Black Versus White Boxes
What is better than how (?)

|
|
History of filters source. |
Wilhelm Cauer was a German mathematician and engineer who worked in Göttingen and the US between the two world wars. He is associated with the term “black box,” although he apparently did not use it in his published papers, and others are said to have used it before. What Cauer did do was conceive a computing device based on electrical principles. According to this essay by Hartmut Petzold, Cauer’s device was markedly more advanced and mathematically general than other ‘analog devices’ of the same decades. He returned to Germany in the early 1930’s, stayed despite attention being drawn to some Jewish ancestry, and was killed in the last days of Berlin despite being on the Red Army’s list of scientists whose safety they’d wished to assure.
Today Ken and I wish to talk about black boxes and white boxes, no matter who invented them, and their relation to computing.

|
|
src |
In computing a black box is a device that given an input returns an output, but we do not get to see inside the box. We only get the output, we do not get any idea how the box computed the value. In a white box, we get to see all of the steps taken in computing the output. Probably better names would be an opaque box and a transparent box. But black and white are the most popular names.

|
|
BB/WB testing source |
The devices built by Germany’s great computing pioneer Konrad Zuse can be viewed as “white boxes,” because he devised an entire programming formalism to control them. He even wrote a computer chess program in his Plankalkül, in 1941 long before the work of Alan Turing and Claude Shannon and others, but chess was hardly a priority in those years.
What and How
Another way to think about black and white boxes is to notice the parallel with “what” and “how.” In English we use “what” to mean the goal, and “how” to mean the method for reaching the goal. A quote from a site on selling products is interesting:
“What” is the end goal, it’s directional. “How” is the journey…
We have edited this slightly—caps to bold.
A Measure Of Complexity
I propose that we can use the issue of what vs. how as a measure of complexity. Problems that force us to look inside a box are much harder—if not impossible—then those where we can avoid this.

We see the what/how divide all the time in physics. The famous Newtonian law of attraction between two masses,

is a perfect example of what. Issac Newton had no idea why this works—how it works. Albert Einstein, in his discovery of General Relativity, showed that the Newtonian formula was only an approximation. His field equations replace the above to explain more accurately the what of how gravity works. The theory successfully predicts many effects that show it is a refinement of Newton’s. Some are: gravitational redshift, light bending by gravity, and the anomalous perihelion shift of Mercury. I would argue that we still have no idea of how gravity works. Yes general relativity says that masses cause space-time to curve, and the curvature directs their motion. In particular, this helps explain how gravity acts at a distance. But does this really answer the how question?
The greatest example for the hundred years since general relativity has been quantum mechanics. No one knows how it works, but it yields incredibly accurate agreement of measurement with prediction for quantities on incredibly small scales. There are many competing white-box attempts to explain it, but this black-box slogan still holds sway:

|
|
Product source |
We see what vs. how all the time in cryptography. Indeed many crypto results view protocols as black boxes and use this routinely. Sometimes there are cases where the how is important, where white boxes are needed in crypto. But these are the exception, and usually are the harder cases.
The physical idea of devices as black boxes enters into quantum protocols. Even there, some theoretical arguments can be defeated when it comes to implementations, if light can be shined inside the box to make it white. This is quite literally the basis of an attack with a “blinding laser: that we wrote about here.
We see the what/how divide all the time in programming. The whole point of abstraction, of modules, of object-oriented programming is to hide the how from us. Programmers are happy to use code written by other programmers, the what, without any understanding of the how. It is vital that a change in the how not disturb many other components in a software system that are relying on the what.
We also see the divide in mathematics. We can use the famous classification of finite simple groups, this is the what. We need not, probably cannot, worry at all about the how. The number of experts in group theory that understand all of the how are few.
Yet applications abound of using this theorem. Right now there is great difficulty in understanding the volumnious development of intra-universal Teichmüller theory on which Shinichi Mochizuki’s claimed proof of the ABC Conjecture and several other conjectures is based. Some hope that further experience with the what of its implications will help to verify the how of Mochizuki’s proofs.
Lower Bounds and How
We see the what/how all the time in lower bounds in complexity theory. The difficulty is that in many lower bounds we must treat the computation as a white box. This forces us into the how situation which is much harder than when we can view computations as black boxes—the what case.
This shows up already with the simplest kind of circuit black box we can imagine, a comparator gate. It has two inputs 

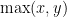

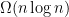

Consider a truly general circuit lower bound. All the results—all?—require a white-box view of the circuit. The whole reason that circuit lower bounds are so difficult is that we must argue, it seems, that the circuit cannot do something. And to do that we must get into the details of how a circuit can work. Sometimes the arguments that make full allowance for how do succeed, for example we can get lower bounds on monotone circuits and on constant depth circuits. All of these proofs require white-box arguments.
Consider a Turing Machine lower bound. These results sometimes can treat Turing Machines as black boxes. Turing’s original proof of the unsolvability of the halting problem did not depend on details of the machines. Okay this is a bit tricky. He needed that any such machines could be simulated, so he did get involved with the how. However, the details of how were not relevant to the core argument, just that there was some way to simulate the machine.
The same weak dependence on how is used in many other complexity results since Turing’s work. The usual diagonalization proofs use only weak information about the how. The myriad relativization results, typified by the existence of oracle sets 



Open Problems
Which side are you on—how do you read our ambiguous subtitle?
Perhaps there is a general way to morph black boxes into white, giving a theory that can provide “fifty shades of grey” in computation?


Historian Lily Kay’s survey The Molecular Vision of Life introduces the reader to a vast “White Box” literature associated to the medical goal of healing-through understanding. Quotes to this effect include remarkably many quantum physicists:
The near-identity of these three passages shows how prevalent White Box biomedical ideas had already become — among top-rank physicists at least — in the 1940s and 1950s! Needless to say, the White Box philosophy of Pauling, Langmuir, von Neumann, Wiener, and Feynman is nowadays the dominant paradigm of molecular, as exemplified by the Human Genome Project and its still-burgeoning successors.
Now in the 21st century, a similar White Box paradigm is (arguably) coming to the fore in complexity theory, by essentially the path that Feynman’s reasoning suggests:
Here the common-sense point is that conditional complexity theory — by which is meant 20th century “Black Box” complexity theoretic results that are conditional upon unproved (and possibly unprovable) oracle-based complexity classes — may yield in the 21st century to an emerging oracle-free “White Box” complexity theory; whose results are seemingly tougher to derive (at least with present knowledge!) yet have the considerable practical advantage of being conditional only upon the axioms of PA/ZFC (etc).
That is why a pair of Gödel’s Lost Letter columns that asked (in succession) “What is your favorite White Box/Black Box Complexity Theory Result?” would be read with interest by me and many!
A starting-point for debate might be
Hopefully such a debate would catalyze plenty of thoughtful remarks on both sides. Which would be FUN and GOOD (for young researchers especially)!
John
Thanks again for your thoughtful comment. I will talk to Ken about this very issue.
More Gödel’s Lost Letter discussion of Black Boxes versus White Boxes would be terrific.
Michael Freedman’s article “Complexity classes as mathematical axioms” (2009) suggests (implicitly) some themes for at least one such GLL article:
Concretely we can ask: What White-Box axioms might we embrace, that would require no changes whatsoever to the Black-Box Complexity Zoo?
For example, might we specify a White-Box “Middle Earth” in which the Extended Church-Turing Thesis (ECT) is true, in the sense (for example) that the Standard Model of QFT is stated to be integrable with PTIME resources?
This would naturally — yet provocatively … unite the mathematical challenge of proving the consistency/inconsistency of the White-Box axioms, with practical Black-Box challenges like demonstrating the feasibility/infeasibility of scalable ShorFactoring and/or BosonSampling.
The discourse associated to this Black-versus-White challenge (as said above) would be FUN and GOOD for young researchers especially. That’s one way to appreciate Michael Freedman’s article, at any rate.
Here are a couple more references relating to “White Box” (unconditional) versus “Black Box” (conditional) STEM research.
The first is from “Interview with Jean-Pierre Serre” (Notices of the AMS, 2004)
Nowadays we commonly regard the Hodge Conjecture and/or the P≠NP Conjecture as boxes that we hope someday to open, while meanwhile proving Black Box (conditional) theorems. And yet mathematicians like Serre and Freedman (and Juris Hartmanis and many more) are right to remind us of the very real mathematical possibility that boxes like “Hodge” and “P≠NP” may perhaps have no interior contents.
Needless to say, medical research and engineering alike are White Box cultures, in which preferable to understand how patients get well and preferable also to design and operate devices whose workings we understand … in the sense that observation, simulation, optimization, control, and treatment planning all are computationally feasible (with PTIME resources).
From a medical point of view, however, there’s not much sense waiting around for the boxes to be opened (or proved to be unopenable). As David Deutsch remarks in his (wonderful!) TED Lecture A New Way to Explain Explanation (2009):
In medicine particularly, Deutsch’s tragedy is keenly felt … because the world’s need for healing is unbounded.
So perhaps we needn’t wait for the inscrutable to be scrutinized? Because fortunately (for young researchers and entrepreneurs especially), there’s plenty that humanity has already accomplished in prior centuries — in math, science, medicine, and engineering — and much more that we can accomplish in the present century, without opening these mysterious mathematical boxes … and without assuming even that these boxes are openable in principle.
Conclusion At present we don’t know whether boxes like “Hodge” and “P≠NP” are black, white, or unopenable. Moreover, we don’t know even which STEM questions (if any!) depend crucially upon the status of these boxes. And the most important (and mysterious) consideration of all, is that these mysteries seemingly are not substantially obstructing sustained rapid progress that spans many STEM disciplines. And so this present ignorance is GOOD and FUN … for young STEM researchers especially.
In further regard to the (inexhaustible) theme of Black Box/White Box mathematics, Nicholas Katz is quoted in Allyn Jackson’s Comme Appelé du Néant — As If Summoned from the Void: The Life of Alexandre Grothendieck (2004)
If the challenge of converting Black Boxes into White Boxes fosters the creation of “incredible new tools” (in Katz’ phrase), perhaps the reverse process also is viable? Vladimir Arnold’s essay Polymathematics: is Mathematics a Single Science or a Set of Arts? (2000) advocates this dual path as follows:
Emphasis as in Arnold’s article.
Conclusion 21st century complexity theory and quantum physics alike are blessed with abundant Black Box conjectures, that researchers struggle unceasingly to rewrap as White Box theorems. And these disciplines are blessed too with an ever-expanding set of amazing findings, both mathematical and experimental, that researchers are struggling mightily — not always successfully — to categorize neatly into traditional 20th century Black-and-White boxes.
There is plenty of room here for many styles of 21st century STEM research … and plenty of scope for Gödel’s Lost Letter essays too. Good!
This post is very curios for me: in 1990s I wrote a paper about black and white boxes in OOP and that very often we need transparent class in spite of OO encapsulation principle. I sent the paper to one programming journal, but it was rejected. There is no state of art — they said 🙂
mt2mt2
So what happen to the paper? If still have would like to see what you had to say. In programming when I did more than now, I often had my team recode something. The reason was we were afraid that the available routines would have bad behavior at the “corner” cases, and so we redid stuff. I imagine related to your issues.
What happen to my paper? — Well, I did it! I had introduced Open OOP (OOOP) – please, see OMG newsletters: M.Trofimov, OOOP – The Third “O” Solution: Open OOP. First Class, OMG, 1993, Vol. 3, issue 3, p.14. Also, my letter about OO Languages future to the Byte editor may be interesting: M.I.Trofimov, The End of Pascal?, BYTE, March, 1990, p.36. – Now you can compare and estimate my predictions 😉
What is computing? A computer is an advanced counting machine, but perceived as intelligent as interactivity and artificial intelligence are built into it. Jesus says something strange in Matthew 10: But the very hairs of your head are all counted. Therefore do not fear!!!
What?? Is the number of hairs on our heads counted?? Are we in a computer? How much RAM in this computer? Are all data stored in a black box or hole?
How many of you have played Call of Duty? Many have found that there was more than one ”glitch” in the game. If you do things the right way, then you can get into a super mode where you can do amazing things. (I have not played much, but been coach for my son).
The programmer has thus added a backdoor (or failure), where someone can get into a sort of supermode. God programmed the earth and the sun, moon and stars. They all are following math calculations. But there is a backdoor. The stories of Joshua and Hezekiah shows that the sun can stop or go backwards. Only the programmer knows all the back doors and all hidden opportunities.
Anyway, our computers are ”stupid” and can not handle real calls. But when you pray to God, the biblical author, you talk to some of the highest intelligence and power. If your heart is set correctly (honest and sincere), He will answer you in His own way.
http://wp.me/p3uvTQ-l
I am only a pointer to a pointer, if you understand what I write about.
hi RJL. this indeed deep mysterious dichotomy of “how” vs “why” is also seen in a neat/great/influential book introducing programming that was used in my freshman software engr class, “structure & interpretation of computer programs” by abelson & sussman (MIT) where they meditate on the subject a bit (free online edition). have been pondering this same deep zen question in mathematics/comp sci for over 2 decades & agree its quite fundamental and indicative of some massive future research attn/energy/motion/expansion/momentum in the area. it seems to be a unifying framework. gotta write a blog on this myself sometime.
to me, automated theorem proving is shedding answers on this question/challenge. have been collecting recent interesting research leads in this area. to me attacking undecidable problems lies at the heart of this question. am also very interested in “answer set programming” (similar to solving SAT equations but more sophisticated) which has the ability to transform how questions into why answers. there was also a recent paper demonstrating this technique by finding record breaking sorting circuits via SAT solvers & think this is just the beginning of this type of attack/research program. some more details in tcs.se chat hope to hear from anyone interested on the subj.
I think the theorems of Rice demonstrate this difference quite well. They totally make clear the situation of a what. But there is no result like that for the corresponding how.
Reblogged this on Heapkhim's Blog and commented:
Best Glass
A computer is an advanced counting machine, but perceived as intelligent as interactivity and artificial intelligence are built into it. Jesus says something strange in Matt 10: But the very hairs of your head are all counted. Therefore do not fear !!!
What ? ? Is the number of hairs on our heads counted ? ? Are we in a calculator ? How much memory in this machine then?
How many of you have played Call of Duty ? Many have found that there was more than one ” glitch ” in the game. If you do things the right way , so you can get into a super mode where you can do amazing things. (I have not played much , but been coach for my son).
The programmer has thus added a backdoor (or failure ) , where one can get into a sort of super mode. God programmed the earth and the sun , moon and stars. The following math courses. But there is a backdoor . The story of Joshua and Hezekiah shows that the sun can stop or go back . Only the programmer knows all the back doors and all hidden opportunities.
Anyway, our computers are ” stupid ” and can not handle real calls. But when you pray to God , the biblical author, talks to some of the highest intelligence and power. If your heart is set correctly ( honest and sincere ) , He will answer you in their own way .
http://wp.me/p3uvTQ-l
Reblogged this on 코리아카지노 우리카지노 다모아카지노 ∽⊙▶ http://WWW.JOWA9.COM ◀⊙∽ 월드카지노 썬시티카지노 에이플러스카지노 ∽⊙▶ http://WWW.JOWA9.COM ◀⊙∽윈스카지노 정선카지노 태양성카지노 ∽⊙▶ http://WWW.JOWA9.COM ◀⊙∽강원랜드카지노 온라인카지노 인터넷카지노∽⊙▶ http://WWW.JOWA9.COM ◀⊙∽바카라카지노 and commented:
코리아카지노 우리카지노 다모아카지노 ☆ http://WWW.TONK6.COM ☆ 월드카지노 썬시티카지노 에이플러스카지노 ☆ http://WWW.TONK6.COM ☆ 윈스카지노 정선카지노 태양성카지노 ☆ http://WWW.TONK6.COM ☆ 강원랜드카지노 온라인카지노 인터넷카지노 ☆ http://WWW.TONK6.COM ☆ 바카라카지노 ~princemarchmraz~
Reblogged this on victormiguelvelasquez.
Thanx fun reading
Reblogged this on The International Blogspaper.
Reblogged this on tjphull.
Reblogged this on emmadol's Blog.
Black Box Vs White Box!
Useful for this post!
#wordpress!
Really interesting piece. Ian x
Reblogged this on The Machinehead Chronicles.
Reblogged this on STOKERLAND and commented:
I just thought this might be of interest to certain folk. Test reblog.
I don’t understand how there can be a meaningful “how” in Physics. If one asks “how”, that only says something about his subjective taste. For example, one might well satisfy oneself with Newton’s theory and not interrogate any further. Or one might find such satisfaction at Einstein’s theory. On the other hand, there could be a finer “particle exchange” type theory of gravity and one could be dissatisfied even with that (“Why should those particles get exchanged?”). In my opinion, the only objective standard for a theory is its agreement with observations along with its economy in axioms. Beyond that, I believe in “Shut up and calculate”.
Reblogged this on ahmadrmahfooz.
Reblogged this on maha's place.
Reblogged this on nexsean and commented:
Black is original