What it takes to understand and verify the claim

|
| Cropped from 2014 Wired source |
John Martinis of U.C. Santa Barbara and Google is the last author of a paper published Wednesday in Nature that claims to have demonstrated a task executed with minimum effort by a quantum computer that no classical computer can emulate without expending Herculean—or Sisyphean—effort.
Today we present a lay understanding of the claim and discuss degrees of establishing it.
There are 76 other authors of the paper. The first 75 are alphabetical, then comes Hartmut Neven before Martinis. Usually pride of place goes to the first author, but that depends on size. Martinis is also the corresponding author. The cox in a rowing race rides at the rear. We have discussed aspects of papers with a huge number of authors here.
Three planks of a quantum supremacy claim are:
-
Build a physical device capable of a nontrivial sampling task.
-
Prove that it gains advantage over known classical approaches.
-
Prove that comparable classical hardware cannot gain such advantage.
Scott Aaronson not only has made two great posts on these and many other aspects of the claim, he independently proposed in 2015 the sampling task that was programmed, and he analyzed it in a foundational paper with Lijie Chen of MIT. Researchers at Google had already been thinking along those lines, and they anchored the team composed from numerous other institutions as well. As if on cue—just a couple days before Wednesday’s announcement—a group from IBM put out a post and paper taking issue with the argument for the third plank.
We’ll start with the task and go in order 1-3-2.
The Task
Any  -qubit quantum circuit
-qubit quantum circuit  and input
and input  to induces a probability distribution
to induces a probability distribution  on
on 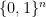 . Because it will not matter if we prepend up to NOT gates to , we may suppose
. Because it will not matter if we prepend up to NOT gates to , we may suppose  . Then
. Then  is a unit complex vector of length
is a unit complex vector of length  with entries
with entries  corresponding to possible outputs
corresponding to possible outputs  . Then the probability of getting
. Then the probability of getting  by a final measurement of all qubits is
by a final measurement of all qubits is

Next we consider probability distributions 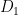 that are generated uniformly at random by the following process, for some
that are generated uniformly at random by the following process, for some  and taking
and taking  :
:
for  to
to 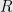 :
:
choose a  uniformly at random;
uniformly at random;
increment its probability  by
by  .
.
Here we intend  to be the number of binary nondeterministic gates in the circuit. In place of Hadamard gates the experimental circuits get their nondeterminism from these three single-qubit gates (ignoring global phase for
to be the number of binary nondeterministic gates in the circuit. In place of Hadamard gates the experimental circuits get their nondeterminism from these three single-qubit gates (ignoring global phase for  in particular):
in particular):

Here  where
where  and
and  is another name for NOT. The difference from using Hadamard gates matters to technical analysis of the distributions but the interplay between quantum nondeterministic gates and classical random coins remains in force.
is another name for NOT. The difference from using Hadamard gates matters to technical analysis of the distributions but the interplay between quantum nondeterministic gates and classical random coins remains in force.
The choice of  , , or
, , or  is itself uniformly random at each point where a single-qubit gate is used, except for not repeating the same gate on the same qubit, and those choices determine . Now we can give an initial statement of the task tailored to what the paper achieves:
is itself uniformly random at each point where a single-qubit gate is used, except for not repeating the same gate on the same qubit, and those choices determine . Now we can give an initial statement of the task tailored to what the paper achieves:
Given randomly-generated quantum circuits 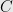 as inputs, distinguish
as inputs, distinguish  with high probability from any
with high probability from any  .
.
In more detail, the object is to take a number 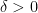 and moderately large integer
and moderately large integer  , both dictated by practical elements of the experiment, and fulfill this task statement:
, both dictated by practical elements of the experiment, and fulfill this task statement:
Given randomly-generated , generate samples  such that
such that  .
.
It’s important to note that there are two stages of randomness: one over which chooses , and then the stage of measuring after (perhaps imperfectly) executing . The latter can be repeated to get a large sample of strings for a given . The nature of the former stage matters most to justifying how to interpret tests of the samples and to closing loopholes. Our does not signify having uniform distribution in the latter sampling, but rather covers classical alternatives in the former stage that (with overwhelming probability) belong to a class we call  . The for random will (again w.o.p.) belong to a class
. The for random will (again w.o.p.) belong to a class 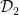 which we explain next.
which we explain next.
The World Series of Quantum Computing
In honor of the baseball World Series, we offer a baseball analogy. To make differences sharper to see, we take  , so
, so  . This is not what the experiment does: their biggest instance has 20 layers totaling
. This is not what the experiment does: their biggest instance has 20 layers totaling  nondeterministic single-qubit gates (plus
nondeterministic single-qubit gates (plus  two-qubit gates) on the
two-qubit gates) on the  qubits. But let us continue.
qubits. But let us continue.
We are distributing  units of probability among “batters” . A batter who gets two units hits a double, three units makes a triple, and so on. The key distinction is between the familiar batting average and the slugging average, which averages all the bases scored with hits:
units of probability among “batters” . A batter who gets two units hits a double, three units makes a triple, and so on. The key distinction is between the familiar batting average and the slugging average, which averages all the bases scored with hits:
-
The chance of making an out—that is, getting no units—is
 which is approximately
which is approximately 
-
The chance of hitting a single is also about
 , leaving
, leaving  as the frequency of getting an extra-base hit—which makes a “heavy hitter.”
as the frequency of getting an extra-base hit—which makes a “heavy hitter.”
-
From batters chosen uniformly at random, their expected batting average will be
 .
.
-
Their expected slugging average, however, will just be
 : they expect units to be distributed among them.
: they expect units to be distributed among them.
Thus with respect to a random , and without any knowledge of , a chosen team of hitters cannot expect to have a joint slugging average higher than . Moreover, for any fixed , the chance of getting a slugging average higher than  tails away exponentially in (provided also grows).
tails away exponentially in (provided also grows).
With respect to , however, a quantum device can do better. Google’s device programs itself given as the blueprint. So it just executes and measures all qubits to sample the output. Finding its own heavy hitters is what a quantum circuit is good at. The probability of getting a hitter who hits a triple is magnified by  compared to a uniform choice. Moreover, will never output a string with zero hits—a “can’t miss” property denied to a classical reader of . For large the probability distribution approaches
compared to a uniform choice. Moreover, will never output a string with zero hits—a “can’t miss” property denied to a classical reader of . For large the probability distribution approaches  and the slugging expectation is approximately
and the slugging expectation is approximately

That is, a team  drafted by sampling from random quantum circuits expects to have a slugging average near
drafted by sampling from random quantum circuits expects to have a slugging average near  . This defines the class . If works perfectly, the average will surpass whenever
. This defines the class . If works perfectly, the average will surpass whenever 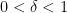 with near certainty as grows.
with near certainty as grows.
Google’s circuits have up to  , so
, so  . Then the “can’t miss” aspect of the quantum advantage is less sharp but the approximation is closer and the idea of is the same. The nature of can actually be seen from point intensities in speckle patterns of laser light:
. Then the “can’t miss” aspect of the quantum advantage is less sharp but the approximation is closer and the idea of is the same. The nature of can actually be seen from point intensities in speckle patterns of laser light:

Real-World Execution
The practical challenge is that the implementation of is not perfect. The consequence of an error in the final output is severe. The heavy-hitter outputs of a random are generally not bit-wise similar, so sampling their neighbors is like sampling uniform distribution. As the paper says, “A single bit or phase flip over the course of the algorithm will completely shuffle the speckle pattern and result in close to zero fidelity.”
Their circuits are sufficiently random that effects of sporadic errors over millions of samples can be modeled by a simple equation using quantum mixed states. We shortcut the paper’s physical analysis by drawing on John Preskill’s illustration of a de-polarizing channel in chapter 3 of his wonderful online notes on quantum computation to reach the same equation (1). The modeling has informative symmetry when the errors of a bit flip, phase flip, or both are considered equally likely with probability  . The action on the entangled pair
. The action on the entangled pair  in the Bell basis is given by the density matrix evolution
in the Bell basis is given by the density matrix evolution  where
where

where  and
and  is the density matrix of the completely mixed two-qubit state which is just a classical distribution. This presumes
is the density matrix of the completely mixed two-qubit state which is just a classical distribution. This presumes  ; note that
; note that  completely mixes the Bell basis already. The fidelity of
completely mixes the Bell basis already. The fidelity of  to the original state is then given by
to the original state is then given by

This modeling already indicates that with  serial opportunities for error the fidelity will decay as
serial opportunities for error the fidelity will decay as  . The Google team found low ‘crosstalk’ between qubits and they used exactly this expression in the form
. The Google team found low ‘crosstalk’ between qubits and they used exactly this expression in the form  , evidently with
, evidently with  being the native gate error rate they call
being the native gate error rate they call  and
and  where having
where having  for single-qubit gates supplies the factor
for single-qubit gates supplies the factor  .
.
The error 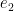 for the two-qubit gates is similarly represented. (The full modeling in the supplement, section V, is more refined.)
for the two-qubit gates is similarly represented. (The full modeling in the supplement, section V, is more refined.)
By observing their benchmarks (discussed below) for varying small they could calculate the decay concretely and hence estimate values of  for the vast majority of runs with larger . The random nature of the circuits evidently makes covariance of errors that could systematically upset this modeling negligible. Thus they can conclude that their device effectively samples from the distribution
for the vast majority of runs with larger . The random nature of the circuits evidently makes covariance of errors that could systematically upset this modeling negligible. Thus they can conclude that their device effectively samples from the distribution

Such distributions can be said to belong to the class  . The paper reports that their is driven below
. The paper reports that their is driven below  but stays above
but stays above  in trials. This bounds the range of the
in trials. This bounds the range of the  they can separate by. That is separated from zero achieves the first plank and starts on the second. The third needs attention first, however.
they can separate by. That is separated from zero achieves the first plank and starts on the second. The third needs attention first, however.
The Third Plank
Both concrete and asymptotic complexity evidence matter for the third plank, the former for now and the latter for how and everything else may scale up in the future. In asymptotic complexity, we still don’t know that  and
and 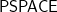 , which sandwich the quantum feasible class
, which sandwich the quantum feasible class 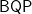 , are different. Thus asymptotic evidence about polynomial bounds must be conditional. Asymptotic evidence about linear time bounds can be sharper but then tends to be conditioned on forms of SETH in ways we still find puzzling.
, are different. Thus asymptotic evidence about polynomial bounds must be conditional. Asymptotic evidence about linear time bounds can be sharper but then tends to be conditioned on forms of SETH in ways we still find puzzling.
Lower bounds in concrete complexity are less known and have a self-defeating aspect: We are trying to say that any program  run for less than an infeasible time
run for less than an infeasible time  must fail. But we can’t run for time
must fail. But we can’t run for time  to show that it fails because time is just as infeasible as time . The best we can do is run for a feasible
to show that it fails because time is just as infeasible as time . The best we can do is run for a feasible  , either (i) on a smaller task size, or (ii) on the original task but argue it doesn’t show progress. Neither is the same; we made some attempts on (ii).
, either (i) on a smaller task size, or (ii) on the original task but argue it doesn’t show progress. Neither is the same; we made some attempts on (ii).
What the paper does instead is argue that a particular classical approach (also from the Aaronson-Chen paper) would take 10,000 years on today’s hardware. This reminds us of a famous 1977 “Mathematical Games” column by Martin Gardner, which quotes an estimate by Ron Rivest that for factoring a 126-digit number on then-current hardware, “the running time required would be about 40 quadrillion years!” It took only until 1994 for this to be broken. Sure enough, IBM calculated that a more-clever implementation of on the Summit supercomputer would take under 3 days. The point is not so much that the Summit hardware is comparable as that estimates based on what are currently thought to be the best possible (classical) methods need asterisks.
On the asymptotic side, the last section (XI) of the paper’s 66-page supplement proves a theorem toward showing that a classical simulation from  that scales polynomially with would collapse
that scales polynomially with would collapse 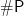 to
to  , and similarly for sub-exponential running times. It does not get all the way there, however: improvements would need to be made in upper bounds for approximation and for worst-case to average-case equivalence. [Added 10/31/19: see this new paper by Scott A. and Sam Gunn.] Moreover, there is a difference from what their statistical testing achieves that we try to explain next.
, and similarly for sub-exponential running times. It does not get all the way there, however: improvements would need to be made in upper bounds for approximation and for worst-case to average-case equivalence. [Added 10/31/19: see this new paper by Scott A. and Sam Gunn.] Moreover, there is a difference from what their statistical testing achieves that we try to explain next.
The Statistical Tests
We can cast the second plank in the general context of predictive modeling. Consider a forecaster who places estimates  on the true probabilities
on the true probabilities 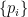 of various events. Here we need to compute the probabilities
of various events. Here we need to compute the probabilities  of output strings observed from the physical device, using the given circuit and the estimate of . This must be done classically, and incurs the “
of output strings observed from the physical device, using the given circuit and the estimate of . This must be done classically, and incurs the “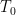 -versus-” issue discussed above.
-versus-” issue discussed above.
But before we get to that issue, let’s say more from the viewpoint of predictive modeling. We measure how well the forecasts 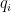 conform to the true
conform to the true 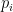 by applying a prediction scoring rule. If outcome
by applying a prediction scoring rule. If outcome  happens, then the log-likelihood rule assesses a penalty of
happens, then the log-likelihood rule assesses a penalty of

This is zero if the outcome was predicted with certainty but goes to infinity if the individual is very low—which is an issue in the quantum case. The expected score based on the true probabilities is
![\displaystyle E[L_i] = \sum_i p_i \log(\frac{1}{q_i}). \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++E%5BL_i%5D+%3D+%5Csum_i+p_i+%5Clog%28%5Cfrac%7B1%7D%7Bq_i%7D%29.+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)
The log-likelihood rule is strictly proper insofar as the unique way to minimize ![{E[L_i]}](https://s0.wp.com/latex.php?latex=%7BE%5BL_i%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) is to set
is to set 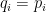 for each . In human contexts this means the model has incentive to be as accurate as possible.
for each . In human contexts this means the model has incentive to be as accurate as possible.
The formula (2) is the cross-entropy from the 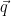 distribution to the
distribution to the 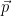 distribution. Before we can use it, we need to ask a question:
distribution. Before we can use it, we need to ask a question:
What is forecasting what? Is the device the imperfect model and do the “true  ” come from the analysis of giving
” come from the analysis of giving  ?
?
This is how it appeared to us and seems from other writing, but we can argue the opposite from first principles: The physical device is the “ground truth” however it works. The assertion that it is executing a blueprint with some estimated loss in fidelity is really the model. Then it follows that is analogous to not , and we can call it  . Since we can compute it, we can calculate
. Since we can compute it, we can calculate  in (2).
in (2).
Saying this leaves “” in (2) as denoting the device’s true probabilities  of giving the output strings . These are not directly observable: it is infeasible to sample the device often enough to expect a sufficiently large number of repeated occurrences based on the “birthday” threshold. Thus there appears to be no way to estimate individual values in (2), but this doesn’t matter: the very act of sampling the device carries out the “
of giving the output strings . These are not directly observable: it is infeasible to sample the device often enough to expect a sufficiently large number of repeated occurrences based on the “birthday” threshold. Thus there appears to be no way to estimate individual values in (2), but this doesn’t matter: the very act of sampling the device carries out the “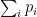 ” part of (2). Summing
” part of (2). Summing  for the that occur over a large but feasible number of trials gives estimates of (2) that are close enough to make the needed distinctions with high confidence. We can then match the estimate of against the theoretical estimate, which we may call
for the that occur over a large but feasible number of trials gives estimates of (2) that are close enough to make the needed distinctions with high confidence. We can then match the estimate of against the theoretical estimate, which we may call  , assuming accurate knowledge of . By the
, assuming accurate knowledge of . By the 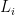 scoring function being strictly proper, this match entails achieving
scoring function being strictly proper, this match entails achieving  with sufficient approximation. This property of the goal mitigates some of the modeling issue.
with sufficient approximation. This property of the goal mitigates some of the modeling issue.
This issue was clarified by reading Ryan O’Donnell’s 2018 notes on quantum supremacy, which preview this same experiment. The above view on which is “forecaster”/”forecastee” might defend the team against his opinion that it “kind of gets its stats backwards”—but the inability to compute cross-entropy from the blueprints’ distribution to that of the device remains an issue. What the team did instead, however, is shift to something simpler they call “linear cross-entropy.” They simply show that the from their samples collectively beat the “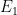 ” that applies to —more simply put, that when summed over -many trials
” that applies to —more simply put, that when summed over -many trials  ,
,

This just boils down to giving a z-score based on the modeling for . It is analogous to how I (Ken writing this) test for cheating at chess. We are blowing a whistle to say the physical device is getting surreptitious input from quantum mechanics to achieve a strength of compared to a “classical player” who is “rated” as having strength .
The difference from showing that the device’s score from (2) is within a hair of is that this is based on . To be sure, the paper shows that their -scores conform to those one would expect an “-rated” device to achieve. But this is still not the same as (2). Whether it is tantamount for enough purposes—including the theorem about —is where we’re most unsure, and we note distinctions between fully (classically) sampling and “spoofing” the statistical tests(s) raised by Scott (including directly in reply to me here) and others. The authors say that using “linear cross-entropy” gave sharper results and that they tried other (unspecified) measures. We wonder how much of the space of scoring rules familiar in predictive modeling has been tried, and whether rules having more gentle tail behavior for tiny than might do better.
Finally, there is the issue that the team were able to verify exactly only for circuits up to  qubits and/or with
qubits and/or with 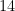 levels, not
levels, not 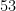 with
with  levels. This creates a dilemma in that IBM’s paper may push them toward
levels. This creates a dilemma in that IBM’s paper may push them toward  or
or  , but that increases the gap from instance sizes they can verify. This also pushes away from the possibly of observing the
, but that increases the gap from instance sizes they can verify. This also pushes away from the possibly of observing the  nature of more directly by finding repeated strings in the second-stage sampling of a fixed . The “birthday paradox” threshold for repeats is roughly
nature of more directly by finding repeated strings in the second-stage sampling of a fixed . The “birthday paradox” threshold for repeats is roughly 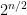 samples, which might be feasible for around
samples, which might be feasible for around  (given the classical work needed for each , which IBM’s cleverness might speed) but not above
(given the classical work needed for each , which IBM’s cleverness might speed) but not above 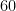 . The distinguishing power of repeats drops further with . We intend to say more about these last few points, and we are sure there are many chapters still to write about supremacy experiments.
. The distinguishing power of repeats drops further with . We intend to say more about these last few points, and we are sure there are many chapters still to write about supremacy experiments.
Open Problems
Is the evidence so far convincing to you? Is enough being done on the third plank to exclude possible clever classical use of the fact that the circuits are given as “white boxes”? Are there possible loopholes?
We would also be grateful to know where we may have oversimplified our characterization of the task and our analysis of the issues.
[Added more error-modeling details to the real-world section; some minor word changes; clarified how X,Y,W are chosen; addendum to clarify modeling issues; 10/31/19: removed addendum after blending it into a revision of the last main section—original version preserved here—and linked new Aaronson-Gunn paper.]
Like this:
Like Loading...
Related




I am a quantum computer skeptic who is amazed that it appears to have worked for a 53 qubit machine. However, I am dissapointed that there does not appear to be a way to directly test it for say a 100 qubit machine, since no digital computer can simulate such a machine. So how long will we have to wait until Shor’s algorithm can be tested? How many qubits will be required?
I”m between skeptic and believer because I think quantum supremacy is undecidable. Whenever people manage to build a quantum machine with tremendous effort, a possibility appears to solve the same task with huge classical resources. So we may never see quantum computers leave the laboratory.
It’s unfortunate that the Google authors didn’t just announce their device and the results of running it, and let the academic community engage in a tasteful discussion of whether this was an example of Quantum Supremacy, any outcome of which would not have reflected negatively on their impressive advance in engineering a reliable superconducting quantum logic circuit.
But of course, that’s not what happened, and with Pons and Fleischmann-like bravado, they had to proclaim to the world that they had won the Gold in the Quantum Supremacy Olympics, with the entirely predictable fertilizer storm over that claim grabbing press attention away from their actual accomplishment.
Quantum Supremacy should at least strongly suggest the inevitability of working quantum computers with low noise and useful numbers of bits. This result, especially with IBM’s contribution. seems to fall a bit short of that mark.
Excellent post!
As you write, there are two crucial questions regarding the Google’s quantum supremacy claims. The first is about the quality of the evidence for their prediction regarding the outcome of the 53 qubit experiment. They predict that the statistical test will give a value larger than t= 1/10,000. (Or 1+1/10,000 if we don’t subtract the 1.) Let’s call t the fidelity. The second question is about the quality of their claim that achieving a sample with t larger than 1/10,000 represents “quantum supremacy”. (To save latex power I use t instead of .)
.)
My own prediction (in several works) about experiments of this kind is that (modulo some small issues that I will neglect) the resulting distribution can be achieved by a classical computer with a polynomial time algorithm in the size of the circuit. And here “polynomial-time” refers to a low degree polynomial with moderate constants.
Regarding the second question. Let me remark that as far as I can see the IBM claim is about a full computation of all the 2^53 probabilities. It is reasonable to think that producing a sample (or even a complete list of 2^53 probabilities) with fidelity t reduces the classical effort linearly with t. (This is the claim about the specific algorithm used by the Google team.) If this holds for the IBM algorithm then the 2.5 days will go down to less than a minute. It will be very interesting to explore if for a version of the IBM algorithm we can have a running time which is linear with t. (It is also interesting if in a discussion based on heuristic arguments both for computational hardness and computational easiness, we can take for granted such a linear dependence on the algorithm running time on t.)
In my view the second issue is the crucial one. Reaching a fidelity above 1/10,000 for a 53 qubit experiments would cause me to have doubts on my conjecture “against” quantum supremacy. (Even if it is only one minute on the IBM super-duper computer.) The crucial aspect, in my view, is to understand (and also further develop, and replicate) the experiments in the regime that can be tested by a classical computer. (This regime is larger now by the IBM method.)
What I would like to see is:
A) an independent verification of the statistical tests outcomes for the experiments in the regime where the Google team classically computed the probabilities.
This seems quite easy to perform and maybe this was already done as part as the refereeing process. This looks to me a crucial step in a verification of such an important experiment.
B) Experiments giving full histograms for circuits in the 10-25 qubit range. (Again maybe this was already done.) See this comment by Ryan.
Perhaps at a later stage also:
C) Experiments in the 10-30 qubit range on the IBM quantum computer. (This is an excellent suggestion by Greg Kuperberg.)
D) In practice the 53 qubit samples might be still hard to check for IBM. (The 1/10,000 improvement that I heuristically suggested is not relevant for checking the fidelity in Google’s sample.) But maybe Google can produce samples for 41-49 qubits for which IBM can compute the probabilities quickly and test the Google’s prediction on the fidelity.
I ask: Does the distinction “polynomial time-nondeterministic polynomial time” dissolve here?
I have a some question concerning the main task statement –
” Given randomly-generated {C}, generate samples {z_1,…,z_k \in \{0,1\}^n} such that {\frac{1}{k}(D_C(z_1) + \cdots D_C(z_k)) \geq 1 + \delta}. ”
Conretely, we have for each i D_C(z_i) \leq 1, so the left part always is less or equal 1
and cannot be greater or equal 1+ \delta. Right ?
OK, but what if building an n-qubit quantum computer takes exponential time in n? Human tasks also have their time complexity…
What is the quantum equivalent of Moore’s law? How many years to double the number of qubits?
Building an n-qubit QC is probably an NP-complete problem. Quantum computers are built by means of classic algorithms since our brains are classic computers. An n-qubit quantum computer being built in time polynomial in n would imply that factoring is in P, since quantum computers can factor in polynomial time.