It’s Still the Slime Mold Story
Short paths for love and glory 

Kurt Mehlhorn is a theorist who has made many contributions to almost all aspects of theory. A recurrent theme is the balance of beautiful theory with potential practical applications—most of his work has some of each. He has made contributions to: data structures, computational geometry, parallel computing, VLSI design, computational complexity, combinatorial optimization, and graph algorithms. He is famous beyond the theory community for his work on LEDA, the Library of Efficient Data types and Algorithms. And he has also been the director of the Max Planck Institute for Computer Science.
Today Ken and I want to talk about yet another paper on slime mold—when will these papers stop?
Just kidding. The paper in question is one of the first to study the general computational power of a slime mold, namely Physarum polycephalum. The paper is joint with Vincenzo Bonifaci and Girish Varma, and is about to appear at this winter’s SODA conference in Japan. While there are many cool papers at SODA 2012—change that to all papers at SODA are cool— this appears to be the only one with the name of a particular type of slime mold in its title.
As a nod to Wikipedia’s “blackout”, here is a picture of black slime mold, along with one of slime mold finding shortest paths in a maze:

I have known Kurt for many years, and have always been a great supporter of his and an admirer of his beautiful work. One of the surprising issues that arose early in the LEDA project was the issue of accuracy. I have talked about it before here: the short story is that even simple computational geometry algorithms can fail in practice, if one is not careful with the issue of finite precision. Quite surprising.
Let’s turn to the computational power of a class of creatures that are called slime molds—a wonderful name.
Slime Mold
When I worked on DNA computing in the late 1990’s, I talked often to biologists. One of the hot areas of research then, and I believe still, is the study of slime molds. I have to admit as a computer scientist that the name of the area did not exactly get me excited, but slime molds are important. There are entire conferences devoted to this single subject, for example.
You may ask why are they so important? A good question. I believe there are several reasons that biologists continue to be so intrigued with slime molds. One is a pragmatic reason: slime molds are easy to work with in the laboratory. They are not hard to grow, to manipulate, or to pay for—mice, for example, are several orders of magnitude more expensive to experiment with. Another is that slime molds have behavior that is more complex than one might imagine, especially given their simple biological structure. Here is a quote on this:
There are few creatures more remarkable than the lowly slime mold.
But is the slime mold really a creature? Or is it a fungus? If it’s not a fungus, is it a single entity—or millions? Or both?
Animal, Vegetable, or Model?
Another way to regard their complexity is the Pluto effect. Recall Pluto was once considered a planet and now is no longer one. When scientists change their minds about what something is, that suggests to me that something complex must be involved. Slime molds were formerly classified as fungi, but are no longer considered part of this kingdom.
Perhaps the most important reason is they exhibit interesting behavior. For example, if you physically divide a mass of slime mold into two pieces on a dish they generally find they way back together. One of the world experts on them, John Bonner, states that they are:
no more than a bag of amoebae encased in a thin slime sheath, yet they manage to have various behaviors that are equal to those of animals who possess muscles and nerves with ganglia — that is, simple brains.
This is pretty neat. As a computer scientist it sounds like he is saying: here are very simple little computational agents and yet as an ensemble they can “compute” quite non-trivial things. This is exactly the types of problems we love: a simple computational device that exhibits complex behavior. Even more relevant to today’s highly distributed and networked world is the paradox: how can simple local rules afford interesting complex computational behavior? This is where slime molds come in to the picture: indeed here is a picture of one.

Luckily we do not have to look at them too much, or even worse grow them, but we can build a simple mathematical model that appears to give good approximations to their behavior, and thereby try to figure out how they work. This is exactly what Kurt and his co-authors have been able to do, in greater generality than previously established.
The Big Picture
One of the driving forces behind the new computational interest in slime molds is a seminal experiment performed by Atsushi Tero of Hokkaido University. He grew the mold Physarum polycephalum on a standard dish, but placed both attractors and obstacles on the dish. The attractors were food—oat flakes if you must know—and the obstacles were bright light. The mold is attracted to food—who is not?—but is camera shy and tries to avoid bright light. Tero for fun arranged the attractors and obstacles to model the major centers in the Greater Tokyo Area. The mold initially filled the whole dish, but over time evolved into a network that connected the centers in a way that closely approximated the actual Tokyo rail system.

Tero introduced a model that claimed to represent the behavior well. Roughly the model was a time varying electrical network. The next major result was by Tomoyuki Miyaji and Isamu Ohnishi. They proved that Tero’s model converges to an optimal solution in any instance of a planar graph.
What this means is that the slime mold units that are initially on non-optimal edges in the graph eventually gain information about this fact and move off them. In the model this is analogized to “taking the path of least resistance” in an electrical network. Here, however, the network itself is adaptive: the resistance an edge changes with time in connection with the organisms’ movements as well as the fixed cost of the edge itself. Eventually edges that are not part of any optimal solution see their resistance grow unboundedly. The nodes in the graph have derived potentials, and these regulate the flow of current which corresponds to how the organisms congregate.
The big picture is that millions of years of evolution can generate organisms responding to local properties (like “potential”) that still collectively solve global computational problems. We may learn from Nature how best to solve non-trivial problems by cheap local means.
Sketch of Model and Result
As in Tero’s original model, every edge 







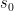


The current 

The magnitudes are normalized by stipulating an overall flow of 





At equilibrium the edge derivatives are all zero, so the normalized current in an edge 


Thus far this is all Tero. The achievement of Kurt and his co-authors is to remove the planarity restriction on 
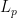
Theorem 1 For any graph
as above, the dynamical system is attracted to
. If
is a unique path then the dynamics converge pointwise to the flow of value
along that path.
The main innovation in the proof is finding the best Lyapunov function to impose on the system while attempting to bound it over all iterations. This was actually done experimentally by regarding various instance graphs as parallel networks. This enabled them to handle arbitrary graphs. As usual the considerable details are in the paper.
I like the fact that this work requires the analysis of a dynamical system. Theory is currently great at many things, but the understanding of dynamic or iterative methods is not one of them. Also we see—is this allowed?—the use of continuous differential equations and related methods in a discrete problem.
They further show that the same dynamic electrical system can be used to solve the transportation problem, which is a generalization of the shortest path problem. This leads us to ask, what else can be done this way?
Open Problems
We quote Kurt:
The Physarum computation is fully distributed; node potentials depend only on the potentials of the neighbors, currents are determined by potential differences of edge endpoints, and the update rule for edge diameters is local. Can the Physarum computation be used as the basis for an efficient distributed shortest path algorithm?
Indeed can these or related local rules be used to solve other problems? For instance, can they be upgraded to evaluate networks of Boolean gates, at least heuristically? Note that the circuit value problem is 
[inserted a missing “(t)”, added slime mold photos to intro]


A (possibly) related “Is this allowed?” work is Sergey Verlan and Yurii Rogozhin’s survey New Choice for Small Universal Devices: Symport/Antiport P Systems :
Symport/antiport systems lend themselves naturally too, to interesting questions at the microscopic level: How do phenomena associated to spacial separation arise spontaneously in dynamical systems whose Hamiltonian lacks a formal notion of space, but does support symport/antiport dynamics?
A request; could you please elaborate on this thought-provoking comment:
“Theory is currently great at many things, but the understanding of dynamic or iterative methods is not one of them.”
Philip,
We should do whole post on this. But for now let me give some intuition. There are many very powerful algorithms are work very well in practice that are iterative. And for most of these theory can prove nothing about them. In the area of SAT solvers there are such algorithms that work well and make iterative improvements. In the area of TSP the famous methods of exchange—local search—work very well. But in neither case can we prove anything.
Thank you, Dick and Craig, for the explanations. Very interesting! I would love to see a whole post on this. I wonder if some of the tools and concepts of finance can be usefully applied to study such dynamic algorithms.
In general, in order to know the outcome of an iterative method, you have to perform the iterative method until it terminates. If you can reduce the iterative method to something simpler, you don’t have to go through all of its steps, but this is usually not the case.
Theory usually can only tell you some general characteristics of the outcome of an iterative method (or how fast the method takes until it stops) but cannot tell you the exact outcome.
In the case of the TSP, there is a fair bit that we know about the worst-case behavior of local heuristics (as David Johnson’s survey outlines). In general, the ‘formal’ way to attack iterative methods has been via PLS and PPAD, but it is true that more problems remain open than have been solved.
Millions of years of selection. Spend a a week in a forest and you’ll see a lot of interesting things..
How do we get rid of it if it is found?? We are freaked out.