When is a Law “Natural”?
When numbers channel minds as much as minds channel numbers

Adolphe Quetelet was a Belgian mathematician who pioneered the use of probability and statistics in the life sciences. He was a successful writer of opera librettos and poetry and literary essays while teaching mathematics at school and then college level, at the College of Ghent. There Jean-Guillaume Garnier recognized his talents as a mathematician, and invited him to do a doctorate at the just-created University of Ghent, which he completed in 1819. Then he heard the call of Interdisciplinary Research (IR), and went on to found the Royal Observatory of Belgium and the field of what he called “social physics.”
Today I (Ken) wish to talk about some statistical laws that seem to straddle the boundary between social science and “hard science.”
The term “social physics” had already been coined by the French philosopher Auguste Comte, who disagreed with the mathematical focus applied by Quetelet. Deciding to switch rather than fight, Comte re-christened his work sociology, by which name we know the field today. Comte also coined the term altruism, which did not get similarly stepped on. Quetelet’s term fell by the wayside, but his work so galvanized a field with an already-known name that he is sometimes called the “Father of Statistics.”
Quetelet always saw his work in the larger context of science, and as early as 1826 he gave courses in the history of science. He also gave popular lectures on applications of probability theory to various branches of science. We cite three of four quotations from these lectures given in his biography here:
- The more advanced the sciences have become, the more they have tended to enter the domain of mathematics…
- It seems to me that the theory of probabilities ought to serve as the basis for the study of all the sciences, and particularly of the sciences of observation.
- Since absolute certainty is impossible, and we can speak only of the probability of the fulfillment of a scientific expectation, a study of this theory should be a part of every man’s education.
His book On Man and the Development of His Faculties quantified the concept of the “Average Man” and distribution of biometric properties—this was the first application of the normal curve beyond its initial formulation to describe errors.
Population Dynamics
Quetelet also did some luring of his own, attracting Garnier’s other doctoral student away from his post-doctoral intent to collect and publish the complete works of Leonhard Euler. This was Pierre-François Verhulst, who pioneered the use of equations to model changes in populations of living things. Verhulst noted Euler’s description of exponential laws of growth, but saw the need to model constraints that would limit such growth. The simplest and most efficacious way was to modify Euler’s differential equation (with initial condition 

into

where 

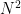


Here is an example of a select population of living beings whose numbers have closely followed such a logistic curve since it came into existence in 1971.

For such small numbers of specimens, the curve is not too grainy and the agreement is striking. It is not a population of exotic snails or salmon swimming past bears upstream, but one that has included me as a member for most of this time. The full legend given in my joint paper with Bartlomiej Macieja (who compiled the figure) and Guy Haworth shows this to be the number of players rated above 2200 by the World Chess Federation (FIDE) each January since the Elo rating system was adopted in 1971. That is the floor to be called a “Master.” My rating is about 2400, and I own the title of International Master which is typical of that strength. Macieja is a Grandmaster and is rated about 2600, while today’s best players are rated a little above 2800.
Now when I competed in a big room full of Masters last July, I did not observe Masters fighting over scarce chess sets or predators carrying losers out of the playing hall for dinner. There are many more books and computerized resources for improving one’s game today than in the early 1990’s when the pace of growth was steepest. So why has my population been following such a law? Is it just because it’s salient, the simplest thing that models a cap on growth?
Natural Statistical Laws
I am told that many such equations since Verhulst’s have been formulated, and they are usually followed “messily” rather than neatly as above. Note also the comment in Wikipedia’s biography of Verhulst that the logistic-curve model was rediscovered in 1920 amid promotion of “its wide and indiscriminate use.” The variety of interdisciplinary applications favors our calling it a statistical regularity, but the lack of uniqueness backs us off calling it a natural law.
When can regularities of behavior in humans or other biota be regarded as a natural law? Ironically, one requisite I suggest is that the kind of human distinction that was the focus of Quetelet’s statistical treatise should have no role in the operation of such a law. It may require some special ability to participate in the experiment that measures the law, such as skill at chess—but it is better when the law operates just as well for players of Dick’s strength and below, as for my strength and above. This past weekend I have discovered a candidate for such a law. It even has a fixed number: 58%.
The Nature of Rybka
Rybka is the commercial chess program written by Vasik Rajlich which was considered the world’s strongest from 2006 until recently, when programs of varying rumored degrees of derivation from it have nipped ahead of it in some informal competitions. Now Rybka itself has come under a cloud for alleged uncredited derivation from a free-source program called Fruit. Fruit gave rise to Toga II, whose programmer Thomas Gaksch helped me personally until late 2008, by which time Rybka 3 came out and was rated over 150 Elo points stronger than its nearest competitors then.
As with virtually all chess programs—called “engines”—Rybka’s search progresses in rounds that add one more move of lookahead to the previous round. Each round computes for each legal move a value in the standard chess units of centipawns—hundredths of a pawn. Rybka maintains the list in sorted order and uses this order to prune the search for moves recognized as inferior. In the normal Single-Line Mode (SLM) of playing only the best move or moves are guaranteed a full search, but for game analysis one can use Multi-Line Mode (MLM) which gives full treatment to the 


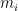
My statistical model usues as input the move values obtained after the 13th round of search—those values are the only things specific to the game of chess. It has two parameters called 

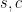



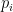

![\displaystyle (\forall s,c)[v_i = v_j \implies p_i = p_j]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%28%5Cforall+s%2Cc%29%5Bv_i+%3D+v_j+%5Cimplies+p_i+%3D+p_j%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
After all, two moves of the same value are interchangeable as far as the program is concerned. The sort doesn’t have to be stable, and the search-pruning would work as well if the order of equal-value moves were randomized at each round. My model uses only the values, so equal-value moves are peas-in-a-pod, no?
A sophisticated thought tells you that since values are rounded in the display but could be kept internally to higher precision, the knowledge that 
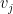


The Law of Rybka
Cases where Rybka shows two or more moves tied for equal-best are common, indeed over 13% of positions that occur in games. Hence I found out early on that human players chose the first-listed move significantly more often than the others, approaching 58% when just one other move is tied. Since the overall spectrum has humans choosing one of the first three moves listed over 85% of the time, I resorted to a “fudge factor” only for these equal-top cases. To induce a 58%-42% split my curves said to drop the value of tied moves by about 1.5 centipawns (i.e., by 0.015), but curiously I found that doubling this worked better in the fitting. So I closed my eyes and punched a 0.03 fix into my 10,000+ lines of C++ code, getting decent results though still feeling that my model was somewhat out-of-tune.
All of my analysis has been conducted on one ordinary quad-core 64-bit home-style PC. It takes typically 6-8 hours to analyze a game—since I skip turns 1–8 and games average about 40 turns this means 30–35 moves for each player. It often takes 10–15 minutes to analyze an early turn to depth 13 in 50-line mode, scaling down to under half a minute in the endgame. Overall it’s about 10 moves (5 for each player) an hour, so allowing for some pauses, each core does about 80,000 moves per year—and in 2-1/2 years of operation I’ve amassed over 750,000 moves done this way—supplemented by over 10,000,000 moves on my other 4-core PC where almost 200,000 games representing the major history of chess have been done in SLM which takes 10-15 seconds per move (except when Rybka 3 goes into an unexplained hours-long stall, a huge and frequent headache which has impeded me from doing automatic scripting and recruiting helpers). All this has gone on in background windows while I do research, write papers, copy-edit and compose blog posts, and everything else including sleep.
Only last weekend did I realize I’d amassed enough data to test cases of equally-valued moves that are not tied for best, indeed are markedly inferior moves buried way down the list. I expected a regression to 50-50, but found instead a house-of-mirrors effect:
Whenever Rybka 3 depth-13 gives the same value to two moves—even inferior moves—the move listed first is preferred by human players 58% of the time, independent of rating or whether the turn number is 9–20, 21–40, or > 40. When three moves have the same value the splits are 44%–32%–24%, whose first and second pair have the same 58% ratio, and similarly for four-or-more tied moves. There appears to be no more deviation than comes from Bernoulli trials that have these true probabilities.
For instance, my data set includes every move of every game played in tournaments of “Category 20” and higher, meaning an average Elo rating at least 2725. Out of 127,258 moves, 7,107 of them give the same value 
I have posted most of my raw data here, with the above plus my 2700-level training set plus all recent world championship matches collected into a file TopRange.txt, games by 2200–2600 players labeled MasterRange.txt, and games mostly by 1600–2200 in MidRange.txt. In the union of those three files there are 55,306 cases with a two-move tie within the top ten moves where one of those two moves was played. The move listed first was selected 38,048 times, for 58.26%. Then I isolated cases where the move played was inferior by a full pawn or more—really a “blunder.” Such a move cannot be tied for first-best, but in every other index position I see similar results:
| 2nd–3rd | 160-109 | 59.5% |
| 3rd–4th | 170-101 | 62.7% |
| 4th–5th | 136-110 | 55.3% |
| 5th–6th | 95-71 | 57.2% |
| 6th–7th | 78-46 | 62.9% |
| 7th–8th | 81-47 | 63.3% |
| 8th–9th | 50-42 | 54.4% |
| 9th–10th | 57-39 | 59.4% |
Super-Fishy, or Superficial?
A blunder is called a “fish move,” while ironically “Rybka” means “Little Fish” in Polish. What can possibly be causing human players to have such a uniform preference for the first-listed of two equally bad moves? When I try this on the three skill divisions of my data set, there appears to be no sensitivity to rating. Nor does it matter much when I restrict to early moves in a game—note that this basically excludes the trace of cases where promoting a pawn to Queen or Rook has equal value because the opponent will capture it regardless, but of course players will choose the Queen.
I don’t yet have a robust hypothesis on the cause, but I can offer a tentative one. I intend to extend my model from the fixed depth 13 to a probability distribution over values at all depths. That is to say, at every move, every human has a set chance of playing like a fish or playing like Fischer. For myself I know I sometimes make a move on superficial impulse, then sigh in relief that a reply I didn’t see can still be met…or not. The first-listed move may be there because of a superficial difference that the computer program picks up in its raw evaluation function as the iterative minimax search begins, with the move never dislodged owing to stable sorting, and perhaps this is what we human players pick up. The better players play like Fischer more often, but perhaps there is not much difference in our occasional “fish mode.”
My work has turned up other regularities. The vast majority of chess games nowadays impose a time control at Move 40. Right now I am following a game by my co-author Macieja via Chessdom.com’s real-time site, and it is Move 28 with both players having only minutes left to make twelve more moves. It is no surprise that the average error ramps up steadily to Move 40 then drops back like Niagara. This is an obviously human factor of procrastination and decision making under stress, and should not be confused with a natural law. In-between is my discovery that the probabilities depend on the values of moves relative to the overall value of the position, much as one should really judge price movements in stocks relative to the current price rather than absolutely. That is to say, human players follow a simple log-log law of scaling, which my program corrects for.
Not only does the 58% regularity seem more spooky and less explainable, but after I imposed it by fiat on my probabilities—and upon my also weighting moves according to the entropy of the inferred probability distribution (namely, by 
My “Fidelity” site has other updated material since last week.
Open Problems
Can you explain the regularity? What significance does it have?
Does it show equally for any chess engine that uses iterative deepening with a stable sort? Does the property pertain to the program, to chess, to brain biology, or something information-theoretic?
Can chess masters be said to “detect” differences of one-hundredth of a pawn in the value of a move, on grounds that they are observed to select the epsilon-better move a significant 55% of the time? Is it still the slime-mold story?
Trackbacks
- Amir Ban on Deep Junior | Combinatorics and more
- The Problem of Catching Chess Cheaters | Gödel's Lost Letter and P=NP
- A Chess Firewall at Zero? | Gödel's Lost Letter and P=NP
- Unskewing the Election | Gödel's Lost Letter and P=NP
- Magnus and the Turkey Grinder | Gödel's Lost Letter and P=NP
- Stopped Watches and Data Analytics | Gödel's Lost Letter and P=NP
- London Calling | Gödel's Lost Letter and P=NP
- Predicting Chess and Horses | Gödel's Lost Letter and P=NP


Ken, like you I am a computer chess aficionado, and it has long seemed to me that Rybka may be improving the accuracy of its search score estimates by a “burning arrow” trick that is broadly analogous to Borel summation.
Let us suppose that in reporting scores to ply (for example) 13, Rybka actually has conducted a search to ply (for example 13+6=19), using the six extra plies solely to weight each score with the future geometry of the search tree. In Rybka’s (postulated) “analytically continuated” evaluation strategy, the value assigned to each position is a coarse-grained, often-tied value that is computed from the position itself, plus a (small) “analytically continued” correction that is associated to the future breadth of the search tree.
The intuition is that the game-winning value of Rybka’s use of “analytically continued” position-scores is not the (small) improvement they yield in the accuracy of the evaluation of the position per se, but rather the (large) improvement these corrections induce in the efficacy of search-tree pruning and in the geometry of the search trees so pruned.
In a nutshell, Rybka’s computational strategy may be “evaluate shallow, prune deep”. And it would not be surprising to find that human chess-players of every caliber use a similar move-choice heuristic.
Would it be cheating for Rybka to report as a ply-13 score a value that includes search-breadth corrections to ply-18? Or does Rybka’s (postulated) shallow/deep local/global evaluate/prune method constitute a valid “burning arrow” insight that yields a tremendous game-winning advantage? The history of mathematics guides us as follows:
With regard to burning arrows, my sympathies reside mainly with Emile Borel, with Rybka, and with Rybka’s ingenious author Vasik Rajlich.
Summary: the more burning arrows in chess and mathematics, the better! 🙂
John, you may be touching on an aspect of Rybka that I cut from my overlong first draft: Rybka treats the bottom 4 plies of the search as a unit, so its reported depth 13 is widely speculated to be “truly” depth 12+4 or 13+4. (Part of this is that when you interrupt Rybka, it often reports its current depth as “-2” or “-1”, and once I saw “0” in the Arena GUI.) These may implement the Borel technique you mention. There are of course also the usual search extensions, and Rybka also does Monte-Carlo simulations though perhaps only if you request them—otherwise it is deterministic on a single CPU thread.
I guess what you’re saying is that the extra search gives the former of equal-valued moves a true “deeper value” greater than the 0.0033 cp over the other move that comes from conditional expectation. But then I would also expect this to obtain for moves valued 0.01 to 0.05 apart, which do regress to 50-50 the worse the move itself becomes. My scaling law mentioned at the very end may be coming into play here, but then why doesn’t it apply to the equal-value case?
I should mention that my data format gives the overall value of the position, i.e. the value of the move the computer likes best, and shows other moves’ values as “deltas” from that—with an asterisk * marking the move that was played. These are unscaled values—i.e., before the log-log scaling. The best move is included in the “delta” line, thus (*0.00,0.02,…) means the best move was played and the top two moves were 0.02 apart as given by the engine. One can explore just using ordinary UNIX “fgrep” and “wc”. [A small proportion of moves have indices where the next delta goes down, and almost all of those are cases where the value of the position or of the move were “extreme” with a 4-pawn difference, and either Rybka’s own “Multi-PV cap” or my manual intervention after a stall cut the depth on the latter move.]
A while back I was wildly thinking about different perspectives of our brains, in terms of how they store data and do dynamic calculations. It was just one of many ideas and I’m not commited to it, but I thought that the information we store might come in a large series of ‘models’ (structurally related symbols), and that we had some form of async multi-threaded processing that was primarily driven by the traversal of these models. I’ll skip most of the details, but I focused in on how I thought that a physical limitation like P != NP might play out in this biological context.
Our notion of ‘intelligence’ is built around the idea that it is some form of underlying deterministic process that is applied to what we know. But my digging into other concepts like ‘infinity’, ‘the continuum’ and possibly even ‘random’ have made me question whether or not these are merely artifacts of our abstract though process. If we takes these, and intelligence, as being theoretical notions that don’t have absolute manifestation in our physical reality — similar to how the halting problem affects Turing machines but can be resolved via approximation on actual computers — then we might conjecture that there only exists discrete estimations for many or all of these abstract notions.
If that were the case, then our actual intelligence would simple be an estimate to our concept of intelligence. And as such, as a person increased their knowledge and abilities by constructing more detailed and complex internal models of the underlying game of chess, they would converge closer and closer on some concrete limitations imposed by the best-case possible estimation towards playing the ‘perfect’ game. Thus, if any of this were true, we would see human players converge on behavior (because of time limitations) that would be significantly less precise than a fully deterministic theoretical model would indicate. Thus separating our inherent intellectual abilities from those of a computer with an infinite amount of resources.
But then again it is Friday 🙂
Paul.
Kean, that’s interesting that Rybka is thought to contain “burning arrow” (nonstandard) search structure.
In this regard, we can imagine an ingenious young chess programmer who conceives a search strategy that never computes numerical evaluations at all, but rather maintains an ordered list of all the positions that it has examined, using for this purpose some (transitive) ordering function that (perhaps) has no explicit numerical representation. At each ply, it’s trivial to purge the move-list of all now-past moves … it’s less trivial to infer an alpha-beta-like pruning of the list solely from the ordering (in fact I myself have no clear idea how to do it) but let us assume that list-pruning too is achieved in some reasonably effective and efficient way.
Thus, at any given moment, the program can specify a sorted list of moves, from good-to-bad … which is all that is needed to play good chess …
…… but of course human customers want more: they want a comparative numerical score (in centipawns) of the first few moves in the list…… even though the computer maintains no such list…… and (perhaps) neither do skilled human players (Ken, you would personally know much more about this than me! 🙂 ).
Therefore, it is conceivable that programs like Rybka compute their numerical scores by very crude means … essentially by a one-or-two parameter centipawn curve-fit to the ordered position list.
The resulting computer chess program would describe its moves rather like Bobby Fischer, who famously said:
In this regard I myself play chess very much like Fischer … except for the part about always choosing the *BEST* moves. 🙂 🙂 🙂
Typo in quote: “part of very man’s education” –> “part of every man’s education”?
Thanks—the typo is in the source; I missed it while adding an “l” to make the American spelling of “fulfillment” 🙂
I believe this might get you started, if I could I would spend more time seeing if this actually leads to the correct answer to this particular problem. The 58% made me think about another measure related to gaussian distributions, the Absolute Deviation [1]. Unlike the standard deviation, for absolute deviation, 58% of results reside within 1 absolute deviation from the mean.
A quick search for absolute deviation finds a nice reference to L1 norm statistics [2]. When one pulls the thread a little more, you run into taxicab geometry and an interesting link to chess [3].
I would be interesting if the conclusion was that the statistics of the board was somehow linked to the statistics of the decision.
[1] http://www.physicslabs.umb.edu/Physics/sum06/Error_Analysis_182_Sum06.pdf
[2] http://en.wikipedia.org/wiki/Absolute_deviation#Minimization
[3] http://en.wikipedia.org/wiki/L1_norm#Measures_of_distances_in_chess
Stable sorting means that the first ranked move of a tied pair is equal at round 13 but better for some earlier round. If a human player is also doing a search but with fewer rounds, he would be expected to prefer the first move.
How does the score difference between a pair of moves depend on the number of rounds? In particular, how often does it change sign, or change to or from zero?
If you run Rybka with fewer rounds r and/or smaller width k, how often does it prefer the first of two tied moves?
Stable sorting means that the first ranked move of a tied pair is equal at round 13 but better for some earlier round.
Hmmm. No, it can be the case that the two moves in a tied pair have always been tied. For example, endgame tablebases are full of positions where most (or all) of the legal moves result in the same outcome with optimal play.
If a human player is also doing a search but with fewer rounds, he would be expected to prefer the first move.
Ah!
When a top-notch human player enumerates all of the legal moves in a position, she can be expected to enumerate them in nearly the same order as any other top-notch human player. (Or that player’s avatar, e.g., Rybka; everyone is trying to be Fischer and “just” enumerate the best move first.) The order in which the legal moves are enumerated/evaluated is very important in computer and human chess, and I would expect Rybka’s authors to have invested a huge amount of effort in fine-tuning that enumeration order. By comparison — the numerical scores? Eh, not so important.
Tesauro made a similar observation about TD-Gammon. Its estimated numerical values of the different moves in a backgammon position were often inaccurate, with errors large enough that human experts “should” have an easy win. But the relative ordering of those different moves was correct, so that the better move came earlier.
Is that 58% related to some statistic about permutations?
Ralph Hartley hits some questions that are on my agenda—they will require an upgrade to my data-collating scripts. They may also require using Stockfish or another engine, as Rybka hides what is going on in the bottom-most levels of the search, and also often skints on showing moves of its principal variation, so one cannot always tell when lines transpose. F. Carr is quite right about the order being more important than the values for alpha-beta, and furthermore I regard the values as having “noise” I ascribe to hash collisions which regularly cause differences of 0.02–0.03 or so when one re-runs using a different hash-memory setting or multiple cores. I don’t believe the 58% has a pure-mathematical cause or significance. I’ve run significant amounts of Single-PV analysis using Stockfish (1.8), enough to tell that its depth 19 gives 0.00 evaluations much more often than Rybka 3’s depth 13—but not yet enough Multi-PV analysis (about 8 hours per core per game on my hardware) to tell whether Stockfish would have a different number on tied moves.
By coincidence the NY Times ran an item last Sunday on sociology’s “physics envy”, which animated the choice of terminology by its inventors in this post’s intro.
Maybe you have measured something about Rybka’s eval function. It is easier to evaluate larger changes… so I think a move’s eval will converge more quickly during search when it is a better move. This would tend to cause better moves to sort above inferior ones even if they happen to have the same eval at a given round — effectively revealing information beyond the search horizon. By averaging over human decisions in your game corpus, maybe you’ve managed to measure this. If true, it could also be measured with Rybka alone, by comparing evals and eval histories of moves at round 13…
“It is easier to evaluate larger changes”
This is true but it doesn’t justify what I’m suggesting. Justification is that an eval will converge more slowly/wildly when fewer continuations lead to the best game result, or the best line starts with a move that’s less obvious to humans and machines (e.g. not a capture or a check). At round 13, a move Y may finally obtain the same eval as move X, though X would be pragmatically better in that it’s easier to play. Such X would tend to be sorted higher in a stable sort. Humans may prefer them because they prefer the certainty, or simply because they fail to find the (obscure) best line for Y.
Or maybe he’s measured a property of any “reasonable” (no, I am not prepared to give a definition) evaluation function. It isn’t necessary that the first sorted move be better, it just needs to be easier to find (or to evaluate). The way the moves are sorted implies that it often will be. Humans have to prefer easier to find moves because they have much more limited search ability.
The apparent universality of the preference, may reflect a property of the number of moves that change relative position as a function of search depth.
Yes, I think you’re right that they don’t have to be better (as I later realized) in the minimax sense. Presumably though, a faster-converging line reduces future search effort and chances for mistakes, while the trickier (slower-converging) line makes things harder for our opponent. Perhaps we should favor faster-converging lines if we are down on the clock and trickier ones if we have more time left than our opponent. Anyway, the convergence of evaluations strikes me as a fertile territory. . .
Thus far Stockfish is showing similar behavior. I think it’s a fairly uniform property of the kind of algorithm used. I have not yet had time to sift through large numbers of cases to see if they really are what I suspect: equal-valued moves include functionally-equivalent pairs where one choice is more surface-attractive both by human and eval-function considerations.