Branch And Bound—Why Does It Work?
One of the mysteries of computational theory

|
| source—our congratulations |
George Nemhauser is one of the world experts on all things having to do with large-scale optimization problems. He has received countless honors for his brilliant work, including membership in the National Academy of Engineering, the John Von Neumann Theory Prize, the Khachiyan Prize, and the Lanchester Prize. He has been a faculty member at Georgia Tech for many years in the ISyE school, which has been one of the top industrial engineering schools in the world for years—these events are certainly correlated.
Today I wish to talk about a class of algorithms that are used all the time in practice, that George has used in his research for decades, but that have eluded our making any definite statements about their theoretical performance.
Recently at Tech there was a lunch meeting with some of the theory faculty and some of the ISyE faculty, including George and also Arkadi Nemirovski. The discussion was about a joint project that is in progress at Tech, which is a whole other story.
During the conversation I was asked what I thought were some of the biggest open questions in optimization. This is not my area of expertise—but that never stops me from having an opinion. I pointed out several questions that I thought were quite important, and then added that perhaps the biggest mystery to me was why we have such difficulty in proving anything about sequential algorithms like branch-and-bound.
Nemhauser smiled and said,
“I have always wanted to prove a lower bound about the behavior of branch and bound, but I never could.”
It was cool to hear that one of the world experts on this method agreed with me. But this lasted only a few seconds, since Nemirovski immediately took exception with my position. My attempt to explain to him what I meant by a lower bound got nowhere. George just smiled during this, and the conversation moved on to another topic.
I do think that there is a real question here: why is one of the most powerful methods for solving hard optimization problems beyond our ability to really understand? I am with George on this—with all due respect to Nemirovski, I think he cut off the search too early.
Let’s talk about that after first defining what branch and bound is.
Branch And Bound
Branch and Bound (BB) is a general method for finding optimal solutions to problems, typically discrete problems. A branch-and-bound algorithm searches the entire space of candidate solutions, with one extra trick: it throws out large parts of the search space by using previous estimates on the quantity being optimized. The method is due to Ailsa Land and Alison Doig, who wrote the original paper in 1960: “An automatic method of solving discrete programming problems.”
Typically we can view a branch-and-bound algorithm as a tree search. At any node of the tree, the algorithm must make a finite decision and set one of the unbound variables. Suppose that each variable is only 0-1 valued. Then at a node where the variable 

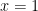

|
|
src |
In the BB case the algorithm tries to avoid searches that are “useless.” Imagine that the algorithm can prove that setting 



Search Time and Branching Factor
In many practical cases, the amount of pruning that occurs in this type of BB algorithm can be immense. This in short is why the algorithm can be so powerful. This is often expressed via the effective branching factor (EBF): the number 

For example, suppose you have the above binary tree and get the “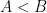

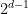
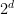
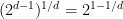

Suppose instead that you get the savings at every other level in the binary tree. Then you have branching at only half the levels, so it is as if you searched a whole tree of depth 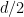
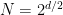

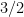

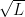
One way to express the issue of upper and lower bounds for BB is, can we give upper and lower bounds on the EBF? This is only a rough way to estimate the time, but already it is hard to do.
Why So Hard To Understand?
I think the reason that BB algorithms are so hard to prove bounds lower or upper is that they fall into a category of sequential algorithms. Of course all algorithms can be viewed as sequential—this was the source of discussion with Nemirovski, I believe. But what I mean is an algorithm that moves from state to state in a manner that is complex, in a manner that does not seem to follow any obvious path. People who have played complex games like chess can recall times when the path was especially hard to find.
I am not explaining this well, perhaps because the notion is unclear in my mind. But here is an analogy with another problem. Consider the famous Collatz conjecture, named after Lothar Collatz, who first proposed it in 1937.
Take any natural number n. If n is even, divide it by 2 to get n/2. If n is odd, multiply it by 3 and add 1 to obtain 3n + 1. Repeat the process. The conjecture is that no matter what number you start with, you will always eventually reach 1.
Paul Erdős said, allegedly, about the this conjecture:
“Mathematics is not yet ripe for such problems.”
There is something inherently sequential that makes them impossible for us, right now, to understand. I think the same behavior is at work with BB algorithms.

|
|
source for Collatz tree |
Is There a General “Proof Method”?
Ken thinks there are two reasons, one merely cultural and the other intractable—basically reflecting my reason. The cultural one is that the depth 

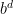
Ken’s main reason is that branch-and-bound methods always have some ad-hoc ingredients: the means of proving bounds on the quantity being optimized. The metric is usually clear, such as the cost of a tour or the size of a clique or the value of a chess position, but the means are not. The problem domain must be taken into account, especially what kind of regularities it enjoys. Other factors may be involved that enable greater savings even than bounds that have been theoretically “proved” in general. Two relevant instances are chess engines and Rubik’s Cube®.
One Fish, Two Fish…
Essentially all strong chess-playing programs are based on alpha-beta search. Two top programs now are Rybka, which is Polish for “little fish,” and Stockfish, of Norwegian roots like Magnus Carlsen, who just set the all-time (human) rating record. A “fish” usually means a poor player, but these programs seem not to mind.
Here’s the basic idea of alpha-beta: Suppose Alice and Bob are playing chess, and Alice has found that move 
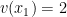
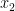
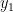
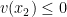
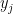
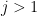
Even if we make the best initial tries, for Bob’s 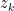
Well that’s if Alice always gets lucky. If you have no advance idea about values and have an average amount of luck, a 1982 paper by Judea Pearl—winner last March of the Turing Award—calculated the average-case EBF as 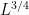
So is 6 a solid lower bound? If it were, then Garry Kasparov would never have lost to Deep Blue, and I (Ken writing this and the next two sections) wouldn’t be asked to worry about cheating with computers at chess.
…in Alpha-Beta Better Beater Battle
When faced with a need to search 8 moves ahead for each player (that’s 16 tree levels, called plies), two of the most important ideas for chess programs are don’t search 8 moves ahead and don’t move at all. First, try a “pilot search” maybe 4 or 5 moves ahead, which takes trivial time. By the regularity of move values usually not changing much at higher depths, this helps you “get lucky” with the order much of the time. It turns out that other factors favor doing all the lower-order searches 
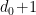
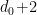
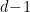

Chess programmers also employ heuristics to try to lower the effective 
This is illegal in chess but works like a charm because often Alice can thereby prove that Bob’s last move was sub-optimal as the search branch bottoms out, without having to lift a finger herself. The main hitch is that chess has a feature called Zugzwang whereby Alice passing would be an unfair advantage. But it usually happens only in endgame positions with lower
“Now, here, you see, it takes all the running you can do, to keep in the same place.”
Instead, in chess programs, Alice often progresses best by not moving. This null-move idea takes the most basic assumption one might make about expanding nodes in a lower-bound proof, and knocks it off the board.
Some chess engines prefer other tricks, and there are other tradeoffs—indeed the tricky position covered here induced one commercial programmer to change his pruning strategy (he called it a bug-fix and thanked me). While alpha-beta itself is always worst-case correct, these other ideas take some risks. But the upshot is that EBF’s under 2.5 are routinely achieved. The engines battle over decrements of 0.1 or even 0.01 in the EBF, but they’re significant because they’re in the base of an exponent.
Proofs and Rubik’s Cube
Well chess is not a simple case of branch and bound because it alternates minimizing and maximizing, and because many heuristics compromise correctness. Let’s consider Rubik’s Cube, a nice finite problem where the number of legal ‘moves’ is the same in every position, the search has a clear goal, and the only quantity being minimized is the length of the path to that goal. A 180-degree rotation counts as one move. It is literally child’s play—kids have solved random cases in under 10 seconds.
There are exactly 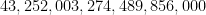

|
|
source for 20-move “superflip” position |
As the children know in their fingers, Rubik’s Cube has a natural group structure, which breaks into a chain of subgroups. Solutions must work along this chain and make yea-many moves in each link. If 
In 1997 Richard Korf applied a whole new search method called IDA* which he had invented in 1985. Instead of subgroups he identified “sub-cubes”—sub-problems that had to be solved along with the main one—that were more ad-hoc than the group decomposition. He also applied iterative deepening like a chess engine, and got … only a bunch of random cases solved within 18 moves. We now know that over 95% of positions are solvable within 18 moves, over 67% needing 18 as well. His was a better algorithm in action, but it didn’t prove an upper or lower bound.
The optimal solvers went back to the group structure, but pre-packaged the use of symmetry in a different way, and found ways to fit needed portions of the search space into separate chunks within the memory of the computers that Google allowed them to use. This still took the equivalent of 35 years of time on a standard 2.8Ghz quad-core CPU.
Is there a general principle for proving good upper and lower bounds, either on solution quality or on time of search, even for a simple well-structured problem like Rubik’s Cube? That would seem a pre-req for any general theory of understanding branch-and-bound.
Open Problems
Can we explain better why BB algorithms are hard to prove anything about? Can we finally understand why they work so well in practice?
[updated and sourced figures]


Just for reference, Herbert Simon and Toshinori Munakata estimated the Deep Blue EBF as “between 4 and 5”, while these slides by Eric Hansen say that the EBF of 6 conferred by alpha-beta was good for an 8-ply search, but heuristics raised it to 12-ply. Robert Houdart, programmer of today’s top-rated Houdini 3 engine, says here, “a low branching factor is obtained through a number of pruning and reduction techniques: null move, LMR, etc.” LMR, “late move reduction,” avoids doing a full-depth search on moves for Alice that looked poor in previous rounds—unless they have a chess tactical feature that might promise an upswing in value.
Just a thought …
Lost the picture …
See image here.
There is a Case Analysis-Synthesis Theorem (CAST) in propositional logic that one can use like boolean expansions or truth tables, except that one can take up variables in different orders along different paths of the search tree.
“Why So Hard To Understand?” The same question may be also asked about other algorithmic paradigms: backtracking, dynamic programming, and even greedy. Recently, some of these questions were answered by the schools of Borodin and Impagliazzo. Albeit impressing, the progress is still slow. Unlike in the case of restricted circuit models. “My attempt to explain to him what I meant by a lower bound got nowhere.” Isn’t not this the explanation of the situation? Complexity theorists don’t take these things in hand because they are “dirty” (hard to formalize, and prove a lower bound). Optimizers ignore lower bounds because they are useless for “real world” problem instances.
he-he. this targets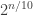 from previous post ;). What left is to map attractive NP-complete problem to BB.
from previous post ;). What left is to map attractive NP-complete problem to BB.
Excellent post. May I point to the following question, asked by myself on TCS Stack Exchange: 0-1 Linear Programming: computing the Optimal Formulation. Although it is not about branch and bound, nor about lower bounds, nor about proving hardness, it deals with optimizing a 0-1 Linear Program (i.e. what Branch and Bound has been invented for). It suggests a possible approach, namely to compute the Optimal Formulation and then to invoke whatever fast LP algorithm (like the Simplex) on it: as the Formulation is Optimal, the solution found will be integer. It’s a sort of Kansas City shuffle: when everybody looks right (i.e. bangs his head in trying to extract an as better as possible integer solution from a non-Optimal Formulation) you go left (i.e. you just compute the Optimal Formulation, and all the rest comes for free). I’m very curious to know if someone already investigated this approach (I would be very surprised if not), and what is known about it.
Is there an algebraic descripion of the problem?
That must be a photo of George Nemhauser from 40 years ago! I met him 2 years ago. He’s probably crossed 75 now.
Is there a proof (a counterexample – that is, a pathological instance) which shows that BB is exponential in the worst case?