An Approach to P=NP via Descriptive Complexity
An approach to P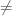

Alfred Horn was a logician who in 1951 discovered the important notion that we now call Horn clauses, in his honor. This class of special clauses has played a foundational role in the area of logic programming—for example, are a key part of the programming language Prolog. I used a picture of one of Horn’s PhD students, Dr. Ali Amir-Moez, who created the Horn-Moez Prize. I was unable to find a picture of Horn—even after a very long search—so I hope that this is okay.
Today I want to talk about an old idea, based on Horn clauses, that may be relevant to the P=NP question.
Years ago David Dobkin, Steven Reiss and I worked on a problem that used Horn Clauses. We proved that Linear Programming (LP) is complete for P with respect to logspace reductions—our proof used, in today’s terminology, an LP relaxation of Horn clauses. At the end of our paper we said:
This theorem is especially interesting since it is not known whether linear programming belongs to P or no? (see [3] for more details on this problem).
The reference “[3]” was to a paper of Dobkin and Reiss that was in preparation; they had found many interesting problems that were equivalent to LP—all in a hope to better understand the problem. I think that they, and others, probably had guessed at the time that LP might be NP-complete, but I am not sure anymore what the conventional wisdom was at that time. Of course it still could be NP-complete, but that would imply that P is equal to NP.
Let’s turn to talking about Horn clauses and the P=NP problem. By the way this whole discussion is joint work with Ken Regan.
Horn Clauses
A Horn clause is a clause with at most one positive literal. Thus,

is a Horn clause, and

is not. A better way, for me at least, to think of Horn clauses is that the general form is:

where all the literals are positive.
The interest to logicians, like Horn, was that this class of clauses had certain model theoretic properties. For a theorist there are two reasons that they are interesting. First, a set of Horn clauses can be checked for satisfiability in polynomial time. The algorithm is just do the obvious: for clauses with just one variable, assign it so that the clause is true, and then keep applying the “implies” rules, until there are no more rules to apply. If you get 

Second, SAT restricted to Horn clauses, HORNSAT, captures P. General SAT is NP; HORNSAT is P. Pretty neat. The intuition is simple: a Horn implication tells you what to do, while an implication like

allows a choice, which is exactly how general clauses encode nondeterminism.
The Descriptive Cook Theorem
In a previous discussion, I talked about descriptive complexity and its possible relationship to separation results. I will first review the notion, and then give a simple example of how it can be used.
Recall, instead of Kolmogorov’s general notion of the complexity of a string, which is based on Turing Machines (TM’s), we will use an intuitively weaker notion based on circuits.
Suppose that 


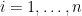

We will use the size of the circuit
The following is a stronger version of Cook’s classic theorem, yet it uses essentially the same proof of his theorem:
Theorem: Let
be a deterministic TM (DTM) that runs in polynomial time
. Let
be an input of length
. Then, there are Horn clauses
so that
- The clauses
- The descriptive complexity of
.
Even though the formulas typically arise from an 




Hypothesis H
If HORNSAT with low descriptive complexity can be solved by a low complexity witness, then 
Suppose that
. If they are satisfiable, then there is a valid assignment for the clauses with description complexity at most polynomial in the description complexity of the clauses.
Main Result
The main result is this:
Theorem: Suppose that Hypothesis H is true. Then,
.
Assume that Hypothesis H is true, and also that 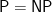


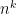



Now let 




- The clauses
are satisfiable if and only if
- The descriptive complexity of
.
This follows by the Descriptive Cook Theorem. Now consider the ATM
- Construct a description
of size
for
- Guess a description
of size
for an assignment
to the up-to-
- Branch over every Horn clause
in
Thus 
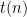
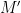


for some constant 


Relaxing a Little
If we could use just 


an exponential upper bound, if used at logarithmic scaling, can help to give a polynomial lower bound.
As things stand, the Descriptive Cook Theorem actually gives 


Open Problems
The key insight here is that an upper bound, Hypothesis H, can be used to prove that P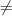


Isn’t the descriptive complexity of a valid assignment (if there exists one) of Horn clause set C with descriptive complexity K(C) is just K(C) plus the constant length of the source code of a HornSAT solver?
Martin, this result is using circuit complexity (not Kolmogorov complexity). See this post for an introduction.
Oh! I see…
Actually Martin Schwartz is in good part right, and this is a perfect context to say more about the work “referenced in the previous discussion.” Before doing that, a simple reply is that the circuit is forced by definition to have size at least log(n) (where n = |x|), because it has log(n) input gates and wires from them. Whereas, standard Kolmogorov complexity can be arbitrarily low. This looks like a limitation of our setup, but since we’re focusing at a log level of scaling, it makes things come out “clean”. We also have in mind a way to control the scaling by iterating this kind of description finitely often.
Now for the longer answer, relating to more-standard Kolmogorov-complexity notions. Eric Allender, Harry Buhrman, Michal Koucký, Dieter van Melkebeek, and Detlef Ronneburger, in their paper “Power from Random Strings”, gave a fairly close characterization of the circuit notion above via a twist on Leonid Levin’s formulation of a “mildly” resource-bounded version of Kolmogorov complexity. Here are the relevant definitions and theorem. Fix a natural universal Turing machine U.
() “Levin’s Kt”: Kt(x) = min{|d| + log(t) : U(d) = x within t steps}.
() “KT Twist”: KT(x) = min{|d| + T : for each bit index i, U^d(i) = x_i within T steps}.
() “Circuit KC”: K_c(x) = min{size(C) : C -> x, i.e. for each bit index i, C(i) = x_i}.
In the latter, the description d is provided as an oracle rather than an input. This is to allow running times as low as logarithmic for cases where a given bit x_i depends on only a few bits of d (whose locations are known in advance or result from a quick decision tree). The paper also stipulates that U must recognize whether the index i is one-past the range, and writes SIZE(x) in place of K_c(x).
Theorem [simplified “Theorem 11” from their paper]: For some c > 0 (related to U) and all x,
(a) K_c(x) <= c.KT(x)^4 + (c.log|x|)KT(x)^2;
(b) KT(x) <= c.K_c(x)^2(log K_c(x) + loglog|x|).
The log factors are "technical grunge", but the simple import is that the circuit-size measure and the Kolmogorov-style measure are polynomially related—and stay polynomially related all the way down to O(log n) scaling. The actual theorem throws conditional complexity, oracle languages, and oracle circuit gates into the mix—and it currently looks like the best formulation of Hypothesis H’ alluded to above will go the same route. This is the sense in which Martin is right, i.e. equivalent.
Backing up to my first answer, our choice of definition seems to involve less “technical grunge”. At least so far…
Backing up further, a key idea of all these definitions is that they embody a search condition: you can try all d or C of a certain size, and see if any one gives x. Levin built this idea into a “universal search algorithm”, along the same(?) general line that led him to his version of Cook’s Theorem (collectively “Cook-Levin Theorem”), for which I refer to the “Kt” section (7.4 in the first ed.) of the Li-Vitanyi book. Hence although basing on circuits C, rather than universal Turing machines U, seems like a “non-uniform” criterion, one gets uniform consequences—and equivalences like the theorem by Allender et al. There are other similar formulations, including the “Speed Prior” of Juergen Schmidhuber.
Still further, the circuit C operates simply and quickly in relation to its size |C|, so call it a “simple algorithm for producing x (bitwise)”. A general Kolmogorov description d might take exp(|d|) or double-exp(|d|) long (etc.) to unpack, and fail to be polynomial even in |x|. A typical example is
x = “the binary string of length n on which algorithm A has the worst running time”.
This is a short description d, but seems to require running thru all 2^n strings of length n to “unpack”. A circuit C for bits x_i would hence seem to require exponential size, complexity which the description d “hides”. A string like x which has a short description, but for which all short descriptions take really long to unpack, is called computationally deep. Murray Gell-Mann advanced this concept in his book The Quark and the Jaguar, in terms of x having a low-entropy origin but going through a long interstellar and biological evolution. It was formalized by Charlie Bennett, and has been related to the complexity of satisfying assignments (and of finding them) in several recent papers, notably this one by Luis Antunes, Lance Fortnow, and van Melkebeek again.
Which all goes to say, the individual concepts in this post are not new, but they have generated interesting recent results, which gives us all the more reason to expect that new ways of combining them will be fruitful. And on a public blog, readers are open to try such “DNA combination”!
Two prose glitches: “latter” became “middle” after I included the “K_c” notation, and I meant to connect my first sentence in the part beginning “Still further” by givinge a less-formal, more-intuitive definition of “x is computationally deep”:
“x has a short description, but no simple algorithm.”
Hypothesis H has another complexity-theoretic consequence that many
consider unlikely: it implies EXP = \Sigma_2^P (and thus that the
polynomial-time hierarchy collapses).
Here is why. Let SUCCINT-HORN-SAT be the following problem: given the
circuit description of a Horn 3-CNF formula, is it satisfiable? By
the strong version of Cook’s theorem for exponential-time machines,
SUCCINT-HORN-SAT is EXP-complete (for a machine M running in time t(n)
on an input x of length n, the descriptive complexity of the Horn
3-CNF formula is O(n + log t), which is polynomial when t(n) is
exponential). Now suppose that H is true. Then SUCCINT-HORN-SAT is in
\Sigma_2^P: guess the description of the satisfying assignment, and
check that it satisfies every clause of the Horn 3-CNF formula. Thus H
implies EXP = \Sigma_2^P.
Incidentally, EXP = \Sigma_2^P implies P \not= NP because P = NP
implies P = \Sigma_2^P and we know that P \not= EXP by the
time-hierarchy theorem.
Correct, very nice point! Expressed in the post’s terms, you’re using the optimal “ ” description of the Horn clauses, but after first scaling up with 2^n in place of “n”.
” description of the Horn clauses, but after first scaling up with 2^n in place of “n”.
The question now becomes whether similarly convincing “collapse” evidence can be given against the 2^{o(d)} bound of the hypothesis H’ which we were moving to. It’s related to the question of whether languages in E (= 2^{O(n)} exponential time) have 2^{o(n)}-size circuits, but doesn’t seem to be subsumed by it. (For references on this question, see Impagliazzo-Wigderson 1997 and Klivans-van Melkebeek 1998.) The closest content I’ve found is another Antunes-Fortnow paper (2005), whose main result is conditioned on E not having 2^{o(n)}-size circuits generalized to allow oracle gates for languages in \Sigma_2^P.
Scaling up removes the need to talk about descriptions conditioned on the input x via oracle gates, so for the succinct Horn clauses, Hypothesis H’ would simply assert that whenever they are satisfiable, there are circuits C_x of size 2^{o(|x|)} that describe some satisfying assignment y. Note that y may fill 2^{kn} variables but C_x needs only kn input gates. If the C_x were somehow “the same” with x treated as a black-box, then this would imply E has 2^{o(n)}-size circuits. But it wouldn’t obviously be equivalent to it—indeed, E having 2^{o(n)}-sized circuits is not known to imply P != NP. (?–if it has poly-sized circuits yes, since then EXP = MA so P != MA which entails P != NP). Hypothesis H’ would put E into 2^{o(n)} time for certain \Sigma_2 alternating machines, but is there any independent reason to disbelieve this, or relevant result we may be missing? Anyway, there is certainly room for further exploration here.
Ah, LaTeX math does work in comments the same way as in posts. The syntax I used for is
is
(dollar-sign)latex (space)(open curly brace)(k\log n)(close curly brace)(ampersand)amp;fg=000000(dollar-sign)
Here my parens are not literal—delete them. Any LaTeX math can go in place of “k\log n” here, e.g. 2^{\epsilon n} becomes .
.
Good points, I think I will definitely subscribe!🙂. I’ll go and read some more!
What is the reason to believe that Hyp H is true? Could it be that a simple diagonalization argument is sufficient to show that it is false?
It is unlikely to be easy to disprove. Open problems would imply H.
What would the consequences be if H were false? Wouldn’t this also imply P!=NP, since the descriptive complexity of the solution to the Horn clause would be exponential, for arbitrarily large Horn clauses?
I meant super-polynomial when I said “exponential”. Also note that if the the statement that H is false implies P!=NP, then because H implies P!=NP, we can conclude that P!=NP.
For those interested in P vs NP, Tarnlund uses logic programming methods
and Horn clauses to give a proof of P is not equal to NP here
http://arxiv.org/abs/0810.5056
What is the time/space complexity of Horn clauses in Presburger arithmetic is the first-order theory of the natural numbers containing addition but no multiplication. It is therefore not as powerful as Peano…
Sorry, I slipped while cut&pasting when my son asked for juice.
However, it is interesting because unlike the case of Peano arithmetic, there exists an algorithm that can decide if any given statement in Presburger arithmetic is true (Presburger 1929). No such algorithm exists for general arithmetic as a consequence of Robinson and Tarski’s negative answer to the decision problem. Presburger (1929) also proved that his arithmetic is consistent (does not contain contradictions) and complete (every statement can either be proven or disproven), which is false for Peano arithmetic as a consequence of Gödel’s incompleteness theorem.
Fischer and Rabin (1974) proved that every algorithm which decides the truth of Presburger statements has a running time of at least 2^(2^(cn)) for some constant c, where n is the length of the Presburger statement. Therefore, the problem is one of the few currently known that provably requires more than polynomial run time.
Fischer, M. J. and Rabin, M. O. “Super-Exponential Complexity of Presburger Arithmetic.” Complexity of Computation. Proceedings of a Symposium in Applied Mathematics of the American Mathematical Society and the Society for Industrial and Applied Mathematics. Held in New York, April 18-19, 1973 (Ed. R. M. Karp). Providence, RI: Amer. Math. Soc., pp. 27-41, 1974.
Presburger, M. “Ueber die Vollstaendigkeit eines gewissen Systems der Arithmetik ganzer Zahlen, in welchem die Addition als einzige Operation hervortritt.” In Comptes Rendus du I congrés de Mathématiciens des Pays Slaves. Warsaw, Poland: pp. 92-101, 1929.
Wolfram, S. A New Kind of Science. Champaign, IL: Wolfram Media, pp. 1143 and 1152, 2002.
Hello.
What if, in a general theory of everything kind of way, some singular human conscious had used simple Yes(I should feel guilty) or No(I do not feel guilty) answers to answer every moral question that he could remember that had ever occurred in his life. In this way he could have become completely pure. He would have truly asked himself all the questions that could be asked of him. He would have emotionally evolved back to when he was a child.
What if he then assigned an ‘It doesn’t matter as life is only made to make mistakes’ label on every decision that he had analysed.
This would not make him God or the devil, but just very still and very exhausted. Anybody can do this but just for the purpose of this experiment lets say I have done this. Which I have.
There are no fears in me and if I died today I could deal with that because who can know me better than myself? Neither God or the Devil. I am consciously judging myself on ‘their’ level.
To make this work, despite my many faults, take ME as the ONLY universal constant. In this sense I have killed God and the Devil external to myself.The only place that they could exist is if I chose to believe they are internal.
This is obviously more a matter for a shrink more than a mathematician, but that would only be the case depending on what you believed the base operating system of the universe to be. Math / Physics / morals or some other concept.
As long I agreed to do NOTHING, to never move or think a thought, humanity would have something to peg all understanding on. Each person could send a moral choice and I would simply send back only one philosophy. ‘ LIFE IS ONLY FOR MAKING MISTAKES’.
People, for the purpose of this experiment could disbelief their belief system knowing they could go back to it at any time. It would give them an opportunity to unburden themselves to someone pure. A new Pandora’s box. Once everyone had finished I would simply format my drive and always leave adequate space for each individual to send any more thoughts that they thought were impure. People would then eventually end up with clear minds and have to be judged only on their physical efforts. Either good or bad. It would get rid of a lot of maybes which would speed lives along..
If we then assume that there are a finite(or at some point in the future, given a lot of hard work, there will be a finite amount) amount of topics that can be conceived of then we can realise that there will come to a time when we, as a people, will NOT have to work again.
Once we reach that point we will only have the option of doing the things we love or doing the things we hate as society will be completely catered for in every possible scenario. People will find their true path in life which will make them infinitely more happy, forever.
In this system there is no point in accounting for time in any context.
If we consider this to be The Grand Unified Theory then we can set the parameters as we please.
This will be our common goals for humanity. As before everyone would have their say. This could be a computer database that was completely updated in any given moment when a unique individual thought of a new idea / direction that may or may not have been thought before.
All that would be required is that every person on the planet have a mobile phone or access to the web and a self organising weighting algorithm biased on an initial set of parameters that someone has set to push the operation in a random direction.
As I’m speaking first I say we concentrate on GRAINE.
Genetics – Robotics – Artificial Intelligence – Nanotechnology and Zero Point Energy.
I have chosen these as I think the subjects will cross breed information(word of mouth first) at the present day optimum rate to get us to our finishing point, complete and finished mastery of all possible information.
Surely mastery of information in this way will lead us to the bottom of a fractal??? What if one end of the universes fractal was me??? What could we start to build with that concept???
As parameters, we can assume that we live only in 3 dimensions. We can place this box around The Milky Way galaxy as this gives us plenty of scope for all kinds of discoveries.
In this new system we can make time obsolete as it only making us contemplate our things that cannot be solved because up to now, no one has been willing to stand around for long enough. It has been holding us back.
All watches should be banned so that we find a natural rhythm with each other, those in our immediate area and then further afield.
An old clock watch in this system is should only be used when you think of an event that you need to go to. It is a compass, a modern day direction of thought.
A digital clock can be adapted to let you know where you are in relation to this new milky way boxed system.(x,y,z).
With these two types of clocks used in combination we can safely start taking small steps around the box by using the digital to see exactly where you are and then using the old watch to direct you as your thoughts come to you.
We can even build as many assign atomic clocks as are needed to individually track stars. Each and every star in the Milky Way galaxy.
I supposed a good idea would be to assume that I was inside the centre of the super-massive black hole at the centre of the galaxy. That would stop us from being so Earth centric.
We could even go as far as to say that we are each an individual star and that we project all our energies onto the super-massive black hole at the centre of the galaxy.
You can assume that I have stabilized the black hole into a non rotating perfect cube. 6 outputs /f aces in which we all see ‘the universe and earth, friends’ etc. This acts like a block hole mirror finish. Once you look it is very hard to look away from.
The 6 face cube should make the maths easier to run as you could construct the inner of the black hole with solid beams of condensed light(1 unit long) arranged into right angled triangles with set squares in for strength.
Some people would naturally say that if the universe is essentially unknowable as the more things we ‘discover’ the more things there are to combine with and therefore talk about. This is extremely fractal in both directions. There can be no true answers because there is no grounding point. Nothing for the people who are interested, to start building there own personal concepts, theories and designs on.
Is it possible that with just one man becoming conscious of a highly improbable possibility that all of universes fractals might collapse into one wave function that would answer all of humanities questions in a day? Could this be possible?
Answers to why we are here? What the point of life really is et al?
Is it possible that the insignificant possibility could become an escalating one that would at some point reach 100%???
Could it be at that point that the math would figure itself out so naturally that we would barely need to think about it. We would instantly understand Quantum theory and all.
Can anybody run the numbers on that probability?
“I used a picture of one of Horn’s PhD students, Dr. Ali Amir-Moez, who created the Horn-Moez Prize. I was unable to find a picture of Horn—even after a very long search—so I hope that this is okay.”
Alfred Horn’s picture is now available on this Wikipedia page:
https://en.wikipedia.org/wiki/Alfred_Horn