Three From CCC
Comments on three papers from the Conference on Computational Complexity

Michael Saks is Chair of the Program Committee of this year’s Conference on Computational Complexity (CCC). He was helped by Paul Beame, Lance Fortnow, Elena Grigorescu, Yuval Ishai, Shachar Lovett, Alexander Sherstov, Srikanth Srinivasan, Madhur Tulsiani, Ryan Williams, and Ronald de Wolf. I have no doubt that they were faced with many difficult decisions—no doubt some worthy papers could not be included. The program committee’s work does not completely end after the list of accepted papers is posted, but it is not too early to thank them all for their hard work in putting together a terrific program.
Today I wish to highlight three papers from the list of accepted ones.
The biggest danger in selecting three is that I will disappoint the authors of the remaining 
Of course as a PC member, Mike was not allowed to submit a paper, so it follows that he is not an author of any of the CCC papers we mention. But one of his recent papers, with Ankur Moitra of Princeton IAS, appeals to me as an example of learning from the past. Their paper analyzes an old algorithm for learning a distribution from random samples to show that it runs in polynomial time, and beefs it up to apply in more-general cases. Their proof uses linear programming duality and analyzes invertible matrices that have bad condition numbers, something Ken and I have been thinking about in connection with the Jacobian Conjecture and other matters. Their paper appeared at FOCS 2013.
Something New About Kolmogorov Complexity

They study the Kolmogorov complexity of 
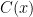


Their cool result is that given a string 

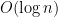
Thus using only few random bits it is possible to do tasks that cannot be done by any deterministic algorithm regardless of its running time.
Very neat.
Progress on Group Isomorphism
Group isomorphism for groups defined by multiplication tables (
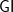
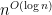
A curious consequence of the classification of finite simple groups is that isomorphism for simple groups is easy—in polynomial time. This is because finite simple groups are all 
So the “hard” cases are all groups that have non-trivial normal subgroups. Suppose that 



The group extension problem is all about how a subgroup sits inside a larger group. And cohomology is one tool that can be used to understand this.
In order to make further progress on group isomorphism the authors believe—I think correctly—that much deeper properties of groups must be brought to bear on 
Note, the bound is still super-polynomial. The exponent still is unbounded, but as someone who has thought too often about this problem, I can aver that going from 

PIT and Polynomial Factoring
The title is direct and almost needs no comment. They prove that polynomial identity testing (PIT) is equivalent to factoring of polynomials over many variables. One fact they use is the—as they say—amazing fact that if a polynomial 




They also use the famous Hilbert Irreducibility Theorem. Actually they use an effective version of it. I thought rather than outline their proof, which is so carefully explained in their paper, that I would instead say something about this theorem.
Suppose that 
Must there be a rational
so that
remains irreducible?
The answer is yes. And it generalizes to multiple variables and to other fields, but not all. Indeed a field with this property is called—you guessed right—a Hilbertian field. Essentially a Hilbertian field is the opposite from being algebraically closed: the complex numbers are not Hilbertian. Even further there is interest in what subsets of the rationals can be used and still leave 
Open Problems
Some obvious questions arise in regard to each paper. Can we use the list of descriptions of a string


Regarding Kolmogorov complexity: why do they end up with a list of possible answers? Why can’t they just run the programs in the resulting list and see which one produces ?
?
Perhaps the issue is that all the candidate programs potentially could produce x, but some may be shorter than others. The halting problem prevents an attempt to check whether the shorter ones suffice. Just a guess.
Dan
The point is we can run the algorithms in parallel and get the one. But they can generate the list fast. Usually, loosely speaking, we expect that the short description is a computation that runs for a very long time.
I understand that the Bauwens-Zimand result has theoretical interest from the point of view of “doing something with randomization that cannot be done deterministically”. But I am wondering whether the object computed, namely the list one of whose elements is a succint representation of x, has any interest (I am considering the computation of a succint representation of a string interesting; but from such a list, one cannot in general deduce which one is the succint representation). Could you say something about that?
Amir
I agree. I like the result, but would really like to see some neat application. At first I thought there might be some way around the fact that the list is not a single element. But my ideas do not yield anything yet.
So I agree, we need to figure out some application.
It is impossible to effectively obtain a shorter list containing the succinct representation. The paper proves a lower bound of for the size of any list obtained by a randomized algorithm (no matter how slow) that contains a representation that is within c bits from optimal. For deterministic algorithms there is lower bound of
for the size of any list obtained by a randomized algorithm (no matter how slow) that contains a representation that is within c bits from optimal. For deterministic algorithms there is lower bound of  , proved in a paper by Bauwens, Mahklin, Vereshchagin and Zimand (CCC 2013).
, proved in a paper by Bauwens, Mahklin, Vereshchagin and Zimand (CCC 2013).
Marius
I fixed the latex. Type usual dollar … dollar but add after the first “dollar” the word latex. It is. Do not ask why.