How Good Is Your Translator?
Using fixed points to measure language translators

Franz Och is a computer scientist whose main research is on machine translation of natural languages. He got his doctorate from RWTH Aachen University in his native Germany, and continued his work at the University of Southern California.
Today Ken and I wish to talk about fixed-point theorems, and their possible application to language translation systems.
After a talk at Google in 2003 Och soon joined Google to attempt to build a system that could translate almost any language to another. The story goes that after his talk Larry Page explained that having such a translation system was critical for the mission of Google. Och joined Google in April 2004 and later said,
Now we have 506 language pairs, so it turned out it was worthwhile.
We see 64 individual languages covered at this moment, so many more pairs. Indeed the Google system is quite good, as you probably know from using it yourself.
I, Dick, just visited CMU for two days and had the pleasure of talking to several of their language translation experts. This reminded me of an old idea of mine on using fixed-point technology to measure how good a translator is. Let’s talk about that in a minute after we just say some general comments about fixed-point theorems.
Fixed Point Theorems
In general a fixed point theorem is a statement of the form: given a nice map from some universe 


- Atiyah-Bott fixed-point theorem
- Borel fixed-point theorem
- Brouwer fixed-point theorem
- Caristi fixed-point theorem
- Diagonal lemma
- Injective metric space (see Helly and retraction properties there)
- Kakutani fixed-point theorem
- Kleene fixpoint theorem
- Tychonoff fixed-point theorem
- Woods Hole fixed-point theorem
Note, most are named for the discoverer of the theorem. The last is named for where the theorem was discovered. It is an interesting story that perhaps we will discuss another day—take a look at the forwarded link to see what happened.
Stephen Kleene has two additional fixed point theorems in computability theory, which he proved in 1938. The most important, perhaps, is the so-called “second recursion theorem”:
Theorem: Let
be a total computable function. Then there is an index
so that

Here as usual—in computability theory—



His proof is simple, but magical. I always found this proof to be special: it proves an important theorem, yet the proof is quite direct and in some sense very simple.
Note first that there is a computable function 

There is a program 

Let 
There is something, in my opinion, that is unique about this proof. You might have expected that a fixed point theorem would require some iterative process. Kleene’s proof is “algebraic” and direct: it can even write down the exact fixed point. I find this remarkable. But Ken has notes showing how to write the fixed point in a more programming-friendly style. Perhaps these will help make it less remarkable.
Language Translation Ranking
One of the central problems in machine translation is how to tell if your translator is “good.” For example a simple word-for-word dictionary translator would be immediately seen by any human to be quite bad. But how to correctly rate translators? This is a non-trivial issue, which is fundamentally different from determining the quality of programs that solve other tasks.
- One way to rank computer chess programs is have them play each other.
- A simple way to rank factoring programs is to see how large a number they can factor.
- A way to rate programs that attempt to solve
-complete problems is to see if they can solve problems that have known solutions.
In all these cases the methods of rating and ranking are fairly objective. This is not the case in machine translation. Indeed NIST runs an annual contest to measure progress on machine translation. They score the translators by using: “automatic metrics and human assessments of system translations.” See this for the details.
Language Translation Ranking via Fixed Points
We propose a simple test for language translators that is quite different. Suppose that 

Let 

Eventually this sequence is stopped: either it cycles or goes on too long so we give up. In all cases we have seen it stops fairly soon at a fixed point, and we speculate that this may even be provable for certain translation systems. Suppose it stops with the sentence 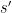
- We can see if
. For if they are the same, then it seems reasonable to argue that the translators work well, If on the other hand,
- The other measure is the number of steps until the sequence hits a fixed point (or cycle, or giving up). If this takes many steps that also suggest that the translators are not so good.
Perhaps these can be made into proper scoring methods for ranking language translators?
Here are some hand experiments that Ken and I just did using Google Translate. It would be a cool project perhaps for someone to try and do this test systematically on a large corpus. In each case I identify the two languages and the series of sentences until a fixed point is reached.

Alice tricked Bob by hiding the key.
Alice Bob cheated by hiding the key.
Today I would like to discuss one of the shortest proofs of a hard theorem.
Today I want one of the shortest proof of a hard proposition to discuss.
Today I would like to discuss one of the shortest proofs of a hard theorem.
Today I want to talk about one of the shortest proof of a theorem of hard.
Today I would like to discuss one of the shortest proofs of a hard theorem.
Today I want to be one of the shortest proof of a hard set to be discussed.
Today I want to be discussing one of the shortest proof of a harsh sentence.
Today I would like to discuss one of the shortest proof of a severe punishment.
The train is late, so we will be late too.
The train is late, so we’ll be late too.
The train is late, so we will be late too.
The train is late, so we’ll be late.
Ken’s Fixed-Point Theorem
While we are taking about fixed point theorems, we note that our own Ken proved a complexity-class version of Kleene’s theorem. He likes to put it in the form of a puzzle. Let 




Sounds easy, no?—after all, each language 
Theorem:
For any language
that breaks down into languages
, and any recursive enumeration
of
, there exists
and
differ on only finitely many strings.
This holds for any reasonable complexity class in place of
Open Problems
Can the iteration fixed point idea be used to measure how good a pair of translator programs are? Should good ones essentially be invertible? Or said another way: should every sentence be a fixed point, or at least map to a fixed point in the other language in one step? What do you think?
Are there any non-trivial cycles in Google Translate?
[Changed photo and singularized Och, said more about fixed-points vs. cycles.]


I believe Google Translate has no nontrivial cycles. One might even be able to abstract the way it works (using empirical samples of translations and huge compendiums of phrases and scores for them) to establish a kind of retraction/Helly property that would prove this. At least Google search doesn’t quickly find me any example of someone posting such a cycle…
The Wikipedia article Double negative provides commonplace examples of linguistic cycles that pose difficult challenges for machine translation.
To which pure-minded mathematicians may say: “Yeah, yeah, yeah …” 🙂
A little more seriously (because communication is a serious business), another mathematically natural place to look for fixed points in communication is within the broader scope of conversation analysis, said fixed point being convergence to a shared mental model (SMM). As it turns out, there is a burgeoning academic literature regarding both conversational and analysis *and* SMMs, and (as far as I can tell) this literature has not been mathematized (yet).
As Bill Thurston put it in his much-cited article On Proof and Progress in Mathematics:
Conversation analysis formalizes methods for studying of Thurston’s model-acquisition process.
Needless to say, one of the main challenges for remote-learning education is to achieve effective model-sharing without face-to-face conversational information exchange.
Yes indeed. I’ve more than once wondered if something in the shape of M-theory, that is, concurrent perturbative (string) theories interlinked by dualities, could not be displayed as the natural form of a cognitive fixed point for a cultural process driven by a not-quite-lucid quest for consensual parsimonious explanations.
Boris, the long arduous multi-generation quest for a mathematically natural appreciation of Onsager theory provides an well-documented example of (in your excellent phrase) “a not-quite-lucid quest for consensual parsimonious explanations.”
Because our appreciation of Onsager theory has evolved more nearly to maturity than our appreciation of M theory, it is easier to extract lessons-learned from the historical process of constructing that appreciation.
Although to be sure, the math-and-physics of neither theory is fully mature, and it is even conceivable that each will someday illuminate the other.
Oh, blast the lack of preview! Hopefully this link will be OK:
———————
More seriously (because communication is a serious business), another mathematical approach would be to look for fixed points in the broader scope of conversation analysis, said fixed point being convergence to a shared mental model (SMM). As it turns out, there is a burgeoning academic literature regarding both conversational and analysis *and* SMMs, that (as far as I can tell) has not been mathematized (yet).
As Bill Thurston put it in his much-cited article On Proof and Progress in Mathematics:
Conversation analysis ingeniously formalizes methods for studying of model-acquisition process that Thurston describes.
Needless to say, one of the main challenges for on-line education is to achieve effective model-sharing without in-person
Quantum computing has its own fixed point theorem:
Grover’s algorithm.
And I’ve heard that some arch-criminals are planning a Grover-kryptonite fixed point theorem
First of all, I’d want to make sure that Google translate doesn’t cache translations, iow, that is valid the assumption that translating a particular sentence from language A to B doesn’t change the state of Google translate, relative to translating the result back from B to A. I suspect the assumption is false, and that invertibility is in fact easier to achieve in this way when translations are bad (because the initial translation result doesn’t naturally occur).
So I believe circular loops of translations involving 3 rather than 2 languages need attention.
Can fixed point theory by any chance make predictions about comparative behavior of 3-languages loops and 2-languages loop, depending on whether the system “cheats” on 2-languages loops or not?
It looks like Google does cache translations. This probably accounts for the fact that their translations to English are often better than to French for any given source text, because there are more available cached English translations.
In fact the quality of the translations seems to come from the interaction with the users, as is granted the possibility to provide your own translation whenever you don’t agree with Google’s. That’s why the English translations are better than in any other language, for there are more English speaking users who’ve contributed their own translation.
Maybe you want to judge the quality of translations using something like clustering in LSA as a metric. If the translated documents cluster like the source documents that would be good.
I was going to implement a larger-scale test of this fixed-point method on Google Translate for fun, but it appears the API it not free to use. What a shame.
The funniest experience I’ve had with Google translate is a translation of a news website in Hebrew – some particular and important word got translated to the f word e.g. the heading of one of their (probably regular) news column shows up as `We are f***d’!
There are many cases where this metric fails. For example, in German you use “sie” (plural you or they) when talking formally to a person. Since english has no such formal form, even correct translations lose this information:
“Könnten sie mir bitte die Tür öffnen” (formal)
-> “Could you please open the door for me”
-> “Könntest du mir bitte die Tür öffnen” (informal)
Which is no problem – we already knew that there is no perfect mapping between languages. The problem is, that a common incorrect translation will actually have an immediate fixed point
“Könnten sie mir bitte die Tür öffnen” (formal)
-> “Could they please open the door for me”
-> “Könnten sie mir bitte die Tür öffnen” (plural)
In fact, you gave an example of a bad but metric-perfect translator yourself. A simple one-to-one dictionary translator will be perfect according to your metric.
“Könnten sie mir bitte die Tür öffnen”
-> “Could they me please the door open”
-> “Könnten sie mir bitte die Tür öffnen”
Indeed, the metric needs to be able to penalize one-to-one translations, as well as many-to-one gaming of the system: Translate every word to the word “No” for the other language, for example. Unless there is a reversible process in there where you can extract the original sentence, or something really close to it, then the translator is of little use. But, I think Dick mentions something to that effect.
A fixed-point theorem with a plethora of applications in TCS is Tarski’s fixed point theorem. For example, the characterization of largest fixed points it provides provides the foundations for co-inductive reasoning, which can be summarized in the motto: “An object is good unless it can be proved to be bad (in a finite number of steps).”
IMHO, that theorem would be a worthy addition to the list of main fixed point theorems.
How do you rule out the case where E and D are identity maps?
There’s a website which basically does what you’re proposing with English and Japanse for entertainment purposes: http://www.translationparty.com
It’s been around for quite some time now.
I’m learning German here: duolingo.com, and I’m starting to really understand why it’s so difficult to program a machine to translate one language to another. Take the simple German sentence, “Kosten wir!”
According to duolingo.com, this sentence can be translated to English as “Let’s sample”, “Let’s take”, and “Let’s caress”. So when a German-to-English translator sees the sentence, “Kosten wir”, how is it supposed to know which translation to use? The only way is from the context. But how can a computer understand the context? This takes a lot of sophistication. It seems to me that the best way would be for the computer to use simple statistics of correlation between different words based on an enormous number of varied texts and not try to program the computer to “understand”.
How is this done in practice today?
Is that really distinct from understanding a given piece of language?
I think so. A statistical translator wouldn’t know what to do with a sentence like “Colorless green ideas sleep furiously”. http://en.wikipedia.org/wiki/Colorless_green_ideas_sleep_furiously
In the case of Google, translation quality relies mainly on user input. The issue’s about how the database of sample translations has been organized so as to manage efficiently the statistics of correlation. But I guess their keep their algorithm secret… 🙂
But would it also translate idioms?
You could get a perfect back-translation, but a native speaker of the language wouldn’t get what you meant.
For example, “when pigs fly” is “quand les poules auraient les dents” in french.
When chickens will have teeth.
The best dictionary is the identity dictionary? (A bad joke unless we cannot automatically verify the translation is semantically correct, in the target language.) When you say that we measure how far the (re-)translation is from the original, you mean semantically how far? Both your two measures seem to involve human interaction.