A Breakthrough On Matrix Product
Beating Coppersmith-Winograd

Virginia Vassilevska Williams is a theoretical computer scientist who has worked on a number of problems, including a very neat question about cheating in the setup of tournaments, and a bunch of novel papers exemplified by this one on graph and matrix problems with runtime exponents of 
Today Ken and I want to discuss her latest breakthrough in improving our understanding of the matrix multiplication problem.
Of course Volker Strassen first showed in his famous paper in 1969 that the obvious cubic algorithm was suboptimal. Ever since then progress has been measured with one parameter 





This has all changed now. Virginia has proved that she can beat the “barrier” of CW and get a new lower value for 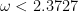


The Basic Idea
Matrix multiplication is bi-linear: the formula for the 




This is a special case of a general tri-linear form

where 


where 



in 
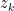
The Basis Idea
The recursion idea is nice to picture for matrices, though its implementation for the way we have unrolled matrices into vectors is not so nice. Picture 


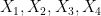

The reason why the vector case does not look so nice is that the tri-linear form 


The final step by CW was to choose a starting algorithm 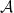





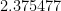
The insight for breaking through was to make a bigger jump in the basis. Vassilevska Williams was actually anticipated in this without her knowledge by Andrew Stothers, in his 2010 PhD thesis at the University of Edinburgh. Stothers used 


The Proof
We cannot yet really give a good summary of the proof—further details are in her paper. One quick observation about her work is in order. She used the CW method, but extended it into a general schema can be used to find good matrix product algorithms, perhaps even better than the one in the paper. The algorithms themselves can be generated and examined, but as usual the task of analyzing them is very hard. The brilliant insight that she has is this task can be laid out automatically by a certain computer program. This allows her to do the analysis where previous others failed.
For example here is a sample of the overview of her main program, in pseudo-code:

The details are not as important as the fact that this program allows one to work on much larger schemas than anyone could previously.
What Does the Bound Mean?
Note that she has improved the bound of Stothers by 




The meaning instead comes from this question: Is there a fundamental reason why 



Open Problems
Can the current bounds be improved by more computer computations? Are we about to see the solution to this classic question? Or will it be struggling over increments of
In any event congratulate Virginia—and Andrew—for their brilliant work.
Update: Markus Bläser, who externally reviewed Stothers’ thesis, has contributed an important comment on the blog of Scott Aaronson here. It evaluates the significance of the work in-context, and also removes the doubt going back to 2010 that was expressed here.
Trackbacks
- A new faster algorithm for matrix multiplication « Introduction to Algorithm Analysis and Design
- Ce se mai intâmplã in informatica teoreticã | Isarlâk
- Shtetl-Optimized » Blog Archive » The Alternative to Resentment
- Key mathematical tool sees first advance in 24 years | Journal of Technology and Economic Development | Future Technology | Green Technology | Military Technology | Business | Trading | Finance | Computer | Robots | Entertainment | Games | GPS | Software
- techtings» Key mathematical tool sees first advance in 24 years
- Cup Sets, Sunflowers, and Matrix Multiplication | Combinatorics and more
- Matrix Multiplication Sees Breakthrough; First In 24 Years - CrazyEngineers
- Key mathematical tool sees first advance in 24 years - physics-math - 09 December 2011 - New Scientist
- Уменьшена экспонента умножения матриц
- The Higgs Confidence Game « Gödel’s Lost Letter and P=NP
- Just a bit faster « Dango Daikazoku
- Links « Front to Back Books
- Cricket, 400, and Complexity Theory « Gödel’s Lost Letter and P=NP
- No-Go Theorems | Gödel's Lost Letter and P=NP
- Are there any new brilliant computer science algorithms in last 10 years | Resume Rewriter Free
- Blasts From the Past | Gödel's Lost Letter and P=NP
- Limits On Matrix Multiplication | Gödel's Lost Letter and P=NP
- Baby Steps | Gödel's Lost Letter and P=NP


Thanks for the very understandable summary. One thing I found interesting about this algorithm is that it uses nonlinear optimization for obtaining the bounds. It is not often one sees algorithms being directly used to prove a theorem.
I meant “interesting about this result”, not “interesting about this algorithm”
I am not quite a theoretical CS person, but I fail to understand the significance or the implications of any improvement over even O(n^3) bound when the NP=?P issue has not made any progress.
In a previous post, Gödel said:
“I thought k*n means you understand the solution, k*n^2 means you can solve it but only partly understand it.”
Thus under the standards of Gödel himself, matrix multiplication is still not well understood. However if the new algorithm can be made practical, it will certainly give rise to new larger-scale implementations of matrix multiplication.
The data size is N = n^2, so in terms of N we’re talking N^{1.1863…}. Bien entendu! 🙂
Dick and I mused that the most “salient” constant c that could form a natural barrier for \omega, with 2 strictly < c < 2.3727…, may be 2 + 1/e = 2.367879441… This as opposed to c = sqrt(5) = 2.236… as I wrote and Dave Bacon independently offered on Scott's blog. As I said there, any takers or breakers?
Merci Ken pour l’explication. 🙂
So now we do have a practical bound for matrix multiplication. I really hope the new algorithm will soon be made feasible.
I should add actually that there is a good point between us and “Gödel” here. The “cubic” algorithms mentioned in this posts’s first sentence are really N^{1.5} by the same token, and N^2 means quartic. For graph and matrix problems one can indeed argue pretty sweepingly that n^4-time algorithms are probably improvable, and n^5 and higher ones are probably short of understanding.
Re salient constants, I know of proofs that naturally give rise to bounds of the form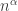 for some irrational
for some irrational  (usually the root of a quadratic). Typically they work by feeding in an existing bound to get a slightly better one, then iterating that process and showing that the limiting exponent satisfies some polynomial equation. I can’t think of any that naturally give rise to a transcendental bound — does anyone have a good example? Maybe something that depends on a continued-fraction expansion?
(usually the root of a quadratic). Typically they work by feeding in an existing bound to get a slightly better one, then iterating that process and showing that the limiting exponent satisfies some polynomial equation. I can’t think of any that naturally give rise to a transcendental bound — does anyone have a good example? Maybe something that depends on a continued-fraction expansion?
Exponent bounds for matrix multiplication generally arise from an iterative process that leads to a transcendental equation (since exponentiation naturally comes into the equation). In simple cases, like Strassen’s algorithm, you get a nice enough equation (namely, 2^x = 7) that you can solve it explicitly and get a transcendental number. Coppersmith and Winograd and the new improvements are a lot more complicated. You can characterize the resulting exponents as solutions of big systems of somewhat complicated simultaneous equations. The solutions are surely transcendental numbers, but I don’t know whether this can be proved.
Oops, I realize now (after reading your response) that I was of course aware of proofs that lead to exponents like — pretty well any proof that starts with a small example of something and tensors it up. So I suppose I’d better make my question more specific and ask whether there a general type of argument that could conceivably lead to the bound
— pretty well any proof that starts with a small example of something and tensors it up. So I suppose I’d better make my question more specific and ask whether there a general type of argument that could conceivably lead to the bound  . Are there natural proof techniques that lead to exponents resembling that one?
. Are there natural proof techniques that lead to exponents resembling that one?
gowers,
I know of no even ideas for lower bounds that could come close to that. The best I know is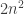 which seems pretty weak, but still needs a proof. Perhaps the best idea could be something like: if matrix product exponent was 2, then this means matrix product is really doable in linear time, which then shows
which seems pretty weak, but still needs a proof. Perhaps the best idea could be something like: if matrix product exponent was 2, then this means matrix product is really doable in linear time, which then shows  Perhaps this approach could be made to work.
Perhaps this approach could be made to work.
Serge- Are these new algorithms really make understanding of matrix multiplication any better?
With the increased [process] complexity to lower the exponent by only a small fraction we going into the opposite direction.
Of course it does. Gödel was right to emphasize that faster algorithms come from a better understanding of the problem to solve.
Maybe it’s no progress towards solving PvsNP, but since it took 25 years to speed up this algorithm by such a small fraction I find it hard to believe that we’ll know someday whether SAT or integer factorization admit polynomial algorithms…
My question isn’t about the size of the exponent, but rather whether an exponent made in a simple way out of e could arise naturally from a proof. I can’t conceive of an argument that would lead to such a bound (upper or lower), but that may be just because there’s a technique I’m not familiar with or I’m forgetting something. To answer my question in the affirmative it would be sufficient to exhibit any sensible argument to a sensible combinatorial problem that yielded a bound of the form where
where  was a simple function such as (for instance) a non-constant polynomial in
was a simple function such as (for instance) a non-constant polynomial in  and
and  with integer coefficients.
with integer coefficients.
To better appreciate Strassen-type theorems, I would very much enjoy reading natural statements of these conjectures in contexts other than purely algebraic. Here is an attempt from a geometrically natural point-of-view:
Is there a more geometrically natural statement of Strassen-type theorems than this? For what other branches of mathematics can Strassen-type theorems be stated naturally? Comments and pointers to the literature — both fundamental and applied — would be very welcome.
As a followup, here’s another (tentative) geometric description of Strassen-type theorems. From a matrix algebra point of view, it is very remarkable that the matrix-matrix product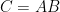 , for
, for  and
and  square matrices, requires — asymptotically and assuming
square matrices, requires — asymptotically and assuming  — no more computational effort than the matrix-vector product
— no more computational effort than the matrix-vector product  for
for  a general vector. Equivalently in the language of differential geometry, the computational effort required to sharp (
a general vector. Equivalently in the language of differential geometry, the computational effort required to sharp ( ) or flat (
) or flat (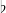 ) a full-rank bilinear form is no greater than the effort to
) a full-rank bilinear form is no greater than the effort to  a vector or
a vector or 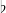 a covector (viewing vectors and covectors as rank-1 bilinear forms).
a covector (viewing vectors and covectors as rank-1 bilinear forms).
These reflections lead us to a (dim on my part) geometric appreciation that somehow, to “learn” that a bilinear form is rank-1 requires computational effort, or equivalently in algebraic terms, matrix-vector multiplication is surprisingly just as costly as matrix-matrix multiplication.
It would be great if someone smarter than me could explain these mysteries better and more naturally! 🙂
Please, could people kindly refrain from fussing over this so called breakthrough and get on with whatever they are supposed to be doing
In particular Scott Aaronson’s blog reads like if someone just proved the Riemann hypothesis.
Such self promotion enterprise is simply embarrassing, both for the people involved and for the TCS community at large.
Anonymous,
Hi. It is not that we will use the algorithm it is galactic. Strassen’s original one is borderline. But the idea that progress is made on a problem that stood for almost 25 years seems pretty cool to me.
dick
“the idea that progress is made on a problem that stood for almost 25 years seems pretty cool to me.”
You are right, but I guess you’d agree there is a difference between “pretty cool” and “one of the best results proved in years in all of theory”. Seriously, is that much hype justified, given that we currently have no clue whether this algorithm will lead to any significant further improvements or will it be a dead end a mere curiosity 20 years from now? Regardless of the importance (or lack of it) of the result, it would much more reasonable to show some restraint, especially as this blog is surely one of the “flagships” of TCS community when it comes to wider outreach.
Well said Michal, I wonder if there is a correlation between this way of thinking about break-through results in TCS and the relevance of TCS in Computer Science as well as how hard it is for students in the field to get a job.
The significance of the result is already explained by Markus Bläser, this is a marginal improvement based on existing technique, period.
PS I would rather be enlightened if you would like to share your view on the recent update in the blog post by Aaronson, in which he advised people to “go to hell”?
That last talk about golden ratio sounds like numerology.
Don’t let yourself be influenced by names! As David Hilbert used to say: “It must be possible to replace in all geometric statements the words point, line, plane by table, chair, beer mug.”
It seems to me that the ongoing discussion of the new Stothers-Vassilevska-Williams algorithms and also Lance Forrnow’s recent essay The Death of Complexity Classes? echo perennial themes that Charles Townes articulated in a 1984 IEEE article titled “Ideas and Stumbling Blocks in Quantum Electronics”;
The following excerpts from Townes’ 1984 essay are refocused to address contemporary issues in complexity theory:
It is wonderful to reflect that even today, more than 60 years after the invention of masers and lasers, we are still finding beautiful new mathematics, physics, engineering, and enterprises associated to these devices. On the other hand, it is sobering to reflect that Townes’ 1984 essay was written ten years after peak enrollment in north american physics programs; and yet few or no physicists of Townes’ generation anticipated this two-generation (and still-persisting) educational stagnation. In failing to recognize the onset of this stagnation, no effective steps were taken to forestall it.
Anxiety that computer science — and even the global STEM enterprise — may be stagnating largely accounts (it seems to me) for both the hyperbole and the rancor that have attended the discussion of these topics. Townes’ essay reminds us that neither hyperbole nor rancor are warranted, rather it’s prudent (for students especially) to take Townes’ advice that we “stay humble and be aware there may be other exciting events around the corner.”
Note: please don’t hesitate to delete the above post, from which some of the HTML markup needed to make it readable is missing; the following post repairs the lack.
Hmmm … let’s switch to an alternative markup strategy for Townes’ essay:
————————————–
It seems to me that the ongoing discussion of the new Stothers-Vassilevska-Williams algorithms and also Lance Fortnow’s recent essay The Death of Complexity Classes? echo perennial themes that Charles Townes articulated in a 1984 IEEE article titled “Ideas and Stumbling Blocks in Quantum Electronics”;
The following excerpts from Townes’ 1984 essay are refocused to address contemporary issues in complexity theory:
It is wonderful to reflect that even today, more than 60 years after the invention of masers and lasers, we are still finding beautiful new mathematics, physics, engineering, and enterprises associated to these devices. On the other hand, it is sobering to reflect that Townes’ 1984 essay was written ten years after peak enrollment in north american physics programs; and yet few or no physicists of Townes’ generation anticipated this two-generation (and still-persisting) educational stagnation. In failing to recognize the onset of this stagnation, no effective steps were taken to forestall it.
Anxiety that computer science — and even the global STEM enterprise — may be stagnating largely accounts (it seems to me) for both the hyperbole and the rancor that have attended the discussion of these topics. Townes’ essay reminds us that neither hyperbole nor rancor are warranted, rather it’s prudent (for students especially) to take Townes’ advice that we “stay humble and be aware there may be other exciting events around the corner.”
Wouldn’t it be helpful to have an online catalogue of matrices
like oeis.org with known lower and upper runtime bounds
for matrix-vector and matrix-matrix product algorithms
for concrete matrices?
Let me add my cranky comment.
In some places people say that Fourier transform of something may lead to major improvement. Fourier Transform usually mean translation invariance. Here that can mean the partial multiplication over the blobs for fixed n M_k,m= L( a_k, a_{k+1}, a_{k+n}) L(b_m, … b_{m+n} ) \forall k,m lead to the desired sums (L – linear operator). Then one can use Fourier transform.
Good luck.
In the course of history we become able to design faster and faster algorithms, so that problems become easier and easier to solve. Therefore it’s not legitimate to credit each problem with an inherent difficulty, for it’s only with time that they become easier. This is why the PvsNP problem is ill-posed, being based on the wrong idea that history can be condensed onto a single point.
This is not very relevant to this particular post…but I am curious about some recent possible developements at LHC. There will supposedly be a public announcement on Dec 13….
I am sorry to churn the rumor mill…Apparently the Higgs bosonmass is most likely to be around 125 Gev .
http://blog.vixra.org/2011/12/02/higgs-rumour-anaylsis-points-to-125-gev/
Curiously this is very close the the one predicted in this paper….
http://www.citebase.org/abstract?id=oai%3AarXiv.org%3A0912.5189
Apparently this involves the use of four color theorem….Is this completely bogus….or is there more to this?
ok, The author in the second paper seems to have made several claims including a simple proof of “4CT” which is quite bogus. Case closed.
I may be wrong, but I think Virginia Vassilevska Williams showed a converse reduction: she proved that a subcubic-time algorithm for triangle finding can be used, in a combinatorial way, to construct a subcubic-time algorithm for Boolean matrix multiplication.
Am I correct?
If the answer is yes, maybe this paper could be a step forward in that direction:
https://www.academia.edu/40163423/Triangle_Finding
We showed if we assume that we can do the Binary AND Operation in constant time, then Triangle Finding can be solved in quadratic time.
It’s just a little result just for sharing!!!
Algorithms such as finding the maximum into an array of integers assumes the operation of comparisons between two numbers take constant time. That’s why, we can affirm the running time of finding maximum is $O(n)$ where $n$ would be the array length.
Operations such as the Binary AND Operation might be more complex than the comparison operations, but if we assume that we can do this operation in constant time, then Triangle Finding can be solved in time $O(n^{2})$. Which means according to the results of Virginia Vassilevska that the Boolean Matrix Multiplication can be done in $O(n^{2})$ as well.
See more in
https://hal.archives-ouvertes.fr/hal-02272547