Counting Votes By Humans
A new way to agree on calculations

|
| Cropped from ABC News source |
Troy Price is the Iowa Democratic Party Chair. He was in charge of Iowa’s primary vote. The vote totals were due Monday night but have not been finished, now three nights later, and may need to be re-tallied. At a press conference to explain the cause for the delay—mainly a failed phone app—Price was asked, “How can anyone trust you now?”
Today, Ken and I discuss a way to make counting votes quickly checkable by humans.
Indeed the issue with vote counting is one of trust. Our idea is to use computers to assist humans in tallying the votes. But the computers will not be trusted. The goal is to make the number of operations that humans perform of order 

The Vote-Counting Game
Our key insight is to assume that the election is being monitored by two parties—call them Donna and Rachel—who are adversaries. Let us suppose the votes can only be 

We insist that D and R play a game. We will explain how the game is played in a moment. The key is that the game—the voting game—has several properties.
-
At the end of the game, D and R both have made at most order
- At the end of the game, D and R may agree on the vote count.
- At the end of the game, if D and R do not agree on the vote count, then one of them will be found to be “cheating” and will be fined a monetary amount.
The voting game “solves” the problem of having a humanly checkable election process. The incentive is for D and R to be honest and correct. This precludes either passive error, such as by having incorrect software, or active cheating. If they cheat they may get the fine. If the fine is high enough, that should make D and R strive to be correct.
Item 2 is critical. We do not claim that if D and R agree that their tally is correct. We only claim that if they agree they should be content with the outcome. This is a key insight and perhaps the most controversial point. If we insisted that D and R only agree when they have the objectively correct count, then it is easy to see they must violate 1: they must take order
Structure of the Game and Preparation By the Parties
One structural requirement that is a practical necessity anyway is that the vote count is ordered and that the R and D counts follow the same order. We may suppose, say, that the votes are totaled alphabetically by county, then in order of precints within each county, and finally by name in each precinct. Both D and R are required to provide running tallies that respect this order and their computer systems must allow random access to any running subtotal. Producing the tallies of course is a lot of work while the votes are being counted, but this is divided among many people where each side has onsite observers. The act of checking the tallies—and either finding an error or agreeing on the totals—is what we will optimize.
Let’s consider the tallying of votes. Let

be the ordered sequence of votes. Let
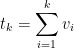
be the running tally of the votes—say the count of
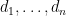
and R’s vector be

These vectors are computed by computers owned and run by D and R respectively, using the agreed ordering. Each is responsible for the correctness of their vectors. A critical point is that D and R are responsible for their vectors—we do not assume that they are correct.
Running The Protocol
First, D and R check whether 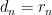

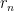
The value they agree on is not necessarily the true
.
This is a critical point. We cannot calculate 
If 
So take 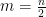
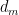

-
If
, then D and R know there is an error in the first half. They recurse on that.
-
If
, then even though these counts may not be correct by themselves, their agreement implies there must be a discrepancy in the second half. D and R recurse on that.
This becomes a binary search in which the invariant is that the counts at the low boundary agree and the counts at the high boundary disagree. In about 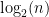
This completes the description of the protocol. In a more abstract setting this is the same as the discrepancy-finding protocol of Mauricio Karchmer and Avi Wigderson; see their 1990 paper and this 2017 paper by Or Meir.
Analysis
The time analysis is simple. The running time 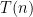

with solution is 
One fine point is that neither D nor R has any incentive to “lie” by making their tallies deliberately wrong. Suppose 
Both the penalty and the swiftness of determining itare incentives to D and R to have good programs. They must rely on a program that each has to determine their values 

-
Humans are able to do the checking. They never do more than order
- The result is not a guaranteed correct sum. It is guaranteed that D and R will be forced to agree.
- The players D and R are assumed to work against each other.
If there are more than two non-negligible candidates then the details are more complicated—such as needing one “prover” per candidate—but the principles are much the same. More problematic are cases where there might be up to 
Open Problems
In what situations might this protocol be useful? Has anything like it been proposed?
Update (12:45am ET 2/7): Iowa did finish the count by midnight Thursday in Central Time, but it is open to challenge by any candidate until 1pm ET. Update: The 1pm challenge deadline has been extended to Monday, so the results will not be final until at least a week later than the vote. See also this CNN story about errors in the count. And this Sunday NYT story on counting errors etc.
[added updates; added reference to Karchmer-Wigderson protocol.]


This seems to me just the Karchmer-Wigderson protocol for , i.e., when D gets some
, i.e., when D gets some  and R gets some
and R gets some  such that
such that  and their goal is to find an
and their goal is to find an  such that
such that  .
.
Thanks very much. I have added a reference to this.
“We cannot calculate {t_{n}} with limited human computations. But if D and R agree that is good enough.”
I claim it isn’t. Voting isn’t just about D and R, it’s about the voters. If the voting public isn’t satisfied their votes have been tallied correctly, it won’t matter that D and R agree. The system loses then anyway. That the voters agree on the outcome is, IMO, far more important than whether the candidates agree.
And how are you going to order the votes? Obviously, this cannot be done with a computer, as the computer may alter the votes before handing them to each party. Doing this by hand, and the number of human actions is no longer O (log n). If you number each ballot paper before hand, you’ll have a hard time convincing people their vote is secret. And which entity is giving copies of the votes to each candidate? How can you trust them? (Surely, you cannot give the original ballot papers to each candidate — either one could change a valid vote to their opponent into an invalid one with ease).
Dear Abigail:
You make two separate points. The reason D and R need to agree is that they represent the voters. I believe that having them agree is perhaps not perfect, but is a reasonable goal. Note, in practice we could have multiple D and R’s and use try and use the same method.
The other issue on ordering is interesting. I think that can also be handled in practice by order groups of the vote objects. But I will think about your point.
Thanks again.
Best
Dick
Discovered a new Era in Optimization: Hypercomplex Optimization and
published a paper in American peer-reviewed journal:
https://www.aimsciences.org/journal/2155-3289
This seems to be basically a refereed delegation protocol: https://www.cs.tau.ac.il/~canetti/CRR11.pdf
Dear Pratyush:
Thanks for pointing out the connection. I believe our suggestion is different in a basic way. Their result assumes that one of the provers is honest, in our terms is correct. We do not. In their result they get the right answer. We do not. We do get agreement which is weaker.
What did you think?
Best
Dick