Is It New?
How to tell algorithms apart

Edgar Daylight was trained both as a computer scientist and as a historian. He writes a historical blog themed for his near-namesake Edsger Dijkstra, titled, “Dijkstra’s Rallying Cry for Generalization.” He is a co-author with Don Knuth of the 2014 book: Algorithmic Barriers Failing: P=NP?, which consists of a series of interviews of Knuth, extending their first book in 2013.
Today I wish to talk about this book, focusing on one aspect.
The book is essentially a conversation between Knuth and Daylight that ranges over Knuth’s many contributions and his many insights.

One of the most revealing discussions, in my opinion, is Knuth’s discussion of his view of asymptotic analysis. Let’s turn and look at that next.
Asymptotic Analysis
We all know what asymptotic analysis is: Given an algorithm, determine how many operations the algorithm uses in worst case. For example, the naïve matrix product of square 
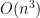

For example, the correct the count of operations for matrix product is actually

In general Knuth suggests that we determine, if possible, the number of operations as

where 





An example from the book (page 29) is a discussion of Tony Hoare’s quicksort algorithm. Its running time is 
that quicksort makes
comparisons, on average, and
exchanges, and
stack adjustments, when sorting random numbers.
The Novelty Game
Theorists create algorithms as one of their favorite activities. A classic way to get a paper accepted into a top conference is to say: In this paper we improve the running time of the best known algorithm for X from order 
But is the algorithm of this paper really new? One possibility is that the analysis of the previous paper was too coarse and the algorithms are actually the same. Or at least equivalent. The above information is logically insufficient to rule out this possibility.
Asymptotic analysis à-la Knuth comes to the rescue. Suppose that we proved that the older algorithm X ran in time

Then we would be able to conclude—without any doubt—that the new algorithm was indeed new. Knuth points this out in the interviews, and adds a comment about practice. Of course losing the logarithmic factor may not yield a better running time in practice, if the hidden constant in
This is quite a nice use of analysis of algorithms in my opinion. Knowing that an algorithm contains, for certain, some new idea, may lead to further insights. It may eventually even lead to an algorithm that is better both in theory and in practice.
Open Problems
Daylight’s book is a delight—a pun? As always Knuth has lots to say, and lots of interesting insights. The one caveat about the book is the subtitle: “P=NP?” I wish Knuth had added more comments about this great problem. He does comment on the early history of the problem: for example, explaining how Dick Karp came down to Stanford to talk about his brilliant new paper, and other comments have been preserved in a “Twenty Questions” session from last May. Knuth also reminds us in the book that as reported in the January 1973 issue of SIGACT News, Manny Blum gave odds of 100:1 in a bet with Mike Paterson that P and NP are not equal.
[fixed picture glitch at top]


There’s a spectrum of precision ranging from coarse theoretical (in P, say) to fine empirical (the algorithm ran in 1831 s). Both ends are useful, but the utility of something in the middle requires more justification. The typical justification for big-O is that it’s the finest measure which is reasonably machine model invariant, and is easy to compute. If you add the constant, the result is typically not invariant, even if you add a bunch of constants: the actual performance of quicksort may depend entirely on the number of cache misses which doesn’t occur in the list.
However, I wrote the above and then realized that discussing constants in the context of distinguishing between algorithms avoids this complaint entirely. *Any* model which produces a different constant between two algorithms is strong evidence that the algorithms are different, which is a lovely way to think about constants and their use. Thanks!
Quite right. Complexity classes are nothing but a scientific-looking notation for the current state of our knowledge about algorithms. Just because a class of problems is independent of a computing model, that doesn’t make it more real.
Thi iis one of those wagers for which we can enjoyably (to borrow the title of one of Scott Aaronson’s columns) “read the Fine Print”.
E.g., it would be logically consistent to wager that the following propositions are either both true or both false:
Prop A P and NP are not equal (e.g., in ZFC).
Prop B P and NP are not provably unequal (e.g, in HoTT).
We reason further, that the discordant world !(Prob A) & (Prob B) is scarcely credible, on the grounds that long-established mathematical edifices like the polynomial hierarchy and the complexity zoo alike would vanish. Similarly, to arrive at the discordant world of (Prob A) & !(Prob B), a considerable set of known complexity-theoretic obstructions would have to be surmounted.
Conclusion It’s a reasonably safe bet that Prob A and Prob B have the same truth-value! Which is easier to prove/disprove? Don’t ask me!
Natural Question What were the precise terms of the Blum-Paterson wager?
The world wonders. Students and wager-holders especially!
Not sure I understand. Suppose the upper bound on the running time of the older algorithm for X was 1/4 * n^3 * log(n) + O(n). It could be that the true running time of the *same* algorithm is O(n^3), which may be is what is proved in the newer paper. So, it’s not necessary that the new paper give a different algorithm…
At the end of the famous paper of Steven Cook about NP-completeness there is an interesting discussion about the measurement of complexity. Cook suggests that we could probably add more variables at the mathematical expressions that discribe complexity and that a new definition of complexity could open new roads to reshearch. Looking at your post and Cook’s paper makes me think that more reshearch about the measurement of complexity should be done.
There’s also a short video in which Donald Knuth elaborates a little bit on his answer of question 17 from the “Twenty Questions” session.
Thanks. It is mainly the “Loss of Innocence of P” answer—a phrase I heard ascribed by Person Y to Person X in the mid/late-1980s where I think X U Y = {Paul Seymour, Neil Robertson, Rod Downey, Mike Fellows, Dominic Welsh}. But I think this possibility has been digested by many people still strongly believing P != NP.
Reblogged this on Pink Iguana.
The reason computer scientists use the coarser estimate is that in most cases they have reason to believe that the answer (whether it be the running time analysis of an algorithm, upper /lower bound on some quantity) is not the “right” one and they expect improvements to follow. In such cases rushing to find the lower order terms or even the hidden constants is misguided and a classic case of premature optimization.
Once there is consensus that the right answer has been reached– a la quicksort– then this makes sense.
P = NP (PROVEN)
P = NP, in the factorization of all odd number.
The P=NP problem has been demonstrated by Andri Lopez.
It fixes a problem that existed in the computer, that stop when (N) is a prime number. It does by sterting the algorithm with a set of equations that make the computer will stop, if (N) is prime and if it is not, continue to define the two factors (N).
Published in: http://www.ijma.info Vol 6 (9) 2015
P=NP problem (proven)
P =NP, in the factorization of all odd number.
The P=NP problem has been demonstrated by Andri Lopez.
It fixes a problem that existed in the computer, that stop when (N) is a prime number. It does by starting the algorithm with a set of equations that make the computer will stop, if (N) is prime and if it is not, continue to define the two factors (N).
Published in: http://www.ijma.info Vol 6 (9) 2015