Rebooting Computing
How to beat the end of Moore’s Law

Elie Track and Tom Conte were co-chairs of the recently-held Third IEEE workshop on Rebooting Computing. Tom is a computer architect at Georgia Tech. A year ago he became the 2014 President-Elect of the IEEE Computer Society, which according to both the press release and Conte’s Wikipedia page entails that he “currently serves as the 2015 President.” I guess that is one way to stay focused on the future. Track is president of the IEEE Council on Superconductivity. A year ago he founded nVizix, a startup to develop photovoltaic power, and serves as CEO. He is also a senior partner at Hypres, a superconducting electronics company.
Today I wish to relate some of what happened last week at the meeting.
The meeting was held in Santa Cruz and had about forty participants. I was honored to be one of them. The problem we were given to consider is simple to state:
Computers are growing in importance every day, in all aspects of our lives. Yet the never-ending increase in their performance and the corresponding decrease in their price seems to be near the end.
Essentially this is saying that Moore’s Law, named for Gordon Moore, is about to end.
Well “about” is a bit tricky. Some would argue it has already ended: computers continue to have more transistors, but the clock rate of a processor has stayed much the same. Some argue that it will end in a few decades. Yet others claim that it could go on for a while longer. Lawrence Krauss and Glenn Starkman see the limit still six hundred—yes 600—years away. This is based on the physics of the Universe and the famous Bekenstein bound. I wonder if this limit has any reality when we consider smartphones, tablets, and laptops?
In 2005, Gordon Moore stated: “It can’t continue forever.” Herbert Stein’s Law says:
“If something cannot go on forever, it will stop.”
I love this law.
The Main Issues
The workshop was divided into four groups—see here for the program.
- Security
- Parallelism
- Human Computer Interaction
- Randomness and Approximation
Let me say something about each of these areas. Security is one of the most difficult areas in all of computing. The reason is that it is essentially a game between the builders of systems and the attackers. Under standard adversarial modeling, the attackers win provided there is one hole in the system. Those at meeting discussed at length how this makes security difficult—impossible?—to achieve. The relationship to the end of Moore’s Law is weaker than in the other groups. Whether computers continue to gain in price-performance, security will continue to be a huge problem.
Parallelism is a long-studied problem. Making sequential programs into parallel ones is a famously difficult problem. It is gaining importance precisely because of the end of Moore’s Law. The failure to make faster single processors is giving us chips that have several and soon hundreds of processors. The central question is, how can we possibly use these many processors to speed up our algorithms? What I like about this problem is it is really a theory type question: Can we build parallel algorithms for tasks that seem inherently sequential?
Human Computer Interaction (HCI) is about helping humans, us, to use computers to do our work. Gregory Abowd of Georgia Tech gave a great talk on this issue. His idea is that future computing is all about three things:
- Clouds
- Crowds
- Shrouds
Of course “clouds” refers to the rise of cloud computing, which is already an important area. And “crowds” refers not only to organized crowdsourcing but also to rising use of social media to gather information, try experiments, make decisions, and more.
The last, “shrouds,” is a strange use of the word, I think. Gregory means by “shrouds” the computerized smart devices that we will soon be surrounded with every day. Now it may just be a smartphone, but soon it will include watches, glasses, implants, and who knows what else. Ken’s recent TEDxBuffalo talk covered the same topic, including evidence that human-computer partnerships made better chess moves than computers acting alone, at least until very recently.
The last area is randomness and approximation. This sounds near and dear to theory, and it is. Well, the workshop folks mean it in a slightly different manner. The rough idea is that if it is impossible to run a processor faster, then perhaps we can get around that by changing the way processors work. Today’s processors are made to compute exactly. Yes they can make errors, but they are very rare. The new idea is to run the processor’s much faster to the point where they will make random errors and also be unable to compute to high precision. The belief is that perhaps this could then be used to make them more useful.
The fundamental question is: If we have fast processors that are making lots of errors, can we use them to get better overall performance? The answer is unknown. But the mere possibility is intriguing. It makes a nice contrast:
Today we operate like this:
Design approximate algorithms that run on exact processors. Can we switch this around: Design algorithms that operate on approximate processors?
I note that in the narrow area of just communication the answer is yes: It is better to have a very fast channel that has a reasonable error rate, than a slower exact channel. This is the whole point of error correction. Is there some theory like this for computation?
Open Problems
There are several theory-type issues here. What really are the ultimate limits of computation? Can we exploit more parallelism? This seems related to the class 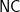


The class NC is too general since it assumes we have polynomially many processors, which in practice will never be the case as communication costs grow quadratically. This limits the number of processors to n^a for a less than 1/2.
The classes we are interested are E(\log n) and E(n^\alpha), where E(p(n)) is the class of problems that can be solved using O(p(n)) processors in time O(T(n)/p(n)) with T(n) the running time of the best sequential solution to the problem.
These classes are specializations of the classes of problems ENC and EP defined by Kruskal et al.
See the link below for a more thorough discussion of why p(n)=\log n and p(n)=n^\alpha are the natural choices:
http://link.springer.com/chapter/10.1007%2F978-3-642-38236-9_18
Hi, Alex: I’ve always had “on a back burner” to review this theory to see how well it aligns with my “Block Move” model. The model’s count of block moves captures uniform bounded-fanin circuit depth up to an additive log(n) term, so it gets the uniform-NC^k levels exactly, but also gives natural and robust sub-polynomial usage measures. For instance, one can study O(log n) block moves with O(n polylog n) overall work as a version of “quasilinear NC^1”. Insofar as my model embodies parallel-prefix-sum (fine-grained at character level), it generates efficient processor-usage patterns, so there might be some correspondence.
Interesting. I should point out that real life RAM machines seem to be better modeled by a finger model cost. In this model the cost of accessing cell a then cell b is proportional to |a-b| in contrast with the max{\mu(a),\mu(b)} cost in the BT or BM models.
A recent paper examining this from an experimental perspective is:
The Cost of Address Translation
Tomasz Jurkiewicz, Kurt Mehlhorn
http://arxiv.org/abs/1212.0703
and a higher level philosophical argument justifying this model was presented by John Iacono earlier this year in Dagstuhl
http://drops.dagstuhl.de/opus/volltexte/2014/4548/
In our case, in the paper above we consider communication costs for architectures which simultaneously use shared memory as well as direct processor to processor interconnects for message passing. This corresponds to modern Intel architectures where processors are connected using a bidirectional ring AND share various levels of the memory hierarchy.
This differs from previous theoretical work in which it was often assumed that if processors were interconnected then they shared no memory as in the case of torus, grid and hypercube architectures OR if they shared memory then there was no interprocessor network as in the case of CREW/EREW/CRCW PRAMs.
Thanks! It is interesting to me to see this so current. One Q after a very quick look at the paper: by |a-b| do you mean absolute value, or the length of the relative address?
This misses the whole point of the RAM model and other simplified computational models. They are designed to let one write programs which have optimal (or if it doesn’t exist…speedup theorem…arbitrarily good) time complexity for solving the problem.
These model’s are specifically designed to capture the ASYMPTOTIC behavior of an idealized computer with INFINITE memory. So whatever happens to a finite initial segment of the algorithm’s behavior is irrelevant.
Besides, the address translation table and lookup functions are inherently designed to work on a fixed sized address space. Do you know what a pain it would be to work out a generalized version where you can access arbitrarily many memory cells? Moreover, you wouldn’t get any advantage out of doing so anyway.
—-
No one should object that things like big O complexity and the like aren’t the best predictor of real world efficacy. This blog has covered this topic ad nauseum. So the slam on the RAM model for getting things wrong is downright misleading since it’s only supposed to be correct asymptotically.
>> by |a-b| do you mean absolute value, or the length of the relative address?
The absolute value.
“communication costs grow quadratically”… this seems to be unaware of basic research/history of hypercube architecture that was designed into the Hillis connection machine years ago. there the ingenious hypercube-pattern communication scales roughly logarithmically.
In the paper above we are talking about networks of diameter O(1) which necessitate Omega(n^2) interconnects, though only 2n capacity, as per the VLB conjecture.
I vaguely remember that in the 80s there was a sort of struggle (heated at times) in the theory community regarding Parallelism: One group insisted that studying the complexity class NC is the correct path for it, while others found much interest in questions regarding “optimal speed-up” – trying to replace an algorithm needing time T with an algorithm working on A processors for S steps where A times S is approximately T.
Correct, and what several people have found out (including us) is that optimal speed-up seems to be much easier to achieve for subpolynomial number of processors. This makes NC less useful as a basis for the parallel processors. Interestingly enough the number of cores on desktops does not seem to be growing polynomially with the input size either, making this observation even more relevant.
We used approximate computing many years ago (see Analog computer in Wikipedia). But sometime it may be very useful to remember something of old fashion. And, perhaps, analog computing + nanotechnology is only way from digital computer limitations 😉 And about NP-complexity: Turing machine looks unlike adequate model for analog computer… BTW: who knows: is human brain analog or digital computer?
Also the reliability has to be add to listed four groups. Today we have very good hardware and very bad software. I think old OO Pascal is the best programming language 😉
Not sure the traditional analog/digital duality is a relevent distinction, by the way… It’s rather a way of looking at things, like proof/program, wave/particle, discovery/creation, observation/interpretation, conceptual/formal, geometry/algebra, and so on… 🙂
Discrete vs continuous is fundamental distinction: integers vs real numbers, for example. It is more important distinction than geometry/algebra…
Yes, but in both analog and digital photography you can interpret the pictures through either discrete lenses – electronic or silver pixels – or continuous ones – geometric shape, intensity of color… The integers in Pascal are all made of bytes but your mathematical tools can be continuous. It’s a global phenomenon, not restricted to quantum mechanics with waves and particles describing the same reality. I guess it’s because we can only view the world through algorithms… 🙂
In meant: the *reals* in Pascal are all made of bytes. Revealing slip…
Yes, we have no real numbers in digital computer, we only have approximate model of real numbers…
“Can we exploit approximate computing to solve traditional problems?”
When we manage to do it, I guess our so-called digital devices will have become a bit more analog…
Perhaps worth mentioning is a variant of Moore’s Law: Koomey’s Law. Koomey’s Law states that the number of computations per joule of energy dissipated doubles approximately every 1.6 years. Koomey’s Law has been holding since roughly 1950, i.e. longer than Moore’s Law. It also seems to be pretty accurate, with R^2 > 0.98.
Koomey’s Law indicates that there is a bound on improvements in irreversible computing. Such improvements must stop by about 2050, according to Landauer’s Principle.
But reversible computing may be possible…
moores law, one of the most remarkable phenomenon of the electronic age. a whole book could be written on the subj. have a big pile of links & commentary on the subj, want to write that up sometime. it has been fueled by somewhat incremental improvements in clock speed & decreasing gate size. however, there are “paradigm shifts” that could fuel it into new generations. 3d circuits (stacked) seem to be on the way, nanotechnology such as nanotubes have been shown to behave as gates, and then theres photonic gate possibilities. then there is the scifi stuff like quantum computing which seems to be progressing. so predictions of both the extension or the demise of moores law are premature…!
fyi to anyone still keeping score, did get around to writing up a survey of supercomputing & moores law here: intel + altera shift, moores law, mobile, cpu^n, future, hardware design
Y’all probably already know this, but I’m going to quote anyway 🙂 This is Kenneth P. Birman of Cornell University, in his book, “Guide to reliable distributed systems”. In a section about the disjunction between theory and practice in cloud computing, he writes:
“Meanwhile if one reads the theory carefully, a second concern arises….For example, one very important and widely cited result proves the impossibility of building fault-tolerant protocols in asynchronous settings, and can be extended to prove that it is impossible to update replicated data in a fault-tolerant consistent manner. While terms like “impossibility” sound alarming, we shall see that those papers actually use definitions that contradict our intuitive guess as to what these terms mean: for example, these two results both define “impossible” to mean “not always possible”.”
“….impossible does not mean that we cannot ever solve the problem; indeed, for these goals, we can almost always solve the problem; an asynchronous fault-tolerant decision protocol can almost always reach a decision; a replicated update protocol can almost always complete any requested update. Impossible simply means that there will always be come sequence of events, perhaps vanishingly improbable, that could delay the decision or update endlessly.”
“The distributed systems that operate today’s cloud tackle impossible problems all the time, and usually, our solutions terminate successfully. To say that something is impossible because it is not always possible seems like an absurdist play on words, yet the theory community has often done just this……….”
Also for the record whether or not allowing errors into our processors can allow us to create faster approximate computations can’t be said to be entirely a CS question. What the underlying material properties that cause errors are and how are these errors distributed matter.
However, given any approximate processor like the one you described there will be an algorithm it gives very wrong answers about.
In particular just take any chaotic system which the approximate processor sometimes makes errors in computing (with some small probability). Iterate sufficiently and by the definition of chaotic behavior you will get something very very far from the true answer with very high probability.
Now perhaps it will always be true that for some kind of fast approximation method there is some way to write algorithms so that the errors don’t blow up. I doubt it however. I do suspect that the physics does work in a way that would allow this kind of processor to speed up many kinds of computation. I’m skeptical.
I wonder if NP complete problems can even have this kind of chaotic behavior (at least properly formulated).
I have to disagree with you on several points.
First, you claim that whether or not we can use many processors to speed up our programs is really a type theory question. While this is true in a *very* trivial sense since I could embed all program logic into the types and all proofs of parallelizability into my type judgements.
What I suspect you had in mind was not arbitrary type systems but ones that relate to the data used by the program in a “natural” way and help organize the semantics not get slapped on afterwards. But I’m skeptical this is really helpful here. It might be a good way to write code in practice but usually to PROVE a result about paralizeability or other complexity like notion it’s easiest to work in the simplest system since the proof itself has to do all the nitty gritty work of verifying the details anyway.
I mean do you know any results about matrix multiplication or the like which rely on type theory to show the problem has a solution at least so-and-so parallelizable? Usually it’s not needed since the work the types help with in generating correct code is already duplicated in the gritty proof details verifying the the parallel time complexity.
—
Also there may well be things that don’t stop but don’t go on forever (open interval). It should be if something can’t continue forever there is a time after which it no longer occurs.
He said “theory-type”, not “type theory”.