Worst Case Complexity
What is the right complexity measure for algorithms?

Claude Shannon is the father of information theory, who–while at Bell Telephone Labs– wrote the seminal paper that created the field in 1948. That is right, it was called “ Bell Telephone Labs” in those days. His famous paper set out the basic framework of information theory that is still used today: a message, an encoder, a channel with noise, a decoder. Very impressive.
Shannon also proved the existence of “good” error correcting codes via a probabilistic existence argument. While we usually associate the probabilistic method with Paul Erdos, Shannon’s use of a randomly selected code, was I believe, just ahead of Erdos. Of course, while random codes can correct errors at rates near the channel capacity, they are hard to encode and to decode. It is easy to get rid of the encoding problem: as shown later select a random linear code.
Today I want to discuss the Shannon model from a modern point of view and also to relate his model, in my opinion, to one of the major open questions of theory: what is the right complexity measure for algorithms?
Worst Case Model Complexity
I love the worst case complexity model, and I hate the worst case complexity model. I love it because there is nothing better than an algorithm that works in the worst case. By definition, such an algorithm can handle anything that you can “throw” at it. All inputs are fine: clever inputs, silly inputs, or random ones. Worst case is great.
I hate the worst case model because it is too restrictive. Often we cannot find an algorithm that works on all inputs. Yet you may need an algorithm that works on the actual inputs that arise in practice. What do we do in this case?
There are several options, of course. We can give up and use heuristics, but then we cannot prove anything comforting about the behavior of the algorithm. Or we can use average case complexity. In this, of course, the inputs are assumed to come from a random distribution. Leonid Levin has worked on formalizing this model, and there are many interesting results. However, I do not think that it is the right model either.
Inputs may not come from an all powerful adversary, but are usually not randomly selected from some distribution either. There must be some model that is in between worst case and random. There are amortized complexity models, and even other models of complexity. Yet I feel that one of great open question in complexity theory still is: How do we model inputs that better reflect what happens in the “real-world?”
While I wish I could tell you the answer, the best I can do is explain an idea from a paper that works in the area of information theory. So lets look more carefully at what Shannon did. Perhaps the idea that I have that works in information theory can be generalized to other areas of theory.
Shannon’s Model
Recall Shannon’s model. In modern terms, Alice wants to send Bob a message 
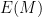



Bob computes via his decoder a message 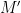

Shannon’s existence proof is that there exists an encoder and a decoder that work, provided the number of bits changed is below a certain rate. Of course, these codes need to add extra bits to overcome the noise that the channel introduces. One key to designing error codes is to balance the number of extra bits against the number of bits the channel can change.
Genius Channels
There is a problem with the Shannon model, in my opinion. He allows the channel to be worst case: it can change any bits that it likes. The decision which bits are changed can be based on any rule, there is no computational limit on the channel’s ability. It hard to believe in many situations that a channel is a “genius”. Such a channel can read all the bits of the message, think for as long as needed, and then decide which bits to corrupt. Noise in many situations is driven by physical effects: sun-spots, electric effects, reflections of signals, and so on. Thus, the idea is to replace the all powerful channel by a more restricted one.
Dumb Channels
In information theory often results are proved for so called memory-less channels: these channels flip a biased coin and if it is heads they change the bit, else they leave it uncorrupted. From the complexity point of view they are very weak, they have no memory and cannot do anything very powerful. Let’s call them “dumb channels.”
Not too surprisingly it is easier to design codes that work for dumb channels, which are usually called binary symmetric channels.
Reasonable Channels
My suggestion is to replace a channel by an adversary that has limited resources. Thus, make the channel somewhere between a dumb channel and a genius channel; somewhere between a channel that is just random and a channel that is all powerful.
Lets do this by assuming that the channel is a random polynomial time adversary. Thus, Alice and Bob need only design an error correcting code that works against a polynomial time adversary.
The key additional assumption, not too surprising, is that we will also assume that Alice and Bob can rely on the existence of a common random coin. Essentially, we are assuming that there is a pseudo-random number generator available to Alice and Bob that passes polynomial time tests.
In this model it is not hard to show the following:
Theorem: Suppose that Alice and Bob have a code that works at a given rate for a dumb channel. Then, there is a code that works at the same rate for any reasonable channel, and further has the same encoding and decoding cost plus at most an additional polynomial time cost.
The additional time depends on the actual pseudo-random number generator that is used: the additional cost can be near linear time.
The method is really simple. Alice operates as follows:
- Creates
using the simple encoder;
- Then she selects a random permutation
and a random pattern
- Alice sends
to Bob.

Than, Bob operates as follows:
- Bob receives
. He computes
.
- Then, he uses the decoder
to retrieve the message as
.
The point is that from the channel’s point of view there is nothing better to do then to just pick random bits to flip. For assume the channel adds the noise 


which is equal to

where 
A Disaster
I made a bad mistake when I got this result, which caused me no small amount of embarrassment. I decided that the result was very cool so I sent an email to about twenty friends with the pdf as an attachment. Today of course I would send them a url to the paper. But then url’s were not yet available so I sent the whole paper.
Sending this email was a bad idea. Really bad. Not everyone wants to have a large pdf file sent to them. But that was only the beginning of my disaster. The email system at the Computer Science department at Princeton went through the campus mail servers and then to the outside. The link from CS to the campus system would die while sending my email, since my message was too large for a certain buffer: twenty times the size of a single pdf file. So it always timed-out after about 50% of the emails were sent.
You can guess what happen next. The “smart” CS code discovered the failure and so it re-sent the whole message again. And again. And again. Each time, a random subset of the emails got through.
People started to send me emails that shouted
“stop already, I do not want your paper, and I certainly do not want ten copies.”
Some people were getting a copy every few minutes, others even more often. I quickly ran to our email experts. They said there was little they could do since the campus system was the problem. I pleaded with them to help me, and finally they got the emails to stop. All seemed well.
However, the next day I came to work, and I was getting shouting emails again. People were getting multiple copies of the paper again. I was dumbfounded. How could this be? I had not sent the message again. I felt like I was in some episode of the Twilight Zone, or in the movie “Groundhog Day.”
I ran down to the email experts. Luckily, they already knew about the problem and were working to fix it. The trouble was that the CS servers had crashed that morning, and the restore was to the last “good” state: the state that was trying to send out my email. So it started the crazy problem up again. Finally, they killed off everything and no more copies of the paper when out. I never did that again.
By the way, when I presented this work at a conference, I got asked for copies of the paper from some of those who shouted back “stop”. Oh well.
Open Problems
I should mention that Moti Yung and Zvi Galil worked on an extension of this idea where the channel was restricted to logspace, which is still unpublished. Since the channel was only able to use logspace, they could give an unconditional proof, using Nisan’s famous result. Also since the original work there have been a number of related and improvements to the idea of limiting channel’s computational power. See this for one example.
The main open problem is can these methods be used beyond information theory? For example, suppose that we have an algorithm that needs an error correcting code. Instead of a complex code suppose we use the codes that only work against a polynomial time adversary. What happens to the algorithm’s correctness? It will not work in worst case, but will it work against a “reasonable” adversary? I do not know.
More generally, can we extend the ideas here to other situations? Can we build a theory like the one developed here for channels for general algorithms?


Dear Prof. Lipton,
Yes, I know the lovely paper of yours that you have described; it needs to be known more widely. There are some additional attempts to meld average- and worst-case — please see this work of Mitzenmacher and Vadhan.
Thanks for pointing this out. With the time pressure of blogging cannot always get all the references I should in.
What is the right complexity measure for algorithms?
What a silly question!!!
Reminds of “What’s the difference between a duck?”
At least for this one there is a right answer (“both legs are identical, mostly the left one”)
Did it not occur to you that the “right complexity measure” depends on what you want to DO with the measured value?
As usual true mathematicians fail to see the point.
I guess I do not agree that it is a silly question. By the way thanks for saying I am a “true mathematician.”
Excuse me to keep laughing as you confirm that “true mathematicians fail to see the point”.
I am not denying that complexity measures for algorithms are of interest (I am a retired software engineer) what I find objectionnable is that stating the question as you did implies that there is a one and only (or best) complexity measure.
How do you know that?
Okay we are in perfect agreement. I never said that there is only one way to measure algorithms. What I was trying to get at is the fact, that you would know better than I, that in real life its hard to imagine that the “system” is trying to deliberately to create “bad” inputs. However, assuming that the inputs are just random is too weak. Murphy’s Law kind of behavior in real life means that being a bit careful about inputs to algorithms is definitely a good thing.
So there must be some way, I think, to not be completely general about behavior and be forced to use the worst case model, but still be careful and use another model. That is what I was trying to get at.
Hi Richard. I was reminded while reading this that Michael Luby and I used this trick in our work on Verification Codes to extend the analysis for the q-ary symmetric channel to the reasonable channel (bounded #of adversary introduced errors) case. (The paper is available at my home page if anyone cares.) We came up with it ourselves but then I think Yan Ding pointed out to me your original paper. Anyhow I remember one reviewer saying that we should take that whole section out and that “everybody knew” you could switch from the random setting to this setting. I think I responded that it was fine if everyone knew it but since your paper actually had the appropriate theorem with the proof we wanted we would go ahead and cite it and make it clear anyway.
Maybe this sort of thing was common folklore knowledge in the coding community but I at least have never seen it mentioned in previous work.
Thanks for the your comment.
When I first got the idea one reason I gotten into the email disaster was that I thought changing worst case to average (roughly) was pretty cool. I was even invited to talk at a pure information theory workshop on the result. But I do not think they really got what I was talking about. So the “everyone knew” may be true or not. It always seemed strange to me that the idea did not seem to change their world in as fundamental way as I thought it might.
Smoothed analysis seems like a very nice hybrid between worst-case and average-case. Granted, it works best on numerical problems, but that can be dealt with.
Hi Dick, great post as usual.
The story I heard (I never read the original papers) was that Shannon’s paper dealt with a channel that makes random errors, and it was Hamming that, independently, introduced error-correcting codes which can correct worst-case errors.
The complexity-theoretic analog of what you describe would be an algorithm that works well on any efficiently samplable distribution of inputs. A result of Impagliazzo and Levin shows, more or less, that if you have a decision problem L and a particular samplable distribution D such that (L,D) is complete in Levin’s sense, then if you have an efficient algorithm that solves L well on inputs sampled from D you also get, for every other samplable distribution D’, an algorithm that solves L well on inputs sampled from D’. By Levin’s enumeration trick I believe you can also switch quantifiers and say that you actually have a single algorithm that works for every samplable distribution.
This is pretty much the complexity-theoretic analog of your coding construction: if you are good for a particular distribution of random inputs, then you are good for any “reasonable” distribution.
Unfortunately these results are all exponential in the length of the algorithms and samplers and so are completely ineffective.
Thanks for posting this. Very educational, and there is certainly some irony in email channel being smart/dumb enough to work against you 🙂
The idea seems also to have connections with game theory and potentially bounded rationality.
It reminded me the paper on “Adversarial Classification” by Dalvi et al. in KDD 2004. In this case the spammer is trying to send a message, and the channel (spam filter) is trying to prevent the message from being delivered. In this case, you may assume that the channel is trying to be a genius and the sender (spammer) is either a (1) genius, or (2) dumb, or (3) reasonable. In case (1), you have the classic case of game theory. In case (2), you have the classic case of machine learning. In case (3), you have the case of game theory with bounded rationality.
I read this post some time ago, and discussed it with Dick at STOC. At the time, Venkat Guruswami and I had been working on a project related to the post topic (codes for “additive” errors). Here are the slides of a recent talk I gave covering the Dick’s original paper as well as our more recent work.
http://www.cse.psu.edu/~asmith/talks/ICITS-crypto-coding-Dec-6-2009.pdf
There’s an interesting coda here: as Michael M. said in his comment above, simple ideas are often absorbed as folklore in one community before being rediscovered elsewhere. I don’t know if that was the case with Dick’s result (certainly the model of shared randomness had been studied extensively in the coding literature, for example in the works on arbitrarily varying channels (AVC)). But a number of the results referred to in my talk slides exist in two versions, one from the IT community and one from CS. Sometimes, the IT result predates the CS one by 10-20 years (note: the reverse ordering also happens, just not for the cases in this talk). Should I have cited the later versions at all? Yes, since they give different proofs of the result. But it did bring to mind this post by Michael:
http://mybiasedcoin.blogspot.com/2009/10/old-references.html
Sometimes, unfortunately, it seems that the selfish optimum is not to read the old papers.
Adam Smith
I also miss smoothed analysis [1] as a quite fruitful (and recently popular) approach to a mixture between average-case and worst-case analysis. For readers who do not know it:
Smoothed analysis allows an (all-powerful) adversary to choose an input, which is then added a limited amount of random “noise”. The complexity is the worst-case among the average-case-complexities for the “noisy” inputs, over all choices of the adversary.
This concept of course does not generalize well to problems where “noise” does not have a practical meaning. However, I think letting the adversary choose a random distribution generateable by a (very) restricted model might be a path to go.
[1] http://www.cs.yale.edu/homes/spielman/simplex/
Sorry for that completely dumb comment.