Is The Hot Hand Fallacy A Fallacy?
A simple idea that everyone missed, and more?

|
|
Composite of src1, src2, src3
—A myth of a myth of a myth? |
Joshua Miller and Adam Sanjurjo (MS) have made a simple yet striking insight about the so-called hot hand fallacy.
Today Ken and I want to discuss their insight, suggest an alternate fix, and reflect on what it means for research more broadly.
I believe what is so important about their result is: It uses the most elementary of arguments from probability theory, yet seems to shed new light on a well-studied, much-argued problem. This achievement is wonderful, and gives me hope that there are still simple insights out there, simple insights that we all have missed—yet insights that could dramatically change the way we look at some of our most important open problems.
I would like to point out that I first saw their paper mentioned in the technical journal WSJ—the Wall Street Journal.
The Fallacy
Our friends at Wikipedia make it very clear that they believe there is no hot-hand at all:
The hot-hand fallacy (also known as the “hot hand phenomenon” or “hot hand”) is the fallacious belief that a person who has experienced success with a random event has a greater chance of further success in additional attempts. The concept has been applied to gambling and sports, such as basketball.
The fallacy started as a serious study back in 1985, when Thomas Gilovich, Amos Tversky, and Robert Vallone (GTV) published a paper titled “The Hot Hand in Basketball: On the Misperception of Random Sequences” (see also this followup). In many sports, especially basketball, players often seem to get hot. For example, an NBA player who normally usually shoots under 50% from the field may make five shots in a row in a short time. This suggests that he is “in the zone” or has a “hot hand.” His teammates may pass him the ball more often in expectation of his staying “hot.”
Yet GTV and many subsequent studies say that this is wrong. They seem to show rather that shooting is essentially a series of independent events: that each shot is independent from previous ones, and that this is equally true of free throws. Of course given the nature of this problem, there is no way to prove mathematically that hot hands do not exist. There are now many papers, websites, and a continuing debate about whether hot hands are real or not.
The Fallacy Of The Fallacy
Let me start by saying that Ken and I are mostly on the fence about the fallacy. I can imagine many situations that make it mathematically possible. For one, what if a player in basketball is not doing independent trials but rather executing a Markov process. That is, of course, a fancy way of saying that the player has “state.” Over a long term they will make about 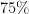
I personally once experienced something that seems to suggest that there is a hot hand. I was a poor player of stick-ball when I was young, but one day played like the best in the neighborhood. Oh well. Let me explain this in more detail another day.
Ken chimes in: This folds into a larger question that is not fallacious, and that concerns me as I monitor chess tournaments:
What is the time or game unit of being in form?
In chess I think the tournament more than game or move is the “unit of form” though I am still a long way from rigorously testing this. In baseball the saying is, basically, “Momentum stops with tomorrow’s opposing starting pitcher.”
Nevertheless, I (Ken) wonder how far “hot hand” has been tested in fantasy baseball. In my leagues on Yahoo! one can exchange players at any time. Last month I dropped the slumping Carlos Gomez in two leagues even though Yahoo! still ranked him the 8th-best player by potential. In one league I picked up Jake Marisnick, another Houston outfielder who had been hot. Marisnick soon went cold with the bat but stole 6 bases to stay within the top 100 performers anyway. The leagues ended with the regular season, but had they continued into the playoffs I definitely would have picked up Houston’s Colby Rasmus after 3 homers in 3 games. While I’ve been writing the last three main sections of this post, Rasmus hit another homer today.
The New Insight
MS have a new paper with the long title, “Surprised by the Gambler’s and Hot Hand Fallacies? A Truth in the Law of Small Numbers.” Their paper is interesting enough that it has already stimulated another paper by Yosef Rinott and Maya Bar-Hillel, who do a great job of explaining what is going on. The statistician and social science author Andrew Gelman explained the basic point in even simpler terms on his blog in July, and we will follow his lead.
For the simplest case consider sequences of 


then we must discard it since there is no

there is no chance for a hot hand since the “game is over.” Hence it seems natural to use the following sampling procedure:
-
Generate a sequence
at random.
-
If it has no head in the first
places, discard it.
-
Else pick a head at random from those places. That is, pick
such that
.
-
Score a “hit” if
, else “miss.”
Let HHS be the number of hits after 




To see why, consider 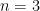



This gives HHS 
A Statistical Heads-Up
What happened is that the heads are not truly chosen uniformly at random. Look again at the six rows. There are 8 heads total in the first two characters. Choose one of them at random over the whole data set. Then you see 4 heads are followed by 
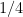
You might think the bias would quickly lessen as the sequence length grows but that too is wrong. Try 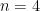


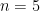










The bias persists if we condition on 



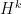
Did GTV really follow this sampling strategy? It seems yes. It comes about if you follow the letter of conditioning on the event that the previous
If you did your hot-hand study as above and got 50%, then chances are the process from which you drew the data really was “hot.”
And since the way of conditioning on misses has a bias toward 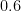
Subtler Bias Still
MS give some other explanations of the bias, one roughly as follows: If a sequence starts with
This suggests a fix, but the fix doesn’t work: Let us only condition on sequences of

This gives 


A Grid Idea
This train of thought led me (Ken) to an ironclad fix, different from a test combining conditionals by MS which they refer to their 2014 working paper. It simply allows only one selection from each non-discarded sequence, namely, testing the bit after the first 

That this is unbiased is easy to prove: Given 
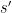

Break up the data into subsequences
of any desired lengths
. The
consecutive “hits” in the first
places, choose the first such sequence and test whether the next bit is “hit” or “miss.”
The downsides to putting this kind of grid on the data are sacrificing some samples—that is, discarding cases of 
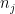
A larger lesson is that hidden bias might be rooted out by clarifying the algorithms by which data is collated. Researchers count as part of the public addressed in articles on how not to go astray such as this and this, both of which highlight pitfalls of conditional probability.
Open Problems
Has our grid idea been tried? Does it show a “hot hand”?
Update (10/18): The idea is apparently new, though as we admit in the post it is “lossy.” Meanwhile this has been covered in the Review section of the Sunday 10/18 New York Times, which in turn references and gives a chart from this post by Steven Landsburg on his “Big Questions” blog.
Trackbacks
- 2 – Is The Hot Hand Fallacy A Fallacy? | Exploding Ads
- October Links and Activities | Mental Wilderness
- Sportswriting and the Humanities | The Spiel
- Bias In The Primes | Gödel's Lost Letter and P=NP
- Blac Chyna & Would You Let Your Woman Ride for You? – Dickie Bhee on the Streetz
- Hot Hands and Tuesday’s Children – Study Score Calc
- Momentum isn’t magic – vindicating the hot hand with the mathematics of streaks ‹ King James
- Momentum isn’t magic – vindicating the hot hand with the mathematics of streaks | Complete World News
- Momentum isn’t magic – vindicating the hot hand with the mathematics of streaks – TSS
- The Science of Being 'In the Zone' - Lila Hafner
- March Madness: The Science of Being 'In the Zone' - Latest celebrities gossip and world news updates
- Momentum isn’t Magic: Vindicating the ‘Hot Hand’ with the Mathematics of Streaks
- Hot Hand Fallacy: When Randomness perceived us non-randomness - Do It Like Plato
- He’s heating up, he’s on fire! Klay Thompson and truth about hot hand NBA – Lo Chun Ming
- He’s heating up, he’s on fire! Klay Thompson and truth about hot hand NBA | Binkily
- He’s heating up, he’s on fire! The truth about the hot hand in the NBA | Sportazine
- He’s heating up, he’s on fire! The truth about the hot hand in the NBA – Sports News
- He’s heating up, he’s on fire! Klay Thompson and truth about hot hand NBA – syahmiidea
- He's heating up, he's on fire! Klay Thompson and truth about hot hand NBA - Sports News Board
- He’s heating up, he’s on fire! Klay Thompson and truth about hot hand NBA – Other Sports News
- He’s heating up, he’s on fire! The truth about the hot hand in the NBA - SportsFan 100.5 Central Wisconsin's Home for ESPN Radio, Wausau, Stevens Point, Wisconsin Rapids, Marshfield
- He is heating up, he is on hearth! Klay Thompson and fact about sizzling hand NBA – Hoops – BasketballMyLife.com
- He’s heating up, he’s on fire! The truth about the hot hand in the NBA | KennyWadeHipHop.com | The Latest News and Sports Updated Daily
- He’s heating up, he’s on fire! The truth about the hot hand in the NBA | Sports News 24/7
- He’s heating up, he’s on fire! The truth about the hot hand in the NBA | Magical Newspaper
- He's heating up, he's on fire! Klay Thompson and truth about hot hand NBA | Breaking News Wiki
- 💢 He's heating up, he's on fire! The truth about the hot hand in the NBA ⋆ 💢 Trendual.com
- He's heating up, he's on fire! The truth about the hot hand in the NBA - Excluto Sports
- He's heating up, he's on fire! The truth about the hot hand in the NBA – Game Day Sports Picks
- He's heating up, he's on fire! The truth about the hot hand in the NBA – Free Game Day Picks
- Hot Hand Fallacy: randomness perceived as non-randomness - Do It Like Plato
- Is There Momentum in Chess? | Gödel's Lost Letter and P=NP
- He's heating up, he's on fire! Klay Thompson and truth about hot hand NBA (From ESPN.com) | Jeremiadus
- The Breakthrough Result Of 2019 | Gödel's Lost Letter and P=NP
- The Breakthrough Result Of 2019 - 2NYZ
- Hot hand fallacy - new study shows momentum is math not magic
- Daniel Kahneman, 1934–2024 | Gödel's Lost Letter and P=NP


I think some of the subtle bias problem stems from the “hot hand” focus and could be avoided by posing the question as whether hot and cold “streaks” actually exist. Then it’s a simple autocorrelation problem, e.g., as a test of whether the sequence obtained from the taking the product of consecutive +1/-1 pairs tends toward zero mean.
Wow! I just heard about it today from Yosi Rinot (mentioned above), whom I met coincidentally in a Tel Aviv street, and planned to write about it before seeing this post…
This was already commented on two blog entries by Andrew Gelman, here and there.
The former post by Gelman is referenced prominently in our post already. I did not see the latter from Sept. 30—these words are notable:
Nevertheless, I wonder if the grid idea which is provably right for coinflips still helps, or (perhaps along with re-sampling) just has the same effect as the Bayesian procedure.
I appreciate this work. Minutia: I believe “shortchanging the two heads-rich sequences” should say “shortchanging the two-heads-rich sequences” — i.e., there are not just two of them.
We appreciate the scrutiny too. I (Ken) did mean the two sequences HHT and HHH in the table which got weighted 1/6; the sequences HTH and THH don’t “count” because the second H in the 3rd position does not affect the selection.
I had a similar thought recently about a newspaper article on the ABC conjecture that stated it “roughly” as “if a + b = c and (…) then c is divisible by only a few, large primes.” I first read it without the comma, but actually the comma is correct.
Statistics aside, from a sports analysis point of view these studies should be taken with a huge grain of salt. In basketball, the belief in the hot hand streak affects both the shot selection of the player and the defensive schemes of her opponents. The incentive structure is complex and can run both ways. Personally I think elite athletes are exceptionally attuned to their bodies and their performance. If they believe the phenomena exists I believe it too.
It is one thing to discuss these concepts with dice rolls and slot machines, which produce largely random outcomes, assuming the dice are rolled in a “thorough” manner, and the slots are not fixed; it is very different, and probably innappropriate to apply them to subsequent acts in a game of skill, where so many factors ARE in the control of the performer. A ball-player really CAN ‘get hot’ – perhaps they finally are getting that sleep they need, or have a new practice regimen that is more effective, or have started thinking about the act of shooting in a different way… point is, a skilled player shooting a basketball is a *radically* different class of activity than a random dice roll.
There’s what is surely a related superstition in pinball. Many pinball leagues run by match play, where groups of four people take turns, each picking a table, and gaining league points based on who scores highest, second highest, et cetera.
Anyway, there’s a folkloric belief that the pinball table you pick will betray you, and you’ll do terribly on it.
Someone gathered the data for the Grand Rapids (Michigan) Pinball League, and found that the table a player picks gave them a first-place finish … nearly a quarter of the time. But they did finish third or fourth slightly more than half the time. It’s probably not an amount of statistical significance, but it does suggest the folklore is at least not perfectly unfounded. It just mostly is.
(I should clarify: this sort of league usually pits players against others of roughly equal ability. The points players score are used to move them up or down in the rankings, and groups are organized by that ranking. So you should expect to come in first about a quarter of the time, second a quarter of the time, et cetera.)
Replying to several above: JKU makes an excellent point—there are studies of streaks including a presentation by the venerable Jim Albert which I heard at the 2013 NeSSiS (New England Symposium on Statistics in Sports). Also there was the noted paper by Andrew Bocskocsky, John Ezekowitz, and Carolyn Stein of Harvard on how basketballers who are “hot” are observed to take more difficult shots. I left these on the cutting-room floor to keep the length down, also figuring I’d touched such sports-specific matters by my insert about the “game unit of form” into what Dick wrote. Also left out was a study of “hot hand” in chess by Alexander Matros and Irina Murtazashvili which I think is still being completed, maybe awaiting some belated input by me…?
Nice work. I have long been skeptical of the standard “hot hand fallacy” consensus. I feel like it’s easier to see in the inverse: “Do cold hands exist?”. Certainly. When I came down with pneumonia in high school my basketball play was completely ruined, of course; an extreme example.
Another point of bias/filtering is that the coaches and other players on the court are assessing and adjusting for this at all times. A truly cold (sick?) player won’t get put in; a hot player will get the ball more often, and a cold player less often (by teammates; perhaps the reverse for opponents). So likely the apparent shooting rates are higher than they would be in a theoretical everyone-takes-a-shot-once-per-minute distribution.
I wonder if this has implications to the similar “no fund manager is really better than any other, it’s just misinterpretations of random sequences” consensus (particularly as a selling point for index funds). I’m likewise skeptical of that idea being completely true.
Forget Colby Rasmus. After just now watching NYM 2B Daniel Murphy hit his 6th homer in 6 postseason games, the inverse of the hot-hand “fallacy” should be renamed “Murphy’s WAR.”
[Delta—yes, what you say goes under my umbrella intent of the “unit of form”.]
The problem with looking at the “Hot Hand” is that shooting a basketball is not a random event.
A very tall Basketball player could always and only “shoot” when he is near enough the basket to make it almost a surety that the ball goes in. [ No Dunking ]
When you flip a coin you either get Heads or Tails, what you don’t get is a near miss –
which should count for something when a person has a “Hot Hand” in basketball.
By only counting success or failure instead of near success…massive failure you discount
the non-randomness of shooting a basketball and create a bias that mimics flipping a coin.