Puzzling Evidence
Exponential hardness connects broadly to quadratic time

|
|
Cropped from src1, src2 |
Arturs Backurs and Piotr Indyk are student and advisor. The latter, Piotr, is one of the leading algorithms and complexity theorists in the world—what an honor it must be for Arturs to work with him as his advisor.
Today Ken and I want to talk about their paper on edit distance and an aspect that we find puzzling.
The paper in question is, “Edit Distance Cannot Be Computed in Strongly Subquadratic Time (unless SETH is false).” It is in this coming STOC 2015.
What we find puzzling is that the beautiful connection it makes between two old problems operates between two different levels of scaling, “

I, Dick, have thought long and hard, over many years, about both the edit distance problem and about algorithms for satisfiability. I always felt that both algorithms should have much better than the “obvious” algorithms. However, I was much more positive about the ability for us to make a breakthrough on computing the edit distance, then to do the same for satisfiability.
The way of linking the two problems is to me quite puzzling. Quoting my favorite band, the Talking Heads:
… Now don’t you wanna get right with me?
(puzzling evidence)
I hope you get ev’rything you need
(puzzling evidence)Puzzling evidence
Puzzling evidence
Puzzling evidence …
The Problems
The edit distance between two strings is defined as the minimum number of insertions, deletions, or substitutions of symbols needed to transform one string into another. Thus CAT requires three substitutions to become ATE, but it can also be done by one insertion and one deletion: pop the C to make AT and then append E to make ATE. Thus the edit distance between these two words is 2. The problem of computing the edit distance occurs in so many fields of science that it is hard to figure out who invented what first. The case of strings of length 

Chak-Kuen Wong and Ashok Chandra proved this is optimal in the restricted model where one can only compare characters to each other. There are algorithms that beat quadratic by logarithmic factors—they essentially treat blocks of characters as one. But it remain open after much research whether there is an algorithm that runs in time of order 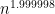
The 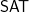
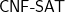
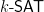

The Connection
Backurs and Indyk prove that if there exists 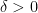
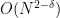



The basic idea is how 



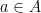

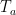


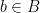
![\displaystyle \phi \in \mathsf{SAT} \iff (\exists a,b)[|S_a \cup S_b| = m] \iff (\exists a,b)[T_a \cap T_b = \emptyset].](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cphi+%5Cin+%5Cmathsf%7BSAT%7D+%5Ciff+%28%5Cexists+a%2Cb%29%5B%7CS_a+%5Ccup+S_b%7C+%3D+m%5D+%5Ciff+%28%5Cexists+a%2Cb%29%5BT_a+%5Ccap+T_b+%3D+%5Cemptyset%5D.+&bg=ffffff&fg=000000&s=0&c=20201002)
Now let us identify 



Orthogonal Vectors Problem (
): Given two sets
of
-many length-
binary vectors, are there
and
such that
?
It is obvious to solve 
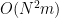


for
What’s puzzling is that the evidence against doing better than quadratic comes when 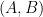
Backurs and Indyk itemize several problems to which this connection was extended since 2010, but we agree that Edit Distance (

The Reductions
The results here and before all use an unusual type of reduction. Ken and I think it would be useful to formalize this reduction, and try to understand its properties. It is not totally correct to call it simply a quasi-linear time reduction because multiple parameters are involved—we can call them
In the above case with 
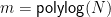


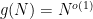
When talking just about the problems 



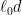

If we assume 
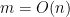




Parameterized complexity defines reductions with two parameters, but the simplest ones are not exactly suitable. Finally, we wonder whether it would help to stipulate any of the specific structure that comes from
Power and Puzzlement
The remarks just above about the reduction time in “

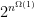
-
SH:
-
ETH: All algorithms for
.
-
SETH: All algorithms for
.
The latter two come in slightly different versions bringing 

Stearns and Hunt emphasized the effect of reductions on SH and the power index in general. The same can be done for ETH. But we remain equally puzzled about the issue of the size of the problems used in the reductions. We start with a SAT problem that uses
The point is that our intuition about the edit distance problem is all on problems that have modest size
Open Problems
So what is the complexity of computing the edit distance? Can we really not do better than the obvious algorithms? This seems hard, no puzzling, to us; but it may indeed be the case.
The 3SUM problem, which we recently covered, is attacked by some of these papers but has not of yet been brought within the scope of the reductions from 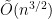

Trackbacks
- Backurs, Indyk connect strong exponential time hypothesis to edit distance; other CS time/ space hiearchy/ continuum news | Turing Machine
- Alberto Apostolico, 1948–2015 | Gödel's Lost Letter and P=NP
- Open Problems That Might Be Easy | Gödel's Lost Letter and P=NP
- Blasts From the Past | Gödel's Lost Letter and P=NP
- The World Turned Upside Down | Gödel's Lost Letter and P=NP
- How Hard, Really, is SAT? | Gödel's Lost Letter and P=NP
- TOC In The Future | Gödel's Lost Letter and P=NP
- Lost in Complexity | Gödel's Lost Letter and P=NP
- Network Coding Yields Lower Bounds | Gödel's Lost Letter and P=NP
- Code It Up | Gödel's Lost Letter and P=NP
- Quantum Supremacy At Last? | Gödel's Lost Letter and P=NP
- Taking a Problem Down a Peg | Gödel's Lost Letter and P=NP
- Database and Theory | Gödel's Lost Letter and P=NP
- P vs NP Proof Claims | Gödel's Lost Letter and P=NP


On thing that the simplicity of many of these new reductions points out is that we have generally been somewhat blinded in thinking about SAT algorithms: We think nothing of using polynomial space when attacking polynomial-time problems like edit-distance or 3SUM but don’t tend to try to exploit exponential space to try to find faster exponential-time problems.
Hi Dick, a few points:
(1) We (Piotr, Arturs, Amir and I) are organizing a tutorial on reductions from popular conjectures (i.e. hardness for easy problems) at this coming FCRC. See here: http://theory.stanford.edu/~virgi/stoctutorial.html
(2) Arturs, Amir and I have an earlier independent result on hardness of Longest Common Subsequence etc. for constant size alphabets. See here: http://arxiv.org/abs/1501.07053
(3) I think that 3SUM and OVP are very different problems, so that there may be no reduction from one to the other. We (Amir, Huacheng Yu and I in this coming STOC’15) have however found a natural problem that is harder than 3SUM, OVP and APSP. It’s called Matching Triangles: you are given a graph on n nodes, where each node has a color, you are given an integer k and you want to know if there is a triple of colors (a,b,c) such that there are at least k triangles whose vertices are colored (a,b,c). It turns out that if Matching Triangles can be solved in truly subcubic (e.g. n^{2.9999}) time, for any k=\omega(1), then APSP has a truly subcubic time algorithm, 3SUM has a truly subquadratic time algorithm and OVP has a truly subquadratic time algorithm, so I’d believe hardness under Matching Triangles more than merely from SETH/OVP.
(4) There are some other very surprising (to me) consequences of believing SETH. For instance, it turns out that if you want to maintain the number of strongly connected components of a directed graph while supporting edge insertions and deletions, then (under SETH) essentially the best you can do is recompute the SCCs from scratch after each update! This even holds if you only want to know whether the number is >3…
–virgi
Wonder if this [conditional] “lower” bound based on SETH re-affirms the belief in
NP!=P, or it will have great implications even when SETH is proven false.
Long back in 1991, I attempted a proof of the conjecture, “NC !=P unless #P=FP”,
based on some information theoretic arguments.
While that “proof” was far from acceptance, the NC algorithm result of Lev, Pippenger and Valiant, for regular bipartite graphs, “A fast parallel algorithm for routing in permutation networks. IEEE Trans. on Computers (1981),
had motivated me into working towards the proof of #P=FP.
If someone cares, here is the link to the latest version.
http://arxiv.org/abs/0812.1385v15
Can I get a reminder on SETH? ETH = exponential time hypothesis = (P≠NP). SETH = strong exponential time hypothesis, but what does the ‘strong’ part entail again?
The “strong” is the constant on n in the exponent being 1, not just “some constant times n” as indicated by the Ω in ETH. P != NP is weaker than the power-index hypothesis and does not necessarily imply any kind of exponential lower bound. My own belief, incidentally, is in size being tight for circuits; I’m less venturesome about machines.
being tight for circuits; I’m less venturesome about machines.
Once you had a post on how big Armageddon it would be if P was NP. Well, on the other side, it also would again make the problem interesting if subquadratic algorithm for edit distance exists, am I right? 🙂
The edit distance between two strings L and S, where |L| >= |S|, is at most |L|. For any number n and string W, a DFA can be built which accepts an input IFF its edit distance to W is < n. Such a DFA can be built and run in O(|W|) time.[1]
What's the complexity of a 'binary search' for the edit distance between L and S using this method? The DFA construction complexity grows very fast with respect to n, but we only need log(|L|) DFAs. And the search cut points can be skewed to amortize the growth with respect to n (i.e. first n << |L|/2).
[1] http://dx.doi.org/10.1007%2Fs10032-002-0082-8
💡 ❗ very interesting! but not following, “the DFA construction complexity grows very fast with respect to n,” can you clarify? you just said it takes O(|W|) time regardless of n…? this also reminds me of another recent paper by Wehar relating the L=?P question to complexity of intersection (nonemptiness) of DFAs.
For any *fixed* n, the complexity is O(|W|). See “Remark 5.2.3” of the cited paper for a note on what happens when n is not fixed.
this seems like a very big deal, even exciting to me & somewhat suddenly leads to the possibility of attacking P vs NP via attempting to prove polynomial lower bounds on a very practical & applied problem, namely edit distance. this would be surprising to me if that route succeeded because my own intuition for many years is that a proof would likely or have to come from circuit theory/ extremal set theory somewhat in the vein of proofs by Razborov and Rossman (2009).
note VWs comment above & these results remind me a lot of her/ RWs work (and this is building on the OVP problem RW isolated years ago) which mostly connect O(n^3) algorithms to larger implications where this is O(n^2). however is it true that polynomial lower bounds have not been proven on any problem whatsoever? which is somewhat shocking.
fyi this result is already covered in two other write ups on the web, 40-year-old algorithm proven the best possible / physorg news and Longstanding problem put to rest mit news.
did some searching around and google intelligence picked up this paper as similar/ related with constructions/ implications wrt P vs NP & Logspace. “how hard is it to compute edit distance” by Pighizzini
if anyone would like to discuss/ further muse/ push in these directions plz join me on stackexchange cstheory chat room for ongoing attn.
It seems Edit Distance CAN Be Computed in Strongly Subquadratic Time!!!
https://www.reddit.com/r/compsci/comments/ad21ux/requestreview_for_logspace_vs_p_paper/