Quantum Switch-Em
A recipe for changing the objectives of problems

|
| Composite crop of src1, src2, src3 |
Aram Harrow, Avinatan Hassidim, and Seth Lloyd are quantum stars who have done many other things as well. They are jointly famous for their 2009 paper, “Quantum algorithm for linear systems of equations.”
Today Ken and I discuss an aspect of their paper that speaks to a wider context.
The paper by Harrow, Hassidim, and Lloyd addresses a fundamental problem: given an 



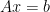
Here, we exhibit a quantum algorithm for this task that runs in
time, an exponential improvement over the best classical algorithm.
What strikes us is what HHL meant by “this task” in their abstract. It is not LSP. Indeed, it can’t be LSP. They want to do it with a number 
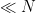


The problem they solve has been given its own name in subsequent treatments, including a 2015 paper by Andrew Childs, Robin Kothari, and Rolando Somma that greatly improved the time to achieve 
Quantum Linear Systems Problem (QLSP): Given a succinct representation of an invertible Hermitian matrix
, code for a unitary operator
that maps
to a quantum state
, and an error tolerance
, output a quantum state
such that

The 
It’s a Changed Problem
What a solution to QLSP gives you is not 

This blog did have a 2012 post on “lazy problem solving” that included the quip:
The idea is that when we solve a system
for
, it is likely that we do not really want
Ironically, the problem we suggested there, which is computing 
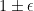
Going from LSP to QLSP switches the problem and enables showing that a quantum algorithm can solve the switched problem much faster than before. Very nice: HHL and its followups deserving of myriad citations. Scott’s review frames the question of whether the switch is fair from a practical perspective, including the restrictions on
Ketted Problems
We think the general recipe will be clear from a couple more examples. The first one seems not to be the same as what is called “QSAT” here or here.


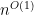


We still suspect this is known at least implicitly in the context of interactive proofs and PCPs and error-correcting codes. In that context, the idea of getting an assignment within distance
Note that the fact of





We can suppose that we have oracle lookup to bits of 

This is not in the shadow of Shor’s algorithm because that needs
More General Changed Problems
With all of these there are questions about how far the change reflects on the original problem, but at least the change generated substantial research and interesting new angles.
The Goldbach problem
Every even number is the sum of two primes 
A number is an almost prime if it is a prime or a product of at most two primes. This is a quite useful result, but not what we really believe is true.
P=NP




This says that if we relativize to some oracle
The Collatz Problem
The 
Let 
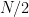


reaches 
All positive integers
Actually, Terence Tao got a cool result this year only by making a second change. In his paper “Almost All Orbits Of The Collatz Map Attain Almost Bounded Values” he proves that 


is fine. Here 
Explicit Hard Boolean Functions
Find explicit boolean functions with non-linear boolean complexity.
Boolean complexity with negation
These are the seminal results on monotone boolean complexity. They came up two years ago in an abortive attempt to prove 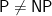
Quantum Supremacy
We come full circle back to quantum computing. This week there has been much hubbub over a prematurely-released announcement that Google researchers have built a quantum device able to complete probabilistic searches that are not feasible by any classical computer. If one goes back to origins of the term “quantum supremacy” in 2012, before Google’s approach was conceived in 2015, one can say the change is:
specific physical simulation or complexity-based problems
Scott has a great post with preliminary descriptions and evaluations, and we confess to adapting the following telegraphic evocation of how it works from Ryan O’Donnell and others in the comments section: Given a randomly-generated probability distribution 
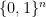








Again, this approach is different from demonstrating a specific computable function to separate classical and quantum and from the instances considered in the concluding post, with “supremacy” in its title, of our eight-part series in 2012 between Gil Kalai and, yes, Aram Harrow.
Open Problems
Is our general notion of “ketted problems” useful? Ketted SAT and Factoring lack the natural continuity in (Q)LSP, but at least for SAT it can be grafted on by composing the formula with an error-correcting code. There is still the issue of being able to extract less classical information from the ketted approximations.
We note a theory workshop being held this Saturday at UW Seattle in honor of Paul Beame’s 60th birthday. We congratulate Paul on both.
[added Aug. 2019 CACM link for Ewin Tang’s theorem; changed 1/e to (1 – 2/e) near end but not sure if that fix is intended by the source; reverted 1/e since the “(1 – 2/e)” holds in a simplified situation]


Trackbacks