We Say Branches And You Say Choices
You like tomato and I like tomahto

Oded Green, Marat Dukhan, and Richard Vuduc are researchers at Georgia Institute of Technology—my home institution. They recently presented a paper at the Federated Conference titled, “Branch-Avoiding Graph Algorithms.”
Today Ken and I would like to discuss their interesting paper, and connect it to quite deep work that arises in computational logic.
As a co-inventor of the Federated type meeting—see this for the story—I have curiously only gone to about half of them. One of the goals of these meetings is to get diverse researchers to talk to each other. One of the obstacles is that the language is often different. Researchers often call the same abstract concept by different names. One of my favorite examples was between “breadth-first search” and “garbage collection”—see the story here.
Another deeper reason is that they may be studying concepts that are related but not identical. We will study such an example today. It connects logicians with computer architects.
One group calls the algorithmic concept choicelessness and the other calls it reduced branching. This reminds us of the old song “Let’s Call the Whole Thing Off” by George and Ira Gershwin:
The song is most famous for its “You like to-may-toes and I like to-mah-toes” and other verses comparing their different regional dialects.
Theorists have been studying various restrictions on polynomial time algorithms for years. What is interesting—cool—is that recently some of these ideas have become important in practical algorithms. The goal is to explain the main ideas here.
Labels and Choices
A binary string 

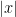


When the input is a graph 


To what extent do the output and execution pattern of
depend on the labeling used for the graph
and the order of presenting edges?
Ideally there would be no dependence. However, consider a simple sequential breadth-first search (BFS) algorithm that maintains a list 



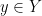

An example of giving different output—one that strikes us as a harder example—is the 


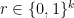
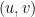





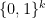
Can we reduce or eliminate the conditional branching that depends on the orderings? That is the question we see as common ground between the two concepts.
Choicelessness
The search for ways to eliminate the dependence on the linear ordering led logicians, years ago, to the notion of PTime logics. In particular they asked if it is possible to create a model of polynomial time that does not depend on the ordering of the input. It was conjectured that such a model does not exist.
For example the work of Andreas Blass, Yuri Gurevich, and Saharon Shelah studies an algorithmic model and accompanying logic called CPT for “Choiceless Polynomial Time.” We’ll elide details of their underlying “Abstract State Machine” (ASM) model which comes from earlier papers by Gurevich, but simply note that the idea is to replace arbitrary choices that usual algorithms make with parallel execution. The key restriction is that the algorithms must observe a polynomial limit on the number of code objects that can be executing at any one time. Here is how this plays out in their illustration of BFS:

The algorithm successively generates the “levels” of nodes at distances 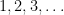



Not all polynomial-time decidable properties of graphs are so readily amenable to such algorithms, and indeed they prove that having a perfect matching is not expressible in their accompanying CPT logic even when augmented with knowledge of
The resulting logic expresses all properties expressible in any other PTime logic in the literature.
A different extension by Anuj Dawar employing linear algebra is not known to be comparable with CPT according to slides from a talk by Wied Pakusa on his joint paper with Faried Abu Zaid, Erich Grädel, and Martin Grohe. That paper extends the following result by Shelah to more-general structures with two “color classes” than bipartite graphs:
Theorem 1
Bipartite matching is decidable in CPT+Counting.
There are many classes of graphs such that restricted to graphs in that class, the power of full PTime logic with order is no greater than CPT over that class. These include graphs of bounded treewidth and graphs with excluded minors, along lines of work by Grohe that we covered some time back. For other classes the power of CPT is open.
Branches
We sense a possible and surprising connection between this beautiful foundational work of Blass, Gurevich, and Shelah to an extremely important practical program.
When a modern computer computes and makes choices this causes it generally to lose some performance. The reason is that modern computers make predictions about choices: they call it branch prediction. If the computer can correctly predict the branch taken, the choice made, then the computation runs faster. If it fails to make the right prediction it runs slower.
Naturally much work has gone into how to make branch predictions correctly. In their recent paper, Green, Dukhan, and Vuduc study a radical way to improve prediction: make fewer branches. Trivially if there are fewer choices made, fewer branches to predict, they should be able to increase how often they are right. They consider two classic algorithms for computing certain graph problems: connected components and breadth-first search (BFS). Their main result is that by rewriting the algorithms to make fewer choices they can improve the performance by as much as 30%-50%. This suggests that one should seek graph algorithms and implementations that avoid as many branches as possible.
They add:
As a proof-of-concept, we devise such implementations for both the classic top-down algorithm for BFS and the Shiloach-Vishkin algorithm for connected components. We evaluate these implementations on current x86 and ARM- based processors to show the efficacy of the approach. Our results suggest how both compiler writers and architects might exploit this insight to improve graph processing systems more broadly and create better systems for such problems.
Here are the old-and-new algorithms for BFS in their paper:

Our speculative question is, can the latter algorithm be inferred from the CPT formalism of the logicians? How much “jiggery-pokery” of the previous illustration from the logicians’ paper would it take, or are we talking “applesauce”? More broadly, what more can be done to draw connections between “Theory A” and “Theory B” as discussed in comments to Moshe Vardi’s post here?
Open Problems
Are choices and branches really connected as we claim? Can we replace the search for algorithms that make no choices with algorithms that reduce choices, branches? In a sense can we make choices a resource like time and space. And not try to make it zero like choice free algorithms, but rather just reduce the number of choices. This may only lead to modest gains in performance, but in today’s world where speed of processors is not growing like in the past, perhaps this is a very interesting question.
This is post number 128 under our joint handle “Pip” by one WordPress count, though other counts say 127 or 129. As we wrote in that linked post: Sometimes we will use Pip to ask questions in a childlike manner, mindful that others may have reached definite answers already. We have thoroughly enjoyed the partnership and look forward to reaching the next power of 2.


Reblogged this on Pink Iguana.
From a programming standpoint, eliminating what are often artifical ‘special’ cases easily simplifies the code, but also indirectly optimizes it. From an encapsulation point of view, interconnection code that is more generally reusable only ‘knows’ the bare minimum about the data it is working with (like network packets). In both cases, going up a few levels of abstraction can significantly reduce the code size, which would almost always reduce the number of branches. So, they seemed tied together in practice. Less if statements sometimes implies faster code.
Memoization on the other hand generally trades space for time, and thus requires extra code to shuffle around the intermiate values. It only works for repeated operations. So, reducing loops seems to be the opposite. More loop improvements implies faster code (and most of these will bring in at least a couple of if statements).
Makes sense in that most aspects of programming involve a delicate balancing of trade-offs.
Paul.
Trivially if there are fewer choices made, fewer branches to predict, they should be able to increase how often they are right.
I’m not sure if I buy that. Clearly some branches are more difficult to predict than others, so if one eliminates only the easy branches, this may not lead to any speed up at all.
not exactly following all this but branches are a big deal in software for another reason, they are hard to test. imagine nested conditional statements with if/ else. for levels of nesting there are
levels of nesting there are  possible code paths in general! test code (eg “junit”) attempts to “exercise” all lines of code and that becomes nearly impossible with highly conditional code. nested conditional code is also harder to maintain, and developers make errors more commonly around it (because there is psychological overhead in maintaining an internal model of all the possibilities/ paths). so yeah it makes sense to look a little more at the concept of branching in code and treat it as a “cost” in more ways than one, develop best practices, figure out ways to write equivalent code with fewer branches, etc…. also its interesting that branch prediction in cpus can be seen as a sort of AI algorithm encoded in silicon! oh, speaking of state of the art silicon advancements recently here wrt FPGAs etc… maybe some of this branch analysis is also applicable there?
possible code paths in general! test code (eg “junit”) attempts to “exercise” all lines of code and that becomes nearly impossible with highly conditional code. nested conditional code is also harder to maintain, and developers make errors more commonly around it (because there is psychological overhead in maintaining an internal model of all the possibilities/ paths). so yeah it makes sense to look a little more at the concept of branching in code and treat it as a “cost” in more ways than one, develop best practices, figure out ways to write equivalent code with fewer branches, etc…. also its interesting that branch prediction in cpus can be seen as a sort of AI algorithm encoded in silicon! oh, speaking of state of the art silicon advancements recently here wrt FPGAs etc… maybe some of this branch analysis is also applicable there?