Fatal Flaws in Deolalikar’s Proof?
Possible fatal flaws in the finite model part of Deolalikar’s proof

Neil Immerman is one of the world’s experts on Finite Model Theory. He used insights from this area to co-discover the great result that 
Today I had planned not to discuss the proof, but I just received a note from Neil on Vinay Deolalikar “proof” that P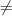
Two Flaws?
Dear Vinay Deolalikar,
Thank you very much for sharing your paper with me. I find your approach and your ideas fascinating, but I am afraid that there is currently a serious hole in your paper as I now describe. For page numbers, I refer to the 102 page, 12 pt. version of your paper.
Your main idea for the lower bound is to show that FO(LFP) is not powerful enough to express SAT, by using Hanf-Gaifman locality to limit the connectivity of the graphs you consider at successive stages of the fixed point computation. As you point out, if a total ordering is given as part of the input structure, then the Gaifman graph has diameter one, so locality is meaningless. Thus you restrict to a successor relation and as you point out, it is still true that FO(LFP) is equal to P in the presence of a successor relation. However, you make two assertions that are not true.
You use the relation 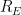

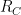
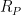
Unfortunately, it is not true that each stage of the fixed point must be order invariant. In particular, consider the definition of ordering from successor, easily defined by a least fixed point and thus the reason that successor suffices to capture P. The ordering is defined by taking the transitive closure of the successor relation. At each stage, the successor distance is doubled, so in 
The other problem is that you restrict your attention to monadic fixed points. You write,
“Remark 7.4. The relation being constructed is monadic, and so it does not introduce new edges into the Gaifman graph at each stage of the LFP computation. When we compute a 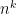
It is not the case that you can freely assume that your fixed points are monadic. If you actually work on the canonical structure, then you require the multiple arity relations that can take us from a tuple to its individual elements and back again. These would again make the diameter of the whole graph bounded. However, in your proof you do not include these relations. Thus, your restriction to only have successor and to restrict to monadic fixed points is fundamental. In this domain—only monadic fixed points and successor—FO(LFP) does not express all of P!
Currently, as I see it, the strongest tool we have in descriptive complexity — rather than the locality theorems — is the Håstad Switching Lemma. Paul Beame and Johan Håstad used this to shown that Mike Sipser’s hierarchy theorem extends all the way to FO[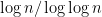
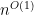
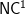
![{AC^1 = FO[\log n]}](https://s0.wp.com/latex.php?latex=%7BAC%5E1+%3D+FO%5B%5Clog+n%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
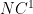
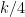
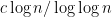

—Neil
Open Problems
Is Neil right? It seems that the most damaging statement of Neil is:
Thus, your restriction to only have successor and to restrict to monadic fixed points is fundamental. In this domain—only monadic fixed points and successor—FO(LFP) does not express all of P!
Most of us have focused on the issues of 2-SAT and XOR-SAT compared to
Trackbacks
- Tweets that mention Fatal Flaws in Deolalikar’s Proof? « Gödel’s Lost Letter and P=NP -- Topsy.com
- Things are not looking good for Deolaikar’s P != NP Proof « Interesting items
- World Wide News Flash
- Recent P != NP excitement & activities « Kempton – ideas Revolutionary
- Deolalikar’s manuscript « Constraints
- Links with little comment (P != NP) « More than a Tweet
- P=NP Yeah or naa « On the learning curve…
- A possible answer to my objection « Gowers's Weblog
- The quest for the lost shtukas » Deolalikar P vs NP paper
- A simple reduction « Constraints
- A simple reduction « Constraints
- Tweets that mention Fatal Flaws in Deolalikar’s Proof? « Gödel’s Lost Letter and P=NP -- Topsy.com
- אז מה זה עניין P=NP, בעצם? « לא מדויק
- Millenium-Problem gelöst? N != NP
- The P≠NP Proof Is One Week Old « Gödel’s Lost Letter and P=NP
- Height » Blog Archive » Индиец попробовал на вкус задачу тысячелетия
- Proofs, Proofs, Who Needs Proofs? « Gödel’s Lost Letter and P=NP
- Top Posts — WordPress.com
- P נגד NP ומדליות פילד. שתי הערות לסדר היום | ניימן 3.0
- Summer « A kind of library
- Michael Trick’s Operations Research Blog : P versus NP and the Research Process
- Method for Secure Obfuscation of Algorithms
- Wine, Physics, and Song » Blog Archive » Consensus on Deolalikar’s P vs. NP proof-attempt (via Scott Aaronson)
- Индиец попробовал на вкус задачу тысячелетия | ScienceEdge.net
- More Interview With Kurt Gödel « Gödel’s Lost Letter and P=NP
- Cornell CS at 50 | Gödel's Lost Letter and P=NP
- Prove This Math Equation to Hack The Entire Digital world - ShoutMeLoud24
- Prove This Math Equation to Hack The Entire Digital world – TIPSBD.BIZ
- Prove This Math Equation to Hack The Entire Digital world - PayLoaded Blog
- Prove This Math Equation to Hack The Entire Digital world – HACKERS ONLY
- Solve This Math Equation To Hack The Entire Digital world
- Prove This Math Equation To Hack The “Entire Digital World”
- Hack the universe by solving this problem. | Maxter Bits


Here’s my 2 cents (again, first post, sorry!):
I’ve previously worked for HP Bangalore as a software engineer. HP kind of had 3 divisions in Bangalore: Labs, Software and Consulting/ Outsourcing.
The division I worked for, Software had quite an emphasis on innovation. We had the option of research disclosures, or patents. Some of the walls in our building were covered with framed certificates of innovations made by local employees. I found the environment to be tremendously empowering for innovation, especially my boss was really encouraging!
To extend this, I can only imagine what the environment would be like at HP LABS in the US, where Vinay hails from! So it would be for HP Labs Bangalore!
I have graduated with an M.A. in CS at Wayne State before.
But I’ve never felt as empowered to publish anything, even though I think learnt an irreplaceable lot there!
So in fact, I published my first paper, a research disclosure while at HP. And, I was brimming with so much confidence that I published a book AFTER I left HP.
http://amzn.com/1452828687
Even though Vinay’s (and possibly mine) attempts may turn out to be duds, I would encourage you to keep an open mind. Don’t hang us for trying!
The state of affairs is reflected in the fact that, even though there are a ton of brilliant people in US schools, somehow they do not seem to have the confidence or initiative to do great stuff. Maybe its the government funded central research that’s killing innovation. Everything is mired in “String theory” to please the NSF and NIH stuffed suits.
While I was studying in the US, I just thought of my school’s low ranking and that I could possibly never do anything considering my low perch! But I now realize that even people sitting high up in US universities are too strait-jacketed to do anything. No wonder, an outsider, Grigoriy Perelman could develop on Richard Hamilton’s Ricci flow to confidently give his solution. On arXiv.
In the end, I’m a strong believer in the future of corporate innovation.
Go HP!
Milz
I’m not quite sure where you get these strange ideas about research and “initiative”. As far as I can tell, most of the tools and techniques that Deolalikar used in his attempt came from the “strait-jacketed” people in universities. And where in the world did you get the idea that the NIH funds anything with “String theory”? Or that the majority of NSF grants involve “String theory”? Or that even the majority of physics grants involve it?
And if you think that Perelman came from “outside”, you’ve been reading the tabloids too much. You should take the time to actually learn who Perelman is and where he came from.
He’s right. If you need education on the prevalence of string theorists as a political (rather than academic) bloc in universities, ISBN-13: 9780618551057. There’s a narrow line between visionaries and devotees.
Dear SN,
Thanks for your support!
Cheers – Milz
Perhaps you’ve misunderstood the character of a response like this. A leading researcher taking the time to read a paper and identify the weaknesses in it is a mark of great esteem, and is generally very encouraging. Most papers that are this bold are simply ignored as “less than serious attempts” or even “cranks”.
Milind,
The above review is not about/against HP research, Corporate Researchers, or Indians. It is about scientists working together to make sure that Mathematics and Science are heading in the correct direction on a solid foundation.
>>”Even though Vinay’s (and possibly mine) attempts may turn out to be duds, I would encourage you to keep an open mind. Don’t hang us for trying!”
Please do not put yourself in the same boat as Vinay – this discussion is not about rest of mathematical community vs HP researchers.
Also, your comments seem to be out of context, so it makes me wonder if you are just trying to market your book.
Lastly, the complaint about brilliant minds in the US not having confidence / initiative is plain wrong (and so does the funding part). Either you had a unfortunately bad sub sample of peers during your university days, or seem to be generally discontent with the whole US higher education system. Either way, the view is skewed and is not supported by facts.
I would advice you to look at the scientific community as a valuable ally in refining your research work and not as an obstacle to overcome. For an excellent example, follow the history of the “Primes in P” by AKS.
Dear Milz,
I don’t know where you get this idea that all the elite academics are focused on string theory, or that they are too straight jacketed to do great things. Gregory Perlman too was a postdoctoral researcher at top American Universities- NYU, Berkeley and Stony Brook and had developed a very good reputation as a serious scholar. Had he not developed such a reputation, no one would have taken his papers seriously. So please remember, that half knowledge is dangerous. In fact it seems like this whole incident may highlight this fact more than anything else.
Milz,
My understanding, perceptions, and experiences do not agree with your comments even in the slightest manner. Intellectual debate is an essential part of advancing human knowledge in any culture and is not limited to the scientific culture. Although, many-a-times, some people might have had historical distastes with intellectual debate, we need to realize that it can only benefit humanity in the long run especially when intelligence is modulated with the human spirit for collaboration and for understanding people and things. In fact, the lack of it may be contributing to the current ills of modern society.
So many people from academia and industry are devoting their precious time and energy to his paper. Some of them have been supported by bodies such as NSF, which you mention. Effort is what is important and Vinay’s efforts have been rewarded already. I hope that everybody’s effort in this forum and outside are also rewarded by this paper. This is synergy, is it not?
PS: I am with HPL and I feel that this is the spirit that is the foundation of HP. http://www.hpalumni.org/hp_way.htm
Best regards,
Kapali
Dear Kapali,
Thanks for reminding me about the HP alumni network! I forgot about it, but not about HP – its’ employees keep making the news for funny reasons – Carly Fiorina (Sarah Palin), Mark Hurd (Bill Clinton) and now Vinay Deolalikar (as?!) … 😀
Maybe that’s the real HP Way it shouldn’t stop 😉 The chaos was great fun!
Cheers – Milz
Hi Dick
The wiki contains two very similar points raised by Steven Lindell and Albert Atserias (Atserias recently expanded on his earlier comments, and made essentially the same comments that Neil makes in the part you refer to as the ‘fatal flaw’.
It seems therefore that independently, three FMT researchers have isolated the same problem in the LFP portion of the argument, and strengthens the weight of this objection.
Neil’s point about order being needed at intermediate stages of an induction seems to me to be new. I read the comments by Atserias and scrolled thru every use of “order” on the wiki and Lindell’s Critique. The latter touches on this at the end, but perhaps in a different vein—I didn’t get Neil’s point from it.
Is it known exactly what “FO(LFP) in the domain of only monadic fixed points and successor” captures? Anything more than AC^0 or some sub-log(n)/loglog(n) extension of it? The closest paper I’ve found in a brief look is this by Nicole Schweikardt in 2005, but the systems there seem to be richer.
Following up my query, maybe good to place on the wiki an entry listing classes C that are already known to be properly contained in NP?
That Deolalikar assumes that each stage of the induction is order-invariant is a point that I raised on this blog (see my posting of 11 August, 12.07pm).
And while it is clear, as “FO(LFP) in the domain of only monadic fixed points and successor” is to weak to capture P, when you also add the restriction that every stage of the induction is order-invariant, then it is weaker still. It can still express 2-SAT, but not XOR-SAT, as I’ve pointed out, and not even parity.
Anuj, yes indeed, thanks! Here’s the link to what you wrote. I didn’t do a similar search-pass on the comemnts here, just the wiki—which this may help document as it’s (pre-)confirmation of Neil’s point.
期待 Vinay Deolalikar的回复 新的博弈开始
Every time I read about a potential flaw in the paper, it reminds me of Russel Impagliazzo’s comments on the lack of a tradional lemma->lemma-> theorem style structure in the paper. Perhaps that’d unravel some of the issues to the author himself in the first place.
I posted the text of Professor Immerman’s letter to the Wiki. (I also included a pointer on the main page). The URL for this Wiki page is:
http://michaelnielsen.org/polymath1/index.php?title=Immerman%27s_letter
OR
http://bit.ly/aIcWBe
My understanding of finite model theory is minimal, but the following highlighted comment of Neil raised a question (probably silly) in my mind–
“Thus, your restriction to only have successor and to restrict to monadic fixed points is fundamental. In this domain—only monadic fixed points and successor—FO(LFP) does not express all of P! ”
The question is what exactly does this restriction capture? Any ideas.
A quick internet search turns up this paper:
On the expressive power of monadic least fixed point logic (2004)
http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.87.2524
This paper also points to other results.
So if Neil is right (I do not know enough to judge that) then Deolalikar does not cover ALL P algorithms. Is it possible that simply Gaussian elimination does not belong to the class he covers? That would resolve the XOR-SAT issue.
So maybe Deolalikar’s work is not a proof for P!=NP, but maybe it is a proof for something like: No polynomial algorithms of type X will solve random k-SAT if the space of solutions had property A. If X covers more than say resolution type of algorithms then such result would still be really interesting!
Precisely matches my first comment on first thread. After all, asking how it proves that answers to SAT are not encoded starting from $10^{10^{10}}$ digit of $\pi$ was a good sanity check idea.
Neil’s critique does seem to align quite consistently with the consensus that we had just been reaching today, that the problems with the argument are originating from the finite model theory component of the argument and then being indirectly detected also at the random SAT and complexity theory side of things. With reference to the three levels of questions from the previous thread, it seems we can now answer both question #1 and question #2 as a definite “No.”.
The status of question #3 still seems to me, though, to be a more equivocal “Probably not”. Ryan’s examples demonstrating how solution space structure seems to be almost decoupled from worst case complexity is admittedly rather compelling, but there could still _conceivably_ be an elusive “Property A” that is obeyed by solution spaces to easy problems (possibly after a reduction), but is not obeyed by a standard problem suspected to be difficult, such as k-SAT, thus splitting a complexity separation task into the Claim 1 and Claim 2 components discussed previously (provided that reduction issues are dealt with properly). While it is now clear that the type of finite model theory tools being deployed in the Deolalikar paper are not powerful enough by themselves to handle Claim 1, it could still be that there exists a reasonable candidate for Property A along the lines of the “polylog-parameterisable” intuition of Deolalikar for which Claim 1 and Claim 2 could still be conjecturally true for some complexity separation problem (perhaps one weaker than P != NP, but still nontrivial). While Ryan’s examples (and also, to some extent, the natural proofs barrier) are certainly significant obstructions to this occuring (and the whole SAT/XORSAT business would also significantly obstruct any attempt to prove the Claim 2 side of things), perhaps there is still some loophole that may offer a way to salvage the strategy at least of Deolalikar’s argument, if not an actual result?
I think Ryan’s 2-SAT example does not have hard structure of solutions in the sense k-SAT or XOR-SAT do. In the 2-SAT example there is only finite number (as opposed to exponentially large in n) of clusters. And more importantly if I condition on the value of one variable, one whole loop of variables is implied by the 2-SAT formula. One just needs to do this n/k times. On the other hand both k-SAT and XOR-SAT are exponentially hard for such kind of “resolution” algorithms. This may be what is called “conditional independence” in the paper.
My current take is that if the answer on question #3 is positive, then the separation must be X!=NP, where X does not even include Gaussian elimination (this may be not very interesting). But said another way: Class X of algorithms cannot solve random K-SAT, XOR-SAT etc. this would be interesting if X is at least a bit non-trivial.
TC^0?
There are already results of this form in terms of
‘proof complexity’. A SAT algorithm can be thought of
as a proof system for propositional tautologies
(a proof of a tautology is the run of the algorithm
failing to find a falsifying assignment). There
are known exponential size lower bounds for proof systems
strictly stronger than resolution, e.g. for systems
operating with AC^0 circuits, with integer linear
inequalities, with polynomials over finite fields,
with OBDDs, and more. Wiki page for ‘proof complexity’
links to some surveys.
Jan
Since your research is in the statistical physics related part, could you perhaps give an explanation about the number of parameters issue?
Do you know how is his number of parameters defined? Is there some way to define this so that it corresponds to number of clusters (or something in the field). Does this part make sense to you?
I think this would be very important to know. Never in the paper he described precisely what his number of parameters is. Does he refer to something which is known, or did he left the point undefined as I suspect he has?
Please answer this, if you do not have idea what he is talking about than this is significant, if you do than please let us know, as this would clarify a lot of things.
Hello Jan,
You are of course correct that all these proof systems have exponential lower bounds; but as far as I know, not for random k-CNF’s. For random k-CNF’s only resolution (and Res(k) and polynomial calculus, together with some of their weak extensions) have known super-polynomial lower bounds.
So perhaps, as Lenka Zdeborova has noted above, the proof strategy might be somewhat helpful for establishing some random k-CNF’s lower bounds in proof complexity (in proof complexity it is fairly interesting to prove such lower bounds also on proof systems that apparently cannot efficiently simulate Gaussian Elimination; e.g., bounded depth Frege).
-I
To vloodin: I have no idea what he means exactly by the “number of parameters”. Trivially all the solutions can be described by the k-SAT formula itself, that is linear number of parameters in n. But he must mean something else. I do not know what.
The solid non-trivial results about the space of solutions are of the kind cited as theorem 5.1 [ART06] in Deolalikar’s paper. But the same theorem (with different constants) is known for k-XOR-SAT. In statistical physics the non-rigorous analytic predictions go beyond that theorem. But we never speak about the “number of parameters needed to describe the distribution”. It is more all about characterizing some statistical properties of the distribution – distribution of distances, correlations between variables, marginals over clusters, number of clusters, etc. And then we have a number empirical results about algorithms, for instance: “Known polynomial algorithms empirically never find frozen solutions in random k-SAT” (where frozen is defined as having a non-trivial core in the sense defined in Deolalikar’s paper just before he states theorem 5.1 [ART06]). I believe that frozen variables in k-SAT pose some kind of non-trivial algorithmic barrier, and if this “barrier” could be formalized that would be great.
Thanks for the reply. In his new survey of the proof, he promises a proof that exponential number of parameters is needed in the hard phase in his new draft.
Apparently, number of parameters has to do with Gibbs potential representation and Hammersen Clifford theorem
“(Hammersley-Clifford). X is Markov random field with respect to a
neighborhood system NG on the graph G if and only if it is a Gibbs random field with respect to the same neighborhood system. ”
It is good to know that it is something he defines, rather than a standard thing in the field.
According to him, his definition of a number of parameters would separate k-XORSAT from k-SAT. But he neither gave definition, nor explained the link to the clustering or other phenomena. He might do it in his new draft.
Another hint about what is meant by number of parameters is his comment that if particles are interacting with at most m-ary potentials, then number of parameters for n-particle distribution is O(n^m). So, it is something like number of potentials in the expression for thermodynamic distribution.
So, I can try to make sense of this in the following way: suppose we have an n-(spin) particle system, with interaction potential U. Then partition function Z=\sum {x is in n-cube} e^{-U(x)/T} can be computed efficiently if number of “parameters” is low.
Number of parameters of thermodynamic distribution would correspond to number minimal number of computations needed so that partition function (it is a function of T) can be computed using product and sum, starting from terms of the form e^{-V(x)/T}.
Now does this make k-XORSAT a 2^poly-log parametrizable, while k-SAT needs exponential number of such parameters?
The energy of the system is given by
U(x_1,… x_n)= \sum delta (\sum (C_{li}S_i),-k)
where first sum is taken over all clauses and second for each clause measures
weather it is satisfied (cf. 5.1 of old or 6.1 of third draft). Hence, energy of the system is equal to the number of unsatisfied clauses. If total number of clauses is m, then energy is between 0 and m.
In k-XORSAT Kronecker delta can be replaced by XOR sum of corresponding elements. To get the partition function, we need to consider cases when energy is equal to 0,1, 2… m. We are interested in number of satisfied equations. Supposedly, simple (linear) structure of solution space would allow us to compute this number as a linear sum of a few parameters, and this would than give simple expression for partition function.
Computing e^{-U(x)/T} takes polynomial number of parameters, computing \sum {x is in n-cube} e^{-U(x)/T} in k-SAT is #P-complete, and hence we all believe (but do not know how to prove) that exponential number of steps is needed, but counting is #P-complete even in polynomial problems like matching. So I am still confused about the definition of “parameters”.
parameters are not x_1… x_n, so in computing sum e^{-U(x)/T} he more likely counts number of terms – basic potentials;
Complexity of the problem Z(T) is not so relevant – it might be #P complete in general, but he uses it to determine (if I am right) the number of parameters/terms, does not need to solve it. It is the other way around – when he CAN compute Z(T), then number of “parameters” is small.
I don’t understand Immerman’s first objection. He points out that in an LFP computation of ordering from successor, each stage of LFP computation is far from order invariant. However, Deolalikar is not doing that computation but rather is computing an extension to a partial assignment of variables to try to satisfy an instance of 3-SAT, right? Does Deolalikar need to make a claim about the former computation to get what he needs for the latter computation? Can some stages of some LFP computations be order invariant even if others aren’t?
As I understand it, Neil is just pointing out that the stages of an LFP induction need not be order-invariant even if the result of the induction is.
The relevance of this observation is that Deolalikar assumes that the stages *are* order-invariant. So, he only proves (if even that) that LFP inductions of this type are unable to express k-SAT. This does not cover all polynomial-time computations.
TC^0?
Does not Neil’s comment explain why 2-SAT and XORSAT might have ‘complicated’ solution space?
I would like to reiterate what I said a few days ago:
“It is quite clear that there is something very wrong in the model theory part of the paper, which is where all the interesting action has to be happening. After having a very weak (and incorrect) characterization of P, the proof could end in a variety of ways. The author has chosen to reach a contradiction using random k-SAT. And this, apparently, is leaving some people (who are unfamiliar with the work on random CSPs) hailing it as a “new approach.”
Yes, it is great that people have isolated some incorrect claims in the model theory sections and thus have “found the bug.” But the point is this: It was obvious from the beginning that this was the problem. All the “power” is coming from the incredibly weak “characterization” of poly-time algorithms, and random k-SAT is just a guise (that got people excited because… they were bored during summer vacation?)
How could I (and, I’m pretty sure tens of other people) know this without pinpointing a specific bug? Because there is no sensical exportable statement from that section. There is no formally defined property “Q” such that all assignments generated by a P-time procedure satisfy “Q.” If the author had even once tried to write down this property formally, the flaw would have become immediately clear. So I will say again: people are being too kind; the author is either crazy or disrespectful.
That’s not a mean or nasty thing to say. It’s just the opposite. It’s protecting the community and its integrity by requiring some basic rules and courtesies in mathematical discourse.
Give him a break. This is just unnecessary.
His lack of proper definitions is another red flag. He hand waves with “parametrizations”, central to his approach, but the way he counts parameters is never defined, and not a single person among many experts here does not have ANY idea what he exactly means.
So, a perhaps more objective assessment of this piece of text (over 100 pages in 12pt, yet more like 70 pages in 10pt) might be:
(1) Author never defines his key notion, number of parameters needed for a distribution description, that supposedly separates P from NP in his strategy.
(2) He than claims that this undefined number of parameters is exponential in a certain phase of k-SAT, as described by work of various statistical physicists. However, he confuses the phases, which is not surprising, since he nowhere explains how is his fictional undefined number of parameters is linked to the statistical physics conclusions. Namely, he points out that in certain phases there are exponential number of clusters. But never does he explain how that means that number of his parameters is exponential. On a rough reading one is perhaps deceived into thinking that this is OK, but it is not – not the least because he never defined his number of parameters. His confusion of phases is another indicator in the lack of proper rigor (or rather meaning) in his vague claim, which seems plausible only if we don’t go much beneath the superficial surface.
(3) Then he proceeds to prove that this fictional undefined number of parameters is O(2^poly(log(n))) for polynomial algorithms. Since no one understands what he means, people here were at least able to analyze this part of the proof, where he constructs certain graph of limited vertex index. He claims that this means the number of parameters is bounded, but since we do not know how he counts these, one can only take this claim for granted, and analyze the reduction to the graph, because at last there we know what he is talking about (graph with bounded index of vertices).
(4) It turns out that even this reduction to a graph is deeply flawed. It does not capture P. He uses monadic (unary) relations, hand waves about reduction to this case, which turns out not to be possible.
He then proceeds to conclusion. Yet as we see, every step is dubious. It is only the point (4) that had claims that were clear enough to be analyzed, so for this reason, clear flaws have been found there (and it is not a single flaw, but several problems).
On another level, other restricted CSP (as I have pointed out early on), including here many times mentioned k-XORSAT etc. have same phases, but a P algorithm. So, even if he was able to provide some reasonable definition of parameter number (that would be the real contribution from his attempt), either this number cannot be concluded to be exponential from phase properties, or this number cannot be concluded to be c^polylog bounded for all P algorithms. But as it seems now, he did not really prove any of these.
He did not even define his central property- number of parameters.
So, the question is not if this paper has any chance of being fixed. The question is not weather this approach is promising. The question is not weather this paper will be published in a peer review journal. These are all answered by a most emphatic NO, no way, not in a million years.
The real question is why would someone who clearly has enough background to understand relevant material (and hence not a complete quack) do something like this, and how can he save face given this embarrassment. Another question is was he aware that his proof is wrong or incomplete when he e-mailed it out.
My guess is that he did not think a proof strategy is so wrong, but probably was aware that proof was incomplete. Perhaps he thought that details can be fixed, and his vague ideas (here we have more a sketch or a strategy) can be made precise. Perelman also published a draft, though his draft was small (30+ pages) packed with the essential points in it, standard (precise) mathematical formulations, and there were many of the breakthrough ideas there. People analyzed and supplied the details. Perhaps he was hoping something of the kind. But Perelman did work out his details (when people asked him during his US tour, he was able to answer all queries), and here we have serious reasons to think that many details are far from being worked out, and hence we have a lot of troubles due to hand waving as opposed to troubles in understanding due to skipped proofs. Here, precise statements are missing. So a manuscript was sent out to colleagues early. I wonder if the reason/timing has anything to do with ICM 2010 held in his native India this month.
Also, the response of the community was perhaps more than such papers usually get. It is rare that these huge claims are made by mathematicians/cs people with any degree of real competence, so this is perhaps the reason he was treated differently (his background is better than that of most of people who make such claims). But this only underlines one other case, where response of the community was far less kind, though merits were clearly much greater than that of this middle age middle range HP researcher with a couple of average publications.
It is the case of Louis de Branges. This guy was attempting to prove Riemann conjecture his whole life. In the process he developed a whole theory, deep on its own right. He was able to prove the famous Bieberbach conjecture using it, in the 80s. But he had to go to Leningrad to get his proof checked. In the meantime, his life turned to hell as math community didn’t want to take him seriously, his wife left him as a failure, and all sorts of bad things befell on this noble soul. His proof turned out to be correct, and this was reluctantly recognized (Bieberbach conjecture was THE major problem for a big class of complex analysts), but professional jealousy further alienated him from the math community (it didn’t help that he was a bit difficult/uncompromising/unwilling to trade/uncorrupted in dealing with them and not part of the social crowd in the field). So this black sheep of complex analysis continued to work on his own, outcasted by the wonderful mathematics community of the time. This person was a top mathematician, expert of his field, professor at Pen-State (I think), who proved some major theorems and solved major conjectures. Yet when he published his proof of the Riemann conjecture on the web a few years ago, he was completely ignored. There was no Soviet Union at this time, no alternative community to talk to. I am sure that his theory and proof attempt have a lot more merit than this one we are all devoting our energies to, and the problem is no less famous, and the guy has a whole insightful theory constructed for that purpose over a lifetime, yet he was deliberately not helped. Too many hurt vanities stood in the way. I can only say, compared to this, his treatment was far from fair. On the other side, and in comparison, the attention this guy is getting is far from what it is worth. Way off.
Vloodin: I think you are reading your preconceptions into the person’s motives. Be careful! This blog is not about judging personal motives, but only for verifying the manuscript.
Louis de Branges is a distinguished professor of mathematics at Purdue (and not
Penn State as claimed).
Every mathematical proof can be broken down into smaller pieces. Eventually these pieces become small enough to be sent to friends, or if you don’t have friends in that area, conferences and journals. Then they are verified and accepted. Then you have your proof verified completely. Win, success!
just some online advice:
nice people generally use the following “emergency” rule of thumb: the more hostile an otherwise nice person’s comment, the more attention it should be given (because it’s such unusual behavior).
however, because it’s online in a weblog, without your full name, your comment is hostile without a known lifetime of nice behavior to back it up. so it has the unfortunate characteristic of being difficult to distinguish from that of “just another internet jerk”.
why not think of a way to phrase your concerns that doesn’t make you sound like you have a mouth full of sour grapes and are trying to denigrate one person’s reputation in order to prop up the reputation of someone else?
it’s really bizarre and antisocial behavior.
if it concerns you that this proof idea was given more time and energy and friendly lookings-over than that of some other proof idea by some other person for some totally different problem, then maybe you could quietly and privately reflect on that and try to figure out why. perhaps you’ll never know, but it’s possible that one doesn’t have a whole lot to do with the other.
Oh, come on, stop coming down so hard on the poor guy! He did NOT submit the paper to a journal, he just emailed it to a few people, so what’s your problem? Stop your personal insults.
Having said that, working alone is a bit foolish, no matter whether you are a genius. It helps to have a research soul-mate to discuss and iron out things, to battle out your arguments.
And I did not find any acknowledgment in the paper (except for the dedication page at the front). Perhaps this explains the end result. He could have just driven down the road to Stanford or Berkeley and had it checked it by someone there.
I don’t know what is wrong with this paper getting the attention it did. Are you implying that is not worthy of expert’s time to discuss a serious attempt at solving a very important problem? Do you think the mathematical community won’t gain anything from this discussion even if the proof is wrong? Surely many worthy papers haven’t received this same attention, but is it really a bad thing that this paper did?
Well you are of course entitled to your opinions, but fail to see why you want to denigrate Vinay’s nationality and age in your criticism. Wrong proofs have happened to people of all nationalities and ages- history of mathematics is full of these examples.
In regards to DeBranges’ attempt to prove the Riemann Hypothesis, it’s worth noting that what he claimed is actually stronger than RH, and that Conrey and Li proved and published a result that contradicts DeBranges, see MR1792282 (2001h:11114)
You make your view very clear by a lot of arguments. But think about the extremely small possibility of some math-amateur giving the correct proof for some really big problem…Riemann, Goldbach, Collatz, whatever…how easy would it be, to see if such a proof is pure nonsense (probably minutes to hours) but how tremendous would be its impact, if it would be correct, and how equally tremendous would be the loss, if this yet unknown guy does not dare to publish anything, because professional mathematicians tend to be somewhat uncomfortable and unpleasant when dealing with some semi-professionals work? Surely it is the rigour, that makes a proof mathematical, but sometimes ideas are more important, even the ideas someone may takes from a wrong proof to devise a better one on this basis.
“Yet when he published his proof of the Riemann conjecture on the web a few years ago, he was completely ignored.”
This is not correct. He was taken seriously, but did not – in contrast to Perelman – give explanations of specific obscure points in his paper when they were requested. His general approach to technical inquisition was “Go figure”.
Mathematicians do not like this.
As if the community needs protecting! ha! What a wild notion!
It’s comments like these that show that public and anonymous mathematical collaboration cannot work.
The end-quote (”) in the third paragraph of Immerman’s letter is misplaced: it should be at the end of that paragraph, not at the end of the first sentence of the quote. So the sentences starting with “This is a technicality.” are also from Deolalikar’s proof attempt; they are quoted by Immerman, not said by Immerman.
Since the process evolving on this blog may be interesting as a social phenomenon(independently of the mathematical contents), it seems important to track the publicity following from it, as is well done on in the Media section of the wiki. I should therefore like to point you to
http://www.zeit.de/wissen/2010-08/milleniumsproblem-beweis-mathematik
where the process was noted in (the online version of) one of the most respected newspapers of Germany, “Die Zeit”. I propose including the link in the Media section of the wiki.
You say
> Yes, it is great that people have isolated some incorrect claims in the model theory sections and thus have “found the bug.” But the point is this: It was obvious from the beginning that this was the problem.
How is that a point? Of what? It is not hard to check that both the lack of rigorous definitions and the specific model theory flaws were pointed out very early on. It just took long until they got attention or were explained in a way that were understood by everyone.
The fish in my aquarium cannot tell by visual inspection the difference between food and their own excrements, so they put the thing in their mouth and after a fraction of a second they spit it if it is not food. I particularly like to watch them when I referee papers.
This said, I do not agree with the previous post. It seems, as others noted elsewhere, that in addition to the social/web/1M$ context, what attracted some really great minds to study the paper was the putting together of different threads from different domains. Certainly, the style of the manuscript cannot be recommended for a standard publishable math paper, but mathematics is *not* only about theorems and proofs, especially in the creative phase:
“All beginnings are obscure. Inasmuch as the mathematician
operates with his conceptions along strict and formal lines, he, above all, must be reminded from time to time that the origin of things lie in greater depths than those to which his methods enable him to descend. Beyond the knowledge gained from the individual sciences, there remains the task of *comprehending*. In spite of the fact that the views of philosophy sway from one system to another, we cannot dispense with it unless we are to convert knowledge into a meaningless chaos.” (Hermann Weyl).
“previous post” in my post referred to the concerned citizen.
Concerned Citizen: I well know Vinay to be far from crazy and disrespectful. He asked a few for comments and uploaded the manuscript on the net. Unfortunately, too many people got into it too soon.
Although active in theoretical computer science, he is not a mathematician by training but is a PhD in Electrical Engg. So, the manuscript might lack the pure math rigor. If his results and/or arguments are wrong, the constructive criticism given by Terrence and others has a hope of salvaging a useful result. Some others may prefer the safe “see no evil” approach though.
It seems that what remains is Terry Tao’s 3. — can these ideas / strategy be used to advance the field?
More precisely, can we get a nice characterization, (using finite model theory?) that must be true of all languages in P, but false for some in NP? The kind of property suggested in the paper as a candidate would be related to the statistical physics landscape of the solution space, which is intriguing to most complexity theorists: it is a subarea where we do not see (yet?) difficult barriers to further progress.
An unreasonable (but perhaps not totally crazy) goal in such a strategy would be showing separation from NL (or, from L), instead of P. Such a result would be also tremendously impressive. Is there a sensible definition of “number of parameters” or of some property of the solution space where a characterization theorem for what algorithms in L can produce could be proven?
Further, if we are to study the solution space of NP predicates, why not go to PP (unbounded probabilistic polynomial time)? The intuitive “distance” from L to #P is bigger than from P to NP, so “it should be easier”. For example, a logspace Turing machine cannot even write down on its workspace the number of satisfying solutions to 3-SAT. Also, the class PP is directly related to the geometry of the solution space: loosely speaking, #P counts the number of absolute minima.
Dealing with PP has an “aesthetic” advantage: it is well known (since the 70s) that the difficulty of counting solutions does not relate nicely to the difficulty of finding solutions (the number of satisfying assignments to 2-SAT is #P-complete, as is the number of satisfying assignments to 3-SAT. Counting the number of spanning trees of a graph is in P, counting the number of perfect matchings is #P-complete). Admittedly, the number of solutions is the simplest statistics of the solution space.
It may well be that, as Russel pointed out, the big problem is to find a way to relate the “shape” of the solution space to algorithmic difficulty.
Honestly, I doubt that even something like that will come out from this. There are #P-complete problems for which polynomial delay enumeration algorithms exist. Existence of PDE algorithm indicates that the state space is not as hard as one might think…
But the XORSAT problem suggests that we have to be very low in the hierarchy, somewhere where we can’t tell what the rank of a matrix is or invert it. This puts us below DET, right?
I have a naive question, please forgive my simple non-expert view of things:
So maybe there is a mistake in Deolalikar’s characterization of P – but there are certainly other correct characterizations of P. There are P-complete problems, e.g. Horn-SAT. So the question (actually questions):
1. If the “solution spaces” (however defined) of Horn-SAT and SAT are different, is it enough to separate P from NP? (My guess is no – unless the translation from any P algorithm to a Horn-SAT instance preserves the “solution space”, which might be impossible.)
2. Is Deolalikar’s approach similar to the above naive idea (just much more technical) or fundamentally different?
I am convinced that there is a proof here that P != NP. Indeed, browsing at the paper, and reading the various comments published here and elsewhere, is proof enough that verifying the correctness of the proof is exponentially hard. Therefore, NP = EXPTIME and, as a result, NP >> P.
Seriously, the paper is in fact ‘poetic’. But, can someone tell me, where is the meat?
P = FO[LFP] is a beautiful theorem (thanks Neil, et. al.) but if using LFP, you might as well stay with the RAM model. Locality of computation? Reminds me of myself in my first year as a graduate student.
And this ‘statistical mechanics’ business? It is also beautiful, and even more poetic than the ‘proof’ itself. Frozen variables, yummy, especially in summer. It used to be called random graph theory in my days. Or am I missing something?
Russell, you are the greatest.
Which reminds me, I have a great ‘get rich quick scheme’. Goes like this. Write some ‘poetic’ proof that P != NP. No less than 100 pages, please. Ask Steve to write that the proof is ‘relatively serious’. Have the community at large work hard filling the details. Collect the Clay award.
Anyway, it was great being part of the community again, after 15 years. I better get back to work now, or I might get fired..
Cheers,
Mauricio Karchmer
Did not the several rounds of monotone conversation convince you of the depth of the paper!? Alas 🙂
Cannot agree with you more on the LFP front though. Yes, it has all turned out to be very poetic and Zen; peel and peel and then nothing! Tao elsewhere has checked all his three questions to a “no.”
But then who knows; there might still be a twist. D has promised a new version over the weekend …
> And this ‘statistical mechanics’ business? It is also beautiful,
> and even more poetic than the ‘proof’ itself. Frozen variables,
> yummy, especially in summer. It used to be called random graph
> theory in my days. Or am I missing something?
Not directly related to the “proof”, but if you want a challenge try
to beat the survey propagation algorithm they invented.
The “fusion method” sounds poetic to me.
Cynical people might think that the attention given to this proof was not so much because the proof looked promising but rather because it was an opportunity to promote the field, attract graduate students, and increase theory funding.
You’re right, that does sound pretty damn cynical.
I think several of us only read the paper because our colleagues in other areas were asking “but you’re the complexity guy/gal, how can you not have read it?” Some put $200k on it being wrong and went back to vacation. Others tried to understand things, airing their concerns in a public forum. But I think most of us ignored it entirely after reading the first few comments on this blog and the wiki.
Somehow this particular paper spread very rapidly. I wouldn’t “blame” complexity theory for that. If anything, blame Clay Math for putting $1M bounty on the problem.
Do you think the publicity from this will have an impact on complexity theory? If so, what sort of impact?
I find it hard to believe that those who commented on the proof gave no thought whatsoever to the fact that the world is watching. This has become a spectator sport.
Paradoxically, I think a lot of people who are still paying attention are non-specialists (like me). For people who know enough about barriers, it must have been easy to take a cursory glance, convince oneself that the strategy was flawed, and go back to one’s own research.
Yes (to Random).
P.S. But I have to admit I am a little bit harassed by
the Russian media these days (I am sure many
colleagues have similar problems), and it is *extremely*
handy to have this blog around as a pointer.
Dick, the Group et. all — thank you *very* much for
investing effort into this.
Amir:
People are commenting here *precisely* because they know the world is watching them 🙂
Amir:
LOL.
The reason the proof got so much attention was because Stephen Cook was quoted characterizing it as a “serious attempt.” Otherwise it would have just been another entry appended to the P vs NP page.
Clearly, the proof is now dead, and we may all move on.
a “relatively serious attempt”. The adverb changes everything.
Although I see this as a bit cynical, there is a certain truth aspect. In the Wolfram Prize discussion, for instance, Vaughan Pratt intertwined some commentary about funding, and it seemed almost non sequitur to me. Not to flog this too much, but for context, see http://cs.nyu.edu/pipermail/fom/2007-November/012253.html
> This entire episode seems to me a massive perversion of the scientific process.
Pratt: In the grand scheme of things I find “perversion of the scientific process” far less destructive than the wholesale starvation of computer science funding that the US government has been indulging itself in during the past decade or so.
So you can see where some priorities are.
Not intending to hijack the thread, but funding need to be balanced between basic and applied research. Applied research should be funded by corporations, and incorporate the basic results from government funded research. Some CS research is basic, some is applied, but there needs to be more flexibility so that scientists can move freely between domains, carrying their passions and ideas wherever their thoughts lead them.
Tim Gowers has just made a post at
http://gowers.wordpress.com/2010/08/13/could-anything-like-deolalikars-strategy-work/
which I think makes a very strong case that there is a natural proofs-like barrier that prevents the answer to question #3 from being “Yes”. Basically, he considers a _random_ (or more precisely, _pseudorandom_) P problem, basically by getting a monkey to design randomly (or pseudorandomly) a polynomial length logical circuit, and looking at the solution space to that problem. Intuitively, this solution space should look like a random subset of {0,1}^n: a pseudorandom circuit should give a pseudorandom function (after selecting parameters suitably to ensure enough “mixing’). In such a setting, any reasonable “property A” should not be able to distinguish that function from a random function. But if “property A” has any strength at all, it should be constraining the structure of the solution space to the extent that a random solution space should not obey property A. (Certainly this is heavily suggested by terminology such as “polylog parameterisable” by basic counting arguments.) As such, the Claim 1 + Claim 2 strategy cannot work.
To summarise, I think we now have at least four significant obstructions to the Claim 1 + Claim 2 strategy working:
1. Ryan’s examples showing that complexity and solution space structure are decoupled.
2. The point made by Russell (and others) that the Claim 1 + Claim 2 strategy ought to also separate non-uniform complexity classes as well, thus possibly triggering the natural proofs barrier or something similar.
3. The difficulty in getting a argument to distinguish “difficult” solution spaces such as SAT from “easy” solution spaces such as XORSAT;
4. The difficulty in getting an argument to distinguish the solution space of a random polynomial length circuit from the solution space of a random function.
Based on this, I think I’m ready to change my answer on Q3 to “No”.
I wonder if it might be possible to obtain something constructive by going the other way. For example, suppose the conjecture is true that the hard instances of k-SAT are exactly when the clusters are frozen. Then maybe “all” we need to do in order to produce a pseudorandom generator is to build a function whose clusters “appear” frozen. (It’s not clear to me whether k-XORSAT freezes in a similar way to k-SAT.) Or, perhaps, there are limits on how frozen something can appear, so there are limits on what kind of PRNGs can be built.
XORSAT freezes much in the way K-SAT does… No differences!
One minor clarification: Gowers’ pseudorandom circuit is made out of _reversible_ logic gates, and so one cannot distinguish this circuit from random functions simply by looking at the influence of individual bits, etc.
I cannot see the barrier. As far as I can see, Gower’s pseudorandom circuit makes a pseudorandom function from problem instances to {0,1} (or {0,1}^n), while Deolalikar is talking about the distribution of the solution space of one problem instance.
If Gower’s pseudorandom circuit is implemented as a NDTM, why the distribution of acceptance paths should look pseudorandom? Or I just miss the point, sorry if saying something stupid…
Yes, we got a bit confused on this point. But Tim’s argument can be modified to deal with solution spaces of individual instances also; see my second response to Jun Tarui below.
In the midst of such intense academic discussion — here’s a note on the lighter side :). Maybe we should use the football(/soccer) world cup Oracle: Paul the octopus to answer if this proof is ok or not [or any other related binary predicates] :). (in case you havent heard about Paul the octopus, here’s the link http://en.wikipedia.org/wiki/Paul_the_octopus)
Why not use it on P=NP and P!=NP while we’re at it? It wouldn’t give us a proof, but it could at last tell us if the majority is right.
Now that a consensus seems to have formed that this P !NP paper is deeply flawed, and skepticism is even beginning to form as to whether it contains any new credible idea (though opinion might shift around on this), I thought I would put forward my impressions on some general issues suggested by this entire episode.
Imagine two quite different actions.
1. Someone with quite reasonable credentials circulates a well written (not in the technical sense) manuscript suggesting what they regard as “promising new approaches to P !NP”, with many details included.
2. Someone with quite reasonable credentials circulates a well written (not in the technical sense) manuscript claiming that they have proved P !NP, with many details included.
The effect of these two actions are radically different. In the case of 2, a large number of very strong theoretical computer scientists and interested mathematicians are rightly compelled to pretty much drop whatever they are doing and look at this seriously NOW – or, in some cases, be compelled to make public statements as to why they are not dropping whatever they are doing to look at this seriously.
So 2 amounts to forcing one’s ideas to the top of the queue for a very large number of very powerful people who are not going to be able to continue doing the great things they normally do until at least a reasonable consensus forms.
Under 1, eventually some very powerful people will take a look, but when it is convenient for them.
The cost of this is, on balance, considerable enough to be of some concern. I’m not thinking of retribution, or anything negative like that.
But considerable enough so that the question of how this came about, and how to prevent this kind of thing from happening in the future, becomes pretty interesting – both from the theoretical and practical points of view.
From the theoretical point of view, broadly speaking, we have a very satisfactory understanding of what an ultimately rigorous mathematical proof is. Furthermore, ultimately rigorous mathematical proofs have actually been constructed – with the help of computers – for a substantial number of theorems, including rather deep ones. E.g., see http://www.ams.org/notices/200811/tx081101408p.pdf This also has a careful discussion at the end of what major advances are needed in order for the construction of ultimately rigorous mathematical proofs to become attractive for more than a few specialists.
On the practical side, I think that there is a reasonably clear notion of “completely detailed proof”, written in ordinary friendly mathematical language, which definitely falls well short of “ultimately rigorous proof”. I have, from time to time, felt compelled to construct “completely detailed proofs” – and it is rather exhausting. I don’t do this as often as I should – perhaps because I don’t prove something important enough as often as I should or would like. But there is some satisfaction that comes from writing up a completely detailed proof.
Bringing this to the matter at hand, I am under the impression that many people do not have a clear idea of what a completely detailed proof is, and rely on some sort of general intuition – which is required to come up with just about any serious proof in any form – even for proofs for publication. Since the refereeing process generally consists mainly of whether the referee feels that they can “see” a correct proof based on what is written, authors are normally never compelled to get their hands dirty with anything remotely approaching a completely detailed proof. This works well as long as they are in an arena where their intuitions are really good enough.
Of course, (most) really strong researchers know just how dangerous it is to operate this way, particularly with notorious problems. But obviously reasonably strong people may not realize this. In fact, I have seen this kind of thing many times before in and around logic – and there is often a defiance stage.
So it might be valuable to
a. Flesh out both theoretically and practically what a “completely detailed proof” is – still well short of “ultimately rigorous proof” which we know a lot about already.
b. Give examples of “completely detailed proofs”.
c. Instill this in the educational process. E.g., all Ph.D.s in theoretical mathematical areas must have written a substantial “completely detailed proof”.
I would be delighted to hear what people think of these comments.
Harvey,
Thanks for these comments.
Professor Lipton,
When the dust finally settles you should write a CACM article on the whole episode :-).
Would somebody tell what approaches have been used by people who proved significant results in the past:
example cases
1. Andrew Wiles (First Announcement)
2. Andrew Wiles (Correct Proof)
3. Grisha Perelman
I meant approaches to make announcements of significant proof
I don’t know about Wiles, other than he was very careful and organized a graduate course where students were checking parts of his proof (without being aware of that). He made first announcement in a talk, directly to a high level public, being cryptic about it. Yet a flaw was nevertheless found, but he was able to fix it.
Grisha Perelman just posted his results on archive. They were written in normal math (read – he had precise statements) and then people started to check it. There was for instance a seminar at MIT devoted to figuring out the details. He was then invited to a tour to USA, to Stony Brook, MIT, California. He communicated directly to the experts, who were already prepared with detailed questions. Grisha was a top researcher and did never hand wave. Unfortunately, after returning to St. Petesburg, he had a row with local math community and quit mathematics for mushroom collecting, a much more profound activity on many levels, including not having to deal with colleagues. For some reason, he started to despise the system, and as one of the reasons he refused Fields medal he said he did not want to validate the system, which is inherently unfair (interestingly, another math genius, Alex Grothendieck, abandoned mathematics for healthy living in Andorra for the very similar reasons).
The opposite technique, aiming for media hype, has become common. “PRIMES IN P” was like that, though supposedly it was Pomerance (I think?) who “notified the press” after he read the version of the manuscript for which the proof finally worked. At the end of the conference on “PRIMES IN P” at AIM, Goldston gave a talk about his new work on prime gaps (this was the earlier wrong version, before Soundararajan found the flaw), again in part to generate press, which is an AIM speciality.
Perelman’s work was odd in that there was a HEAVY demand for COMPLETE details, with some experts saying that if this wasn’t the Poincare conjecture, it would have been accepted much more easily.
I don’t think Wiles was affected by the Miyaoka FLT/1988 incident, as he was already working in his attic. But crying wolves do have some effect on communities.
As for something (fixable) caught in a close review (but not by the referee!), I heard that the famed Friedlander-Iwaniec paper on primes of the form x^2+y^4 was given by Granville to some student to look at, and, in a flurry of estimates in one of the middle technical chapters involving bounds with Mellin transforms(?), there was something incorrect. I think the fault was that they claimed it worked like the other estimates in a previous section, which was not true. The method was robust enough that they could easily rewrite it, moving some of the workload to a different portion, but they did have to make a nontrivial change. Friedlander and Iwaniec are also technical geniuses, and all the ideas were already clearly there, so the final capitulation was easily foreseen.
I fully agree with the opinion expressed. Mathematical theorems require proofs which meets the current standards in mathematics — for this TCS needs to adopt standard mathematical publishing practices, journal publications, careful refereeing etc . The current publication practices in TCS in my opinion falls short in this regard, and there seems to be no consensus in the TCS community how to remedy the situation (despite periodic attempts by various people to raise this issue — for example,
Neal Koblitz in the AMS notices a couple of years ago).
Yes, I think the real problem is w/ current publishing practices in TCS. Most conference submissions require only proof sketches and additional details may be included in appendices (and viewed at the discretion of the reviewers). This is a serious problem for two reasons, one mathematical and the other political. The mathematical as mentioned above is that authors do not necessarily go through all the details in writing the paper. (I have read papers that have had errors later found in them for this reason.) Second, without everyone being required to support and present their work carefully and rigorously, there is a bias in the review process whereby some researchers (i.e. better reputation, school, insert your favorite bias here etc) are given more serious consideration and more generous slack that their work is correct. It is seriously harmful to the TCS community in many ways.
There is also a strong impact from “cryptography”, perhaps just as a buzzword for funding purposes. Springer Lecture Notes in Computer Science aren’t even counted as publications by some departments any more because of the decline in level. This said, there are still a number of quality researchers in these fields (and many of them, at least privately, are dismayed at the lack of quality content that has emerged in some places).
Harvey,
My feelings on this are that complete detail at the “high-level” scale (i.e. a clear synopsis of the argument, a sense that the problem is being factored into strictly simpler problems, high-level compatibility with other results and insights, generation of new insight and understanding for this problem and for related problems, etc.) is more important for establishing the convincing and robust nature of a proof than complete detail at the “low-level” scale (at the level of individual steps in the proof), though of course the latter is also valuable. See for instance this earlier comment of Gowers, and this earlier comment of Impagliazzo.
It’s also worth mentioning an older observation of Thurston that mathematicians ultimately are not after proofs; they are after understanding.
Terry,
As you well know, depending on the mathematical context, the high level and the low level are more critical or less critical. The high level is always of first importance, because it is next to impossible to construct a fully detailed proof of something interesting without a good understanding at the high level.
But I am addressing the issue of how to prevent the present situation from arising in the first place (assuming it is as it now appears). I.e., a flat out apparently bogus claim of P != NP – sufficient to attract the press, and a whole host of stars and superstars from their normal brilliant activity.
We all know the essential importance of “high level” criteria. Yet this obviously did not prevent a claim being made from a credible looking scholar, with a large number of yet more important scholars dropping what they are doing in order to spend serious time looking at this! And involving the press!!
When the dust settles, the best guess will be that the whole episode was a waste of a lot of people’s time – relative to what else they would be doing. For those of us who will have learned something from this, we probably will have learned a lot more from continuing the wonderful things we were doing before this occurred.
But adherence to my “low level” criteria would have almost certainly prevented the claim from being made. Instead of claiming P != NP, it would have read something like
“an approach to P != NP”
and then interested parties could take a look according to their inclinations and schedules. There would have been no press coverage.
So I repeat my suggestion, with c) below as an *addition* to the usual process for getting a Ph.D. in pure mathematics, theoretical computer science, and heavily mathematical areas:
a. [Those of us interested in logical issues] Flesh out both theoretically and practically what a “completely detailed proof” is – still well short of “ultimately rigorous proof” which we know a lot about already [but which is generally too cumbersome to create under current technology by nonprofessionals].
b. Give [a wide palette of] examples of “completely detailed proofs”.
c. Instill this in the educational process. E.g., all Ph.D.s in heavily mathematical areas must have written a modest sized “completely detailed proof” in normal mathematical language. Exceptions always should be made for “geniuses”.
This is my suggestion for prevention.
For those of us who will have learned something from this, we probably will have learned a lot more from continuing the wonderful things we were doing before this occurred.
I think you exaggerate a bit. Even the greatest scientists, most of the time, don’t do “wonderful things”. They just live. Especially that now it’s summer. So I don’t think there is any harm if they invest several days in this forum (even if the paper is completely bogus); and I believe that most of the non-experts readers here certainly learned a lot just by witnessing the discussion.
While these suggestions may be laudable in their own right, I doubt that they will do much to prevent the problem of a proof that is unlikely to work being nevertheless being taken seriously by a large number of people. For instance, a typical flawed proof written by a serious mathematician may well resemble a completely detailed proof in 98% of the manuscript, and it is only in a crucial 2% of the ms in which there is enough hand-waving that a serious error can slip through that ends up dooming the entire argument. Such a paper may well resemble a “completely detailed proof” to a superficial or even a moderately careful inspection, and in particular in the mind of the author, while being nothing of the sort. (Now this can be remedied in principle by writing the proof in a PCP format, but clearly this is not going to be feasible in practice.)
In contrast, a proof with a complete high-level description can be gauged for plausibility much more effectively. One of the criticisms of the current paper was that a precise top-level description of the proof (in particular, splitting the main result into key sub-propositions) was lacking, and it is only in the last day or so that we are able to reverse engineer such a description (and not coincidentally, we are now also beginning to find significant obstructions to the method). If such a high-level description was in place in the initial ms then indeed I would imagine that a lot less time would have been spent to arrive at the current verdict.
To put it another way: a paper with a careful high-level structure can often survive a lot of low-level sloppiness, whereas the converse is often not true once the complexity of the argument is sufficiently large. So if I had to drill my students on the importance of something, I would rather it be high-level structure than on getting every last detail right, though of course the latter should not be neglected either.
But in either case, there is a limit as to how much good expository guidelines can help in preventing these sorts of events from occurring. There is an understandable (if unfortunate) tendency, in the excitement of thinking that one has solved a great problem, to rush out the paper and make the exposition mediocre rather than perfect, no matter how much they are drilled on the importance of good exposition in their education. And it is not as if one could enforce some sort of rule that badly written solutions to famous problems will not be read; if the attempt looks serious enough, people may well have to grit their teeth and plow through the bad exposition anyway, to settle the matter.
In dealing with this high-level vs low-level problem, I have heard from a senior colleague who complains that he is expected to referee papers which are high-level only, the low level being riddled with holes (we’re talking here about CS papers in a very mathematized area, so you need both practical algorithms and theorems/proofs).
He refuses to do that, and blames other referees who let people get away with that, as well as authors trying to expedite publication by letting the referee do the most unpleasant part of the job.
I cannot comment on how widespread the problem is since I’m not in a similar position. But this suggests that sloppiness may arise more systematically than just from the excitement about having proved the next Big Theorem.
re: Harvey Friedman’s call for heightened standards (or articulation of standards) so as to prevent “irregular” proofs from capturing researcher-time on a large scale —- is this really a repeatable episode, especially after happening once? In 15+ years of the World Wide Web this is the only instance where it occurred. The media also will be more skeptical for some time to come, and they were not credulous in this instance.
Response to T.
I like your point that I may be calling for , as you say, “heightened standards or articulation of standards so as to prevent irregular proofs from capturing researcher-time on a large scale”, where, as you suggest, this may happen extremely rarely. But perhaps there are enough famous open problems left in mathematics and mathematical computer science, so that this kind of reform would have greater applicability? Also, and most importantly, the kind of educational reform I proposed could really help in those much more common situations of people submitting papers for publication – or even internet publication – with erroneous proofs. I’m thinking that it would not only ease the burden on Journals, but also help unfortunate authors. What remains to be seen is whether this reform can really made sufficiently user friendly. I think it can, with the right kind of “logic engineering”. Perhaps we (or I) need to know more about what causes intelligent people to cling to erroneous mathematical arguments? I do think that unfamiliarity with what it would even look like to get to the “absolute bottom” of something, plays a big role. As a logician, I am more familiar with “absolute bottoms” than most mathematical people.
A 3-page “SYNOPSIS OF PROOF” has been posted by Vinay Deolalikar on his HP site:
http://www.hpl.hp.com/personal/Vinay_Deolalikar/Papers/pnp_synopsis.pdf
Based on the synopsis (see in particular the foonote) it seems the finite model theory part will be completely rewritten for the new version. Wait and see..
The synopsis seems promising enough. This guy is going to pull some noses a bit longer. Fixing his “proof” on the fly, he now claims that locality approach (that was so efficiently trashed from many angles on this very forum, and clearly in his private correspondence in 10pt and 12pt) was not really what he meant, but some other property of his obscure model of P computation. I guess he made a mistake of not obscuring some parts of his reasoning enough, but now that can be fixed.
There are hints though of what he meant by number of parameters. These really have to do with Gibbs potential representation of a distribution. He even promises a proof that there are exponentially many of those (the part that is entirely missing in drafts so far). If he delivers that, than we will know what he had in mind. But he runs the danger of being precise, and hence allowing some proper scrutiny of his reasoning, and no doubt, new epic thrashing.
vloodin: Hmm…judging by your many posts personally attacking Deolalikar, I must raise the question; do you have a personal grudge against him? This is no way to behave according to standards (which you apparently hold so dearly), and is frankly quite childish.
“the final version should be up in 3-4 days here”.
Can’t wait.
I think we are past that stage now. We now discuss the merits and limitations of the overall high-level strategy described by, e.g., Tao and Gowers, independently of the original paper. Maybe something can be done with this seemingly interesting strategy. (Maybe a new barrier?).
It seems (to me) that Terry Tao is giving Vinay Deolalikar (and everyone else) a useful hint when he writes: “Errors are first originating in the finite model theory sections but are only really manifesting themselves when those sections are applied to random k-SAT and thence to the complexity conclusions.”
Contemplating Tao’s insight, we see that one repair option for Deolalikar is to restrict P to a weaker model of computation, such that his proof (or a modified version of it) does go through.
That suggests a pragmatical line of inquiry that is very natural for engineers: Can we weaken the mathematical definition of the complexity class P (we’ll call the weaker version P’), such that P’ still captures the practical engineering definition of PTIME computing, and yet Deolalikar’s technology—or indeed any proof technology—for P’/NP separation works?
As a bonus, any reasonably natural definition of P’ (if such could be constructed) would help explain why P≠NP is so unexpectedly challenging, namely, it’s not quite the right question to ask.
We engineers have embraced similar strategies quite often, and with considerable success, e.g., if quantum simulation is hard on Hilbert spaces, then move to a state-space whose geometry is more favorable. In disciplines as diverse as computational fluid dynamics, lattice gauge theory, and density functional theory, this strategy has led to practical and even mathematical successes … so why shouldn’t it work for P≠NP too?
That sounds like an interesting thing to try, but it also seems from the comments people have been making that it would be a big challenge to find a definition of P’ that allows you to do linear algebra.
Partly seriously and partly in jest, I will point that for us engineers there are two kinds of PTIME linear algebra codes: codes that are documented (or can be) versus codes that are more-or-less hopeless to document.
This remark is partly serious in the sense that this distinction is very real to engineers … as the entries in the International Obfuscated C Code Contest (IOCCC) amply demonstrate … not to mention how difficult it proves to extinguish errors even in (to cite a painful example) LAPACK’s singular value routines. One shudders to contemplate what an adversarial version of LAPACK might look like. 🙂
And the remark is partly in jest for simple reason that neither I nor any else (AFAIK) at present knows how to concretely formalize this none-the-less-real distinction.
And finally, I should acknowledge that Tim Gowers’ weblog qualifies him among us engineers as yet another lamed-vavnik of computational complexity … meaning, that ofttimes we engineers imagine that we understand what he is writing about, and are grateful for it.
PS: Hmmmm … Tim, I will try to phrase my natural-to-engineers questions in the less-natural-to-engineers language of complexity theory … I ask your forgiveness in advance for any solecisms that arise.
Q1: Are there algorithms in P that cannot be proven to be in P by any concrete computational resource (in effect, a fixed verification procedure) that is itself in P?
Q2: Define P’ to be the exclusion of these (in effect, non-verifiable) algorithms from P; is P’ easier than P to separate from NP?
Here the point is that for practical purposes of engineering, P’ is just as useful as P.
Like many folks, I’m winding up my own comments on this (wonderful) topic, until such time (in a few weeks?) when some kind of consensus emerges.
Responding to (fun!) posts from Raoul Ohio and András Salamon on Scott Aaronson’s blog, I wrote-up a (clumsy) description of an Impagliazzo-style universe of ingeniarius worlds, that is, worlds in which all legal algorithms are provably in P.
The bottom line was that Impagliazzo’s worlds—from algorithmica to cryptomania—are perhaps too smart for engineers; while in contrast, ingeniarius worlds are perhaps “dumb, dumber, uselessly dumb” … which describes our engineering conception of computational complexity all right! 🙂
Especially, my sincere appreciation and thanks are extended t0 all who have helped to create, upon this forum and other forums, a community that has helped many folks (me especially) to a broader & better … and infinitely more enjoyable … appreciation of complexity theory.
1) Why can’t a few competent theoretical computer scientists in the San Francisco bay area meet with Mr. D., and talk?
2) Raise the objections point blank
3) And report it to the larger community
Seems like an effective strategy to figure out the truth, and the cost is minimal.
The current strategy of raising objection without a careful reading of the paper seems to be counterproductive to me.
The attempts by Terry Tao and others to see if the proof strategy will work at all are very honorable indeed. However, finding a very specific flaw is the most effective way to show that the proof is broken.
The only people who have raised very carefully considered objections are Neil and Anuj on the finite model theory part, and Ryan Williams on how Mr. D tries to connect complexity and complicated structure of solution space. Vloodin has raised the objection that parameterization is not well-defined.
However, nobody has reported on how Mr. D answered these objection, if at all.
Let us ask him point blank in an email, and report his response on this blog.
v,
I offered early on to talk directly to VInay or to have him visit here (at our expense) so we could help. For a variety of reasons that did not happen.
Professor Lipton,
That’s a great idea. Pick up the phone, talk to Vinay, then fly him down to Atlanta (and perhaps Terry Tao and a couple of others) — have a small workshop for 2-3 days to thrash out the issues. Great effort!
Chris
I believe Vinay is giving a talk at HP Labs on Sep 1, 2010 on his paper. I am not sure if it is open to public.
Dr Lipton,
Please allow me to implore you to lay down etiquette guidelines for posting opinions on your forum (analogous to those proposed for an unimpeachable mathematical proof by Dr Friedman above). Many self-appointed geniuses here (they know who they are) would have us believe that Vinay is either a Darth Vader or a Bernie Madoff or a parvenu. In UK, these folks could be sued for libel. Let us wait for Vinay to respond. If he has tried to con the math community, HP would fire him in a nanosecond or less – look what happened to their CEO for a far lesser offence.
Or even, Vinay Deolalikar can directly respond in this blog itself – at least in a hand-waving fashion (till he completes the update on his formal draft) – on why the objections could be overcome. To the majority, it doesn’t sound like they could be circumvented, but if the author himself thinks that way, everybody is happily willing to give him a ground (and he should also give others a chance as well) to bring his side of the arguments to the community’s disposition.
Nothing personal going on here – after all, it is a search for one of the most elusive truths facing mankind as a whole for a few decades.
Yeah, sure! As if he will respond to emails! You must be crazy to think that he is going to read (and much less, answer) emails these days! Just pick up the phone and call him.
Some comments related to the comments by Terence Tao and Tim Gowers (and his blog): I am not sure if the paper’s claim is that for any poly-time-computable Boolean function f on the n-cube, the solution space of f, i.e., f^-1(1) is “poly-log parametrizable.” In fact, for the poly-time-computable predicate R(x, y) that is 1 iff y satisfies x, where x is a k-SAT instance and y is an n-bit vector, the paper seems to claim that the solution space of R(x, * ) is not “poly-log parametriable” for most x’s with respect to some distribution.
The paper seems to be, or, may be claiming that (1) if the problem: “Given x, decide if y such that R(x, y) exists” is in P, then the solution space R(x, *) is poly-time samplable (by “extending a partial assignment”, LFP, etc), and (2) any poly-time samplable distribution is not “poly-log parametriable.”
Possible claim (2) seems unplausible: Let f, g : {0,1}^n –> {0,1}^n respectively be a truly random function and the pseudorandom function obtained from a poly-time pseudorandom generator G: {0,1}^n –> {0,1}^2n in a standard way. Think of f and g as samplers defining distributions on n-cube: Think of the images of n-cube under f and g as the multisets of size 2^n; e.g, if an n-bit vector y appears 3 times, prob weight of y is 3/2^n.
I don’t know what poly-log parametriability exactly means, but it seems reasonable to assume the following: Given a distribution D on n-cube, in terms of samples, deciding if D is (almost) poly-log parametrizable or not can be done in time 2^(n^epsilon). But then this amounts to distinguishing random f vs pseudorandom g, and can’t be done if G is a reasonably strong pseudorandom generator.
Ah, yes, my use of the term “solution space” was perhaps sloppy in that respect, it’s more like the fibers { y: R(x,y) = 1 } above the solution space { x: R(x,y)=1 for some y} than the solution space itself. Still, I think it is likely that Tim’s objection can be modified to concoct a polynomially solvable problem with pseudorandom fibres (I suppose this is similar to your point (2)).
I think you meant ‘(2) any poly-time samplable distribution *is* “poly-log parameterizable”’?
Actually, on thinking about it a bit I think that Tim’s objection can be trivially modified to deal with this more complicated notion of a solution space.
Let f: {0,1}^{2n} -> {0,1} be a pseudorandom circuit. Let R(x,y) be the predicate “f(x,y) = 1”, where x, y are n-bit strings. Then one definitely expects by probabilistic heuristics that for all sufficiently large n that the satisfiability problem “Given x, does there exist y such that R(x,y)?” to have a positive answer, and so this problem is trivially in P (just return “Yes” all the time). But for typical x, the solution spaces {y: R(x,y)} of R(x,*) look pseudorandom, and so I think Tim’s objection still applies here (unless I am still misunderstanding something…)
P.S. one could argue in this case that the corresponding random satisfiability problem (in which f is replaced with a random function) is also trivially in P and there is thus no direct need to separate these two examples. But it is not hard to tinker with the problem a bit more to fix this also. For instance let R(x,y) be the predicate “f(x,y)=1 AND f'(x)=1” where f’: {0,1}^n -> {0,1} is another pseudorandom circuit. Then this problem is still in P and the fibers are still pseudorandom. But if we replace both f and f’ by random functions, then the problem is no longer in P, but the solution spaces look indistinguishable.
The high-level point here, I guess, is that once one possesses the primitive of a pseudorandom circuit whose output also behaves pseudorandomly, one can start constructing a very large number of examples of computationally feasible problems that are very difficult to distinguish from infeasible problems in their solution space geometry (regardless of how one chooses to define “solution space”) , and which look like an extremely robust barrier to any attempt to separate complexity through a structural analysis of solution spaces.
isn’t (1-(1/2)^n)^(2^n) approximately 1/e? Well, still a fraction of the randomly generated pseudorandom circuits will be in P, as far as I can see, but what can we say about their pseudorandomness if they are selected for some feature (for each x have at least one y)???
Well, OK, we can just give y 2n bits instead of n bits (so f is now a function on {0,1}^3n then), so that the probability of unsatisfiability goes exponentially to zero with n. As I said, there is a lot of flexibility here to design one’s problem to do more or less anything one wants in the solution space geometry…
But Deolalikar sais: “It is not only the geometry of the solution space, but the effect that it has on the number of independent parameters required to specify the distribution, that has to be taken into account.”
This could in principle exclude the pseudo-random function example. But how?
Thinking a bit more on it, it is still not clear. Actually, you need a pseudorandom generator that builds for each n a pseudorandom circuit, and then the R(x,y) predicate asks for a (whatever function in n) x if there is a (whatever function in n) long y for which the output of the circuit is 1.
Is it in P? I doubt. I understand that there is a lot of flexibility here, on the other hand, our algorithm should work for any n, and I’m afraid the trivial solver that always returns with YES will not work. Then you have to build up a pseudorandom circuit, take a fixed x, and… How to continue? If we cannot be sure that the answer is yes, we are in trouble…
Actually, now that I look at it more carefully, one does not need to extend the length of y to 2n bits, because I don’t think the 1/e calculation was correct.
If R behaves like a random function, then for any n-bit x and y, there is a 1/2 chance that R(x,y)=1, and so for any n-bit x, the solution space { y: R(x,y) = 1 } will be non-empty with probability 1 – 2^{-2^n}. Thus, for any fixed n, the probability that the solution space is non-empty for _all_ x is something like (1 – 2^{-2^n})^{2^n}, which is more than exponentially close to 1. From the Borel-Cantelli lemma we thus expect that the trivial YES solver will work for all sufficiently large n and all n-bit inputs x. (Note that we do not actually have to possess a proof that YES will work; we just need to believe the conjecture that it does in order to disbelieve that one can use the structure of solution spaces to separate complexity classes.)
The point is that you cannot fix n…
You must have a solver that works for any n…
Yes, this is why I invoke the Borel-Cantelli lemma to ensure that (heuristically, at least), the YES solver is going to work for _all_ sufficiently large n.
But you cannot apply the Borel-Cantelli lemma for pseudorandom events, I reckon… Sorry for my ignorance in analysis, and lots of apologizes if I am wrong, but I’m afraid, you even cannot set up a solver based on the Borel-Cantelli lemma, which first infers if n is sufficiently large, if not then do some brute-forse calculation and otherwise returns with YES. I’m afraid the problem is with the definition of sufficiently large.
Well, the Borel-Cantelli lemma is being applied at a heuristic level rather than a rigorous one. Consider for instance the standard heuristic argument that there should only be finitely many Fermat primes 2^2^n+1, because (using standard randomness heuristics about primes) each such candidate has a probability about 1/2^n of being prime (this is an oversimplification, but let us use it for sake of argument), and this is an absolutely summable sequence, so by Borel-Cantelli we heuristically conclude that there are only finitely many such primes. Indeed the same argument gives us quite good confidence that there are no such Fermat primes with n > 1000 (say).
In a similar vein, the same heuristics give us quite a bit of confidence that the YES solver is going to work for all n > 100o and all inputs. Yes, this is only a heuristic conjecture rather than a rigorous argument, but so is the hypothesis that pseudorandom number generators exist in the first place.
1. I meant to say: (2) any poly-time samplable distribution *is* “poly-log parameterizable, as pointed out/corrected by Milos Hasan (Thank you, Milos).
2. As to Terry’s comments, I still don’t understand: I think that the fact that pseudorandom fibers of poly-time random-like functions and random fibers of random functions looking very similar is consistent with the paper, as opposed to being a problem for it, because the paper claims that fibers of R(x, y) are *complex* (x: SAT instance, y: n-bit vector; R(x, y) = 1 iff y satisfies x).
Yes, but the point is that one can also make the fibers of R(x,y) complex if one replaces SAT by a P problem by using pseudorandom circuit constructions. So there does not appear to be a separation between SAT and P here.
I think the paper says “poly-log parametrizability” follows from the poly-time decidability of a question “Is y a solution?” *and* a question, for any partial assignment s fixing some bits to be 0/1, “Is there a solution extending s (ie, compatible with s)?”
In other words, the claim for polylog-parametrizability is being made not for all solution spaces of P-problems, but only for their subclass where the existence of s-compatible solution is also poly-decidable for any partial assignment s.
For random-like poly-time functions (and their fibers), compatibility existence questions do not seem be poly-time computable in general.
I maybe missing something, and I’m a bit unsure if there is any point in analyzing the proof or the proof strategies further at this point…
Well, if one wanted to analyse the solvability of R(x,y)=1 for some pseudorandom circuit R, with x a fixed n-bit string and y already having a partial assignment s, then there are two cases. If there are less than 100 log n (say) bits remaining to assign to y, one can simply use brute force, which takes polynomial time. If there are more than 100 log n bits remaining, then a back-of-the-envelope heuristic computation suggests to me that the YES solver should always work once n is large enough (basically because there is a factor of 2^{-2^{100 log n}} that dominates all 2^{O(n)} entropy losses).
I personally agree that there is not much doubt left that the proof strategies here are unlikely to lead to a viable approach to P != NP, but since we’ve come all this way already, we may as well finish the job and make a precise description of the obstruction…
OK, along a similar line to various attacks on the paper, I will attack Tao’s argument: if a procedure like this worked, could it not be used on SAT itself, solving it in polynomial time? A solution to SAT can, after all, be trivially verified in P. I think the issue here is the density of the solution space–if this density gets exponentially lower in N, then an approach like this must become exponential.
Tao’s argument relies on a solution (to the problem of extending a string) being verifiable in P. But being able to verify a solution implies that the problem is in NP, not in P. In other words, he has shown that the paper’s argument can’t substitute NP from NP…
Or am I missing something here (I may very well be, since I don’t understand the paper at all).
The question which I insisted on, how is number of parameters defined, seems to have been hinted on in his new survey. It is based on Gibbs potential.
One idea of how this might work, based on the paper, is the following:
Consider the formula f in k-SAT, with m clauses and n variables. Define the following function of T (a real parameter, temperature in stat. physics)
Z(T)=\sum{2^n possible values of (x_1…x_n)} e^(-M(x)/T)
where M(x) is number of unsatisfied clauses in f(x_1…x_n), 0<=M(x)<=m.
We say that solutions are L-parametrizable if there are L terms of the form z_i(T)=e^(-c_i/T) so that we can express Z(T) from these using addition/multiplication,
Z(T)=(z_1(T)+z_2(T)+…z_{l1-1}(T))*(z_l1(T)+…+z_{l2-1}(T))*…*(z_lj(T)+…+z_L(T)).
Here c_i are some constants, depending on formula f.
This defines L precisely, as a function of f, and is related to the solution space.
Now apparently L is 2^polylog(n) for k-XORSAT but is exponential for k-SAT.
I am not sure about the definition above, but I believe, at least conceptually, that
the elusive “number of parameters” was encoded in the complexity of the partition function Z(T) (which depends on the formula).
So, the following conceptual points can be made:
(1) “Number of parameters” is something that depends on a k-SAT formula, not on an ensamble of formulas. Given a single instance of a k-SAT problem, we get a well defined function Z(T), and its complexity is measured by “number of parameters” (perhaps a bit more complicated than the one I suggested, but still, depending on function Z(T) of single variable)
(2) Any polynomial algorithm gives rise to simple Z(T). Most generally, this means that we can compute Z(T) in polynomial time, but probably is much more than this.
(3) General k-SAT formulas have Z(T) that are hard to compute.
On a conceptual level, this is not necessarily a bad idea. We could define complexity of Z(T) in some way so that all polynomial algorithms, via sampling, would allow us to compute Z(T) easily. This should be manifested in a small number of “parameters” that measure complexity of Z(T).
On the other side, complexity of Z(T) (“number of parameters”) should be defined in a way simple enough so that we can determine it for typical k-SAT formula in relevant phase to be exponential, i.e. greater than possible if P=NP.
As I commented above, I do not think one can define these “parameters” via “number of steps needed to compute Z(T)”. Z(T) is a counting problem, and many polynomial decision problems have #P-complete counting problems (e.g. matching).
If he is using something like this, and if he is right, then the paper should be called P!=#P, isn’t it?
He does say at one point in the paper that number of parameters in interactions with potentials which are k-ary, grows as c^k, rather than as c^n (n number of variables). So “parameters” seem to be more like these individual potentials, than variables x_1… x_n.
Even if complexity of Z(T) were #P complete, that would not necessarily invalidate this approach. He wants to show that if we can solve formulas with P, THEN we can compute Z(T) efficiently (in essence, by computing contributions from each of these “parameters”). Than this would contradict the fact that in general Z(T) is hard to compute. But presumably, this is shown by mere counting of the “parameters” – there should be exponentially many of them. Yet in P algorithms, there are much fewer of these.
So a question is: for k-XORSAT, can we compute Z(T) efficiently (is it in this case #P complete as well?). If we can, than there might be something in his approach. If we cannot, than one needs probably some other measure than complexity of Z(T).
Computing Z(T) for any value of T in XORSAT is indeed very difficult. In fact, when a XOR-SAT formula is UNSAT, finding the assignment with the lowest cost is NP-HARD… It is only the decision problem SAT/UNSAT that is easy for XORSAT formulas.
This is why getting a precise definition is important. It would allow one to test the whole strategy in a straightforward way.
It is possible that his definition of number of parameters is such that this number is exponentially large for k-XORSAT, despite of what he thinks. After all, this would only make sense since statistical behavior of k-SAT and k-XORSAT has same phases, and many similarities.
That would mean that he has an error on the other side of the argument (where currently flaws are located), i.e. that having small number of parameters does not follow from P. He has some class much weaker than P that gives Z(T) simple structure. That is, if anything at all follows from his paper.
We can wait and see what the new draft brings. Then it will be clear which of the speculations was right, but despite of what he says, it doesn’t seem likely that he has a way to capture all of P, and get small number of “parameters”, since this would probably give a simple Z(T).
So, as we all suspected, there is little chance for this approach to be saved.
Lenka, do we know that P != #P or would it be a new result? If it is new, and Deolalikar’s approach might save that it would be still nice!
Istvan: I believe that P != #P is stronger than P != PSPACE (you can count the solutions by iterating through all of them in polynomial space), which is not known.
From point 8. of Deolalikar’s synopsis: “We prove that each set of values the core takes in the exponentially many clusters must be specified as an independent parameter of the joint distribution”.
If there is anybody out there having a clue of what is the definition of the “independent parameters”, then please save me the headache :)!!!!!!
No one seems to know that. I have been asking this question for a while.
Yet, it seems to me that this number of parameters measures complexity of the partition function, Z(T). It depends on a single formula. The distribution is just the Boltzmann distribution, but what matters here is complexity of Z(T). However, the details of this are not given.
So, there is some measure of complexity of partition functions, the elusive “number of parameters”, call it P(Z). It is supposed to be 2^polylog on instances of k-XORSAT but exponential on typical hard instances of k-SAT.
After rereading section 2, independent parameters appear to refer to how many values are needed to describe the joint distribution. The standard analogue in directed graphical models would be the size of the tables that form the conditional probability distributions.
For example, assuming three variables X,Y, and Z. If all are independent then P(x,y,z)=P(x)P(y)P(z) and would require three parameters because each is over one variable. This would be the case of a completely disconnected graph. But if this DAG was fully connected then, P(x,y,z)=P(x)P(y|x)P(z|xy), where P(z|xy) is over three variables and would require 4 parameters and the total distribution would take 7. So it takes 2^(c-1) parameters to specify each factor where c is the number of variables the factor is over.
The analogue for an undirected graph would be, given size of the cliques in the graph, each clique of size c would require 2^c parameters.
The analog for undirected models would b
Yes, but what probability distributions are parametrized/considered.
I can understand in Markov network, you would have certain family of distributions satisfying Markov conditional independence property.
But what about the solution space? What probability distribution family is parametrized there? He speaks of potentials, and Gibbs energy, so presumably you put Boltzmann distribution with parameter T. The parameters correspond to cliques or potentials that one can define arbitrarily.
It is still unclear what he means, and given that this is the central issue in his “proof”, one has to see what he is going to say in his new draft.
I suspect that his definition will imply that if there are few parameters for a given formula, then Z(T) can be computed easily.
But then it would easily follow that he did not capture all of P, since k-XORSAT has NP-hard function Z(T).
Is it easier to prove Reimann hypothesis?
I often tell people (not many, luckily) who want to prove P=NP or P/=NP that they are better off trying to prove the Reimann hypothesis. The problem with P/=NP is that it is not enough to prove great combinatorial results (which is most likely what is required to prove the Reimann hypothesis, whether it uses dazzling analytic tools or not), one has to first tackle the issue of what computation in P-time means.
All known equivalent formulations of PTIME allow such generality, as well as the nature of computation to allow easy relativization, that some people think it is not even possible to separate P-time computation from others using proof techniques (and even very general fragments of logic) known to humans so far.
As far as P=NP is concerned, suppose somone comes up with an algorithm for their favorite problem say SAT. Then, one realizes that they have a new algorithm for not just other NP-hard problems but also simpler problems like primality testing.
Now, reducing Primality testing to NP requires just the minimal of axioms about numbers, for example associativity. So then, you have an algorithm for testing primality which uses only simple properties of numbers like associativity, and the new SAT algorithm. If the new SAT algorithm did not discover some profound properties of numbers but relied on logical formulations and combinatorics thereof, then, it means primality testing is at the same level…hence possibly you have a new insight for Reimann hypothesis.
In order to argue that you are “better off trying to prove the Riemann hypothesis,” don’t you need to assume that P is equal to NP? If they’re not equal, how does that impact RH?
In P/=NP case, I was just remarking that this problem has some results which lead us to believe it is independent of fragments of Number theory like bounded arithmetic (although, no definitive such theorem has yet be proven…but serious attempts and some progress has been made). This is not the case with RH.
Paradoxically, I should add though that it is probably easier to prove that NP/=P is independent of certain fragments of bounded arithmetic than proving RH.
Hi all,
I have posted what I think is a definitive objection to any proof separating P from NP that relies on the structure of the solution spaces of SAT, and tries to argue that no problem in P has this kind of solution space. The basic idea is that every satisfiable formula’s solution space can be mapped to the solution space of a formula satisfied by the all-zeroes assignment, which is always trivially solvable. This map exactly preserves the number of variables and all distances between satisfying assignments. It is of course non-uniform, but that doesn’t matter: for every infinite collection of satisfiable formulas there’s an infinite collection of formulas satisfied by all-zeroes which has exactly the same solution space structure. Details are here:
http://michaelnielsen.org/polymath1/index.php?title=Deolalikar_P_vs_NP_paper#Issues_with_random_k-SAT
Thanks to Jeremiah Blocki for helping me sort this out.
Isn’t it tautology? I mean if we know that there is a satisfying formula, then of course the answer is “yes, satisfiable”, without transforming the function…
On the other hand, if you are given a formula that is not satisfiable, your predictor will “YES, satisfiable”, and gets wrong…
The issue here is that we have a problem which is in P, meaning that for every problem instance there is an algorithm which solves the decision problem in polynom time. Deolalikar’s claim is that if the problem is in P, then every problem instance has a simple solution space.
A problem is in P when there is a polynomial time algorithm such that for every problem instance it is decided by the algorithm. Your quantifiers are backwards.
I know what Deolalikar is claiming. I am proving that for any structure you have in the solution space of any SAT instance, you have identical structure in the solution space of some SAT0 instance. That is, there are problem instances with the SAME solution space structure. If you want more formality, the formal definition of “same structure” is that there is a distance-preserving isomorphism between solution spaces. So no proof of P vs NP can work by looking at the structure of solution spaces.
Something is still fishy here. You force not to give hard problem instances in some sense. How could you achieve this? If you gave me a problem instance:
!@£@£%$^!$^!^!£$QFS@£%^T@$
I can say, NO, I am a linear equation solver, this is not a linear equation.
How could your solver decide if it got a normal form that is not satisfiable or a normal form that you gave accidentally without transforming, otherwise satisfiable but the all-0 input is not accepted?
Istvan, there is nothing fishy going on. The map from SAT to SAT0 is definitely not polynomial-time computable, if that’s what you’re worried about!
Before we even start talking about CNF satisfiability, we must agree on a formal encoding of CNF formulas. I assume that any prospective algorithm knows whatever encoding is agreed upon, and if it doesn’t see something in that encoding it just rejects.
No, I am not worrying about the transformation. Rather, my concern is that what is SAT0 exactly? We agree in the encoding, fine. Then I gave you the problem instance:
(x_1 OR NOT x_2 OR X_3 ) AND (X_123 OR … etc.
And then your prospective algorithm will ask me: hey, if this formula is satisfiable, did not you forget to transform as we agree? And if I am rude, and will not answer, and might happen that I did not transform it, your prospective algorithm will be in trouble.
I will be also in trouble if not going to bed, the kids get up early so do I have to. Let’s continue tomorrow, sorry.
OK, now I see why Ryan’s idea must work:
Consider a NDTM solving SAT0 problems. It must accept all satisfiable SAT0 instances and reject all others. Then it first must infer if the all-0 assignment is a solution to the query, otherwise it could accept satisfiable normal forms coming from SAT\SAT0. At this point you can see that there might be several NDTM solving SAT0, and we are in trouble as we do not know whose acceptance path distribution we should consider. One might argue that there is an unlimited number of NDTMs solving SAT0, and one might come up with the idea to factorize the NDTMs based on they accept the same set of inputs. Then one might argue to look at the ‘simplest’ one. But amongst the equivalent NDTMs solving SAT0, the simplest one is the DTM solving SAT0.
Hence one cannot prove that P!=NP by considering the solution space of the usual NDTM solving SATs, as one parallel must prove that there is no equivalent NDTM with a ‘simpler’ solution space. However, this later on its own would prove that SAT is not in P…
So I think, the answer for Terry’s (3) point is a definite NO.
This is very very interesting. Thanks Ryan.
Yes, this is nice. This also seems to rule out even weaker separations by the same method: even uniform-AC^0 \neq NP seems to be ruled out!
Am I correct?
Conan: Yep! See the wiki.
Ryan,
Thanks for this great comment.
Ryan Williams’s argument is very interesting, and Russell Impagliazzo made a related
comment a couple of days ago that stuck in my mind:
“Here’s why I think this paper is a dead-end, not an interesting attempt that will reveal new insights. As Terry says in his post, the general approach is to try
to characterize hard instances of search problems by the structure of their solution
spaces. This general issue has been given as an intuition many times, most notably
and precisely by Aclioptas in a series of lectures I’ve heard over the past few years.
(Probably co-authors of his should also be cited, but I’ve Aclioptas give the talks.)
“The problem is that this intuition is far too ambitious. It is talking about what makes INSTANCES hard, not about what makes PROBLEMS hard. Since in say,
non-uniform models, individual instances or small sets of instances are not hard,
this seems to be a dead-end. There is a loophole in this paper, in that he’s talking
about the problem of extending a given partial assignment. But still, you can construct artificial easy instances so that the solution space has any particular structure. That solutions fall in well-separated clusters cannot really imply that the search problem is hard. Take any instance with exponentially many solutions and
perform a random linear transformation on the solution space, so that solution
y is “coded” by Ay. Then the complexity of search hasn’t really changed,
but the solution space is well-separated. So the characterization this paper is attempting does not seem to me to be about the right category of object.”
http://tinyurl.com/349fbzu
Ryan,
I think this shifting trick of yours and Jeremiah preserves the P-nature (or lack thereof) of the unrestricted SAT problem, but not for the restricted SAT problem in which some of the literals are already fixed. (In particular, the most extreme case in which _all_ the literals are fixed now morphs from a trivial problem to what looks to be an infeasible one, as it requires knowledge of the non-uniform shift (A_1,…,A_n).) As I just learned from Jun Tarui in his comment above, Deolalikar’s argument is only supposed to obtain a contradiction if both the unrestricted problem and its restrictions are both in P.
But perhaps some variant of this trick can get around this issue…
Ryan,
Really like this simple but clever idea.
For the skeptical about Ryan’s idea, let me try to make my two cents:
Ryan showed that there exists a mapping that takes an arbitrary satisfiable formula F with n (free) variables and maps it to a formula F’ also with n (free) variables with the following two properties:
1. the all-zero assignment satisfies F’,
2. there is a Hamming-distance-preserving permutation of {0,1}^n that maps the set of satisfying assignments of F to the set of satisfying assignments of F’.
Let’s show that this rules out any proof-strategy of P != NP that depends only on distance-based landscapes of solutions.
Let’s say a property of solution spaces A is landscape-invariant if the following holds: if S is the solution space of a SAT-instance with n variables that has property A and f is a Hamming-distance-preserving permutation of {0,1}^n, then f(S) also has property A.
Now, suppose that we managed to show that P != NP by proving the following two claims:
Claim 1: For every polynomial-time algorithm, every SAT-instance accepted by the algorithm has a solution space that has property A.
Claim 2: There exists a satisfiable SAT-instance whose solution space does not have property A.
In such a case we can argue that property A is not landscape-invariant. Here is how:
Let F be the SAT-instance from Claim 2. Look at F’, the transformed F, and apply Claim 1 to the trivial algorithm that always says “yes” and F’, which is obviously accepted by the algorithm. Claim 1 tells us that the solution space of F’ has property A. Since there is a Hamming-distance-preserving permutation of {0,1}^n that maps the solution space of F to the solution space of F’, we must conclude that property A is not landscape-invariant.
I can see that there must be something ridiculously wrong in this thing I wrote, but I can’t find what. Sorry for that. I guess I am just too tired as it’s getting late here. I’ll stop here for today.
I think you may be overlooking a subtlety. I think Vinod was claiming that the structure of a solution space implies that it is hard, given an arbitrary partial solution, to extend it to a complete solution. (Not that it is just hard to find a single solution.) This is more subtle to refute. If by partial
solution, it means the values of consecutive bits from x_1,..x_i, then we can construct examples
like you said. For example, let \Phi be from the distribution in question, and \Psi be any formula
with a unique solution , say 0. Then the solution space for \Phi(x) \lor \Psi(y) is isomorphic to
that for \Phi but given any consecutive partial solution, we can fill in the rest. (Simply assign unassigned bits 0. If we were not given all of x, this is a solution. If we are, it is a solution if
and only if the given bits of y are all 0 if and only if a solution extending the partial solution exists.)
But I haven’t worked out any example where, given any subset of bits, possibly non-consecutive,
it is easy to extend it to a complete solution (if there is one).
Russell
Ryan, a neat way to turn the tables, so to speak. Wonderful!
This trick is a tad too cheap. It doesn’t show anything.
For in the paper, it was important to be able to extend partial assignments, and argument was from that. Yet SAT0 (which I guess is just a trivial algorithm checking weather assignment x_i=0 holds for the formula) has no such ability.
In fact, there is no “solution space” for SAT0 (if SAT0 is anything other than checking assignment x_i=0, then I guess this whole comment is off the mark, but I assume that is what SAT0 is). What would a solution to a problem that checks a particular instance x_i=0 in a CNF be? It does not have any unassigned variables, it just checks one assignment and it is all that it does. We cannot determine all satisfying instances of a given CNF formula using SAT0. SAT0 is a closed formula, there is no existential quantifier there, and hence no solution space.
This can be contrasted with k-SAT, that looks weather there is any satisfying assignment. There is existential quantifier and instances which give positive answer are the solutions.
Hence, the analogy does not exist. For k-XORSAT we do have an analogy, since there is existential quantifier involved, and it gives rise to a solution space. But SAT0 is just a completely trivial algorithm that checks one particular assignment, and can not be used to replace k-SAT in the argument from the paper. It is of the wrong type and conceptually does not fit.
See my comment above.
Yes, you are right, the problem is with the precise definition of solution space. For me, the easiest approach to consider solution spaces as the space of acceptance path for a NDTM. But it turns out that there are an unlimited number of equivalent NDTMs accepting the same inputs, and in each equivalent class, there are members with complicated solution space.
To see this, consider the EDGE decision problem which asks if there is an edge in a graph. Surely, you can build up a NDTM that checks all pairs of vertices if they in the edge set. Fine, now extend this NDTM which does the following: if there is an edge connecting a pair of nodes, then do not stop, but split to two paths. The first is the safe ending, it ends with YES in the next step after the branching, the other continues as a NDTM that solves the maximum match problem. Then this NDTM has a complicated solution space, in fact it is in #P-complete.
You might argue that it is sufficient to look at the solution space of the simplest NDTM, but in fact, if a problem is in P, then there is DTM which has only one acceptance path. So now, if you would like to separate P from NP based on the solution space of the ‘usual’ NDTM representation of the kSAT problem that has exactly one acceptance path for each satisfying assignment, then you also must prove that there is no equivalent NDTM with simpler solution space. However, this later on its own would prove that P!=NP.
vloodin, you are missing the point. I am taking the solution space for SAT0 to be just the set of possible satisfying assignments to such a formula. That is the same solution space we have been talking about all along, for k-SAT, for XOR-SAT, for 2-SAT, etc. The goal has been to find polynomial time solvable problems with “hard” solution spaces. I am saying that for SAT0 that space can be just as “complex” as that of any usual SAT formula. I see no reason why one should “discriminate” against all the solution space structure arising in a SAT0 formula simply because it happens to be satisfied by all-zeroes.
That said, the issue that Terry and Russell raised of extending partial assignments and keeping the problem inside P is tricky. I don’t know if this is necessary to show, though. There is some measure of how complicated the solution space of random k-SAT is, and all I am saying is that, under any reasonable measure, the “random SAT0” solution space should require at least the same measure. Just because all-zeroes shows up among the satisfying assignments, I don’t see why that makes the entire distribution trivial. The fact that, if you extend a partial assignment to a SAT0 instance with some ones, then the problem becomes SAT again, seems to only help the case.
You are right that much of the discussion has been hand-waving, but that is inevitable when you are trying to prove a “meta-theorem” showing that no approach to P vs NP can work in some generic manner. Think of this way: “you must hand-wave before you learn to fly”.
If you would like a non-hand-waving comment, here goes. Strictly speaking, the “solution space” to an arbitrary problem inside of NP (and thus inside of P as well) is not well-defined, because it depends on which verifier you use to check witnesses. We are already giving significant liberties to the author in assuming that such a space does exist, independently of a verifier. This is related to what Istvan says above.
I tried to give some structure for “well-defining” things in my comment back here. If one steps back from a “property of solution spaces” to a hardness predicate, then one can quantify over verifier predicates R(x,y) defining the solution space.
Likewise, quantifying over distributions D on the instance space may help pin down the “phases” the paper talks about. My effort doesn’t digest details like the “ENSP” model, but I think a “switch” from distributions on one space to induced distributions on the other is involved somewhere, maybe multiple times.
One other idle thought, which perhaps Terry has picked up on: does working inside a proof where “P = NP” is taken as a for-contradiction assumption help with issues of “keeping the problem in P” as you say? Dick and I have been interested generally in whether/how-far this kind of device can matter.
The blame for wasting important people’s valuable time lies not only with the author of
the bogus proof but also with the bloggers who prematurely made such a big deal of this story.
Any reason for doing that?
The only reason, IMO, is that nobody ever thought if the separation of P from NP can be based on looking at the solution space. We are not talking about Deolalikar’s work (at least, I got headache reading too much hand-wawing, so stopped considering reading it), but I guess the discussion here is about if any proof trying to separate P from NP could work by looking at the solution space.
If so, it opens some avenue for brave guys trying to prove P?NP, if not, then we have another barrier here, which might be also interesting.
I do not think that this is wasted time. I think we have learned some math, and also learned quite a bit about the social aspects of solving a big problem in the web world we now live in.
Yes, I agree. These are quite interesting and inspiring discussions.
I completely agree. This collaboration has been a great knowledge booster. It yet again showed what that P=NP beast. The wiki is a good collection of resource materials. Dick, you can’t be thanked enough for the polite initiative that you took. I am surprised to see no mention of you or your blog in any of VDs writeup/webpage. Not that you or me, for that matter, care much, but no mention of this big effort does not just sound right.
I also want to thank Dick Lipton for the monumental effort. I am very thankful not only for the things already said (things learned, putting N != NP in the spotlight, etc) but also for something else that many researchers here take for granted: this was a public showing of the rigorous peer-review process that many people, specially aspiring researchers, non graduate students and amateur scientists, are unfamiliar with. For somebody attending a good university in his/her country of origin but where top notch research is not conducted, this whole exercise provided a glimpse about what’s like doing cutting edge work. Hopefully that might be a motivation to pursue a career in math or science later on.
Kudos Mr Lipton!
On the contrary, nobody’s time was wasted because THIS IS WHAT WE DO EVERYDAY.
Exchanging ideas with colleagues in order to learn more about the nature of computation? CHECK
Promoting our field to the public by showing how fascinating these questions can be? CHECK
Collectively peer reviewing and correcting each other’s mistakes? CHECK
This is probably the best promotion of theoretical computer science in a loong time, and unlike some dumb movie it wasn’t diluted or watered down.
Thanks Vinay!
Indeed, it must be an exciting time to be a student. (I find it fun even just being a bystander.) The internet has changed the way things are done a bit, but not so much after all, this is still refereeing and animated discussions etc. But it has opened up the process for outsiders to see, and I hope it will enlighten the next generations. (I was an undergrad during Wiles’s proof, and though we did hear about it some, I remained rather naive about research for a while after that.)
Sorry guys, it is midnight here in Europe, so I have to go. Thanks for all participating in the discussion, it was really nice!
One has to understand what Steve Cook meant by “relatively serious attempt” . The volume of obviously completely baseless “proofs” of P=NP or P!=NP we have all seen is enormous and you can imagine how much larger his inbox on the subject has been. Quick kills usually take a matter of seconds or minutes to find and there are some stock replies that can be sent out based on these.
The last time I can recall that there was any argument, claiming either answer, that seemed worth exploring was one by Swart in 1984 which claimed that P=NP because he claimed that one could solve the TSP by creating an LP whose variables were indexed by 4-tuples (or later 6-tuples) of vertices, whose resulting extremal points were integral. It seemed highly unlikely but one could not dismiss it out of hand. There was considerable back and forth, with the number of indices growing. The final nail in the coffin was a lovely paper by Yannakakis, using communication complexity of all tools, to show that any such approach was bound to fail. This paper inspired people like Lovasz and Schrijver to consider the properties of of other methods for lifting LP-relaxations and SDP-relaxations of 01-IP problems. In the end, something useful did emerge from the community’s need to deal with the faulty argument.
It remains to be seen if there is anything to be gained from the current paper, assuming a similar failure – which very strongly seems to be the case. (At least Swart’s paper had formal statements that could be checked, though it was fuzzy in some details.) I expect that it will focus some serious research, if only for the following reason: Given the current state of publicity, it is possible that it will generate an entirely new class of faulty arguments by a much broader group of people and we will need some like Yannakakis to provide a nail in the coffin in the approach in order to deal quickly with its inevitable imitators.
Well, the problem is that, when one is making such (non-negative to say the least) comment, it is not terribly difficult to predict the reaction of all the journalists and pseudo academics like Greg Baker (whose research interest focuses on how to enforce his authority when dealing with “problem undergrads”).
Actually, the original statement was: “this appears to be a relatively serious claim to have solved…”.
This puts two reservations before the word “serious”, i.e., “appears to be” and “relatively”. Let’s assume that each reservation decreases the statement coming after it by a factor of 1/3. So we end up with the statement saying that “the paper is 1/9-serious”. Which is somewhat accurate.
It is indeed accurate — especially if his comment only stays within TCS. As anyone would not expect such proof to be confirmed within two days. But it became disastrous after it’s disclosed to the public (again thanks to Greg Baker…), you know what journalists are like, any slightest acknowledgement gets massively amplified…
In case anybody is wondering, Greg Baker has:
B.Sc., Queen’s University, 1998
M.Sc., Simon Fraser University, 2000
and is a lecturer at Simon Fraser. LOL.
Based on the synopsis it seems that the alternate perspective posted by Leonid Gurvits on the wiki captures Vinay’s ideas.
Basically using FP(LFO) the proof generates a solution space of SAT whose distribution is described by poly(log n) parameters. Immerman has pointed out technical flaws in the use of FP(LFO) and it appears Vinay thinks he can address them.
Coming from the NP side, the proof claim (roughly) that this violates the c^{n} lower bound for SAT for k >9. Ryan Williams has a “meta” argument against this. However, the claim made by Vinay is quite concrete: “In the hard phase of for random k-SAT, for k> 9, the number of independent parameters required to specify the distribution is c^n.” Is this true?
What about the following question: Is there any new theorem proved correctly in Vinay’s paper? If yes, it could be useful to filter them out and put them on the wiki for future reference.
Suppose I assume “In the hard phase of for random k-SAT, for k> 9, the number of independent parameters required to specify the distribution is c^n.”
What I don’t understand is: why doesn’t it also take c^n independent parameters to specify the distribution of a “random” SAT0 formula (a formula satisfied by the all-zeroes assignment), under the following distribution?
First, I pick a random k-SAT formula. Whatever distribution you want to use, I will use it.
Then I choose a satisfying assignment of that k-SAT formula uniformly at random, call it (A1…An).
Then the transformation (seen in the wiki) to SAT0 is performed.
We now have a random SAT0 instance, and its solution space is just as “complicated” as the original k-SAT formula… except for the little detail that the formula’s trivially satisfiable in polynomial time by trying the all-zero assignment.
How can you “specify the distribution” of these SAT0 instances with less information? The fact that the all-zeroes assignment happens to be included in the distribution looks totally irrelevant to the complexity of specifying the distribution.
To finally dismiss the proof (from the NP side) it will have to be demonstrated that if F is the distribution of the solution space of random K-SAT and G is the distribution of solution space of SAT0, then F=G in distribution. Perhaps you can show that the Kullback-Liebler divergence which is the sum of F_iLog(F_i/G_i) indexed over the histogram bins is zero. At the moment your transformation is injective and not necessarily surjective so the distributions might not be the same (even though the solution space of K-SAT is contained in SATo) as the probabilities have to add up to 1).
This argument with SAT0 is really not showing anything. But it is perhaps a rebuttal that this paper deserves – sloppy paper with superficial arguments and lots of hand waving that are in fact wrong and off the mark should have at least some rebuttals of the similar quality. Cosmic justice, if you like.
First, we do not know what “number of parameters” means.
Secondly, it seems that under any reasonable interpretation of “number of parameters”, not only k-SAT formulas will require exponential number of them, but k-XORSAT also. So, the part of the argument which fails is on the side that each algorithm in P gives rise to a small number of parameters.
Then again, we do not know what is his number of parameters, and what are distributions that he parametrizes. That is one of the many (but perhaps the most important) places where the author waves his hands and confuses the naive audience.
Please pardon me if the following is an ignorant comment, but here goes:
I’m a lowly PhD physics student at MIT. 🙂 Specifically, I am a PhD student who is very concerned with how well classical and quantum annealing algorithms approximate the solutions to random constraint satisfaction problems.
Now when one investigates random local search heuristics like classical simulated annealing or quantum annealing, one never expects a constrained-minimization problem to be easy just because it has a single global minimum. One needs to know how many local minima there are that could trap your search algorithm.
As such, I agree with the many critiques of Deolalikar’s proof that say it’s a wrong-headed goal to separate P and NP by pointing to the “complex structure” in the “solution space” of random k-SAT for k \geq 9. While it’s still a little unclear to me what exactly Deolalikar means by “solution space”, it seems that he at least sometimes means “solution space” simply as the set of assignments that satisfy all the k-SAT clauses. If so, then as many others have mentioned, it’s quite obvious “complex structure” of “solution space” is neither necessary nor sufficient to prevent polynomial-time solution (e.g., one reason it’s unnecessary for computational intractability is Valiant and Vazirani’s randomized reduction of SAT to SAT-with-a-Guarantee-that-There’s-At-Most-1-Solution).
But what if we generalize this notion of the complexity of parametrizing solution space? To be specific, what if we instead investigate the “complexity” of describing the distribution of the number of violated clauses over all possible assignments (thus caring not only about global minima but local minima too, and all those pesky maxima and saddles as well providing barriers between the local and global minima)?
If we did this, how many of the random k-SAT critiques of Deolalikar’s proof could then be circumvented? (Granted, it might take major new ideas to figure out the “complexity” of parametrizing the distribution of violated clauses over all possible assignments).
Thanks,
Bill Kaminsky
With respect to the conversation that has unfolded on this blog, some people are still thinking in terms of what went wrong and how a repeat can be prevented. I can’t fathom this perspective.
Although I am entirely unqualified to comment on Deolalikar’s paper, I have an overwhelmingly positive attitude toward the discussion that has transpired here in its wake. What I have seen on this blog is a process of immense power and beauty. Everyone should pay close attention to what Professor Lipton has facilitated, in hopes of making it happen repeatedly in the future.
Fritz, imagine a hiker is injured and stranded on a mountain top. A bunch of mountain climbers from the region drop everything they are doing and mount a brilliantly coordinated rescue effort which pulls off a number of amazing technical feats in a very short time in order to get the hiker off the mountain. Do we say it was a beautiful and exhilarating experience for the rescuers? OK, maybe we do. Would they say “let’s do it again” in the sense that people getting stranded (because they were improperly trained and didn’t bring the right equipment, say) is a good thing? Not the same question.
Nice analogy, except that mountain-climbing rescue efforts are a burden on society and benefit nobody other than the person being rescued. The present discussion, in contrast, benefits the participants and onlookers regardless of what it does for Deolalikar.
At this point, with the proof seriously damaged if not completely busted, nobody is neglecting activities they would rather be doing in order to participate here out of a sense of social obligation. Clearly the participants are getting so much out of it that they volunteer their time gladly. It is misplaced for observers to fret about the “wasted” efforts of people are engaging in joyous exploration and producing concrete, valuable insights.
Sorry but this analogy is incorrect. Someone stranded atop a mountain is in mortal risk and it is ethically imperative for rescuers to make an effort to reach him. No such ethical compunction exists in the case of this proof.
A better analogy would be to someone who, having reached the mountain top, sends photographs to other climbers suggesting that they come take a look as well. Should they choose to follow his call (which, once again, they are not compelled to do), and find later that the promised panorama is not in their opinion up to the billing, surely the blame does not lie with the author. Especially if, in the effort of scaling the mountain, much thought-provoking conversation (or mountaineering equivalent result) is obtained.
In fact, the analogy is useful in a very different sense: The commentor (asdf) has correctly identified that what is being promised here is the mountaintop (from a mountaineer who is credentialed enough to have possibly gotten there).
Assuming that D is able to answer all the questions raised here and else where, and that the proof does go through, what happens to complexity theory after that? I was just wondering…
Once P neq NP is proved, then true understanding in complexity theory will really begin, rather than end. It would make complexity theory an extremely hot area, because P neq NP is really among the “first” lower bound questions one can ask. Many people really think that SAT needs exponential time, and P neq NP is only the first step towards proving this.
Right now one might say that complexity theory is in a kind of “prehistory”, where much of the work consists of proving many conditional statements of the form “If this lower bound holds up then this other lower bound holds”, “if this upper bound holds then this lower bound holds”, and so on. There are some unconditional lower bounds but they are quite rare. One idea behind building this catalog of relationships is that, with each new relationship found, the first gigantic breakthrough will have an even bigger “ripple effect” through complexity than before.
Also, the complexity theory of polynomial-time solvable problems (which is covered by much of parameterized complexity theory) has hardly been touched. Fix k \geq 3. Does the k-clique problem really require n^{Omega(k)} time? It seems only harder to prove tight polynomial lower bounds on polynomial-time solvable problems.
This will not be well received, and my late father would not approve (even if his old friend Steve Kleene would probably chuckle a bit), but I think it should just be put out there for the record. This “proof” is fundamentally non-constructive. As it is, it appears not to be correct anyway for reasons that Neil Immermann and various others have pointed out. But, even if their issues were somehow to be overcome, there would remain doubt from the point of view of a deeper critique.
For the record, I have always found proofs by contradiction to be elegant and beautiful, even as I am unfortunately aware of their ultimate limitations.
There are some powerful automatic conversion theorems in mathematical logic to the effect that if a sentence of a certain form is provable in the usual sense then it is provable constructively. Of course, these terms need to be defined for the purpose of this family of theorems. Generally speaking, this family of general results takes the following form, for a large variety of axiom systems T. Let T- be the constructive (intuitonistic) form of T, where we simply require that the proofs avoid the law of excluded middle (in the usual sense as formulated by Arend Heyting). It is known that under general conditions on T, any AE sentence provable in T is already provable in T-, and there is an explicit conversion method for this, known as the A-translation. Here AE means (for all integers n)(there exists integer m) such that something readily testable holds.
The most commonly quoted case of this is where T = Peano Arithmetic = PA, and T- = Heyting Arithmetic = HA. HA is the constructive form of PA. But the result applies flexibly to many other systems, both much stronger and much weaker than Peano Arithmetic/Heyting Arithmetic.
The statement P = NP takes the form EA, which means (numerical) existential universal, using SAT. So P !NP takes the form not(EA). This conversion theory tells us how to convert a proof of not(EA) in PA to a proof of not(EA) in HA, and more. Write P != NP in the form (En)(Am)(P(n,m)), where P is totally innocent logically. Here “E” is “exists”, and “A” is “for all”.
If PA proves not(En)(Am)(P(n,m)), then HA proves not only not(En)(Am)(P(n,m)), but even (An)(Em)(not P(n,m)), and the conversion from PA proof to HA proof is rather explicit, using the A-translation.
Returning to the specific case at hand, of P != NP, these considerations tell us, for example, that any (CORRECT!) proof in PA of P !=NP can be explicitly converted to a proof in HA of P !=NP. In fact, it can be converted to a proof in HA of the statement T(f) =
“for all constants c, any algorithm of size at most n with built in running time <= (x+c)^c must give the wrong answer to SAT at some input of size x <= f(n,c)"
where f is a so called <epsilon_0 recursive function. I am under the impression in this Deololikar P !=NP "proof", this statement above under quote signs is "proved" where f is an exponential(?).
BTW, this raises some interesting questions that perhaps have been addressed(?) independently of any logical issues. What can we say about the statement T(f) when f is slow growing? I.e., what is the "strongest" statement that we can hope to prove, or at least can't refute, or believe, concerning the identification of, or size of, a mistake that any purported algorithm for SAT of a certain size running in a certain time must make? This question can obviously be raised in a very wide range of complexity contexts, and surely(?) has been addressed.
For fast-growing f this was addressed by many people (including DeMillo-Lipton); then Deborah Joseph and Paul Young argued in the early 1980’s that f should be no worse than elementary. The latest effort in this line that I’ve tracked is by Shai Ben-David and Shai Halevi (ps.gz here). But all this stops short of a really concrete treatment of SAT, and maybe now that should be revisited. Scott Aaronson’s 2003 survey http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.89.6548 has more.
Minor typo in paragraph beginning “The statement P=NP…”, should say later “Write P != NP in the form not(En)(Am)(P(n,m))” (missing “not”).
I took a quick glance at the references you mention (Kenneth W. Regan), and these “arguments” seem to be exploiting the observation that current concrete independence results are connected with fast growing functions – e.g., no current concrete independence results for Pi-0-1 (purely universal sentences quantifying over integers).
This is no longer the case. See the latest, http://www.cs.nyu.edu/pipermail/fom/2010-August/014972.html where natural (steadily increasingly natural) Pi-0-1 sentences are claimed to have been proved independent of ZFC (not just PA), and in fact stronger systems involving large cardinals. Here natural Pi-0-1 sentences (i.e., A sentences) relate to kernels in order invariant digraphs on the rationals.
In any case, I didn’t spot an outright definite claim that, e.g., if P != NP is true in Pi-0-2 (i.e., AE) form, then it is true iterated exponentially. Did I misread these papers, and they do claim such a thing? (I’m better at thinking than reading – sometimes this is a handicap).
Here is a TR version of the paper “Polynomial Time Computations in Models of ET” by Deborah Joseph—its essence is also mentioned in other papers by Joseph and (Paul) Young which can be found online. Maybe it speaks toward what your reference says about towers. (A slightly longer reply with 2 links got into the mod queue; I see that didn’t happen to my first reply because I muffed the Ben-David-Halevi link.)
Thank you Harvey and others. Very useful.
Just one other note—we mentioned right away last Sunday that the paper does not even state a concrete deterministic time lower bound for SAT. Among private friends I projected disappointment in the event that “P != NP” would be solved that way, though as Ryan Williams has just noted here, it would be a harbinger of more constructive complexity separations to come.
http://www.topnews.in/p-vs-np-mathematical-problem-successfully-solved-indian-brain-2268953
P vs NP mathematical problem is successfully solved by an Indian brain
Even though Vinay Deolalikar has solved this P vs NP mystery but many of the scientists have not accepted his way of solving the theory, they want him to solve it practically in the right way.
Few of them also claim that if Vinay can prove its claim right then they promise to pay $ 2 million as a prize.
On the number of parameters issue. Take a look at this link:
http://www.nlpr.ia.ac.cn/users/szli/MRF_Book/Chapter_1/node12.html
Most interesting is the following:
For discrete labeling problems, a clique potential V_c(f) can be specified by a number of parameters. For example, letting f_c=(f_i1,f_i2,f_i3) be the local configuration on a triple-clique (i_1,i_2,i_3), f_c takes a finite number of states and therefore V_c(f) takes a finite number of values.
Thus, we see that to get this number of parameters, we need to express potential U as a sum of simpler potentials V_c(f), and then count parameters according to arity of these simpler parameters. However, if this were all there is, then the number of parameters would be proportional to number of clauses, so there is probably something else going on.
The goal is to compute Z(T). My guess is that number of parameters is somehow related to complexity of this function.
vloodin, good link.
Clique potentials V_c(f) are exponential in size of the number of configurations. For example if you have three nodes in the clique X,Y,Z which can take on binary values 0 and 1 then it would take 2^3 entries to fully specify V_c as something like so. The table of values could be something like
V_c(x=0,y=0,z=0) = .34 ( param 1)
V_c(x=0,y=0,z=1) = .34 ( param 2)
V_c(x=0,y=1,z=0) = .34 ( param 3)
V_c(x=0,y=1,z=1) = .34 ( param 4)
V_c(x=1,y=0,z=0) = .34 ( param 5)
V_c(x=1,y=0,z=1) = .34 ( param 6)
V_c(x=1,y=1,z=0) = .34 ( param 7)
V_c(x=1,y=1,z=1) = .34 ( param 8)
Therefore the number of parameters grows exponentially with the size of the clique. So in a fully connected graph with n nodes V_c would need 2^n parameters to specify. And a fully disconnected graph would only need 2 paramters for each node or 2*n values.
The key question is how does he go from FO(LFP) and k-sat to these graphical models and compare them in terms of size of cliques. Some of this is detailed in sections 4 and sections 7 but still fuzzy to me.
That is not the problem. The clique size is k, which is independent on n. In the expression for potential, we have m clauses, and if each is given by this number of parameters, number of parameters is not exponential. So he must mean something else.
I believe it is some number connected with complexity of Z(T), but it is never defined. Also it is not clear which set of distributions are parametrized/ allowed (Boltzmann under some variation of potential?)
I don’t think Vinay is using a direct mapping of SAT into a graphical model with clauses represented by cliques of size k.
He talks about embedding into a larger graphical model and has a picture on p. 74 that seems to visualize some of the construction. Along with some details on p. 48 on how to go from LFP to a directed graphical model.
His new ideas, I believe are just these constructions that go from LFP described computations to graphical models. Hopefully, he clarifies these constructions in more detail.
“Thus, your restriction to only have successor and to restrict to monadic fixed points is fundamental. In this domain—only monadic fixed points and successor—FO(LFP) does not express all of P! ”
http://scottaaronson.com/blog/?p=458#comment-45448
Tim Gowers’ weblog has just posted an equally good one: “Deolalikar is making a move that I, for one, had not thought of, which is to assume that P=NP and derive a contradiction.”
Vinay said yesterday “I was able to fix the issues raised with the earlier versions – the final version should be up in 3-4 days here.”
3-4 days from yesterday is August 15, Independence Day in India. So is there a Phoenix rising from the ashes?
Here is a PDF of one of the Joseph-Young papers, and another TR version (http://ecommons.cornell.edu/bitstream/1813/6340/1/82-500.pdf) of the paper “Polynomial Time Computations in Models of ET” that goes the furthest to what you may be doing with “towers” in the item you gave (?—here I’m being better at posting than reading:-).
Is this like the FIFA World Cup of the nerds.
OK, after reading through the ms I think I have isolated the fundamental problem with Deolalikar’s argument, which was disguised to some extent by the language of FO(LFP). It is simply that he does not address the issue of how polylog parameterisability is affected by reductions (or more precisely, by “forgetting” a bunch of auxiliary variables). This appears to be an extremely major oversight that more or less means that the real difficulty in the P!=NP problem has not even been touched by the paper.
Let me explain in more detail. Consider a random k-SAT problem with a nonempty solution space S (in {0,1}^n), and let mu be the uniform distribution on S. As I now understand it, Deolalikar’s argument proceeds by asserting the following two claims:
1. If k-SAT was in P, then the measure mu would be “polylog parameterisable”.
2. For a certain phase of k-SAT, mu is not “polylog parameterisable”.
This is the contradiction that is supposed to give P != NP.
What does polylog parameterisable mean? Basically, it means that mu admits a Gibbs type factorisation into exp(polylog(n)) factors, each of which only involve polylog(n) of the variables, organised according to some directed acyclic graph. For instance, the uniform measure on {(0,..,0), (1,…,1)} can be factorised as
mu(x_1,…,x_n) = 1/2 prod_{i=2}^{n} 1_{x_i = x_{i-1}}
and thus qualifies as polylog parameterisable (due to the acyclic nature of the graph with edges from i-1 to i); more generally, the output of a straight line program (and apparently, certain types of monadic FLP programs) starting from uniformly distributed inputs would be polylog parameterisable.
The thing though is that Deolalikar does not actually seem to prove 1. Instead he proves
1′. If k-SAT was in P, then _after embedding the original space of variables into a polynomially larger space of variables_ (see page 92), the measure mu lifts to a polylog parameterisable measure mu’ in the larger space. In other words, mu is the _projection_ of a polylog parameterisable measure.
For instance, if mu was computed using the final output x_N of a straight line program, one would have to add back in all the intermediate literals of that program before one obtained the polylog parameterisable structure. I give some examples of this on the wiki at
http://michaelnielsen.org/polymath1/index.php?title=Polylog_parameterizability
But what is completely missing from the paper is any indication why the property of polylog parameterisability would be preserved under projections. Thus, for instance, the uniform measure on the space of k-SAT solutions may well be so complicated that it defies a polylog parameterisation, but that if one lifts this space into a polynomially larger space by adding in a lot of additional variables, then polylog parameterisability might well be restored (imagine for instance if SAT could be solved by a polynomial length straight line program, then by adding all the intermediate stages of computation of that program we would get a polylog parameterisation).
Now I may be wrong in that the stability of polylog parameterisation with respect to embedding the problem in a polynomially larger space has been addressed somewhere in Deolalikar’s paper, but I have read through it a few times now and not seen anything of the sort.
Terry, you indicated why problems in P leads to polylog param. distribution mu but isnt it the case also for problems in NP?
Sorry, my earlier formulation of polylog parameterisation was misleading in this regard. It’s not enough that mu has a product formulation prod_C p_C(x_C) into local factors (which would already allow the uniform distribution of SAT to qualify, regardless of whether SAT is in P); the p_C(x_C) have to be organised in a “directed acyclic manner”, which means that they take the form p_i(x_i; x_{pa(i)}) where for each choice of parent literals x_{pa(i)}, p_i is a probability distribution in x_i.
Basically, polylog parameterisability of (say) k-SAT provides an efficient way to generate a random solution of that k-SAT problem (though not necessarily with the uniform distribution, see comment below, but merely a distribution that gives each such solution a nonzero probability).
What I was asking is this. Problems in P lead to a measure mu on the set of satisfying inputs which are “polylog parameterisable”. My question is: Isnt it also the case (perhaps by a similar argument) for all problems in NP?
If this is the case case then the missing argument “that k-SAT does not lead to such a parametrization” will also prove that k-SAT is not in NP which, while a surprising twist of events, much too good to be true.
Gil, I guess it may clarify things if we rename “polylog parameterisable” as “polylog recursively factorisable” (see Definition 2.12 of the paper). The uniform distribution on the k-SAT solution can be factorised as the product of local factors (one for each clause), but it is not _recursively_ factorisable as the product of local conditional probability distributions. On the other hand, if a problem and all of its partial completions are in P, then this seems to give a polylog recursively factorisable distribution on the solution space _after_ one expands the space to a polynomially larger one by throwing in additional literals in order to perform the P computations.
Isn’t there a trivial way to show that, if we allow projections, every problem i k-SAT is polylog parametrizable. For instance, we might make a graph that has many copies for each variable x_i, so that it is forced to be equal to original x_i, and then somehow to make a graph that directly gives distribution of solutions of k-SAT formula, using clauses as conditions.
I am also a bit puzzled why number of p_i in the product is n, equal to number of variables. Also, why are sums not in the definition. It seems rather restrictive to have just n factors.
I see now that there is probably no trivial way to do this, as we can sample efficiently even when we extend the space. Yet clearly, sampling solutions is as hard as getting them.
I got it, thanks. With this definition I am not even sure that the claim in D’s paper is stronger than NP=!P and amounts to a statement that there is no polynomial algorithm for k-SAT for some nice (albeit non uniform) distribution.
So, if somehow one can construct an argument that polylog parametrizability is preserved under projection, will that fix the proof ? or that itself is impossible?
Yes, but the task of proving that the projection of a simple computation is again a simple computation is essentially the claim that P = NP. Given what Deolalikar is trying to prove, this looks unlikely, to say the least…
Sorry, I should have said “is analogous to the claim that P=NP” rather than “is essentially the claim that P=NP”. The computational model here is quite different (polylog recursive factorisability rather than polynomial time computation).
To put it another way, I now think that what Deolalikar really proves in the paper is not that P != NP (i.e. the projections of polynomially computable sets need not be polynomially computable), but rather the much weaker statement that the projections of polylog recursively factorisable measures are not necessarily polylog recursively factorisable.
If this is the definition of polylog parameterizability, then isn’t it true that every k-SAT formula is polylog parametrizable? Namely, if N is number of satisfying assignments, then uniform distribution mu on the space of solutions can be expressed as
1/N prod_{i=1}^{m} p_i
Where p_i corresponds to the clause c_i, has the same k arguments, and is 1 if clause is satisfied, 0 if it is not satisfied. But clearly he wants number of parameters that is exponential.
What am I missing here?
What do you mean by “organised according to some acyclic graph”? I guess this would not allow my simple expression, but what expressions are allowed?
Perhaps you want uniform distribution to satisfy Markov network property (conditional independece) according to this graph, but how do you know such a graph exists?
I’ve written up a more accurate definition of the concept on the wiki at
http://michaelnielsen.org/polymath1/index.php?title=Polylog_parameterizability
and see also Definition 2.12 of the third draft of the paper (an earlier version of this wiki page was not precise enough). Basically, to be polylog parameterisable, one has to have an algorithm to sample from the solution space, in which the conditional distribution of each literal x_i is determined by the values of only polylog(n) parent literals.
In other words, each p_i must take the form p_i(x_i; x_{pa}(i)), where x_{pa(i)} are a polylog number of parent literals of x_i, and for each fixed instance of x_{pa}(i), p_i is a probability distribution in i.
Also, I realised that the distributions here were not quite uniform as claimed above; see my comment below.
Thanks. That makes some sense. So basically, you want to express uniform (or something like that) distribution with a distribution which is coming from some Markov network, satisfying conditional independence properties.
I can understand that having his model of computation, he can find such a directed graph (this is what he did in chapter 7, now 8), and sample a uniform distribution.
However, there should be also a computational model-independent way to determine this number of parameters, as he claims this number is exponential for k-SAT in hard phase. We could perhaps say number of parameters is minimum over all possible such graphs, but I don’t see why a uniform distribution can have such a directed graph at all.
So, a priori, given a distribution mu corresponding to solutions of k-SAT formula f, why is there a directed graph and expression in the corresponding way at all?
Yes, I do find it quite unlikely that the uniform distribution on the k-SAT solution space (or any other distribution with this solution space as its support) admits a recursive factorisation along a directed graph with only polylog degree. And it may well be that Deolalikar actually proves this using what is known about the clusters of k-SAT etc.
But I don’t see the paper address the real question, which is whether a measure on the k-SAT solution space can be the _projection_ of a polylog recursively factorisable measure in a polynomially larger space.
I meant expression in that form without polylog restriction.
But I see now there is one for any distribution, namely
p(x_1)*p(x_2;x_1)*….p(x_n;x_2,x_3,…x_n)
which takes 2^n-1 parameters, as you defined them.
As for the projection issue, perhaps there is some trivial way to get solutions to k-SAT with polylog parameters if we are allowed to extend number of variables, and then take projections.
However, this given that you can sample solutions efficiently if you have polylog parametrization in that sense (with additional variables, projection), perhaps what he showed is that P=NP implies that you can do this sampling easily, which is of course not hard to see.
So, the missing part would be: in the hard phase of k-SAT, sampling is hard.
So, the missing part would be: in the hard phase of k-SAT, sampling is hard.
Yes, this appears to indeed be the missing part. Deolalikar has apparently shown that sampling is hard if one is not allowed to introduce some intermediate variables for the sampling process, due to the geometry of the SAT clusters, but that is like saying that solving an n-bit SAT problem is hard if one is only allowed to use n steps in the computation. Once the intermediate variables are thrown in (as they are done in Section 8.3), this lifts the solution space to another space in which the cluster geometry could be completely different.
Isn’t that the result from statistical physics for k=9, that he uses? In the critical regime it takes an exp number of these parameters to specify the joint distribution. Hence, the contradiction.
It may well require an exponential number of parameters to specify a distribution on the original n-dimensional k-SAT solution space in the precise recursively factorisable form that Deolalikar needs. However, this does not seem to preclude the existence of a much shorter parameterisation of a distribution on some _lift_ of the k-SAT solution space formed by creating more variables. Since variables are certainly being created in Deolalikar’s argument, this creates a serious gap in the argument.
Let me quote the paragraph immediately preceding Remark 8.8 on page 92 of the paper, which I think is very revealing with regards to the entire strategy, and its inherent flaw:
A slight correction: the measure mu considered in the paper is not quite the uniform measure on the solution space k-SAT, but a slightly biased measure formed by selecting the literals x_1,…,x_n in the following slightly correlated manner. Assume inductively that one has a partial solution x_1,….,x_i to k-SAT, then at least one of x_1,…,x_i,0 or x_1,…,x_i,1 is also a partial solution. If only the former is a partial solution, we set x_{i+1} := 0 (we have no choice); similarly, if only the latter is a partial solution, we set x_{i+1} := 1. If they are both 1, we choose x_{i+1} to be 0 or 1 uniformly at random.
Note that if k-SAT was in P, this gives a polynomial time algorithm to generate a random instance of a solution to k-SAT, which gives each such solution a nonzero probability, but the probability is not quite uniform. As stated, it is not obviously polylog parameterisable because the distribution of each literal x_i depends on all of the preceding literals x_1,..,x_{i-1}. But if SAT was solvable by (say) a straight line program, then one could lift this distribution to one involving polynomially more literals in such a way that it was polylog parameterisable (each literal is selected in terms of a conditional probability distribution that involves only polylog many ancestors).
Terry, Several characterizations of P are known and let us say we prove one more that says problems in P are “polylog parametrizable.” All of these are resource shifting characterizations that shift polynomial time into another resource. Adding one more to the list will not be a surprise.
To me, the real play is on the other side, showing 3SAT/9SAT does not have this “polylog parametrizable” property. This is still a hard unconditional lower bound argument. How do we know that the k-Sat soln space cannot be “factorized” etc? Because there is no algorithm … cannnot be the answer without being circular.
Here is my intuition. Just as all NP-complete problems are isomorphic to each other (at least under AC^0 reductions) and are just disguises of each other, all characterizations are also just resource shifting which are basically the same in different disguises. Occasionally, we get a surprising characterization like IP=PSPACE or the PCP thm. They surprise because computation seem more powerful than we had anticipated or expected. The same is true with Primality as well. Given that the power of computation continues to surprise us, we really do not understand well what cannot be done. Which is why results such as derandomizing identity testing implying lower bounds excites us because they seem to give us hope.
In any case, there is nothing new that I have said that the community does not already know. The nub being that (1) and (2) in your comment points to a traditional resource shifting strategy in D’s paper. Your point that (1) is difficult to prove is likely true and well taken; but even if it is proved, so what? Can we really show (2)? I believe this is what holds the key. I am asking for a relative change in emphasis. Yet another characterization of P is not necessarily useful unless we make some simultaneous progress on (2).
Many thought V Vinay has taken permanent recluse from complexity theory. Great to see him back, at least in a commentary mode, and sharing sharp insights.
I think that Terry’s definition of polylog parameterizability above and at Polymathwiki is a fairly strong (severely limiting) one; in particular, the following two examples will not be polylog-parametrizable. Maybe this is just part of Terry’s point, but I thought I’d point out easy concrete things in case this piece of info is epsilon-useful.
(1) uniform (or any positive) measure on Even={x in the n-cube : x1+…+xn =0 (mod 2)}
(2) uniform (or any positive) measure on the n-cube – {(0,0,…,0)}
Claim: Let S be a subset of the n-cube, let Chi_S be the characteristic function of S on the n-cube, and let mu be a measure on S such that mu(x) > 0 for each x in S. Assume that mu is polylog parametriable. Then, there is some permutation (reordering) of [n] such that Boolean function Chi_S(x1,..,xn) can be expressed/computed as follows:
Chi_S(x1,…,xn) = AND_{i=1,…, n} g(xi; xj’s), where each g is a Boolean function of xi and polylog-many xj’s with j < i.
We can see the claim by focusing on measure being zero or nonzero in the definition of polylog paramateizability. Now consider (1). With respect to any ordering (permutation) of [n], the membership in Even cannot be expressed by such an AND as in the claim because the last factor g(xn; xj's) only depend on *fixed* polylog many xj's. By the same reason, (2) is not polylog parametrizable. (To express (1) and (2) in such a form, the last g(xn; xj's) have to depend on all n variables.)
Indeed, though your example is not in k-XORSAT, it clearly shows his point:
there are distributions polylog parametrizable in projections, but not polylog parametrizable without projections.
EVEN can be polylog parametrized if we add a number of auxilary variables, placeholders for partial sums, so that we never add more than polylog elements (we can always add a fixed number).
However, as you pointed out, without these variables, EVEN is not polylog parametrizable according to Tao’s definition.
It is also easy to see that k-XORSAT can be polylog parametrized with projections, but it is not clear to me if it can be polylog parametrized without projection according to Tao’s definition.
Jun, earlier you were saying that Deolalikar’s simplicity definition applied only to problems in a subset of P — problems with all their projections in P. But Terry’s interpretation of polylog-parametrizability (with projections) applies to all functions in P. This appears to give us mildly contradictory accounts of what Deolalikar is claiming. Do you have a view about which is correct? (Perhaps they are both correct and Deolalikar’s strategy is different in different parts of the paper …)
I like these examples, particularly the second one, because the uniform distribution on has no non-trivial conditional independence properties whatsoever, which reveals that the “link between polynomial time computation and conditional independence” to which Deolalikar devotes an entire chapter is completely absent if one does not allow the ability to add variables (and thus change the geometry of the solution space drastically).
has no non-trivial conditional independence properties whatsoever, which reveals that the “link between polynomial time computation and conditional independence” to which Deolalikar devotes an entire chapter is completely absent if one does not allow the ability to add variables (and thus change the geometry of the solution space drastically).
Case 2 is interesting because clearly the last factor only needs 2 numbers to specify it’s distribution, one for when all the previous variables are 0 and one for all other cases, in other words the last variable becomes independent if any of the previous are non-zero.
If we can’t capture these kind of relationships in the solution space then the representation seems too crude. How would we distinguish XOR-SAT from 3-SAT if this was the case?
I guess this is obvious to you experts, but I’d just like to point out explicitly that both (1) EVEN and (2) have the property that all their projections are in P, and that there are obvious polynomial algorithms to extend any partial assignment.
So from what I think I understand of this discussion, they seem to be in the class of problems that Deolalikar needs to have “easy” structure, and so the version of parametrizability that doesn’t use projections cannot be used.
Tim, my point was only that Deolalikar is using, in his reasoning, the simple fact that if k-SAT is in P, one can decide, given a partial assignment s, whether a satisfying solution y extending s exists. I think the same thing was also mentioned by Russell Impagliazzo: http://rjlipton.wordpress.com/2010/08/12/fatal-flaws-in-deolalikars-proof/#comment-5429
I think D’s reasoning above certainly is *not* a big deal; it is not a possible way around the natural proof’s barrier or anything. On the other hand, I found your post at your blog (= Tim Gowers’ blog) interesting, where you talk about a class of poly-time functions with the property that for any projection P, existence of a solution in P can be poly-time computable (the same thing as the n-dim 0-1-colored hybercube induced by a poly-time Boolean function with the property that determining if there is 1 in any given subcube is also in P).
As for polylog parametrizalibility, I think what we may consider include the following. They are related but seem to be nonequivalent. I will just give a list; I don’t have anything useful to say about them at present.
(1) Terry’s definition with projections (with poly-many auxiliary variables) for the distribution on the *graph* of f:{0,1}^n –> {0,1}, i.e., the distribution on {(x1,…,xn, f(x1,…,xn) ): x in the n-cube} induced by the uniform distribution on the n-cube.
(2) parametrizability of the uniform, or some, distribution on the solution space, i.e,. on f^{-1} (1) (as opposed to the graph space above)
(3) sampling (= generating) a point in the solution space with *some* distribution with support equal to the solution space (This is explained in the last part of Terry’s wiki entry for polylog parametrizability)
(4) poly-time samplability of the solution space, i.e., sampling a solution uniformly (or nearly uniformly): This is in some sense a reverse view of Terry’s definition with projections: Start with the uniform distribution the r-cube, the set of random r-bits that a sampling algorithm can use; use auxiliary variables to represent intermediate states of computation, which will be projected out (thrown out); the distribution on the *outputs* x1,,,,,xn must be (nearly) equal to the uniform distribution on the solution space.
(5) In my previous comment, I pointed out that Terry’s definition without projection is fairly limiting. I guess one can consider extending his definition (without projection) in some ways.
For example, we can consider distributions D(x1,…,xn) expressible as a *sum* over poly-many distributions L(x1,.,,,,xn) each of which is expressible by Terry’s form (Ordering of variables may be depend on each L).
“But what is completely missing from the paper is any indication why the property of polylog parameterisability would be preserved under projections. Thus, for instance, the uniform measure on the space of k-SAT solutions may well be so complicated that it defies a polylog parameterisation, but that if one lifts this space into a polynomially larger space by adding in a lot of additional variables, then polylog parameterisability might well be restored (imagine for instance if SAT could be solved by a polynomial length straight line program, then by adding all the intermediate stages of computation of that program we would get a polylog parameterisation).”
Does D actually need to show this? He is assuming that P=NP and deriving a contraction. So if D has lemma of the form:
“Suppose P=NP. Then the projection of a polylog paramaterisation is polylog,”
then the actual status of projections of polylog paramaterisation is irrelevant. (Sorry if I’ve missed the point, or if this is dealt with below.)
This is a fair point; P=NP is certainly a very big tool available to Deolalikar. On the other hand, it does seem now that we have some basic counterexamples (see e.g. the wiki) that show that projections of polylog parameterizable distributions need not be polylog parameterizable. It would still be that P=NP implies the negation of this statement, but then we could prove P!=NP more efficiently by a contradiction argument than by using any of Deolalikar’s machinery at all.
First on notations: (i) quasipoly(n) = exp(polylog(n)) = 2^polylog(n) = n^polylog(n); (ii) I’ll use the abbreviation ‘ppp’ for ‘projection-polylog-parameterisable’ as defined by Terry above and at the wiki *except* that I’ll allow quasipoly-many auxiliary variables; (iii) f will denote a function mapping {0,1}^n to {0,1}; (iv) the *solution space* of f means the set f^{-1} (1) ; we’ll assume this set is nonempty; (v) the *graph* of f, graph(f), is the following subset of the (n+1)-cube with size 2^n: graph(f) = {(x1,…,xn, f(x)): (x1,…,xn) in the n-cube}; we’ll consider the distribution on graph(f) with support size 2^n induced by the uniform distribution on the n-cube.
I think that the following holds.
Prop. The following are equivalent.
(a) f:{0,1}^n –> {0,1} is in nonuniform-quasiP.
(b) The distribution on graph(f) is projection-polylog-parameterisable (ppp).
(c) The uniform distribution on the solution space of f is ppp.
(d) Some distribution whose support equals the solution space of f is ppp.
Proof Sketch: (a) –> (b): Explained by Terry.
(b) –> (a): The same thing as what I said above about the two examples (also explained at the wiki) applies; that is, ppp for the distribution directly yields a factorization representation by 0/1 *Boolean* factors. If each Boolean factor depends only on polylog many parents xj’s, this can be expressed by a quaipoly-size Boolean circuit, thus f can be computed by a quasipoly-size Boolean circuit.
(a) –> (c) (hence also (d)): Explained by Terry; express the uniform probability weight of each solution in the solution space by dividing Terry’s factorization expression by the size of the solution space (as opposed to by 2^n in Terry’s formula).
(d) –> (a): By the same reasoning as in the part for (b) –> (a) above: All that matters is nonzero (=positive) vs zero.
Remarks: (1) I’m talking in terms of quasipoly because that helps stating things in a simple way; the same reasoning above works for P.
(2) In Terry’s expression for ppp, consider posing the further limitation that, istead of p_i(x_i; polylog many x_j’s), each p_i has the form p_i(x_i; x_j), where *single* x_j is one of input variables x_1, …, x_n, i.e., j is an integer between 1 and n. This definition leads the complexity class L (= deterministic logspace): Think in terms of deterministic polynomial-size branching programs; use poly-many auxiliary variables to represent nodes in the branching program.
Caveat: My confidence for what I’ve said is not exactly high… ; I’m writing from Tokyo, and it is getting fairly late…
I see a potential problem with (c)(d) when you use projections. Without projections, this is clear: you divide by number of solutions N and each factor is 0 or 1. But when you take projections, the extended space has much more than N solutions, its “geometry” is completely different. Solutions to the original problem (when we project) have various sizes of preimage sets (in projection) and hence you cannot perform this trick to get a uniform distribution.
Or in other word, using equivalence of ppp to distributions which can be computed using probabilistic TM (see my simple proof below), if we can get some distribution using probabilistic TM, your result would imply that we can get a uniform distribution, which I am not sure is true.
Yes, it may be that a problem needs to be in something like #P in order to be able to easily sample the _uniform_ distribution in a ppp manner, in order to get all the normalisations working properly. (Without #P but just non-uniform quasiP, I think one can still write the uniform distribution as the product of local factors in quasipolynomially many variables, but these factors will not be organised along a directed acyclic graph and so cannot be used to easily sample the solution space uniformly.)
I am assuming that, for projection poly parametrizability, auxiliary variables (those which will be projected out) are *binary*. With this assumption/qualification, I think what I’m claiming holds. For the direction (a) –> (b) or (c) or (d), one automatically gets binary binary auxiliary variables. For the other direction, I need the assumption that each auxiliary variable takes only quasipoly many values with positive probability; but to make a story simple, I want to assume these are binary. If we allow auxiliary random variables to take exponentially many values, then these auxiliary random variables can “encode” input n-bit vectors as their values, and any function can be parameterized by O(n) such random variables.
With the assumption above that auxiliary variables are binary, I think what I’m claiming holds.
As for the comment by Terry: Please note that I am *not* saying anything about poly-time sampling, and that since we are talking about a *fixed* function f, the number of its solutions is *fixed*, and *not* something we have to count (by a #P computation, etc).
As for the comment by vloodin: Suppose that we are given a projection-polylog-parameterisation for a Boolean function f on the n-cube with m solutions, i.e, |f^{-1}(1)| = m. When we transform this ppp into a circuit, it is true that the number of bit vectors (x_1, …, x_n, x_{n+1}, …, x_q) with nonzero probability can be much larger than m, where xi’s other than x1, …, xn are auxiliary variables. But the sum of the probability weights of all such bit vectors with a *common* n-bit initial prefix (x1,…,xn) is 1/m, and thus our transformation does work through (I think).
It’s not just the number of solutions of {x: f(x)=1} that one has to count in order to factorise the uniform distribution; one also has to count the number of solutions to partial problems such as { (x_{i+1},…,x_n): f(x_1,…,x_n) = 1}. To do this in a quasipoly manner basically requires the various projections of f to be in (quasi-)#P.
I retract my “proposition” above (in my comment at 1:23pm) about (a)–(d) being equivalent; my “proof” was wrong. (vloodin and Terry, thank you for pointing out and explaining) For convenience, let me repeat conditions (a) — (d):
(a) f : {0,1}^n –> {0,1} is in nonuniform-quasiP.
(b) The distribution on graph(f) is projection-polylog-parameterisable (ppp).
(c) The uniform distribution on the solution space of f is ppp.
(d) Some distribution whose support equals the solution space of f is ppp.
The implication (a) –> (b) does hold as explained by Terry at the wiki; for all the other implications that I claimed, my proof sketches were wrong. But I think that there are some things we can say about (b) — (d); I’ll continue.
I think that (c) is basically equivalent to the condition that there is a poly-time randomized algorithm that samples a solution with respect to the uniform distribution on the solution space. I say “basically” because we have to allow an error of 2^{-quasipoly(n)} for the statistical distance.
For the direction (c) –> sampling, we can give a sampling algorithm A as follows. Let y1,…,yq be binary random variables in a projection-polylog-parameterisation for f, where (q-n) variables among y1,…,yq are auxiliary ones. For y1,…,y_polylog, i.e., for the first polylog-may yj’s, algorithm A computes their joint probability weights for all the possible 2^polylog binary values within precision 2^{-quasipoly}. Using its own random bits, algorithm A “picks” one particular polylog bit vector as the value for (y1,…,y_polylog), and continue. Note that the factorization expression naturally yields an expression for the distribution conditioned upon the first polylog yj’s being a particular vector. So indeed algorithm A can continue till it obtains a particular sample for (y1,…,yq); A can then return the appropriate n-dimensional projection of this sample.
In general, up to within 2^{-quasipoly} accuracy, for any measure mu on the n-cube, the following two are equivalent: (1) measure mu admits ppp with quasipoly-many auxiliary variables; (2) sampling according to mu can be done by a quasipoly-size probabilistic circuit. So condition (b) and (d) respectively imply corresponding sampling.
As for (b) vs (a): For some function g, it may well be the case that sampling from graph(g) is easy, but even the average complexity of g is high: Consider G:(x, r) –> (f^{-1}(x), r, x*r), where f is a one-way permutation on the n-cube, both of x and r are n-bit vectors, and * is the inner product mod 2, i.e., the setting of Goldreich-Levin Theorem. Computing G is hard, but sampling on graph(G) is easy.
I do not like the structure of comments at wordpress, many of the recent comments are hidden in the middle of the page, so I would like to recall Lenka Zdeborova’s comment as I am very curious to know the answer:
Could Deolalikar’s approach prove that P != #P?
No, that comment had to do with speculation about Z(T), and I think the answer is clear no, in the context it was given.
Vinay Deolalikar. P is not equal to NP. 6th August, 2010 (66 pages 10pt, 102 pages 12pt). Manuscript sent on 6th August to several leading researchers in various areas. You can find an older version here. Many researchers advised me to prepare a concise synopsis of the proof. I have done so, you may obtain it here. The 3 issues that were raised were (a) the use of locality and the techniques used to deal with complex fixed points (b) the difference between 9-SAT and XORSAT/2-SAT and (c) clarification on the method of parametrization. I will address all these in the version being prepared, which will be sent for peer and journal review.
This is excellent news. If he does clarify this, then we will be able to see clearly if this proof works after all.
For any physics types in the low-rent ‘crowdsource’ section watching, like me, this wonderful conversation with a bag of popcorn in hand:
The author has a notably good taste in textbooks and having a bunch of us comb them for perspective is a contribution well within our reach, or in any event a fine way to spend a bit of spare time in August.
My copy of Mezard and Montanari, Information, Physics, and Computation just arrived and it looks like a page turner. I’ll quote the first paragraph:
(emphasis mine).
Indeed.
Now that Statistical Physics, Information Theory, and the Theory of Computation has had it Woodstock, perhaps we will be seeing more of one another. The hot topic driving this in Industry is, by the way, message passing algorithms in a Cloud Computing context, and their promise of scale. It surely comes as a shock to us Physicists that Belief Propagation and neural nets obey Hamilton-Jacobi formalism! And even recently schooled grad students of Neural Nets seem never to have heard of Spin Glasses or Glauber dynamics. Perhaps this event will finally break down that barrier — and I suspect that will be its enduring value to both the Physics and the Industrial Mathematics communities.
In any event the book has a high text to formula ratio and looks to be a good read. Its ToC is available at Amazon link, and it covers the 1RSB cavity method. I see contributers above among its readers. I am unrelated to the authors, their institutions, and live on the other side of the planet from them….
The term “Industrial Mathematics” is cute 😉
Can you give a reference on this Belief Propagation – neural nets – Hamilton-Jacobi connection, I would be interested to learn. Thanks.
This is definitely a sidebar, however there seems to be a deep connection between Belief Propagation (and its generalisation Expectation Propagation) and a sort of theory that comes out of optimal control theory for stochastic signals.
Here is a good page on Expectation Propagation:
http://research.microsoft.com/en-us/um/people/minka/papers/ep/roadmap.html
Anyone reading this not already familiar with Loopy BP, EP, and factor graphs (probably a minority of the contributors to this conversation but certainly including me since I am just learning!) will really enjoy Minka’s 1-hour lecture on the topic, the first link on the page cited. This may give you a feel for where ‘Industrial Maths’ is at these days.
The connection to signal theory is profound: in that lecture, Minka shows the connection to Kalman filters, for example, as a natural consequence of running forwards then backwards over a certain sort of factor graph.
In any event, it seems that Hamilton-Jacobi has a stochastic cousin:
http://en.wikipedia.org/wiki/Hamilton-Jacobi-Bellman_equation
the discrete version of which is Bellman’s equation (this is the same topic that Economists call ‘Recursive Methods’ — see the famous text by Sargeant and Lundkvist for an example) and which OR types call ‘Dynamic Programming’ – the reason why one is ‘working backwards’ is obvious to anyone who has seen these techniques in action in those respective fields).
and the claim is that that *backwards* belief propagation just recovers HJB the same way that forwards and backwards combined, running over the factor graph, gives you Kalman filtering. I don’t claim to understand the result — just to be surprised and amazed by it as a physicist who is now aware computer science is a lot more interesting than it looked at first glance. 😉
Again, it looks like physics and comp sci (and signal theory and ‘the stochastic calculus’) are coming together in unexpected ways. However, this is so far off topic that anyone who wished to discuss it may contact me via my (dated but still functional) LinkedIn page, linked to my name.
Best Regards and good luck to you all in your quest!
On the k-XORSAT problem:
Using definition of number of parameters that Terrence Tao has suggested, we can analyze uniform distribution on solutions of k-XORSAT.
Since k-XORSAT is a linear problem, and space of solutions can be expressed in terms of parameters (like in the linear algebra), which we can take to be some of the variables. Without loss of generality (permuting variables if necessary), for easy notation, assume x_1,… x_l are independent parameters for this linear space.
Then let p_i for i<=l be uniform distribution i.e. (1/2, 1/2), then we can factor uniform distribution on the solution space:
p_1(x_1)p_2(x_2)*..*p_l(x_l)*p(x_{l+1};x_1,…x_l)* …*p(x_n;x_1,…x_l)
However, this is not polylog parametrization if l is not of order polylog(n). The following question is then interesting: can we do a polylog parametrization of this form?
Note that all equations are of the fixed size (k variables, it is k-XORSAT). So, can we always get a polylog parametrization? This seems like a fun thing to consider
It is easy to see that if we allow additional parameters, we can indeed do a parametrization which is polylog. All we have to do is to introduce intermediate results, say if
x_{l+1} is expressed as sum of many of the basic variables x_1…x_n, we can introduce intermediate variables, holding sums of polylog factors. We could even do sum two by two. We are allowed to do O(n) such sums, since we add number of parameters for each factor, and for each factor, we have 2^arity parameters. So we easily get 2^polylog parametrization, but only at the cost of extending number of variables.
Thus, given what D. is assuming (he does this extension of number of parameters in chapter 8), for him, this would be enough.
But if we do not allow this extension of parameters, is then polylog parametrization possible?
I meant variables (parameters in the linear algebra problem) above, when I said parameters at the beginning. This should not be confused with parameters with respect to Tao’s definition, which are also mentioned; sorry if this caused confusion.
What is the the experts’ opinion? Will P != NP ever be proved? I have been sceptical on the grounds that the collection of all programs that can be computed in a polynomial time is so immensely complex.
I see that Razborov and Rudich have been able to prove the non-existence of a ‘natural proof’ for P != NP. In this blog discussion someone said that P != NP might be independent in some axiom systems.
One thing puzzling me with his synopsis is the comment there is empirical evidence that 3-SAT does not enter a d1RSB phase, which would imply no contradiction if it was polylog parameterizable.
Isn’t this different behavior between 3-SAT and 9-SAT a fundamental contradiction since both are in NP and his machinery seems to suggest that 3-SAT is polylog parameterizable and 9-SAT isn’t?
Jeff, the trouble with 3-SAT is that the clustering was not proven rigorously, because it is technically more difficult. In the statistical physics terminology (which is different from the one of Deolalikar) 3-SAT does not have this d1RSB phase. But it has a frozen phase very nearby to the satisfiability threshold, which is so far empirically unpenetrable for polynomial algorithms.
I have been blissfully away from the blogosphere. I just wanted to mention a few things. First of all, the goal of sampling uniformly random satisfying assignments is, of course, a much harder goal than finding a single one.
1. we believe, but have no proof, that 3-SAT enters a clustered phase, but not with frozen variables.
2. we believe that in this phase we can find a satisfying assignment in polynomial time — but that we _cannot_ sample uniformly random satisfying assignments in polynomial time.
This is partly why physicists call this the “dynamical” transition, since local search algorithms will get stuck in particular clusters and fail to sample the entire space.
3. we have a proof for sufficiently large k that there is a clustered phase with frozen variables. We believe that in this phase, even finding a single satisfying assignment is hard.
4. we have a proof that XORSAT enters a clustered phase with frozen variables. However, because of its linearity, even in this phase we can sample uniformly random satisfying assignments.
I’m sure this is redundant with some other people’s comments (including my own 🙂
I think very little is missing (if anything) to prove Cris’s statement n. 2 in the 3-coloring problem if one restricts to local Markov chain sampling. The 1RSB threshold is at average degree 4, there is a rigorous link between necessary local Markov chain sampling time and reconstruction on trees. And in 3-COL and old lower bound on reconstruction tells us that above 4 sampling with Glauber dynamics takes exponential time. At the same time Cris himself proved that simple algorithms work up to 4.03.
As far as I can tell, any SAT instance can be reduced to a SAT instance with large (and deterministic) separation of solutions. Attempts to use arguments about “separation of solutions” would then need to explain an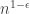 -separation, for any $\epsilon > 0$. Apologies for the diversion, but editing complex comments is quite tough, so have posted details over at A simple reduction.
-separation, for any $\epsilon > 0$. Apologies for the diversion, but editing complex comments is quite tough, so have posted details over at A simple reduction.
(This seems like a colossal cheat so it may well be wrong. Comments would be appreciated.)
I will look directly to the ACKNOWLEDGMENTS in the revised version of Deolalikar’s paper.
On the Tao’s definition of number of parameters:
With this definition, the following problem, solvable in P, has exponential number of parameters (see comment above by Jun Tarui about EVEN):
n-XORSAT (which is just system of linear equations, say m equations of n variables; we ask if there solution to this system, system not assumed homogenous)
On the other side, it (i.e. uniform distribution on solution space) is a projection of a c^polylog parametrizable distribution (obtained by adding variables, placeholders for partial sums) in the Tao’s sense.
I don’t know if the same holds for k-XORSAT, but for purpose of a counterexample, n-XORSAT is just as good. It is in P, yet not 2^polylog parametrizable.
Hence, if Tao’s definition is what D. had in mind proof does not stand. He needs to prove he does not have a polylog parametrization with projections in hard phase (as Tao suggested, and this is just a concrete illustration/counterexample for this).
If D. had definition of the more general form in mind, namely this: solution space uniform distribution (or the like) is polylog parametrizable if it is a PROJECTION of polylog parametrizable distribution in the Tao’s sense, then the following would be true:
1. In this more general sense k-XORSAT is c^polylog parametrizable, but possibly not k-SAT.
2. His arguments based on computational model could as well show that if P=NP, then k-SAT solution space has a (quasi uniform) distribution that is c^polylog parametrizable in this more general sense. His promise to fix the bug in this part, which seems plausible enough to give it benefit of a doubt, could as well turn out to be fulfilled.
3. With this more general definition, the shift is to the part that claims, from statistical physics, that in hard phase in this sense distribution a-priori not 2^polylog parametrizable.
The point 3. is not even considered in D.’s paper at this point, other than referring to the physics results.
But even if he has some proof in mind, it is more likely that he proved it for more restrictive Tao’s definition. As example above clearly shows, this definition cannot work.
It seems to be much more easy to come to ends with a paper, when definitions are given. It also shows that good starting point for analysis is knowing what is EXACTLY meant by number of parameters. Hand waving there can easily obscure fundamental errors.
Nevertheless, if he does fix bug in the part 2. D will have a potentially useful reformulation of P=NP problem. It would be enough to prove that in the extended sense (which includes projections) k-SAT is not polylog parametrizable.
It is unclear if this leads to anywhere, but it is still interesting (provided 2. is fixed). It reduces P=NP question to a form that may be more tractable, certainly a partial result that can stand on its own. It also gives (all that if 2 is fixable) a new way, other than circuits, finite models etc. to study complexity problems. Number of parameters as a measure of complexity (providing the definition is clear, like the one Tao suggested or rather a bit stronger version) would be this new approach, and essential contribution coming from D’s work.
In the view of my comment below, that seems to give an easy argument for 2. it seems that it is a bit of an overstatement to say this is a valuable new approach. It just shifts the question of P vs NP to impossibility of polynomial time circuit sampling of k-SAT. So it shifts P vs NP to a harder question, and thus, it is useless.
Ryan Williams has a map which takes any infinite collection C
of satisfiable formulas into a subset C’ of SAT0, the set of
formulas satisfied by the all-zeroes assignment.
He then claims that this set C’ has “analogous solution structure”
to C.
But I don’t know what such a claim is supposed to signify.
Solution structures are attached to problem definitions, not to
sets of formulas, right? What exactly are the problem definitions?
If the original problem was [here’s a formula, is it in set C],
then maybe he’s considering the transformed problem to be
[here’s a formula, is it in set C’].
But the trivial decidability of SAT0 doesn’t seem to solve this
problem; it can sometimes give quick “no” answers but can’t give quick “yes”
answers because the map from C to C’ is non-uniform. In other words,
the hard part isn’t the variable assignment, it’s the [is it in set C’] part.
I believe his remark does not show what he claims. For there is no “solution space” for SAT0 (which corresponds to a closed formula) to speak of, i.e. SAT0 is not analogous to k-SAT in a way that it can replace it in D’s proof.
I will explain what I wrote once more. I can see that the phrase “solution space of SAT0” causes a nasty knee-jerk reaction. So I will state the problem completely in terms of k-SAT:
There is an infinite collection C of satisfiable k-SAT formulas with two properties:
(a) C is decided by a single, simple algorithm
(b) For any other collection C’ of satisfiable k-SAT formulas, the collection C contains a subcollection of formulas with solution distributions that require at least as many parameters to describe as C’ (provided I understand “parameters” correctly, which I think I do now, thanks to Tao and vloodin).
You can guess what C is. So the idea that we are capturing the complexity of a problem by showing how hard it is to generate satisfying assignments at random, doesn’t work. The statement that random k-SAT requires too many parameters should have a hole. I apologize if I didn’t make that clear.
If the current draft of the paper no longer is subject to this objection, that’s OK with me. I am planning for the future.
Let us consider the following claim: Suppose we can get a certain probability distribution on a set of binary variables (x_1,…,x_n) using a polynomial time run on a probabilistic Turing machine. Then our distribution is a projection of a c^polylog parametrizable (in the sense of Tao) distribution.
This claim seems to be pretty much what is done in the last chapter of D’s draft, using finite model theory, as it seems. But there appears to be a much easier direct proof of this.
It involves looking at a Cook-like table for the probabilistic Turing machine.
Suppose algorithm takes T steps on probabilistic Turing machine, and takes space which is of course bounded by T. T is less than poly(n), and can be encoded by O(log) bits. Now we add T^2 auxiliary variables for content of relevant stretch of Turing tape at every time T, plus O(T*log(T)) auxiliary variables encoding position of the head at each moment, as well as state of the machine (which takes O(1) bits for every moment). Now content of each cell at time t+1 is probabilistic function of position of the tape, previous content of that cell at time t and state of the machine, i.e. it clearly has a fixed polylog input. The state of the head and the next position are function of previous state and content of the cell under the head. This last is a problem, since position of the head is not fixed. To get transformation of the head, we need a fixed node in the graph that can read it. For that, we add more auxiliary variables in the following way. We introduce T (size of the tape) variables for each step of computation, that simply copy content of the tape cell p if p=position of the tape at that step, and write a dummy symbol (denote it by *) if p is not equal to position of the tape. Then we “add” these together using O(log(T)) auxiliary variables (adding 2 by 2 at a time) so that *+*->*, *+x->x. This will read state of the cell using a fixed graph. Then we update state of the machine and its position using a fixed node holding the “sum”. In this way, we have constructed a directed graph and parametrization in the Tao’s sense, with number of parameters that is in fact polynomial in n (and hence O(c^polylog), we see that we in fact have a bit better than this, polylog is here O(log^2) ). At the end, we remember just the final state of the cells where result is written, i.e. perform a projection, and get our distribution.
So, if this is correct, then there is a trivial proof that polynomial sampling gives rise to a projection of polynomial-parametrizable distribution, which is content of chapter 8.
So, it appears that step 2. can be fixed, in fact it is something easy, no need to prove this using finite model theory. Also, if we have a distribution with polynomial number of parameters, then we can sample it in polynomial number of steps (though this is on a circuit level). Thus, polynomial parametrizibility is just the same as polynomial random circuit sampling, and c^polylog parametrizibility is c^polylog random circuit sampling.
The non-trivial part is to show that k-SAT distribution does not have polynomial number of parameters (this is weaker than O(2^polylog), and of course than the claim that we need exponential number of parameters, in the Tao’s sense but allowing for projections). But as we see, this is just as hard as showing that k-SAT cannot be sampled in polynomial time (using circuits), and harder than showing k-SAT cannot be sampled in polynomial time (using algorithms); note that distribution is not uniform, as Terrence pointed out.
So does this follow from statistical physics results? Of course not, this would be an entirely new result. Yet not a word about how condensing implies exponential number of parameters is in D’s draft. And clearly, any proof of this would be proof that k-SAT does not have easy sampling, which is no easier than P!=NP in the first place.
Thus, as Terrence said, it seems that this paper does not even touch the P!=NP question.
Let’s not overstate and say that part 2 is true and has an easy proof and part 1 is the only missing part. Deolalikar’s claim was that poly-time algorithms have simple solution spaces and this is not what part 2 shows. We all know that projections of simple objects need not be simple themselves. This is the P vs NP question itself and has provable manifestations in many other domains.
There is a small correction – to “add” T numbers (using dummies) we need O(T) nodes, not O(log T) – we construct a tree of depth log(T), but on first level there are T/2 nodes, then T/4 etc.
On another note, about the question of a-priori estimating number of parameters (with projection), there seems to be some point to D’s approach. He essentially defined hardness of solution space by difficulty of sampling a quasi-uniform distribution on it (distribution is not uniform, but is easy enough to define, see Terrence’s comments). Thus, while in circuit complexity we had to deal with circuits that solved various instances of k-SAT, here we have probabilistic circuits that sample solutions of a single instance k-SAT formula. Now perhaps someone can answer this: how does the natural proofs barrier apply to this setting? I do not know enough about natural proofs barrier to answer this, but it appears that these probabilistic circuit samplings are subject to the same barrier as ordinary circuit complexity. But maybe, just maybe, there is a difference.
Also, D’s approach does give a way to separate easy from hard instances of k-SAT formulas. For each formula, his approach defines (difficult to compute) number of parameters constant, that is minimal number of parameters needed for distribution in Tao’s sense, but allowing projections. It is similar to another constant which can be defined to measure complexity of a k-SAT formula, that is complexity of a circuit determining if a partial assignment can be extended, which is just an application of circuit complexity, known to be subject to the natural proofs barrier.
Note that non-uniform distribution that appears seems to depend on the order of variables. So a complexity invariant is up to this order, but one would guess these should not vary that much (or one can take order that has minimal number of parameters). But I am skeptical how useful this invariant, a number attached to each single formula f from k-SAT, really is.
vloodin: A measure of “instance hardness” would have many practical applications, but I don’t see how one could efficiently compute this measure. This seems at first glance as hard as establishing the Kolmogorov complexity of an associated circuit (as you also seem to suggest).
Also the variable ordering is critical: for algorithms based on exhaustive search, this is the main challenge. By arranging the search tree with the solution leaves clustered together, a deterministic depth-first search can find the first solution in logarithmic time, and list the rest in near-constant time per solution.
Yes, it is as hard as that. This definition seems to have same problems as circuit complexity approach, which is natural proofs. So it seems rather useless when we come to the bottom of it.
vloodin’s proof can be made even simpler: there is no need for a complicated encoding of the head position. One can just use oblivious machines, at the cost of a multiplicative logT factor, which is OK for polynomial T.
“But what is completely missing from the paper is any indication why the property of polylog parameterisability would be preserved under projections. Thus, for instance, the uniform measure on the space of k-SAT solutions may well be so complicated that it defies a polylog parameterisation, but that if one lifts this space into a polynomially larger space by adding in a lot of additional variables, then polylog parameterisability might well be restored (imagine for instance if SAT could be solved by a polynomial length straight line program, then by adding all the intermediate stages of computation of that program we would get a polylog parameterisation).”
Does D actually need to show this? He is assuming that P=NP and deriving a contraction. So if D has lemma of the form:
“Suppose P=NP. Then the projection of a polylog paramaterisation is polylog.”
then the actual status of projections of polylog paramaterisation is irrelevant. (Sorry if I’ve missed the point, or if this is dealt with elsewhere.)
What is the arity of Rp ?
If a researcher were to prove that P=NP, presumably the proof would be easily checked because he or she would suggest an algorithm and we’d all type it up in our favorite programming language and watch it solve hard problems fast.
A proof of the non-existence of such an algorithm is obviously much harder, which is why (I assume) most of the attempted proofs are long sequences of math statements instead of algorithms we could check by running. I’m curious if there are any ideas for a (possibly very long running) algorithm that could test all the cases of 3SAT and prove that for each possible configuration, no simple solution exists, essentially a proof of NP!=P that is similar to the 4-color theorem proof. Anyone know of any work in that direction?
(A proof that P = NP might not lead to a practical algorithm — it might be a non-constructive proof, or it might provide an algorithm whose complexity was a “very large” polynomial, e.g. of exponent 1000 or even 10^(10^1000), which would be useless in practice. In real life, even an exponent of 4 or 5 is usually hard to make practical use of.)
Ok, you’re right about the non-constructive case, where all the person does is prove “there exists…”. But for the high power polynomials, we could still confirm time empirically on small values of N, even if it couldn’t handle anything large enough to be of real world value.
That’s still a tangent off of my main question — is there any brute force “division of the 3SAT into testable cases” algorithm that anyone has proposed? Is that a direction from which researchers have ever tried to attack P=NP ?
I am a professor of Computer Science in University of Hyderabad located in Hyderabad, India. Ours is a post-graduate and research institution and is recognized as one of the best universities in India. On Saturday, 28 August 2010, we heard a talk by Prof. Narendra S. Chaudhari (currently a visiting professor here in our department but in real-life, Professor at Dept. of Computer Science and Math at IIT, Indore). He said that the work is a result of more than 4 years of his efforts and also it is the first time that he is going public with it. The talk, titled Computationally Difficult Problems: Some Investigations gave a constructive procedure for solving 3-SAT problem in polynomial time (O(n^13)). Of course, the implications, if the procedure is true and holds in general are enormous as it also implies that P = NP. I found the procedure fascinating as it is fundamentally different from all existing ones that I have seen. The main trick lies in representation that allows Chaudhari to cast the 3-SAT problem in terms of the CLAUSES and not the literals. The complexity is fundamentally different because the mapping from literals to clauses is exponential while from clauses to 3-SAT is linear. There are space-time trade-offs and also aspects of dynamic programming involved in his constructive procedure. One the whole, the attempt appeared very serious and worth looking into more closely. I cannot still recover from the talk and there is a feeling of being a part of something momentous even if someone later finds a flaw in his procedure. The procedure appears to ring true on many critical aspects and I am speaking as a true-blue CS academic:-) A full account of the work is published in the Journal of the Indian Academy of Mathematics (Vol 31(2), 2009 pp 407,444) and a copy is available at this link. Prof. Chaudhari said that he has communicated the paper to some of the experts in our field and is awaiting comments, but thought that your blog is a great place to post given the people that seem to read it.
The paper does not report on actual runs of the algorithm, which seems like it should be easy to program. Neither do the slides. There are competitions on heuristics for solving SAT going on all the time—see section 7 of Wikipedia’s SAT page and references from there, including http://www.satcompetition.org
Most to the point, these competitions have lists of hard instances on which to test the algorithm. Of course I expect that carefully programming it would reveal errors. The paper needs to compare the algorithm to the well-known technique of resolution. The slides should also reference the mid-1980’s attack on P=NP by Ted Swart of Guelph University, whose error though blunt was tough to refute concretely, and hence led to some interesting work.
Thanks for the suggestion that careful programming is expected to reveal the errors: a few independent groups are in my contact and they have initiated the careful programming you have suggested. Testing on a few datasets in fact gave encouraging results.
Ted Swart’s work, if I remember correctly, was on Hamiltonian Circuit problem: I had seen the work earlier sometime in mid 1980’s but I am unable to trace it now. I dont think my approach has some similarity with that work. I would highly appreciate a copy on my gmail account (nsc183@gmail.com) to explore the possibility of refering to the same.
3-SAT-Satisfiability Algorithm step V suggests possible invariants for the necessary
algorithm correctness proof, namely that T contains a list of top-level restricted
literals, Wx,x contains such a list when x = true and Wx,y contains such a list when
the pair of literals (x,y) = (true, true). Naturally one wonders why there is no
need for a set Wx,y,z to contain such a list when the
triple of literals (x,y,z) = (true, true, true).
I’d want to try the algorithm on $(\notp \or \notq \or t) \and (\notr \or s \or \not t)
to observe how the Truth-Value Assignments Algorithm avoids serving up the
non-solution p=T q=T r=T s=F.
Part 1: (why there is no need for Wx,y,z): The justification is based on how the approach is developed using “literal-pair” as antecedent (for 3-Clause representation).
Part 2: (explanation of how the non-satisfying truth-value assignment is avoided) : explanation based on C-matrix (Clause representation) takes care of avoiding the non-satisfying truth-value assignment. (i have prepared the detailed steps for the example you have suggested, and I would email you the file containing the same: I could not attach that file with the present comment).
Vinay gave a talk at HP Labs today – it was very high level and had no details. He claimed that some of the experts in the field have “okayed” his revised version.
A proof of the non-existence of such an algorithm is obviously much harder, which is why (I assume) most of the attempted proofs are long sequences of math statements instead of algorithms we could check by running. I’m curious if there are any ideas for a (possibly very long running) algorithm that could test all the cases of 3SAT and prove that for each possible configuration, no simple solution exists, essentially a proof of NP!=P that is similar to the 4-color theorem proof. Anyone know of any work in that direction?
That is not the problem. The clique size is k, which is independent on n. In the expression for potential, we have m clauses, and if each is given by this number of parameters, number of parameters is not exponential. So he must mean something else.
Have not read the other comments yet, but look forward to doing so later. This is a great conversation from someone completely outside this community of intellects. I’m glad to have stumbled upon it and forgive amateur understandings, but my preliminary two cents below.
He’s precisely right though. P{\neq}NP *only* in that model which I get if one model its {\neq} then that means it cannot be purely P=NP because there is obviously one model that isn’t =. BUT that is only considering the problem as a boolean of binary logic model and as Neil right points out there is a wraparound that could self contain the monadic fixed point model with {\neq} AS WELL AS models where it = and not be in conflict