Lint For Math
Can we remove simple errors from math proofs?

|
|
simple-talk interview source |
Stephen Johnson is one of the world’s top programmers. Top programmers are inherently lazy: they prefer to build tools rather than write code. This led Steve to create some of great software tools that made UNIX so powerful, especially in the “early days.” These included the parser generator named Yacc for “Yet Another Compiler Compiler.”
Today I (Dick) want to talk about another of his tools, called lint. Not an acronym, it really means lint.
Steve was also famous for this saying about an operating system environment for IBM mainframes named TSO which some of us were unlucky enough to need to use:
Using TSO is like kicking a dead whale down the beach.
Hector Garcia-Molina told me a story about using TSO at Princeton years before I arrived there. One day he wrote a program that was submitted to the mainframe. While Hector was waiting for it to run he noticed that it contained a loop that would never stop, and worse the loop had a print statement in it. So the program would run forever and print out junk forever. Yet Hector, because of the nature of TSO, could not kill the program. Hector went to the system people to ask them to kill his program. They answered that they could not kill it until it started to run. Even better: the program would not run until that evening—do not ask why. So they could not kill it. But the evening crew could once it started. So they left a handwritten note to kill Hector’s program later that night. A whale indeed.
Lint
Steve’s lint program took your C program, examined it, and flagged code that looked suspicious. The brilliant insight was that lint had no idea what you were really doing, but could say some constructs were likely to be bugs. These were flagged and often lint was right. A beautiful idea.
For example, consider the following simple C fragment:
while (x = y)
{
...
}
This is legal C code. But, it is most likely an error. The programmer probably meant to write:
while (x == y)
{
...
}
Recall that in C the test for equality is x == y while x = y is the assignment of y to x. The former could be correct yet it is likely a mistake. These are exactly the type of simple things that lint could flag.
The lint program has changed over the years and now there are more powerful tools that can flag suspicious usage in software written in many computer languages. It was originally developed by Steve in 1977 and described in a paper “Lint, a C program checker” (Computer Science Technical Report 65, Bell Laboratories, 1978).
Lint For Math
I believe that we could build a lint for math that would do what Steve’s lint did for C code: flag suspicious constructs. Perhaps this already exists—please let me know if it does. But assuming it does not, I think even a tool that could catch very simple mistakes could be quite useful.
There is lots of research on mechanical proof systems. There is lots of interest in proving important theorems in formal languages so they can be checked. See this and this for some examples. Yet the vast majority of math is only checked by people. I think this is fine, even essential, but a lint program that at least caught simple errors would be of great use.
Let me give three types of constructs that it could catch. I assume that our lint would take in a LaTeX file and output warnings.


The lint program would notice that the variable 

Again note: this is not a certainty, since the former is a legal math expression.

If there is nothing before to constrain 
For some
it follows that
.
The statement may be technically true when 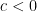
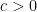

The TextLint applet page hosted by Lukas Renggli with Fabrizio Perin and Jorge Ressia does not flag the unused-variable condition, and evidently does not try to handle the other two situations. It also fails to catch 2^16 which will give 

Open Problems
Does a lint program like this—for general mathematical writing not just LaTeX code—already exist? If not, should we build one?
[added “environment” qualifier to TSO]


Please fact check before you write. TSO is not and has never been an operating system. Our is a shell, loosely analogs to bash.
Thanks, added “environment”.
There might be some opportunities for automatic proof checking as well.
It would seem that what you are looking for is Coq, and that’s only constructionist.
Although a nice idea, I think it would be very difficult to formalise use of math notation given how informal the notation is — each field takes to its own forms.
A former colleague of mine used to say that if you are suspicious of an argument and want to zero in on the point where it is wrong, then look for the words “It is easy to show that” (or a similar phrase). Even a program that mechanically searched for things like “A simple calculation shows that X” and responded with “I’m afraid I can’t quite see why X”, would catch a lot of errors.
Another point is that we have an emotional investment in our arguments, which can make it hard to look at them with the right degree of scepticism, but easier for somebody else. That suggests that a website somewhat like Mathoverflow could be helpful. The idea would be that people would post statements that they felt slightly worried about (for example because they have a proof where the calculations appear to work out but they are complicated and there doesn’t seem to be any explanation for why they should work out) and other people would be able to say, “Here is a counterexample” or “Here is a simpler proof” or “That’s known — see paper P” etc.
This is a fantastic idea. Emphasis on *idea*.
Let’s cast aside some of the frustrations I’ve had with program linters, and assume they work great.
Linting works as a concept for programming because literally everything you need to know about a program is within the program you are checking.
Mathematics, in practice, could safely be said to have “weakly typed” variables. Or not typed at all, depending how you look at it.
1. Math variables don’t need to (and I didn’t ever, really) declare them at the start of the proof.
2. The variables are not typed, which in math would be “all reals”, “complex numbers”, “integers”, etc.
Proofs generally have intuitive leaps “Without loss of generality…” and reference equations and adopt terminology and assumptions wholesale from referenced works.
Its’ my opinion that mathematical linting would be closer to automated proof checkers than anything else.
My argument mostly relies on using those fucking linters with real programming. Yes, they are useful, but even when you conform to style they generate an exceedingly large amount of spurious noise that reduces their value significantly.
Doing this would require treating math like code, which would require a formal structure, aggressive enforcement of variable usage, and a rigorous internal understanding of complex mathematics.
Eg, do you want to turn this into someting like a compiler that would look for errors?
Say, divison by zero, complex valued functions, branch cuts, actual logical errors?
Or do you want to limit it to generally trivial things?
It would definitely help for amaturs or really long proofs. Back when I used to work on large C programs, I’d use lint occasionally but because it tended to produce a lot of noise I wouldn’t use it for everything. The modern versions that you find in the newer languages and IDEs are pretty good, but there are still lots of things they complain about, that we’re willing to live with in order to meet the crazy schedules so they get ignored.
What would be neat is to mix the lint idea back with Knuth’s literate programming, to craft a tool that checks and cross-checks a big paper in LaTeX. A spelling, grammer, syntax, ambiguity, and consistecy checker. Everything but the higher level meaning …
Paul.
Unbound variables example is a bit synthetic – there are conventions for filling the gaps e.g. [1][2].
I never used any of these, but maybe formal verification tools can be the answer?
[1] http://en.wikipedia.org/wiki/Einstein_notation
[2] http://www.adt.unipd.it/corsi/Bianco/www.pcc.qub.ac.uk/tec/courses/f90/stu-notes/F90_notesMIF_3.html
A tool that rejects constructs like “while (x = y)” is a sort of randomized syntax checker, because it is right “most of the time”. So let’s imagine a randomized version of CoQ, with a more human-readable syntax. It would reject a proof that’s likely to be false, but without forcing you to formalize it entirely. Because, once you’ve managed to do this, you hardly need a proof checker anymore…
Reblogged this on Just another complex system.
Copied from http://cs.stackexchange.com/a/35791
Using automated reasoning tools is surprisingly useful for me, when I come across cited theorems where I am unsure how to “interpret” the text (http://www.iam.fmph.uniba.sk/amuc/_vol-75/_no_1/_maity/maity.pdf):
In 1974, Karvellas [ 3 ] studied additive inverse semiring and he proved the following:
(Karvellas (1974), Theorem 3(ii) and Theorem 7) Take any additive inverse semiring (S, +, ·).
(i) For all x,y∈S, (x⋅y)′=x′⋅y=x⋅y′ and x′⋅y′=x⋅y
(ii) If a∈aS∩Sa for all a∈S then S is additively commutative.
I adapted my prover9(/maze4) input files for this theorem, and was immediately shown a counter-example for the theorem as cited. Slightly modifying the assumptions produced many similar true theorems, which makes it most likely that Karvellas actually stated and proved a correct theorem, which was only cited incorrectly here. Googling for the reference of this theorem only turned up another paper which cited Karvellas even less accurate (http://shodhganga.inflibnet.ac.in/bitstream/10603/6716/6/06_chapter%201.pdf).
—
In my experience, the worst errors (not just in mathematics) occur during sloppy citing and incorrectly referencing prior work. Worse yet are reproduced sketches or images, where the important parts get messed up to a point that you ask yourself whether the creator of the reproduced sketch ever saw and understood the original sketch.
Edit 22 Jan 2018 I found out now how I should have “interpreted” the text quoted in the example below. It was my own fault, the inverse element was required to be unique. Here is my input file from 22 Dec 2014 (addinvrig.in) and here is the fixed input file from today (addinvrigFixed.in). The crucial line is
(x+(-x))+((-y)+y)=((-y)+y)+(x+(-x)).The power of the automated reasoning tools themselves is still fascinating to me, even if they cannot save me from misinterpreting other people’s writings.Reducing illogical errors in the mathematical literature is of course a commendable objective, and lint-highlighting software can help with this.
However, the broader objective of removing rhetoric from the mathematical literature is more problematic … and arguably is not even desirable.
The following collection of observations and references was stimulated by one of Michael Harris’ remarks:
Note These remarks were pulled from my Lost Worlds file … they address concerns that are universal (for your researchers especially), yet are not often discussed in the STEM blogo-sphere.
And needless to say, it is neither necessary, nor feasible, nor even desirable, that everyone share the same opinions in regard to issues of lint, rhetoric, narrative, and empathy in STEM literature and culture.
————————
Foundations for [constructing lint-free mathematical narratives] are laid-out in a thrilling (to me) four-essay sequence by mathematician / philosophers Colin Mclarty, Michael Harris, Tim Gowers, and Barry Mazur, as collected in Circles Disturbed: the Interplay of Mathematics and Narrative (2012, Princeton University Press). The four essays are:
* Colin McLarty “Hilbert on theology and its discontents: the origin myth of modern mathematics”
* Michael Harris “Do androids prove theorems in their sleep?”
* Tom Gowers “Vividness in mathematics and narrative”
* Barry Mazur “Visions, dreams, and mathematics”
Confection The above four essays (all by top-rank mathematicians, and all available on-line) are particularly commended to […] readers who plan to view this week’s “empathy-on” film release Chappie. The essay-collection’s title “Circles Disturbed” refers to the (mythic?) narrative of the death of Archimedes … which also is echoed in Chappie.
————————
“Lint” Considered Beneficial:
a Reading of the Literature
Harris’ observation that “rhetorical devices are present on practically every line” of the mathematical literature, of course applies also to [math blogosphere] essays and comments, and (here’s the point) variant parsings of these rhetorical devices largely account for the diversity of viewpoints expressed.
Obviously, no amount of non-empathic discourse can reconcile these variant readings … contemporary feminist theory is right about this!
Question Can “doing mathematics” feasibly be realized as an “empathy-on” practice (per Frans de Waal’s Age of Empathy, 2009), as contrasted with an “empathy-off” practice (per Steven Pinker’s Better Angels, 2011)?
Answer The Mclarty/Harris/Gowers/Mazur essays (as I read them) — and Chappie too — argue that the answer is “yes.”
Summary The shift from an “empathy-off” STEM culture to an “empathy-on” STEM culture (or not) is a fundamental topic of [much math blogo-sphere] debate. If in eliminating lint, we also eliminate empathy, the result is a net loss for STEM culture.
Prediction As students increasingly appreciate — feminism-positive students especially — the public sympathy of top-rank mathematicians for empathy-on narratives, and the associated greater recruitment and greater retention of women, both will help to ensure, in coming decades, that the STEM professions continue to gain in demographic diversity and in narrative empathy. And this will be good!
@incollection{cite-key, Address = {Princeton}, Author = {Mclarty / Harris / Gowers / Mazur}, Booktitle = {Circles disturbed: the interplay of mathematics and narrative}, Editor = {Doxiades, Apostolos K. and Mazur, Barry}, Publisher = {Princeton University Press}, Title = {"Theology" ... "Androids" ... "Vividness" ... "Visions"}, Year = {2012}}There is a LaTeX package called _nag_ (https://www.ctan.org/tex-archive/macros/latex/contrib/nag) that nags you whenever it finds something suspicious in your LaTeX code. If you’re looking for somebody who would nag you whenever your calculation or proof has a suspicious step, then it won’t be of use. You simply need to run it by somebody who doesn’t take anything for granted and is not afraid to ask silly questions.
QuickChick (https://github.com/QuickChick/QuickChick) is a Coq plugin that doesn’t require you to prove your properties, but tries to numerically test them for sanity. This works great in the case of $\Pi^0_1$ sentences, but obviously not as well above that… It would certainly help a lot to have a simple “math type-checker” but the math community isn’t there yet…
On a syntactic or very shallow level I would suggest such a tool:
Verify that the conclusion actually is related to what the problem requests, or in the case of a proof, that the conclusion is what is stated as required to prove.
If your goal is prove P, and you have a proof
Q -> R
Q
:. R
that is not a proof to prove P. Just that trivial doublechecking of P and R, even just a *type*-style checking of P and R, without going into the details of Q->R would get some mileage here.
It sounds trivial, but this would have saved me 39 times that I’ve counted, and I can’t be alone.