Alberto Apostolico, 1948–2015
Our condolences on the loss of a colleague

|
|
Cropped from TCS journal source |
Alberto Apostolico was a Professor in the Georgia Tech College of Computing. He passed away on Monday after a long battle with cancer.
Today Ken and I offer our condolences to his family and friends, and our appreciation for his beautiful work.
Alberto was still active. He had a joint paper in the recent 2015 RECOMB conference, that is Research in Computational Molecular Biology. It was written with Srinivas Aluru and Sharma Thankachan and titled, “Efficient Alignment Free Sequence Comparison with Bounded Mismatches.” Srinivas is also here at Tech and wrote some words of appreciation:
[We] submitted two journal papers from this joint work this month, one on last Thursday night. … When I empathized with his situation, he would remind me that all of our lives are temporary and his situation is no different.
A full session of that conference was devoted to fighting cancer. One can only hope that some of the results of this and other theory conferences contribute to finally solving that problem.
Words and Work
Alberto’s work was on how much work one needs to do to identify notable properties of words. We mean very long words such as the textual representation of the human genome. Many “obvious” methods for processing strings do too much work. In a Georgia Tech feature several years ago, Alberto put it this way:
How do you compare things that are essentially too big to compare, meaning that the old ways of computing are no longer feasible, meaningful, or both? It’s one thing to compare and classify 30 proteins that are a thousand characters long; it’s another to compare a million species by their entire genomes, and then come up with a classification system for those species.
The theme of a special issue of the journal Theoretical Computer Science for Alberto’s 60th birthday in 2008 was:
Work is for people who do not know how to SAIL — String Algorithms, Information and Learning.
The foreword by Raffaele Giancarlo and Stefano Lonardi lists Alberto’s many contributions.
Giancarlo, who did a Master’s with Alberto in Salerno and then a PhD with Zvi Galil—our Dean at Georgia Tech—told some stories yesterday to a mailing list of their field. As an undergraduate feeling jitters attending a summer school taught by Apostolico on the island of Lipari off the north coast of Sicily, he was greatly heartened to see the leader arriving in his sailboat, named Obliqua (“Oblique”). A month ago Ken was in Sardinia—further north in the same waters—for a meeting of the World Chess Federation’s Anti-Cheating Committee, and offers this peaceful picture of the 41-foot yacht in which they took an excursion.

Stringology and Zvi
Ken and I have already talked about stringology—see here. Stringology is the study of the most basic objects in computing, linear finite sequences of letters, and is filled with deep and often surprising results. In the post we mentioned the surprise that an ordinary multitape Turing machine working in real time can print a 1 each time the first 


Alberto and Rafaelle wrote a paper about Zvi before either wrote a paper with Zvi: “The Boyer-Moore-Galil String Searching Strategies Revisited.” This paper has a Wikipedia page under the name, “Apostolico-Giancarlo algorithm.” By employing a compact database of certain substrings of the pattern string 


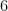
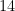
Before the paper, however, Alberto and Zvi edited and contributed to a highly influential collection of papers from a workshop in Italy sponsored by NATO’s Advanced Sciences Institute in 1984, titled Combinatorial Algorithms on Words. Many great people we know took part and wrote for the volume: Michael Rabin, Andy Yao, Andrew Odlyzko, Bob Sedgewick with Philippe Flajolet and Mireille Régnier, Andrei Broder, Joel Seiferas—and others such as Maxime Crochemore, Shimon Even, the aforementioned Guibas, Michael Main, Dominique Perrin, Wojciech Rytter, and James Storer. A contribution from Victor Miller and Mark Wegman (of universal hashing fame) titled “Variations on a Theme by Ziv and Lempel” is followed by one from the Lempel and Ziv.
Alberto and Zvi teamed on another volume in 1997, viz. the book Pattern Matching Algorithms. And yes they did co-write papers, including several on parallel algorithms for string problems—even the basic palindrome-finding problem. Their latest collaboration was a multi-author survey titled “Forty Years of Text Indexing,” which was a keynote presentation at the 2013 Combinatorial Pattern Matching symposium.
Discovery…
Alberto proved many surprising theorems during his long career. A recent example of his “out-of-the-box” approach is his 2008 paper with Olgert Denas titled, “Fast algorithms for computing sequence distances by exhaustive substring composition.” The abstract notes that the standard edit-distance measure
…hardly fulfills the growing needs for methods of sequence analysis and comparison on a genomic scale […] due to a mixture of epistemological and computational problems.
Well we have compressed the abstract with a little stringology ourselves. Recall our recent post on new evidence that the time to compute edit distance really is quadratic. Edit distance is so basic, it takes chutzpah to imagine that “alternative measures, based on the subword composition of sequences” could be both quicker and useful. The main theorem is a linear-time algorithm for a distance measure that seems to depend on quadratically-many pairs of substrings. This is a real feat of leveraging the ways words can combine. The paper goes on to show how this is programmed and applied—note also that the link to the paper is on the NIH website.
In the Georgia Tech feature we quoted above, Alberto said this about the genome:
It’s the closest thing we have to a message from outer space. We do not know where it comes from, understand very little of what it means, and have no clue about where it is going.
He went on to note the shift from pattern matching to pattern discovery—without saying how far he was in the vanguard on this.
…and Surprise
Alberto captured discovery by the element of surprise, which can be quantified statistically. One of my favorite papers of his is titled, “Monotony of Surprise and Large-Scale Quest for Unusual Words,” with Mary Ellen Bock and the above-mentioned Lonardi. It is another victory in Alberto’s perpetual battle of linear over quadratic.
Here is the idea. Given a long string 

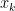

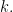



![\displaystyle z_x(y) = \frac{f_x(y) - E[Z_y]}{\sigma(Z_y)}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++z_x%28y%29+%3D+%5Cfrac%7Bf_x%28y%29+-+E%5BZ_y%5D%7D%7B%5Csigma%28Z_y%29%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
is a normal statistical z-score, where ![{E[\cdot]}](https://s0.wp.com/latex.php?latex=%7BE%5B%5Ccdot%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)




Telling which substrings are surprising still seems to face the wall that there are quadratically many substrings overall. But now the authors work a little structural magic. Suppose we have a partition ![{[C_1,C_2,\dots,C_\ell]}](https://s0.wp.com/latex.php?latex=%7B%5BC_1%2CC_2%2C%5Cdots%2CC_%5Cell%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

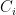



Theorem 1 Given any
of length
and an
-partition of its substrings as above, and any fixed displacement
, the sets
and
can be computed in
time.
We have skimmed some fine print about complexity of the distribution and access to the longest and shortest strings in the 
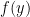
Open Problems
We could go on… But let’s stop now and just again repeat our condolences again to his family and friends. Georgia Tech will be putting together a memorial in his honor—perhaps you will be able to attend.
Alberto is missed already.
Trackbacks
- Playing Chess With the Devil | Gödel's Lost Letter and P=NP
- Complexity Year in Review 2015 • emoo.eu
- Complexity Year in Review 2015 | TRIFORCE STUDIO
- The World Turned Upside Down | Gödel's Lost Letter and P=NP
- TOC In The Future | Gödel's Lost Letter and P=NP
- Database and Theory | Gödel's Lost Letter and P=NP


I had the opportunity to get to know both Alberto and his wife, Titti, when attending events at GA Tech and in the Atlanta community. In time we became friends and I cherish the moments we spent together. Alberto possessed a sharp and inquisitive mind. Like all gifted scholars and curious thinkers, he tended to ask many more questions in conversation rather than offer simplistic solutions, especially in regard to approaching everyday problems. Alberto was also a keen observer of human behavior and a sophisticated aesthete of the finest order. He enjoyed the experience of savoring exquisite wines, viewing independent films, devouring delicious meals and debating the absurdity of Italian politics. In short, Alberto Apostolico was a gentleman of the Old School. His legacy in achieving excellence in scholarship, innovation in classroom teaching, devotion to mentorship and curiosity of spirit lives on in the generations of students who knew him as “professor.” Bravo to a life well lived!
I am sorry that it took the passing of this man for me to hear about his work, which is very interesting to me. Even a casual glance shows that his 2008 paper “Fast algorithms for computing sequence distances by exhaustive substring composition” shares much of the same philosophical perspective as work that I am presenting in September at WORDS 2015.
Here is the gist: consider the “order k de Bruijn quiver” formed by treating a word over n symbols as cyclic and taking k-grams as vertices and each instance of a (k+1)-gram as an edge in the obvious way. If two words are statistically similar, the quiver corresponding to the absolute value of the difference of the adjacency matrices will contain most of the information needed to reconstruct one word from another, and the matrix-tree/BEST theorems inform the computation of the appropriate notion of entropy, which I call “relative de Bruijn entropy”. The necessary matrix determinant, nominally taking $O((n^k)^\omega)$ time, can in principle be computed in $O((n^k) \log^2 (n^k))$ time using black-box/superfast linear algebra. Since a natural heuristic for maximally informative k is just $\log_n (word length)$, this is very close to linear time for practical problems. This dissimilarity measure captures all of the information from subwords of length $k$ and is completely ignorant of scales larger than $k$, which in many settings is a feature, not a bug.