Part 1 of a two-part series

Daniel Winton is a graduate student in mathematics at Buffalo. He did an independent study with me last semester on descriptive complexity.
Today we begin a two-part series written by Daniel on a foundational result in this area involving first-order logic and star-free languages.
Dick and I have discussed how GLL might act during the terrible coronavirus developments. We could collect quantitative and theoretical insights to help understand what is happening and possibly contribute to background for attempts to deal with it. Our March 12 post was this kind, and was on the wavelength of an actual advance in group testing announced in Israel two days ago, as noted in a comment. We could try to be even more active than that. We could focus on entertainment and diversion. Our annual St. Patrick’s Day post mentioned the ongoing Candidates Tournament in chess, with links to follow it live 7am–noon EDT. Game analysis may be found here and elsewhere.
Here we’re doing what we most often do: present a hopefully sprightly angle on a technical subject. We offer this in solidarity with the many professors and teachers who are beginning to teach online to many students. The subject of regular languages is the start of many theory courses and sometimes taught in high schools. Accordingly, Dick and I decided to prefix a section introducing regular languages as a teaching topic and motivating the use of logic, before entering the main body written by Daniel.
Regular Languages and Logic
Regular languages are building blocks used throughout computer science. They can be defined in many ways. Two major types of descriptions are:
-
Regular expressions. For example, the regular expression

describes the set of strings over the alphabet 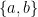 that have an even number of
that have an even number of  ‘s.
‘s.
-
Finite automata, for example:

The regular languages defined by (1) and (2) are the same. All regular expressions have corresponding finite automata. This equivalence makes a powerful statement about the concept of regular languages. The more and more diverse definitions we have, the better we understand a concept. This leads us to consider other possible definitions.
A natural kind of definition involves logic. Studying complexity classes through logic and model theory has proven fruitful, creating descriptive complexity as an area. Good news: there are logic definitions equivalent to the regular languages. Bad news: they require going up to second-order logic. We would like to stay with first-order logic. So we ask:
What kind of languages can we define using only first-order logic (FOL) and simple predicates like “the 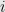 th bit of
th bit of  is
is  ” and “place comes before place
” and “place comes before place  “?
“?
The answer is the star-free languages, which form a subclass  of the regular languages. They were made famous in the book Counter-Free Automata by Robert McNaughton and Seymour Papert, where the equivalence to FOL was proved. A portentous fact is that these automata cannot solve simple tasks involving modular counting. Nor can perceptrons—the title subject of a book at the same time by Papert with Marvin Minsky, which we discussed in relation to both AI and circuit complexity. This post will introduce and FOL, prove the easier direction of the characterization, and give two lemmas for next time. The second post will present a new way to visualize the other direction. The rest of this post is by Daniel Winton.
of the regular languages. They were made famous in the book Counter-Free Automata by Robert McNaughton and Seymour Papert, where the equivalence to FOL was proved. A portentous fact is that these automata cannot solve simple tasks involving modular counting. Nor can perceptrons—the title subject of a book at the same time by Papert with Marvin Minsky, which we discussed in relation to both AI and circuit complexity. This post will introduce and FOL, prove the easier direction of the characterization, and give two lemmas for next time. The second post will present a new way to visualize the other direction. The rest of this post is by Daniel Winton.
No Stars Upon Thars
A regular language over an alphabet  is one with an expression that can be obtained by applying the union, concatenation, and Kleene star operations a finite number of times on the empty set and singleton subsets of . Star-free languages are defined similarly but give up the use of the Kleene star
is one with an expression that can be obtained by applying the union, concatenation, and Kleene star operations a finite number of times on the empty set and singleton subsets of . Star-free languages are defined similarly but give up the use of the Kleene star  operation, while adding complementation (
operation, while adding complementation (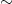 ) as a basic operation. The star-free languages are a subset of the regular languages, because regular languages are closed under complementation.
) as a basic operation. The star-free languages are a subset of the regular languages, because regular languages are closed under complementation.
Complementation often helps find star-free expressions that we ordinarily write using stars. For instance, if the alphabet is , then  gives
gives  . The following lemma gives a family of regular expressions that use Kleene star but are really star-free.
. The following lemma gives a family of regular expressions that use Kleene star but are really star-free.
Lemma 1 The language given by taking the Kleene star operation on a union of singleton elements in an alphabet  is star-free.
is star-free.
Proof. For  we have that
we have that  can be given by
can be given by


For example, the language  is star-free because
is star-free because  is by this lemma. This idea extends also to forbidden substrings—e.g., the set of strings with no
is by this lemma. This idea extends also to forbidden substrings—e.g., the set of strings with no 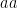 is
is  .
.
The language  is not the same, however, and it is not star-free. Intuitively this is because it involves modular counting: an in an odd position is OK but not even. The parity language
is not the same, however, and it is not star-free. Intuitively this is because it involves modular counting: an in an odd position is OK but not even. The parity language  from the introduction is another example. So is a proper subset of the regular languages. What kind of subset? This is where having a third description via logic is really useful.
from the introduction is another example. So is a proper subset of the regular languages. What kind of subset? This is where having a third description via logic is really useful.
The First Order of Business
In addition to the familiar Boolean operations  and truth values, first-order logic provides variables that range over elements of a structure and quantifiers on those variables. Since we will be concerned with Boolean strings
and truth values, first-order logic provides variables that range over elements of a structure and quantifiers on those variables. Since we will be concerned with Boolean strings  , the variables will range over places in the string
, the variables will range over places in the string  , where
, where  . A logic also specifies a set of predicates that relate variables and interact with the structure. For strings we have:
. A logic also specifies a set of predicates that relate variables and interact with the structure. For strings we have:
-
 , meaning that the symbol indexed
, meaning that the symbol indexed  in is the character
in is the character  . The logic gives one such predicate for each
. The logic gives one such predicate for each  .
.
-
 , with the obvious meaning for natural numbers and
, with the obvious meaning for natural numbers and  .
.
We can take the  for granted since we are talking about strings, but we need to say that predicates like
for granted since we are talking about strings, but we need to say that predicates like  and
and  are excluded, so we call this
are excluded, so we call this ![{\mathsf{FO}[<]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathsf%7BFO%7D%5B%3C%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . We could define equality by
. We could define equality by  but we regard equality as inherent.
but we regard equality as inherent.
We can use 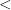 to define the successor relation
to define the successor relation  , which denotes that position comes immediately after position :
, which denotes that position comes immediately after position :

Note the use of quantifiers. We can use quantifiers to say things about the string too. For instance, the language  of strings having no substrings is defined by the logical sentence
of strings having no substrings is defined by the logical sentence

It is implicit here that and are always in-bounds. If  were a legal constant with
were a legal constant with  always false then a string like
always false then a string like  (which belongs to ) would falsify
(which belongs to ) would falsify  with
with  and
and  .
.
How big is ? We'll see it is no more and no less than .
From SF to FO
To prove that any language in has a definition in  , we will not only give a sentence but also a formula
, we will not only give a sentence but also a formula  . We will define this formula to indicate that for a given string , the portion of the string between indices and
. We will define this formula to indicate that for a given string , the portion of the string between indices and  is in . Then for the correct choices of and , gives . We define
is in . Then for the correct choices of and , gives . We define  to test middle portions of strings, because it handles lengths better for the induction in the concatenation case.
to test middle portions of strings, because it handles lengths better for the induction in the concatenation case.
Theorem 2
Every language in  is definable in
is definable in ![{\mathsf{FO}[<]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathsf%7BFO%7D%5B%3C%5D%7D&bg=e8e8e8&fg=000000&s=0&c=20201002) .
.
The proof is a nice example where “building up” to prove something more general—involving two extra variables—makes induction go smoothly.
Proof: Let be a star-free regular language and  the portion of the string between indices (inclusive) and (exclusive) is contained in
the portion of the string between indices (inclusive) and (exclusive) is contained in  . Let
. Let ![{\phi_L(i,j)\in \sf{FO}[<]}](https://s0.wp.com/latex.php?latex=%7B%5Cphi_L%28i%2Cj%29%5Cin+%5Csf%7BFO%7D%5B%3C%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) be the formula denoting that for a given string
be the formula denoting that for a given string  , that is, is the representation of
, that is, is the representation of  in . We will show that such a exists via induction on . This is sufficient, as for a given symbol that always represents the length of a string ,
in . We will show that such a exists via induction on . This is sufficient, as for a given symbol that always represents the length of a string ,  is the formula in representing the language .
is the formula in representing the language .
First, we must show that  is in for one of the basis languages,
is in for one of the basis languages,  , and , for some in . We have that:
, and , for some in . We have that:

Now, we must show that given star-free languages 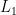 and
and 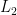 with FO
with FO![{[<]}](https://s0.wp.com/latex.php?latex=%7B%5B%3C%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) translations
translations  and
and  respectively, we have
respectively, we have  ,
,  , and
, and  are in
are in ![{\sf{FO}[<]}](https://s0.wp.com/latex.php?latex=%7B%5Csf%7BFO%7D%5B%3C%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . Then:
. Then:

Since star-free languages can be obtained by applying the union, concatenation, and complementation operations a finite number of times on  and singleton subsets of , this completes the proof of
and singleton subsets of , this completes the proof of ![{\mathsf{SF} \subseteq \mathsf{FO}[<]}](https://s0.wp.com/latex.php?latex=%7B%5Cmathsf%7BSF%7D+%5Csubseteq+%5Cmathsf%7BFO%7D%5B%3C%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) .
.
Two Lemmas For Next Time
Prefatory to showing (in the next post) that is contained in , we prove properties about substrings on the ends of star-free languages, rather than in the middle as with the trick in the proof of Theorem 2.
Let be a language over an alphabet and  be a word in
be a word in  for some
for some 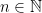 . Define
. Define  , the right quotient of by , by
, the right quotient of by , by  and
and  , the left quotient of by , by
, the left quotient of by , by  . First we handle right quotients:
. First we handle right quotients:
Lemma 3 If 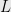 is star-free, then
is star-free, then  is star-free.
is star-free.
Proof: For any word over we define a function  by
by  where
where  . If
. If  , then
, then  , and so the statement of the lemma trivially holds. So let
, and so the statement of the lemma trivially holds. So let  for some string
for some string  and character . Note that
and character . Note that  . Thus
. Thus  for all
for all  . Hence it suffices to define
. Hence it suffices to define  for any single character by recursion on . We have:
for any single character by recursion on . We have:

and recursively:

In general, if  , then
, then

Lemma 4 If is star-free, then  is star-free.
is star-free.
The proof of Lemma 4 is similar to the proof of Lemma 3. The main differences lie in the concatenation subcase for the  case and the order of quotienting when using this operation repeatedly.
case and the order of quotienting when using this operation repeatedly.
Proof: For any word over we define a function by where  . If , then , and so the statement of the lemma trivially holds. So let for some string and character . Note that
. If , then , and so the statement of the lemma trivially holds. So let for some string and character . Note that  . Thus
. Thus  for all . Hence it suffices to define for any single character by recursion on . We have:
for all . Hence it suffices to define for any single character by recursion on . We have:

and recursively:

In general, if , then

Open Problems
There are richer systems such as  and
and  . Note that allows defining the relation via
. Note that allows defining the relation via  . We can define non-regular languages such as
. We can define non-regular languages such as  in . The class
in . The class  famously equals uniform
famously equals uniform 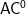 , see chapter 5 of Neil Immerman's book Descriptive Complexity. Thus we hope our new style for proving
, see chapter 5 of Neil Immerman's book Descriptive Complexity. Thus we hope our new style for proving ![{\mathsf{FO}[<] \subseteq \mathsf{SF}}](https://s0.wp.com/latex.php?latex=%7B%5Cmathsf%7BFO%7D%5B%3C%5D+%5Csubseteq+%5Cmathsf%7BSF%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) (to come in the next part) will build a nice foundation for visualizing these higher results.
(to come in the next part) will build a nice foundation for visualizing these higher results.
Like this:
Like Loading...
Related


SF = FO[<] is known as Theorem of Schützenberger. What is not very well-known is that
Schützenberger gave another characterization of SF in terms of regular expressions:
A language is star-free iff it expressible by regular expressions where the use of the star-
operation is only allowed over (prefix?)codes of bounded synchronization delay.
Thanks. More detail is available in this 2007 survey, and we followed its ascriptions.
SInce FO[<] is in my mind an alias of SF, I made this mistake. Sch. related automata and syntactic monoids to expressions, while the relations to logic are off course due to M.+P. Sorry for that.
NB: The reference to Schützenberger's other characterization of SF was given to me by one of the authors of the survey.
Maybe I misunderstood something. I think the proposal for defining equality in FOL[<] contains a typo? Doesn't seem to be well-formed. If I'm mistaken, please clarify. thanks!
Given only ‘<', you'd want to say neither i < j nor j < i.
Thanks! Something went strange in the translation of “lor” and “land” and only there. I think what happened is that the text “neither i j” made the middle part get parsed as an HTML angle-bracket item. Hard to spot… Added: in fact, it happened again or “neither i < j nor i > j, and probably to you in your first comment… So “neither I < j nor j < i" it has to be…
This is great! I really enjoyed reading through this article.
Thank yo so much