A Magic Madison Visit
To give a Hilldale Lecture and learn about fairness and dichotomies

|
| UB CSE50 anniversary source |
Jin-Yi Cai was kind enough to help get me, Dick, invited last month to give the Hilldale Lecture in the Physical Sciences for 2017-2018. These lectures are held at The University of Wisconsin-Madison and are supported by the Hilldale Foundation. The lectures started in 1973-1974, which is about the time I started at Yale University—my first faculty appointment.
Today Ken and I wish to talk about my recent visit, discuss new ideas of algorithmic fairness, and then appreciate something about Jin-Yi’s work on “dichotomies” between polynomial time and 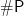
The Hilldale Lectures have four tracks: Arts & Humanities and Physical, Biological, and Social Sciences. Not all have a speaker each year. The Arts & Humanities speaker was Yves Citton of the University of Paris last April, and in Social Sciences, Peter Bearman of Columbia spoke on Sept. 28, three weeks before I. Last year’s speaker in the Physical Sciences track was Frank Shu of Berkeley and UCSD on the economics of climate change. Before him came my former colleagues Peter Sarnak and Bill Cook. Dick Karp was invited in 2004, and mathematicians Barry Mazur and Persi Diaconis came between him and Cook.
I am delighted and honored to be in all this company. We all may not seem to have much to do with the physical sciences but let’s see. I spoke on (
My Visit
The other highlight of my visit was meeting with the faculty of the CS department and also with the graduate students. I hope they enjoyed our discussions as much as I did.
One topic that came up multiple times is the notion of fair algorithms. This is a relatively new notion and is being studied by several researchers at Wisconsin. The area has its own blog. The authors of that blog (one I know well uses his other blog’s name as his name there—are we to become blogs?) also wrote a paper titled, “On the (Im)Possibility of Fairness,” whose abstract we quote:
What does it mean for an algorithm to be fair? Different papers use different notions of algorithmic fairness, and although these appear internally consistent, they also seem mutually incompatible. We present a mathematical setting in which the distinctions in previous papers can be made formal. In addition to characterizing the spaces of inputs (the “observed” space) and outputs (the “decision” space), we introduce the notion of a construct space: a space that captures unobservable, but meaningful variables for the prediction. We show that in order to prove desirable properties of the entire decision-making process, different mechanisms for fairness require different assumptions about the nature of the mapping from construct space to decision space. The results in this paper imply that future treatments of algorithmic fairness should more explicitly state assumptions about the relationship between constructs and observations.
There is a notion of fairness in distributed algorithms but this is different. The former is about the allocation of system resources so that all tasks receive due processing attention. The latter has to do with due process in social decision making where algorithmic models have taken the lead. Titles of academic papers cited in a paper by three of the people I met in Madison and someone from Microsoft (see also their latest from OOPSLA 2017) speak why the subject has arisen:
- “Hiring by algorithm: predicting and preventing disparate impact.”
- “Predictive policing: The role of crime forecasting in law enforcement operations.”
- “Three naive Bayes approaches for discrimination-free classification.”
- “Algorithmic transparency via quantitative input influence.”
- “Discrimination in online ad delivery.”
Also among the paper’s 29 references are newspaper and magazine articles whose titles state the issues with less academic reserve: “Websites vary prices, deals based on users’ information”; “Who do you blame when an algorithm gets you fired?”; “Machine bias: There’s software used across the country to predict future criminals. And it’s biased against blacks”; “The dangers of letting algorithms enforce policy.” Evan a May, 2014 statement by the Obama White House is cited.
Yet also among the references are papers familiar in theory: “Satisfiability modulo theories”; “Complexity of polytope volume computation” (by Leonid Khachiyan no less), “On the complexity of computing the volume of a polyhedron”; “Hyperproperties” (by Michael Clarkson and Fred Schneider), “On probabilistic inference by weighted model counting.” What’s going on?
The Formal Method
What’s going on can be classed as a meta-example of the subject’s own purpose:
How does one formalize a bias-combating concept such as fairness without instilling the very kind of bias one is trying to combat?
We all can see the direction of bias in the above references. You might think that framing concepts to apply bias in the other direction might be OK but there’s a difference. Bias in a measuring apparatus is more ingrained than bias in results. What we want to do—as scientists—is to formulate criteria that are framed in terms apart from those of the applications in a simple, neutral, and natural manner. Then we hope the resulting formal definition distinguishes the outcomes we desire from those we do not and stays robust and consistent in its applications.
This is the debate—at ‘meta’ level—that Ken and I see underlying the two papers we’ve highlighted above. We blogged about Kenneth Arrow’s discovery of the impossibility of formalizing a desirable “fairness” notion for voting systems. The blog guys don’t find such a stark impossibility theorem but they say that to avoid issues with analyzing inputs and outcomes, one has to attend also to some kind of “hidden variables.” The paper by Madison people tries to ground a framework in formal methods for program verification, which is connects to probabilistic inference via polytope volume computations.
Many other ingredients from theory can be involved. The basic idea is determining sensitivity of outcomes to various facets of the inputs. The inputs are weighted for relevance to an objective. Fairness is judged according to how well sensitivity corresponds to relevance and also to how the distribution of subjects receiving favorable decisions breaks according to low-weight factors such as gender. Exceptions may be made by encoding some relations as indelible constraints—the Madison plus Microsoft paper gives as an example that a Catholic priest must be male.
Thus we see Boolean sensitivity measures, ideas of juntas and dictators, constraint satisfaction problems, optimization over polytopes—lots of things I’ve known and sometimes studied in less-particular contexts. My Madison hosts brought up how Gaussian distributions are robust for this analysis because they have several invariance properties including under rotations of rectangles. This recent Georgetown thesis mixes in even more theory ideas. The meta-question is:
Can all these formal ingredients combine to yield the desired outcomes in ways whose scientific simplicity and naturalness promote confidence in them?
Thus wading in with theory to a vast social area like this strikes us as a trial of “The Formal Method.” Well, there is the Hilldale Social Sciences track…
Did “hidden variables” bring quantum to your mind? We are going there next, with Ken writing now.
A Magic Madison Upper Bound
We covered Jin-Yi’s work in 2014 and 2012 and 2009. So you could say in 2017 we’re “due” but we’ll take time for more-topical remarks. All of these were on dichotomy theorems. For a wide class 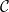
Jin-Yi’s answer to a question last month between Dick and me recently brought home to us both how wonderfully penetrating and hair-trigger this work is. Dick had added some contributions to the paper covered in the 2009 post and was included on the paper’s final 2010 workshop version. Among its results is the beautiful theorem highlighted at the end of that post:
Theorem 1 There is an algorithm that given any
and formula for a quadratic polynomial
over
computes the exponential sum
exactly in time that is polynomial in both
and
. Here
and
means the number of arguments on which
takes the value
modulo
.

That the time is polynomial in 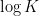

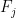


When 
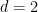


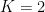



Dichotomy and Quantum
I wrote a post five years ago on his joint work with Amlan Chakrabarti for reducing the simulation of quantum circuits to counting solutions in 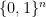

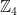
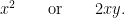
These terms are invariant on replacing 
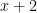

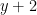




Adding any non-Clifford gate makes a set that is universal—i.e., has the full power of 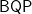
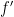
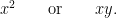
Those are quadratic too, so Theorem 1 counts all the solutions in polynomial time. Does this make 
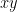
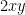
I thought maybe the counting problem for quadratic-and-binary could be intermediate—perhaps at the level of
-
Counting all solutions of quadratic polynomials over
-
Counting the binary solutions however is hard:
-
Counting the binary solutions when the coefficient of all terms of the form
Thus the difference between easy and general quantum circuits hangs on that ‘
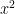
Might there be some other easily-identified structural properties of the 
Open Problems
Trying to make up for blog pause while we were busy with a certain seasonal event, we offer several open problems:
- Is there a ‘fair’ way to define algorithmic fairness?
- What are the most important structural and numerical properties from theory to use in such a definition and key results about it?
-
Can solution counting modulo
fixed and
-
What structural properties of the polynomials
-
The exponential sum in Theorem 1 has long-known physical meaning as a partition function. It is hence reasonable to expect that algebraic-geometric properties of the polynomial
[“stabilizer theorem”->”theorem for Clifford gates”; added links to OOPSLA 2017 paper and May 2017 Cai-Guo-Williams paper]
Trackbacks
- Predictions We Didn’t Make | Gödel's Lost Letter and P=NP
- Predictions For 2019 | Gödel's Lost Letter and P=NP
- A Quantum Connection For Matrix Rank | Gödel's Lost Letter and P=NP
- Predicting Chess and Horses | Gödel's Lost Letter and P=NP
- Our Thoughts on P=NP | Gödel's Lost Letter and P=NP
- A Little Noise Makes Quantum Factoring Fail | Gödel's Lost Letter and P=NP
- Dominic Welsh, 1938–2023 | Gödel's Lost Letter and P=NP


You may be interested in this letter from the Brennan Center for Justice, which is signed by a number of people in CS and ML. It regards the latest frontier in algorithmic fairness: namely, the proposal for Immigration and Customs Enforcement to use automated methods to decide whether a person is a threat, or contribute to the “national interest”.
https://www.brennancenter.org/sites/default/files/Technology%20Experts%20Letter%20to%20DHS%20Opposing%20the%20Extreme%20Vetting%20Initiative%20-%2011.15.17.pdf
– Cris
It was great talking to you during your visit and thank you for writing this great piece about our work on FairSquare.
I’m linking the main paper here for those interested in reading more about fairness verification
http://pages.cs.wisc.edu/~loris/papers/oopsla17.pdf
Thanks! Added link to it alongside the earlier one. Also thanks, Cris.