Magic To Do
Can we avoid accepting what we cannot verify?

|
| Cropped from biography source |
Arthur Clarke was a British writer of great breadth and huge impact. He was a science writer, of both fiction and non-fiction. His works are too many to list, but 2001: A Space Odyssey—the novel accompanying the movie—is perhaps his most famous. He received both a British knighthood and the rarer Pride of Sri Lanka award, so that both “Sri” and “Sir” were legally prefixed to his name.
Today Dick and I want to raise questions about modern cryptography, complexity, and distinguishing science from “magic.”
Clarke added the following widely quoted statement to the 1973 revised edition of his book Profiles of the Future: An Inquiry into the Limits of the Possible as the third of three “laws” of prediction:
Any sufficiently advanced technology is indistinguishable from magic.
When I, Ken, first read the quote, I was surprised: it didn’t seem like something a proponent of science would say. Tracing versions of his book’s first chapter in which the first two “laws” appear, it seems Clarke first had nuclear fission in mind, then transistors, semiconductors, clocks incorporating relativity, and a list that strikingly includes “detecting invisible planets.” I agree with critiques expressed here and here: these phenomena are explainable. Perhaps Richard Feynman was right that “nobody really understands quantum mechanics,” but besides rebuttals like this, the point is that a natural explanation can satisfy by reduction to simpler principles without their needing to be fully understood. In all these cases too, experiment gives the power to verify.
My newfound appreciation for Clarke’s quip, and Dick’s all along, comes from realizing the potential limits of verification and explanation in our own field, computational complexity. This applies especially to crypto. Let’s see what the issues are.
Checking Results
As often in computing, issues have “ground” and “meta” levels. Let’s start on the ground.
The big center of gravity in complexity theory has always been the idea of 
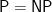
An even lower example in complexity terms is verifying a product 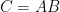

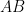
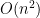



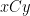
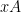

As the field has matured, however, we’ve run into more cases where no one has found a verifying predicate. For example, every finite field 






To see a still broader form of not knowing, we note this remark by Lance Fortnow on the Computational Complexity blog about a ramification of the deep-learning technique used to craft the new powerful Go-playing program by Google:
“If a computer chess program makes a surprising move, good or bad, one can work through the code and figure out why the program made that particular move. If AlphaGo makes a surprising move, we’ll have no clue why.”
To say a little more here: Today’s best chess programs train the coefficients of their position-evaluation functions by playing games against themselves. For example, the Weights array for last year’s official Stockfish 6 release had five pairs:
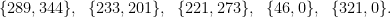
Line 115 of the current Stockfish source file evaluate.cpp has four pairs:

(Update 2/11/16: the array was removed entirely—see this change note.)
The myriad Score numbers following it are likewise all different. They are mysterious but they are concretely present, and one can find the position-features they index in the code to compute why the program preferred certain target positions in its search. A case of why Deep Blue played a critical good move against Garry Kasparov in 1997 caused controversy when IBM refused Kasparov’s request for verifying data, and may still not be fully resolved. But I’ve posted here a similar example of tracing the Komodo program’s refusal to win a pawn, when analyzing the first-ever recorded chess game played in the year 1475.
Deep learning, however, produces a convolutional neural network that may not so easily reveal its weights and thresholds, nor how it has learned to “chunk” the gridded input. At least with the classic case of distinguishing pictures of cats from dogs, one can more easily point after-the-fact to which visual features were isolated and made important by the classifier. For Go, however, it seems there has not emerged a way to explain the new program’s decisions beyond the top-level mixing of criteria shown by Figure 5 of the AlphaGo paper. Absent a human-intelligible explanation, the winning moves appear as if by magic.
Crypto and Illusion
James Massey, known among many things for the shift-register deducing algorithm with Elwyn Berlekamp, once recorded a much-viewed lecture titled,
“Cryptography: Science or Magic?”
What Massey meant by “magic” is different from Clarke. In virtually all cases, modern cryptographic primitives rely on the intractability of problems that belong to the realm of 

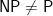
As above the issue is lack of ability to verify a property, but this time of an algorithmic protocol rather than a single solution or chess or Go move. This “meta” level goes to the heart of our field’s aspiration to be a science. Of course we can prove theorems conditioned on hardness assumptions, but apart from the issue we have covered quite a few times before of loopholes between security proofs and application needs, we perceive a more fundamental lack:
The theorems don’t (yet) explain from first principles what it is about the world that yields these properties.
Modern cryptography is filled with papers that really say the following: If certain simple to state complexity hardness assumptions are correct, then we can do the following “magical” operations. This is viewed by those who work in cryptography, and by those of us outside the area, as an example of a wonderful success story. That factoring is hard implies the ability to encrypt messages is not so hard to believe, but that we can make the encryption asymmetric—a public key system—was at first a real surprise. But that this assumption further allows us to do some very powerful and wonderful operations is even more surprising.
Massey gives as example the technique developed by Amos Fiat and Adi Shamir to convert any interactive proof of knowledge into one that carries the signature of the person conveying proof of knowledge without needing that person’s active participation. It preserves the feature that only the person’s fact of knowing is transmitted, not the known data itself. This is truly wondrous: you can interact offline.
We can trace the composition of hardness assumptions, plus the assumption of implementing a suitable random oracle, in a conditional theorem. Since we cannot prove any of the conditions, Massey asks, is this all an illusion? How can we tell it’s not? For us this raises something further:
If a capability seems too wondrous to believe, can that be grounds for doubting one or more of the assumptions that underlie it?
In short, the magical success of crypto could be misleading. Could the assumptions it rests on go beyond magic into fantasy? In short could factoring be easy, and therefore modern crypto be wrong? Could the whole edifice collapse? Who knows?
Open Problems
The three issues we have highlighted can be summarized as:
- Not knowing how to test what we are getting;
- Getting something that works in the field but not knowing how we got it; and
- Not knowing whether things deployed in the field are really true.
Can we distinguish the parts of theory that underlie these problems from “magic”? Must we bewail this state of our field, or is it an inevitable harbinger that complexity, learning, and crypto are becoming “sufficiently advanced”?
Trackbacks
- New NAE Members | Gödel's Lost Letter and P=NP
- Waves, Hazards, and Guesses | Gödel's Lost Letter and P=NP
- A Matter of Agreement | Gödel's Lost Letter and P=NP
- Stonefight at the Goke Corral | Gödel's Lost Letter and P=NP
- TOC In The Future | Gödel's Lost Letter and P=NP
- Lost in Complexity | Gödel's Lost Letter and P=NP


Is paradox recognition possible or impossible? This is the BANNED question.
Rafee Kamouna.
Clarke’s aphorism could be rephrased as:
Now you may apply this to “P=NP”, to “factoring is in P”, or to whatever you want in complexity theory. It’s a scientific field which feels like quicksand…
Try to address “Paradox Recognition”.
are you saying crypto is on false foundations in general and that in particular using rsa can be broken? RSA is already tested out there it has been deployed on many products.