Stopped Watches and Data Analytics
Is this a new or old paradox?

|
| UK Independent source—and “a gentle irony” |
Roger Bannister is a British neurologist. He received the first Lifetime Achievement Award from the American Academy for Neurology in 2005. Besides his extensive research and many papers in neurology, his 25 years of revising and expanding the bellwether text Clinical Neurology culminated in being added as co-author. Oh by the way, he is that Bannister who was the first person timed under 4:00 in a mile race.
Today I cover another case of “Big Data Blues” that has surfaced in my chess work, using a race-timing analogy to make it general.
Sir Roger also served as Head of Pembroke College, one of the constituents of Oxford University. He was one of three august Rogers with whom I interacted about IBM PC-XT computers when the machines were installed at Oxford in 1984–1985. Sir Roger Penrose was among trustees of the Mathematical Institute’s Prizes Fund who granted support for my installation of an XT-based mathematical typesetting system there, a story I’ve told here. Roger Highfield and his secretary used an XT in my college’s office, and I was frequently called in to troubleshoot. While drafting this post last month, I received a mailing from Sir Martin Taylor that Dr. Highfield had just passed away—from his obit one can see that he, too, received admission to a royal order.
Dr. Bannister was interested in purchasing several XTs for scientific as well as general purposes at Pembroke. At the time, numerical performance required purchasing a co-processor chip, adding almost $1,000 to what was already a large outlay per machine by today’s standards. I wish I’d thought to say in a quick deadpan voice, “let it run four minutes and it will give you a mile of data.” (Instead, I think the 1954 race never came up in our conversation.) Today, however, data outruns us all. How to keep control of the pace is our topic.

|
|
Roger Bannister 50-year commemorative coin. Royal Mint source. |
Stopped Watches Can Be Correct
As shown above in the commemorative coin’s design, the historic 3:59.4 time was recorded on stopwatches. We’ll stay with this older timing technology for our example.
Suppose you have a field of 200 milers. Suppose you also have a box of 50 stopwatches. For each runner you pick a stopwatch at random and measure his/her time. You get results that closely match the histogram of times that were recorded for the same runners in trials the previous day.
How good is this? You can be satisfied that the box of watches does not have a systematic tendency to be slow or to be fast for runners at that mix of levels. Projections based on such fields are valid.
The rub, however, is that you could have gotten your nice fit even if each individual watch is broken and always returns the same time. Suppose your field included Bannister, John Landy, Jim Ryun, and Sebastian Coe, with each in his prime. They would probably average close to 3:55. Hence if one of the 50 watches is stuck on 3:55, it will fit them well. It doesn’t matter if you actually draw the watch when measuring the last-place finisher. The point is that you expect to draw the watch 4 times overall and are fitting an aggregate.
Indeed, you only need the distribution of the (stopped) watches to match the distribution of the runners under random draws. You may measure a close fit not only in the quantiles but also the higher moments, which is as good as it gets. Your model may still work fine on tomorrow’s batch of runners. But at the non-aggregate level, what it did in projecting an individual runner was vapid.
Another Quick Example
Here is a hypothetical example in the predictive analytic domain of my chess model. Consider a model used by a home insurance company to judge the probabilities of damage by earth movement, wind, fire, or flood and price policies accordingly. I’ve seen policies with grainy risk-scale levels that apply to several hundred homes in a given area at one time. The company only needs good performance on such aggregates to earn its profit.
But suppose the model were fine-grained enough to project probabilities on individual homes. And suppose it did the following:
- Home 1: Earth 0.047, wind 0.001, fire 0.001, water 0.001; total risk 0.05.
- Home 2: Earth 0.001, wind 0.047, fire 0.001, water 0.001; total risk 0.05.
- Home 3: Earth 0.001, wind 0.001, fire 0.047, water 0.001; total risk 0.05.
- Home 4: Earth 0.001, wind 0.001, fire 0.001, water 0.047; total risk 0.05.
This is weird but might not be bad. If the risks average out over several hundred homes, a model like this might perform well—despite the consternation homeowners would feel if they ever saw such individual projections.
Of course, “real” models don’t do this—or do they? The expansion of my chess model which I described last Election Day has started doing this. It fixates on some moves but gives near-zero probability to others—even ones that were played—while giving fits 5–50x sharper than before. If you’ve already had experience with behavior like the above, please feel welcome to jump to the end and let us know in comments. But to see what lessons to learn from how this happens in my new model, here are details…
How My Original Model Works
My chess model assigns a probability 
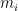






The model asserts that the parameters can be used to compute dimensionless inferiority values 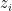
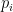

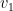

Lower 


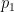

where 






This “inner loop” defines 





-
.
-
.
The regression makes these into unbiased estimators by matching them to the actual values 


where the weights 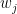


In my original model, all is good. My training sets for a wide spectrum of Elo ratings 



![{[s_E]}](https://s0.wp.com/latex.php?latex=%7B%5Bs_E%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[c_E]}](https://s0.wp.com/latex.php?latex=%7B%5Bc_E%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

The New Model
My old model is however completely monotone in this sense: The best move(s) always have the highest 
The new model postulates a mechanism by which weaker moves 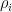
A player’s susceptibility to “swing” is modeled by a new parameter called 



where 




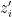
Note that the formulas for 
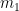
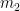

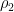


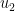
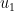
The second big win is that 
The third big win—but tantalizing—is that the extended model not only allows solving 2 more equations but often makes other fitness tests 
-
.
-
, for various error bounds
.
-
;
or
or
-
for appropriate weights
- The frequency of certain kinds of move, e.g. moving a Knight, or capturing, or retreating.

A typical fit that looks great by all these measures is here. It has 26,450 positions from all 497 games at standard time controls with both players rated between Elo 2040 and Elo 2060 since 2014 that are collected in the encyclopedic ChessBase Big 2017 data disc. It shows 
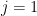
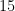






Only 

Whiplash Under the Dial
The first hint of trouble comes from the fitted value of 









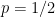

Those effects show up immediately in the file. I skip turns 1–8, so White’s 9th move is the first item. In the following position at left, Black has just captured a pawn and White has three ways to re-take, all of them reasonable moves according to the Stockfish 7 program.

|
|
Positions in game Franke-Doennebrink, 1974 at White’s 9th move (left) and Black’s 11th (right). |
Here is how my new model projects them:
NRW Class1 1314;Germany;2014.02.02;6.4;Franke, Thomas;Doennebrink, Elmar;1-0 r1b1k2r/pp2bppp/2n1pn2/3q4/3p4/2PBBN2/PP3PPP/RN1Q1RK1 w kq - 0 9; c3xd4, engine c3xd4 Eval 0.24 at depth 21; swap index 1 and spec AA2050SF7w4sw10-19: (InvExp:1), Unit weights with s = 0.0083, c = 0.3846, d = 12.5000, v = 0.0500, a = 0.9863, hm = 1.8024, hp = 1.0000, b = 1.0000: M# Rk Move RwDelta ScDelta Swing SwDDep SwRel Util.Share ProjProb'y 1 1 c3xd4: 0.00 0.000 0.000 0.000 0.000 1 0.79527569 2 2 Nf3xd4: 0.42 0.321 -0.035 -0.034 -0.034 0.144422 0.20472428 3 3 Be3xd4: 0.55 0.395 0.008 0.005 0.005 0.00445313 0.00000001
That’s right—it gives zero chance of a 2050-player taking with the Bishop, even though Stockfish rates that only a little worse than taking with the Knight. True, human players would say 9.Bxd4 is a stupid move because it lets Black gain the “Bishop pair” by exchanging his Knight for that Bishop. Of 155 games that ChessBase records as reaching this position, 151 saw White recapture by 9.cxd4, 4 by 9.Nxd4, and none by 9.Bxd4. So maybe the extremely low projection—for 9.Bxd4 and all other moves—has a point. But to give zero? The 



M# Rk Move RwDelta ScDelta Swing SwDDep SwRel Util.Share ProjProb'y 1 1 c3xd4: 0.00 0.000 0.000 0.000 0.000 1 0.57620032 2 2 Nf3xd4: 0.42 0.321 -0.035 -0.034 -0.034 0.280586 0.14018157 3 3 Be3xd4: 0.55 0.395 0.008 0.005 0.005 0.241178 0.10168579
At Black’s 11th turn, however, the new model gives three clearly wrong “zero” projections:
NRW Class1 1314;Germany;2014.02.02;6.4;Franke, Thomas;Doennebrink, Elmar;1-0 r1b2rk1/pp2bppp/2nqpn2/8/3P4/P1NBBN2/1P3PPP/R2Q1RK1 b - - 0 11; Rf8-d8, engine b7-b6 Eval 0.11 at depth 20; swap index 1 and spec AA2050SF7w4sw10-19: (InvExp:1), Unit weights with s = 0.0083, c = 0.3846, d = 12.5000, v = 0.0500, a = 0.9863, hm = 1.8024, hp = 1.0000, b = 1.0000: M# Rk Move RwDelta ScDelta Swing SwDDep SwRel Util.Share ProjProb'y 1 1 b7-b6: -0.00 -0.000 0.000 0.000 0.000 1 0.56792559 2 2 Nf6-g4: 0.18 0.163 -0.001 -0.002 -0.002 0.0907468 0.00196053 3 3 Rf8-d8: 0.18 0.163 0.042 0.046 0.046 0.00391154 0.00000001 4 4 Bc8-d7: 0.21 0.187 -0.029 -0.030 -0.030 0.278053 0.13071447 5 5 Nf6-d5: 0.28 0.241 0.047 0.050 0.050 0.00218845 0.00000001 6 6 a7-a6: 0.30 0.256 -0.049 -0.051 -0.051 0.28777 0.14001152 7 7 Qd6-c7: 0.31 0.264 -0.012 -0.012 -0.012 0.097661 0.00304836 8 8 g7-g6: 0.37 0.306 0.015 0.017 0.017 0.00355675 0.00000001 9 9 Qd6-d8: 0.39 0.320 -0.054 -0.051 -0.051 0.206264 0.06438231 10 10 Qd6-b8: 0.39 0.320 -0.037 -0.038 -0.038 0.158031 0.02787298
Owing to many other games having “transposed” here by a different initial sequence of moves, Big 2017 shows 911 games reaching this point. In 683 of them, Black played the computer’s recommended 11…b6. None played the second-listed move 11…Ng4, which reflects well on the model’s giving it a tiny 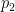
To be sure, this is a well-known “book” position. The 75% preference for 11…b6 doubtless reflects players’ knowledge of past games and even the fact that Stockfish and other programs consider it best. It is hard to do a true distributional benchmark of my model in selected positions because the ones with enough games are exactly the ones in “book.” Studies of common endgame positions have been tried then and now, but with the issue that the programs’ immediate complete resolution of these endgames seems to wash out much of the progression in thinking and differentiation of player skill that one would like to capture. (My cheating tests exclude all “book-by-2300+” positions and all with one side ahead more than 3.00.) Most to the point, the fitting done by my model on training data is supposed to be already the distributional test of how players of that rating class have played over many thousands of instances.
The following position is far from book and typifies the most egregious kind of mis-projection:

SVK-chT1E 1314;Slovakia;2014.03.23;11.6;Debnar, Jan;Milcova, Zuzana;1-0 2r4k/pp5p/2n5/2P1p2q/2R1Qp1r/P2P1P2/1P3KP1/4RB2 b - - 1 32; Qh5-g5, engine Qh5-g5 Eval 0.01 at depth 21; swap index 2 and spec AA2050SF7w4sw10-19: (InvExp:1), Unit weights with s = 0.0083, c = 0.3846, d = 12.5000, v = 0.0500, a = 0.9863, hm = 1.8024, hp = 1.0000, b = 1.0000: M# Rk Move RwDelta ScDelta Swing SwDDep SwRel Util.Share ProjProb'y 1 1 Qh5-g5: 0.00 0.000 0.129 0.137 0.000 0.0347142 0.00018527 2 2 Rc8-d8: 0.00 0.000 0.026 0.025 -0.112 1 0.74206054 3 3 a7-a6: 0.09 0.085 -0.008 -0.005 -0.142 0.117659 0.07922164 4 4 Rc8-g8: 0.21 0.187 -0.092 -0.087 -0.225 0.0996097 0.05003989 5 5 Rh4-h1: 0.25 0.219 -0.166 -0.165 -0.302 0.136659 0.11270482
This has two tied-optimal moves for Black in a position judged +0.01 to White, not a flat 0.00 draw value, yet the one that was played gets under a 1-in-5,000 projection. Here are the by-depth values that produced the high positive 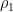
--------------------------------------------------------------------------------------------
5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
--------------------------------------------------------------------------------------------
Qg5 -117 -002 -008 +000 -015 +008 +017 +032 +011 +007 +000 +004 +001 +000 +000 +006 +001
Rd8 -089 -058 -036 -032 -013 -025 +006 +000 -010 +000 -012 -013 +001 +014 +001 +001 +001
The numbers are from White’s view, so what happened is that 32…Rd8 looked like giving Black the advantage at depths 10, 13, and 15–16, whereas 32…Qg5 looked significantly inferior (to Stockfish 7) at depth 12 and nosed in front only at depth 20 just before falling into the tie. The swing computation begins at depth 10 to evade the Stockfish-specific strangeness I noted here last year, so in particular the “rogue” values at depth 5 (and below) are immaterial. The values and differences from depth 10 onward are all relatively gentle. Hence their amounting to a tiny
A Kind of Race Condition
What I believe is happening to the fit is hinted by this last example giving the highest probability to the 2nd-listed move. Our first game above has two positions where the 9th-listed move gets the love. (The second, shown in full here, is notable in that the second-best move gets a zero though it is inferior by only 0.03 and was played by all three 2200+ players in the book.) This conforms to the goal of projecting when weaker players will prefer weaker moves.
This table shows that the new model quite often prefers moves other than

To be sure, the model is not putting 100% probability on these preferred moves, but when preferred they get a lot more probability than under my old model, which never prefers a move other than 
Yes, greater concentration was the goal—so as to distinguish the most plausible inferior moves. But the above examples show a runaway process. The new model seems to be seizing onto properties of the 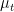


These few moves are the “stopped-watch reading” in my analogy. The moves given zero are the readings that cannot happen for a given runner/position. The fitting doesn’t care whether moves getting zero were played, so long as other turns fill in the histogram. If a high 


What can fix this? The maximum likelihood estimator (MLE) in this case involves minimizing the log-sum 



There are various other ways to fit the model, including a quantiling idea I devised in my AAAI 2011 paper with Guy Haworth. In principle, and because the training data is copious, it is good to have these ways agree more than they do at present. Absent a lightning bolt that fuses them, I am finding myself locally tweaking the model in directions that optimize some “meta-fitness” function composed from all these tests. There is copious data—as noted in the previous posts, it comes gratia the University at Buffalo Center for Computational Research (CCR).
Open Problems
Is this a known issue? Does it have a name? Is there a standard recipe for fixing it?
Do any deployed models have similar tendencies that aren’t noticed because there isn’t the facility for probing deeper into the grain that my chess model enjoys?
[added “at standard time controls”, a few other word changes, added game diagrams and acknowledgment]
Trackbacks
- Happy Birthday Ken | Gödel's Lost Letter and P=NP
- Is There Momentum in Chess? | Gödel's Lost Letter and P=NP
- Sliding-Scale Problems | Gödel's Lost Letter and P=NP
- London Calling | Gödel's Lost Letter and P=NP
- Far From a Turkey Shoot | Gödel's Lost Letter and P=NP
- Predicting Chess and Horses | Gödel's Lost Letter and P=NP


Very nice post.
Definition: Consider a 2-player game, say G, of alternating moves/rounds (e.g. chess) with three possible outcomes, namely, win/draw/lose (like chess). Define G to be R-complete if there exists a Turing machine in the position of a player scoring at least draw (or better) provided the Turing machine is allowed at most a polynomial number of steps in each round.
I think Zermelo showed that chess is always a draw for ‘infinite’ players.
Conjecture: Chess is R-complete.
*R in R-completeness is for Reagan.
**I am writing from Dodoni coffee shop in Melissia, Athens.
***No regret algorithms in machine learning provide guarantees against arbitrary intelligence. Ken’s post made me think that this is quite important: No matter how infinitely human you are, there are Turing machines that cannot beat you in some environments.