the foundation is faulty. If many theorems of the form: “If X, then Y” are proved, then when X is finally disproved a great deal of hard work will become vacuous.
- Finally, even if X is true, by thinking about both X and its negation, the field may discover other nuggets that would otherwise have been missed.
Three Choices, Not Two
Before I present the list I want to be clear that in my mind there are three choices—actually there are many more as I have pointed out before, but let’s stick to three:
- P
NP: Let this mean that P is really equal to NP, that there is a practical polynomial time algorithm for SAT. Note, even this does not imply there are practical algorithms for all of NP, since the running time depends on the cost of the reduction to SAT.
- P
NP: Let this mean that there is a polynomial time algorithm for SAT, but the exponent is huge. Thus, as a theory result, P does equal NP, but there is no practical algorithm for SAT.
- P
As I pointed out in my previous post there are even other possibilities. But let’s keep things manageable and only use these three for today.
A “Why P
Here are some of the reasons that I have heard people voice for why they believe that P
- P
- P
- P
- P
- P
- P
- P
for some
. The brilliant work of Wolfgang Paul, Nick Pippenger, Endre Szemerédi and William Trotter shows that
, which is a far distance from proving that there is no
is impossible. That is nondeterminism does help for Turing Machines.
- P
-SAT can be solved in exponential time
. Rainer Schuler, Uwe Schöning,, Osamu Watanabe have a beautiful algorithm with a
upper bound, while the best is around
.
- P
- P
A Comment On The List
I do want to point out that the some of the list would change if we replace P
- P
- P
Open Problems
What are your major reasons for believing P
Some people would include observations like: no one has found an algorithm for P
Another reason mentioned sometimes is P

I would like to give a special thanks to Paul Beame, Jonathan Katz, and Michael Mitzenmacher for their kind help with this post. As always any errors are mine, and any good insights are theirs.
Finally, this is the 
Trackbacks
- Math World | Why Believe That P=NP Is Impossible? « Gödel's Lost Letter and P=NP
- Math World | Why Believe That P=NP Is Impossible? « Gödel's Lost Letter and P=NP
- A Problem With Proving Problems Are Hard « Gödel’s Lost Letter and P=NP
- Proving A Proof Is A Proof « Gödel’s Lost Letter and P=NP
- We Believe A Lot, But Can Prove Little « Gödel’s Lost Letter and P=NP
- P=NP: The origin of the believe. Part I. | Why do I believe that P=NP
- Giving Some Thanks Around the Globe « Gödel’s Lost Letter and P=NP
- Why Read the Heroes? « Pink Iguana
- Measures Are Better | Gödel's Lost Letter and P=NP
- Fourier Transforms of Boolean Functions : 1 | Inquiry Into Inquiry
- Fourier Transforms of Boolean Functions : 2 | Inquiry Into Inquiry


I don’t believe P=NP because I can construct instances of SAT that, if satisfiable would answer many open questions in discrete mathematics, and I can’t solve them in any reasonable time, even though they are relatively small instances.
I heard this statement many times. Are there actual scientific experiments of the following form: I took a “hard” problem and encoded it into 3-SAT. Then, I ran the best SAT solvers on the problem. After many months of running on a super fast server I got no solution.
I think that it is likely to be that you are correct, but the thought experiment is not the same as an experiment. Also the answer you get could depend tremendously on how you encode the problem, so that is another dimension that would have to be explored. Perhaps for the obvious encoding the solver does not work, while for a clever encoding it will.
Has anyone done such experiments?
People have said that if P=NP was really equal, then they could have an oracle that would solve any problem. They would code any question into a formal one and run the SAT oracle. This is a bit too simple. As I point out later on the problem could still be way too big for the solver to solve. But I have heard this claim. It was referenced in my last post.
My personal reason is that it is just very hard to accept that the non-deterministic exploration of exponential numbers of guesses in polynomial time is in some sense “useless”. Admittedly, the intuition is only strong for low exponent polynomials.
I think you said the main reason better than I did.
The problem of course is that there are many examples of surprises: algorithms that use some structure or trick or insight about their huge search space that allows them to “cheat”. To somehow avoid all the guesses and get to the solution without looking at all of the space.
Even as simple an algorithm as solving a linear system Ax=b is finding an object that lies in a huge search space. It does this by using the structure, of course, of linear systems. But if we did not know that we might be amazed that such a problem could be solved fast.
But again thanks for a great statement of the intuition behind believing P cannot equal NP.
There is pretty good circumstantial evidence to think that most instances of NP-complete problems are easy, but that a relative few instances are truly hard. The framework of statistical physics, and phase transitions in particular, has provided a decent idiom for this. See Monasson et al.’s 1999 Nature paper “Determining computational complexity from characteristic `phase transitions'” for an early reference.
A paper of Susan Coppersmith (http://arxiv.org/abs/cs.CC/0608053) suggests why this framework does not present a simplification so much as an alternative way of viewing the problem: to show that P ≠ NP, show that a) “all functions in P are either in a non-generic phase or else very close to a phase boundary” and b) exhibit a function that is obtained as the answer to a problem in NP and that fails to be close enough to a non-generic phase.
The evidence such as that mentioned above bears on this, and provides another reason to suspect that P ≠ NP.
Why is religion A more popular than religion B? Very seldom the reason is something like “there is more scientific evidence in favour of belief A” or “belief B would be too good to be true”.
The main factor might be simply a bunch of historical accidents. And once you happen to have a majority of A-believers around you, it’s usually simplest and safest to play along. Your parents’ religion is part of your culture, and many people might not even consciously question it.
Is it any different with the religions P≠NP and P=NP?
Is it any different with the religions P≠NP and P=NP?
Yes.
P≠NP is in this world.
P=NP is in heaven.
Maybe you merely live in hell?
Beautifully said JS!
Our intuition doesn’t tell us that P!=NP: it only says that it’s impossible to find a polynomial algorithm for an NP-complete problem. This is a slightly different thing from P!=NP. The common belief that P!=NP is probably just a consequence of the impossibility of proving neither P=NP nor P!=NP.
Congratulations on your century! Always a stimulating read.
I actually don’t understand reason 1 (” . . . would end human creativity”). Is the assumption that human creativity is somehow fairly represented by (research on) a P-time SAT algorithm a valid one?
There are gradations to the statement “P != NP” also. The two could be separate, but only a negligible part of NP could lie outside of P, which could potentially allow all of NP to be “feasible for practical purposes.” My experience is that when people assert “P != NP” they mean something much stronger, something that could have technical translation, “NP has resource-bounded measure one in EXP.” They intend to assert that it is infeasible to approach NP from below.
I think progress on this question will come “indirectly” — from getting a better understanding of what “polynomial-time algorithm” really means. On the one hand, there are “exotic” approaches (holographic algorithms/signature theory) that are not well understood. But perhaps more significantly, our understanding of problem structure is not good enough even to parallelize well at this point. In my last comment on this blog, I posted a link to some recent slides by Guy Steele, in which he says that the programming intuitions and techniques of the last 50 years are getting in the way of our ability to do concurrent programming, and they need to be thrown out. He then gives several examples to justify that statement.
There is plenty of empirical evidence, coming out of concrete work to build massive parallelism, that our feasible-algorithm toolkit is nowhere near complete, and, further, that some of our “most obvious” intuitions are almost certainly wrong.
Dear Prof. Lipton,
Could you please elaborate on the arguments made to connect separating P from NP with automating creativity? I have come across this slogan a few times but am unable to see how one arrives at such a conclusion.
If creativity in this context is interpreted as mathematical reasoning, then I would argue that decision procedures for various mathematical theories do automate creativity. Theories known to be decidable range from simple ones to sophisticated theories over algebraic structures or vector spaces. Such procedures can prove statements that would be challenging for say, the average undergraduate student with mathematical training.
If creativity is interpreted as efficient mathematical reasoning, I do not see how to argue that human beings are creative, even if we consider only the class of people with the requisite mathematical education. I do not see a compelling argument for connecting efficiency with creativity either. If the human enterprise takes a few centuries to prove a statement, we appreciate the creativity involved (though we are not searching all the time). If a machine were to take 50 years to generate such a proof, is it still to be considered a mechanical as opposed to creative achievement?
Beyond the realm of proofs of mathematical statements, such arguments become even more vague. In the page you linked to, Scott Aaronson points out that Argument no. 9 about ‘”creative leaps”‘ would apply to not being able to solve NP-complete problems efficiently in the physical world. Why would this entail anything about the automating creativity in the physical world? Are we not physical entities that realise creativity? Isn’t it conceivable that some markedly different physical entity could realise the same?
Vijay.
I think Gowers has a good comment on this. They usually link creative with being able to solve problems or prove theorems. Then, they argue if P=NP was practical this type of “thinking” would be automatic. Thus, this would be a way to show the creative (as problem solving/proving) could be done by machines.
The main problem with this argument, I think, is that even if P=NP had a practical algorithm it is unclear whether or not one could still solve the problem. The difficulty is that even if the SAT algorithm was fast, when your problem is encoded into SAT the size of the problem might be too big to run anyway.
I hope that helps some.
Although it again sounds stupid and abstract, here it is.
Creative means create algorithms, or learn, this is harder than execute algorithms. Do not forget that computation is performed in real time, those who cannot compute fast and efficient die. Therefore, even if P=NP, but to learn one need different exponent, then to be creative in real life is still much harder (much riskier), than to follow.
This series of posts and the comments are fascinating. Opinions sway either way (especially for someone like me who has become a bystander not a participant in P vs NP) depending on who you talk to. I’ve also been attracted to the possibility that “P = NP” may be like CH (i.e., independent) not relative to set theory but to the very constructive things that cs theorists do. Not very comforting if you want to use it for crypto and other thingss that people rely upon. In any event lower bounds even if they exist can be not very helpful since as you point out it’s possible to get one that doesnt yeild much information about the problem.
I think that P=NP (type 2) is far less implausible than P=NP (type 1). I sometimes imagine that our current methods are only able to probe the “small-scale” structure of problems. Perhaps it is true that if we were to look at very large scales, then NP-complete problems would have certain symmetries and structures that would emerge only on those scales. This could manifest itself, for example, as a poly-time algorithm but with a necessarily enormous constant in front.
Does anyone know of an example of a problem with this kind of feature? It happens a lot in physics (e.g. in astrophysics.) I envision something inspired by matrix multiplication, where perhaps “higher-order” Strassen formulas could be found that only start to work on extremely large instances. (Maybe this is already how other algorithms like Coppersmith-Winograd work? I don’t know; I’m just a physicist.)
Taking off my Math professor hat for a moment, and putting on my science fiction author hat: maybe OUR universe is too small for difference between P and NP to make a difference. But in much bigger, much more complex universes within the Multiverse, the difference is essential to the very nature of meta-life, meta-thought, and meta-consciousness. We DO have a consistent logical metalanguage for beings in universe A with Logic A to discuss beings in universe B with Logic B, or beings in universe B who falsely claim to use Logic B, or even fictional beings in other universes. Google Scholar “Imaginary Logic” and the more recent publications on N.A. Vasiliev.
You are awesome.
My wife is smarter than me, and outranks me. I was merely an Adjunct Professor of Astronomy at one college and Adjunct Professor of Mathematics at another university, but she is Chair of Sciences (Astronomy, Biology, Physics, Environmental Studies) at a university, so our son earned a double B.S. In Math and computer Science at 17, a JD at 20, was an attorney and Adjunct Professor at 21 and 22 respectively… So I believe in evolving people who can solve P=NP.
I’m trying to work out why I strongly believe that P does not equal NP. But in the meantime, here are a few comments on your list.
1. I’m not at all fond of the “P=NP says that creativity can be automated”slogan. I happen to believe that mathematical creativity *will* be automated one day (because I don’t believe that our brains work by magic, and we get round not knowing how to solve an NP-complete problem by restricting to a very special class of instances).
2-3 seem very feeble reasons. 2 in particular is completely unconvincing once you’ve proved the existence of an NP-complete problem. One might just as well say that it seems highly unlikely that an NP-complete problem would exist. But it does.
I don’t know enough about 4 and 5 but 6 was important for my own personal belief that P doesn’t equal NP. However, I am troubled by the thought that the correct analogue for Borel set is not obviously P but could be some other complexity class such as AC_0. For instance, a set is Borel if and only if it is analytic and coanalytic. Do people who like this reason for P not equalling NP also believe that a function is in P if and only if it is in NP and co-NP? I doubt it (despite AKS). Also, what is the analogue of the parity function in the infinite world? It appears not to be measurable.
8 I find at least moderately convincing. Some NP-complete problems feel so much as though one is forced to use a brute-force search that one can imagine that perhaps somebody would actually prove that one day.
10 I find unconvincing. It often happens that a class of mathematical problems seems pretty well impossible until somebody invents the appropriate tool (cohomology, the Fourier transform, etc.).
I will try to think hard about how I would justify my own belief, given that I don’t find any of the reasons you mention all that convincing. One thing I would say is that I believe in the stronger statement that pseudorandom generators exist. Indeed, it seems to me that a random function in P behaves in a way that is computationally indistinguishable from a purely random function. But I don’t yet have a good way of justifying this stronger belief.
Do we know anything about what results wrt average time complexity of an NP problem would imply for P == NP?
That is, if I were to show that
– for some algorithm A (say: 3-sat solver)
– for E(N) == average running time on 3-sat instances of length N
– then E(N) is asymptotically in O(n^6) (or whatever)
…do we have any results that force the above to prove anything about P =? NP?
If it’s actually possible for both NP != P AND there to be “polynomial on average” algorithms for NP it’s hard to give much credence to the various standard intuitions as to why P can’t be NP.
There is a theory of problems that are hard even on average. I should post another day on them. These results show for certain problems the average case is as hard as the worst case—very roughly. Not all problems fit this, of course.
Would any NP-complete problems fit this class? We know there are a bunch of easy SAT problems. So if there is some NP-complete problem class where the average case is hard, then where do all the easy SAT problems map to? And when you map back, what problems from the “hard” side map to the easy SAT problems? And if they do then they can’t be more than Polynomially hard then right? You can’t use infinities and things like all to even mappings because the the problem spaces have to be covers of each other right?
I don’t know and look forward to your posting on this. It just struck me that the idea of completeness and polynomial transformations means that it is the problem class with the most easy problems that must be dealt with, because all the classes with hard problems could be mapped onto it polynomially … I would love to know the answer to the question raised about the measure of the set of hard problems inside a class of NP-complete problems.
Good question.
Imagine that there is a NP-complete problem A that is hard most of the time. Then we reduce SAT to A. That means that x in SAT if and only if f(x) is in A, where f(x) is some polynomial time reduction. Now the hard instances of SAT will map to the hard ones of A and the easy ones of SAT will map to easy ones of A. Even if “most” of A is hard, there will be plenty of instances of A that might be easy—so the easy ones of SAT can go there. Note, however, the reduction x->f(x) does not have to preserve complexity. There is no reason that an easy SAT instance has to go to an easy A instance.
Would you say there is no reason that an hard SAT instance has to go to an hard instance of A?
…then one may translate any hard SAT instance into other NP-complete problems until the instance becomes easy. Or I miss something?
If you keep reducing a problem to another problem, on and on, then there is no reason to believe that it will eventually hit an easy one.
In engineering, many practical problems (most practical problems?) are of the form “show that ‘A’ (a seemingly hard problem) reduces to ‘B’ (which is easy to solve)”.
What is the complexity class of the reduction problem itself? Obviously (?) it is in NP; seemingly (?) it is NP-complete. Then isn’t a plausible argument against P=NP that optimal reductions can’t always be easy to find?
The engineering rationale for this intuition is that, in practice, optimal reductions always seem to have immensely more mathematical power (in some not-rigorously-defined sense) than the specific problem they are created to solve.
John, the complexity class of the reduction problem is in P for NP-complete problem. See Cook-Levin theorem.
Personne, my question wasn’t about polynomial-time reduction to SAT, but rather about the computational complexity of finding that reduction. In other words, to what natural complexity class do problems like finding the Cooke-Levin reduction algorithm belong too? Clearly a pretty hard class, since it encompasses code-breaking, for example. And yet, people solve problems in the algorithm-finding class amazingly often (otherwise mathematics, engineering, and science could scarcely exist).
John Sidles, sorry I misunderstood you. What would be a negative instance for finding a reduction?
Personne: consider “sort a list of integers” and SAT. You can trivially reduce “sort a list of integers” to an instance of SAT but you can’t always (in fact: usually can’t) reduce SAT instances to instances of “sort a list of integers”.
I think what Sidles is getting at here is something like:
– assume some fixed alphabet Sigma
– you’ve got formal language A (over Sigma) and turing machine M_A which (1) provably halts when run on any word in A and (2) has distinct “accepting” / “rejecting” halting states
– you’ve got formal language B (over Sigma) and turing machine M_B with the same relationship
– you want to find turing machines R_AB and R_BA s.t.:
— R_AB (1) provably halts when run on any word in A and (2) if W is a word in A that M_A “accepts” (or “rejects”) then M_B run on the tape contents after running R_AB with W on the tape will also “accept” (or “reject”) (R_AB maps “accept” or “reject” words W in A to “accept” or “reject” words in B)
— R_BA (1) provably halts when run on any word in B and (2) if W is a word in B that M_B “accepts” (or “rejects”) then M_A run on the tape contents after running R_BA with W on the tape will also “accept” (or “reject”) (R_BA maps “accept” or “reject” words W in B to “accept” or “reject” words in B)
…(and you’d want R_AB, R_BA to have polynomial execution time if you’re interested in polynomial reduction). If you want to switch from “accept”/”reject” to input/output I think it’s pretty clear how to edit the above.
Off the top of my head it seems like you can safely assume A and B are completely specified by some context-free-grammar. If you define Sigma’ to be Sigma augmented with whatever special symbols you need to (1) encode the CFG for A and B in something (eg EBNF) (2) encode M_A and M_B for execution by some universal turing machine U and (3) include a ‘;’ delimiter, you arrive at Sidle’s question:
PROBLEM: given (CFG(A);U(M_A);CFG(B);U(M_B)) either (1) find R_AB and R_BA as described above or (2) determine that no R_AB or R_BA exists.
QUESTION: what is the computational complexity of this problem (assuming it’s well-defined)?
With what little computational complexity insight I have (very little) it seems like it ought to be very hard. If so, it’s curious that people are (apparently) as good at it as they seem to be. This (apparent) surprise suggests one of the following may be true:
(a) people aren’t actually very good at it; the brain has some heuristics that work well for some of the problems we’ve encountered but for anything fancier we have next to no advantage over brute force, and this is a problem with a very large search space in general
(b) people aren’t actually very good at it; we’re just sufficiently stupid we can’t even come up with “hard problems” of this sort so everything we think up is “easy” (or “easy enough”, at least) wrt our abilities
(c) there’s some clever strategy that is efficient (either always or sometimes) that people use unconsciously (some sort of algebra of states and situations, probably); figuring out what this is might give insight into algorithms for other hard problems
Upon careful reading, anon’s post does an outstanding job of formalizing the everyday engineering (and mathematics) notion of “find a simpler algorithm that explains the system”, as well as pointing to avenues for research.
I am anispeptic, phrasmotic, even compunctious with appreciation. 🙂
Seriously: whoever this person “anon” may be … over the years (s)he has written innumerable wonderful posts … of which the preceding post is exemplary … thank you sincerely, anon.
Good question Sidles, but it is not clear why you think REDUCTIONS is obviously in NP. Finding reductions is akin to finding a function with certain properties whose domain is infinite. I have not read anon’s post in detail, but many questions about grammars are undecidable, let alone in NP or any other puny class. For example, telling whether two CFGs are equivalent is not decidable. This is similar in spirit to the reduction problem (although I haven’t read anon’s post in any detail).
Great post anon, thank you (I already said it, but my post is misplaced for a unclear reason). I vote (a), although your post inspires a slightly modified answer.
Maybe for any n there is a set of algorithms to find solutions to NP-complete problem, but the sets do not apply to lower n. If finding this set is hard in general, this would prevent finding a general solution even if NP-complete problem were easy in nature. And thus people would look good only because they are well trained to workspaces limited in n size.
#
To anon’s opinions:
People are good at it because one can think of the set of brains as a very special nonuniform family of circuits. These are circuits that slowly specialize themeslves in understanding and finding a reduction for a particular problem.
But we seldom find polymaths. This gets closer to what we mean by a uniform algorithm that can deal with all problems of a certain type.
Reply
There is no reason that an easy SAT instance has to go to an easy A instance. There is no reason that an hard SAT instance may hit an easy instance. Topsy-turvy! So I guess this is an open problem. Have computer simulations said something about it?
Seconding the notion that I’d be thrilled if you’d do a post on this class for which average cases are as bad as worst cases.
Also congratulations on 100 posts and thank-you for this wonderful blog.
I agree that there are 3 main choices, but I don’t agree with the exact phrasing of the middle choice, nor with the symbol you use for it, since I’m not sure if this middle choice is more like “P=NP” or more like “P\neq NP”.
For me, if the true complexity of SAT is n^{10^{10}} or it’s 2^{n^{1/loglog n}} it’s the same thing: In both cases it’s a mixture of “P=NP” and “P\neq NP” (yes, I know that technically in the first case P=NP and in the second P\neq NP):
On both cases, we get the property of the “P=NP” world, that you have a highly non-trivial improvement over brute force search.
On the other hand, in both cases, almost all of the reductions we make under the assumption P\neq NP” will still be meaningful: NP hardness of exact and approximate computation, cryptography etc… (for many of them, if the complexity of SAT was n^{1000} then they show that the other problem has complexity at least n^{500}).
But there will be some results (e.g. some kinds of pseudorandom generators, some crypto that assumes strong hardness) that hold if NP has exponential complexity, but may fail in these middle choices.
I think the main reason people discount this middle choice is the belief that “there is a mathematical god” and that it would either have the complexity of SAT be O(n) or O(n^2) or 2^{Omega(n)}, and not some ugly function in between. There’s also a general assumption almost all theoretical computer scientists make, and that is that the world is large enough to observe qualitative behavior that exists in the limit (otherwise you could also worry about a n*10^{1000} algorithm or a 2^n/10^{1000} algorithm).
—-
My main reasons to believe that P\neq NP, in the sense that, say, SAT has complexity 2^{Omega(n)}, are:
1) General intuition that you should not be able to beat brute force in general.
2) No one had found an algorithm yet. Even though this holds for any open problem, I think in SAT’s case this is particularly compelling since:
2a) Like, say, the Factoring problem, we can generate random instances for SAT that no current algorithm can solve. This means that we don’t really have even a conjectured algorithm to solve it, even if we didn’t need to prove its efficiency/correctness.
2b) But unlike the Factoring problem, where you have highly non-trivial algorithms but progress at stopped at some bound ( exp(n^{1/3} ), in SAT to some extent we haven’t moved beyond the most trivial algorithm. (Well we have a bit as you say, in particular for 3SAT, but it still doesn’t seem like much progress compared with the Number-Field Sieve and if you replace SAT with CIRCUIT-SAT then we haven’t progressed at all.) This makes me believe much more that the current hardness for SAT is more or less optimal than my belief that this is true for Factoring.
3) There have been cases where people made conjectures based on P \neq NP (e.g., some linear/semi-definite program will have a large integrality gap, soap bubbles will fail to solve it, proof complexity lower bounds, etc..) , and later these conjectures were proven. So P\neq NP did lead to various falsifiable predictions that were confirmed.
4) Indeed, this belief that there is a mathematical god, and so if this wasn’t the case, then probably SAT has linear time algorithms, and all sort of extremely strange things happen.
Why is polynomial time the thing that is so desirable in algorithms rather than subexponential time? Even if f(x) grows faster than any polynomial, if f(x) 1, then algorithms with running time f(x) still are better than brute search.
That should say, “if f(x) is less than c to the x for all c bigger than 1”
You raise an excellent point. For years many of us in the theory community have struggled with the issue of what should be the meaning of tractable. You are right, of course, that n^1000 is much worse than 2^n/1000 for any reasonable size n. Alan Perlis had made this point to me years ago—see here for some details. The trouble is how to create a reasonable and rich theory based on this observation is an open question.
Prof.Lipton,
I’ve only recently started following your blog. I like it very much. Best wishes to you on your 100th post.
Just a couple of brief comments:
When someone defines something, the defined object can not be included within the definition itself. When you say that “Unfortunately, we do not seem to have any computational evidence that we can collect for the P=NP question. It would be cool if that were possible.”, I recall a previous article of yours where you try to use a mathematical element called “computations” in your proof. You can not have computational evidence onto something which includes such things as computations in its definition. Or can you?
On the other hand, I find very interesting the case that P{\simeq}NP (very large exponent), because this sounds plausible. If you have read Solaris from Stanislaw Lem, you may remember how a thinking ocean blob could compute large numbers in a way our limited human mind could not ever do. This hipothetical exponent might be too large for us to get a glimpse of, without a proper scaffolding.
For reason #4: Can you post a reference that nondeterminism is exponentially useful for finite automata? I was searching for this result recently and couldn’t find it.
A better argument against P = NP is Tarnlund’s proof
that P is not equal to NP http://arxiv.org/abs/0810.5056v2.
“PNP: Let this mean that P is really equal to NP, that there is a practical polynomial time algorithm for SAT. Note, even this does not imply there are practical algorithms for all of NP, since the running time depends on the cost of the reduction to SAT”.
Even if the reductions were free of cost this won´t be the paradise. Unless the practical polynomial time algorithm for SAT is optimal for all NP problems (must it be?), there will still be room for improvements i.e it would still be interesting to study the special structure of problems in order to reduce the running time of this general SAT algorithm, not to mention the parallelization challenges (i.e the P=NC problem, wich i personally like much more than the P versus NP ).
In any case, as a follower from your first post, congratulations and thanks for this great blog. I hope great advances will be made in this issue before you reach the next decimal power.
First I would to give Congratulations on a very fine Blog!
Now my two pence…
The reasons given for believing P not equaling NP are fascinating! However I am interested in the psychology of those who believe in the above.
Is this belief one about abstract theory of computing, or is this a belief in the real world out there?
Now in the real world there are great difficults regarding solving large matrices because of norm problems! Linear Algebra is difficult! Yet is has O(N ^ 3) algorithm supposely!
Another point is that NP complete problems have exponential search spaces while P complete one have polynomial bounded spaces. This is not really true! It depends on the hidden symmetry!
Essentially, the difference between those who believe that P=NP (Bollobas the most famous)
and P ne NP (Gower… everyone else…) is about hidden symmetries. Now, is it really possible for all of those symmetries in say the Permanent to go to waste? and other problems like Knapsack (Scaling symmetries)?
The battle is joined. Symmetry or Chaos.
Thanks for a great blog
Zelah
Yet another reason to be skeptical is that NP=P would imply any problem in PH would be easy. For eg., finding the smallest circuit equivalent to a given circuit, or approximating no. of satisfying assignments to within any polynomial factor. It’s hard enough to believe that SAT is easy – with these other problems, the disbelief is amplified.
John, sorry I misunderstood you. What would be a negative instance for finding a reduction?
Thanks anon. I vote (a).
Good question Sidles, but it is not clear why you think REDUCTIONS is obviously in NP. Finding reductions is akin to finding a function with certain properties whose domain is infinite. I have not read anon’s post in detail, but many questions about grammars are undecidable, let alone in NP or any other puny class. For example, telling whether two CFGs are equivalent is not decidable. This is similar in spirit to the reduction problem (although I haven’t read anon’s post in any detail).
To anon’s opinions:
People are good at it because one can think of the set of brains as a very special nonuniform family of circuits. These are circuits that slowly specialize themeslves in understanding and finding a reduction for a particular problem.
But we seldom find polymaths. This gets closer to what we mean by a uniform algorithm that can deal with all problems of a certain type.
It is better to believe that P=NP is impossible.
See Prof. Erik Demaine “proves” P = NP April 1, 2008.
http://courses.csail.mit.edu/6.006/spring08/p=np.html
Put it as the 11.th item into your “A “Why P=NP is Impossible” List”.
I recently found the page of dr Joel Hamkins.
He introduces the notion of infinite-time turingmachines at:
http://arxiv.org/PS_cache/math/pdf/0212/0212047v1.pdf
Later Ralf Schindler proved that P is not equal NP on those
infinite-time-Turingmachines :
http://wwwmath.uni-muenster.de/logik/Personen/rds/pnenp.pdf
I wonder if that is a good reason to suspect P not equal NP in the
classical case. Atleast if the problemsize is countable infinite, there
seem to be no “shortcuts”.
The following text is a little idea to the P vs NP problem from an
amateur, trying to make use of the infinite P vs NP problem.
I hope i didn’t wrote too much nonsense :-).
I don’t fully understand the implications of his infinite-time
turing-machine so i came up with my own infinite-time
turingmachine :
(let P’ be infinite polynomial Time, NP’ infinite nondeterministic
polynomial time)
Let T be a deterministic type 2 Turing machine with three tapes.
The first tape of T contains a word of infinite lenght. The second
tape is reserved for calculations, the third tape is emty. T accepts
W if and only if it writes an “1” into infinitely many cells of the third
tape. T is allowed to perform countable infinitely many steps.
A language L, wich is allowd to contain words of infinite length,
is in P’ if there is such a Turingmachine T, that decides L.
Now one could look at an infinite version of 3-Sat for example,
where there are infinitely many clauses. An input is accepted,
if there is an assignment of variables, so that every clause is true.
T could check the answer of an infinite 3-Sat problem with, by
checking each clause and write an “1” on the third tape if the
clause is true. If a clause fails to be true no more ones are written
on the tape. So infinite 3-Sat is in NP’ .
I think infinite 3-Sat might even be in P’. However it might be
possible to use a more general “infinite Sat” problem in NP’ wich
can be shown to be NP’-complete by adapting the proof of Cooks
theorem, with infinite-time turingmachines and an infinite version
of Sat.
I just had the funny idea to make a little “conjecture”.
“Infinite 3-Sat” is in some sense an “infinite extension” of classical
3-Sat by allowing infinitley many Clauses.
If one would find a clear definition what an infinite extension of a
classical NP Problem is. I would “conjecture”:
let A be a Problem in NP an A’ be it’s infinite extension in NP’.
If A is in P, A’ is in P’.
The idea is, that the polonomial time algorithm for A could be
adapted to apply for A’, too. If the algorithm has an upper bound
of O(n^5) for example, one could argue that if n is the cardinality
of an countable set, so is n^5. Therefore the running time would
still require countable infinitley many steps. in contrast an
exponential function would require
uncountable infinitley many steps.
To be honest i’m not sure how to proof this, but i think a proof
could be resistant against realtivization arguments ( if the
algorithm would use an oracle, how would it be adapted to A’,
since A’ can’t use an oracle ).
Ofcourse that depends of how one would show what it means
to adapt the algorithm.
Now for Hamkins infinite-time Turing machines P does not equal
NP. If it would be possible to adapt this result for the infinite-time
Turing machine T, then P’ is not equal NP’.
The last step would be,to assume there is a polynomial time
algorithm for Sat. It would follow that infinite Sat is in P’.
Therfore P’ = NP’. Because of the result of ” P’ is not equal NP’ “,
there can’t be a polynomial time algorithm for Sat.
All very interesting comments and thoughts. I must admit my ignorance on not having the first clue as to how to solve the issue but I would like to offer some conjectures that might give others, far more talented than I, a clue in dealing with the fabulous problem.
First of all the three possibilities were offered in the context of an experimental science. Since my training was in chemistry (even though my career is in computer science) that means that some of the time you might get one answer and at other times under other conditions you might get another answer. This seems to run counter to the basic idea in mathematics that environmental factors (such as temperature, etc.) shouldn’t effect your proof, and is the reason you can have proofs in mathematics while in science we have verifications, stilll bound to reasoning but a very different process.
So is mathematics now a science? I can almost hear the shouts of “NO!” over the Internet.
The other conjecture, which requires a single step back away from the problem, that I wanted to deposit at your doorstep is whether the resolution of the P ?= NP problem is, itself, an NP problem? Or is it a P problem. If it is not a P problem, then it must be an NP problem, no? So finding a contradiction to the assumption that solving the P ?= NP problem is a P problem might be a more productive way to approach the issue.
Just a thought. Like I said, I’m just a total ignoranmous, and if I have made what are ridiculous comments, I hope you enjoy the laugh.
I will give you something you probably aren’t expecting. An actual, coherent, logical reason to suspect that P=NP. And that is, that if finding formal mathematical proofs is in NP, then why have humans been able to prove difficult things? There’s no denying that we don’t understand the algorithms that run in our own heads. Our best robots can’t tell the difference between a shadow and a hole in the floor, and if you take the number 5 or the letter e, make it all curvy, break the lines and slash through it with a few extra lines, a 4 year-old will still identify it right away, but not a computer program. So we have yet to figure out how to reproduce the most basic feat of intellect that we ourselves possess. I therefore would like you to observe that it would be entirely logically consistent if intelligence itself is in NP, and thus the very existence of an intelligent being innately proves that P=NP, and thus an intelligent being has an innate built-in NP problem solver. It may just be very difficult to produce this algorithm, and if it was to be the key to intelligence itself, then that would merely explain why our AIs aren’t very good – the fact that we are lacking in a NP problem solver – though we know that intelligence itself is possible since we exist. So the fact that our best AIs aren’t very good, and that there really hasn’t been a lot of progress in that regard after a whole lot of trying (just like finding a polynomial NP algorithm), certainly doesn’t stand up to what we know to be true, that an intelligent being is possible, since here we are. But being self-consistent isn’t enough. Here’s some actual evidence: How long was the proof to Fermat’s last theorem? Supposing there wasn’t a shortcut to it as Fermat claimed couldn’t quite fit in the margins of his notebook and that formal mathematical proofs are in NP, then how did a human solve it? If P!=NP, finding the proof to such a thing as Fermat’s Last Theorem, or anything that requires a long proof, ought to require far longer than the age of the universe or super-astronomically good luck. Yet, there are such proofs. Solved by humans. Incredibly long proofs, easily enough verified, but apparently not impossible to produce because they WERE produced. And FLT is not the only one. If P!=NP, then how did we do it? We shouldn’t have been able to find the proof, or any other long proof, unless every one of those proofs is way longer than it has to be, and they probably aren’t.
zotharg asks: “Incredibly long proofs, [that are] easily enough verified, but apparently not impossible to produce because they WERE produced … if P!=NP, then how did we do it?”
One answer commonly given in the mathematical literature amounts to “We produce proofs with the help of an oracle … and the physical world is that oracle.” As Bill Thurston puts it:
Thurston’s view is consistent with recent research themes in AI that emphasize, not solely logic, but physicality too.
I am a science philospher and not a mathematician but I wanted to add a question to the discussion. We all know that transendental numbers can be expressed as infinite numbers of polynomial expepressions. Thus Pi or e can be expressed in terms of infinite series. If NP can be treated as transendental, that would imply that it could be expressed in some similar fashion. However, this would not show nor prove that P=NP as a proof would have to be expressed in finite terms, unless you wanted to change the definition of a proof. Nor could you express an NP problem in a finite number of P problems.
What this amorphous thought implies to me is that NP is sort of like a phenomenon that supervenes upon P and although it is dependent on P, it cannot be proven from P or expressed in a finite number of expressions or time, except as an approximation, just as we can derive a value for Pi up to whatever desired number of significant digits we want depending on how many finite polynomial expressions we accumulate. The question then becomes can we be satisfied with approximations in solving NP problems?
I hope this not utter nonsense and might be helpful.
In fact programmers have to content themselves with approximations. You idea is interesting in that it expresses the fact that an ideal algorithm – not an ideal problem, be careful – is most of the time unreachable. But contrary to transcendental numbers, this doesn’t mean that ideal – or optimal – programs don’t exist in the countable set of all possible programs. It just means that our brains need an irreducible amount of time in order to design more and more efficient programs. To me this is kind of a law of evolution, or even the very definition of the arrow of time.
You may view the set of all programs like the set of all possible books: the best way to know the content of a non-existent book is to write it yourself. There are no clever shortcuts to do away creation.
What’s the algorithm with a practical application (that is, directed at a real problem, not one constructed for the purpose – I don’t care if it’s too slow to be practically used) with the slowest polynomial time?
Here (http://sourceforge.net/projects/bqp/) is the python version of a toy for testing believes. In this case, there is no failure in approximating binary quadratic program. Start playing with small dimensions, the memory requirements grows fast ( ) depending on the implementation. I would love to learn counterexamples!!!
) depending on the implementation. I would love to learn counterexamples!!!
As for me, I think that P = NP but that it’s also impossible to prove. So, if by chance we came accross the magic algorithm for SAT, we would be either unable to prove that it’s correct or that it does run in polynomial time.
When they want to prove the efficiency of their algorithms, programmers usually use low-level languages. Two examples: complexity theorists are fond of Turing machines, while Donald Knuth – the inventor of the analysis of algorithms – designed the MIX machine-like language for his complexity purposes. But when you want to prove the correctness of your programs you tend to use very highly typed languages such as those that are used in proof checkers. Unfortunately, these languages prevent the programmer from having full control on the efficiency of their algorithms.
All this makes me believe that you can’t have at the same time certified correctness and certified efficiency. So even if P = NP, we won’t have a proof of the correctness and a proof of the polynomial time behaviour of the algorithm – provided we’re even able to find it. This is, IMHO, the circumstance which would be too good to be true.
> “You can’t have at the same time certified correctness and certified efficiency”.
Or alternately, to put it in a more Heisenberg’s uncertainty-like style:
The product of the probability that an algorithm is correct by the probability that it is optimal is lower than some constant which depends only on the polynomial reducibility class of the problem to be solved. The harder the problem, the lower the constant.
Well, forget about the reduction thing and just read “… a constant that depends only on the problem to solve.”
What I mean is this: when you have control on efficiency you lose control on correctness, and the other way around. There may already be a precise statement of this idea using probabilistic algorithms. I’d like to learn more about it. Can anyone help me?
The produce of efficiency and accuracy is a constant.
Dear Professor Lipton,
I agree that the most intuitive is, either,
1 P{\equiv}NP: Let this mean that P is really equal to NP, that there is a practical polynomial time algorithm for SAT. Note, even this does not imply there are practical algorithms for all of NP, since the running time depends on the cost of the reduction to SAT.
or
P{\simeq}NP: Let this mean that there is a polynomial time algorithm for SAT, but the exponent is huge. Thus, as a theory result, P does equal NP, but there is no practical algorithm for SAT.
I think that Math can device us! For example,
“It is impossible to map, continuously [0,1]X[0,1] onto [0,1]” It is a very natural believe. How amused you was when you discovered that is not true. Another good one:”Hey guys, what are we waiting? Hilbert Program has to be fulfilled before 2015!”
I learned that nothing is correct until exhaustively checked. My intuitive reason, if one can be posted, it that as a mathematician I know that e^{x} is not a polynomial function, but why I can write
e^{x} =1+x or e^{x} =1+x+x^{2}/2 or e^{x} =1+x+x^{2}/2+x^{3}/6?
If I really know the theory I can think that all the above approximations are good. If I am free to think about math as a fairy tale, polynomial functions are the sheep herd and exponential functions are the fence. When they are too far, I cannot really distinguish them. How far do we see?
Thank you for your blog,
angela
I kind of object to the listing for number 3, that P = NP (sorry no “identical to” in comments) would put an end to modern cryptography. I agree that if true it would, but I don’t see that as a reason for it not being identical.
It’s a similar argument to, it has to work because it’s the only choice we’ve got. Otherwise though, an amazing list and a great way to procrastinate whilst writing my dissertation
Doesn’t 7 already show P neq PSPACE since c>1?