A Great Solution
A great conjecture too

|
| Alternate photo by Quanta |
Thomas Royen is a retired professor of statistics in Schwalbach am Taunus near Frankfurt, Germany. In July 2014 he had a one-minute insight about how to prove the famous Gaussian correlation inequality (GCI) conjecture. It took one day for him to draft a full proof of the conjecture. It has taken several years for the proof to be accepted and brought to full light.
Today Ken and I hail his achievement and discuss some of its history and context.
Royen posted his paper in August 2014 with the title, “A simple proof of the Gaussian correlation conjecture extended to multivariate gamma distributions.” He not only proved the conjecture, he recognized and proved a generalization. The “simple” means that the tools needed to solve it had been available for decades. So why did it elude some of the best mathematicians for those decades? One reason may have been that the conjecture spans geometry, probability theory, and statistics, so there were diverse ways to approach it. A conjecture that can be viewed in so many ways is perhaps all the more difficult to solve.
Even more fun is that Royen proved the conjecture after he was retired and had the key insight while brushing his teeth—as told here. Ken recalls one great bathroom insight not in his research but in chess: In the endgame stage of the famous 1999 Kasparov Versus the World match, which became a collaborative research activity later described by Michael Nielsen in his book, Reinventing Discovery, Ken had a key idea while in the shower. His idea, branching out from the game at 58…Qf5 59. Kh6 Qe6, was the Zugzwang maneuver 60. Qg1+ Kb2 61. Qf2+ Kb1 62. Qd4!, which remains the only way for White to win.
The Germ
Although solutions often come in a flash, the ideas they resolve often germinate from partial statements whose history takes effort to trace. One thing we can say is that the GCI does not originate with Carl Gauss, nor should it be considered named for him. A Gaussian measure on 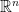

where 
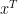


Suppose 
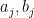
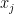


What if they are not independent? If they are positively correlated, then we may expect it to be higher. If they are inversely related, well…let’s also suppose the variables have mean 



Who Dunnett?
Charles Dunnett and Milton Sobel considered some special cases, such as when 

But it was Olive Dunn who first posed the above general terms in a series of papers that have had other enduring influence. The first paper in 1958 and the second in 1959 bore the like-as-lentils titles:
- Estimation of the Means of Dependent Variables.
- Estimation of the Medians for Dependent Variables.
These seem to have generated confusion. The former is longer and frames the confidence-interval problem and is the only one to cite Dunnett-Sobel, but it does not mention a “conjecture.” The latter does discuss at the end exactly the conjecture of extending a case she had proved for 

Dunn became a fellow of the American Statistical Association, a fellow of the American Association for the Advancement of Science (AAAS), and a fellow of the American Public Health Association. In 1974, she was honored as the annual UCLA Woman of Science, awarded to “an outstanding woman who has made significant contributions in the field of science.” Her third paper in this series, also 1959, was titled “Confidence intervals for the means of dependent normally distributed variables.” Her fourth, in 1961, is known for the still-definitive form of the Bonferroni correction for joint variables. But in our episode of “CSI: GCI” it seems we must look later to find who framed the conjecture as we know it.

|
|
Not an ad. Amazon source. So is it an ad? |
Sobel came back to the scene as part of a 1972 six-author paper, “Inequalities on the probability Content of Convex Regions for Elliptically Contoured Distributions.” They considered integrals of the form

for general functions 





Inequalities for
perhaps originate with special results of Dunnett and Sobel (1955) and of Dunn (1958), in which it is shown that
for special forms of
(with
) or for special values of
.
They mention also an inequality by David Slepian and what they termed “the most general result for the normal distribution” by Zbynek Šidák, still with special conditions on
This suggests the conjecture: if
is a random vector (with
of dimension
and
of dimension
) having density
and if
and
are convex symmetric sets, then
where


Clearly by iteration this implies the inequality with regard to 
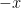


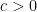
Finally in 1977, Loren Pitt proved the case 
Pitt had been trying since 1973, when he first heard about [it]. “Being an arrogant young mathematician … I was shocked that grown men who were putting themselves off as respectable math and science people didn’t know the answer to this,” he said. He locked himself in his motel room and was sure he would prove or disprove the conjecture before coming out. “Fifty years or so later I still didn’t know the answer,” he said.
So as for framing GCI, whodunit? Royen ascribes it to the 1972 paper which is probably what popularized it to Pitt, but Dunn’s orthogonal-intervals formulation spurred the intervening work, accommodates extensions noted as equivalent to GCI by Royen citing this 1998 paper, and still didn’t get solved until Royen. So we find these two sources equally “guilty.”
The Conjecture and Solution
The 1972 form of GCI has a neatly compact statement and visualization:
For any symmetric convex sets
in
and any Gaussian measure
on

That is, imagine overlapping shapes symmetric about the origin in some Euclidean space. Throw darts that land with a Gaussian distribution around the origin. The claim is that the probability that the a dart will land on both shapes is at least the probability that it will land in one shape times the probability that it lands in the other shape.

|
|
UK Daily Mail source |
George Lowther, in his blog “Almost Sure,” has an interesting post about early attempts to solve GCI. He notes the following partial results from the above-mentioned 1998 paper:
-
There is a positive constant
such that the conjecture is true whenever the two sets are contained in the Euclidean ball of radius
.
-
If, for every
, then it is true in general.
The first statement proves GCI in a “shrunken” sense, while the second makes that seem tantamount to solving the whole thing. Lowther explained, however:
Unfortunately, the constant in the first statement is
, which is strictly less than one, so the second statement cannot be applied. Furthermore, it does not appear that the proof can be improved to increase
to one. Alternatively, we could try improving the second statement to only require the sets to be contained in the ball of radius
for some
but, again, it does not seem that the proof can be extended in this way.
Royen did not use this idea—indeed, Wolchover quotes Pitt as saying, “what Royen did was kind of diametrically opposed to what I had in mind.” Instead she explains how Royen used a kind of smoothing between the original 


“He had formulas that enabled him to pull off his magic,” Pitt said. “And I didn’t have the formulas.”
Royen’s short paper does need the background of these tricks to follow, and the fact that the same tricks enabled a further generalization of GCI makes it harder. The proof was made more self-contained in this 2015 paper by Rafał Latała and Dariusz Matlak (final version) and in a 2016 project by Tianyu Zhou and Shuyang Shen at the University of Toronto, both focusing just on GCI and cases closest to Dunn’s papers. Rather than go into proof details here, we’ll say more about the wider context.
Why GCI Is Important
Independent events are usually the best type of events to work with. Recall if 


Of course actually more is true: 


Since independence is not always true for two events 


GCI reminds us of another inequality that intuitively cuts very fine and was difficult to prove: the FKG inequality. Ron Graham wrote a survey of FKG that begins with a discussion of Chebyshev’s sum inequality, named after the famous Pafnuty Chebyshev.

Chebychev’s sum inequality states that if

and

then

Wikipedia’s FKG article says how the relevance expands to other inequalities:
Informally, [FKG] says that in many random systems, increasing events are positively correlated, while an increasing and a decreasing event are negatively correlated.
An earlier version, for the special case of i.i.d. variables, … is due to Theodore Edward Harris (1960) … One generalization of the FKG inequality is the Holley inequality (1974) below, and an even further generalization is the Ahlswede-Daykin “four functions” theorem (1978). Furthermore, it has the same conclusion as the Griffiths inequalities, but the hypotheses are different.
We wonder whether the new results on GCI will spur an over-arching appreciation of all these inequalities involving correlated variables. We also wonder if in the complex case there is any connection between Royen’s smoothing technique and the process of purifying a mixed quantum state.
Open Problems
The amazing personal fact is that a retired mathematician solved the problem and did it with a relatively simple proof. What does this say about our core conjectures in theory? I am near retirement from Georgia Tech—does that mean I will solve some major open problem? Hmmmmmmm.
Also, which of you have had key insights come in the bathroom?
[nonsingular R–>positive definite R, other tweaks]


You’re risking your reputation, but you think it’s worth it.
“All right, he was a good mathematician, but at the end of his life he lost his marbles.”
https://www.quantamagazine.org/20160303-michael-atiyahs-mathematical-dreams/
Thank you very much for bringing that great article to our attention.
I would still ask you what is really essential in quantum computing? Superposition of states? You have it in any linear system. Operation on a sum gives a sum of operations. Just use 2 orthogonal directions for each bit. Sum of these vectors is a superpositiion of 2 states. Sum of all vectors for all bits is a superposition of all possible binary values. Measurement is an application of linear operator, say, projection. The result of its aplication to the sum above is the total number of solutions. The only problem is that a universal classical gate is not possible to implement as a linear operator on the original space. So the design of the universal gate is what makes quantum computer different. The main question is what os entanglement, which is connecting the result of universal gate application to the original set of vectors. Once it is technically solved parallel computation on a same peice of hardware would be possible without quantum computers.
Oh sorry. This was a project for retirement.
you think P=NP will be proved this easily?
The P=NP is about parallel computation on the same piece of hardware at the same time. If P=NP the proof should be easy! We just do not have an intuition. All linear operators that are coming in mind are loosing the identity of operand. That is what entanglement is supposed to overcome. So the question is to construct one or show that it is impossible. One candidate for the representation is a linear combination of vectors with some kind of vector product that keep the identity of operand after aplication.
The complicated way is to show that it is possible to break the space into polynomial number of pieces where it takes polynomial time to find satisfability. This approach is taken in general numerical slieve, except that it is not polynomial.
Is it not possible that someones proof of NP==P is already facing a similar (or worse) fate?